引言
Iceberg 是 Netflix(美国网飞)公司为了解决数据存储和计算引擎之间的适配的问题(即 Hive 在云上的痛点)开发的,2018年11月16日进入Apache孵化器,2020 年5月19日从孵化器毕业,成为 Apache 的顶级项目。
Hudi 是 Uber(美国优步)公司为了解决传统批处理模型在近实时场景下的局限性问题(即实时增量更新需求)开发的,2019年1月,Uber 将 Hudi 捐赠给 Apache 软件基金会,推动其成为开源项目;后续版本持续增强功能,如2021年引入对Spark 3.0的支持,2022年加强Flink集成,2023年至2024年优化查询性能和云原生支持。
所以,Iceberg 和 Hudi 开源时间都差不多。
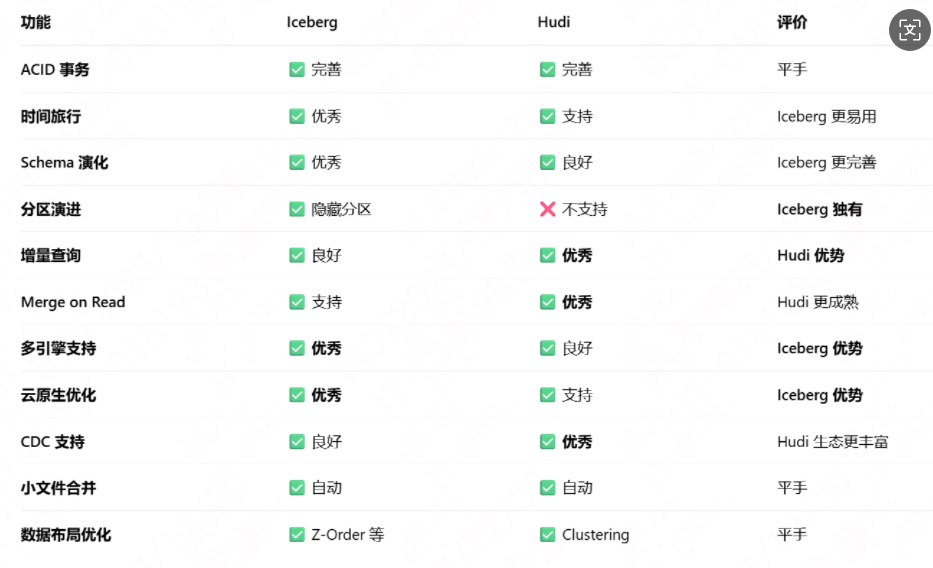
功能对比表
2024 年行业采用现状
- Iceberg: ★ 4.2k+ stars, 1.6k+ forks, 300+ contributors
- Hudi: ★ 3.9k+ stars, 1.8k+ forks, 400+ contributors
从Github 的关注度上看,目前 Iceberg 略高;但是由于 Hudi 社区更早,其贡献者更多。从发展趋势看,Iceberg 增长曲线更陡峭。
云厂商支持情况
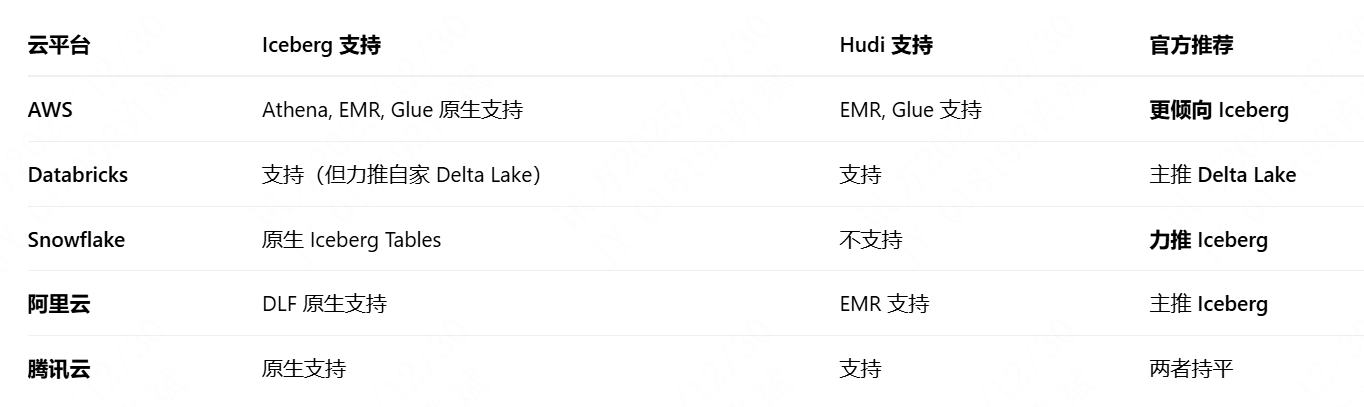
可以看到,阿里云主推 Iceberg,而腾讯云两者都支持。
这里少了华为云,华为云支持 Hudi和 Iceberg,但华为云的湖仓一体架构是以 Hudi 为基础,应该是主推 Hudi。
大厂选择
明确选择 Iceberg 为主力:
- 字节跳动: 全面 Iceberg,构建实时数仓
- 美团: 核心业务迁移到 Iceberg
- Netflix: 亲儿子,内部大规模使用
- Apple: 数据湖基于 Iceberg
- LinkedIn: 新项目以 Iceberg 为主
- Snowflake: Iceberg Tables 核心战略
Hudi 主导或两者并用:
- Uber: 亲儿子,核心业务用 Hudi
- 腾讯: 内部两者都有,微信支付用 Hudi
- 阿里云: 对外推广 Iceberg,内部部分业务用 Hudi
- 字节: 少量业务用 Hudi
- 小米: 早期用 Hudi,部分迁移到 Iceberg
自研或混合:
- 阿里: 内部有 MaxCompute+自研格式,对外推 Iceberg
- 腾讯: 内部有 TDW,同时支持两者
- Databricks: 力推 Delta Lake
Iceberg 和 Hudi 到底选谁
