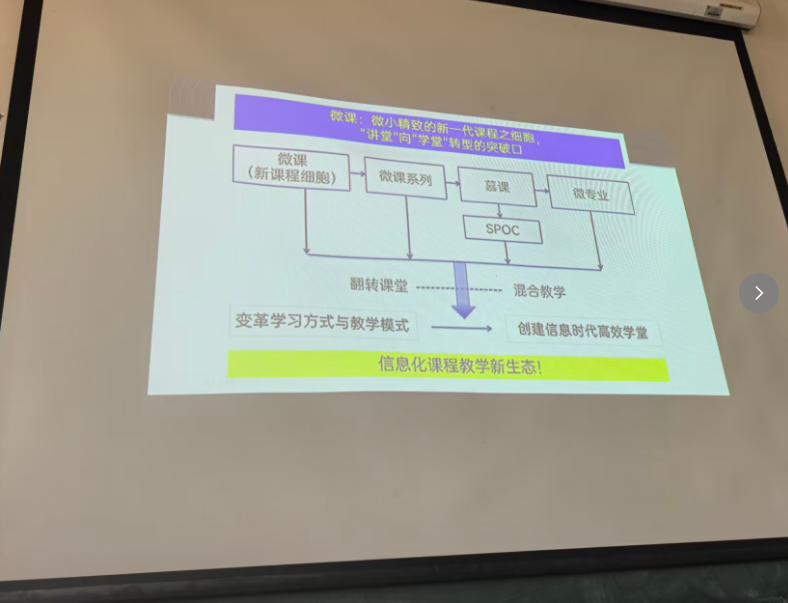
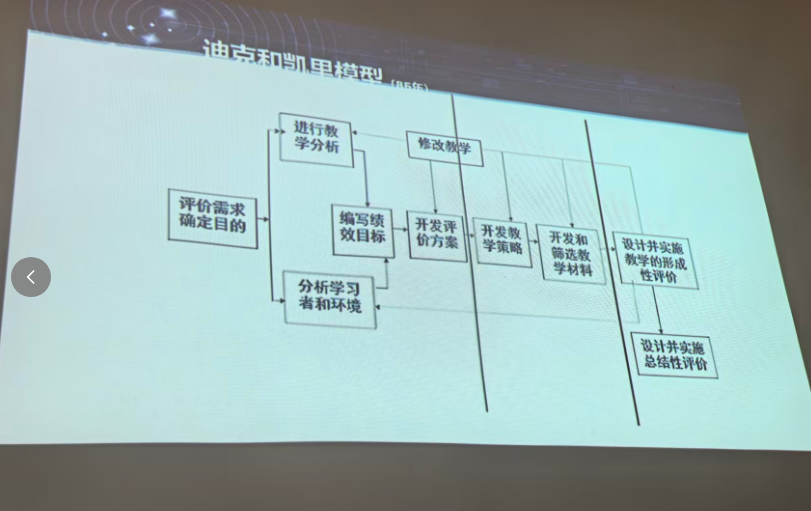
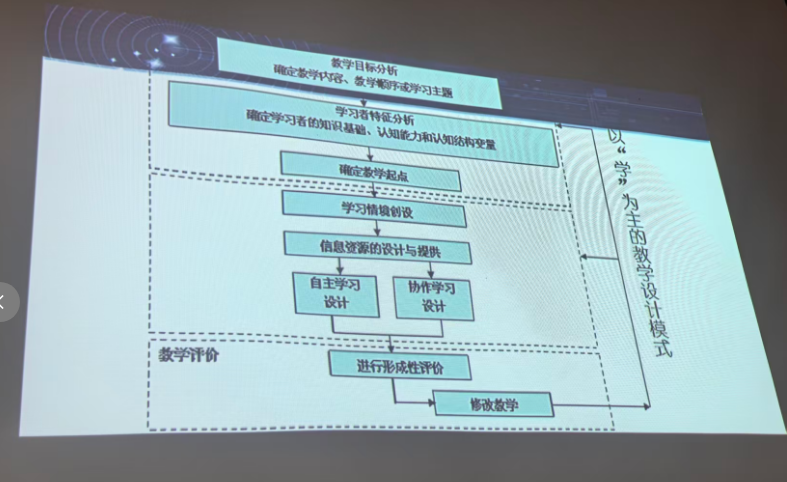
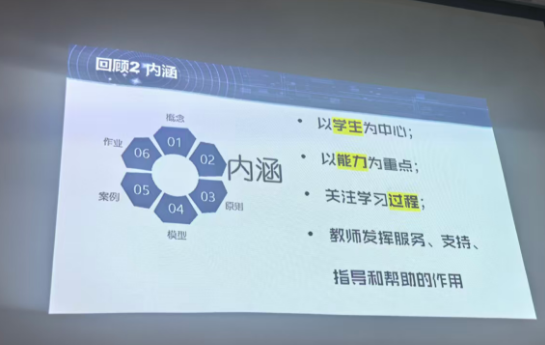
背景需求
马上人工智能课要考试了,我要下载课件
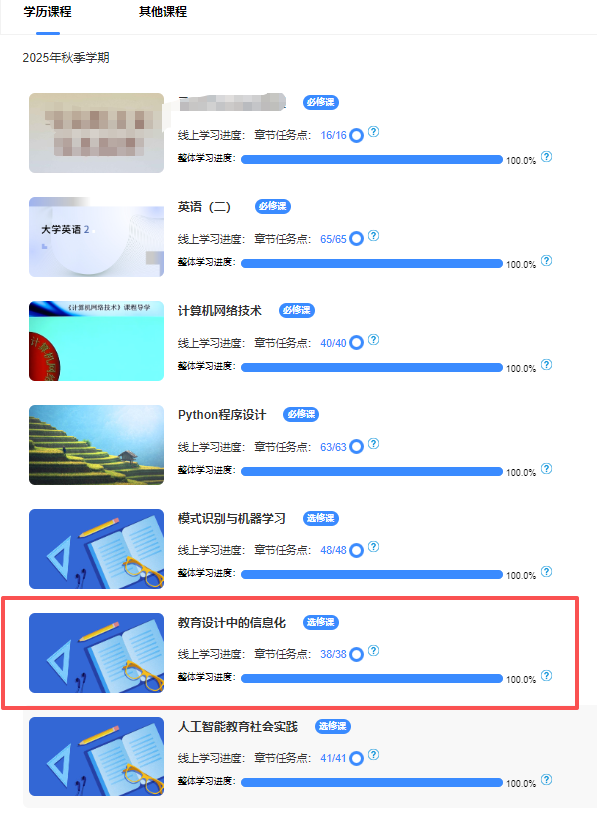
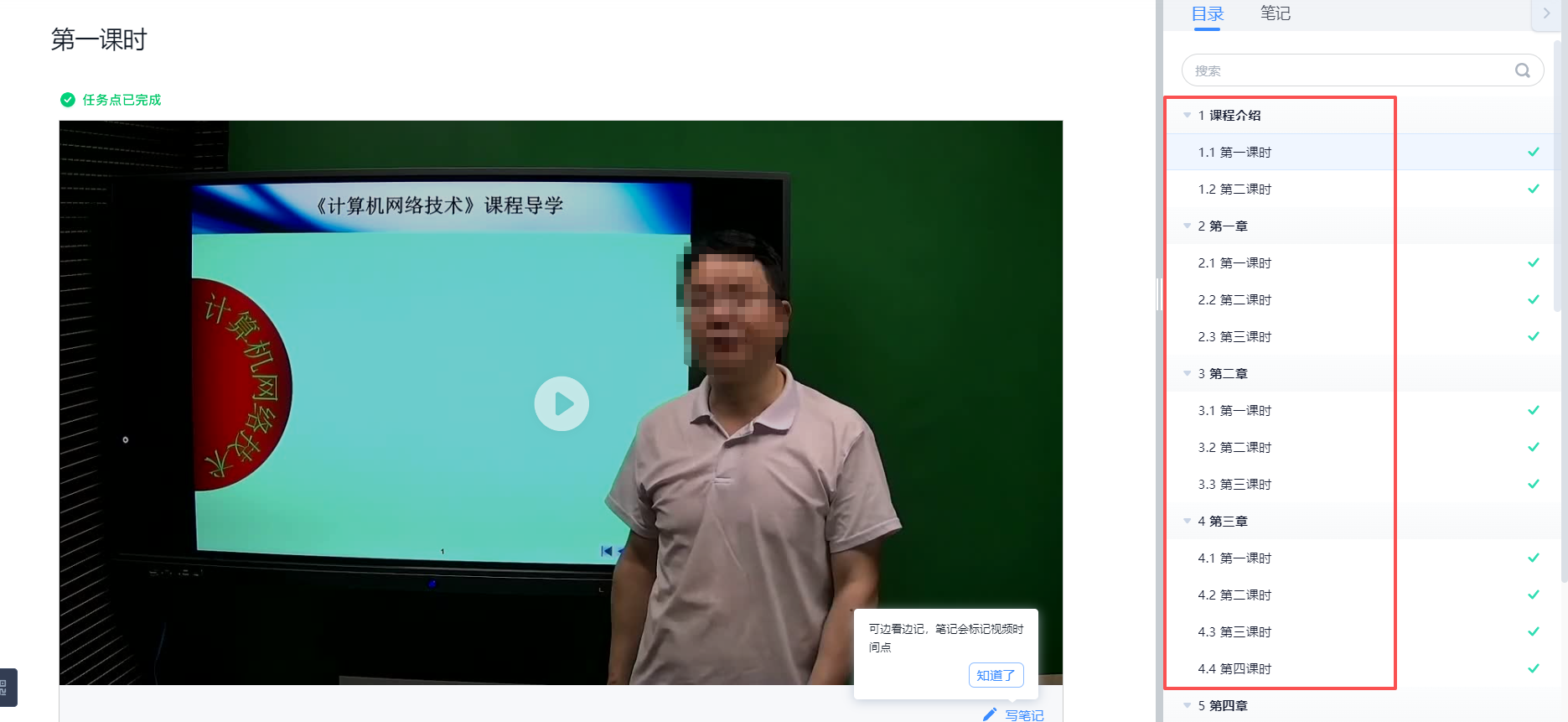
我把所有的课件mp4下载(IDM下载)。
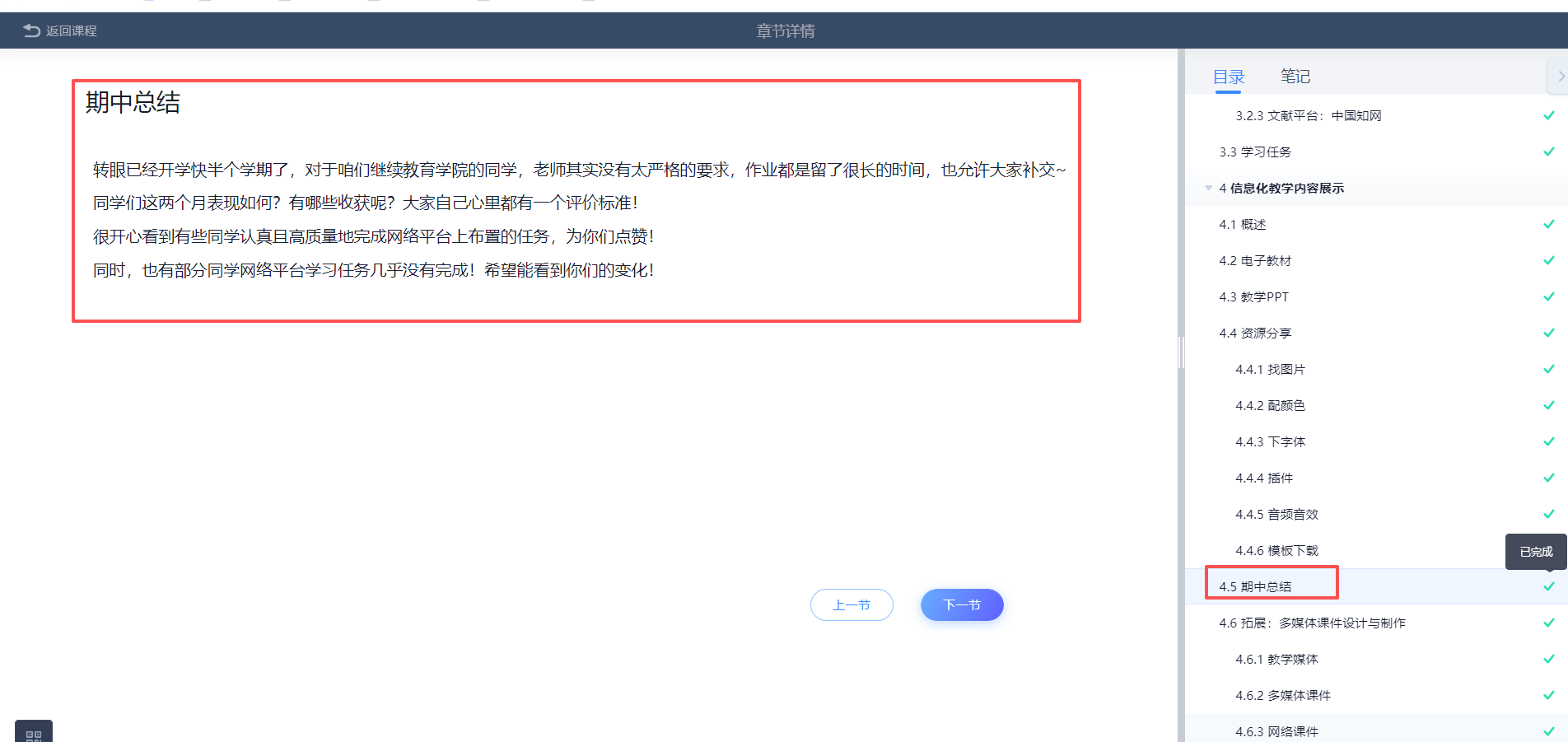
但是《教育设计中的信息化》里面并不是课件,而是有文字、有视频、有音乐、有"在线多人编辑的ppt或docx"
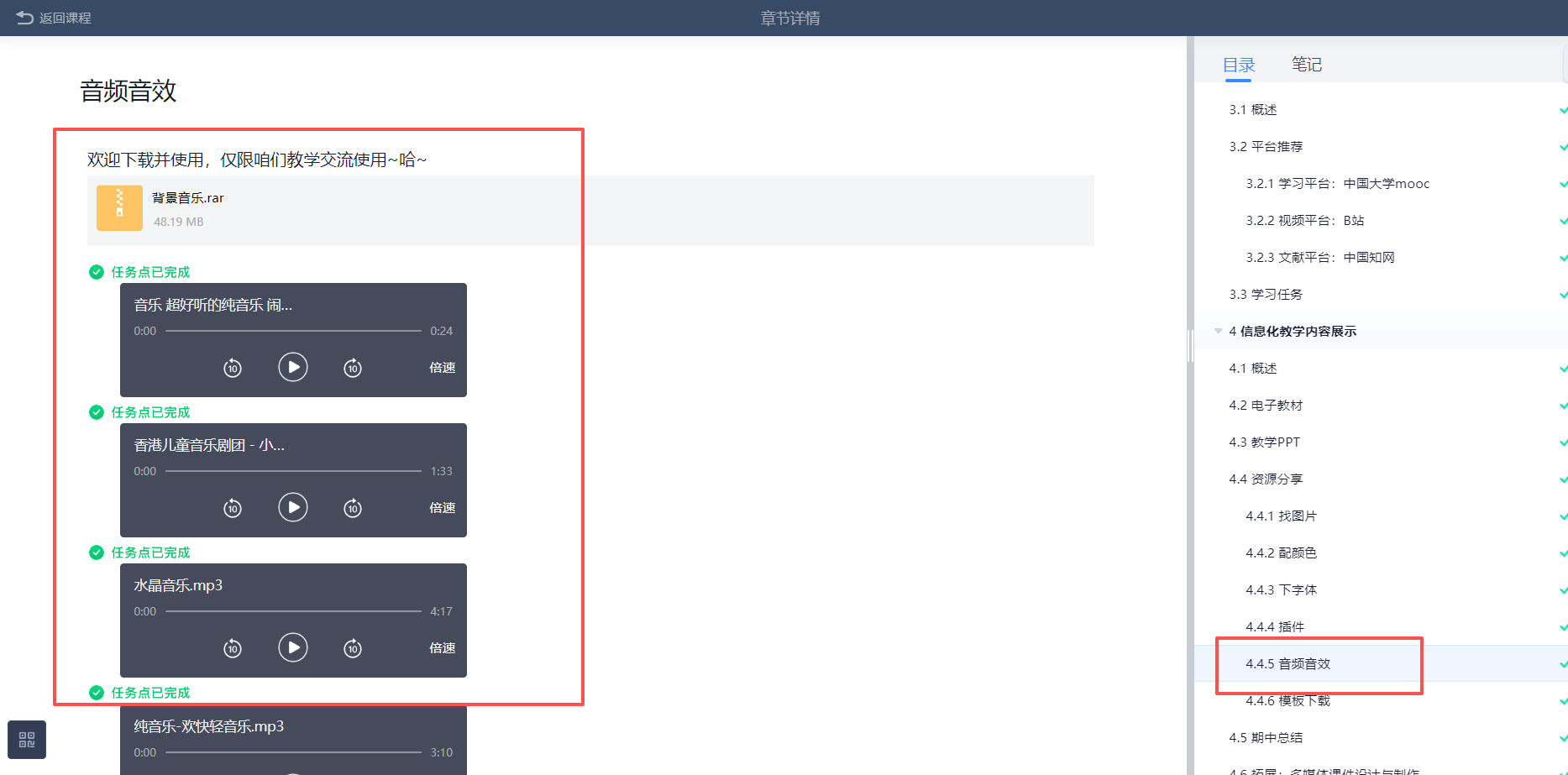
这种PPT右下角有下载按钮,可以直接下载
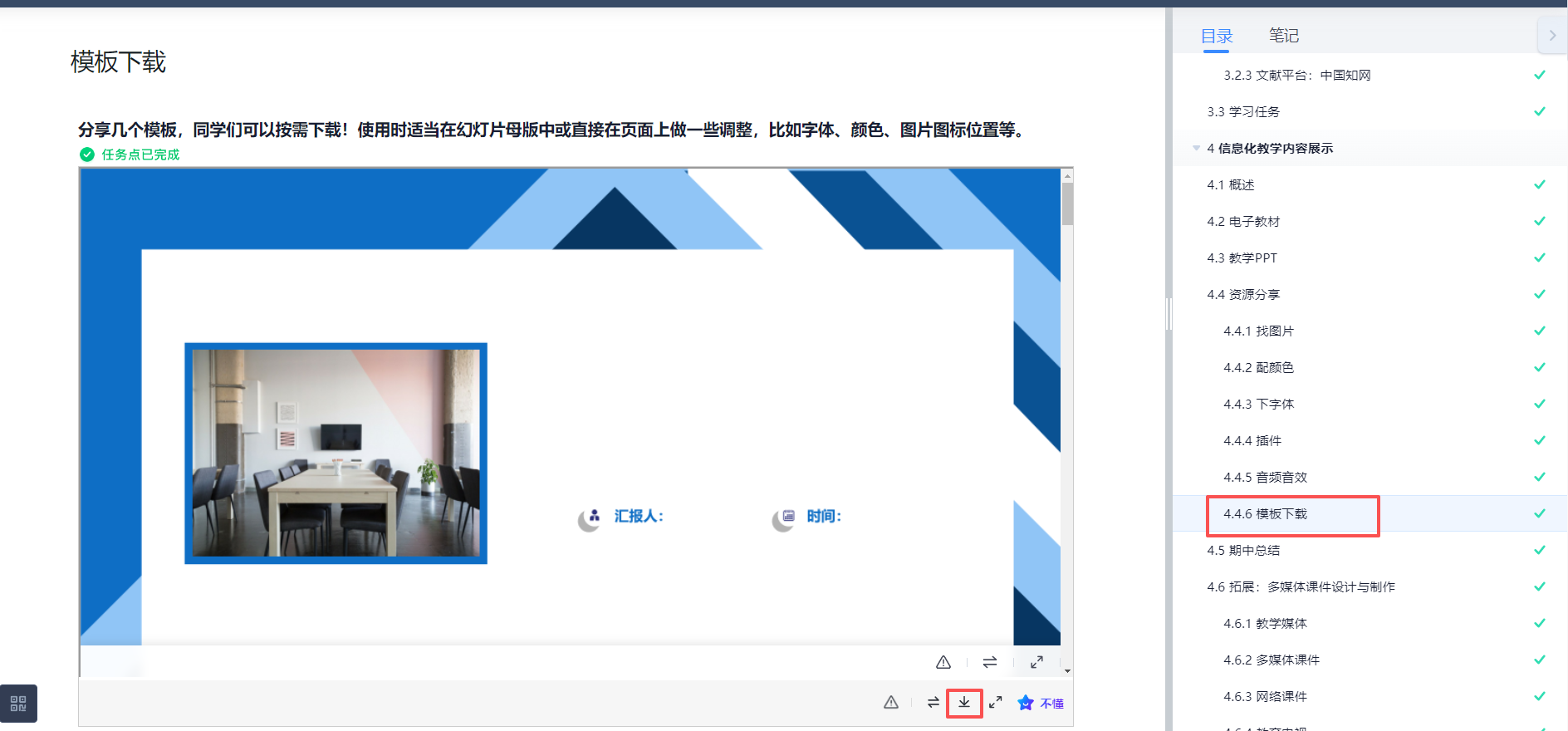
但是也有没有下载按钮的,没有下载
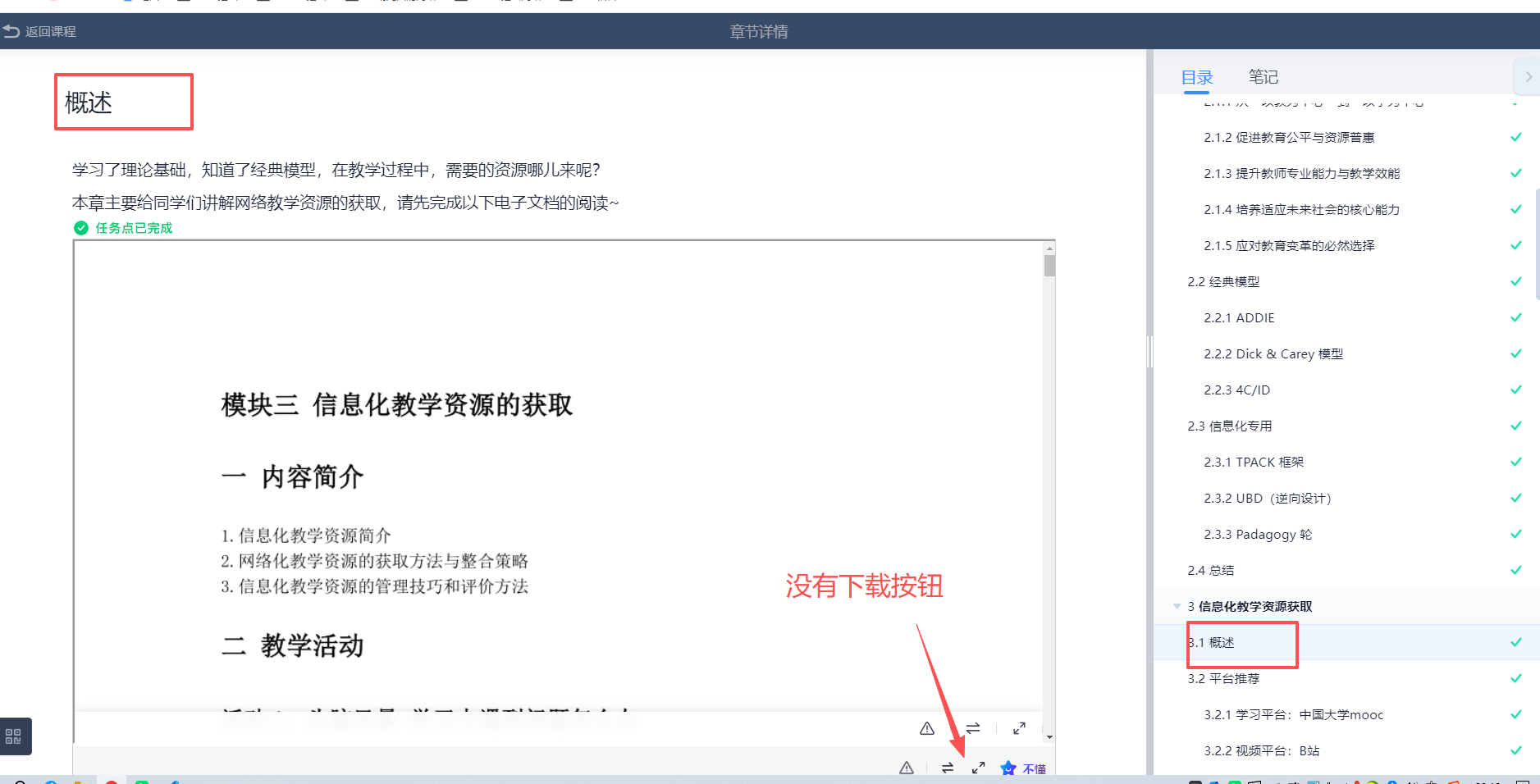
