文章目录
- 前言
- 背景
- 核心需求点
- 数据流介绍
- 适合场景
- 数据增长与容量分析
- 第一阶段
-
- [步骤 1: 创建"Hot-Only"的 ILM 策略](#步骤 1: 创建“Hot-Only”的 ILM 策略)
- [步骤 2: 创建数据流索引模板](#步骤 2: 创建数据流索引模板)
- [步骤 3: 创建数据流 & 使用](#步骤 3: 创建数据流 & 使用)
- 删除策略
- 后续的一些策略
-
-
-
- [步骤 1: 规划节点角色(为扩展做准备)](#步骤 1: 规划节点角色(为扩展做准备))
- [步骤 2: 扩展热数据节点](#步骤 2: 扩展热数据节点)
-
-
- 资料获取

前言
博主介绍:✌目前全网粉丝4W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
CSDN搜索:长路
视频平台:b站-Coder长路
背景
基于当前的配置(index_patterns, rollover_alias)【前面一篇时序数据自动化管理】已经非常接近数据流的配置模式。如果未来您的系统需要扩展,同样也可以考虑迁移到数据流,能简化管理并利用更多 ES 8 的新特性。
核心需求点
- 数据不能删除:需要永久保存。
- 每个主分片大小控制在 30GB:为了性能和管理均衡。
(数据不删除、全局查询、性能均衡)和硬件环境(3节点,每年1000万文档增长),设计一个从初始部署到未来扩展的完整方案。
数据流介绍
官方文档:https://www.elastic.co/docs/manage-data/data-store/data-streams
数据流(Data Stream)在 ES8 中是一组隐藏且自动生成的后备索引的抽象,对外暴露为单一命名资源。它满足以下特征:
- 时间戳驱动 :每个文档必须含
**@timestamp**字段 - 仅追加写入:默认禁止更新/删除,保证顺序写性能
- 自动滚动:通过 ILM 或手动 rollover 生成新写入索引
官方建议:当数据极少更新 且持续增长时,优先使用数据流。
适合场景
数据流不适合频繁更新的场景。直接在数据流上进行频繁更新会带来严重的性能问题和管理复杂性。
数据流的设计哲学是 "Append-Only"(仅追加),它为时序数据(如日志、指标、事件)而生,这类数据一旦写入就几乎不会改变。
当您在 Elasticsearch 中执行"更新"操作时,它内部执行的是 "删除旧文档 + 插入新文档"。在数据流上频繁这样做,会产生以下问题:
- 性能急剧下降:
-
- 产生大量小段:每次"删除+插入"都会创建新的 Lucene 段文件。频繁更新会导致一个索引中产生海量的、未合并的小段。
- 查询变慢:查询时需要扫描所有这些段,导致查询性能严重下降。
- 合并压力巨大:ES 的后台合并进程会疯狂工作,试图合并这些小段,这会消耗大量的 CPU 和 I/O,进一步影响整个集群的稳定性。
- 生命周期管理(ILM)混乱:
-
- Warm/Cold 阶段的只读冲突 :当索引进入
warm或cold阶段,ILM 通常会将其设置为只读(例如,通过allocate操作)。此时,如果您尝试更新这个索引中的文档,更新会失败。 - 强制回退 :即使配置允许写入,对一个处于
warm阶段的索引进行更新,也可能会触发 ILM 将其强制移回hot阶段,这完全打乱了您设计的成本优化和性能分层架构。
- Warm/Cold 阶段的只读冲突 :当索引进入
- 存储空间浪费:在后台合并完成之前,旧版本的文档和新版本的文档会同时占用磁盘空间。
数据增长与容量分析
- 年增长:1000万条记录。
- 单条记录估算 :假设一个非结构化文档(如PDF、Word)包含元数据(1KB)和部分或全部文本内容(平均19KB),单条记录在ES中(包含
**_source**和索引)大小约为 20KB。 - 年数据量:10,000,000 条 * 20 KB/条 = 200 GB (原始数据)
- ES存储开销 :考虑到索引、副本(1个副本)、操作系统开销等,实际存储需求大约是原始数据的 2-3倍。
- 年存储需求 :200 GB * 2.5 = 500 GB/年。
