前言
看图猜故障系列,来自于技术群讨论的又一个问题,数据包如下图,No.4900 原始数据包,No.4901 间隔208ms第一次重传,No.4903 间隔208ms第二次重传。
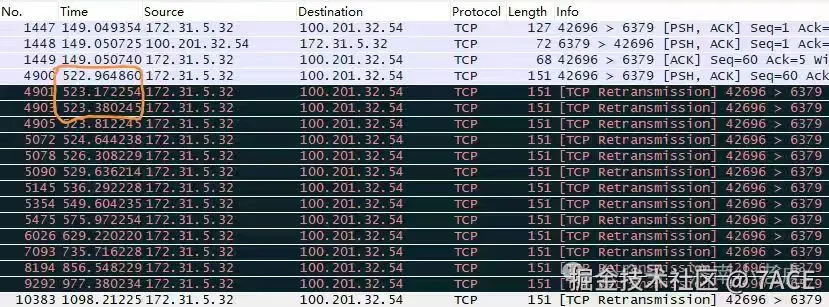
问题就是数据包第二次超时重传,间隔时间为什么没有翻倍。
问题分析
说实话,刚看到这个数据包文件截图时,记忆中竟然没有一丝相似的故障现象,略感纳闷。实际解读,也没有特别反常的迹象,只是在间隔 384s 后,客户端所发送的数据段由于得不到 ACK 确认,进行了重传的过程。当然由于第二次重传的超时时间未翻倍的原因,所以首先我并没有把这些重传全部定义为是超时重传。
但既然是一个数据段的重传,没有其他输入的信息,那么可以先简单模拟超时重传,对比看下。
plain
# cat test.pkt
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_TCP, TCP_NODELAY, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 10000 <mss 1000>
+0 > S. 0:0(0) ack 1 <...>
+0.01 < . 1:1(0) ack 1 win 10000
+0 accept(3, ..., ...) = 4
+0.1 write(4,...,100) = 100
+0 `sleep 5`
#执行脚本,同时通过 tcpdump 抓取数据包,现象如下。
可以看到发出数据段后,第一次重传间隔时间为213ms,而第二次重传间隔时间为436ms,也就是说都符合超时重传的现象,超时时间是正常翻倍了。
plain
# packetdrill test.pkt
#
# tcpdump -i any -nn port 8080
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
22:25:38.983501 tun0 In IP 192.0.2.1.34827 > 192.168.209.238.8080: Flags [S], seq 0, win 10000, options [mss 1000], length 0
22:25:38.983536 tun0 Out IP 192.168.209.238.8080 > 192.0.2.1.34827: Flags [S.], seq 3745491915, ack 1, win 64240, options [mss 1460], length 0
22:25:38.993637 tun0 In IP 192.0.2.1.34827 > 192.168.209.238.8080: Flags [.], ack 1, win 10000, length 0
22:25:39.093744 tun0 Out IP 192.168.209.238.8080 > 192.0.2.1.34827: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
22:25:39.307178 tun0 Out IP 192.168.209.238.8080 > 192.0.2.1.34827: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
22:25:39.743184 tun0 Out IP 192.168.209.238.8080 > 192.0.2.1.34827: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
22:25:40.607187 tun0 Out IP 192.168.209.238.8080 > 192.0.2.1.34827: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
22:25:42.335186 tun0 Out IP 192.168.209.238.8080 > 192.0.2.1.34827: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
#当然,由于第一个测试并没有支持 SACK,因此继续可以增加尝试测试。
plain
# cat test.pkt
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_TCP, TCP_NODELAY, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 10000 <mss 1000,nop,nop,sackOK>
+0 > S. 0:0(0) ack 1 <...>
+0.01 < . 1:1(0) ack 1 win 10000
+0 accept(3, ..., ...) = 4
+0.1 write(4,...,100) = 100
+0 `sleep 5`
#执行脚本,同时通过 tcpdump 抓取数据包,现象如下。
可以看到发出数据段后,第一次重传间隔时间为213ms,而第二次重传间隔时间为216ms,和问题截图一模一样的现象,第二次重传的超时时间并未翻倍。
plain
# packetdrill test.pkt
#
# tcpdump -i any -nn port 8080
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
