关于知识库以及RAG、向量相似度和向量数据库有关前置知识,已经在下面文章提到:
1.概述
LangChain4j中RAG过程分为两个不同的阶段:索引和检索
-
索引 Indexing
将文档切分为片段,并嵌入转换为向量,将文档片段和对应向量成对一并保存到向量数据库。
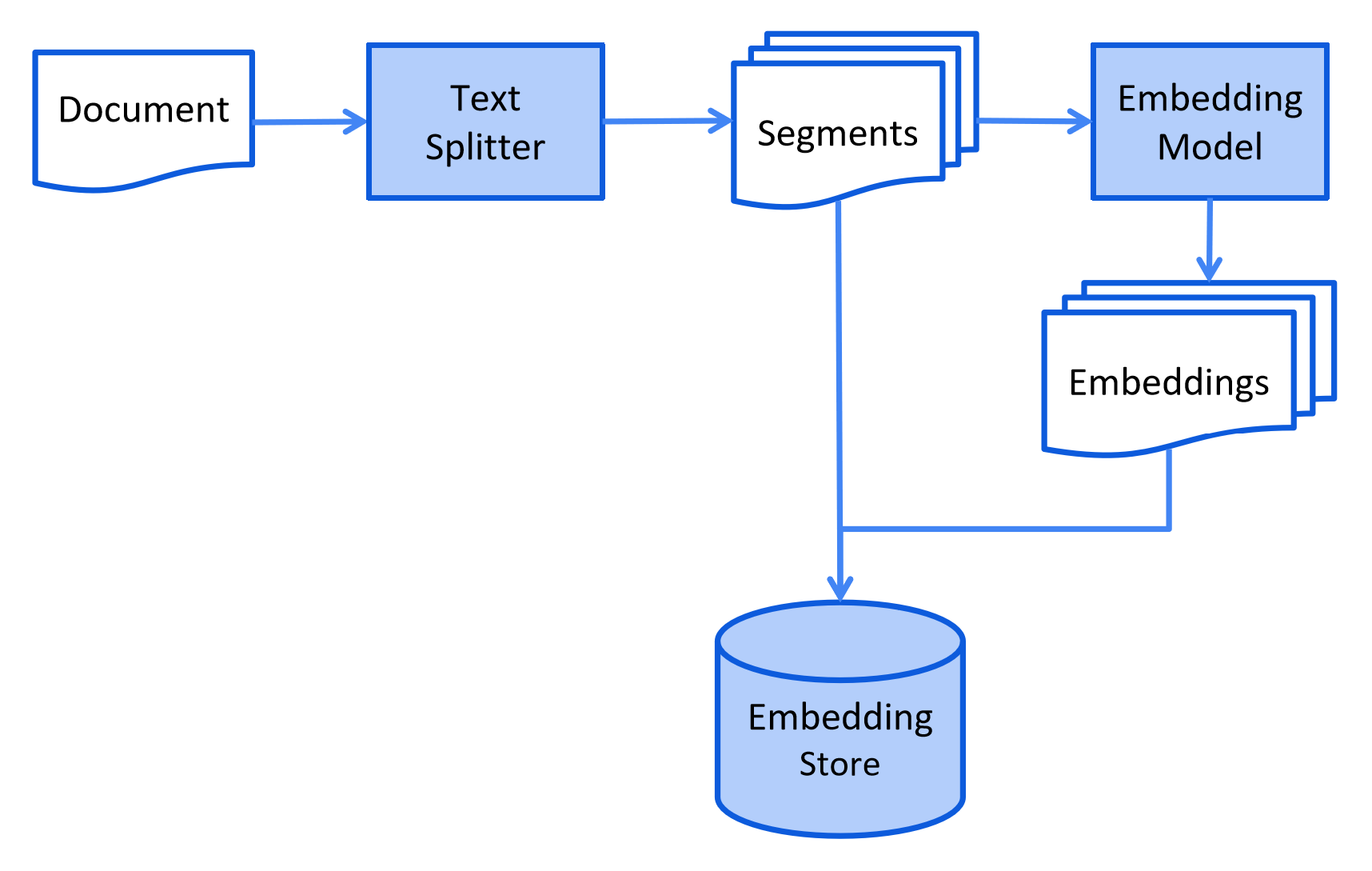
-
检索 Retrieval
当用户提交一个应该使用索引文档回答的问题时,将用户提问内容进行嵌入转换为向量,在将转换成的向量在向量数据库中检索出相似的片段,连同提示词一块发送给大模型。
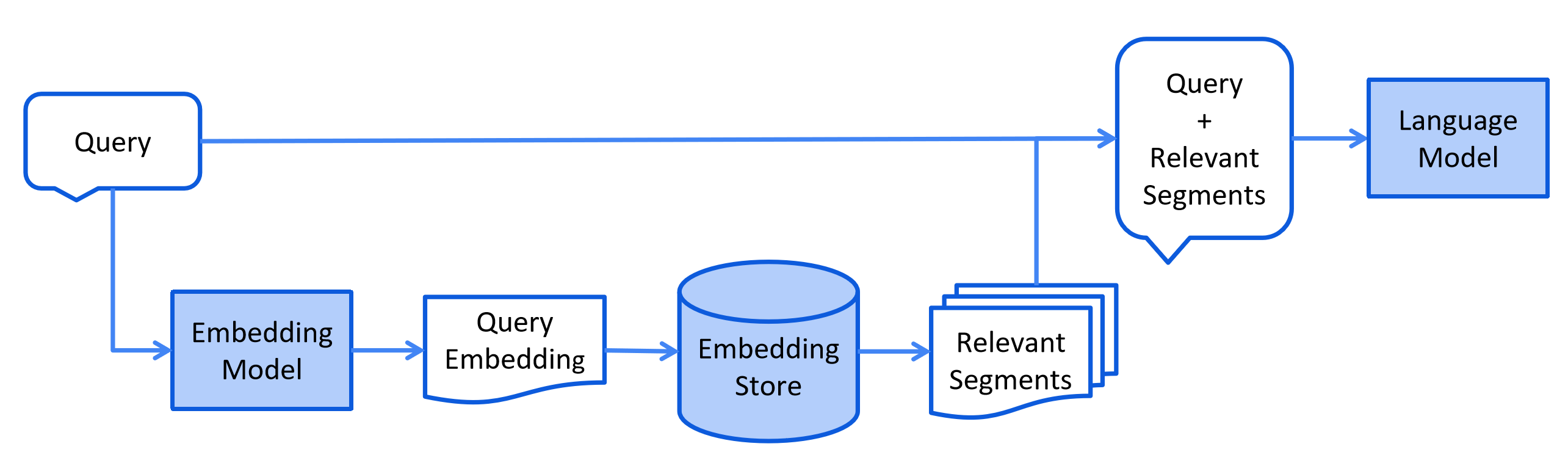

2.API详解
LangChain4j为RAG提供的工具,主要包括以下几种概念和对应API
-
文档 Document 一个文件,office,txt,pdf等等
-
文档加载器 Document Loader 从本地或网络加载文档
-
文档解析器 Document Parser 用于将文档(ms office, pdf)转换为纯文本数据的工具
-
文档分割器 Document Splitter 用于将文档按照行,段落等转换为的纯文本
-
向量模型 Embedding Model 将文本等数据转换为向量坐标
-
向量数据库操作对象 Embedding Store 用于操作向量数据库
2.1 文档加载器
- FileSystemDocumentLoader 从本地磁盘绝对路径加载
- ClassPathDocumentLoader 从工程类路径加载
- UrlDocumentLoader 从URL加载
2.2 文档解析器
-
TextDocumentParser 默认的解析器
-
ApachePdfBoxDocumentParser pdf解析器
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-document-parser-apache-pdfbox</artifactId> </dependency> -
ApacheTikaDocumentParser 几乎可以解析所有文档,但是可能解析PDF不专业
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-document-parser-apache-poi</artifactId> </dependency> -
ApachePoiDocumentParser 解析ms office文档,同样要引入langchain4j-document-parser-apache-poi
2.3 文档分割器
-
DocumentByParagraphSplitter 根据段落分割
-
DocumentByLineSplitter 根据行分割
-
DocumentBySentenceSplitter 根据句子分割
-
DocumentByWordSplitter 根据词分割
-
DocumentByCharacterSplitter 根据固定数量字符分割
-
DocumentByRegexSplitter 按照正则表达式分割
-
DocumentSplitters.recursive() 递归分割(默认分割器,单片段最大300字符)将文本按照段,行,句,词,字的优先级顺序分割
💡关于递归分割器:
将文本按照段,行,句,词,字顺序分割,能尽量多的截取信息。例如,如果限制截取最多300字符,要分割一个每段200字共两段的文档,使用段落分割器,会丢失整个的第二段。但如果使用递归分割器,可以尽可能将信息截取为第一段200字外加第二段的前几个行/句子组成的100字的形式。
如果默认的单片段最大300字符不能满足需求,还可以定制自己的递归分割器
DocumentSplitters.recursive(每片段最多字符, 两片段之间重叠字符个数);2.4 向量模型
langchain4j中使用EmbeddingModel接口操作向量模型,前面的例子中,文本向量化使用的是EmbeddingStoreIngestor默认的向量模型BgeSmallEnV15QuantizedEmbeddingModel,但是它的功能有限,实际项目中应当替换为其他的向量模型,例如阿里巴巴千问text-embedding-v4,它兼容open-ai的API协议,因此和ChatModel一样进行配置
langchain4j:
open-ai:
embedding-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: sk-5589********39970d248
model-name: text-embedding-v4
log-requests: true
log-responses: true
