7.1 升级Node.js版本
在学习Prisma之前,我们需要先将Node.js版本升级到24,24版本的Node.js是可以直接在终端运行ts后缀的文件(不需要编译)。
升级Node.js版本可以从Node.js官网重新下载:Node.js --- Node.js 版本,选择状态为Active LTS(保持活跃)的版本,如图7-1所示。
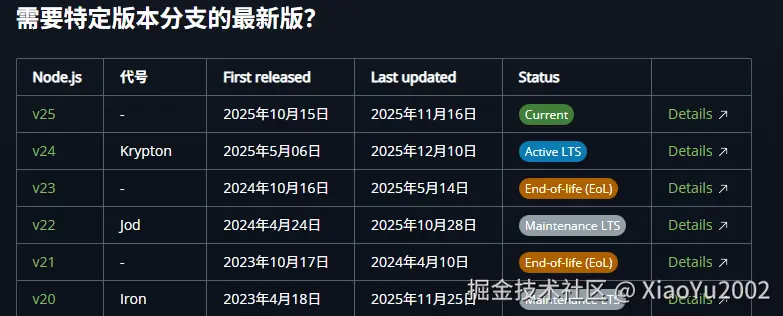
图7-1 Node.js官网安装
但重新下载Node.js版本还是过于麻烦,因此我推荐大家通过nvm来管理Node.js的版本,Win+R打开运行窗口输入cmd进入终端,通过以下命令升级。
ts
// 确认nvm有正确安装
nvm --version
// 安装最新版本的Node.js
nvm install 24.12.0Node.js的最新版本号从Node.js官网获取,点击如图7-1所示Status为Active LTS的Details,会跳出保持活跃的Node.js大版本细分,如图7-2所示。看到最新版本的v24.12.0(实际最新以你打开时为准),使用nvm install <Node.js版本>下载。
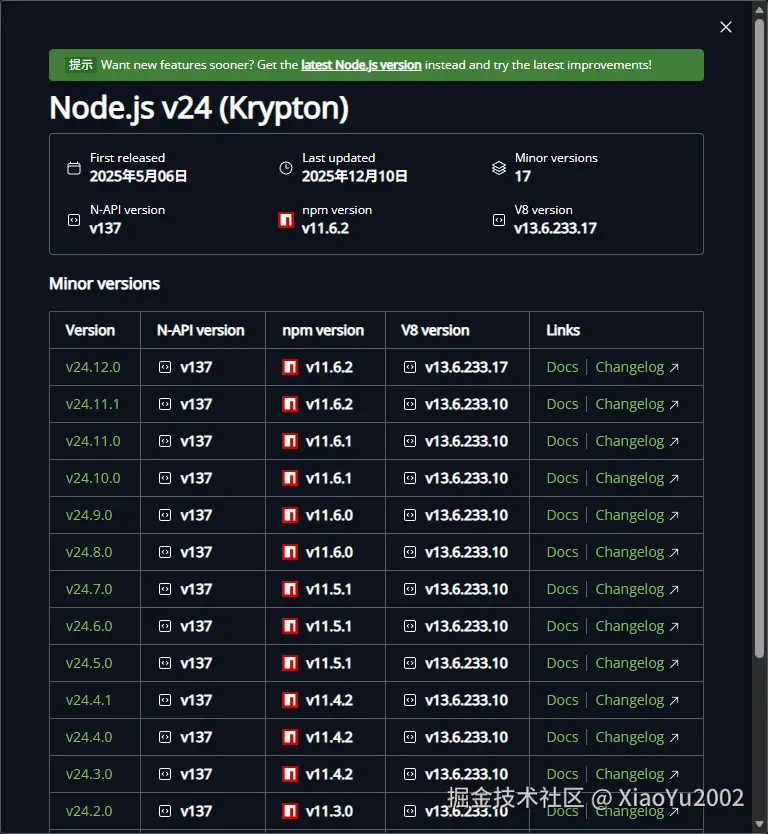
图7-2 保持活跃的Node.js大版本细分
使用nvm下载Node.js 24.12.0之后,通过node --version可以看见Node.js版本并不是最新的。因为需要使用以下nvm命令将Node.js版本切到最新,然后重新node --version就可以看到目前的Node.js版本已经是24.12.0了,操作如图7-3所示。
ts
// 显示电脑目前存在的所有Node.js版本和目前使用的Node.js版本
nvm list
// 切换为最新的Node.js版本24.12.0
nvm use 24.12.0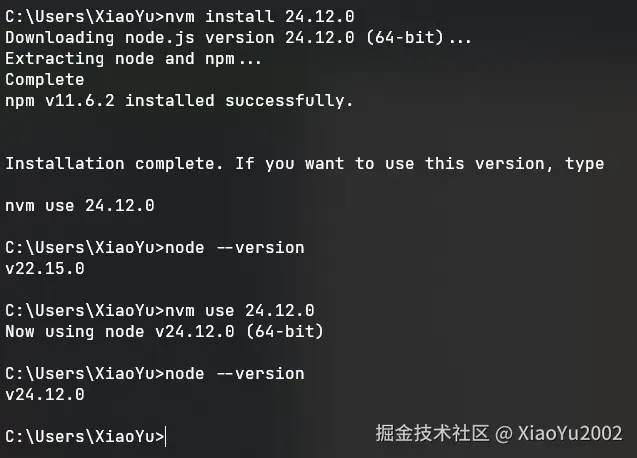
图7-3 安装最新版本的Node.js
接着打开vscode或者cursor的插件商店,安装插件Prisma,如图7-4所示。

图7-4 Prisma插件安装
7.2 Prisma安装
安装完成Node.js版本升级以及Prisma插件安装,开始正式学习Prisma。
首先什么是Prisma。正常情况下,我们的数据是存储在数据库里面,但如果我们需要操作数据库就需要编写SQL语句,而Prisma属于ORM框架的一种,ORM框架可以让我们通过面向对象的方式去操作数据库,也就是说通过编写JavaScript代码去自动生成SQL语句来操作数据库,我们就不需要去记忆这些SQL语句,还能防止SQL注入的风险。
现在我们重新启一个空项目(项目名:PRISMA)来安装学习Prisma。通过以下命令安装Prisma和客户端的包
ts
npm i prisma
npm i @prisma/client@prisma/client才是我们在代码里真正"用来操作数据库的库",而prisma本身是一个"生成它的工具(CLI + Generator)"。简单的说prisma是"造ORM的工具",@prisma/client是我们在用的ORM。
之所以要将@prisma/client单独拆成一个包,是为了解耦工具和运行时。CLI很大、更新频繁,而Client相对稳定,这两者不同频。这种思想理念,我们在学习Nest.js的业务合并就实践过,将业务数据格式层和业务数据层拆分开。
好的,通过以上概念,我们清楚了prisma这个第三方库其实是一个CLI工具,而CLI工具都有一系列配套命令的,就类似Nest CLI工具一样,总结如表7-1所示。
表7-1 Prisma CLI工具命令总结
| 命令 | 用途 |
|---|---|
| prisma init | 初始化项目 - 创建一个新的本地 Prisma Postgres 开发项目,生成 schema.prisma 等基础文件 |
| prisma dev | 启动开发服务器 - 启动一个本地的 Prisma Postgres 服务器用于开发 |
| prisma generate | 生成 Prisma Client - 根据 schema 生成类型安全的数据库客户端代码,每次修改 schema 后都需要运行 |
