摘要:在将 Vision Transformer (ViT) 从预训练模型(如 ImageNet-1k, 224x224)迁移到工业缺陷检测或高分辨率任务(如 384x384, 512x512)时,最常见的报错就是位置编码维度不匹配。本文将用通俗易懂的"图像缩放"视角,详解为何需要插值以及底层的代码实现逻辑。
关键词:Vision Transformer, ViT, Fine-tuning, Position Embedding, PyTorch
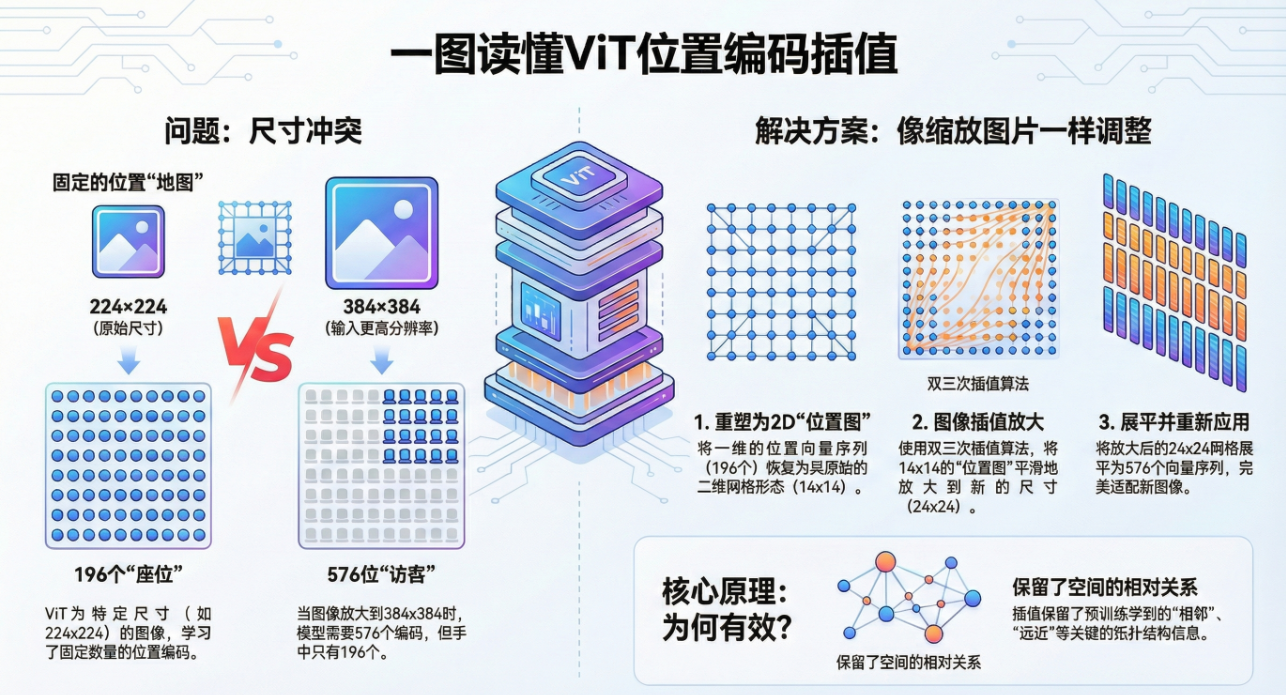
一图读懂VIT位置编码
1. 问题现场:为什么会报错?
很多从 CNN 转到 Transformer 的视觉工程师,在加载 ViT 预训练权重时,经常遇到类似这样的 RuntimeError:
原因分析
这本质上是 "坑位"不够了。
-
预训练时 (Pre-training) :输入图像是 224 *224。Patch Size 为 16,那么 Patch 的数量是 (224/16)^2 = 14 * 14 = 196 个。加上 1 个
[CLS]Token,模型里存了 197 个位置向量。 -
微调时 (Fine-tuning) :为了看清缺陷细节,你把输入改成了 384* 384。Patch 数量激增到 (384/16)^2 = 24 *24 = 576 个。加上
[CLS],你需要 577 个位置向量。
冲突点:模型手里只有 196 个位置的"身份证"(权重),现在却来了 576 个 Patch。直接加载权重自然会对不上。
2. 核心逻辑:像"缩放图片"一样"缩放权重"
我们不能随机初始化多出来的 380 个位置向量,那样会破坏预训练学到的空间关系。
解决的核心思路非常符合直觉:把位置编码当成一张图,直接做 Resize。
通俗类比
想象你有一张 14 * 14的像素画(预训练权重)。
现在你需要一张内容一样,但分辨率更高的 24*24 的画(微调权重)。
你会怎么做?直接用 PS 或者 OpenCV 拉伸(插值)一下。
ViT 的处理方式一模一样:
-
把一维的向量序列还原成二维网格。
-
使用 双三次插值 (Bicubic Interpolation) 将网格放大。
-
再展平回一维序列。
这样做的好处是保留了相对拓扑关系:原图左上角的位置向量,插值后依然位于新图的左上角。
3. 详细步骤拆解 (Step-by-Step)
假设我们从 224 *224(14 * 14) 迁移到 384 * 384(24*24)。
Step 1: 剥离 CLS Token
序列中的第一个 Token 是 [CLS],它代表"全图特征",不具有空间物理位置概念。
- 操作 :把它单独拿出来,不参与插值,直接 Copy 过去。
Step 2: 恢复空间结构 (Reshape)
剩下的 196 个向量,在内存里是 [1, 196, 768] 的 1D 序列。
-
操作 :根据 H=W= sqrt{196}=14,将其 Reshape 成
[1, 768, 14, 14]的 4D Tensor。 -
注:这里类似把一个长条形的数据变成了 NCHW 的图片格式。
Step 3: 双三次插值 (Interpolate)
调用 PyTorch 的 F.interpolate,将 14x14 放大到 24x24。
-
操作 :输入
[1, 768, 14, 14]-> 输出[1, 768, 24, 24]。 -
为什么选 Bicubic? 相比双线性插值 (Bilinear),双三次插值更平滑,能更好地保留高维特征的连续性。
Step 4: 展平与拼接 (Flatten & Concat)
-
操作 :将放大的特征图展平为
[1, 576, 768],然后把 Step 1 剥离的[CLS]拼回去。 -
最终结果 :
[1, 577, 768],完美匹配新模型。
4. 硬核代码实现 (PyTorch)
以下是基于 timm 库风格的最小化实现代码,可直接复制使用:
5. 总结
ViT 的位置编码插值并不是什么高深的数学魔法,本质就是 Feature Map 的 Resize。
这使得 ViT 能够突破固定分辨率的限制,让同一个预训练模型能够适应不同分辨率的下游任务。对于我们做工业视觉的人来说,理解这一点非常重要:ViT 里的 Patch 序列,骨子里依然保留着二维图像的空间结构。