本系列介绍增强现代智能体系统可靠性的设计模式,以直观方式逐一介绍每个概念,拆解其目的,然后实现简单可行的版本,演示其如何融入现实世界的智能体系统。本系列一共 14 篇文章,这是第 2 篇。原文:Building the 14 Key Pillars of Agentic AI
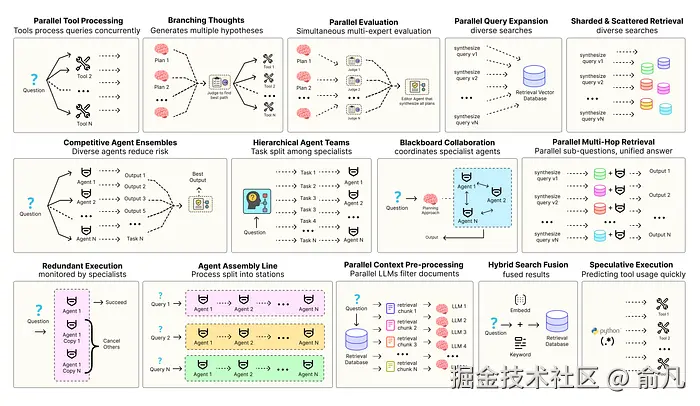
优化智能体解决方案需要软件工程确保组件协调、并行运行并与系统高效交互。例如预测执行,会尝试处理可预测查询以降低时延 ,或者进行冗余执行,即对同一智能体重复执行多次以防单点故障。其他增强现代智能体系统可靠性的模式包括:
- 并行工具:智能体同时执行独立 API 调用以隐藏 I/O 时延。
- 层级智能体:管理者将任务拆分为由执行智能体处理的小步骤。
- 竞争性智能体组合:多个智能体提出答案,系统选出最佳。
- 冗余执行:即两个或多个智能体解决同一任务以检测错误并提高可靠性。
- 并行检索和混合检索:多种检索策略协同运行以提升上下文质量。
- 多跳检索:智能体通过迭代检索步骤收集更深入、更相关的信息。
还有很多其他模式。
本系列将实现最常用智能体模式背后的基础概念,以直观方式逐一介绍每个概念,拆解其目的,然后实现简单可行的版本,演示其如何融入现实世界的智能体系统。
所有理论和代码都在 GitHub 仓库里:🤖 Agentic Parallelism: A Practical Guide 🚀
代码库组织如下:
erlang
agentic-parallelism/
├── 01_parallel_tool_use.ipynb
├── 02_parallel_hypothesis.ipynb
...
├── 06_competitive_agent_ensembles.ipynb
├── 07_agent_assembly_line.ipynb
├── 08_decentralized_blackboard.ipynb
...
├── 13_parallel_context_preprocessing.ipynb
└── 14_parallel_multi_hop_retrieval.ipynb从预生成到战略探索
在之前模式中,代理遵循单一线性思维路径,如果初始方法存在缺陷或不是最优,整个过程就会受到影响......
在复杂或富有创意的任务中,最先出现的点子往往不是最佳的,这是一个重大风险。
并发预生成(Parallel Hypothesis Generation) ,也称为分支思考(Branching Thoughts),是一种不对单一想法作出回应的结构性方法。
- 系统一开始就明确生成多种多样的策略或"假设",而不是单一线性推理。
- 然后并行探索所有路径,并为每条路径生成解。
- 最后评估竞争方案,选出最优方案。从而创造更稳健、更具创造力,且更不容易陷入次优路径的系统。
我们将构建一个多智能体系统,以应对创意营销任务。由 规划器(Planner) 、并发 执行器(Workers) 和 评估器(Judge) 组成,目标是展示最终输出相比单个代理能产出的明显有质的提升。
首先,为管理代理之间复杂的信息流,需要为输出定义结构化的双质模型,这是将多智能体系统粘合在一起的纽带。
python
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
class MarketingHypothesis(BaseModel):
"""A Pydantic model for a single, distinct marketing angle or strategy to explore."""
# 为这个角度取一个简短、朗朗上口的名字 (例如, 'The Tech Enthusiast')
angle_name: str = Field(description="A short, catchy name for the marketing angle (e.g., 'The Tech Enthusiast').")
# 对目标受众和核心信息的简明描述
description: str = Field(description="A one-sentence description of the target audience and core message for this angle.")
class Plan(BaseModel):
"""A Pydantic container for the Planner's output, holding multiple hypotheses."""
# 列表包含 3 种需要并行探索的营销假设
hypotheses: List[MarketingHypothesis] = Field(description="A list of exactly 3 distinct marketing hypotheses to explore in parallel.")
class Slogan(BaseModel):
"""A Pydantic model for the output of a single copywriting Worker."""
slogan: str = Field(description="The generated marketing slogan.")
class Evaluation(BaseModel):
"""A Pydantic model for the final, structured output of the Judge agent."""