结论 :您当前3节点 * 1TB/节点 = 3TB 的总存储空间,在不做任何优化的情况下,大约可以支撑 5-6年 的数据增长。但考虑到性能和扩展,我们不能等到空间用尽才行动。
第一阶段
目标:立即部署一个高性能、稳定、易于管理的系统,满足当前业务需求,并为未来扩展打下良好基础。
步骤 1: 创建"Hot-Only"的 ILM 策略
"全局查询"需求,我们暂时放弃warm/cold阶段,确保所有数据都在高性能节点上,以获得最快、最稳定的查询响应。
- 初步测试场景使用1gb一个分片
json
PUT /_ilm/policy/file_document_lifecycle_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "1gb", // 🎯 核心参数:整个索引达到30GB时滚动
// "max_age": "90d" // 保险策略:即使数据量少,90天也滚动一次,防止索引过大
}
}
}
// 🎯 注意:没有 warm, cold, delete 阶段,数据永久保留在 hot 节点
}
}
}步骤 2: 创建数据流索引模板
这个模板将数据流、ILM策略和您的数据结构绑定。
java
PUT /_index_template/file_document_template
{
"index_patterns": ["file-documents"], // 🎯 数据流名称,建议用复数
"data_stream": { }, // 🎯 声明为数据流模板
"template": {
"settings": {
"number_of_shards": 1, // 🎯 核心:1个主分片,确保每个索引约30GB
"number_of_replicas": 1, // 🎯 1个副本,保证数据高可用
"index.lifecycle.name": "file_document_lifecycle_policy", // 🎯 关联策略
"refresh_interval": "1s",
"analysis": {
"analyzer": {
"path_analyzer": {
"type": "custom",
"tokenizer": "path_tokenizer"
}
},
"tokenizer": {
"path_tokenizer": {
"type": "path_hierarchy"
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"fileName": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
},
"raw": {
"type": "text",
"analyzer": "standard"
}
}
},
"fileContent": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"fileType": {
"type": "keyword"
},
"filePath": {
"type": "text",
"analyzer": "path_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"fileSize": {
"type": "float"
},
"createUserId": {
"type": "keyword"
},
"catalogStatus": {
"type": "integer"
},
"tags": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "ik_smart"
}
}
},
"catalogNames": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "ik_smart"
}
}
},
"catalogFields": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "ik_smart"
}
}
},
"catalogFieldValues": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"tagIds": {