选 Iceberg
- 新项目/新团队:从零开始构建数据湖
- 多引擎环境:需要被 Spark、Flink、Trino、Snowflake 等同时访问
- 云原生优先:主要使用云对象存储(S3/OSS)
- 标准化要求:需要开放、标准的表格式
- 时间旅行重要:合规、审计、数据回滚是强需求
选 Hudi
- 存量 Hudi 项目:已有成熟 Hudi 体系
- Spark 为主:技术栈深度绑定 Spark
- CDC 场景:高频 upsert/delete 操作
- 点查性能敏感:需要内置索引优化
- Uber 技术栈:跟随 Uber 技术选型
除了 Iceberg 和 Hudi 之外,还有一个 Delta Lake。 由于 Delta Lake 的贡献者以 Databricks 及国外公司为主,国内企业参与度相对较低,导致其在国内社区支持和问题响应上存在短板。2024 年 Delta Lake项目经历了重要变化,它被捐赠给 Linux 基金会并加入 Apache 孵化器,但截至 2025年12月,尚未成为Apache顶级项目。
总结
Iceberg 和 Hudi 的初衷场景并不完全相同,造成了在设计上的差别。 因此后面是趋同还筑起各自专长优势壁垒未可知。
Hudi跟Spark的代码深度绑定,尤其是写入路径。其设计之初,基本上把Spark作为他们的默认计算引擎了。
而 Apache Iceberg 的方向非常坚定,宗旨就是要做一个通用化设计的Table Format。它完美的解耦了计算引擎和底下的存储系统,便于多样化计算引擎和文件格式,很好的完成了数据湖架构中的Table Format。这一层的实现,因此也更容易 成为Table Format层的开源事实标准。
另一方面,Apache Iceberg 也在朝着流批一体的数据存储层发展,manifest和snapshot的设计,有效地隔离不同transaction的变更 ,非常方便批处理和增量计算。并且,Apache Flink已经是一个流批一体的计算引擎,二都可以完美匹配,合力打造流批一体的数据湖架构。
最后,Apache Iceberg这个项目背后的社区资源非常丰富。在国外,Netflix、Apple、Linkedin、Adobe等公司都有PB级别的生产数据运行在Apache Iceberg上;在国内,腾讯这样的巨头也有非常庞大的数据跑在Apache Iceberg之上,最大的业务每天有几十T的增量数据写入。
最终结论:Iceberg 正在成为更主流的、通用性更强的数据湖表格式标准,但 Hudi 在实时流式处理和 CDC 场景仍有其独特优势。 对于大多数企业,从未来扩展性、生态完整性和社区趋势来看,Iceberg 是更安全的选择。