# 一份比较所有生成口号的详细评估
critique: str = Field(description="A detailed critique of all slogans, explaining the pros and cons of each.")
# 评估器选出的最佳标语
best_slogan: str = Field(description="The single best slogan chosen from the list.")这些 Pydantic 模型是代理之间的正式"数据契约"。例如,Plan 类确保规划器代理始终输出一个 MarketingHypothesis 对象列表,Evaluation 类确保评估器不仅会提供一个致胜口号,还会提供详尽的 critique。
接下来定义 GraphState,这比之前的模式更复杂,需要跟踪初始计划以及多个并行工作分支的结果。
python
from typing import TypedDict, Annotated, List, Dict
import operator
class GraphState(TypedDict):
product_description: str
plan: List[MarketingHypothesis]
# 'worker_results' 是字典,键是角度名称,值是生成的口号
# 'operator.update' 归约函数告诉 LangGraph 从并行分支合并字典,而非替换
worker_results: Annotated[Dict[str, Slogan], operator.update]
final_evaluation: Evaluation
performance_log: Annotated[List[str], operator.add]最重要的部分是:worker_results: Annotated[Dict[str, Slogan], operator.update]。当并行工作节点完成时,每个节点会返回一个带有自身结果的小字典。operator.update 归约函数指示 LangGraph 将这些词典合并为最终状态下的综合 worker_results 对象,以确保数据不丢失。
接下来定义 规划器(Planner) 代理,它是图中的第一个节点。
python
def planner_node(state: GraphState):
"""The Planner node: generates the initial marketing plan with multiple, diverse hypotheses."""
print("--- AGENT: Planner is thinking... ---")
start_time = time.time()
# 创建一个链,将 planner_prompt 传递给 LLM,指示它输出一个 'Plan' 对象
planner_chain = planner_prompt | llm.with_structured_output(Plan)
plan = planner_chain.invoke({"product_description": state['product_description']})
execution_time = time.time() - start_time
log_entry = f"[Planner] Generated {len(plan.hypotheses)} hypotheses in {execution_time:.2f}s."
print(log_entry)
# 用假设列表和性能日志更新状态
return {"plan": plan.hypotheses, "performance_log": [log_entry]}planner_node 通过 LLM 将高层次的 product_description 分解为三个独立且可并行化的子任务(MarketingHypothesis 对象),这个初始的"扇出"步骤是整个图的基础。
接下来定义 执行器(Worker) 代理,该节点特殊之处在于会并行多次执行,每个由规划器生成的假设都会执行一次。
python
def worker_node(state: GraphState, config):
"""The Worker node: generates a slogan for a single, specific hypothesis. This node will be run in parallel for each hypothesis."""
# 'config' 对象是 LangGraph 的一个提供运行时信息的特殊参数
# 从 'configurable' 字典中检索执行器实例的特定假设
hypothesis = config["configurable"]["hypothesis"]
angle_name = hypothesis.angle_name
print(f"--- AGENT: Worker for '{angle_name}' is thinking... ---")
start_time = time.time()
# 为这个执行器创建链
worker_chain = worker_prompt | llm.with_structured_output(Slogan)
result = worker_chain.invoke({
"product_description": state['product_description'],
"angle_name": angle_name,
"description": hypothesis.description
})
execution_time = time.time() - start_time
log_entry = f"[Worker-{angle_name}] Generated slogan in {execution_time:.2f}s."
print(log_entry)
# 输出是字典,键是角度名称,
# 允许 'operator.update' 归约函数正确合并所有并行工作的结果
return {
"worker_results": {angle_name: result},
"performance_log": [log_entry]
}worker_node 是复写器(copywriter),不会从主 state 读取,相反从 config 对象那里接收 hypothesis。这就是 LangGraph 将唯一输入传递给同一节点的并行执行的方式,使每个执行器能够专注于其分配的问题切片。
现在我们需要一个作为条件边的函数,把任务分配给并行执行器。
python
from langgraph.graph.graph import Send
def scatter_to_workers(state: GraphState) -> List[Send]:
"""A special edge function that scatters the plan to the parallel workers."""
print("--- ORCHESTRATOR: Scattering tasks to workers --- ")
# 函数返回 'Send' 对象列表
# 每个 'Send' 对象都是图的一条指令,通过 'config' 参数传递特定输入,
# 将任务分派给特定节点('worker')。
tasks = [
Send(
"worker",
config={"configurable": {"hypothesis": hypothesis}}
)
for hypothesis in state['plan']
]
return tasksscatter_to_workers 函数是动态并行的核心,它不是标准节点,而是用作条件边的函数。从状态读取 plan,并程序化的构建 Send 对象列表。每个 Send 都是 LangGraph 命令,用于调用具有唯一配置的 worker 节点。当条件边返回此类 Send 对象列表时,LangGraph 理解必须并行执行所有对象。
最后,评估器(Judge) 代理负责收集并评估所有执行器的结果。
python
def judge_node(state: GraphState):
"""The Judge node: evaluates all worker results, provides a critique, and selects the single best one."""
print("--- AGENT: Judge is evaluating... ---")
start_time = time.time()
# 将并行工作结果格式化为单个字符串,以供评估器提示
slogans_to_evaluate = ""
for angle, slogan_obj in state['worker_results'].items():
slogans_to_evaluate += f"Angle: {angle}\nSlogan: {slogan_obj.slogan}\n\n"
# 构建评估器链
judge_chain = judge_prompt | llm.with_structured_output(Evaluation)
evaluation = judge_chain.invoke({
"product_description": state['product_description'],
"slogans_to_evaluate": slogans_to_evaluate
})
execution_time = time.time() - start_time
log_entry = f"[Judge] Evaluated {len(state['worker_results'])} slogans in {execution_time:.2f}s."
print(log_entry)
# 在状态里更新最终结果
return {"final_evaluation": evaluation, "performance_log": [log_entry]}judge_node 是"扇入"或聚合,负责读取 worker_results 词典并综合结果,执行最后的关键推理步骤,即比较竞争观点并做出合理决策,最终产出整个系统的高质量输出。
定义好所有节点和边后,可以组装并编译最终的图。
python
from langgraph.graph import StateGraph, END
# 用定义的状态初始化一个新的图
workflow = StateGraph(GraphState)
# 添加代表代理的节点
workflow.add_node("planner", planner_node)
workflow.add_node("worker", worker_node)
workflow.add_node("judge", judge_node)
# 工作流入口点是规划器
workflow.set_entry_point("planner")
# 在规划器之后,用特殊的 'scatter_to_workers' 函数作为条件边来扇出工作
workflow.add_conditional_edges("planner", scatter_to_workers)
# 当所有执行器节点完成后,结果将自动聚合,
# 定义一个静态边来扇入到评估器中
workflow.add_edge("worker", "judge")
# 评估是图结束前的最后一步
workflow.add_edge("judge", END)
# 将图编译为可执行应用程序
app = workflow.compile()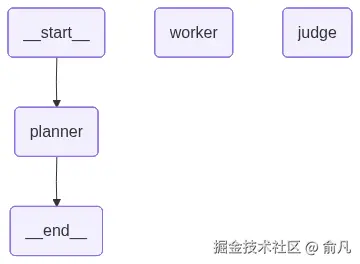
现在进行最终定量证明,分析性能日志,看看并行执行的好处。
python
total_time = 0
planner_time = 0
worker_times = []
judge_time = 0
# 解析性能日志以提取每个阶段的时间
for log in final_state['performance_log']:
time_val = float(log.split(' ')[-1].replace('s', ''))
if "[Planner]" in log:
planner_time = time_val
elif "[Worker-" in log:
worker_times.append(time_val)
elif "[Judge]" in log:
judge_time = time_val
# 并行步骤的总时间是运行时间最长的任务的时间
parallel_worker_time = max(worker_times) if worker_times else 0
# 整个工作流的总时间
total_execution_time = planner_time + parallel_worker_time + judge_time
print(f"Total Execution Time: {total_execution_time:.2f} seconds\n")
print("Breakdown:")
print(f" - Planner: {planner_time:.2f} seconds")
print(f" - Parallel Workers (longest path): {parallel_worker_time:.2f} seconds")
print(f" - Judge: {judge_time:.2f} seconds\n")
# 现在模拟在顺序工作流程中会发生什么
sequential_worker_time = sum(worker_times)
time_saved = sequential_worker_time - parallel_worker_time这就是现在看到的......
python
#### 输出 ####
============================================================
PERFORMANCE ANALYSIS
============================================================
Total Execution Time: 19.24 seconds
Breakdown:
- Planner: 6.78 seconds
- Parallel Workers (longest path): 5.31 seconds
- Judge: 7.15 seconds三个执行器分别用了 5.31s、5.12s 和 4.98s。如果按顺序执行,该阶段将耗时 15.41s(5.31 + 5.12 + 4.98)。
通过并行执行,该阶段时间仅为 5.31s(即最长执行器时间)。
这为这一步骤节省了超过 10s 的时间。
更重要的是,最终产出质量更好。系统不仅生成了口号,而且探索了由三种不同策略定义的空间,然后通过另一个推理步骤选择最佳策略。
Hi,我是俞凡,一名兼具技术深度与管理视野的技术管理者。曾就职于 Motorola,现任职于 Mavenir,多年带领技术团队,聚焦后端架构与云原生,持续关注 AI 等前沿方向,也关注人的成长,笃信持续学习的力量。在这里,我会分享技术实践与思考。欢迎关注公众号「DeepNoMind」,星标不迷路。也欢迎访问独立站 www.DeepNoMind.com,一起交流成长。