dimensions: 1024配置类中注入即可
@Resource
private EmbeddingModel embeddingModel;2.5 向量数据库
langchain4j操作向量数据库使用EmbeddingStore接口,默认会采用一个内存向量数据库,实际项目中数据的持久化存储,需要整合外置向量数据库,比如redis-stack,milvus, Qdrant等
以Qdrant为例,首先要引入Qdrant的依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-qdrant</artifactId>
</dependency>用Docker启动一个Qdrant示例
docker run -d -p 6333:6333 -p 6334:6334 qdrant/qdrant6333端口是浏览器访问控制台用的,6334是grpc协议,用于客户端连接。浏览器打开对应ip的6333端口,访问/dashboard,就可以看见Qdrant的控制台了

在Dashboard的Console中执行命令,创建一个test-qdrant库,这个步骤和ES还是很相似的
创建的向量库的维度size=1024,要和嵌入模型配置dimensions:1024一致,否则保存数据会出错

PUT /collections/test-qdrant
{
"vectors": {
"size": 1024,
"distance": "Cosine"
}
}配置类中使用EmbeddingStore接口操作对应向量数据库QdrantEmbeddingStore
@Bean
@Primary
public EmbeddingStore<TextSegment> embeddingStore() {
return QdrantEmbeddingStore.builder()
.host("192.168.228.104")
.port(6334)
.collectionName("test-qdrant")
.build();
}3.实现案例
这里先用一个简单实现介绍LangChain4j RAG的大致用法,采用阿里巴巴text-embedding-v4向量模型和Qdrant向量数据库,使用过程大致步骤是:
-
文档经Document Loader加载为Document对象到内存中,通过解析器Document Parser解析为文本,通过分割器Document Splitter进一步转换为片段Text Segment,最终,经向量模型Embedding Model转换为向量Embedding

-
当用户询问问题,ContentRetriever会将问题向量化,从向量数据库查询出相关片段夹在提示词中一并发送给大模型。

要实现一个最简单的langchain4j rag功能,需要导入langchain4j-easy-rag依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.4</version>
<relativePath/>
</parent>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>1.8.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>
</dependencies>
<repositories>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>21</source>
<target>21</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>application.yml配置基本的日志,嵌入模型等
server:
port: 8080
logging:
level:
dev.langchain4j: debug
langchain4j:
open-ai:
embedding-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${QWKEY}
model-name: text-embedding-v4
log-requests: true
log-responses: true
dimensions: 1024新建配置类:
-
EmbeddingStore<TextSegment>:向量数据库,设置为@Primary替换spring的自动装配
-
EmbeddingStoreIngestor:用于分割文档,转换向量和存储
-
ContentRetriever:用于检索与提示词相关的知识,一并发送给大模型,通过
