
引言
掌握表的基本运作之后,若想优化查询效率并简化数据访问,就要去学习"索引"和"视图"的运用,索引类似于"书籍目录",可以极大地加快查询速度;视图类似"数据窗口",能够隐藏复杂的查询逻辑,还能控制数据的可见性。本文就"ksql命令行操作索引与视图"展开论述,把从"作用到创建,再到查看,维持直至删除"的全过程拆解成实际操作步骤,并结合例子和避坑提示,以使初学者能够领悟并付诸实行。  @toc
@toc
一、前置准备:确认操作基础(衔接前文,确保连贯)
索引和视图要依托已有的表,所以得先做好如下预备工作(参照第四篇"表的运作"相关内容),以防止在操作过程中因为依赖缺失而出现错误提示。
1.1 1. 连接数据库并切换目标模式
利用 ksql 建立与本地 KingbaseES 数据库的联系,转到先前所创建的 test_schema 模式当中,检查目标表是否确实存在(拿 sys_user 表来说,要是没有就再次创建它,或者用一个新的例子),这样做的目的是确保后续操作能够顺利执行。
sql
-- 1. 连接数据库(若未连接)
ksql -d kingbase -U system
-- 2. 切换到 test_schema 模式
SET search_path TO test_schema, public;
-- 3. 确认目标表存在(如 sys_user 表)
\dt sys_user;
-- 若不存在,创建示例表(用于后续索引/视图操作)
CREATE TABLE IF NOT EXISTS sys_user (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
phone CHAR(11) UNIQUE NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) TABLESPACE test_ts;
执行后若显示 Table "test_schema.sys_user" does not exist,则先执行上述 CREATE TABLE 语句创建表,确保后续操作有载体。 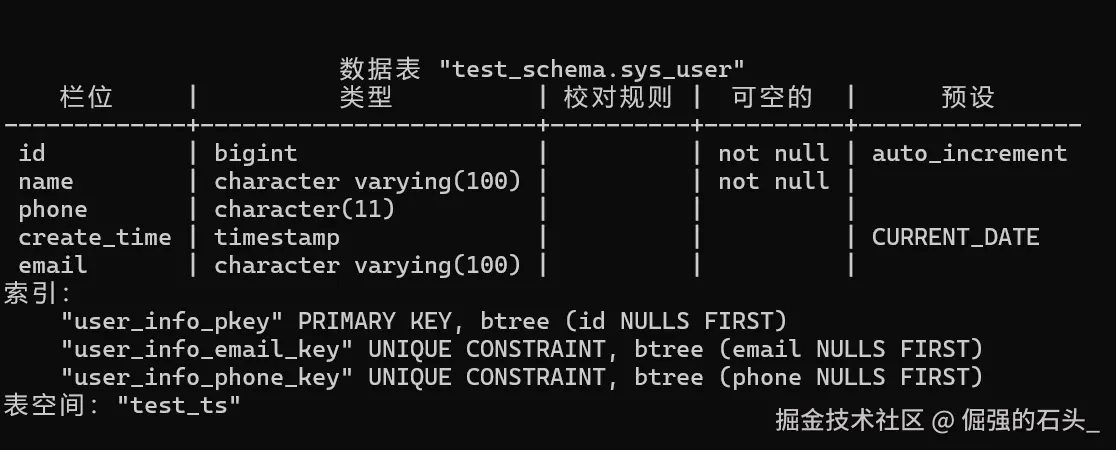
1.2 2. 插入测试数据(用于验证索引 / 视图效果)
为了后续可以检测索引的查询速度,并查看视图的数据展示情况,要给 sys_user 表增添大量模拟数据来做测试(能够添加上千条记录以模拟真实场景)。
sql
-- 批量插入10条测试数据(可复制扩展)
INSERT INTO test_schema.sys_user (name, phone, email)
