Kubernetes 可观测性实战:解构 Prometheus + Grafana 企业级监控架构
目录
[Kubernetes 可观测性实战:解构 Prometheus + Grafana 企业级监控架构](#Kubernetes 可观测性实战:解构 Prometheus + Grafana 企业级监控架构)
[1.1 核心概念解析:监控 vs 可观测性](#1.1 核心概念解析:监控 vs 可观测性)
[1.2 Prometheus 的设计哲学:为什么是 Pull 模式?](#1.2 Prometheus 的设计哲学:为什么是 Pull 模式?)
[1.3 整体架构蓝图](#1.3 整体架构蓝图)
[第二部分:Prometheus 数据模型与核心原理解析](#第二部分:Prometheus 数据模型与核心原理解析)
[2.1 指标的四大天王](#2.1 指标的四大天王)
[2.2 PromQL 查询语言实战](#2.2 PromQL 查询语言实战)
[第三部分:Kubernetes 环境下的自动化采集(Operator 模式)](#第三部分:Kubernetes 环境下的自动化采集(Operator 模式))
[3.1 Prometheus Operator 与 CRD](#3.1 Prometheus Operator 与 CRD)
[3.2 实战演示:配置 ServiceMonitor](#3.2 实战演示:配置 ServiceMonitor)
[第四部分:Grafana 可视化与高效看板构建](#第四部分:Grafana 可视化与高效看板构建)
[4.1 数据源与变量](#4.1 数据源与变量)
[4.2 核心看板复刻](#4.2 核心看板复刻)
[第五部分:告警治理与 Alertmanager 路由策略](#第五部分:告警治理与 Alertmanager 路由策略)
[5.1 告警的生命周期](#5.1 告警的生命周期)
[5.2 告警分组与抑制](#5.2 告警分组与抑制)
[6.1 单点 Prometheus 的局限性](#6.1 单点 Prometheus 的局限性)
[6.2 解决方案选型:Thanos vs VictoriaMetrics](#6.2 解决方案选型:Thanos vs VictoriaMetrics)
[方案 A:Thanos(生态标准)](#方案 A:Thanos(生态标准))
[方案 B:VictoriaMetrics(性能怪兽)](#方案 B:VictoriaMetrics(性能怪兽))
[6.3 性能优化 Tuning](#6.3 性能优化 Tuning)
第一部分:从监控到可观测性------理念演进与架构选型
【专栏正文】
在云原生时代,传统的"监控"概念已经不足以应对复杂的分布式系统。当应用从单体架构拆分为微服务,再部署到随时可能发生扩缩容的 Kubernetes 集群中时,我们需要一种全新的视角来看待系统的状态。这就是"可观测性"。
1.1 核心概念解析:监控 vs 可观测性
很多工程师容易混淆"监控"和"可观测性"。简单来说,监控是"知其然",而可观测性是"知其所以然"。
- 监控:通常指我们预先设定好一组阈值或检查项,系统定期汇报状态。例如:"CPU 使用率超过 90% 就报警"。这是一种基于"已知问题"的被动防御。
- 可观测性:通过系统外部输出的数据,推断系统内部运行状态的能力。它不仅仅是报警,更是为了在未知故障发生时,能够通过数据分析快速定位根因。
云原生领域的可观测性通常由三大支柱构成:
