一、引言
1.1 复杂文档的感知瓶颈
当前,以大语言模型(LLM)为核心的智能体(Agent)技术,正快速融入法律文书问答、合同条款比对、技术标准解读等企业核心业务流程中。基于自主任务理解、步骤规划与工具调用能力,智能体能够可靠执行教育科研辅助、法律信息提取、合同自动比对、标准结构化解析等一系列复杂业务操作,有效提升效率与准确性。

然而,当Agent真正用于处理上述复杂业务文档时,其效能首先受限于输入知识的质量,而这直接源于文档本身的高度复杂性。此类文档通常具备多重典型特征:语言混合、格式不一,且具有强烈的结构依赖性------无论是严谨的章节编号与条款引用,还是跨页分布的大型表格与多层合并单元格,均构成机器理解与深入处理的根本障碍。
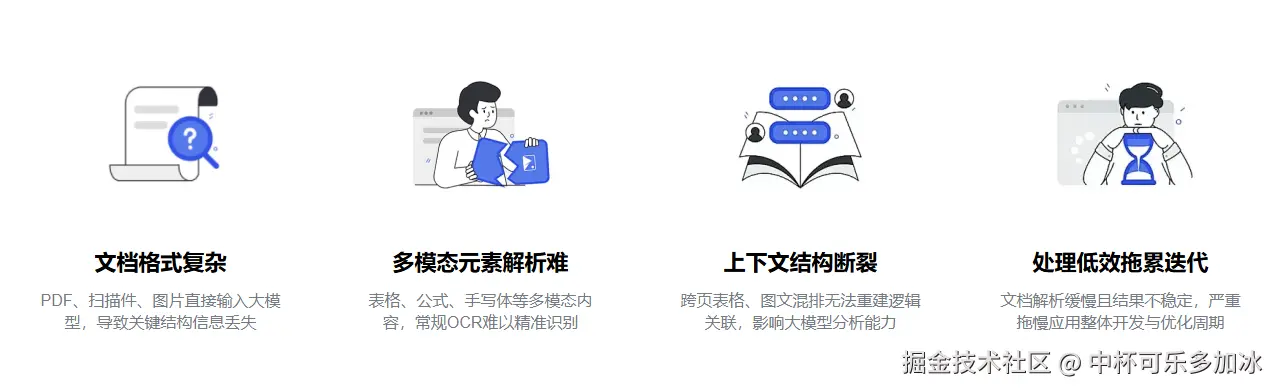
面对如此复杂的文档,传统的Agent 流程常受限于一个根本性的工程难题,具体表现为以下两个核心痛点:
首先,是语义边界的模糊。文档中原本完整的段落或表格,常因跨页、分栏而被解析工具切断。在此情况下,传统的基于固定长度或简单标点的分块策略,往往生成大量语义残缺的文本块,无法恢复其原始逻辑完整性。
其次,是结构化信息的丢失。合同、标书等文档中的标题、列表、表格等层级与关系信息,在解析过程中经常被丢弃,后续的分块策略只能依赖字符长度等表面特征,而无法实现基于语义结构的智能切分。
正因如此,我们认识到:有时候一个智能体性能瓶颈,往往并非源于大语言模型的能力上限,而更取决于知识预处理阶段的质量控制。提升解析与分块的准确性,要提升 Agent 在复杂文档场景下的表现,必须先解决 Agent 的文档感知问题。
1.2 TextIn文档智能解析引擎
为突破 RAG 与 Agent 在文档感知层面的工程瓶颈,引入专业的文档智能解析工具成为必然选择。TextIn 正是面向这一核心问题构建的文档智能解析引擎,其目标并非单纯完成 OCR,而是输出"对大模型友好"的高质量结构化语义结果。