所以我用F12,看后台代码,可以点击看到每一页PPT的图片版本
第一个PPT
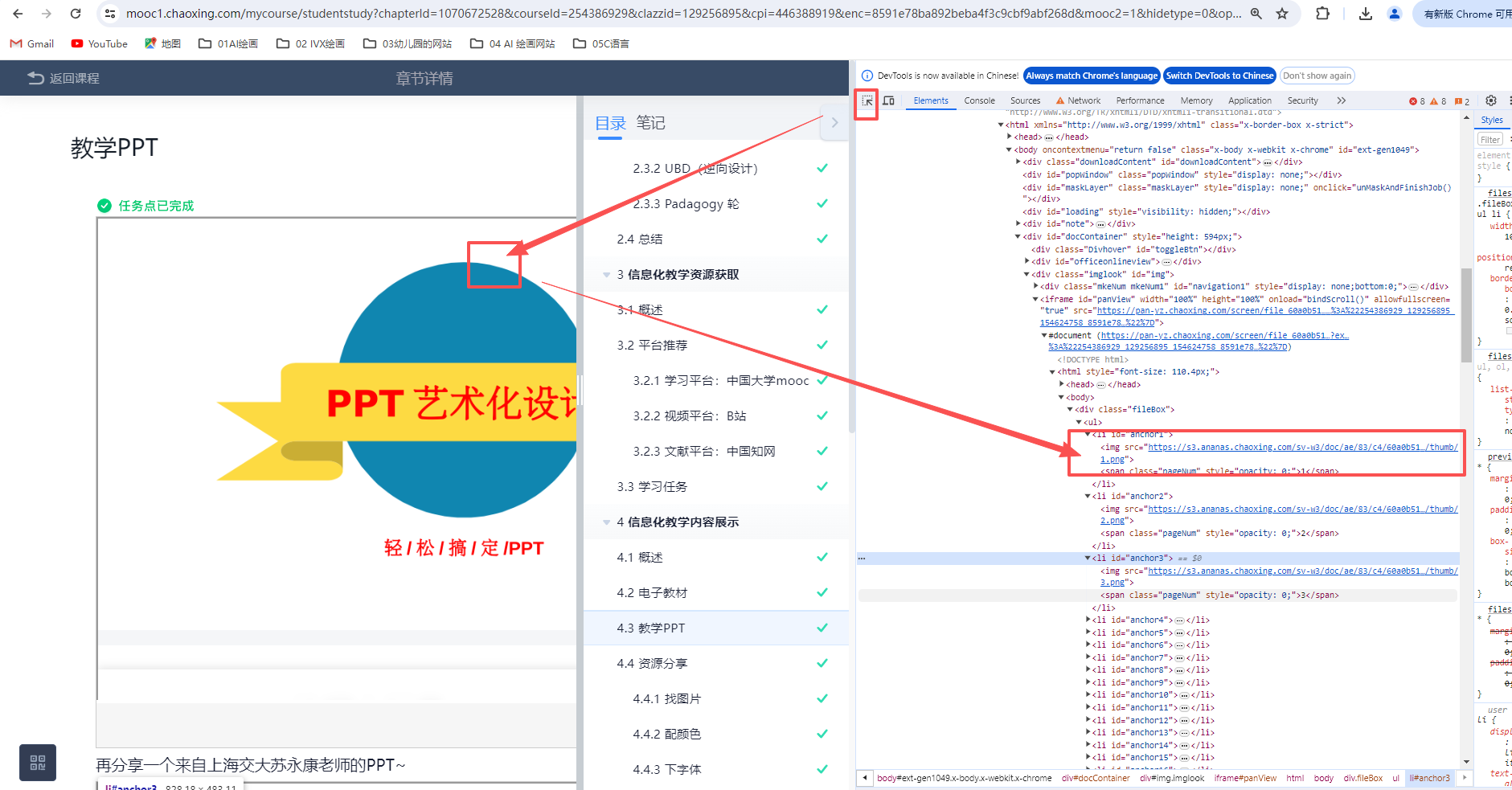
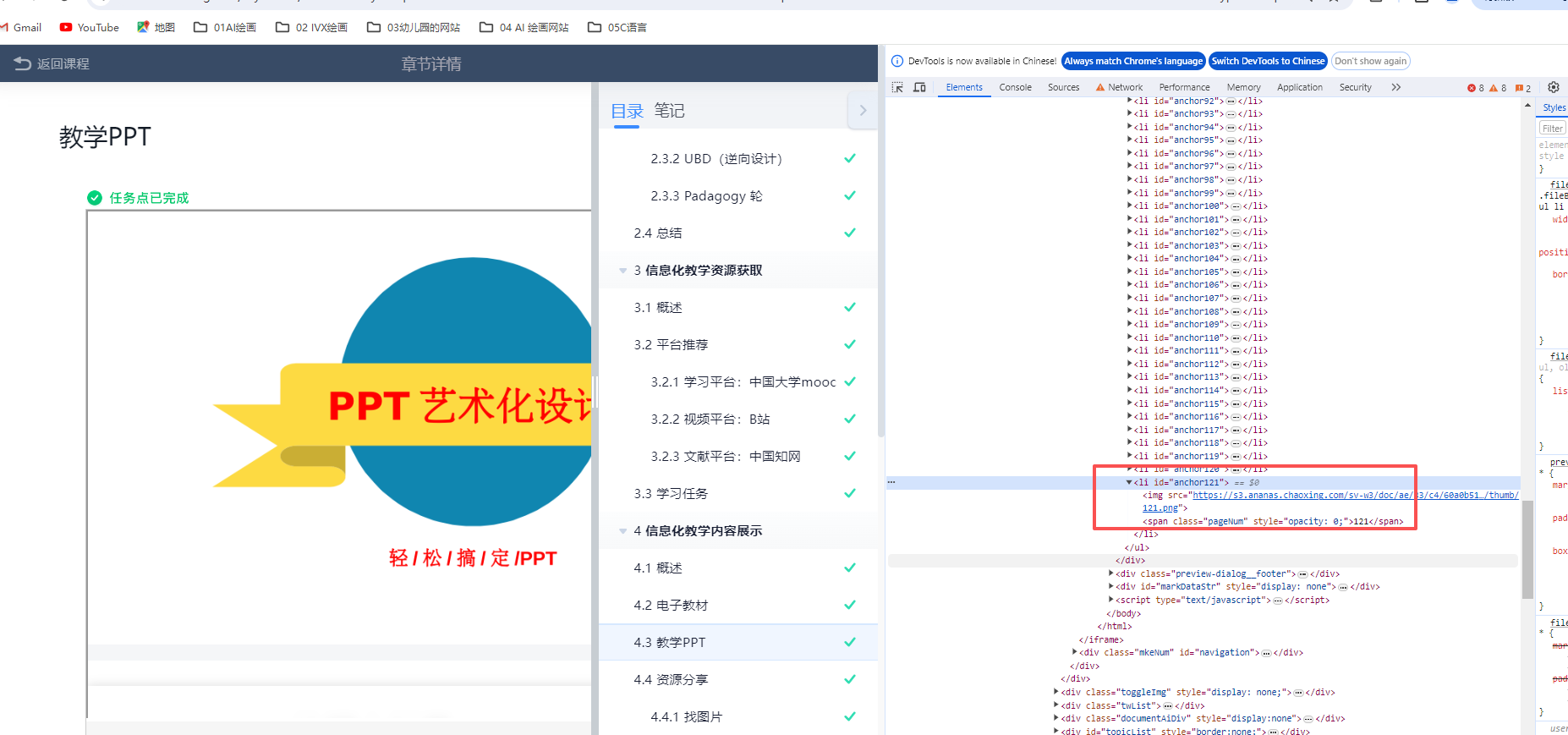

用豆包写了十几次,才实现了需求
需要先把图片的网址链接贴入
同时要看看一共几张图片
python
'''
爬虫下载网页里面的"在线多人协作",图片样式下载
写入图片.png的链接,批量下载
豆包,阿夏
20251226
'''
import requests
import os
import time
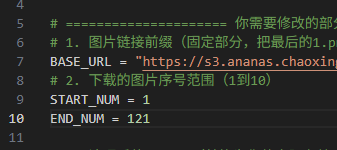
# ===================== 你需要修改的部分 =====================
# 1. 图片链接前缀(固定部分,把最后的1.png去掉)
BASE_URL = "https://s3.ananas.chaoxing.com/sv-w3/doc/ae/83/c4/60a0b5114e957abf0fed3efcd263ac8d/thumb/"
# 2. 下载的图片序号范围(1到10)
START_NUM = 1
END_NUM = 121