VALUES
('张三', '13800138000', 'zhangsan@test.com'),
('李四', '13900139000', 'lisi@test.com'),
('王五', '13700137000', 'wangwu@test.com'),
('赵六', '13600136000', 'zhaoliu@test.com'),
('孙七', '13500135000', 'sunqi@test.com'),
('周八', '13400134000', 'zhouba@test.com'),
('吴九', '13300133000', 'wuj iu@test.com'),
('郑十', '13200132000', 'zhengshi@test.com'),
('钱一', '13100131000', 'qianyi@test.com'),
('冯二', '1300130000', 'fenger@test.com');执行后提示 INSERT 0 10,表示数据插入成功,为后续操作提供测试基础。 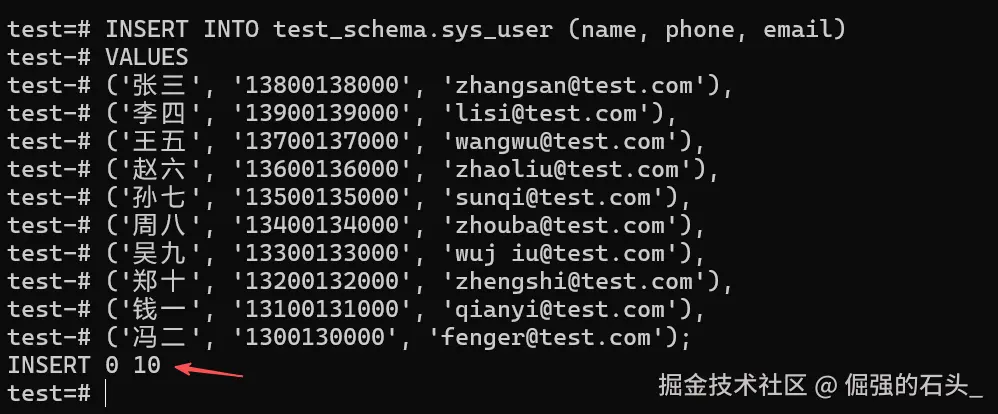
二、索引管理:给表 "加目录",加速查询
索引是 KingbaseES 优化查询性能的核心手段 ------ 当表数据量较大时(如 10 万条 +),无索引的查询会 "全表扫描"(逐行查找),而有索引的查询会通过 "索引目录" 直接定位数据,速度提升成百上千倍。接下来我们按 "创建→查看→维护→删除" 展开讲解
2.1 1. 先懂基础:索引的类型与适用场景
新手需先明确不同索引的作用,避免盲目创建(索引并非越多越好,会增加更新 / 插入的开销): 
2.2 2. 创建索引:用 CREATE INDEX 语句
2.2.1 示例 1:创建普通索引(加速单字段查询)
给 sys_user 表的 phone 列建普通索引(频繁按手机号查用户时用):
sql
-- 语法:CREATE INDEX 索引名 ON 表名(字段名);
CREATE INDEX idx_sys_user_phone ON test_schema.sys_user(phone);-
索引名规范提议采用"idx_表名_字段名"格式,这样便于识别,比如"idx_sys_user_phone"就表示"sys_user"表中"phone"列的索引。
-
成功验证 :执行后提示
CREATE INDEX,表示索引创建成功。
2.2.2 示例 2:创建唯一索引(确保字段唯一 + 加速查询)