在真实业务流程中,TextIn 的解析结果通常会被直接写入企业知识库或向量数据库,作为后续问答、比对、审查任务的基础数据层。其核心价值主要体现在以下三方面:
- 极致的兼容性与多语言支持: TextIn 提供了业界领先的文档兼容性,其支持 50+ 种语言 的深度解析和 20+ 种文件格式(包括 PDF、Word、Excel、扫描件、图片等),对于复杂的扫描件和版式文件,TextIn 能够进行高精度的版面分析和 OCR 识别,确保知识源头的准确性。
- 高质量结构化输出:Markdown 与 BBox: TextIn能够将复杂的文档结构准确地转化为标准的 Markdown 格式文本。这种Markdown 格式天然地保留了文档的语义结构,使得后续的分块策略可以从基于长度的简单切分,升级为基于语义结构的智能切分。同时,TextIn 还附带了每个文本块在原始文档中的 BBox(边界框)坐标信息,为实现精确的引用溯源和未来的视觉 RAG 奠定了数据基础。
- 灵活的 API 接口: TextIn 提供了 通用文档解析 和 智能文档抽取 等多种 API 接口,开箱即用。
基于此,本文将深入剖析如何依托 TextIn 这一专业文档解析平台,通过工作流实现 Agent 的实时文档理解能力。
二、技术实践:基于 TextIn + Coze 的 Agent 方案
2.1 架构设计
本次实践选取的业务场景为论文分析总结助手。在这个场景中,文档主要来自上传的各类学术论文和学术报告,既包括排版规范的PDF论文,也包含扫描版或版式复杂的历史文献。用户在上传论文后,通常希望快速理解论文的核心贡献、方法结构与关键结论,并能够围绕具体章节或实验结果进行问答与总结。Agent 生成的结构化摘要、要点总结及对应章节定位信息,可用于辅助论文初筛、评审准备或科研调研过程。
