介绍
今天,我们正式宣布:AutoMQ BYOC(Bring Your Own Cloud)正式上线 Connector 托管能力。
AutoMQ 作为基于 S3 构建的新一代 Diskless Kafka,已经在存储层实现了计算存储分离与 Zero Cross-AZ(零跨可用区)复制,大幅降低了云上 Kafka 的 TCO。随着 Connector 托管能力的引入,我们进一步降低了数据集成场景的准入门槛:在 AWS 等公有云上,你现在可以在一个统一的控制面中,以极简的方式构建从数据采集(Connect)到流存储(AutoMQ)的数据管道。通过产品层面的深度集成,我们把构建生产级 CDC 链路的复杂度从"专家级"降低到了"入门级"。
挑战:CDC 链路中的"流量刺客"与配置壁垒
在云原生架构中,Kafka Connect 是连接数据库与 Kafka 的关键桥梁。特别是在高吞吐的 CDC(Change Data Capture)场景下,用户往往面临着两个核心挑战,导致成本与运维压力居高不下:
难以规避的跨 AZ 流量"隐形税"
AutoMQ 通过基于 S3 的共享存储架构,可以在服务端层面完全消除客户端写入 AutoMQ 时的跨 AZ 流量费用。但要真正做到"端到端 Zero Cross-AZ",通常还要求**客户端(例如 Kafka Connect Connector)**具备一定的可用区感知能力或遵循特定的路由策略。现实情况是,在传统自建 Connector 模式下,Worker 节点往往用默认配置直接启动,对服务端的网络拓扑一无所知。结果就是:即便 AutoMQ 侧已经为本地写入做好了架构准备,这些"蒙眼狂奔"的 Connector 仍可能把 TB 级别的 CDC 流量写到其他 AZ 的 Broker,产生大量跨 AZ 传输(Regional Data Transfer)费用,把 Diskless 架构在存储层带来的优势抵消掉。

自管理 Connector 成本高昂
在传统模式下,要把 Connector 调到既稳定又省钱,本质上是一整套高门槛的"自助运维套餐":
- 配置上的精细活:你得啃完一堆文档,手动配置 Rack Awareness,按 AZ 划分 Bootstrap 地址,权衡要不要开压缩、到底用哪种压缩算法;
- 集群和基础设施运维:还要自己拉起并维护 Connect 集群,在 K8s 里部署、配置 VPC/安全组、接好监控告警,预估并处理扩缩容和升级带来的各种影响;
