基于 token 的定价是否正在变得比基于 credit 的定价更经济?
作者: Darko 发布时间: 2025年11月10日
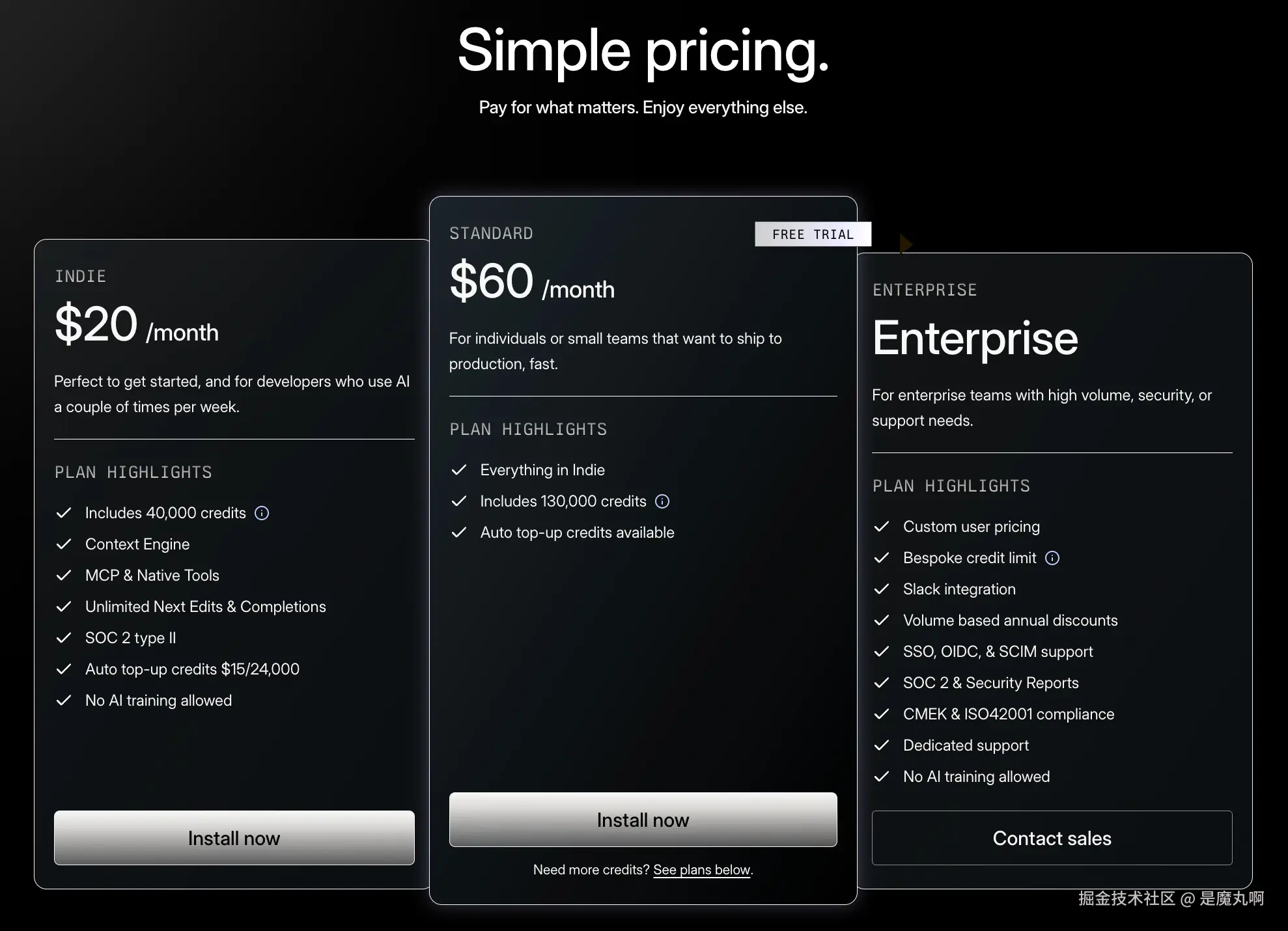
Augment Code 在 2025 年 10 月从基于消息数量的定价转向基于 credit 的定价。现在你可以购买每月的 "credits" 额度,这些额度会在月末过期。
问题所在: 这是又一个公司提供自己版本的 "credits" 的案例,没有清晰说明这能覆盖多少任务,或者 credits 如何转换为实际的 token 使用量。
这可能是件好事(相比基于 token 的定价你获得更多),也可能是件坏事(相比基于 token 的定价你获得更少)。Augment 属于前者还是后者?让我们一探究竟。
实验: 我们注册并通过 Augment 平台和 Kilo Code 运行了四个标准开发任务,来比较成本(Augment 的 credit vs. Kilo 的基于 token 的定价),并了解这个新的基于 credit 的定价系统对你日常编码工作流的意义。
测试方法
我们创建了一个 Node.js、TypeScript 和 Express 项目,包含一个简单的任务管理 API,并在 Augment Code 和 Kilo Code 中使用相同的基础项目。

然后我们通过两个平台运行了四个常见的开发任务:添加验证、重构代码、实现功能和编写测试。
使用的模型: 所有 Augment Code 测试都使用 Claude Sonnet 4.5,这是他们推荐用于编码任务的模型。对于 Kilo Code,我们测试了 Claude Sonnet 4.5(用于直接比较)和 GLM 4.6(用于展示使用预算模型的成本节省)。我们在测试期间使用完全相同的 prompts,并跟踪了 credit/token 消耗和成本。
成本明细
任务 #1:添加验证 Middleware
Prompt: "为任务创建端点添加验证 middleware。验证 title 是必需的,必须是 1-200 个字符之间的字符串。Description 是可选的,但如果提供必须少于 1000 个字符。对于验证失败返回 400 并带有具体的错误消息。"
结果: 这个基础的输入验证任务在 Augment Code 上消耗了 519 credits($0.26)。