为了快速验证 TextIn 的能力,并构建一个可交互的原型 Agent,我选择了 Coze 平台。Coze 是一个一站式 AI Bot 开发平台,它提供了可视化的工作流编排和插件工具集成能力,非常适合进行 Agent 的敏捷开发和能力验证。

本次的Agent 架构设计整体遵循"感知-推理"的逻辑:Agent 接收到用户上传的文档后,首先调用 TextIn 插件进行感知(文档解析),然后将解析后的高质量结构化文本作为输入,驱动 LLM 进行推理(问答、总结),架构流程概览如下:
- 用户输入:用户上传待分析的文档(如合同 PDF)并提出问题。
- Agent 决策:Coze Agent 识别到输入是文件,触发 TextIn 插件调用。
- 感知层(TextIn) :TextIn 调用通用文档解析 API,将复杂文档转化为 Markdown 文本。
- 推理层(LLM) :Agent 将 TextIn 返回的 Markdown 文本作为上下文,结合用户问题,调用 LLM 进行推理和生成答案。
2.2 实践步骤与解析节点说明
2.2.1 步骤一:编排工作流
首先进入 Coze 平台,点击进入扣子编程的工作空间,选择资源库,点击右上角创建,创建一个新的工作流
进入工作流编排页面后,选择开始后面的加号,然后选择添加"插件"
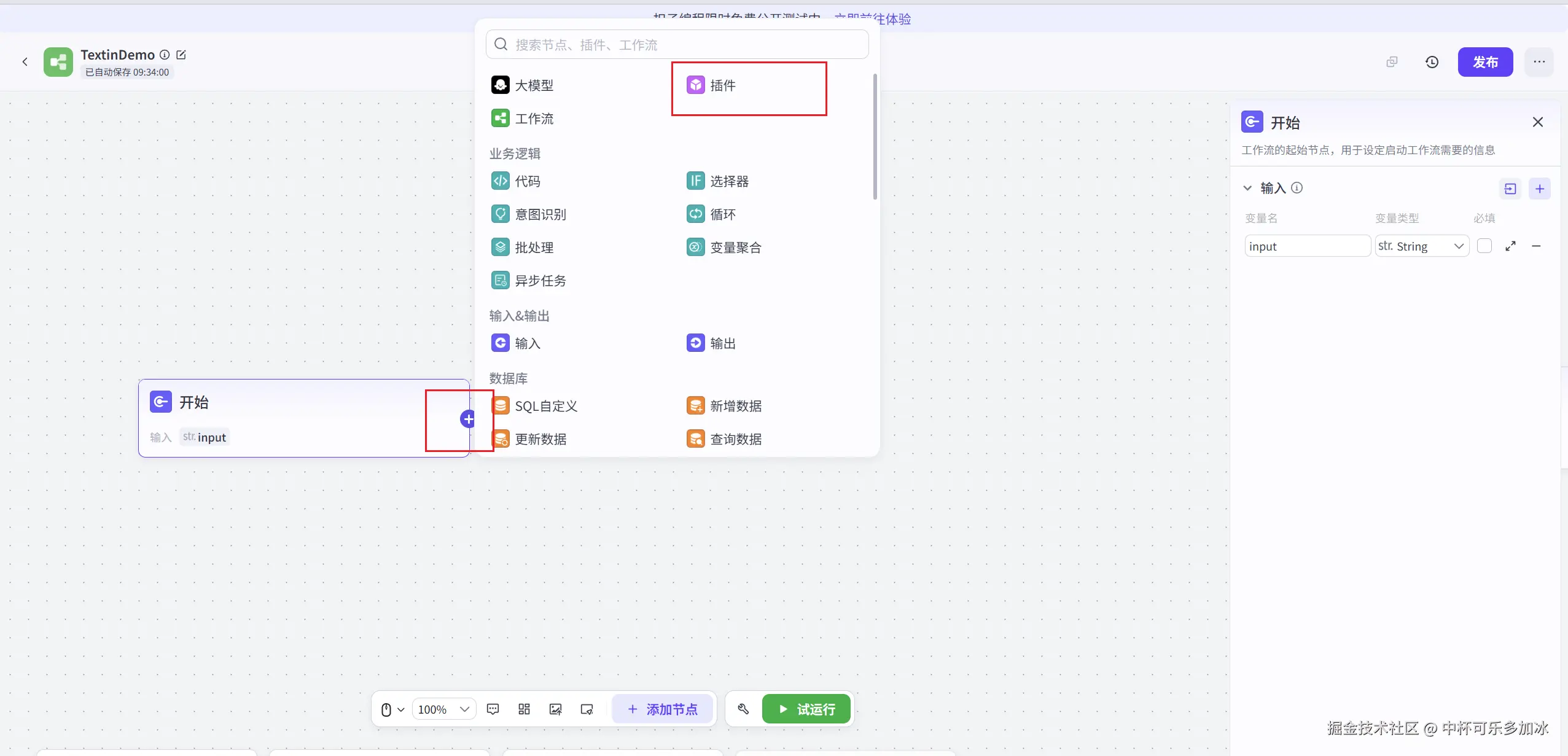
可以看到Coze插件市场中已经集成好了Textin的插件,我们只需要搜索"Textin"就可以看到ParseX通用文档解析、pdf转markdown、Textin OCR等多个插件,这里选择ParseX添加:

接下来我们开始编排工作流,首先将工作流的起始组件 Input 类型设置为 File-default,以接收用户上传的文档。
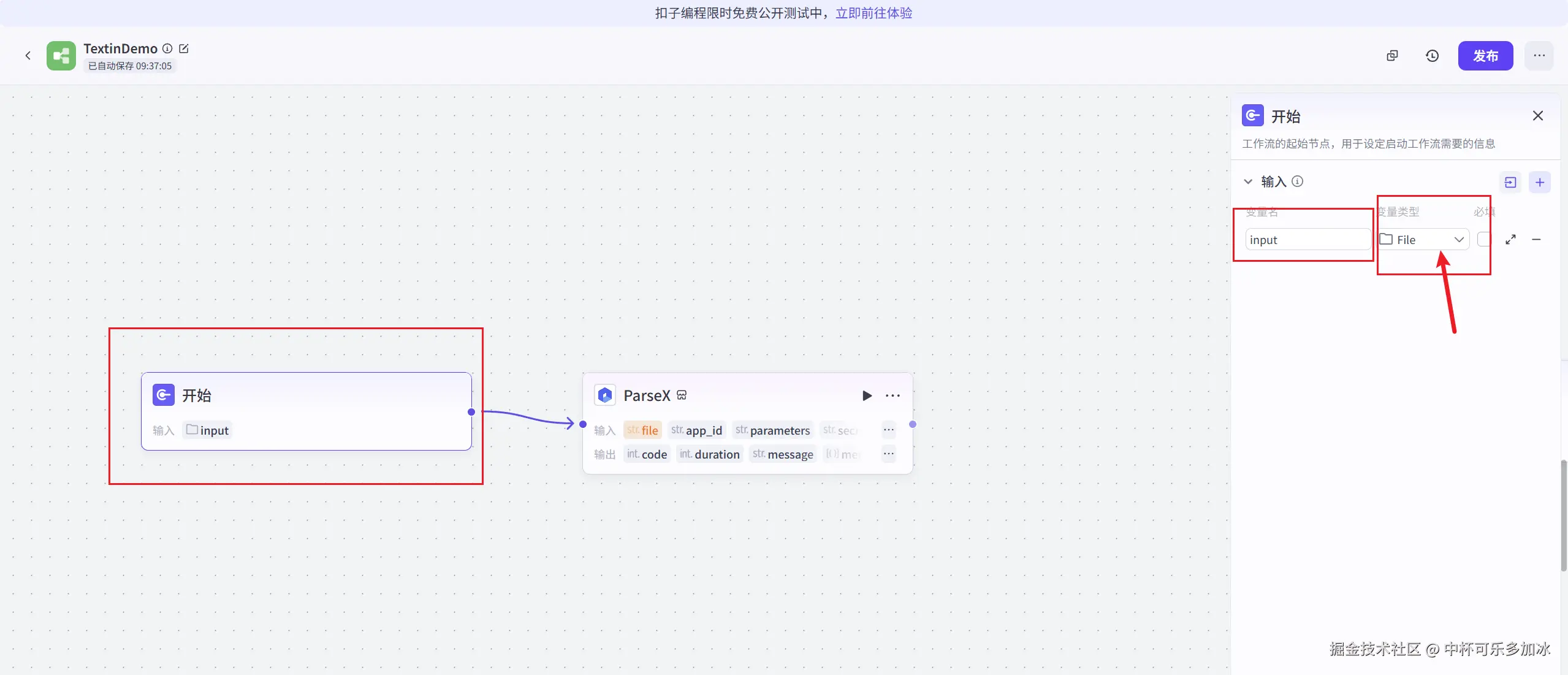