# 3. 清理后的Cookie(替换为你的实际有效Cookie,删除中文字符)
CLEAN_COOKIE = "JSESSIONID=xxx; UID=123456; _uid=7890; uf=xxx; vc=xxx; _d=xxx"
# 4. 保存路径(桌面的123文件夹)
SAVE_DIR = r"C:\Users\jg2yXRZ\OneDrive\桌面\123\自动下载的PNG图片"
# ============================================================
# 请求头(彻底解决编码问题)
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Cookie": CLEAN_COOKIE.encode('utf-8').decode('latin-1', errors='ignore'),
"Accept": "image/avif,image/webp,image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5",
"Referer": "https://mooc1.chaoxing.com/" # 避免403权限错误
}
# 创建保存文件夹(自动创建不存在的文件夹)
os.makedirs(SAVE_DIR, exist_ok=True)
def download_png(url, save_path):
"""下载单张图片,包含完整的异常处理"""
try:
# 流式下载(适合大图片)+ 超时保护
response = requests.get(
url,
headers=HEADERS,
timeout=20,
allow_redirects=True,
stream=True
)
# 检查请求是否成功(4xx/5xx错误会触发异常)
response.raise_for_status()
# 写入文件(二进制模式,避免图片损坏)
with open(save_path, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk: # 过滤空数据块
f.write(chunk)
return True
except requests.exceptions.HTTPError as e:
print(f"❌ HTTP错误:{e}(可能是链接无效/权限不足)")
return False
except requests.exceptions.Timeout:
print(f"❌ 下载超时(链接:{url})")
return False