| prisma studio | 可视化数据库 - 打开一个 Web 界面,让你可以浏览和编辑数据库中的数据 |
| prisma migrate dev | 开发环境迁移 - 根据 schema 变更创建迁移文件,应用到数据库,并重新生成 Prisma Client(开发时最常用) |
| prisma db pull | 拉取数据库结构 - 从现有数据库反向生成/更新 schema.prisma(适用于已有数据库的项目) |
| prisma db push | 推送 schema 到数据库 - 直接将 schema 变更同步到数据库,不创建迁移文件(适合原型开发阶段) |
| prisma validate | 验证 schema - 检查 schema.prisma 文件的语法和配置是否正确 |
| prisma format | 格式化 schema - 自动格式化 schema.prisma 文件,使其更易读 |
| prisma version | 显示版本 - 查看当前安装的 Prisma 版本信息 |
| prisma debug | 调试信息 - 显示 Prisma 的调试信息,排查问题时有用 |
7.3 Prisma初始化
那么接下来就通过这个Prisma CLI工具来初始化prisma项目。因为我们没有全局安装CLI,所以采用npx从当下这个项目中去找Prisma CLI的命令,后续的操作都是这样。
ts
npx prisma init项目会额外生成1个文件夹(内含1个文件)和3个文件:
(1)Prisma文件夹:存放 Prisma 的核心配置文件schema.prisma,用于定义数据模型、数据库连接和生成器。schema.prisma文件用代码定义数据库表结构、关系和连接方式。
(2).env文件:存储环境变量,特别是 DATABASE_URL,用于安全配置数据库连接字符串而不暴露在代码中。
(3).gitignore文件:告诉 Git 忽略哪些文件(如 .env、node_modules),防止敏感信息或无关依赖被提交到版本库。
(4)prisma.config.ts文件:prisma的配置文件。
首先我们打开prisma.config.ts配置文件,最上方有两行注释,对应解释如下。需要我们通过npm安装prisma和dotenv,此时prisma我们已经安装了,而dotenv还没有安装需要安装一下。
ts
// This file was generated by Prisma and assumes you have installed the following:
// 这个文件是由Prisma生成的,假设你已经安装了以下软件
// npm install --save-dev prisma dotenv
// 通过npm安装prisma和dotenv通过以下命令安装dotenv。
ts
npm install --save-dev dotenv这个dotenv是用来读取环境变量的包,dot是英文里的点(.)的直译,整个名称.env就是指以点号开头的环境文件。安装dotenv之后,prisma.config.ts文件就可以通过env()去获取到环境变量。
ts
// prisma.config.ts
import "dotenv/config";
import { defineConfig, env } from "prisma/config";
export default defineConfig({
schema: "prisma/schema.prisma",
migrations: {
path: "prisma/migrations",
},
datasource: {
url: env("DATABASE_URL"),
},
});而环境变量在.env文件中,prisma.config.ts文件env()里的字符串"DATABASE_URL"会读取到.env文件中的环境变量。那么这个DATABASE_URL地址是做什么的?可以帮我们去连接数据库,默认生成的内容可以直接删除。
DATABASE_URL变量组成的三部分格式如图7-5所示。