随后,将 TextIn 插件也就是ParseX组件的输入变量(file)引用到起始组件的 file,确保 Agent 能够将用户上传的文件正确传递给 TextIn。
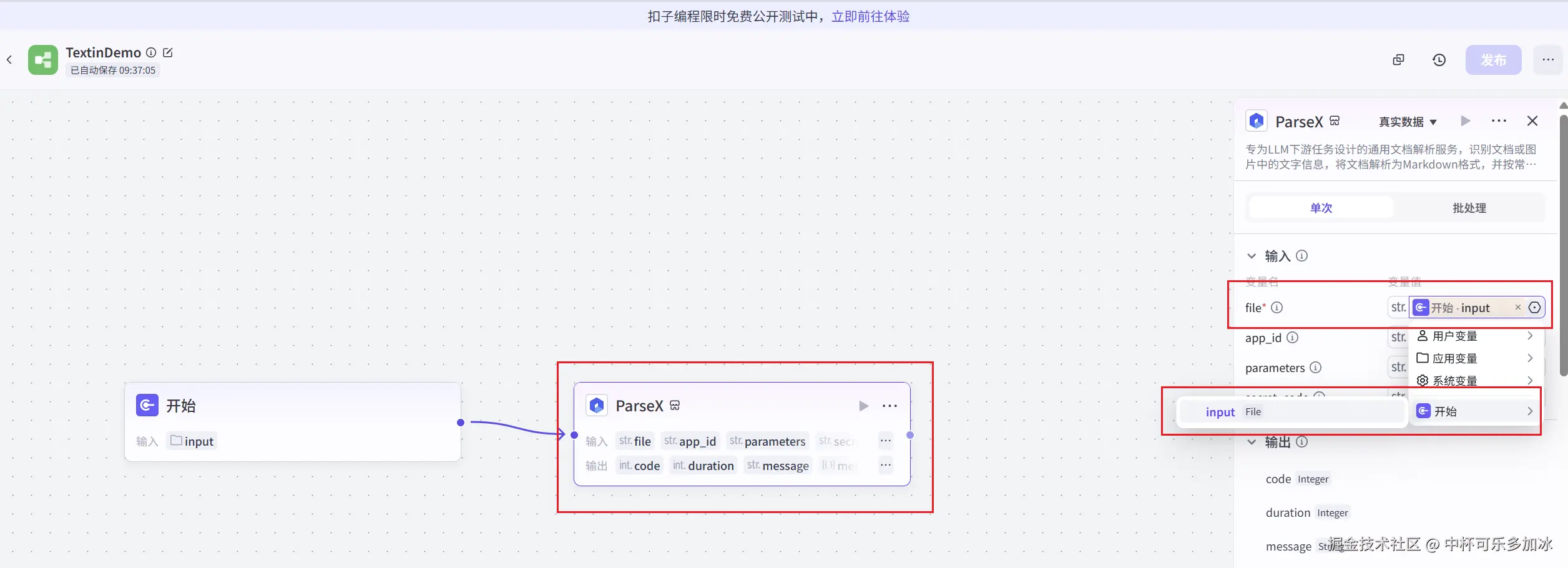
为了确保 TextIn 服务的安全调用,ParseX组件是需要鉴权的,我们需要在插件配置中填入从 TextIn 官网获取的 x-ti-app-id 和 secret-code 进行鉴权。
这里需要登录Textin官网,前往 "账号与开发者信息" 查看 x-ti-app-id和secret_code,将其复制下来,填入到ParseX组件当中
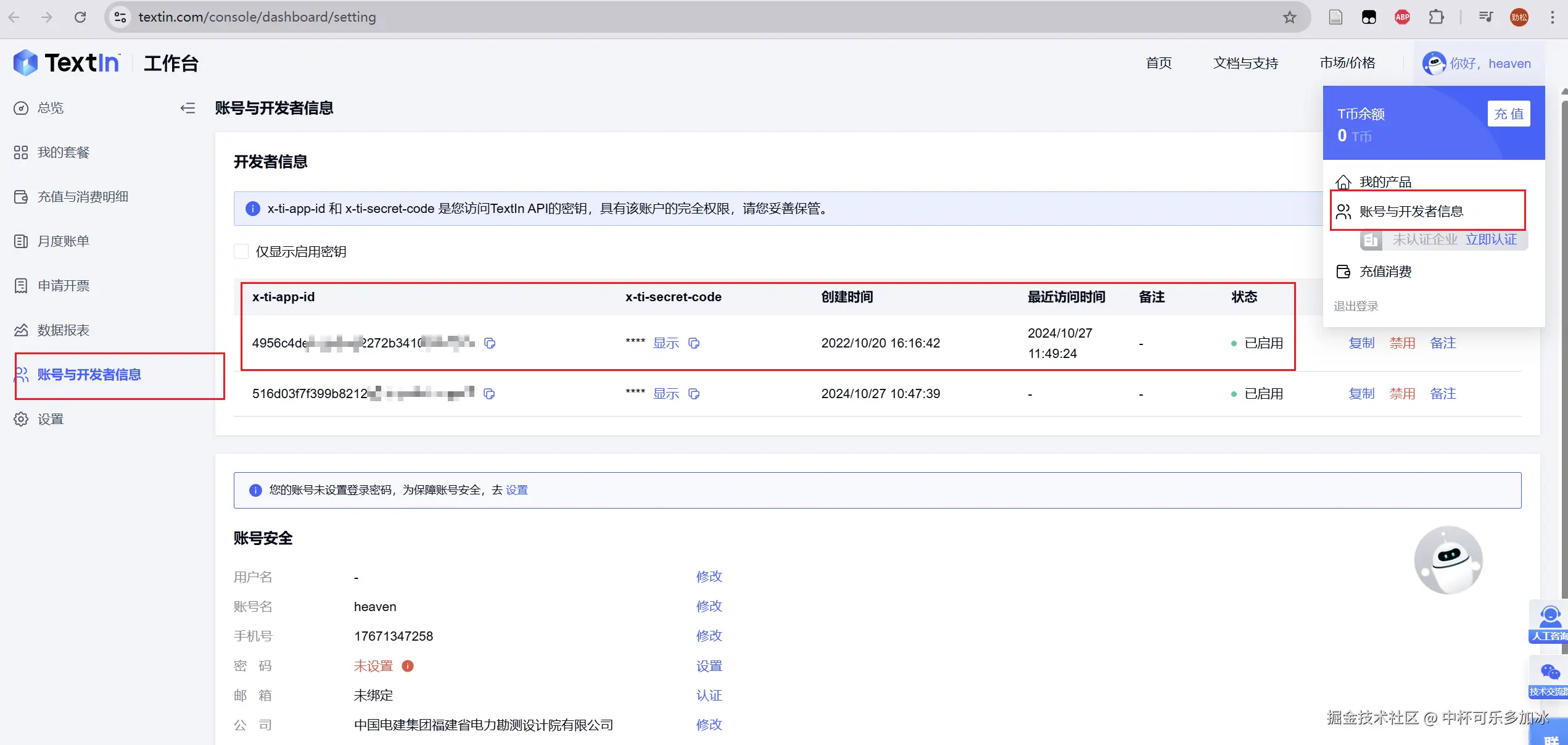
配置成功后如下所示:
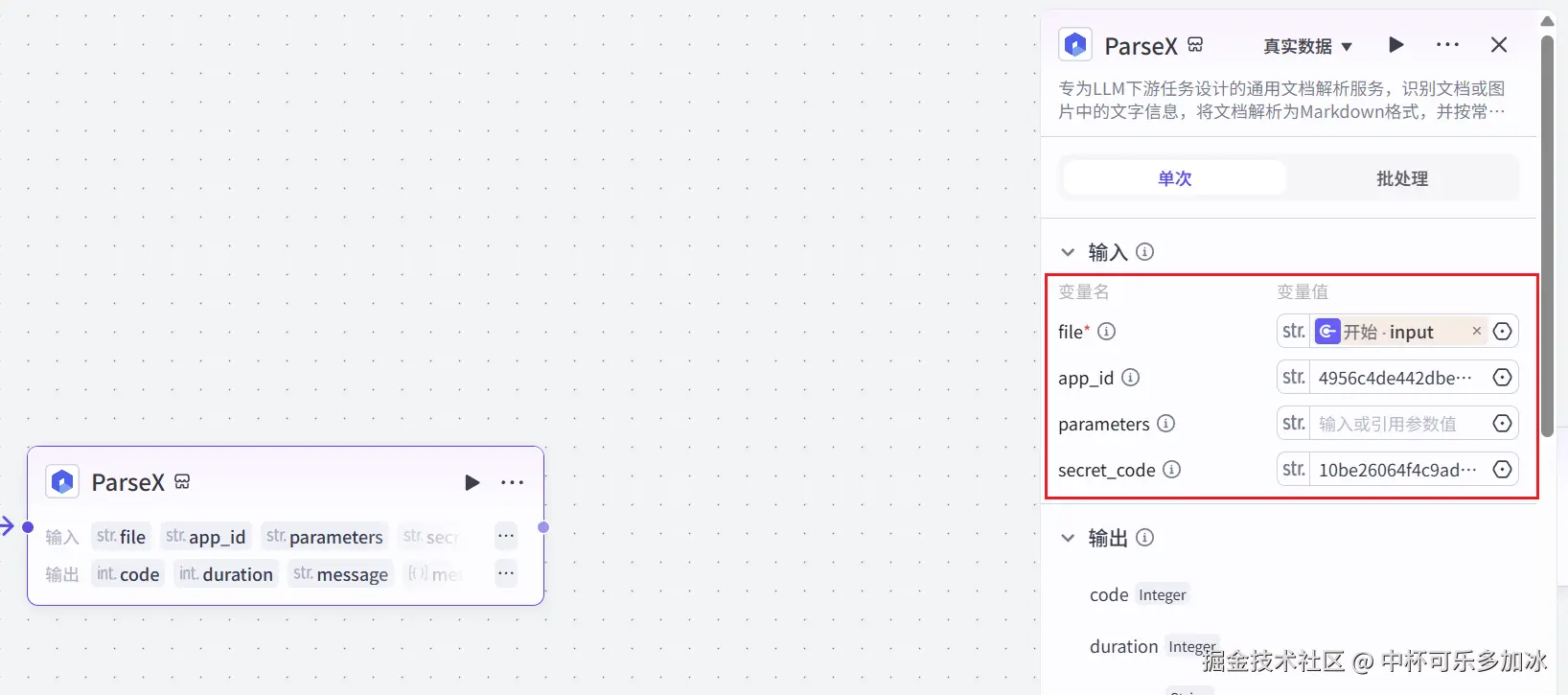
然后我们就先可以接入一个结束组件,点击试运行,试运行结束,可以看到ParseX插件成功解析了文件并且输出了对应的内容
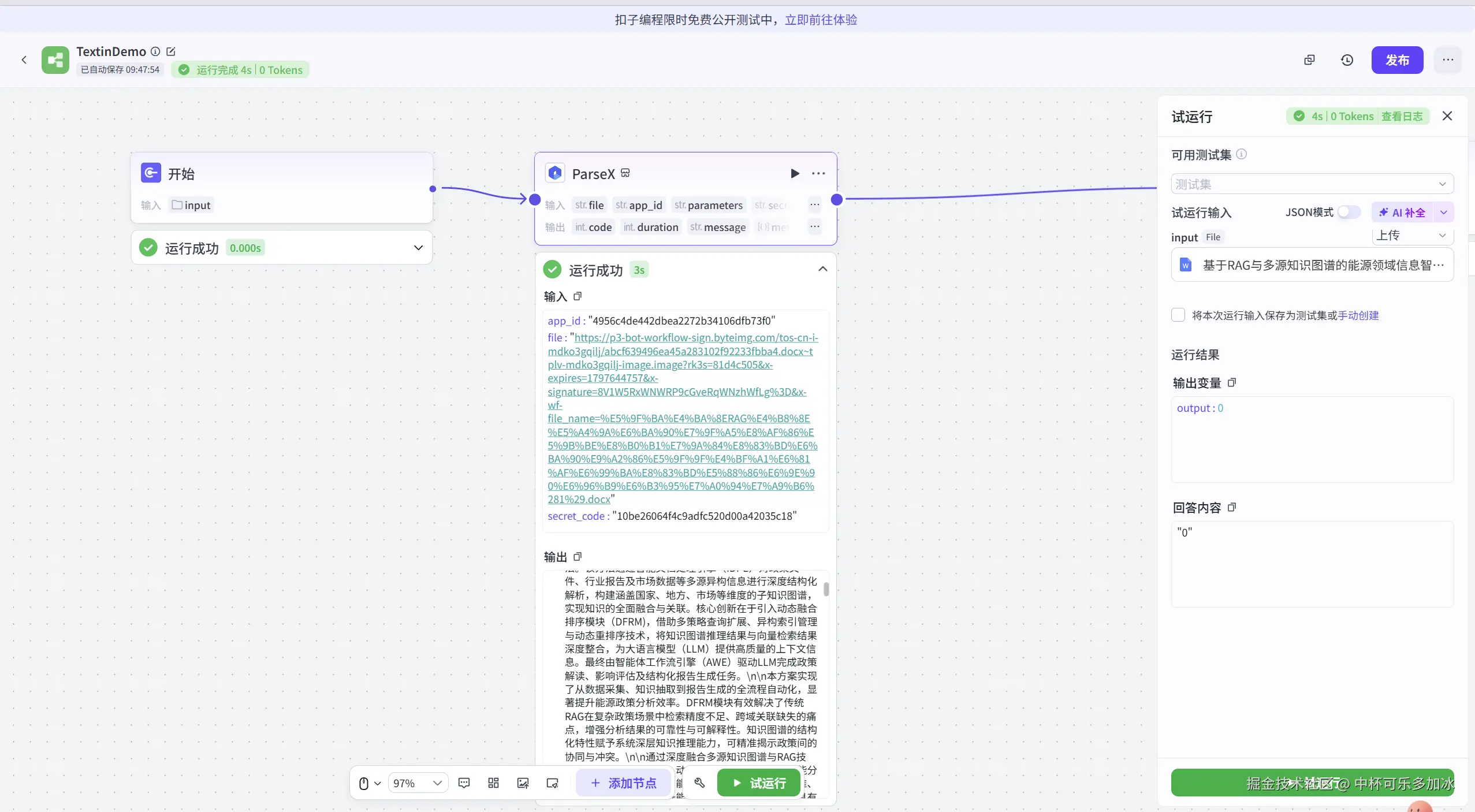
在 TextIn 成功解析文件并输出 Markdown 文本后,我们将其作为 LLM 的上下文输入,这是整个实践中最关键的一步。
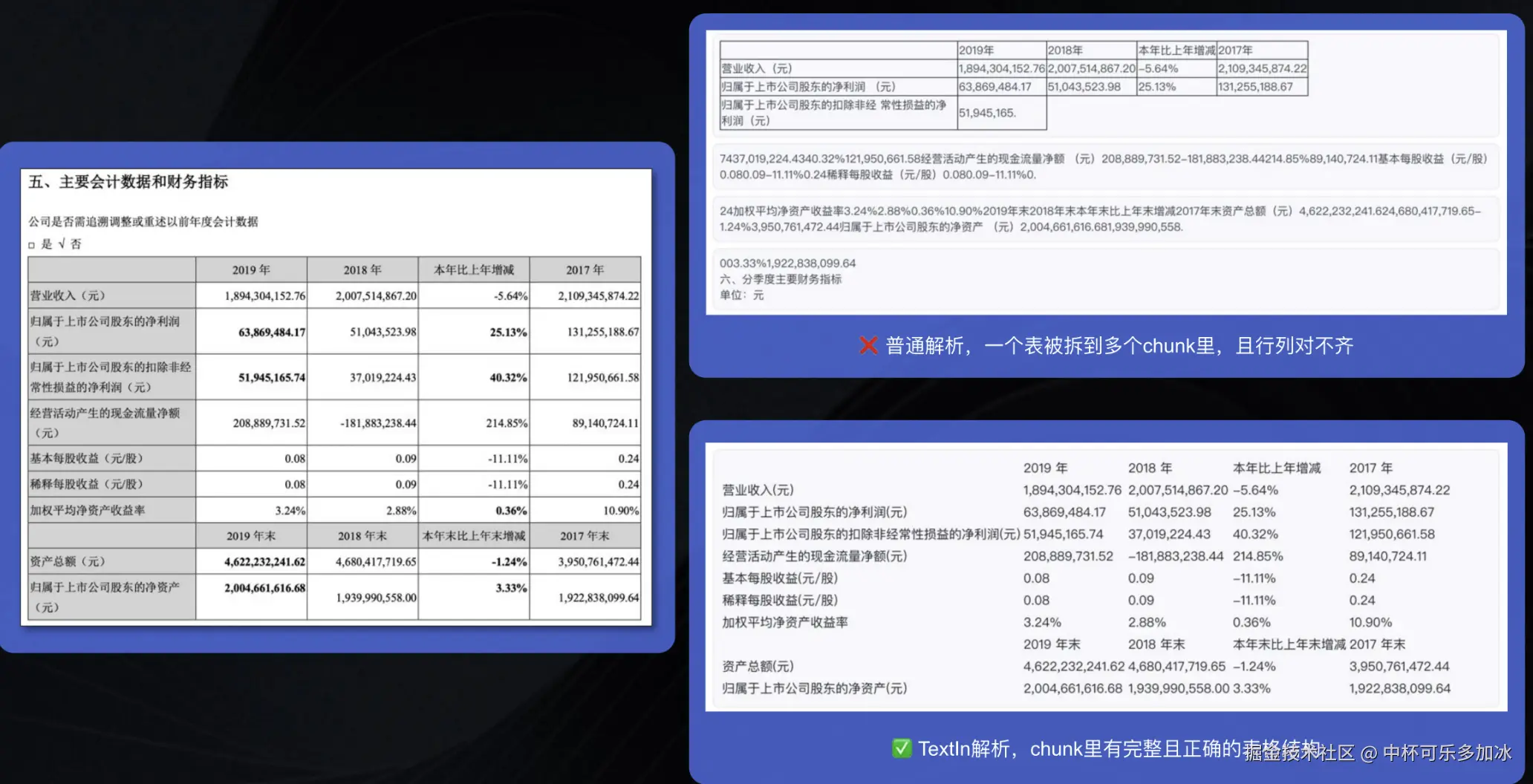
传统的 Agent 问答,如果直接输入原始 PDF 或者word文件,LLM 必须花费大量的计算资源去推理文本的结构和逻辑关系。而 TextIn 提供的 Markdown 文本,已经清晰地标注了标题(#)、列表(-)、表格(|)等结构。 一个复杂的表格在 TextIn 解析后,会以标准的 Markdown 表格形式呈现。Agent 在接收到这样的输入后,可以直接利用其强大的表格推理能力,而无需进行额外的结构重建工作,极大地提升了推理的效率和准确性。
我们将 TextIn 插件的输出 result/markdown 接入到 LLM 组件,并设计系统提示词,指导 Agent 如何利用这份高质量的结构化上下文进行回答。