.dynamicFilter的配置回调方法在查找到相关知识片段后,还要根据某个元信息进行匹配,这里简单的将传过来的会话ID:chatMemoryId当作用户ID,用于区分用户,实际项目中可以实现根据chatMemoryId得到userId的方法,最终用userId进行查询。package org.example.config;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.splitter.*;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.StreamingChatModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiStreamingChatModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.filter.MetadataFilterBuilder;
import dev.langchain4j.store.embedding.qdrant.QdrantEmbeddingStore;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import dev.langchain4j.store.memory.chat.InMemoryChatMemoryStore;import jakarta.annotation.Resource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;@Configuration
public class RagConfig {@Resource private EmbeddingModel embeddingModel; @Bean public StreamingChatModel streamingChatModel() { return OpenAiStreamingChatModel.builder() .baseUrl("https://api.deepseek.com/") .apiKey(System.getenv("DSKEY")) .modelName("deepseek-reasoner") .logRequests(true) .logResponses(true) .returnThinking(true) .build(); } @Bean public ChatMemoryStore chatMemoryStore() { return new InMemoryChatMemoryStore(); } @Bean public ChatMemoryProvider chatMemoryProvider () { return new ChatMemoryProvider() { @Override public ChatMemory get(Object id) { return MessageWindowChatMemory.builder() .id(id) .maxMessages(1000) .chatMemoryStore( chatMemoryStore() ) .build(); } }; } @Bean public EmbeddingStoreIngestor ingestor() { return EmbeddingStoreIngestor.builder() .embeddingStore(embeddingStore() ) .documentSplitter( DocumentSplitters.recursive(1000, 100) ) //指定分割器 .embeddingModel(embeddingModel) .build(); } @Bean public ContentRetriever contentRetriever(EmbeddingStore embeddingStore) { return EmbeddingStoreContentRetriever.builder() .embeddingStore(embeddingStore) .maxResults(7) //返回片段数 .minScore(0.5) //最小余弦相似度 .embeddingModel(embeddingModel) //使用自己定义的向量模型 .dynamicFilter(query -> { Object chatMemoryId = query.metadata().chatMemoryId(); String userId = chatMemoryId.toString(); return MetadataFilterBuilder.metadataKey("author").isEqualTo(userId); }) .build(); } @Bean @Primary public EmbeddingStore<TextSegment> embeddingStore() { return QdrantEmbeddingStore.builder() .host("192.168.228.104") .port(6334) .collectionName("test-qdrant") .build(); }}