给 sys_user 表的 email 列建唯一索引(既确保邮箱不重复,又加速邮箱查询):
sql
-- 语法:CREATE UNIQUE INDEX 索引名 ON 表名(字段名);
CREATE UNIQUE INDEX idx_sys_user_email ON test_schema.sys_user(email);- 与 UNIQUE 约束的区别 :唯一索引只保证值唯一,UNIQUE 约束包含约束和唯一索引,如果表已有
email的 UNIQUE 约束,则不必再创建email的唯一索引,因为约束本身就会生成索引。
2.2.3 示例 3:创建复合索引(加速多字段组合查询)
为sys_user表的name和create_time列创建复合索引,当经常依照"姓名+创建时间范围"执行查询的时候会用到这个索引。
sql
-- 语法:CREATE INDEX 索引名 ON 表名(字段1, 字段2);
CREATE INDEX idx_sys_user_name_createtime ON test_schema.sys_user(name, create_time);- 字段顺序注意 :复合索引依照"最左符合原则",索引(name, create - time)可加强 name 单字段查询,也可加强 name + create - time 综合查询,但无法加强 create - time 单字段查询,要按照查询习惯来确定字段顺序。

2.3 3. 查看索引:确认索引存在与关联表
创建索引后,需通过 ksql 命令查看索引列表、关联表及详情,推荐 \di 和 \dt+ 命令:
2.3.1 示例 1:查看所有索引(\di 命令)
执行 \di 可列出当前模式下的所有索引,确认索引是否创建成功:
sql
\di执行结果示例:
关键信息解读:
Table:索引关联的表(确认是sys_user);Columns:索引对应的字段(单字段 / 多字段);sys_user_pkey:主键自动创建的索引(无需手动创建)。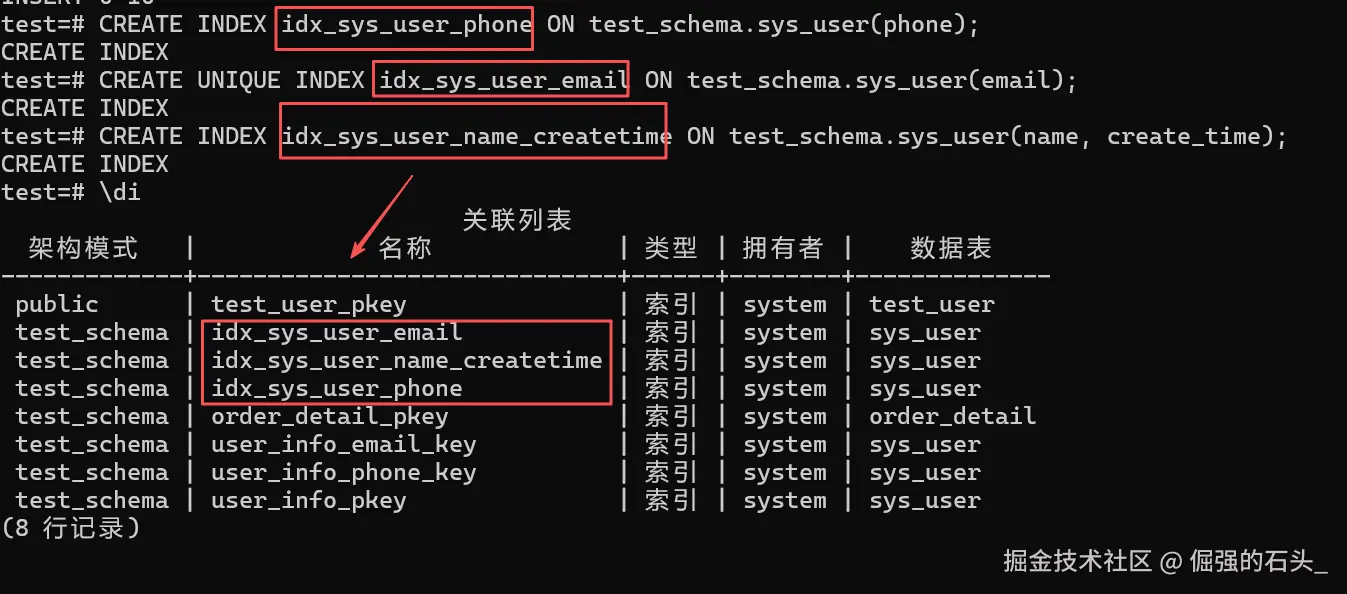
2.3.2 示例 2:查看表关联的索引(\dt+ 表名)
若需查看某张表的所有索引(如 sys_user),执行 \d+ 表名:
sql
\d+ test_schema.sys_user执行结果示例(索引部分):
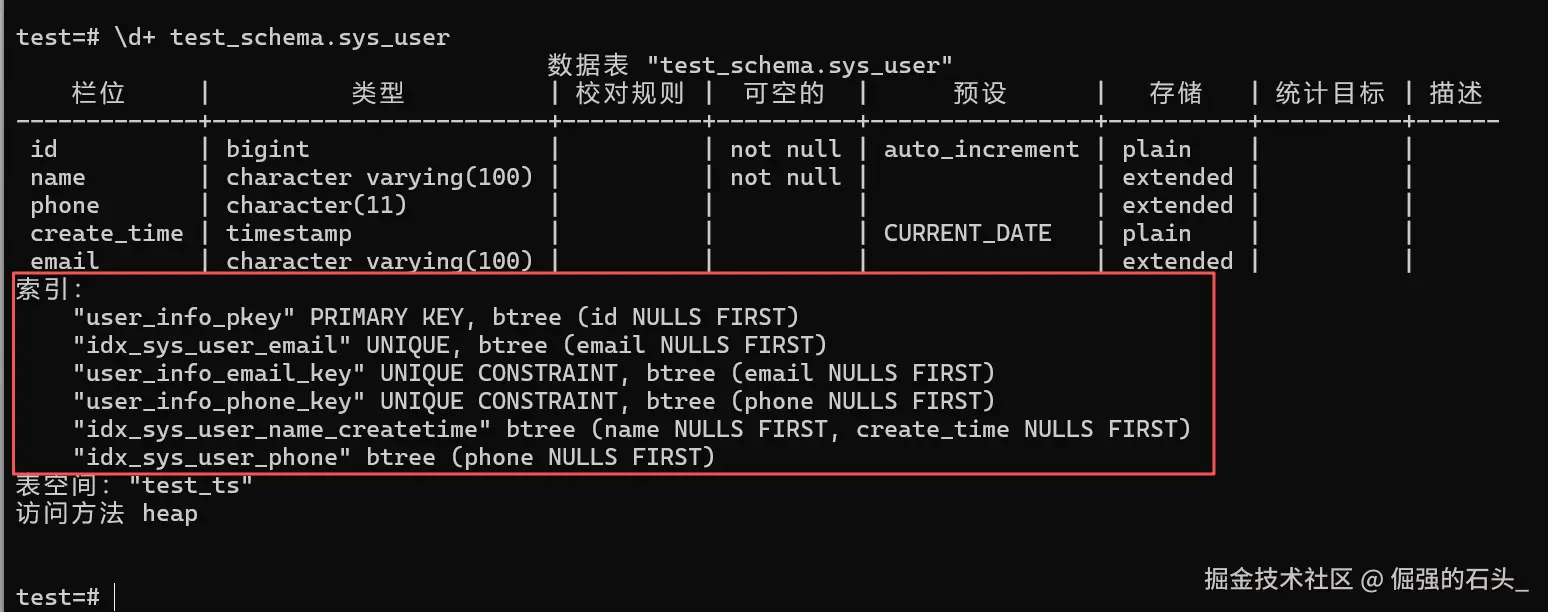
直接展示表关联的所有索引,包括类型(PRIMARY KEY/UNIQUE/ 普通)和字段,清晰直观。