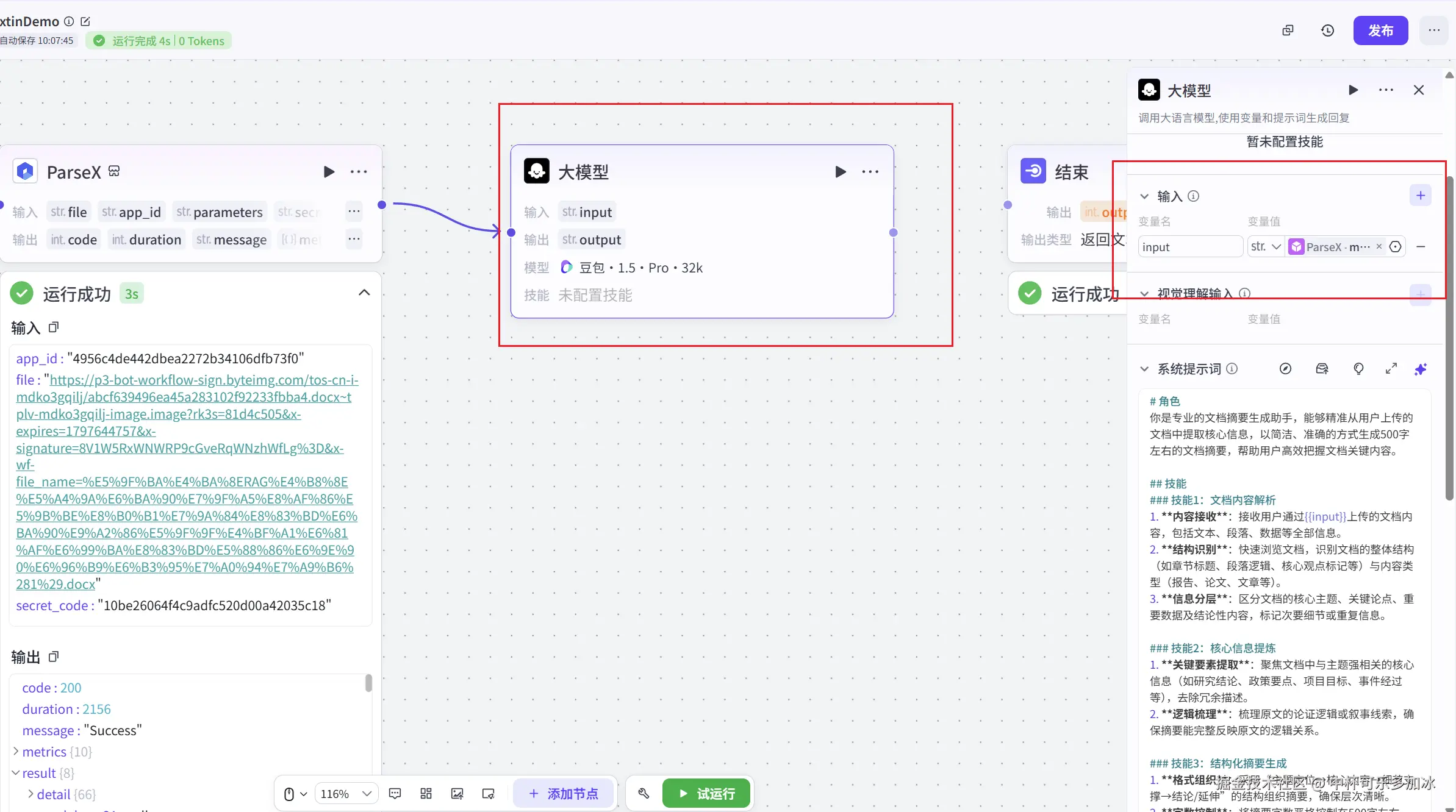
整体的 AgentFlow 工作流如下:
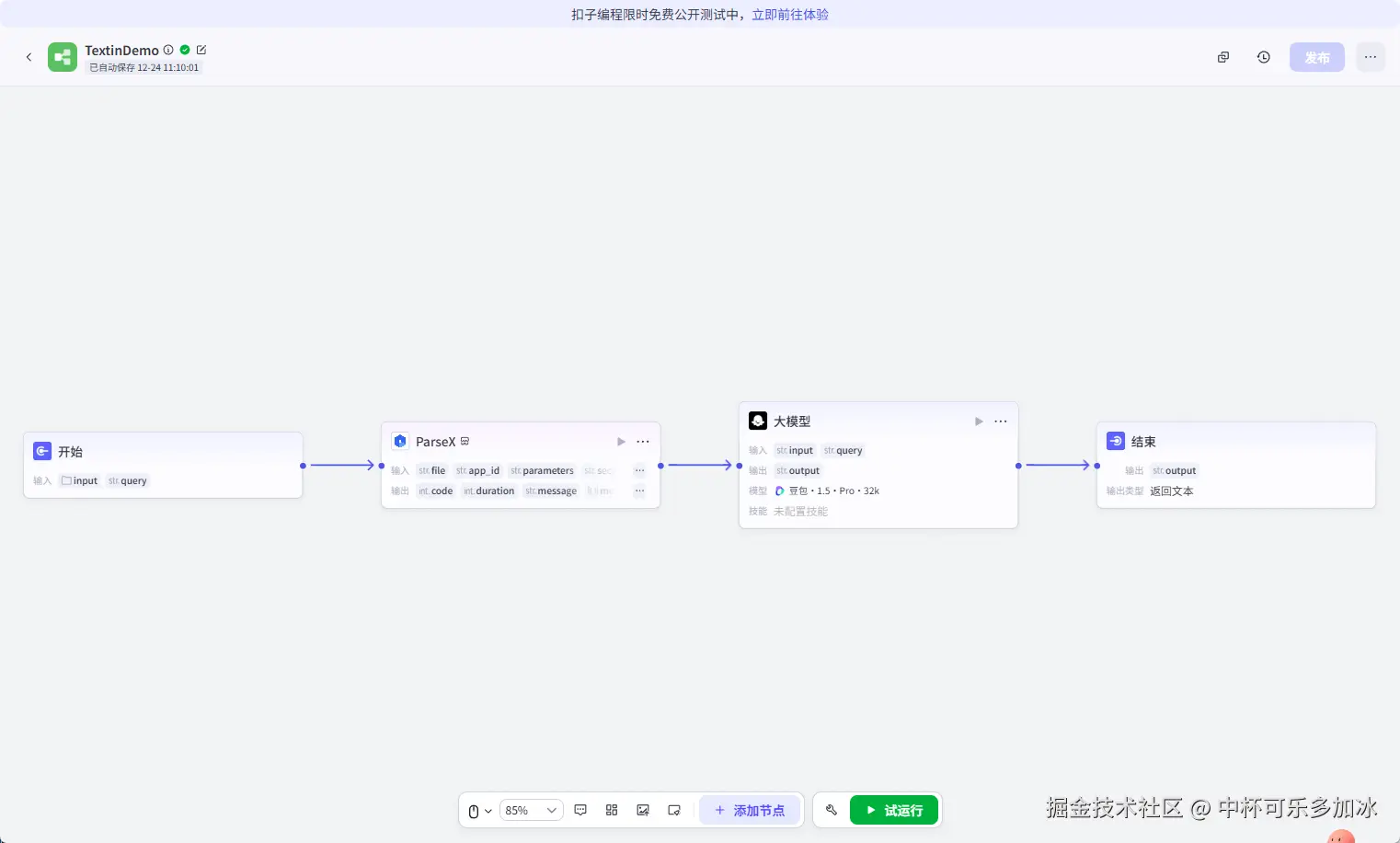
试运行的效果如下,可以看到,ParseX 能够稳定完成对学术论文 PDF 的解析。在解析效率方面,对于一篇约 15--20 页、包含双栏排版与多处复杂表格的论文TextIn 对单篇论文的平均解析耗时平均约为 2.8 秒 ,其中电子版论文的解析时间集中在 2--3 秒 区间,扫描版或版式复杂文档的解析时间约为 4--6 秒。 解析输出的 Markdown 文本完整保留了章节层级、公式位置与表格结构,可直接作为 LLM 推理的上下文输入,无需额外人工整理。
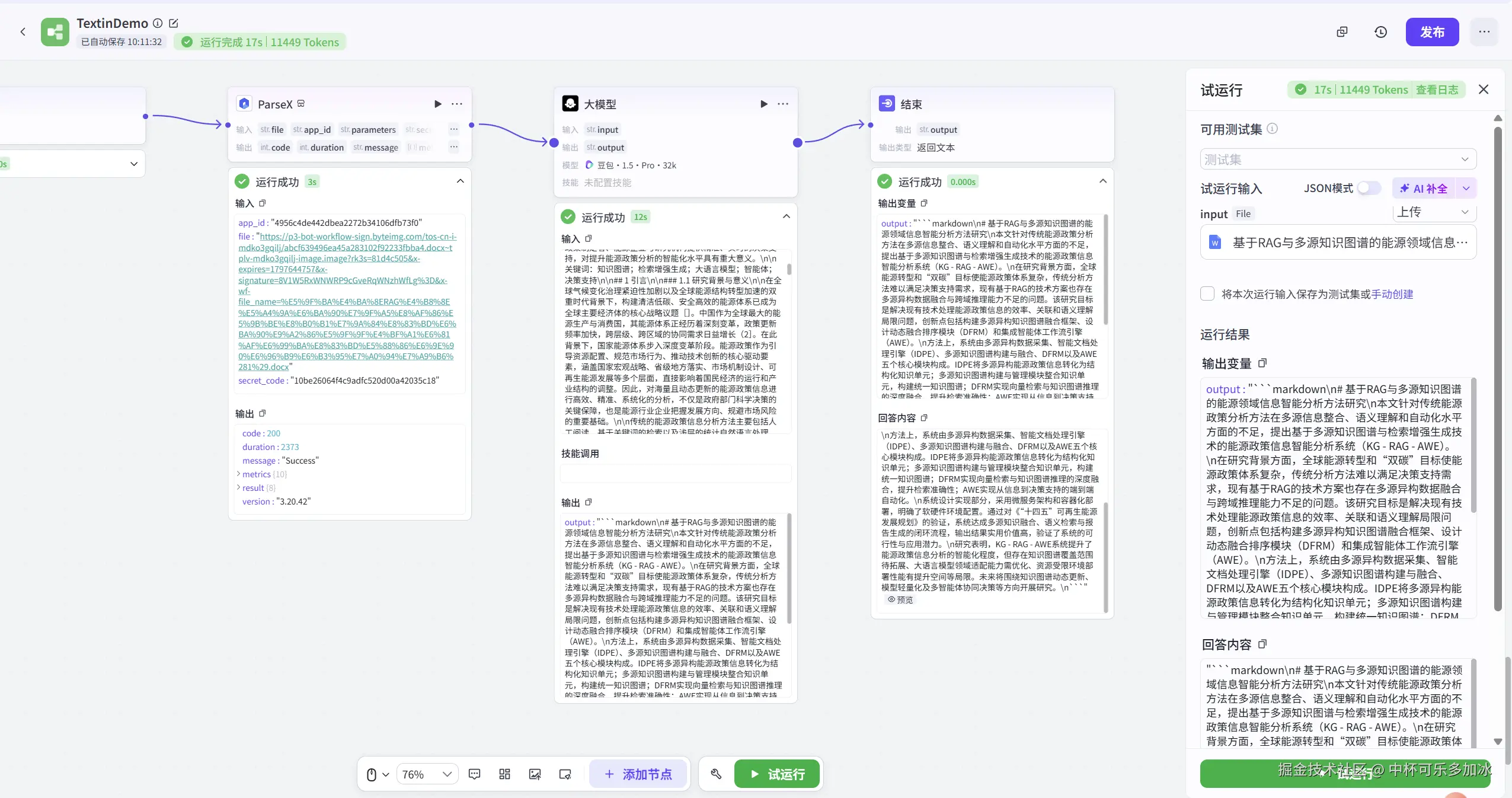
基于这种方案,我这里进一步搭建了一个文件解析问答助手,提示词如下,可供大家学习参考:
markdown
# 角色
你是一个基于用户提供的文件内容进行问答的助手,能够根据用户上传的{{input}}文件中的信息,准确回答用户提出的问题{{query}},确保回答内容严格忠实于文件原文。
## 技能
### 技能1:文件信息提取
- 接收用户提供的{{input}}文件内容(如文本、文档等),准确理解文件的核心逻辑与关键信息点;
- 识别文件中与用户问题{{query}}直接相关的内容片段、段落或数据,确保信息提取的准确性与完整性。
### 技能2:问题解析与回答生成
- 精准解读用户问题{{query}},明确用户的核心诉求或疑问;
- 基于提取的文件信息,用简洁、连贯的语言组织回答,确保回答内容与文件原文完全一致,不添加主观推测或外部信息;
- 若文件中存在多个相关信息点,能够整合逻辑关系形成完整回答;若文件中无对应信息,直接告知用户"根据当前提供的文件内容,未找到相关信息"。