"type": "long"
},
"catalogIds": {
"type": "long"
},
"updateTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"yearMonth": {
"type": "date",
"format": "yyyy-MM"
}
}
}
},
"priority": 500 // 设置高优先级,确保覆盖默认模板
}步骤 3: 创建数据流 & 使用
创建数据流:
sql
PUT /_data_stream/file-documents写入数据示范:
json
POST /file-documents/_doc
{
"id": "doc-001",
"fileName": "项目规划书.docx",
"createTime": "2023-10-27 10:00:00",
"@timestamp": "2023-10-27T10:00:00.000Z"
}注意写入数据还需要带有timestamp属性值。
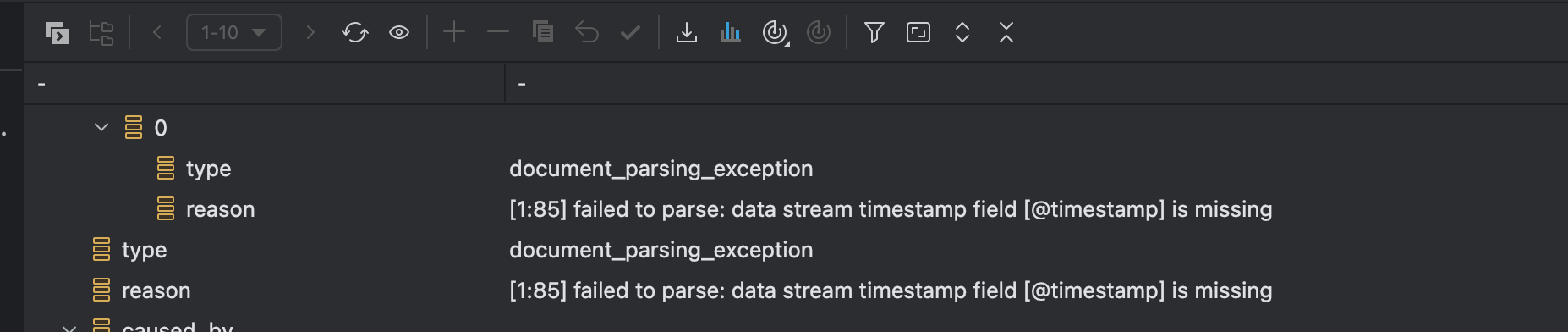
查询数据:
json
GET /file-documents/_search
{
"query": { "match_all": {} }
}查询索引值:
shell
GET /_cat/indices/file-documents
删除策略
shell
# 删除索引模板
DELETE /_index_template/file_document_template
# 查询索引
GET /_cat/indices/file-documents
# 删除索引
# 先查看再删除(推荐)
GET /_data_stream/file-documents
# 确认无误后执行删除
DELETE /_data_stream/file-documents
# 删除策略
DELETE /_ilm/policy/file_document_lifecycle_policy后续的一些策略
| 阶段 | 核心任务 | 架构特点 | 何时执行 |
|---|---|---|---|
| 第一阶段 (当前) | 部署高性能、简单的归档系统 | 数据流 + Hot-Only ILM | 立即执行 |
| 第二阶段 (扩展) | 角色分离,扩展热节点 | Master节点 + 专用Data节点 | 当热数据存储告急时 |
| 第三阶段 (优化) | 引入温节点,实现分层存储 | Hot节点 + Warm节点,ILM自动迁移 | 当存储成本成为主要矛盾时 |
步骤 1: 规划节点角色(为扩展做准备)
当前您的3个节点是"全能型"节点(兼具Master、Data、Ingest等角色)。扩展的第一步是角色分离。
- Master-eligible节点:负责集群状态管理,对CPU和内存要求高,对磁盘要求低。建议3台专用(利用现有机器)。
- Data节点:负责数据存储和查询,对磁盘和内存要求高。
- Coordinating-only节点(可选):负责接收请求、路由和聚合,对CPU和网络要求高。
步骤 2: 扩展热数据节点
当您的热数据(近期查询频繁的数据)总量接近当前SSD存储的70%时,开始扩展。
- 新增节点:购买新的、配置较高的机器(如更大的SSD),加入集群。
- 配置角色 :将新节点的
**elasticsearch.yml**配置为纯数据节点。yaml自动换行折叠复制
shell
node.roles: [ data, data_hot, ingest ]- 数据迁移:Elasticsearch 会自动在新的数据节点上均衡分片,无需手动干预。
资料获取
大家点赞、收藏、关注、评论啦~
精彩专栏推荐订阅:在下方专栏👇🏻
- 长路-文章目录汇总(算法、后端Java、前端、运维技术导航):博主所有博客导航索引汇总
- 开源项目Studio-Vue---校园工作室管理系统(含前后台,SpringBoot+Vue):博主个人独立项目,包含详细部署上线视频,已开源
- 学习与生活-专栏:可以了解博主的学习历程
- 算法专栏:算法收录
更多博客与资料可查看👇🏻获取联系方式👇🏻,🍅文末获取开发资源及更多资源博客获取🍅