图7-5 DATABASE_URL变量组成的三部分格式
ts
// .env
# Environment variables declared in this file are NOT automatically loaded by Prisma.
# Please add `import "dotenv/config";` to your `prisma.config.ts` file, or use the Prisma CLI with Bun
# to load environment variables from .env files: https://pris.ly/prisma-config-env-vars.
# Prisma supports the native connection string format for PostgreSQL, MySQL, SQLite, SQL Server, MongoDB and CockroachDB.
# See the documentation for all the connection string options: https://pris.ly/d/connection-strings
# The following `prisma+postgres` URL is similar to the URL produced by running a local Prisma Postgres
# server with the `prisma dev` CLI command, when not choosing any non-default ports or settings. The API key, unlike the
# one found in a remote Prisma Postgres URL, does not contain any sensitive information.
DATABASE_URL="prisma+postgres://localhost:51213/?api_key=省略"7.4 Prisma连接数据库
打开Prisma官方文档,官方文档会教我们如何去连接数据库。
官方文档:PostgreSQL database connector | Prisma Documentation。
DATABASE_URL变量占位符表示路径结构如图7-6所示。
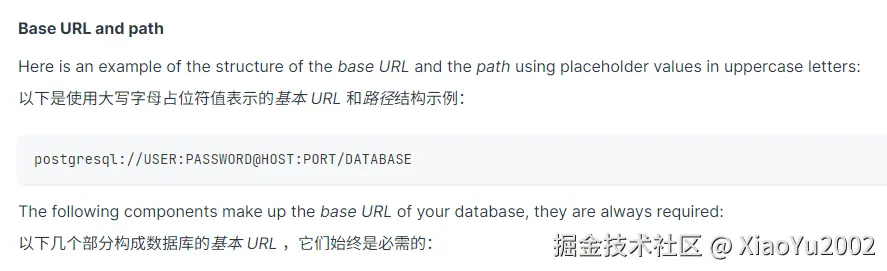
图7-6 DATABASE_URL变量占位符表示路径结构
可以看到DATABASE_URL的三部分组成分别是:
(1)需要连接的数据库名称:postgresql(或者mysql什么的)。
(2)数据库的登录信息。
(3)登录成功后,要连接的具体哪个数据库。
ts
postgresql://USER:PASSWORD@HOST:PORT/DATABASE在官方文档中,有一份英文的表格来说明这行的组成部分,我将它翻译成中文放在下方,如表7-2所示。
表7-2 DATABASE_URL占位符含义
| 名称 | 占位符 | 描述 |
|---|---|---|
| 主机 | HOST | 数据库服务器的 IP 地址或域名,例如 localhost |
| 端口 | PORT | 数据库服务器运行的端口,例如 5432 |
| 用户 | USER | 数据库用户名称,例如 janedoe |
| 密码 | PASSWORD | 数据库用户的密码 |
| 数据库 | DATABASE | 要使用的数据库名称,例如 mydb |
对于我们而言,主机是localhost(本地),端口是postgresql默认的5432(如果是自定义的话,要去看下是多少),用户名是postgres,密码是123456,具体数据库还没建(提前想个数据库名test,等下建)。
因此DATABASE_URL是:"postgresql://postgres:123456@localhost:5432/test"。将我们这份数据库地址拿到.env文件中使用。
通过编辑器插件找到DATABASE,新建数据库test。如图7-7所示。
图7-7 新建数据库test
到目前位置,我们就配置好了环境变量DATABASE_URL,接着就可以到prisma文件中的schema.prisma文件中去具体编写代码对数据库的操作了。
接下来我们要通过编写JavaScript代码,通过Primsa这个ORM框架转成SQL语句之后,对postgres数据库进行操作修改。我们有如下需求:
(1)在test数据库中创建User表,内部存在一定的字段。
(2)在test数据库中创建Post表,内部存在一定的字段。
用户表用于存放用户信息,而用户可以编写很多文章,所以有一个对应的文章表用于存放文章的一些信息,并将文章表和用户表关联起来。在这份 Prisma schema 中,用户表(User)与文章表(Post)之间建立的是"一对多"的关系:一个用户可以拥有多篇文章,而每一篇文章只属于一个用户。Prisma 通过外键字段 + 关系指令,把这种业务关系同时落实到了数据库结构和 ORM 层的访问方式中。
ts
// prisma/schema.prisma
// This is your Prisma schema file,
// learn more about it in the docs: https://pris.ly/d/prisma-schema
// Looking for ways to speed up your queries, or scale easily with your serverless or edge functions?