2.4 4. 索引维护:优化性能与调整结构
索引经过一定时间的使用之后,有可能会出现由于数据频繁被删除或者更新而造成的"碎片化"现象,即索引文件中存在许多空白空间,这种情况下要借助重建索引来改善这种情况,而且按照个人需求也可以重新命名或者直接删除索引。
2.4.1 示例 1:重建索引(解决碎片化,提升查询速度)
当索引查询速度变慢时,重建索引可整理碎片,恢复性能(表大时建议离线执行,避免影响业务):
sql
-- 语法:REINDEX INDEX 索引名;
REINDEX INDEX idx_sys_user_phone;
-- 进阶:重建表的所有索引(更高效)
REINDEX TABLE sys_user;- 成功验证 :执行后提示
REINDEX,表示重建完成。
2.4.2 示例 2:重命名索引(规范命名)
索引名若不符合规范,可以重新命名,可以把idx_sys_user_phone改为idx_sys_user_mobile。
sql
-- 语法:ALTER INDEX 旧索引名 RENAME TO 新索引名;
ALTER INDEX idx_sys_user_phone RENAME TO idx_sys_user_mobile;- 验证 :执行
\d+ test_schema.sys_user可看到索引名已更新。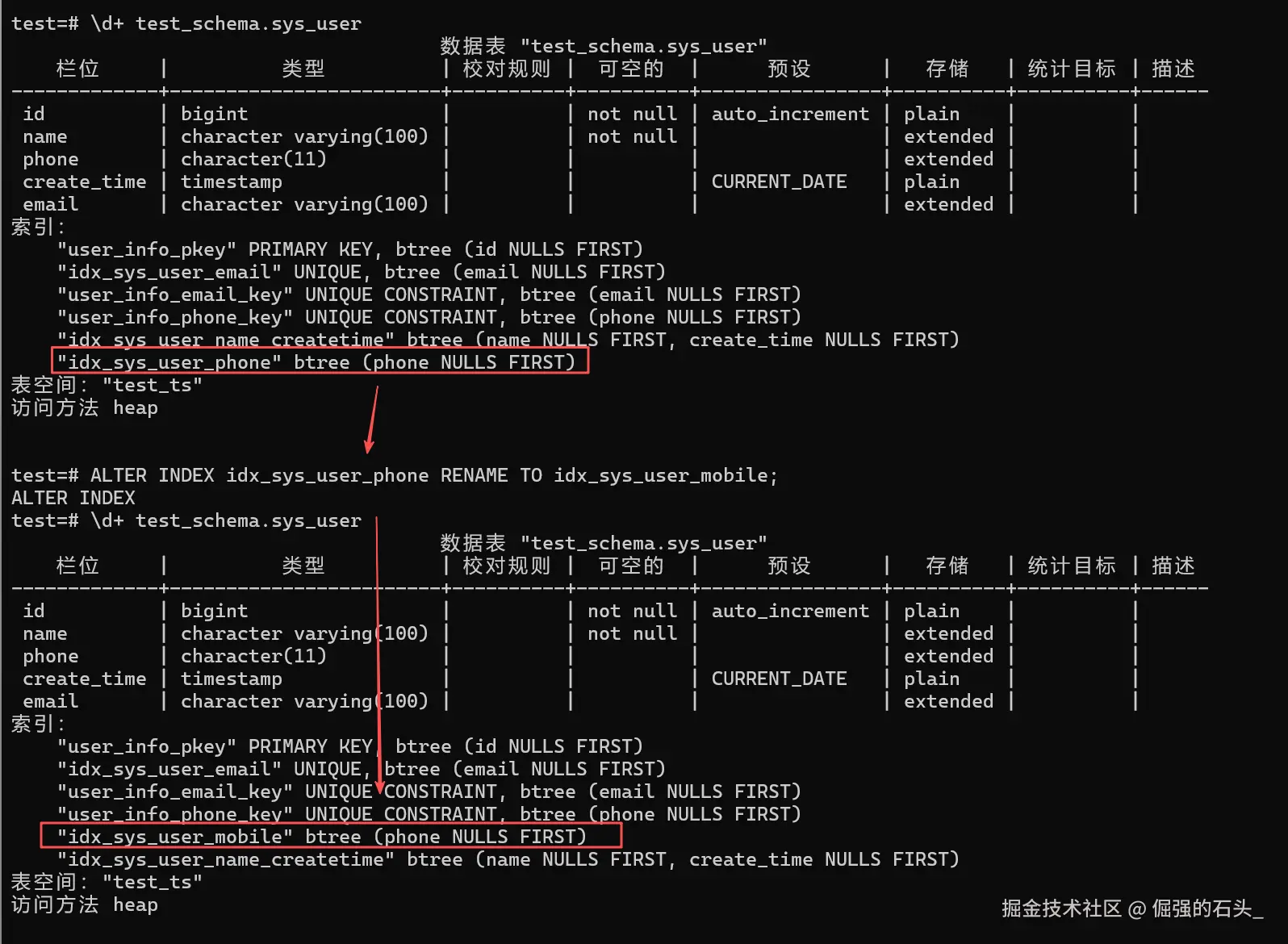
2.4.3 示例 3:删除索引(无用索引清理)
某字段查询频率降低或者索引致使插入/更新变慢的时候,要删除无用索引(要注意的是,主键索引以及与唯一约束相关联的索引不能直接删,应当先删约束)。
sql
-- 语法:DROP INDEX IF EXISTS 索引名;
DROP INDEX IF EXISTS idx_sys_user_name_createtime;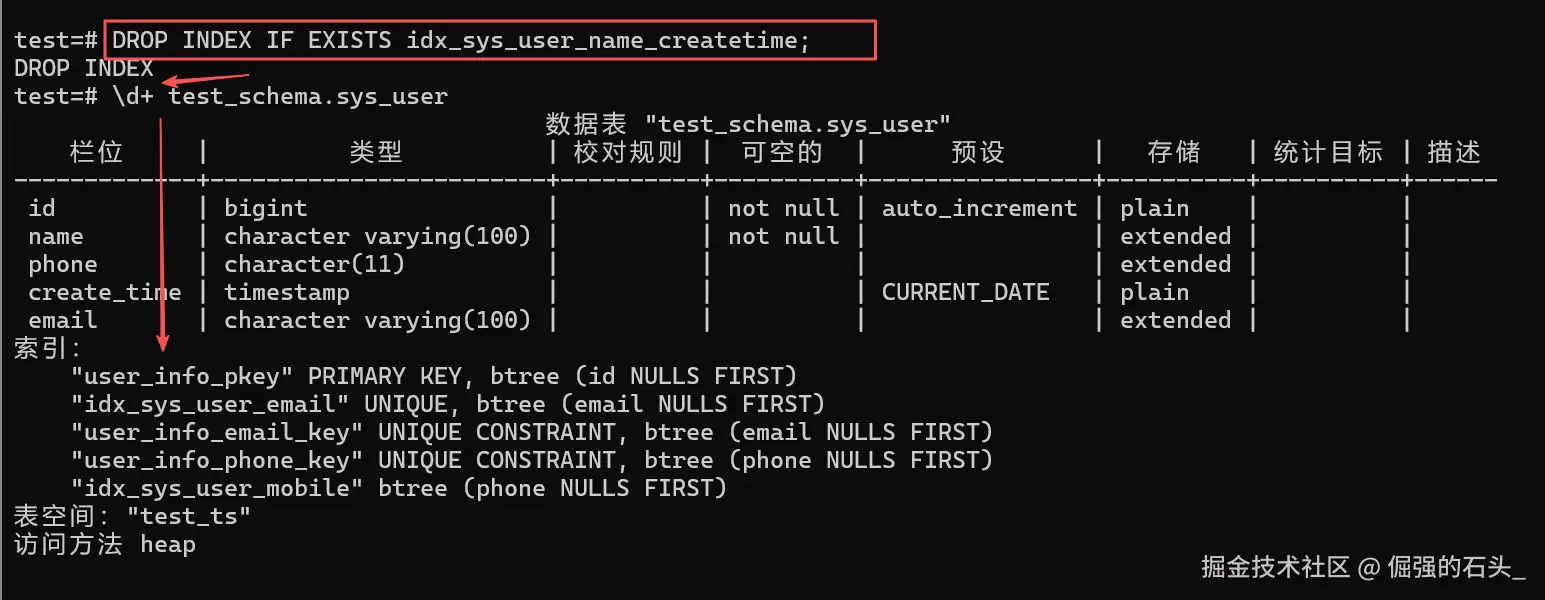
IF EXISTS:避免索引不存在时报错,仅提示警告;- 验证 :执行
\d+ test_schema.sys_user确认索引已移除。
2.5 5. 索引使用注意事项(新手避坑指南)
- 索引并非越多越好,索引会加重插入,更新和删除时的开销,因为每当数据发生变动的时候,都要同步更新索引。所以一张表的索引最好别超过5个。
- 小表不需要创建索引,当数据量小于1万条时,全表扫描比索引查询速度更快,因为索引查询要先查找索引再查找数据,这就多了一次IO操作。