except requests.exceptions.ConnectionError:
print(f"❌ 网络连接错误(链接:{url})")
return False
except Exception as e:
print(f"❌ 未知错误:{e}")
return False
# 批量生成链接并下载主逻辑
success = 0
fail = 0
total = END_NUM - START_NUM + 1
print(f"🚀 开始下载 {START_NUM}-{END_NUM}.png 共 {total} 张图片...")
print(f"📁 保存路径:{SAVE_DIR}\n")
for num in range(START_NUM, END_NUM + 1):
# 自动拼接图片链接(1.png → 10.png)
img_url = f"{BASE_URL}{num}.png"
# 生成文件名(保留原始数字,比如 1.png、2.png)
filename = f"{num:03}.png"
save_path = os.path.join(SAVE_DIR, filename)
print(f"📥 正在下载 [{num-START_NUM+1}/{total}]:{filename}")
time.sleep(1.5) # 延时1.5秒,避免反爬限制
# 执行下载
if download_png(img_url, save_path):
print(f"✅ 下载成功:{save_path}")
success += 1
else:
print(f"❌ 下载失败:{img_url}")
fail += 1
# 下载结果汇总
print("\n" + "="*60)
print(f"📊 下载完成!总计:{total} | 成功:{success} | 失败:{fail}")
print(f"📁 最终保存路径:{os.path.abspath(SAVE_DIR)}")
if fail > 0:
print("⚠️ 失败原因可能:Cookie过期/链接无效/网络问题,请检查Cookie和链接前缀!")
python
'''
爬虫下载网页里面的"在线多人协作",图片样式下载
写入图片.png的链接,批量下载
下载的图片合并PDF
豆包,阿夏
20251226
'''
import os
from PIL import Image
from fpdf import FPDF
def images_to_pdf(folder_path, output_pdf):
"""
将指定文件夹下的所有图片合并为PDF
:param folder_path: 图片文件夹路径(如"123")
:param output_pdf: 输出PDF的路径(如"merged_images.pdf")
"""
# 支持的图片格式(小写)
supported_formats = ('.jpg', '.jpeg', '.png', '.bmp', '.gif')
# 1. 获取文件夹下所有图片文件
image_files = []
for file in os.listdir(folder_path):
file_path = os.path.join(folder_path, file)
# 过滤文件:是文件 + 后缀在支持列表中
if os.path.isfile(file_path) and file.lower().endswith(supported_formats):
image_files.append(file_path)
# 检查是否有图片
if not image_files:
print("错误:指定文件夹下未找到支持的图片文件!")
return
# 2. 按文件名排序(保证顺序)
image_files.sort()
print(f"找到 {len(image_files)} 张图片,开始合并...")