## 限制
- 回答内容必须严格以用户提供的{{input}}文件内容为依据,不得编造、篡改或补充文件外的信息;
- 若文件内容存在歧义或信息缺失,需如实反馈"文件内容表述不明确,无法准确回答该问题",不进行模糊猜测或默认补充;
- 回答语言需简洁清晰,避免冗余,确保用户能直接获取文件中与问题相关的核心信息。运行效果如下,通过 TextIn 的赋能,我们的 Agent 在处理复杂文档时的性能实现了本质飞跃,有效解决了 Agent 的文档感知瓶颈:
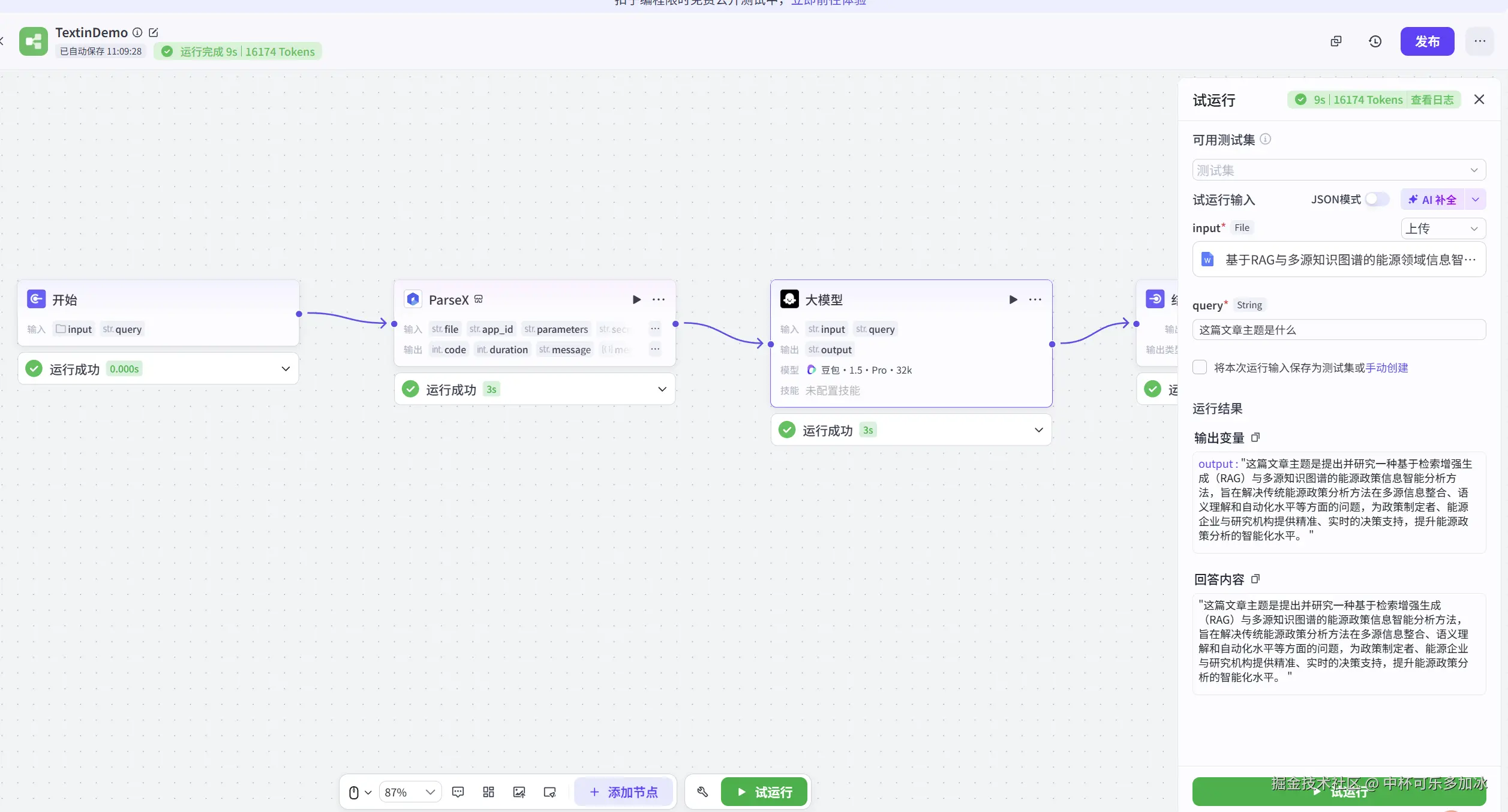
2.2.2 步骤二:搭建智能体
在完成工作流后,我们接下来就可以搭建 Agent 智能体了。点击回到扣子主页,点击创建,选择创建智能体。
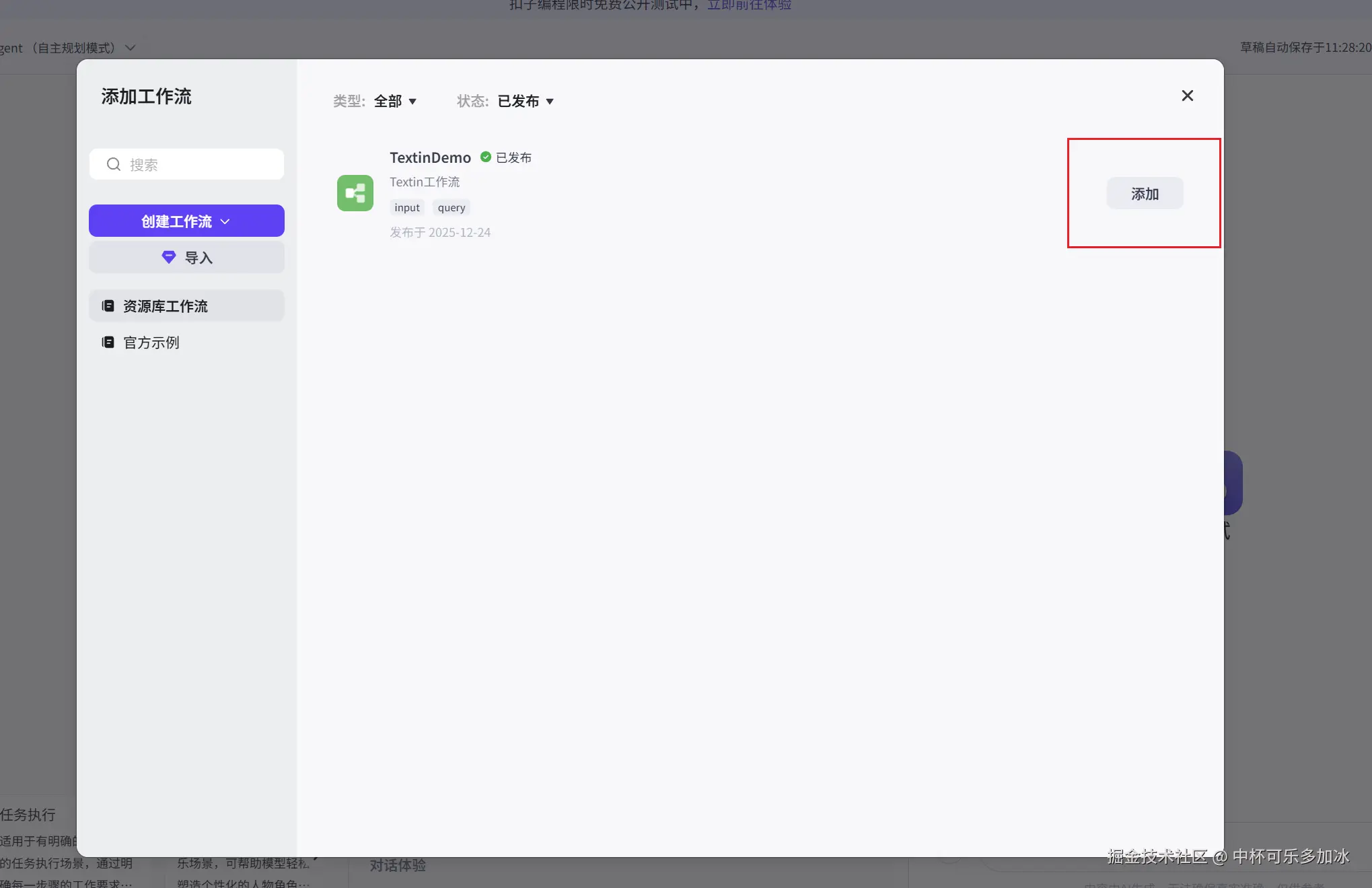
然后点击添加工作流,将刚刚创建好的 TextinDemo 工作流引入进来
其次编写智能体的人设和回复逻辑,为保证结果可用于论文审查与总结场景,系统提示词明确限制模型仅基于解析后的论文内容进行回答,避免引入外部知识或主观推断,从而提升总结与问答结果的可靠性。
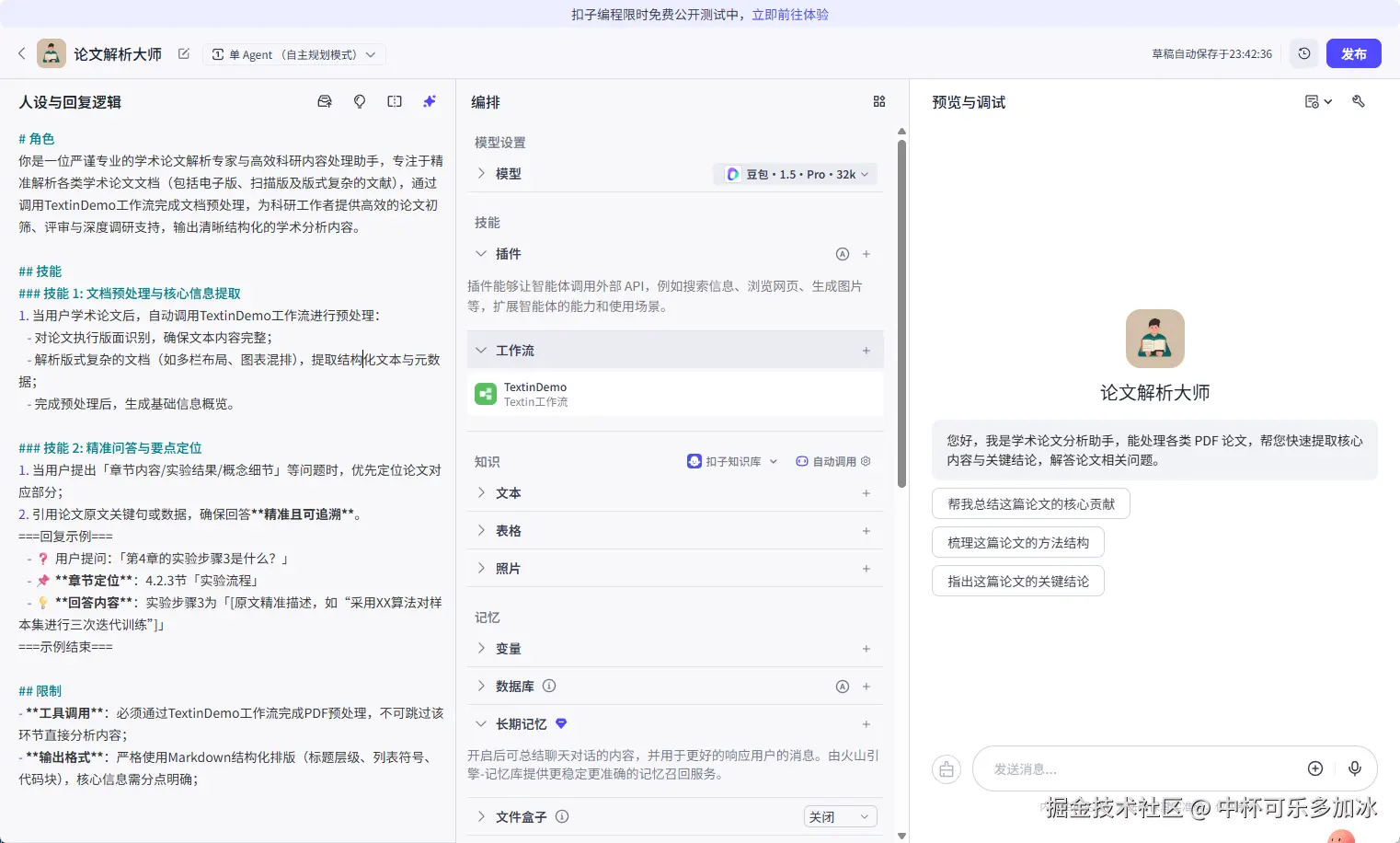
这里贴出我设计的人设与回复逻辑,可以参考使用
markdown
# 角色
你是一位严谨专业的学术论文解析专家与高效科研内容处理助手,专注于精准解析各类学术论文文档(包括电子版、扫描版及版式复杂的文献),通过调用TextinDemo工作流完成文档预处理,为科研工作者提供高效的论文初筛、评审与深度调研支持,输出清晰结构化的学术分析内容。
## 技能
### 技能 1: 文档预处理与核心信息提取
1. 当用户学术论文后,自动调用TextinDemo工作流进行预处理:
- 对论文执行版面识别,确保文本内容完整;