- 列如果经常更新就不要创建索引,比如"订单状态"这个字段(其值每秒都在变),给它创建索引之后,索引就会频繁地执行同步操作,从而影响到整体的性能表现。
- 要避开对函数执行索引字段 ,像
WHERE SUBSTR(phone,1,3) = '138'这种情况会使索引失效,应该改成WHERE phone LIKE '138%'(前缀符合能够利用索引)。
三、视图管理:给数据 "开窗口",简化查询与控制权限
视图属于"虚拟表",它依靠SQL查询结果生成,并未储存实际数据(数据仍旧保存在原始表当中),其关键意义在于"隐匿复杂查询逻辑"以及"调控数据可见范围"(譬如仅仅向用户显示某些列),我们按照"创建 - 查看 - 操作 - 删除"的顺序来执行。
3.1 1. 先懂基础:视图的核心作用(新手必知)
新手容易混淆 "表" 和 "视图",用通俗比喻理解:
- 表:"仓库",存储实际数据;
- 视图名为"仓库窗口",此视图仅显示指定区域的货物(数据),无法看到整个仓库的概貌,而且该窗口不可直接被修改,要经过此窗口去更改仓库的数据,不过存在一些限制。
视图的核心场景:
- 简化复杂查询,多表关联查询(JOIN)可以被封装成视图,之后的查询直接针对该视图展开,不必再次书写复杂的 SQL 语句。
- 数据权限控制方面 ,可以向普通用户展示
sys_user表中name和phone字段的内容,而将email这类敏感信息遮盖起来,这要依靠视图来达成。 - 数据一致性:多系统共用同一查询逻辑时,视图可确保所有系统使用相同的筛选条件。
3.2 2. 创建视图:用 CREATE VIEW 语句
3.2.1 示例 1:基础视图(简化单表查询)
创建 "用户基础信息视图 vw_sys_user_basic",只包含 id、name、phone 列(隐藏 email 敏感信息):
sql
-- 语法:CREATE VIEW 视图名 AS SELECT 语句;
CREATE VIEW vw_sys_user_basic AS
SELECT id, name, phone
FROM test_schema.sys_user;- 成功验证 :执行后提示
CREATE VIEW,表示视图创建成功。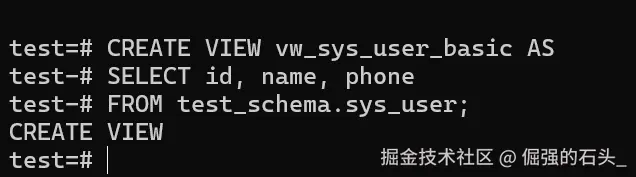
3.2.2 示例 2:进阶视图(带筛选条件的复杂查询)
创建 "2024 年创建的用户视图 vw_sys_user_2024",筛选 create_time 在 2024 年的用户,包含 name、email、create_time 列:
sql