// Try Prisma Accelerate: https://pris.ly/cli/accelerate-init
generator client {
provider = "prisma-client"
output = "../generated/prisma"
}
datasource db {
provider = "postgresql"
}
// 以下是编写的代码
// 用户表
model User {
id String @id @default(cuid())
email String @unique
password String
posts Post[]
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
// 文章表
model Post {
id String @id @default(cuid())
title String
content String
userId String
user User @relation(fields: [userId], references: [id], onDelete: Cascade, onUpdate: Cascade)
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}Prisma通过以下4步实现表关联:
(1)第一步是在文章表中引入外键字段。在Post模型里,userId String这个字段就是外键,它用于存放所属用户的id。从数据库角度看,这意味着Post表中每一行数据,都通过userId指向User表中的某一条记录,这是表关联最核心、也是最底层的实现方式。
(2)第二步是通过@relation明确外键指向规则。user User @relation(fields: userId, references: id) 这一行告诉 Prisma:Post.userId对应的是User.id。fields 表示当前表中作为外键的字段,references 表示被引用表中的目标字段。这样一来,Prisma 在生成数据库结构时,会创建一条正式的外键约束,保证文章只能关联到真实存在的用户。
(3)第三步是在用户表中定义反向关系。User 模型中的posts Post\[\]并不会在数据库里额外生成字段,它只是一个"关系描述"。它的作用是告诉Prisma:一个用户可以关联多条文章记录。借助这一声明,Prisma Client才能在代码中提供诸如 prisma.user.findMany({ include: { posts: true } })这样的查询能力,实现从用户反查文章的能力。
(4)第四步是通过级联规则保证数据一致性。在@relation中配置的onDelete: Cascade和onUpdate: Cascade表示:当用户被删除或其主键被更新时,与之关联的文章会自动同步删除或更新。这一规则由数据库层执行,避免出现"文章存在,但作者已不存在"的脏数据问题,也让业务层不需要手动处理关联清理逻辑。
7.5 schema.prisma文件执行
如果我们要将schema.prisma文件中,用JavaScript代码编写的内容转为SQL语句执行到数据库,要怎么做?需要我们运行迁移文件的一个命令。表7-1所示的prisma migrate dev,即根据schema变更创建迁移文件,应用到数据库,并重新生成Prisma Client。
--name:为本次迁移创建一个描述性名称(必填参数)。这个名称会成为我们迁移文件夹的一部分,用于清晰记录这次迁移的目的(例如这是我们第一次迁移,所以取名init)。
ts
npx prisma migrate dev --name initschema.prisma文件执行如图7-8所示。淡灰色内容从上往下的意思分别是:
(1)已从Prisma.config.ts文件中加载配置,也就是读取DATABASE_URL。
(2)从schema.prisma文件中加载Prisma模式,然后连接上PostgreSQL数据库。
然后进行应用迁移,迁移文件是20251214151823_init,其实是执行迁移命令的时间点加下划线和--name取的名字所组成的,所以能够看到我执行命令的时间是2025年12月14号。最后一行绿色英文说明的是我们的数据库和模式同步了。
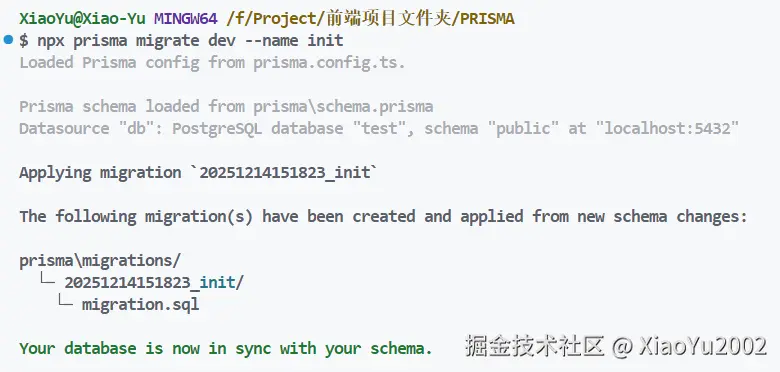
图7-8 schema.prisma文件执行
文件迁移完成之后,会根据新的模式更改创建并应用,在prisma文件夹下创建migrations文件夹,这个文件夹就专门用来存放迁移文件的,里面有我们的20251214151823_init文件夹,而20251214151823_init文件夹里就有我们JavaScript代码所转化生成的SQL代码文件:migration.sql。让我们打开这个SQL迁移文件,看里面都有哪些内容?