在@AiService注解上新增属性值contentRetriever = "contentRetriever",使chat功能具备RAG能力
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,
streamingChatModel = "streamingChatModel",
chatMemoryProvider = "chatMemoryProvider",
contentRetriever = "contentRetriever"
)
public interface RagAssistance {
Flux<String> chat(@UserMessage String prompt, @MemoryId String msgId);
}新建一个测试类,将信息向量化,然后写入刚刚创建的向量数据库
实际项目中,这个过程就是用户自己上传文档到自己的知识库,供大模型参考,同时还附带了一些知识片段的元信息,主要用于标识知识片段,例如:用于区分所属用户。
package org.example.test;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.apache.pdfbox.ApachePdfBoxDocumentParser;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import jakarta.annotation.Resource;
import org.example.Main;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest(classes = Main.class)
public class RagTest {
@Resource
private EmbeddingStore embeddingStore;
@Resource
private EmbeddingModel embeddingModel;
@Resource
EmbeddingStoreIngestor ingestor;
//文字
@Test
public void index() {
String msg = """
户晨风,男,汉族,1998年10月11日出生,成都卖有回音文化传媒有限公司法定代表人, [7]网络视频博主,泛娱乐领域自媒体创作者,截至2025年9月,哔哩哔哩粉丝数达67.4万,抖音粉丝数达93.7万 [1-2],微博粉丝数达20万。2025年9月16日,话题 "户晨风疑似被封" 登上微博热搜,其微博、抖音、B站等多个社交平台的账号遭到封禁或功能限制。
户晨风成长于一个贫穷农村家庭,后随父母搬到城里。2023年11月27日,他发布了首个作品《100元人民币,在泰国首都曼谷的购买力到底有多强?》,从此开始进行自媒体创作。2024年6月21日,发布作品《新加坡街边卖艺,84 岁老人的一生》。2025年9月7日,发布作品《呼和浩特,真假乞讨?------户晨风全球真假乞讨系列》。
2025年,户晨风以"苹果安卓"为标签代指消费、学历上的鄙视链等言论引发巨大争议 [5]。9月16日,其微博、抖音、B站等多个社交平台的账号遭到封禁或功能限制 [3]。9月20日下午,有网友报料,网红"户晨风"在抖音、微博等多个平台账号已被封禁,其账号内容被清空 [5]。9月30日晚,极目新闻记者搜索发现,户晨风全网账号被彻底封禁,且无法通过搜索找到账号,账号主页已无法查看信息 [6]。11月5日,户晨风账号被封详情披露,从展示跨国消费差异到制造阶层对立,户晨风以"苹果、安卓论"收割流量,最终突破监管红线 [9]。
2025年12月消息,网络账号"户晨风"在多个平台长期编造所谓"安卓人""苹果人"等煽动群体对立言论,各平台相关账号已关闭。
""";
Response<Embedding> response = embeddingModel.embed(msg);
Embedding embedding = response.content();
TextSegment segment = TextSegment.from(msg);
segment.metadata().put("author", "lzj");
segment.metadata().put("doc", "1.txt");