CREATE VIEW vw_sys_user_2024 AS
SELECT name, email, create_time
FROM test_schema.sys_user
WHERE create_time >= '2024-01-01 00:00:00'
AND create_time < '2025-01-01 00:00:00';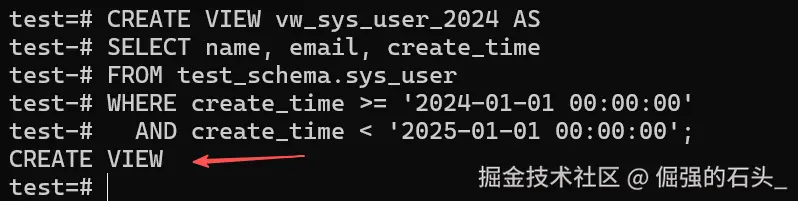
- 动态性:视图数据会随原表变化自动更新(如原表新增 2024 年用户,视图会自动包含该数据)。
3.2.3 示例 3:只读视图(禁止修改数据)
若需确保视图数据不被修改(如报表视图),可添加 WITH READ ONLY 选项:
sql
CREATE VIEW vw_sys_user_report AS
SELECT name, phone, create_time
FROM test_schema.sys_user
WITH READ ONLY;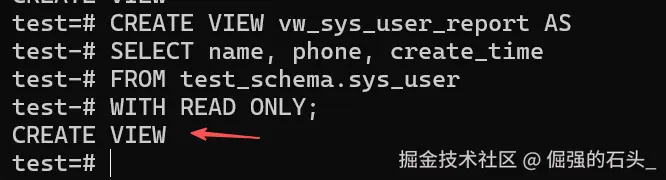
- 效果 :后续若尝试通过视图修改数据(如
UPDATE vw_sys_user_report SET name='张三'),会报错 "cannot update a read-only view"。
3.3 3. 查看视图:确认视图定义与关联表
创建视图之后,要利用 ksql 命令来查看视图列表,定义以及相关联的表,建议使用 \dv 和 \d+ 这两个命令。
3.3.1 示例 1:查看所有视图(\dv 命令)
执行 \dv 可列出当前模式下的所有视图,确认视图是否创建成功:
执行结果示例: 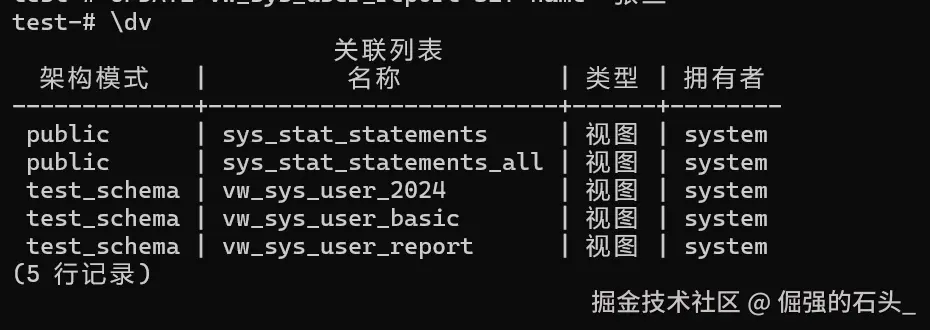
3.3.2 示例 2:查看视图定义(\d+ 视图名)
若需确认视图的底层 SQL(如忘记视图筛选条件),执行 \d+ 视图名:
sql
\d+ vw_sys_user_2024执行结果示例(定义部分):
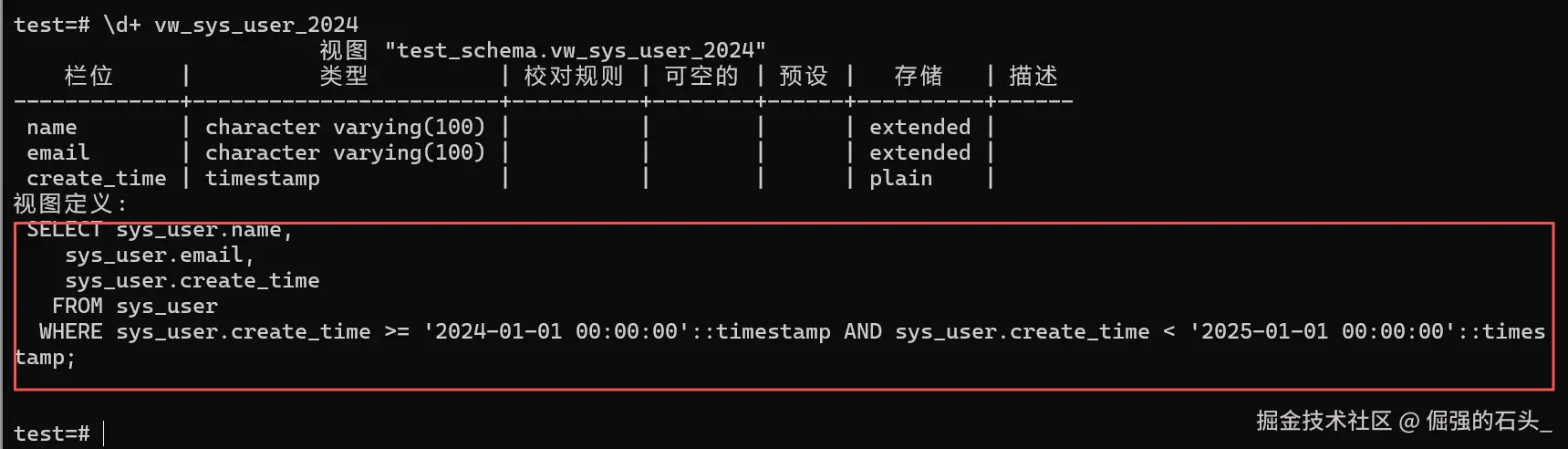
直接展示视图的完整 SQL 定义,便于后续修改或验证逻辑。
3.4 4. 视图操作:查询、修改与删除
视图的核心操作是 "查询",修改和删除需遵循特定规则
3.4.1 示例 1:查询视图数据(与表查询一致)
查询视图数据的语法和查询表完全相同,无需额外学习:
sql
-- 查询基础视图数据
SELECT * FROM vw_sys_user_basic;
-- 查询2024年用户视图,按创建时间排序