ts
// migration.sql
-- CreateTable
CREATE TABLE "User" (
"id" TEXT NOT NULL,
"email" TEXT NOT NULL,
"password" TEXT NOT NULL,
"createdAt" TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP,
"updatedAt" TIMESTAMP(3) NOT NULL,
CONSTRAINT "User_pkey" PRIMARY KEY ("id")
);
-- CreateTable
CREATE TABLE "Post" (
"id" TEXT NOT NULL,
"title" TEXT NOT NULL,
"content" TEXT NOT NULL,
"userId" TEXT NOT NULL,
"createdAt" TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP,
"updatedAt" TIMESTAMP(3) NOT NULL,
CONSTRAINT "Post_pkey" PRIMARY KEY ("id")
);
-- CreateIndex
CREATE UNIQUE INDEX "User_email_key" ON "User"("email");
-- AddForeignKey
ALTER TABLE "Post" ADD CONSTRAINT "Post_userId_fkey" FOREIGN KEY ("userId") REFERENCES "User"("id") ON DELETE CASCADE ON UPDATE CASCADE;migration.sql文件里面的SQL语句不需要我们再去执行一遍,JavaScript代码转化生成SQL语句的时候就已经执行过了,一般情况下,我们不需要关心migration.sql文件,它的作用更像是为我们每一次执行SQL语句存档备份。
接下来我们看下test数据库里的表结构,看User表和Post表是否成功添加到数据库中。schema.prisma文件成功执行修改数据库,如图7-9所示。
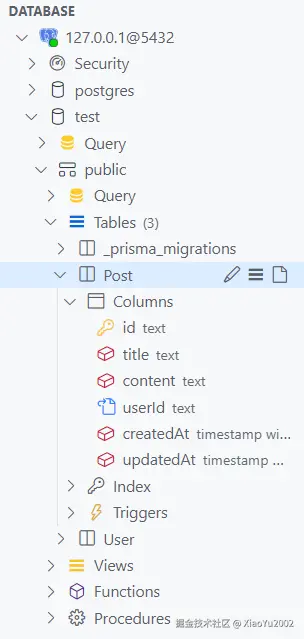
图7-9 schema.prisma文件成功执行修改数据库
在执行schema.prisma文件中的JavaScript代码并转化为SQL文件执行到数据库中之后。我们还需要执行以下一个Prisma命令,这个命令是每次执行schema.prisma文件之后都要运行一遍的。
ts
npx prisma generate这个命令是生成一个客户端文件的,生成的位置要从schema.prisma文件中查看,如下output所对应的路径就是客户端文件的生成位置。
ts
// src/prisma/schema.prisma
generator client {
provider = "prisma-client"
output = "../generated/prisma"
}终端执行prisma generate命令如图7-10所示。

图7-10 终端执行prisma generate命令
prisma generate 命令会根据当前的 schema.prisma 生成一系列文件,如图 7-11 所示。由于 schema.prisma 发生变更后,Prisma Client 的结构也需要随之更新,因此每当修改 schema 文件时,都需要重新执行一次 prisma generate。
从本质上看,prisma generate 的作用是将 schema.prisma 中对数据模型、关系和约束的描述,转换为应用程序可以直接使用的 Prisma Client 代码。schema.prisma 本身只是一种用于描述数据库结构的声明式语言,无法被 Node.js 直接执行。
因此,Prisma 需要在生成阶段,将这些抽象的结构信息转化为包含运行时代码与 TypeScript 类型定义的 ORM 客户端实现。这样一来,开发者才能在 JavaScript / TypeScript 代码中,以类型安全的方式操作数据库,并持续获得准确的代码提示和参数校验。
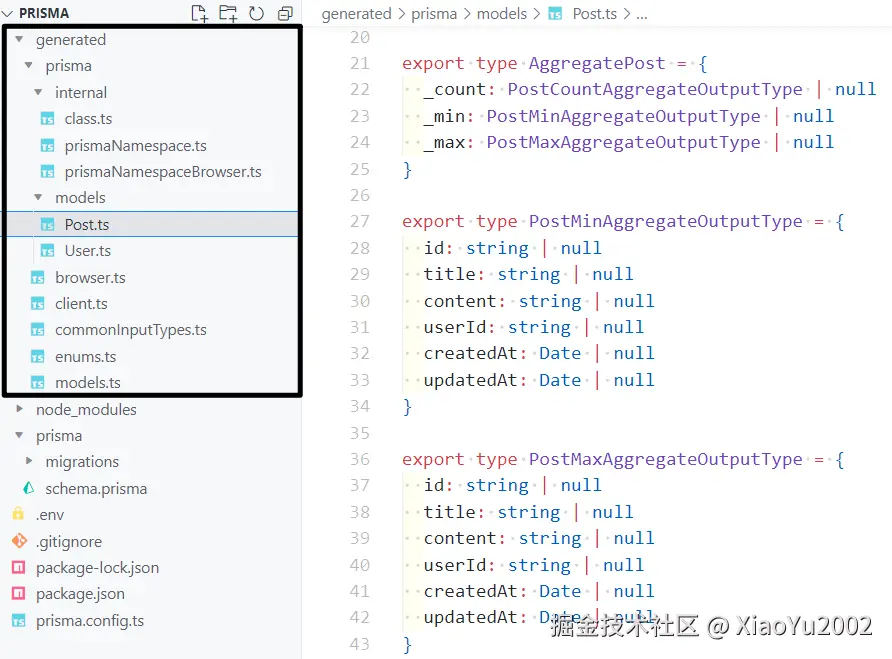
图7-10 prisma generate命令生成文件