embeddingStore.add(embedding, segment);
}
//模拟pdf文档
@Test
public void pdf() {
Document document = FileSystemDocumentLoader.loadDocument("D:/毕业设计/装订/答辩.pdf", new ApachePdfBoxDocumentParser());
document.metadata().put("author", "lzj");
document.metadata().put("doc", "答辩.pdf");
ingestor.ingest(document);
}
}调用RagAssistance的方法,可以看到会在发送提示词给大模型前检索向量数据库查询相似片段进行拼接
GET http://127.0.0.1:8080/rag-chat/stream?msg=你知道安卓苹果相对论吗&msgId=lzj
package org.example.controller;
import jakarta.annotation.Resource;
import org.example.ai.RagAssistance;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("rag-chat")
public class RagController {
@Resource
private RagAssistance assistance;
@GetMapping(value = "stream", produces = "text/html; charset=utf-8")
public Flux<String> stream(String msg, String msgId) {
return assistance.chat(msg, msgId);
}
}
2025-12-14T15:06:25.110+08:00 INFO 14848 --- [nio-8080-exec-1] d.l.http.client.log.LoggingHttpClient : HTTP request:
- method: POST
- url: https://api.deepseek.com/chat/completions
- headers: [Authorization: Beare...07], [User-Agent: langchain4j-openai], [Content-Type: application/json]
- body: {
"model" : "deepseek-reasoner",
"messages" : [ {
"role" : "user",
"content" : "你知道安卓苹果相对论吗吗\n\nAnswer using the following information:\n2025年12月消息,网络账号"户晨风"在多个平台长期编造所谓"安卓人""苹果人"等煽动群体对立言论,各平台相关账号已关闭。\n\n2025年,户晨风以"苹果安卓"为标签代指消费、学历上的鄙视链等言论引发巨大争议 [5]。9月16日,其微博、抖音、B站等多个社交平台的账号遭到封禁或功能限制 [3]。9月20日下午,有网友报料,网红"户晨风"在抖音、微博等多个平台账号已被封禁,其账号内容被清空 [5]。9月30日晚,极目新闻记者搜索发现,户晨风全网账号被彻底封禁,且无法通过搜索找到账号,账号主页已无法查看信息 [6]。11月5日,户晨风账号被封详情披露,从展示跨国消费差异到制造阶层对立,户晨风以"苹果、安卓论"收割流量,最终突破监管红线 [9]。\n\n户晨风,男,汉族,1998年10月11日出生,成都卖有回音文化传媒有限公司法定代表人, [7]网络视频博主,泛娱乐领域自媒体创作者,截至2025年9月,哔哩哔哩粉丝数达67.4万,抖音粉丝数达93.7万 [1-2],微博粉丝数达20万。2025年9月16日,话题 "户晨风疑似被封" 登上微博热搜,其微博、抖音、B站等多个社交平台的账号遭到封禁或功能限制。\n\n户晨风成长于一个贫穷农村家庭,后随父母搬到城里。2023年11月27日,他发布了首个作品《100元人民币,在泰国首都曼谷的购买力到底有多强?》,从此开始进行自媒体创作。2024年6月21日,发布作品《新加坡街边卖艺,84 岁老人的一生》。2025年9月7日,发布作品《呼和浩特,真假乞讨?------户晨风全球真假乞讨系列》。"
} ],
"stream" : true,
"stream_options" : {
"include_usage" : true
}
}一个简单的RAG实现就完成了,实际项目中按照实际情况切换向量数据库和文档加载器和分割器即可。