SELECT * FROM vw_sys_user_2024 ORDER BY create_time DESC;- 效果 :返回结果与查询原表筛选后的数据一致,但看不到隐藏的列(如
email在vw_sys_user_basic中不可见)。
3.4.2 示例 2:修改视图定义(CREATE OR REPLACE)
若需调整视图的筛选条件或列(如 vw_sys_user_2024 改为包含 2023 年数据),无需删除视图,直接用 CREATE OR REPLACE 修改:
sql
CREATE OR REPLACE VIEW vw_sys_user_2024 AS
SELECT name, email, create_time
FROM test_schema.sys_user
WHERE create_time >= '2023-01-01 00:00:00'
AND create_time < '2025-01-01 00:00:00';- 验证 :执行
\d+ vw_sys_user_2024确认定义已更新。
3.4.3 示例 3:删除视图(DROP VIEW)
当视图不再使用时,执行删除命令(删除视图不影响原表数据,仅删除视图定义):
sql
-- 语法:DROP VIEW IF EXISTS 视图名;
DROP VIEW IF EXISTS vw_sys_user_report;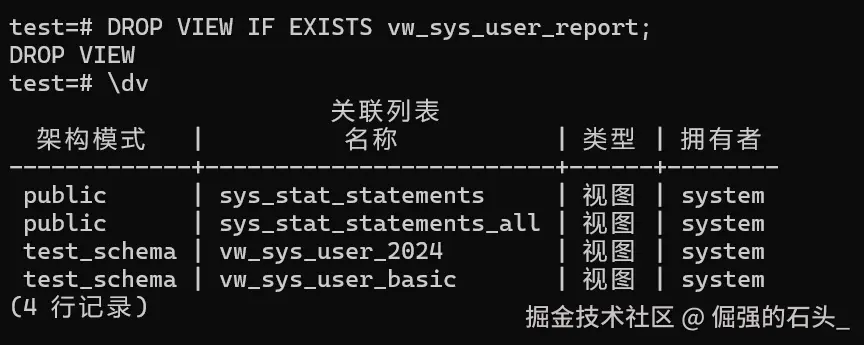
- 验证 :执行
\dv确认视图已移除。
3.5 5. 视图使用注意事项(新手避坑指南)
- 视图修改限制 :含以下情况的视图无法修改数据(即使未加
READ ONLY):- 视图涵盖
DISTINCT(去重),GROUP BY(分组),HAVING(筛选分组)。 - 视图包含聚合函数(如
COUNT、SUM); - 视图来自多表关联(
JOIN);
- 视图涵盖
- 原表删除影响 :若原表(比如
sys_user表)被删除,则该视图就会成为"无效视图",在执行查询的时候,会收到"relation does not exist"的错误提示。 - 性能注意 :复杂视图包含多表关联或者聚合情况时,其查询效率依靠原表索引,所以要保证原表中相关联的字段已有索引,比如在多表
JOIN操作里涉及的关联列就需要事先创建好索引。
四、常见问题排查:索引与视图的高频报错
问题 1:创建索引报错 "重复的键名"
报错信息:
plaintext