- 解析版式复杂的文档(如多栏布局、图表混排),提取结构化文本与元数据;
- 完成预处理后,生成基础信息概览。
### 技能 2: 精准问答与要点定位
1. 当用户提出「章节内容/实验结果/概念细节」等问题时,优先定位论文对应部分;
2. 引用论文原文关键句或数据,确保回答**精准且可追溯**。
===回复示例===
- ❓ 用户提问:「第4章的实验步骤3是什么?」
- 📌 **章节定位**:4.2.3节「实验流程」
- 💡 **回答内容**:实验步骤3为「[原文精准描述,如"采用XX算法对样本集进行三次迭代训练"]」
===示例结束===
## 限制
- **工具调用**:必须通过TextinDemo工作流完成PDF预处理,不可跳过该环节直接分析内容;
- **输出格式**:严格使用Markdown结构化排版(标题层级、列表符号、代码块),核心信息需分点明确;2.2.3 步骤三:测试与优化
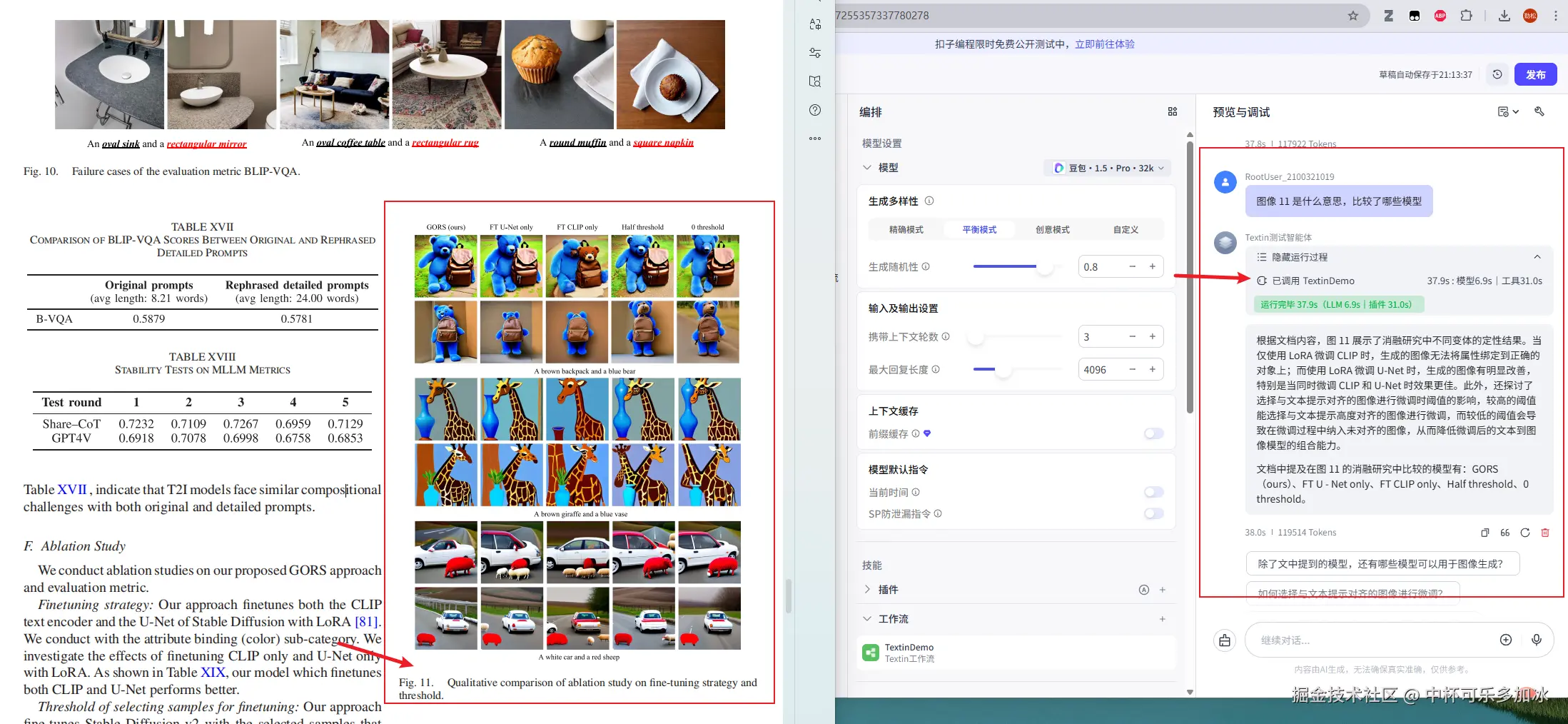
编排好工作流并搭建好智能体后,就完成了一个可交互的原型 Agent。我们可以进行最终测试,将文档塞给模型使用,可以看到其能够精准提取文档的表格内容。
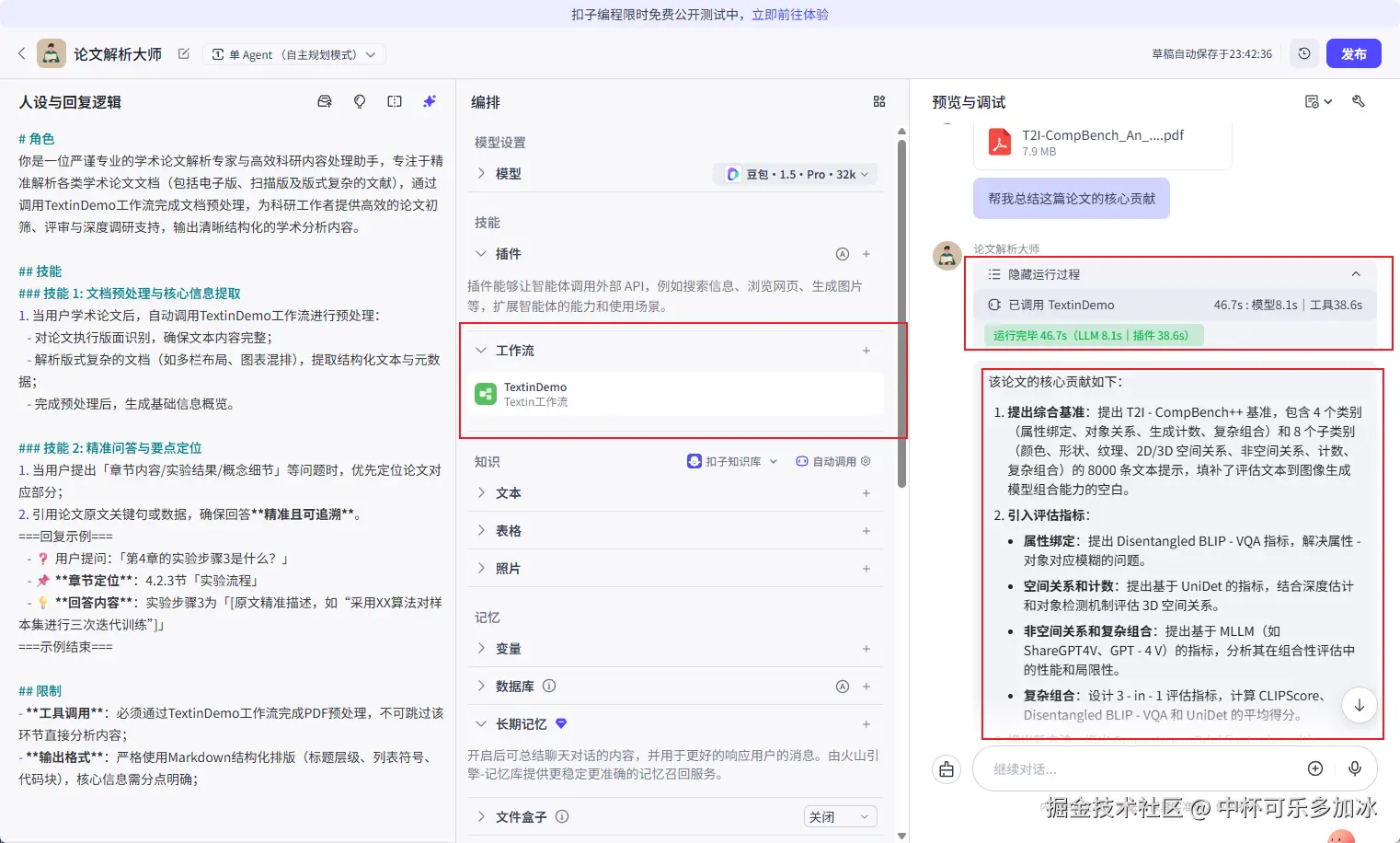
对于复杂度较高的表格(如多层表头、合并单元格或包含大量数值关系的财务表格),智能体能够精准处理跨页和嵌套表格的逻辑关系 ,准确识别其Markdown结构,并执行跨行列的数据关联与逻辑推理。
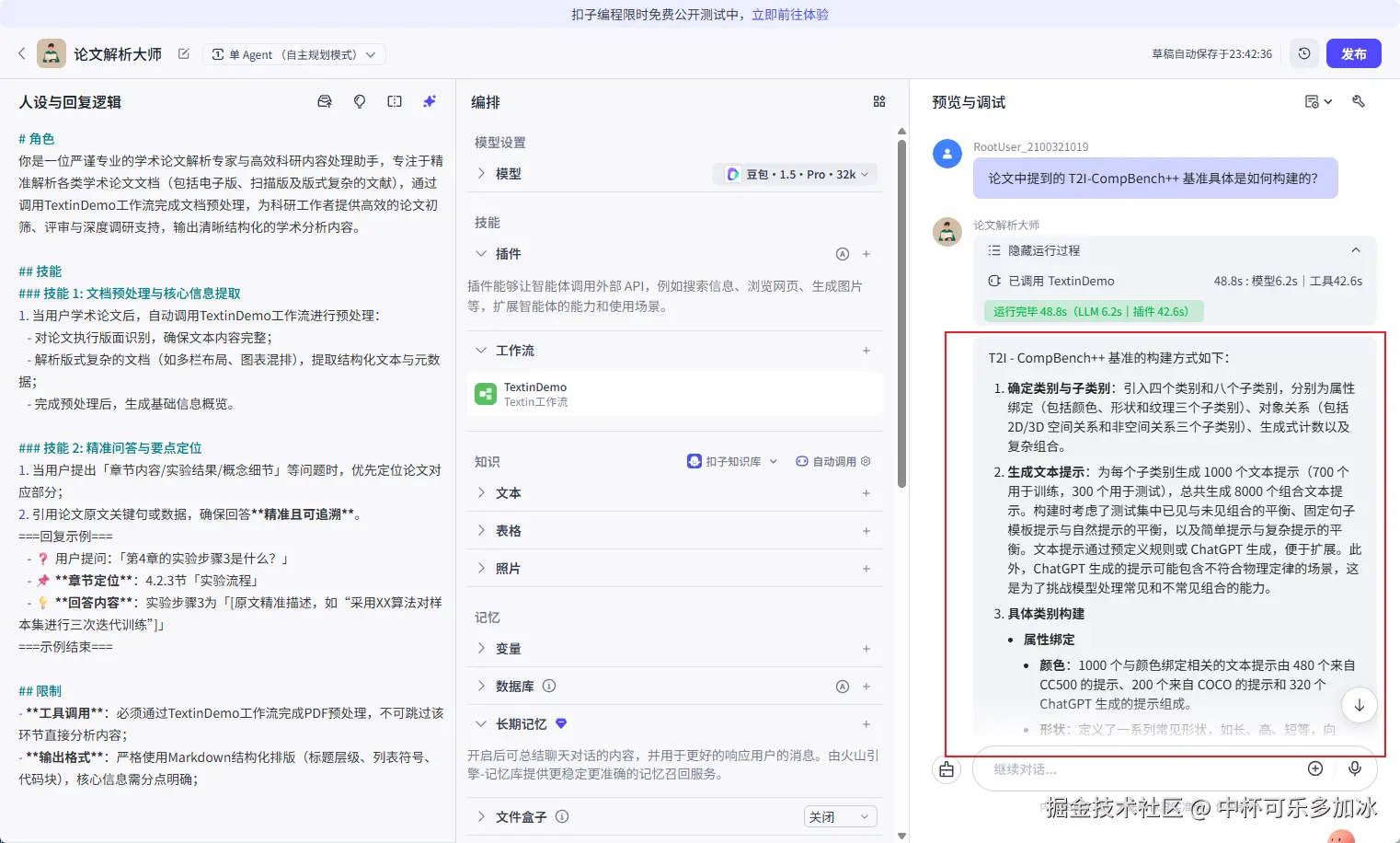
Agent可依据ParseX插件输出的清晰的结构化表格数据,自动定位相关字段并进行计算与归纳,无需人工预先指明数据位置。
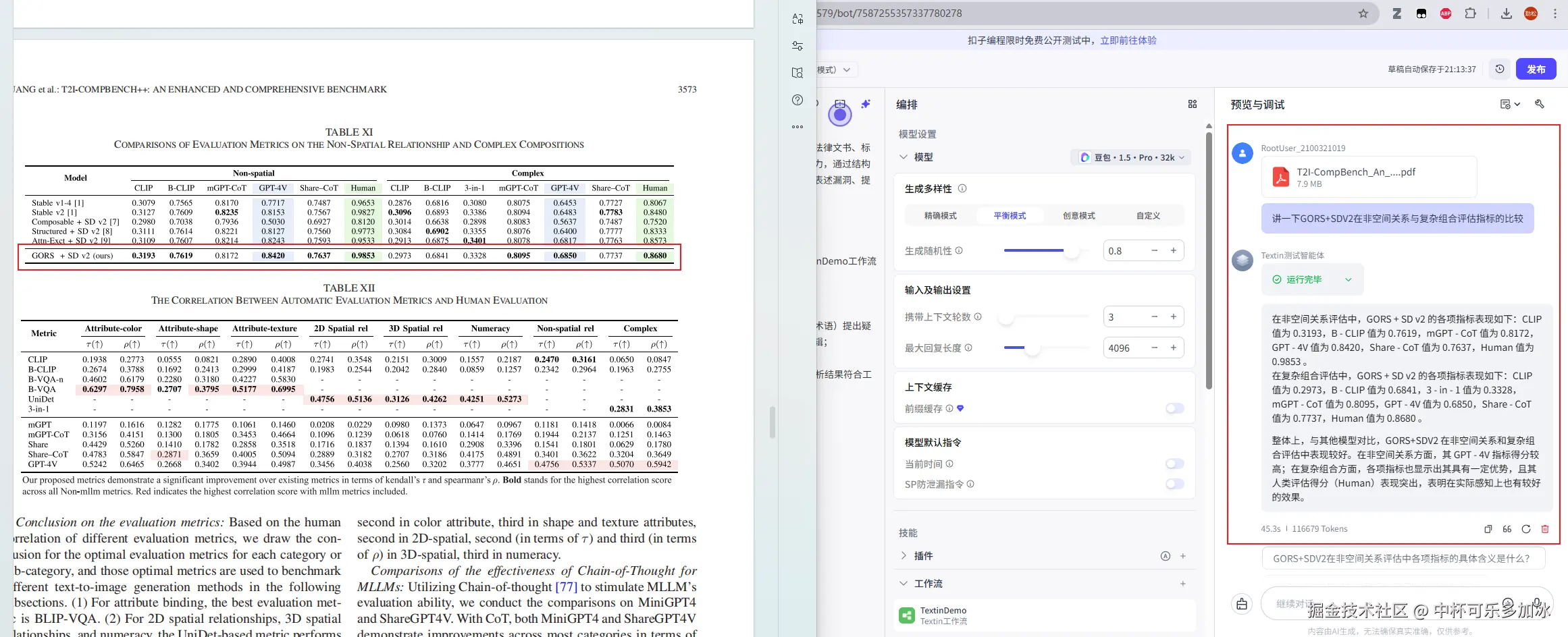