第一类被生成的文件是Prisma Client的核心代码。这些文件会被放在我们配置的output目录(如 ../generated/prisma)或默认的 node_modules/@prisma/client 中。它们定义了PrismaClient类以及prisma.user.findMany()、prisma.post.create() 等 API。生成的代码完全基于我们的 model 定义,因此我们只能访问schema中真实存在的表和字段,这也是Prisma能做到"写错字段名直接编译报错"的根本原因。
第二类文件是TypeScript类型定义(.d.ts)。这些类型文件描述了每个模型的字段类型、可用的查询参数、返回结果的结构以及关联关系的形态。它们让编辑器能够在我们写查询时提供自动补全、参数校验和返回值推导。换句话说,prisma generate把数据库结构"投射"成了TypeScript的类型系统,让数据库约束在代码层面就能被发现和约束。
第三类文件是 查询引擎与运行时绑定代码。Prisma在底层并不是直接用JS拼SQL,而是通过一个高性能的查询引擎(基于Rust)来执行查询。生成的文件中包含了JS与查询引擎之间的桥接逻辑、序列化规则以及错误映射机制。这一步的存在,是Prisma在复杂查询、事务和性能表现上稳定可靠的关键原因。
之所以必须"生成"这些文件,而不是在运行时动态解析schema,是因为这种方式可以在启动前完成所有结构分析与校验。一旦生成完成,运行时只需要调用已经确定结构和类型的代码,既减少了性能开销,也避免了在生产环境中因schema错误而产生不可预期的问题。这也是 Prisma 非常适合Serverless和Edge场景的原因之一。
接下来,我们来梳理一下思路:
通过prisma migrate dev命令,我们同时做了3件事情:
(1)对比 schema.prisma 和当前数据库。
(2)生成一份迁移 SQL 文件。
(3)把这份 SQL 真正执行到数据库。
到这一步为止,SQL 都已经执行到数据库里了,如果从"数据库存在与否"的角度看,确实已经结束了。那为什么还要 prisma generate?它到底在补什么?
migrate解决的是数据库长什么样,而generate解决的是我们在代码里怎么用它。如果我们现在"不 generate",会发生什么?假设一个情况:现在只有数据库(表已经存在了)和migration SQL,没有Prisma Client。
然后我们在代码文件里写以下这行代码。
ts
const user = await prisma.user.findMany()就会出现问题了,prisma.user是谁?.findMany() 是谁定义的?返回值是什么结构?答案是:没人知道。因为数据库不会"反向生成 JS API",SQL不会自动变成TypeScript类型,而Node.js更不会认识我们的schema。
到这里,我们可以更深刻的意识到,我们使用的Prisma是一个ORM框架,通过JavaScript代码转化成SQL语句执行后,我们也需要数据库中的表、字段等信息提供给我们一定量的代码提示,方便我们以JavaScript的形式继续写下去并且持续获得良好的提示反馈。例如我们要新增一个字段,但其实表中已经有这个字段了,要删除一个字段,而表中其实没有这个字段,如果没有类型约束,这类错误往往要等到运行时甚至线上才暴露。很多操作都需要有良好的代码提示,否则我们很难持续的用JavaScript代码去操作数据库。
7.6 Prisma增删改查
7.6.1 PrismaClient的引入
完成了一次Prisma的基础建设:项目初始化、连接数据库、执行schema.prisma文件操作数据库以及通过prisma generate生成对应的数据库客户端代码。接下来我们会通过Prisma做一次基础的增删改查,前置要求为以下2点:
(1)在PRISMA项目下创建index.ts文件,用于写入增删改查代码。
(2)在package.json文件中添加"type"字段,设置为module,开启ESM语法。
ts
// Prisma旧版本写法
import { PrismaClient } from "@prisma/client"
// Prisma7新版本写法
import { PrismaClient } from "./generated/prisma/client.ts";编写增删改查的代码,我们需要引入PrismaClient,因为PrismaClient是数据库操作的统一入口。在Prisma旧版本中,是存放在@prisma/client中,而在目前Prisma7版本中,是存放在./generated/prisma/client下,也就是通过prisma generate命令生成的数据库客户端代码中。
但Prisma新版本为什么把 PrismaClient从@prisma/client"挪出来"?