# 3. 初始化PDF对象(A4纸张,单位mm)
pdf = FPDF(unit="mm", format="A4")
try:
for img_path in image_files:
# 打开图片并处理
with Image.open(img_path) as img:
# 转换为RGB(避免透明通道/调色板问题)
if img.mode != "RGB":
img = img.convert("RGB")
# 获取图片尺寸(像素)
img_width, img_height = img.size
# A4纸尺寸(mm):210×297
pdf_width = 210
pdf_height = 297
# 计算图片在PDF中的缩放比例(适配A4,不超出边界)
width_ratio = pdf_width / img_width
height_ratio = pdf_height / img_height
scale_ratio = min(width_ratio, height_ratio)
# 缩放后的图片尺寸
img_width_scaled = img_width * scale_ratio
img_height_scaled = img_height * scale_ratio
# 添加新页面
pdf.add_page()
# 将图片添加到PDF(居中显示)
pdf.image(
img_path,
x=(pdf_width - img_width_scaled) / 2, # 水平居中
y=(pdf_height - img_height_scaled) / 2, # 垂直居中
w=img_width_scaled,
h=img_height_scaled
)
print(f"已添加:{os.path.basename(img_path)}")
# 4. 保存PDF文件
pdf.output(output_pdf)
print(f"✅ PDF合并完成!文件保存至:{os.path.abspath(output_pdf)}")
except Exception as e:
print(f"❌ 处理失败:{str(e)}")
# 主程序执行
if __name__ == "__main__":
# 配置参数:图片文件夹(当前目录下的123文件夹)、输出PDF名称
IMAGE_FOLDER = r"C:\Users\jg2yXRZ\OneDrive\桌面\123\自动下载的PNG图片" # 图片文件夹路径
OUTPUT_PDF = IMAGE_FOLDER+r"\merged_images.pdf" # 输出PDF文件名
# 检查文件夹是否存在
if not os.path.exists(IMAGE_FOLDER):
print(f"错误:文件夹 {IMAGE_FOLDER} 不存在!")
else:
images_to_pdf(IMAGE_FOLDER, OUTPUT_PDF)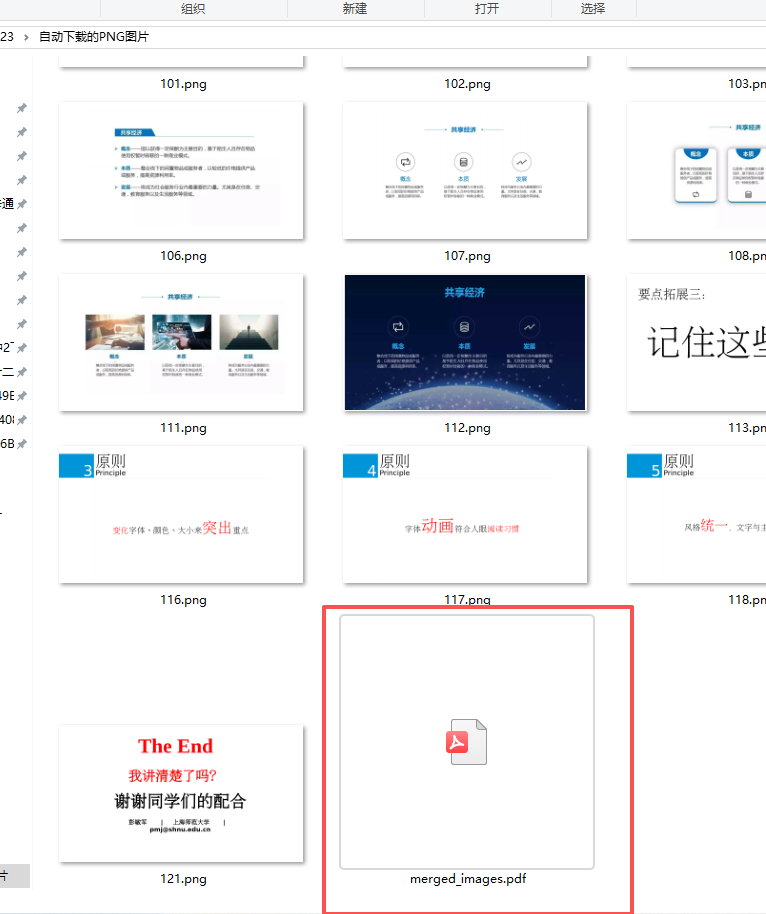

第二个PPT
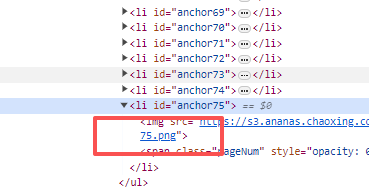

最后把下载的图片做成PDF,修改名称
20251227今天正好去上师大听《教育设计中的信息化》的线下课