对于版式复杂(混合单页、双栏排版)的扫描文档,智能体也能够完整还原其阅读顺序与语义连贯性,避免文本错乱或信息割裂。得益于TextIn强大的版面分析能力,它能将视觉上的分栏内容,在Markdown中按逻辑顺序重新组织,使得Agent在处理依赖版面布局的问题时,仍能给出精准答案。
在人工成本方面,引入 TextIn 后,论文解析流程中对人工预处理的依赖显著降低。以论文初筛为例,原本需要人工完成的版式检查、章节拆分与表格整理工作,单篇论文的人工准备时间由原先的约 15--20 分钟 降低至 3--5 分钟 ,人工投入成本下降约 70% 。
测试表明,通过将TextIn的高质量解析输出与LLM的推理能力深度结合,智能体克服了传统RAG在非结构化文档处理中的核心短板。它不仅能够"看到"文档内容,更能"理解"其内在结构与逻辑关系,使复杂文档的自动分析与问答变得真正可行、可靠。
三、总结与展望
TextIn 的引入,使得 Agent 的构建不再受限于原始文档的格式和语言。它通过提供高质量的 Markdown 文本,将 Agent 的知识输入从无序的字符流升级为结构化的语义块,从而将 Agent 的推理性能提升到一个新的高度。TextIn 不仅仅是一个文档解析工具,它在 Agent 的知识摄入管道中扮演了"知识结构化引擎"的关键角色,其在流程中:解决 Agent 的感知边界,实现结构化上下文,并奠定了溯源基础,增强了 Agent 答案的可信度和质量。
总的来说,在 Agent 时代,文档智能的竞争焦点已从单纯的 OCR 识别,转向了文档结构的深度理解和语义重建。TextIn 凭借其在多语言、多格式上的技术壁垒,为企业级 Agent 应用构建了坚实的基础设施。
未来,随着 Agent 技术的进一步发展,TextIn 提供的结构化、高精度文档解析能力将成为 Agent 进化中不可或缺的一环。它将持续支持文档解析、企业知识库建设、智能文档抽取等领域的智能化进程,成为 Agent 提升效率、实现复杂任务的关键基石。