- 隐藏成本和不可见风险:即便前面所有步骤都做对了,细节上也很容易翻车------只要有一个 client 参数漏配或配错,就可能让本应利用 AutoMQ 架构优势实现的 Zero Cross‑AZ 能力彻底失效,跨 AZ 流量又悄悄回到老路子上,直到月底账单出来才发现被多收了一大笔钱。
正是因为自管 Connector 充满这种看不见、摸不着但真金白银买单的复杂度,很多团队才开始认真评估:是不是应该把这部分彻底交给一个 Fully Managed 的平台来做。
深度集成:把复杂留给平台,把简单留给用户
AutoMQ 托管 Connector 的核心价值,在于利用统一控制面(Unified Control Plane)的上下文优势,实现了 Connector 与 AutoMQ 集群的深度绑定与自动化适配。
我们通过产品设计,将"如何正确连接 AutoMQ"这一复杂问题,在平台侧通过自动化手段解决:
上下文感知的配置注入
在 AutoMQ 控制台中,托管 Connector 天然知道它所连接的 AutoMQ 集群的一切信息(接入点、认证方式、版本特性等)。 当用户创建 Connector 时,系统会自动生成并注入适配 AutoMQ 最佳实践的 Client Configuration 。无论是基础的连接参数,还是适配 AutoMQ Zero Cross-AZ 特性所需的特殊配置,平台都会在后台自动完成。 这意味着,用户不需要理解底层的参数细节,Connector 启动即处于"最佳状态"。
统一网络环境的无缝连接
托管 Connector 部署在与 AutoMQ 集群相同的 VPC 环境中。平台自动处理了网络连通性配置(Connectivity),用户无需在复杂的 VPC Peering、Secuity Group 规则中周旋。只要在同一个环境,就能天然连通,安全且高效。
一站式全生命周期管理
我们将 Connector 的创建、配置、监控和日志查询全部收敛到了 AutoMQ 控制台。这不仅仅是 UI 的整合,更是运维流的打通。用户可以在一个页面闭环解决所有问题,大幅降低了构建和维护 CDC 链路的隐形成本。
产品体验:四步向导,一屏掌控
我们将复杂的集成逻辑封装为标准化的四步向导,让 CDC 链路的搭建回归业务本质。
1. 通用设置:自动化的环境适配
这是集成的起点。用户只需选择目标 AutoMQ 实例和 Kubernetes 集群,系统会自动锁定正确的网络上下文和 IAM 角色。"选择即适配",复杂的连接参数配置在后台自动完成。