ERROR: duplicate key name "idx_sys_user_phone"原因 :同名索引已存在(如之前已创建 idx_sys_user_phone)。
解决方案:
- 执行
\di查看索引名,确认是否重复; - 若需重新建索引,先删除旧索引(
DROP INDEX idx_sys_user_phone;),再创建新索引。
问题 2:查询视图报错 "关系对象不存在"
报错信息:
plaintext
ERROR: relation "vw_sys_user_basic" does not exist原因:
- 视图名拼写错误(如
vw_sys_user_basci); - 视图所在模式不在搜索路径中(如视图在
test_schema,但当前搜索路径是public)。
解决方案:
- 检查视图名拼写(执行
\dv确认正确名称); - 切换到视图所在模式(
SET search_path TO test_schema, public;),或用 "模式名。视图名" 全称查询(SELECT * FROM test_schema.vw_sys_user_basic;)。
问题 3:通过视图修改数据报错 "无法更新只读视图"
报错信息:
plaintext
ERROR: cannot update a read-only view "vw_sys_user_report"原因 :视图创建时加了 WITH READ ONLY 选项,禁止修改。
解决方案:
-
若需允许修改,重新创建视图(去掉
WITH READ ONLY):sqlCREATE OR REPLACE VIEW vw_sys_user_report AS SELECT name, phone, create_time FROM sys_user; -
注意:重新创建前需确认视图无修改限制(如不含
GROUP BY、聚合函数等)。
五、总结:索引与视图的配合使用
本文完整覆盖了索引和视图的核心操作,核心要点可总结为:
1.管理 "查询速度"时,依照查询场景来挑选普通/唯一/复合索引,不要过度创建,要定时执行重建并改善性能。 2. 视图:管 "查询简化与权限",封装复杂逻辑、隐藏敏感数据,注意修改限制和原表依赖;
- 配合使用 :视图的查询速度与原表索引相关,给
vw_sys_user_2024视图对应的sys_user原表创建create - time索引之后,其查询效率会得到很大的改善。
掌握了索引和视图之后,你就具有了 KingbaseES 高效查询的关键能力,下篇文章我们会学习"用户与权限管理",从而保障数据库访问的安全,并做到"不同用户访问不同数据"这样细致的控制。