- Metrics(指标):数值型的聚合数据(如 QPS、内存使用率)。适合用于告警和趋势分析。这是 Prometheus 最擅长的领域。
- Logs(日志):离散的事件记录(如 Error Stacktrace)。适合用于排查具体的错误细节。
- Tracing(链路追踪):请求在微服务间流转的路径(如一次 HTTP 请求经过了哪些服务、耗时多少)。适合用于性能分析和依赖梳理。
在本专栏中,我们将重点聚焦于Metrics 指标体系的建设。
1.2 Prometheus 的设计哲学:为什么是 Pull 模式?
在监控系统领域,存在两种流派:Pull(拉) 和 Push(推)。
- Push 模式(如 Graphite):应用主动将数据发送到监控服务端。
- Pull 模式(如 Prometheus):监控服务端主动去目标应用拉取数据。
Prometheus 为什么坚定地选择 Pull 模式?这与其诞生的环境(Kubernetes)密不可分:
- 简化服务发现:在 K8s 中,Pod 的 IP 是时刻变动的。如果是 Push 模式,应用需要知道监控服务端的地址,且配置变更极其复杂。而在 Pull 模式下,Prometheus 只需要调用 Kubernetes API,就能动态获取所有需要监控的 Pod 列表,无需重启服务。
- 全局视角的掌控:由监控端决定抓取频率和超时时间,可以更好地控制整体负载,防止被监控应用洪峰般的数据打垮。
- 目标健康度自检:如果某个目标挂了,Prometheus 在尝试 Pull 时会立刻感知到;而如果是 Push 模式,服务端很难区分是"应用挂了"还是"应用只是没数据发送"。
当然,Prometheus 也支持通过 Pushgateway 适配短生命周期的任务,但这只是为了兼容性,并非核心设计。
1.3 整体架构蓝图
构建一个企业级的 Prometheus + Grafana 监控体系,实际上是在构建一个数据流水线。让我们通过架构图来理解核心组件的交互。
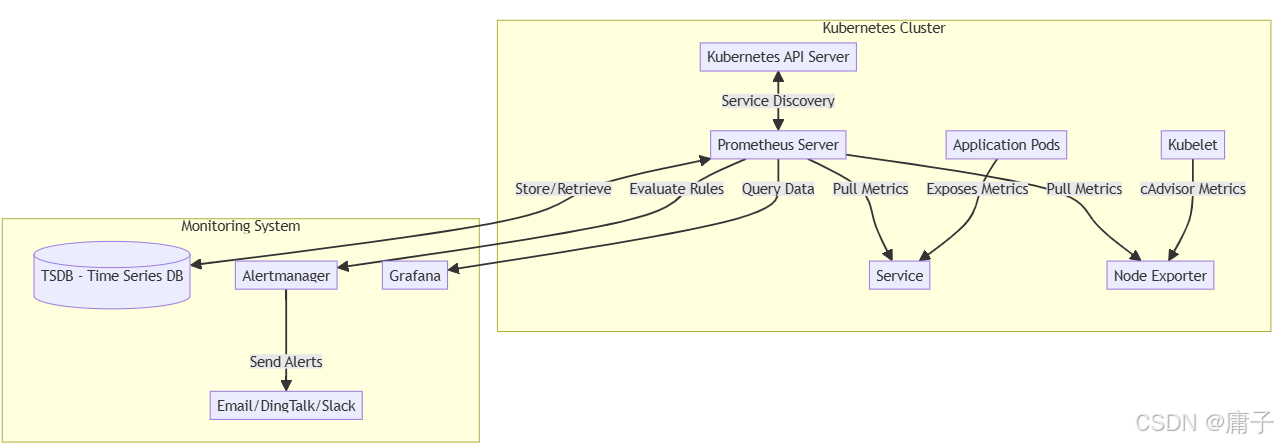
核心组件职责:
- Prometheus Server:核心大脑。负责定期去拉取数据、计算规则、存储数据。它是系统的"心脏"。
- Service Discovery:服务发现模块。在 K8s 中,它主要对接 API Server,根据 Label Selector 自动找到需要监控的 Pod。
- TSDB (Time Series Database):时序数据库。Prometheus 内置的高效存储引擎,按时间序列存储指标数据。
- Exporter (如 Node Exporter):"翻译官"。很多应用(如 Nginx、MySQL)原生不支持 Prometheus 格式,Exporter 负责收集它们的指标并转化为 Prometheus 能理解的格式。
- Alertmanager:告警分发器。它不负责判断是否告警(这是 Prometheus 的事),它负责将告警进行去重、分组、抑制,然后路由给接收人。
- Grafana:可视化大屏。它只是一个"画家",从 Prometheus 拿数据,画出漂亮的图表。
【架构师手记】
- 为什么很多公司上了监控却"看不懂"系统?
新手往往喜欢直接复制粘贴现成的 Grafana 仪表盘,上面密密麻麻几百个图表。但在故障发生时,这反而是一种灾难。
- 架构师视角:监控的核心不在于"大而全",而在于"与 SLO(服务等级目标)对齐"。你应该问自己:用户最关心什么?通常是"延迟"、"错误率"和"吞吐量"(RED 方法)。先保证这三个核心指标清晰可见,再去关注 CPU 和内存这些基础设施指标。
- 关于 Pull 模式的"坑"与解法
虽然 Pull 模式在 K8s 中是王道,但跨机房监控时要注意。
- 避坑指南:不要让 Prometheus 跨公网去拉取数据,这不仅慢,而且不安全。对于跨云或混合云环境,通常采用 "联邦" 或者部署多个 Prometheus 实例,再通过 Thanos 等方案进行数据汇聚。
- 别让 Pushgateway 成为"黑洞"
- 实战经验:我看到很多团队把 Pushgateway 当成常态监控方案,让业务代码通过 SDK 推送数据。这是极其错误的! Pushgateway 只是一个中转缓冲,它不会保留过期数据。如果 Pushgateway 挂了,你的数据就丢了;更重要的是,Prometheus 从 Pushgateway 拉取时,看到的永远是你 Pushgateway 的机器,而不是真实的业务实例,这会导致你无法感知具体的实例宕机。
- 建议:90% 的场景下,请坚持使用 Exporter + Pull 模式。
第二部分:Prometheus 数据模型与核心原理解析
【专栏正文】
要精通 Prometheus,仅仅会搭建环境是不够的,必须深刻理解其数据模型和查询语言。这是从"使用者"迈向"专家"的分水岭。
2.1 指标的四大天王
Prometheus 中的所有指标都是时间序列,每个序列由指标名称和标签唯一标识。根据业务场景的不同,我们将指标分为以下四大类型:
- Counter(计数器)
- 特性:单调递增,只增不减。
- 场景:记录 HTTP 请求总数、订单成交数量。
- 注意:如果你需要记录"当前用户数"(因为用户会下线),Counter 就不适用了。
- 示例 :
http_requests_total{method="GET", path="/api"}
- Gauge(仪表盘)
- 特性:可增可减,反映当前状态。
- 场景:内存使用率、CPU 使用率、当前线程数、队列长度。
- 示例 :
node_memory_MemAvailable_bytes
- Histogram(直方图)
- 特性:在客户端(或服务端)将数据分桶统计。它会生成三个序列:
_bucket(小于等于该桶边界的次数)、_sum(样本总和)、_count(样本总数)。 - 场景:分析请求延迟分布(如 P95、P99 延迟)。
- 示例 :
http_request_duration_seconds_bucket{le="0.1"}
- 特性:在客户端(或服务端)将数据分桶统计。它会生成三个序列:
- Summary(摘要)
- 特性:在客户端计算分位数(φ-quantiles),直接输出如
0.95分位的延迟值。 - 场景:虽然用起来简单,但不可聚合(无法计算两个实例的平均 P99)。
- 建议:在现代云原生架构中,优先使用 Histogram,放弃 Summary。
- 特性:在客户端计算分位数(φ-quantiles),直接输出如
2.2 PromQL 查询语言实战
PromQL 是 Prometheus 的灵魂,它允许你对时序数据进行切片、聚合和计算。
- 基础查询:直接查询指标名。
# 查询所有节点的内存可用量
node_memory_MemAvailable_bytes- 标签过滤:使用
{}匹配特定标签。
# 查询特定实例的 CPU 使用率
rate(node_cpu_seconds_total{mode="idle"}[5m])- 核心函数:rate() vs irate()
rate[5m]:计算过去 5 分钟内的平均增长率。优点:平滑曲线,适合长期趋势分析。irate[5m]:计算过去 5 分钟内最后两个样本点的瞬时增长率。优点:灵敏,适合告警。- *实战建议*:告警用
irate,看板用rate。
- 聚合操作:sum() by ()
- 这是最常用的组合,用于将分散的数据聚合。
# 计算每个 Pod 的 CPU 使用量
sum(rate(container_cpu_usage_seconds_total{image!=""}[5m])) by (pod)【架构师手记】
- Histogram vs Summary 的终极选择
- 新手陷阱:很多开发者喜欢用 Summary,因为它直接给出了
0.95的数值,画图很方便。但是,当你有 1000 个微服务实例时,Summary 无法告诉你"整个集群的 P95 延迟是多少"。因为数学上,平均值的 P95 不等于 P95 的平均值。 - 架构师决策:在分布式系统中,强制使用 Histogram。虽然它会让查询语句稍微复杂一点(需要用
histogram_quantile()函数),但它赋予了我们在服务端任意计算分位数的能力。
- 关于 Rate 的"5分钟黄金法则"
- 避坑指南:在使用
rate()或increase()计算 Counter 类指标时,采集间隔必须大于等于抓取间隔。如果你设置了scrape_interval=15s,却在rate[10s]中计算,你会得到锯齿状甚至缺失的数据。 - 最佳实践:为了保证数据的准确性和平滑度,推荐在 Grafana 面板和告警规则中,至少使用
rate[4m]或rate[5m]。
第三部分:Kubernetes 环境下的自动化采集(Operator 模式)
【专栏正文】
在 Kubernetes 动态的环境中,手动编写 Prometheus 的 targets 配置文件是极其痛苦的。Pod 的 IP 会变,副本数会变,服务名也会变。我们需要一套机制,让 Prometheus 能够"感知" K8s 的变化。这就是 Prometheus Operator 的用武之地。
3.1 Prometheus Operator 与 CRD
Prometheus Operator 是 CoreOS 开源的一个项目,它引入了 Kubernetes 的自定义资源定义(CRD),将监控资源的声明变成了 K8s 的 YAML 文件。
它主要引入了以下核心 CRD:
- Prometheus:声明式地定义 Prometheus 部署实例。
- ServiceMonitor:定义 Prometheus 应该监控哪些 Service。这是最常用的对象。
- PodMonitor:直接定义监控哪些 Pod(适用于没有 Service 的场景)。
- AlertmanagerConfig:定义告警路由配置。
- PrometheusRule:定义告警规则和记录规则。
3.2 实战演示:配置 ServiceMonitor
假设你部署了一个名为 my-app 的应用,该应用通过 Service 暴露了 /metrics 接口。
第一步:给 Service 打标签
Prometheus Operator 通过标签匹配来发现目标。
apiVersion: v1
kind: Service
metadata:
name: my-app-service
namespace: production
labels:
# 关键标签:用于 ServiceMonitor 匹配
app: my-app
spec:
selector:
app: my-app
ports:
- name: http-metrics
port: 8080
targetPort: 8080第二步:创建 ServiceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: my-app-monitor
namespace: production # 通常与业务在同一命名空间,或在监控命名空间
labels:
release: prometheus # 这个标签必须与 Prometheus CRD 中的 serviceMonitorSelector 匹配
spec:
selector:
matchLabels:
app: my-app # 选择第一步中创建的 Service
endpoints:
- port: http-metrics # 对应 Service 中定义的 port name
path: /metrics
interval: 30s # 覆盖全局抓取间隔一旦你应用这个 YAML,Prometheus Operator 会自动检测到变更,更新 Prometheus 的配置文件,并触发 Prometheus 热加载,开始抓取数据。
【架构师手记】
- Label 标签匹配的"死循环"
- 踩坑经验:很多新手配置了 ServiceMonitor 却发现 Prometheus 没有抓取数据,90% 的原因是标签不匹配。
- 排错逻辑:
- 检查 Prometheus CRD 的
serviceMonitorSelector是否包含了 ServiceMonitor 的标签(如release: prometheus)。 - 检查 ServiceMonitor 的
selector.matchLabels是否匹配了 Service 的 Label。 - 如果 Prometheus 和 Service 在不同的 Namespace,务必检查 ServiceMonitor 是否开启了
namespaceSelector(默认只监测同命名空间)。
- 检查 Prometheus CRD 的
- 不要过度抓取
- 性能考量:不要为所有的 Pod 都创建 ServiceMonitor。对于 Kubernetes 自身组件和核心业务,采集频率可以是 15s 或 30s;对于边缘应用或日志型应用,采集频率可以降到 60s 甚至更久,以节省 Prometheus 的存储和计算资源。
第四部分:Grafana 可视化与高效看板构建
【专栏正文】
数据收集好了,如果看不懂,那就毫无价值。Grafana 是目前云原生领域事实标准的可视化工具。
4.1 数据源与变量
在 Grafana 中添加 Prometheus 数据源非常简单。但要想构建一个"高级"仪表盘,必须善用变量。
变量实战:
不要为每个环境创建一个 Dashboard。使用变量(如 $namespace 或 $pod)让一个 Dashboard 适配所有环境。
- 定义变量 :Query:
label_values(kube_pod_info, namespace)。 - 使用变量 :在 PromQL 查询中替换:
rate(container_cpu_usage_seconds_total{namespace="$namespace"}[5m])。
4.2 核心看板复刻
一个标准的集群监控 Dashboard 应该包含以下关键面板:
- 集群健康度:
- CPU/Memory 总使用率 vs 总分配量(Requests/Limits)。这是容量规划的基础。
- 集群节点状态。
- Pod 性能:
- CPU 使用率。
- 内存使用率(注意区分 Cache 和 Working Set)。
- 网络流量(TX/RX)。
- K8s 核心组件:
- Kubelet、API Server、Etcd 的请求延迟和错误率。
【架构师手记】
- 颜色的心理学
- 避坑指南:很多新手喜欢把"高 CPU 使用率"标红,把"低 CPU 使用率"标绿。但在生产运维中,低 CPU 使用率(资源浪费)往往也是红色的(成本浪费)。
- 架构师建议:对于 Gauge 类面板,颜色使用"蓝-黄-红"渐变,或者简单的单色。不要滥用红色报警,Grafana 是用来观察趋势的,Alertmanager 才是用来报警的。
- Working Set 才是真内存
- 实战陷阱:
container_memory_usage_bytes包含了操作系统的 Page Cache(文件缓存)。当你的 K8s 节点显示内存用满时,其实大部分可能是缓存,Linux 会自动回收。 - 最佳实践:监控
container_memory_working_set_bytes。这是 Kubernetes 计算 OOM(Out of Memory)杀手时的依据,才是真正的"应用内存占用"。
第五部分:告警治理与 Alertmanager 路由策略
【专栏正文】
监控的最终目的是为了"止损"。当系统出现异常时,我们要第一时间知道,并且以正确的方式通知正确的人。
5.1 告警的生命周期
一个告警在 Prometheus 内部经历以下状态:
- Inactive:未触发。
- Pending:刚刚触发条件,但未持续
for子句规定的时间(防止瞬时抖动)。 - Firing:持续满足条件,发送给 Alertmanager。
5.2 告警分组与抑制
如果你的生产环境有 1000 个 Pod,网络抖动可能导致它们瞬间全部连接失败。如果不做处理,你会收到 1000 条短信/钉钉消息。这会导致"告警风暴",运维人员直接关机睡觉。
我们需要在 Alertmanager 中配置 route:
route:
group_by: ['alertname', 'cluster', 'service'] # 按照这些标签聚合
group_wait: 10s # 等待 10s 收集同组告警一起发
group_interval: 5m # 同一组告警发送后的 5m 内如有新触发,合并发送
repeat_interval: 12h # 重复通知间隔,避免骚扰
receiver: 'default'
routes:
# 如果是 Node 级别的故障
- match:
severity: critical
receiver: 'admin-pager'
# 如果是 Pod 级别的故障
- match_re:
severity: warning|critical
receiver: 'dev-team'
inhibit_rules: # 抑制规则
# 如果 Node 宕机了,就不要发该 Node 上 Pod 的告警了
- source_match:
alertname: 'NodeDown'
target_match_re:
alertname: 'PodCrashLooping'
equal: ['node']【架构师手记】
- 告警不仅是通知,更是 Runbook
- 经验之谈:不要在告警信息里只写"High CPU"。这会让收到告警的人一脸懵逼,然后开始登服务器查日志,错过了黄金止损时间。
- 最佳实践:在 PrometheusRule 的
annotations里,直接放入 Runbook 文档的链接或者排查命令。
annotations:
summary: "Pod {{ $labels.pod }} High Memory Usage"
description: "Memory usage is above 85%."
runbook_url: "http://wiki.mycompany.com/runbooks/high-memory"- 告警分级要严格
- P0(紧急):电话/短信呼叫,必须有 On-call 人员响应(如"集群宕机"、"核心交易链路中断")。
- P1(重要):IM 群通知,工作时间处理(如"应用实例重启"、"磁盘空间不足")。
- P2(一般):邮件/Jira 工单,定期优化(如"代码质量下降"、"非核心接口慢查询")。
第六部分:架构师进阶------高可用与长期存储
【专栏正文】
对于小型集群,单节点 Prometheus 足矣。但对于拥有 10 万+ Pod 的超大规模集群,或需要保留 1 年以上数据进行合规审计的企业,单点 Prometheus 已无法满足要求。
6.1 单点 Prometheus 的局限性
- 单点故障:如果 Prometheus 挂了,监控数据就会中断。
- 存储瓶颈:本地存储难以无限扩容,且无法跨实例共享数据。
- 采集压力:单机采集数百万个时序,CPU 和 I/O 压力巨大。
6.2 解决方案选型:Thanos vs VictoriaMetrics
目前业界的两大主流解决方案是 Thanos 和 VictoriaMetrics。
方案 A:Thanos(生态标准)
- 架构:基于 Sidecar 模式。在每个 Prometheus 实例旁挂载一个 Thanos Sidecar,负责上传数据到对象存储(S3/MinIO),并提供全局查询接口。
- 优点:与 Prometheus 100% 兼容,利用对象存储实现无限期存储,支持 downsampling(降采样,自动降低历史数据精度)。
- 缺点:组件多,架构复杂,运维成本高,对象存储下载可能存在延迟。
方案 B:VictoriaMetrics(性能怪兽)
- 架构:单进程一体机,提供兼容 Prometheus 的写入接口和查询接口。
- 优点:写入性能是 Prometheus 的 10-20 倍,存储压缩率极高(节省 10x 空间),运维极其简单(单二进制文件)。
- 缺点:不完全支持 Prometheus 的某些高级特性(如 Recording Rules 的语法细节略有不同),生态略逊 Thanos(但正在快速追赶)。
6.3 性能优化 Tuning
无论选择哪种方案,本地 Prometheus 的优化都必不可少:
- 调整采集频率:不要盲目追求 1s 采集。对于 K8s 集群,15s-30s 是性价比最高的选择。
- 配置 Series Limit:在
prometheus.yml中限制每个 Query 和 总体的 Series 数量,防止一条"全限定"查询把 OOM。 - 启用存储压缩:虽然 Prometheus 默认开启,但在高版本中,可以调整压缩算法以换取更低的 CPU 占用。
【架构师手记】
- 不要迷恋"联邦"
- 过时方案:早期的 Prometheus HA 方案是"联邦"。即一个主 Prometheus 拉取其他从 Prometheus 的
/federate接口。 - 架构师警告:这在现代架构中已经被淘汰。
/federate接口性能极差,且无法解决长期存储问题。请直接转向 Thanos 或 VictoriaMetrics。
- 对象存储的坑
- 实战经验:在使用 Thanos 接入阿里云 OSS 或 AWS S3 时,一定要注意上传的压缩格式。默认通常不压缩,这会导致巨大的流量费用。开启 snappy 或 zstd 压缩,可以节省 80% 的存储费用和网络流量。
总结
至此,我们已经完整构建了一套从数据采集、存储分析、可视化到告警治理的 Prometheus + Grafana 监控体系。
作为架构师,你需要记住的核心原则是:
- 标准化:坚持使用 Pull 模式和 Exporter 标准。
- 声明式:拥抱 Operator,让 K8s 管理监控配置。
- 关注价值:监控是为了解决问题,而不是为了看漂亮的图表。所有的告警都应对应一个具体的运维动作。
希望这篇专栏能助你在云原生的道路上更进一步!