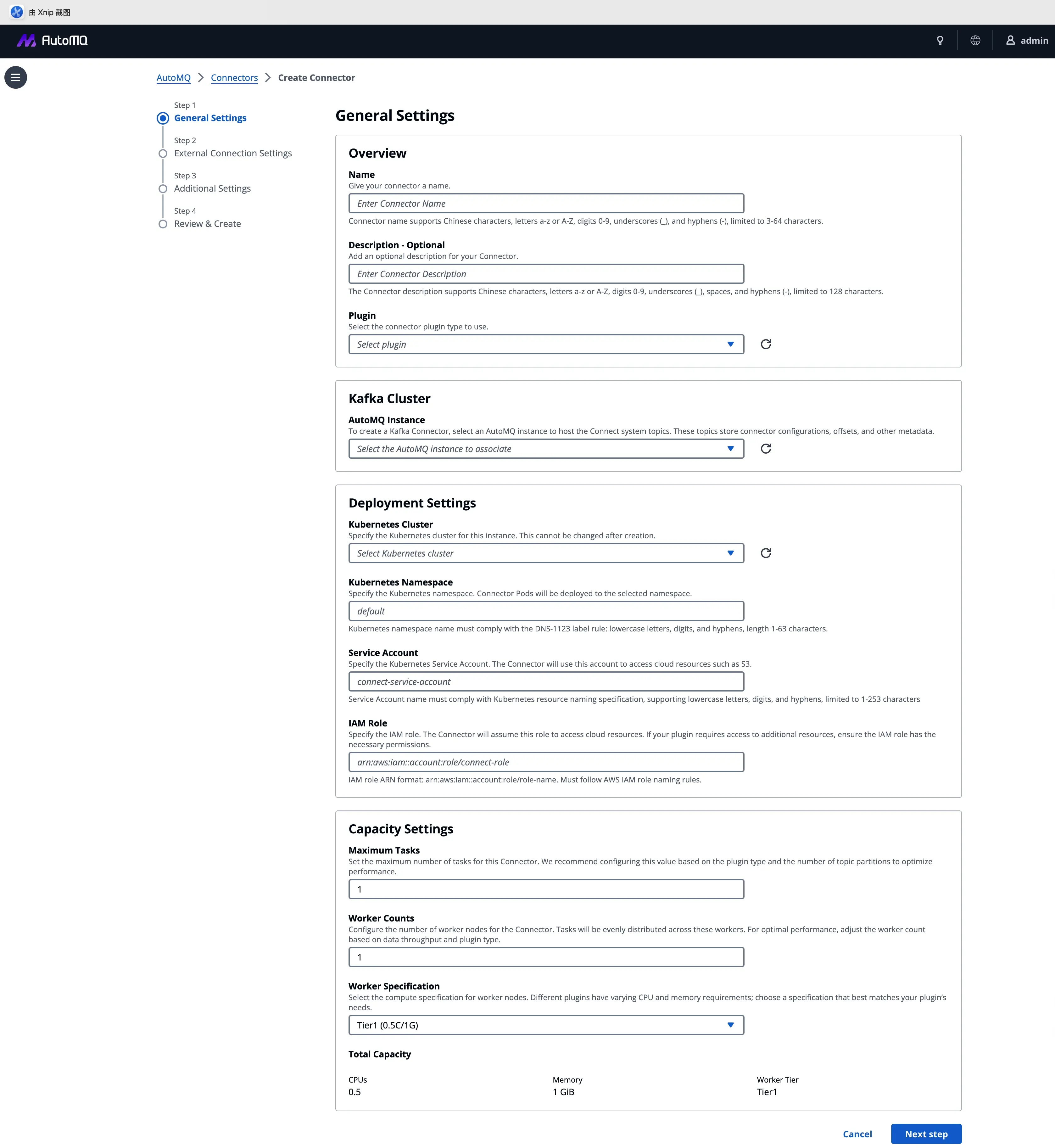
2. 连接配置:兼容性与易用性的平衡
支持标准的 Kafka Connect 插件生态,并系统内置了 Debezium 等 CDC 插件,针对不同的用户习惯,我们提供了灵活的配置模式:
- 表单模式:针对 S3 Sink 等标准化插件,参数可视化,减少配置错误。
- 自定义模式:针对 Debezium 等复杂场景,支持直接粘贴 JSON/Properties,确保存量业务的平滑迁移。
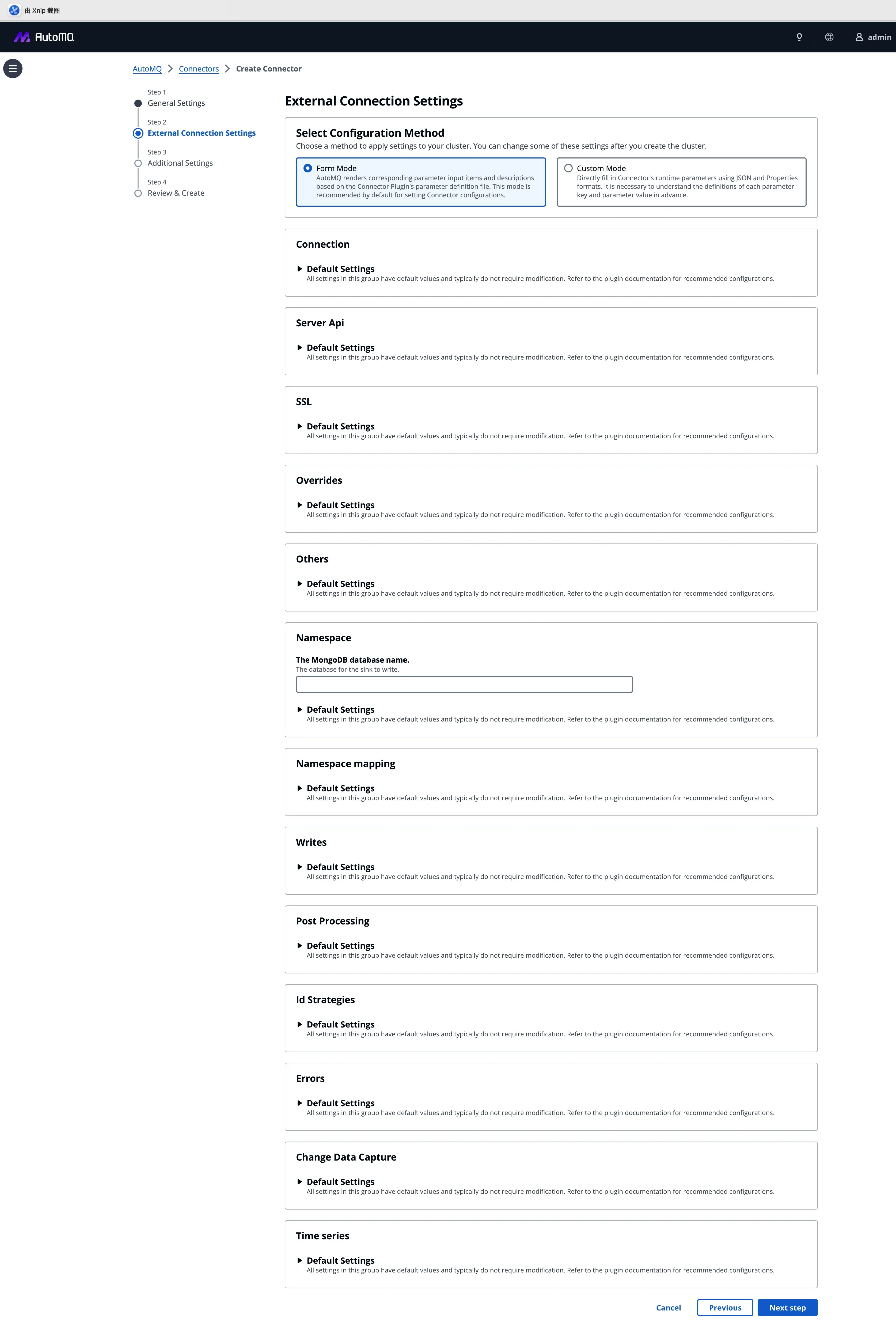
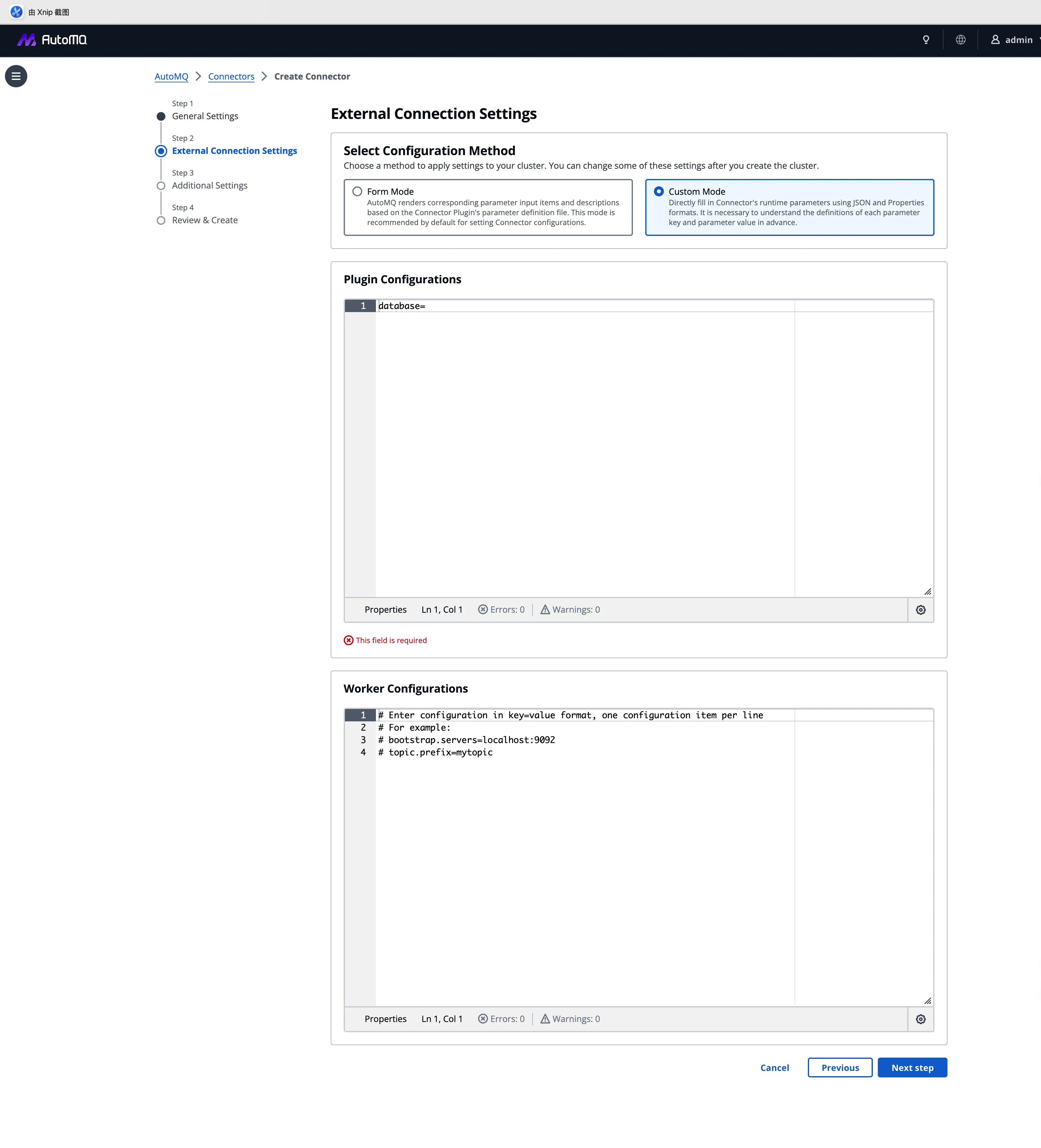
3. 可观测性:打破数据孤岛
在"额外设置"中,我们内置了标准化的可观测性集成。通过勾选 Remote Write,Connector 的监控指标可直接对接到 Prometheus/Grafana 体系,无需额外部署 Exporter,彻底告别黑盒运维。
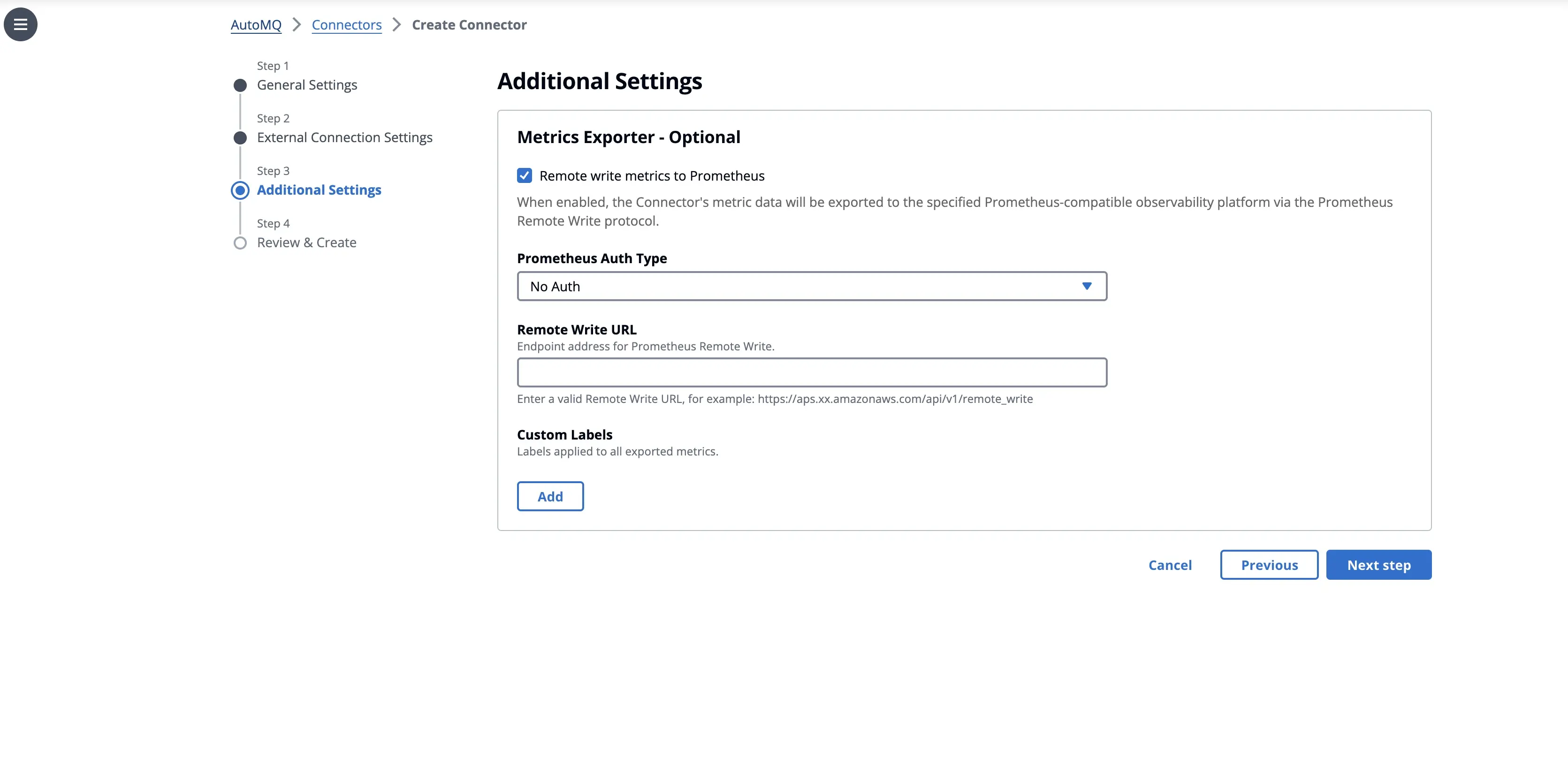
4. 部署与运维:全程可视
提交后,AutoMQ 接管全流程部署。部署完成后,用户获得的是一个具备深度的运维仪表盘。