在 Kilo Code 上使用 Claude Sonnet 4.5 完成相同任务花费 0.16,使用GLM4.6仅需0.03。
注意: 我们使用简单的数学计算 Augment Code 的 credits 成本,即 20购买40,000credits=每个credit0.0005。
任务 #2:重构为 Repository Pattern
Prompt: "将基于文件的存储重构为适当的数据访问层。创建一个 TaskRepository 类,包含以下方法:getAll()、getById(id)、create(task)、update(id, task)、delete(id)。repository 应该正确处理文件 I/O 和错误。更新路由以使用这个 repository 而不是直接访问文件。"
结果: 这个架构重构在 Augment Code 上消耗了 1,218 credits($0.61)。
Kilo Code 使用 Claude Sonnet 4.5 花费 0.16,而GLM4.6处理它花费0.09。
任务 #3:添加优先级和截止日期功能
Prompt: "为任务添加 priority(high、medium、low)和 dueDate 字段。更新 Task interface,添加过滤端点 GET /api/tasks?priority=high 和 GET /api/tasks/overdue 用于查询已过截止日期的任务。包含适当的 TypeScript 类型。"
结果: 添加这些新字段和端点在 Augment Code 上消耗了 1,248 credits($0.62)。
使用 Kilo Code 上的 Claude Sonnet 4.5 实现相同功能花费 0.43,或使用GLM4.6花费0.20。
任务 #4:编写测试和文档
Prompt: "为 TaskRepository 类编写 Jest 单元测试,测试所有 CRUD 操作,包括错误情况。Mock 文件系统。同时为所有公共方法生成 JSDoc 注释,并创建一个 README.md,包含 API 文档,包括示例请求和响应。"
结果: 这个最后的任务在 Augment Code 上消耗了 1,337 credits($0.67)。
在 Kilo Code 上,使用 Claude Sonnet 4.5 花费 0.56。GLM4.6在设置Jest时稍有困难,需要更多迭代,花费0.52。
总成本比较
运行完所有四个任务后,这是完整的成本明细:
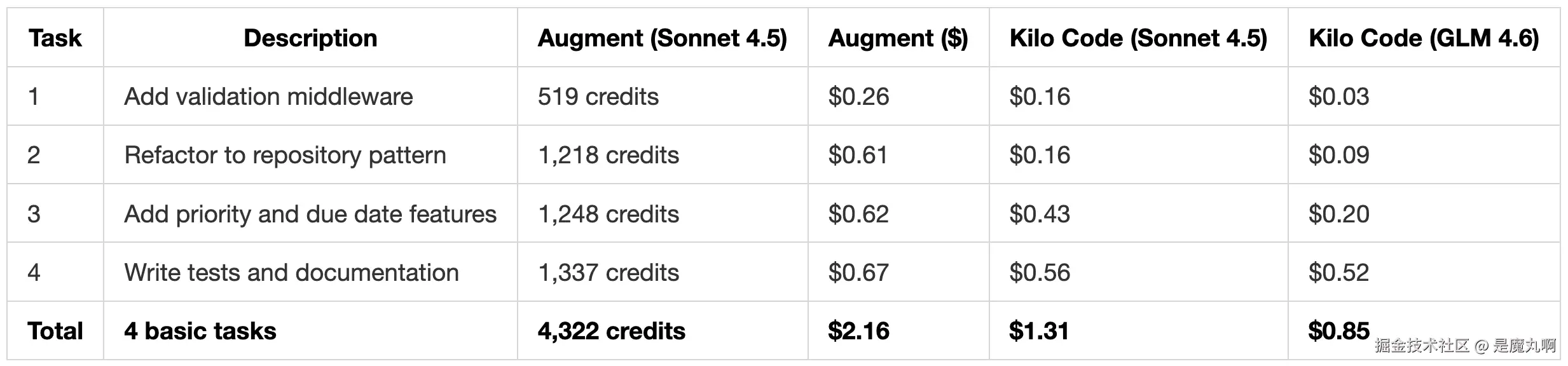
| 任务 | Augment Code Credits | Augment Code 成本 | Kilo Code (Claude Sonnet 4.5) | Kilo Code (GLM 4.6) |
|---|---|---|---|---|
| 任务 #1:添加验证 Middleware | 519 | $0.26 | $0.16 | $0.03 |
| 任务 #2:重构为 Repository Pattern | 1,218 | $0.61 | $0.16 | $0.09 |
| 任务 #3:添加优先级和截止日期 | 1,248 | $0.62 | $0.43 | $0.20 |
| 任务 #4:编写测试和文档 | 1,337 | $0.67 | $0.56 | $0.52 |
| 总计 | 4,322 | $2.16 | $1.31 | $0.84 |
Augment Code 的 credits 按 20购买40,000credits=每个credit0.0005 计算
唉......这出乎意料。
这一切意味着什么: Augment Code 的 20方案每月提供40,000credits。这四个任务在大约2−3小时的开发工作中消耗了超过1020 的方案只能维持 1-2 天。难怪这么多人在抱怨。
Augment Code 的定价更新做出了具体声明:"Completions & Next Edit 用户通常适合 20/月方案",而"每天使用Agent完成几个任务的用户通常在60- 200/月之间"。我们的测试显示了不同的现实:推算到实际的日常开发,成本将达到300-$600/月,远远超过他们的估计。

除了总成本之外,我们还发现 Augment Code 通过将你限制在四个 premium 模型上,来限制你如何在任务之间分配支出。
相比之下,Kilo 采用 100% 开放模型方法,这意味着你可以通过任何 AI 提供商使用(几乎)任何 AI 模型。
有限模型选择的问题
截至 2025 年 11 月,Augment Code 提供四个模型:
所有四个都是定价高昂的 premium 模型。这种有限的选择造成了成本效率低下:
添加验证或格式化代码等简单任务仍然以 premium 费率消耗 credits。这些任务用预算模型就可以很好地完成。如果你想优化成本,对简单任务使用 premium 模型相当于用超级计算机运行计算器应用。
价格与 OpenAI 和 Anthropic 的费率相同
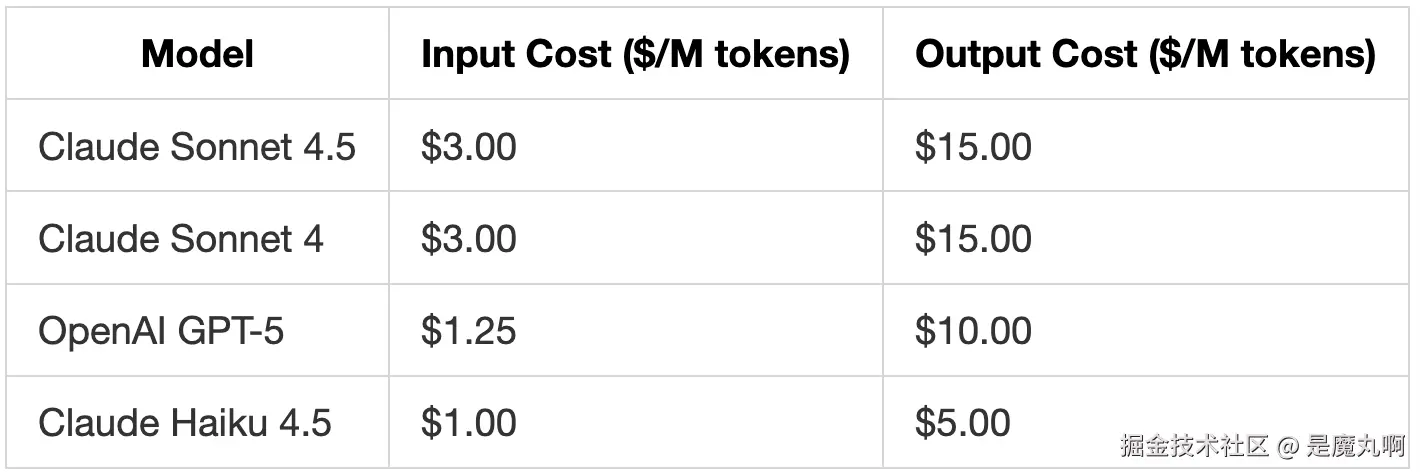
我们通过 Kilo Code 使用 Z.ai 的 GLM 4.6 直接测试了这种"简单任务用预算模型"的方法。GLM 4.6 以几分钱的成本处理了前三个任务。然而,任务 4 更复杂,使用 GLM 4.6 的成本上升到 $0.52,因为它需要更多迭代。在真实工作流中,你可以为简单任务选择 GLM 4.6 或类似的小型模型,当你知道任务更困难时切换到更强大的模型(如 Claude Sonnet 4.5 或 OpenAI GPT-5),简单任务的成本会比这些强大模型便宜得多。
价格与 OpenRouter API 定价相同

Kilo Code 提供来自多个提供商的数百个模型的访问。你可以为日常工作使用预算模型,为复杂问题使用最先进的模型。
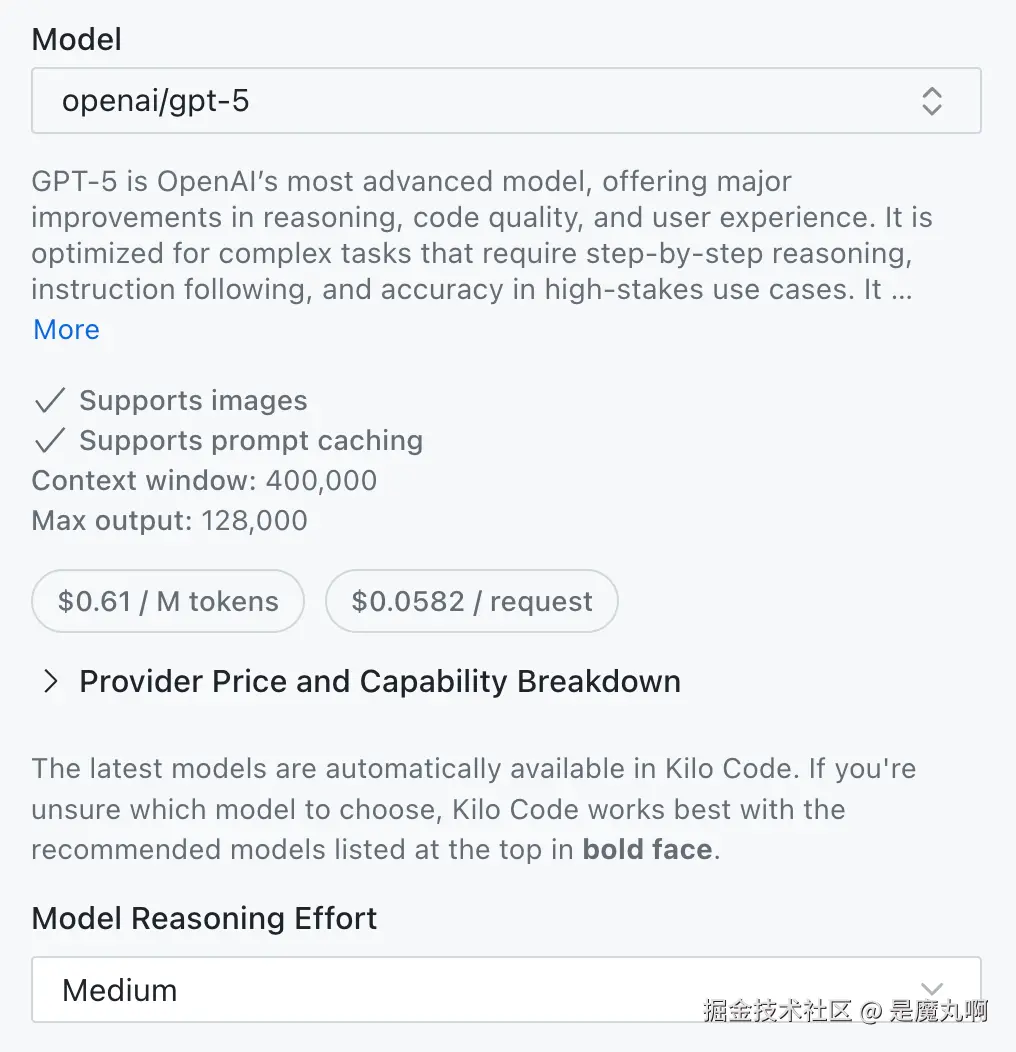
还值得注意的是,Augment Code 中的模型限制不仅仅是模型选择。使用 reasoning models 时,你也无法调整 reasoning effort 级别。
在 Kilo Code 中,你可以根据任务复杂度将 GPT-5 等模型设置为高、中或低 reasoning effort。Reasoning 是 AI 模型在提供答案之前逐步"思考"问题的过程,类似于人类在最终确定解决方案之前在纸上解决复杂问题的方式。更高的 reasoning 能改善复杂任务的结果,但成本更高。更低的 reasoning 在简单任务上节省资金,通常会产生更快的响应时间。Augment Code 锁定了这些设置,移除了另一个成本和性能优化的手段。
实时成本跟踪
Augment Code 不提供每个 prompt 的成本可见性。你可以在分析仪表板中看到总使用情况(每日消耗和模型分布),但无法跟踪单个操作的成本。这使得实时优化工作流变得困难。
相比之下,Kilo Code 在每次会话期间显示全面的成本和使用数据:
- 聊天顶部的运行成本总计
- 每条消息的成本明细
- 显示 AI reasoning 步骤、checkpoints 和工具使用的可视化进度条
- 用于成本验证的精确 token 计数
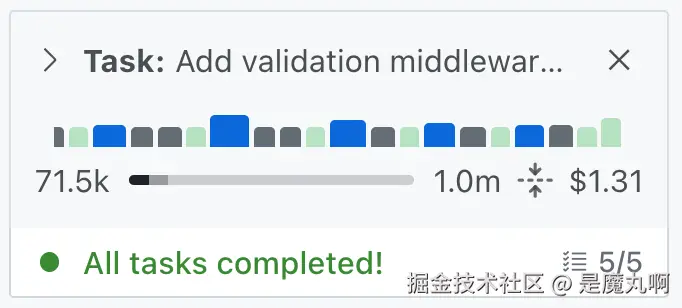
在编码会话期间,上下文管理不仅仅关乎成本。模型通常在达到某些上下文使用阈值后表现更差并变慢。当你能看到上下文使用情况时,你就知道何时压缩上下文或开始新聊天,以节省成本并提高速度和响应质量。
Credits vs 基于 Token 的定价
相比基于 token 的替代方案,credit 系统造成了根本性的限制:
Credits(Augment Code):
- 每月过期,不能结转
- 必须在不知道使用需求的情况下预先购买
- 隐藏实际成本(519 credits 等于 $0.26,但你在任务中途永远不会计算这个)
- 将你锁定在固定的月度方案中
- 无法跨不同工具比较价格
基于 Token 的 BYOK(Kilo Code):
- 仅为实际使用付费
- 以实际美元查看成本
- 余额不过期
- 根据复杂度为每个任务切换模型
- 立即使用任何提供商(订阅或按 token 付费)
- 在免费期间尝试实验性模型(如当前在 Kilo Code 中免费的 MiniMax M2 或 Grok Code Fast 1)
credit 系统解决了 Augment Code 的业务挑战(可预测的收入,无结转负债),但为需要成本可见性和灵活性的开发者制造了摩擦。
更广泛的背景
Augment Code 在这一转变中并不孤单。多个 AI 编码助手最近已经从透明的基于 token 的定价转向了 credit 系统。这些 credits 通常不能清楚地映射到实际使用情况。有些不管大小都计算"prompts",其他的使用专有计算方法,使成本比较变得不可能。
这种全行业的模式为开发者制造了几个问题。当每个工具使用不同的 credit 公式时,你无法比较工具之间的成本。
每月过期的配额制造了"不用就浪费"的压力,而不是根据实际需求进行优化。最重要的是,当你不知道东西实际花费多少时,你无法就哪些模型用于哪些任务做出明智的决定。
支持 BYOK(Bring Your Own Key)的开源工具保留了开发者需要的透明度。你实时看到确切的 token 使用情况,只为消耗的内容付费,并且 tokens 永不过期。更重要的是,你保持了根据任务需求和预算限制在模型和提供商之间切换的自由,而不是供应商锁定。
向 credits 的转变显然有利于 AI 编码助手公司:可预测的月度收入,无结转义务,简化的计费。但它减少了开发者对成本和工具选择的控制。