22:35:37.983481 tun0 In IP 192.0.2.1.54829 > 192.168.44.251.8080: Flags [S], seq 0, win 10000, options [mss 1000,nop,nop,sackOK], length 0
22:35:37.983508 tun0 Out IP 192.168.44.251.8080 > 192.0.2.1.54829: Flags [S.], seq 2010255923, ack 1, win 64240, options [mss 1460,nop,nop,sackOK], length 0
22:35:37.993598 tun0 In IP 192.0.2.1.54829 > 192.168.44.251.8080: Flags [.], ack 1, win 10000, length 0
22:35:38.093722 tun0 Out IP 192.168.44.251.8080 > 192.0.2.1.54829: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
22:35:38.307185 tun0 Out IP 192.168.44.251.8080 > 192.0.2.1.54829: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
22:35:38.523213 tun0 Out IP 192.168.44.251.8080 > 192.0.2.1.54829: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
22:35:38.975187 tun0 Out IP 192.168.44.251.8080 > 192.0.2.1.54829: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
22:35:39.839188 tun0 Out IP 192.168.44.251.8080 > 192.0.2.1.54829: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
22:35:41.567190 tun0 Out IP 192.168.44.251.8080 > 192.0.2.1.54829: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
#通过两次实验对比,可知仅仅是增加了 SACK 的支持,就产生了不一样的结果,同时结合数据包的重传时间,可以判断出第一次重传并不是普通的超时重传,而在它发出之后,看到的第二次重传,才是真正的第一次超时重传,之后的也才是 RTO 不断翻倍后的超时重传过程。
那么第一次重传是什么?在 linux 系统中,它实际是一个 TLP 数据包,在SACK开启下,TLP 会重传强制传输还没有收到 ACK 确认的报文里面的最后一个报文或者未发送的新报文。 而在上面的测试以及问题截图场景中,也比较特殊,因为只发送了一个报文,所以第一次重传也就是发送了 TLP 定义中的最后一个报文,乍看起来,确实像是在进行超时重传。
TLP 介绍
Tail Loss Probe (TLP)是一个发送端算法,主要目的是使用快速重传取代RTO超时重传来处理尾包丢失场景。如果TCP尾包丢失,如果依靠RTO超时进行重传会带来比较大的延迟,进而影响用户体验。
那么如果一个TCP连接没有在一段时间内没有收到ACK报文,TLP会强制传输还没有收到ACK确认的报文里面的最后一个报文或者未发送的新报文(传输的这个报文就叫做loss probe)。
tcp_early_retrans - INTEGER
Enable Early Retransmit (ER), per RFC 5827. ER lowers the threshold for triggering fast retransmit when the amount of outstanding data is small and when no previously unsent data can be transmitted (such that limited transmit could be used). Also controls the use of Tail loss probe (TLP) that converts RTOs occurring due to tail losses into fast recovery (draft-dukkipati-tcpm-tcp-loss-probe-01).
Possible values:
0 disables ER
1 enables ER
2 enables ER but delays fast recovery and fast retransmit by a fourth of RTT. This mitigates connection falsely recovers when network has a small degree of reordering (less than 3 packets).
3 enables delayed ER and TLP.
4 enables TLP only.
Default: 3
证明实验
在 linux 中 tcp_early_retrans 参数默认值为 3,也就是同时启用了 Delayed ER 和 TLP。
plain
# sysctl -a|grep early_retrans
net.ipv4.tcp_early_retrans = 3
# 如果想证明确实和 TLP 相关,可以从三个方面测试下:
- 关闭 SACK;(上述实验已测试)
- net.ipv4.tcp_early_retrans 值修改为 4,仅开启 TLP;
- net.ipv4.tcp_early_retrans 值修改为 0,关闭 ER 以及 TLP。
首先仅开启 TLP 的情况,继续测试在 SACK 开启的脚本。
plain
# sysctl -q net.ipv4.tcp_early_retrans=4
# sysctl -a|grep early_retrans
net.ipv4.tcp_early_retrans = 4
# 执行脚本,同时通过 tcpdump 抓取数据包,现象如下,可以看到与默认值 3 的测试结果一致,说明了和 ER 重传无关,与 TLP 可能有关(严谨的说法,因为也有可能是某某重传引起)。
plain
# tcpdump -i any -nn port 8080
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
10:12:36.563494 tun0 In IP 192.0.2.1.50647 > 192.168.165.47.8080: Flags [S], seq 0, win 10000, options [mss 1000,nop,nop,sackOK], length 0
10:12:36.563526 tun0 Out IP 192.168.165.47.8080 > 192.0.2.1.50647: Flags [S.], seq 3170095082, ack 1, win 64240, options [mss 1460,nop,nop,sackOK], length 0
10:12:36.573627 tun0 In IP 192.0.2.1.50647 > 192.168.165.47.8080: Flags [.], ack 1, win 10000, length 0
10:12:36.673761 tun0 Out IP 192.168.165.47.8080 > 192.0.2.1.50647: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
10:12:36.887178 tun0 Out IP 192.168.165.47.8080 > 192.0.2.1.50647: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
10:12:37.103192 tun0 Out IP 192.168.165.47.8080 > 192.0.2.1.50647: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
10:12:37.535174 tun0 Out IP 192.168.165.47.8080 > 192.0.2.1.50647: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
10:12:38.399184 tun0 Out IP 192.168.165.47.8080 > 192.0.2.1.50647: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
10:12:40.127180 tun0 Out IP 192.168.165.47.8080 > 192.0.2.1.50647: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
#继续关闭 TLP 的情况,仍然是测试 SACK 开启的脚本。
plain
# sysctl -q net.ipv4.tcp_early_retrans=0
# sysctl -a|grep early_retrans
net.ipv4.tcp_early_retrans = 0
# 执行脚本,同时通过 tcpdump 抓取数据包,现象如下,可以看到与关闭 SACK 的首次测试结果一致,标准的超时重传现象。对于关闭 TLP 和开启 TLP 的两次实验结果,可得知第一次重传数据包确实是 TLP 报文。
plain
# tcpdump -i any -nn port 8080
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
10:17:24.423493 tun0 In IP 192.0.2.1.35821 > 192.168.117.180.8080: Flags [S], seq 0, win 10000, options [mss 1000,nop,nop,sackOK], length 0
10:17:24.423527 tun0 Out IP 192.168.117.180.8080 > 192.0.2.1.35821: Flags [S.], seq 1548070828, ack 1, win 64240, options [mss 1460,nop,nop,sackOK], length 0
10:17:24.433632 tun0 In IP 192.0.2.1.35821 > 192.168.117.180.8080: Flags [.], ack 1, win 10000, length 0
10:17:24.533759 tun0 Out IP 192.168.117.180.8080 > 192.0.2.1.35821: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
10:17:24.751193 tun0 Out IP 192.168.117.180.8080 > 192.0.2.1.35821: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
10:17:25.183189 tun0 Out IP 192.168.117.180.8080 > 192.0.2.1.35821: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
10:17:26.047181 tun0 Out IP 192.168.117.180.8080 > 192.0.2.1.35821: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
10:17:27.775172 tun0 Out IP 192.168.117.180.8080 > 192.0.2.1.35821: Flags [P.], seq 1:101, ack 1, win 64240, length 100: HTTP
#问题总结
实际上对于重传触发出来的原因,或者说重传的归类,远远不止众所周知的超时重传、快速重传这两种,后续再慢慢展开分享吧。