- 实时吞吐监控:
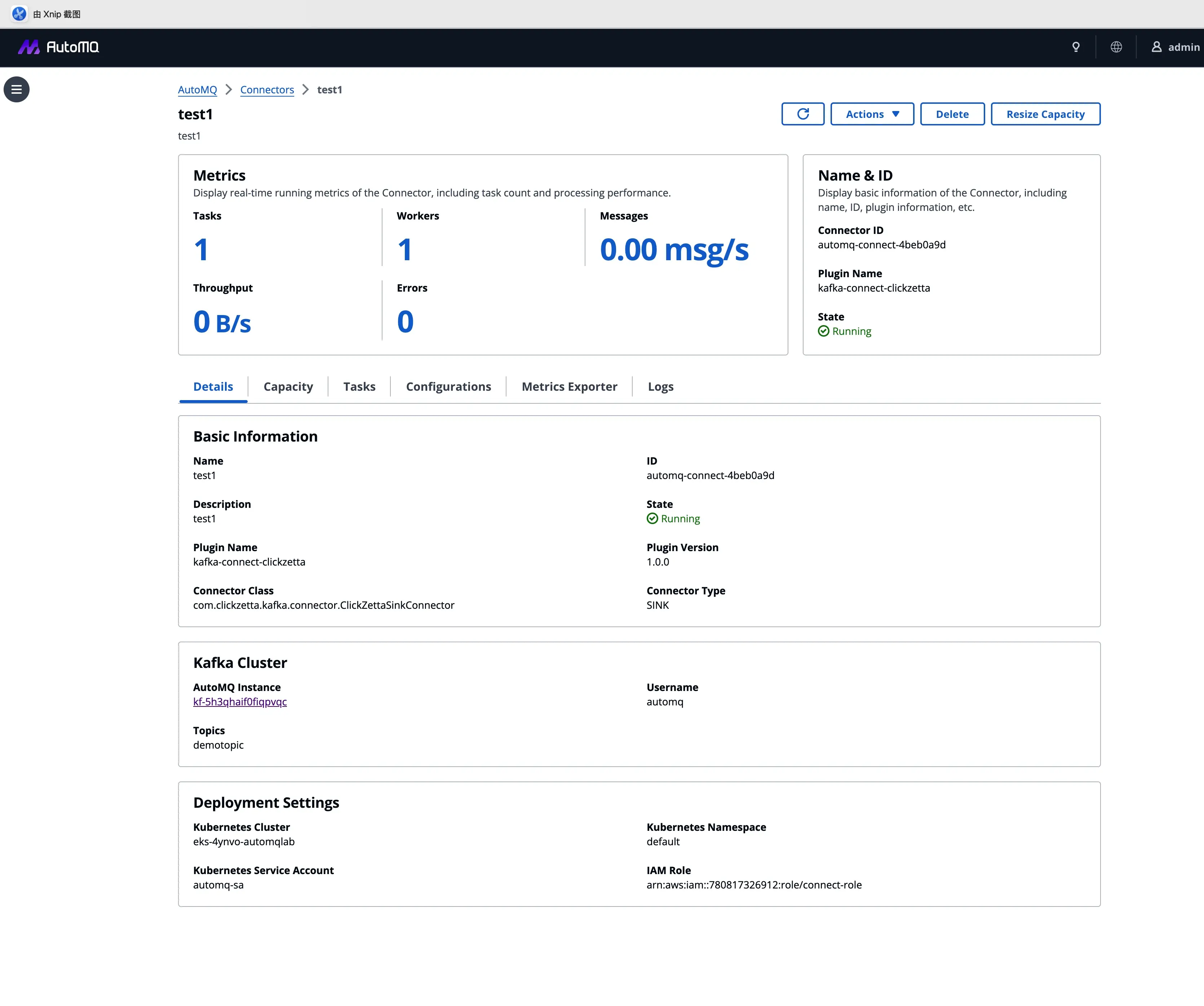
- 日志聚合查询:无需登录 K8s,直接在控制台聚合查询所有 Worker 日志,快速定位业务异常。
总结
AutoMQ Connector 托管能力的上线,标志着 AutoMQ 从单一的流存储引擎向完整的云原生流数据平台迈出了关键一步。
通过将 Connector 与 AutoMQ 集群进行产品级强绑定,我们实现了:
- 极简的 CDC 链路构建:无需关心繁琐的 Client 参数与网络配置,四步向导即可拉起生产级链路。
- 默认的最佳实践:通过自动化的配置注入,天然适配 AutoMQ 的核心特性(如 Zero Cross-AZ),消除配置错误带来的隐患。
- 统一的治理体验:从 Broker 到 Connector,在同一控制台内实现全栈闭环管理。
如果你正在寻找一个能够快速落地、且运维成本极低的数据集成方案,欢迎参考我们的官方文档,在 AutoMQ BYOC 环境中体验这一新特性。
💡 开源 AutoMQ 正在 Github Trending 中,欢迎关注:
👇 AutoMQ 商业版当前提供 2 周免费试用,欢迎试用: