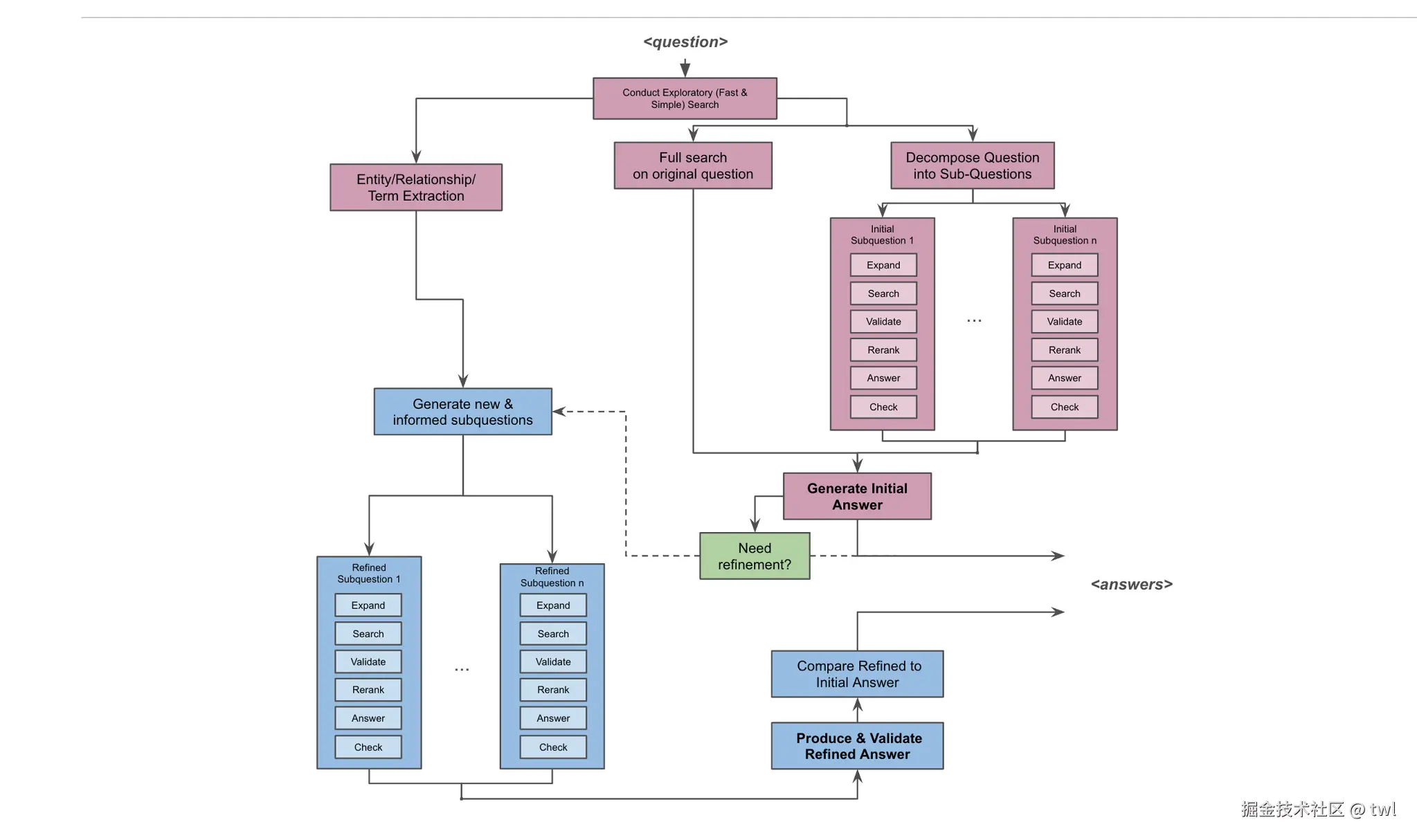
我们从这张图开始说明,这张图描述的是一种**"先粗后细、可迭代精炼"的问答/检索式推理流程**:先用快速搜索和问题分解得到初版答案 ,再根据初版答案暴露的缺口生成更有针对性的子问题 ,继续检索与验证,产出精炼答案,并与初版对比后输出最终结果。
1)整体结构:两阶段 + 一个循环
图里用颜色区分了阶段:
- 紫色(Initial) :第一次处理------从原始问题出发,得到初始子问题 和初版答案
- 绿色(决策) :判断要不要继续精炼(Need refinement?)
- 蓝色(Refined) :第二次处理------生成更聪明/更具体的子问题 ,得到精炼答案并做对比验证
- 虚线箭头:表示"反馈/迭代",即初版的结果会反过来帮助下一轮提出更好的子问题
2)输入:Question
最上方是 <question>,用户提出的原始问题。
接下来立刻进入一个"快速探路"步骤:
Conduct Exploratory (Fast & Simple) Search(快速探索式检索)
目的:快速摸清方向,比如:
- 找到关键词、核心实体(人/机构/产品/时间)
- 判断这题是否需要拆分
- 先拿到一些候选材料,避免一上来就深挖跑偏
3)三条并行主线(初始阶段的三件事)
从快速探索检索后,流程分成三条线并行推进:
A. Entity/Relationship/Term Extraction(实体/关系/术语抽取)
把问题里的关键元素结构化,例如:
- 实体:谁/什么(公司、人物、指标、系统名...)
- 关系:谁影响谁、A 属于 B、A 在 B 之后发生...
- 术语 :专业名词、同义词、缩写
这一步的产物,后面会用于生成更好的子问题(尤其是精炼阶段)。
B. Full search on original question(针对原问题的完整检索)
不拆分,直接对"原问题整体"做一次更全面的搜索,目的:
- 尽快找到"可能直接回答"的材料
- 作为后续分解/验证的主参考
C. Decompose Question into Sub-Questions(分解成子问题)
把复杂问题拆成多个可检索、可验证的子问题。右侧的方框表示:
- Initial Subquestion 1 ... Initial Subquestion n(多个初始子问题并行)
4)每个子问题内部的"标准流水线"
每个紫色的子问题框里都有同样的步骤(这是典型的检索增强/多跳问答流水线):
- Expand:扩展查询(同义词、别名、上下位概念、时间范围、语言变体...)
- Search:检索(搜索引擎/知识库/数据库/向量检索等)
- Validate:验证候选证据是否相关、是否可信(来源质量、是否过时、是否自相矛盾)
- Rerank:对证据排序,把最相关、最可靠的排前
- Answer:基于证据回答该子问题
- Check:自检(答案是否直接回应问题、是否缺关键条件、是否需要更多证据)
这些子问题的结果会汇聚到下一步。
5)Generate Initial Answer(生成初版答案)
紫色模块 Generate Initial Answer:把
- 原问题的 full search 结果
- 各个初始子问题的答案与证据
综合成一个"可读"的初版回答。
然后进入绿色决策:
Need refinement?(需要精炼吗?)
判断标准通常类似:
- 证据不足/冲突
- 答案缺关键细节(时间、条件、边界)
- 子问题覆盖不全(漏了某个维度)
- 需要更强的可验证性/引用
如果不需要 :箭头直接指向右侧 <answers>,输出初版即最终答案。
如果需要:进入精炼循环。
6)精炼阶段:生成"更有信息量"的新子问题
左侧蓝色模块:
Generate new & informed subquestions(生成新的、更有依据的子问题)
这一步的"informed"很关键:它不是凭空再拆,而是利用:
- 前面的 实体/关系/术语抽取(A线的结构化信息)
- 初版答案暴露的缺口(虚线反馈箭头暗示这一点)
所以精炼子问题(Refined Subquestion 1...n)往往更精准,例如:
- 把模糊概念换成明确术语/别名
- 把时间范围缩小到关键窗口
- 专门针对冲突点发问("A 与 B 哪个为准?依据是什么?")
- 针对关键链路补齐缺失的"中间跳"(多跳推理)
7)精炼子问题同样走一遍流水线
每个蓝色 refined 子问题也走:
Expand → Search → Validate → Rerank → Answer → Check
然后汇聚到右下角两个蓝色模块:
Produce & Validate Refined Answer(产出并验证精炼答案)
把 refined 子问题答案综合起来,并做更严格的验证(一致性、证据充分性、引用覆盖等)
Compare Refined to Initial Answer(与初版对比)
对比目的:
- 精炼版是否纠正了初版错误
- 是否补足缺失信息
- 是否更一致、更可解释
- 是否需要进一步迭代(图里没有画第三轮,但这个结构天然支持多轮)
最后输出到 <answers>。
8)你可以把它理解成什么?
一句话: "先用粗粒度分解 + 检索得到可用答案,再用答案反推更尖锐的问题继续查证,最终得到更可靠的回答。"
那么具体的落地是如下的流程,请看下一张图:
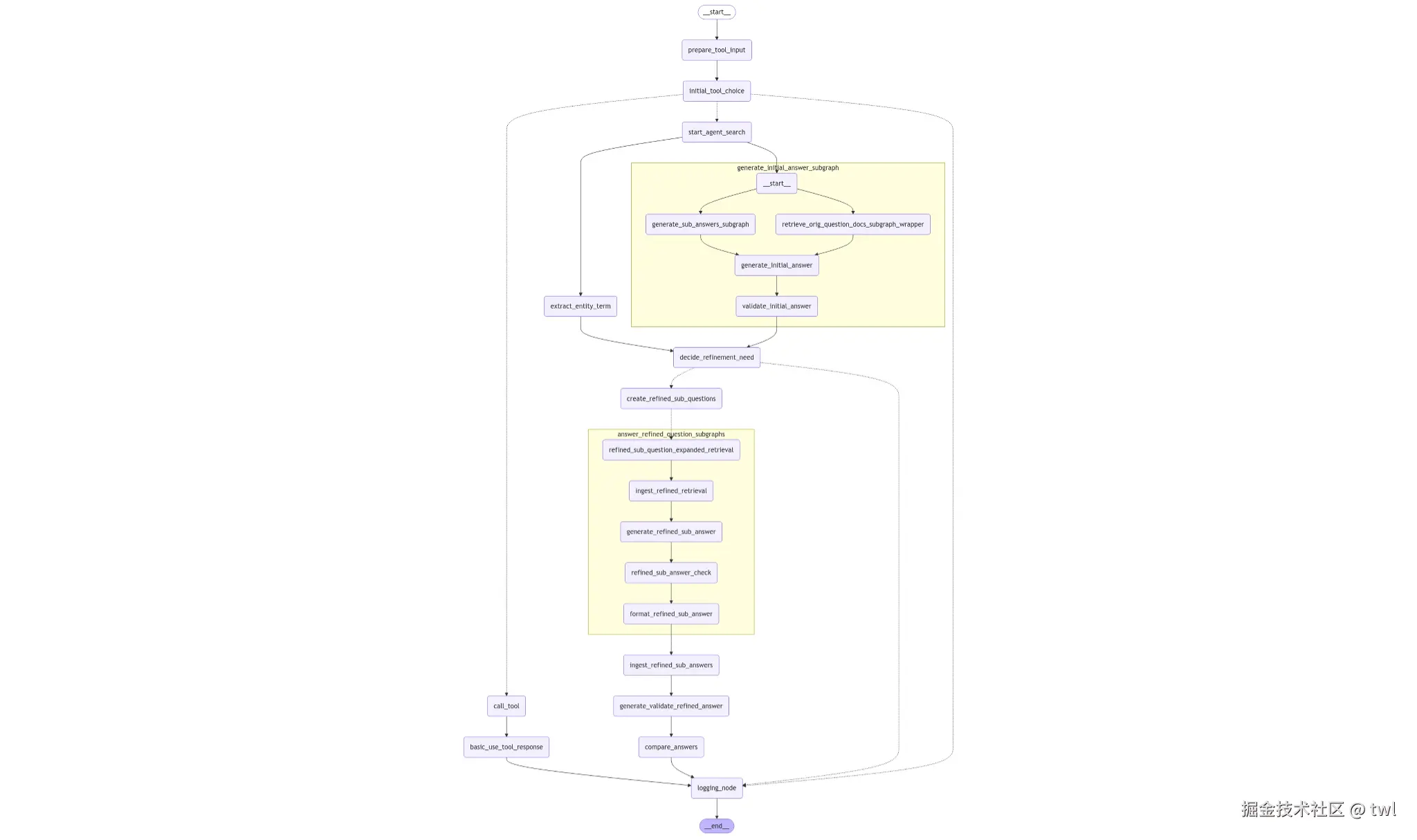
这张图是把前一张"概念级流程图"落实成"可执行 Agent / Graph 工作流"的实现版 。
如果说上一张图回答的是「逻辑上怎么想 」,这一张回答的是「系统里怎么跑」。
按 自顶向下 + 分层 来详细解释。
一、整体视角:这是一个「有条件迭代的 Agent Graph」
你可以把它理解为:
一个有状态、有子图(subgraph)、能判断是否继续精炼的 Agent 工作流 DAG
核心特点:
- 有 start → end 的完整生命周期
- 有 subgraph(黄色区域) 封装复杂逻辑
- 有 refinement loop(是否精炼)
- 有 工具调用(tool)与非工具路径并存
- 有 日志与对比节点,便于调试和评估
二、最外层主流程(从 start 到 end)
1️⃣ _start_
流程入口。
2️⃣ prepare_tool_input
职责:
- 标准化用户输入
- 补充上下文(历史对话、系统 prompt、约束条件)
- 为后续「是否调用工具」做准备
👉 这是 Agent 工程里非常关键的一步,但在论文里常被省略。
3️⃣ initial_tool_choice
做什么?
- 判断:
👉 这次任务要不要用工具?
👉 要用哪些工具?(搜索 / RAG / DB / API)
输出:
- tool plan(可能为空)
4️⃣ start_agent_search
标志着:
- 正式进入"搜索 + 推理"阶段
- 后面会进入一个「生成初始答案的子图」
三、黄色子图 ①:generate_initial_answer_subgraph
这是初始答案生成阶段,对应你第一张图里的「紫色部分」。
子图入口:__start__
4.1 两条并行主线
🟣 A. generate_sub_answers_subgraph
-
对 初始子问题做并行处理
-
本质就是:
拆问题 → 查资料 → 回答子问题
🟣 B. retrieve_orig_question_docs_subgraph_wrapper
- 不拆分
- 直接对 原问题整体做一次检索
- 防止「拆错问题」或「遗漏全局信息」
这两个输出会在下一步合流。
4.2 generate_initial_answer
做什么?
-
汇总:
- 原问题检索结果
- 各个初始子问题的答案
-
生成 initial_answer
4.3 validate_initial_answer
初版答案自检
- 是否回答了问题?
- 是否有明显事实冲突?
- 是否缺关键信息?
⚠️ 注意:
这里不是最终 validation,而是 "是否值得继续 refinement" 的判断依据之一
四、并行支线:extract_entity_term
这条线很容易被忽略,但非常重要。
extract_entity_term
作用:
-
抽取:
- 实体(entity)
- 术语(term)
- 可能的关系线索
关键点:
- 它 不直接生成答案
- 它为后续的 refined sub-questions 提供"结构化认知"
👉 对应你第一张图里的
Entity / Relationship / Term Extraction
五、决策节点:decide_refinement_need
这是整个系统的"智能阀门" 。
输入:
initial_answervalidation resultentity / term 信息
输出:
- ✅ 不需要 refinement → 直接收尾
- 🔁 需要 refinement → 进入下一阶段
典型触发 refinement 的条件:
- 证据不足
- 子问题覆盖不全
- 结论不稳定
- 实体关系复杂但未展开
六、精炼阶段(Refinement Loop)
6.1 create_refined_sub_questions
这是"informed refinement"的核心
不是再随便拆问题,而是:
-
基于:
- 初版答案的缺口
- 抽取到的实体/关系
-
生成 更尖锐、更具体、更可检索的子问题
七、黄色子图 ②:answer_refined_question_subgraphs
这是 Refined Subquestion 的完整处理流水线,对应你第一张图里的蓝色部分。
子图内部步骤(严格顺序):
-
refined_sub_question_expanded_retrieval- 扩展查询(同义词、别名、时间约束)
-
ingest_refined_retrieval- 整理 / 清洗 / 去重检索结果
-
generate_refined_sub_answer- 基于证据生成子问题答案
-
refined_sub_answer_check- 针对该子问题的自检
-
format_refined_sub_answer- 标准化输出格式,便于后续聚合
6.2 ingest_refined_sub_answers
- 汇总所有 refined 子问题答案
- 作为下一步生成最终 refined answer 的输入
八、最终答案生成与对比
8.1 generate_validate_refined_answer
- 综合 refined 子答案
- 生成 Refined Answer
- 做更严格的验证(一致性、覆盖性)
8.2 compare_answers
非常工程化、但非常关键的一步
比较:
- initial_answer
- refined_answer
常见比较维度:
- 是否修正错误?
- 是否信息更完整?
- 是否证据更充分?
👉 这一步非常适合用在 自动评估 / A-B test / RLHF 信号 中。
九、工具调用分支(左侧)
call_tool → basic_use_tool_response
这是一个独立的工具执行路径:
- 当 initial_tool_choice 判定需要工具
- 或中途某节点触发工具调用
- 结果会被并入主流程
🔟 收尾
logging_node
-
记录:
- 决策路径
- 是否 refinement
- 中间答案
-
对 debug / offline analysis 极其重要
_end_
流程结束。
十、一句话总结这张图
这是一个把"多步推理 + RAG + 自我评估 + 条件精炼"完整工程化的 Agent Graph 实现图。