在旧版本 Prisma 中,PrismaClient 是通过 @prisma/client 这个包直接引入的。虽然这种方式使用起来非常方便,但它在工程语义上存在一个隐含问题:Prisma Client 实际上是根据当前项目的 schema.prisma 动态生成的代码,却被放置在 node_modules 这样一个本应只存放第三方依赖的目录中。这会模糊"外部依赖"和"项目生成代码"之间的边界,使生成物的来源和职责不够清晰。
随着项目规模变大,这种设计的局限逐渐显现。例如在多数据库、多 schema 或 Monorepo 的场景下,项目往往需要同时维护多个 Prisma Client。旧的引入方式只能依赖包名区分,不仅结构笨拙,也不利于表达不同 Client 在项目中的实际角色。此外,在 Serverless、Edge Runtime 或使用现代构建工具时,node_modules 可能被裁剪或重组,导致生成的 Prisma Client 不易被稳定、明确地管理。
因此,在新版本中,Prisma 将生成的 Client 明确输出到项目内的指定目录,并通过相对路径进行引入。这一变化本质上是将 Prisma Client 从"隐藏在依赖中的黑盒"转变为"项目中的显式生成产物"。生成代码的位置、来源和用途都变得一目了然,也更符合"生成代码属于项目本身"的直觉。
这种调整带来的直接好处是工程结构更加清晰。每一个 Prisma Client 都有明确的输出路径和语义位置,天然支持多 Client 并存,也更适合在 Monorepo 或分层架构中进行统一管理。同时,构建工具和部署环境也能更准确地识别和打包这些生成文件,减少因环境差异带来的不确定性。
因此Prisma 新版本中 PrismaClient 引入方式的变化是工程理念上的升级:通过显式化生成代码的位置,明确区分第三方依赖与项目生成物,从而让 Prisma 在复杂工程和现代运行环境中更加可控、可靠。
7.6.2 适配器
完成PrismaClient的引入后,由于我们使用的是PostgreSQL数据库,所以还需要引入对应的适配器。Prisma针对不同数据库存在不同的"适配层",例如MySQL的适配器和PostgreSQL的适配器不是同一个,而这是ORM能够成立的一个必要前提,不是可有可无的设计。
首先,Prisma 并不是直接执行一套"通用 SQL"。虽然我们在代码里写的是统一的 Prisma Client API,但底层真正执行的,是针对具体数据库生成并优化过的查询逻辑。PostgreSQL、MySQL、SQLite、SQL Server 在 SQL 方言、数据类型、约束行为以及事务语义上都有大量差异,如果没有适配层,ORM 就只能支持"最小公分母"(即SQL语言中保持一致的部分),功能和性能都会被严重限制。
其次,适配器的存在是为了屏蔽数据库差异,向上提供统一模型。Prisma 的目标,是让我们在 JavaScript / TypeScript 层面始终面对一致的模型定义和查询方式。为了实现这一点,Prisma 必须在底层为每一种数据库实现一套映射规则:如何把 String 映射成具体数据库的列类型,如何实现 @default(now()),如何生成外键约束,如何处理 onDelete: Cascade 等行为。这些逻辑无法通过一套通用规则完成,只能针对不同数据库分别实现。
再次,不同数据库在"能力边界"上的差异,决定了适配器必须不同。例如,PostgreSQL 支持原生的 JSONB、数组类型、复杂索引和更强的事务隔离能力,而 SQLite 在并发和约束能力上相对有限,MySQL 在时间精度、大小写敏感性等方面也有自身特性。Prisma 的适配器不仅要"能跑",还要确保行为符合该数据库的真实语义,否则就会出现"代码看起来没问题,但数据库行为完全不一致"的风险。
所以Prisma为不同数据库提供不同适配器,并不是为了增加复杂度,而是为了在"统一抽象"和"数据库之间存在差异"之间取得平衡。适配器的作用,是把各数据库千差万别的实现细节收敛到底层,让上层的 Prisma Client 保持稳定、可预测、类型安全,从而确保ORM能够在复杂工程中长期使用。
PostgreSQL适配器文档如图7-11所示,Prisma给每一个数据库都编写了对应的适配器使用文档。文档地址:PostgreSQL database connector | Prisma Documentation。
图7-11 PostgreSQL适配器文档
接下来通过npm命令来安装适配器。
ts
npm install @prisma/adapter-pg安装完成之后,通过以下命令引入并且使用。使用process读取环境变量会报错,错误如下:
找不到名称"process"。是否需要安装 Node.js 的类型定义? 请尝试运行 npm i --save-dev @types/node。把这行npm命令在终端执行就可以消除报错了。
ts
// src/index.ts
// 引入环境变量
import 'dotenv/config'
// 引入适配器
import { PrismaPg } from '@prisma/adapter-pg'
import { PrismaClient } from './generated/prisma/clien.ts'
// 连接的数据库地址,通过环境变量读取
const connectionString = `${process.env.DATABASE_URL}`
console.log(connectionString)我们直接使用node执行index.ts文件(引入的PrismaClient所对应的路径来源client需要加后缀.ts),看环境变量能否正常读取。实际是可以的,读取内容不再展示。
确认可以读取到环境变量后,通过以下两行代码对prisma进行初始化,主要做的事情是先创建一个"如何与 PostgreSQL 对话"的适配器,再把这个适配器交给 PrismaClient,让 Prisma 知道"底层该用哪种方式连数据库并执行 SQL"。
ts
const adapter = new PrismaPg({ connectionString })
const prisma = new PrismaClient({ adapter })先连接一下数据库,看能否正常连接。
ts
// src/index.ts
// 引入环境变量
import 'dotenv/config'
// 引入适配器
import { PrismaPg } from '@prisma/adapter-pg'
import { PrismaClient } from './generated/prisma/client.ts'
// 连接的数据库地址,通过环境变量读取
const connectionString = `${process.env.DATABASE_URL}`
const adapter = new PrismaPg({ connectionString })
const prisma = new PrismaClient({ adapter })
const main = async () => {
await prisma.$connect()
console.log('连接数据库成功')
}
main()
// 连接数据库成功接下来,我们就可以基于prisma实例对象去进行增删改查的操作。
7.6.3 增删改查操作
增删改查通过prisma实例对象里的一些方法去实现。并且由于通过prisma generate命令生成的数据库客户端代码有对应的声明文件,因此在编写代码操作时,是由对应的代码提示的,例如想操作数据库在哪张表(post表/user表),如图7-12所示。
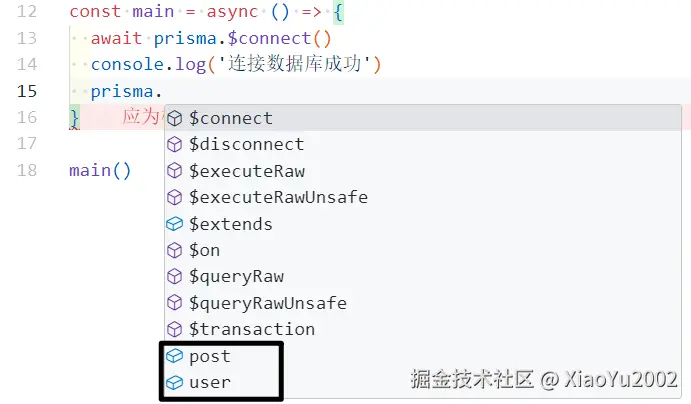
图7-12 声明文件的作用
新增操作对应的是 create() 和 createMany() 方法,当我们调用 prisma.user.create() 时,Prisma 会根据 schema 中的字段定义,强制我们提供所有必填字段,并自动处理默认值(如 cuid()、now())。而对于需要批量插入数据的场景,则可以使用 createMany()方法,它会在保持结构校验的同时,减少数据库往返次数,提高效率。
ts
// src/index.ts
const main = async () => {
await prisma.$connect()
console.log('连接数据库成功')
const user =await prisma.user.create({
data:{
email:'test@test.com',
password:'123456'
}
})
console.log(user)
}通过prisma实例对象的create创建方法成功创建数据之后,是有返回值的,通过打印返回值可见id、email、password,createAt和updateAt这些字段,如图7-13所示。这些返回信息可以有效提示数据是否创建成功,从数据库中可查看到user表的对应新增数据。

图7-13 创建数据的返回信息
除此之外,还可以同时创建子表的对应数据,都非常方便,不需要我们去编写SQL语句,而是用面向对象的方式就完成需求。
查询:对应 Prisma 中的 findMany()、findUnique()、findFirst()等方法。例如,通过 prisma.user.findMany(),可以一次性获取用户表中的多条记录;而 findUnique()方法则要求查询条件必须命中唯一约束(如 id 或 email字段)。Prisma 会根据 schema 中定义的唯一性规则,在代码层面就限制我们只能写合法的查询条件,避免在运行时才发现查询逻辑错误。
此外,查询操作还可以通过 where、select、include 等参数进行精确控制,在 JavaScript 层就能清晰表达"我要什么数据",而不需要关心 SQL 的拼接细节。
修改:主要通过update()和updateMany()实现。update()方法要求提供一个唯一条件(例如 id),以确保"我们要改的是哪一条数据";updateMany()方法则适用于批量更新,但不会返回具体修改后的记录。
Prisma 在更新操作中非常强调明确性:必须清楚地告诉它"更新哪条数据"和"更新哪些字段",而不能像手写 SQL 那样随意省略条件。这种设计可以有效避免误操作,比如一次不小心更新整张表。同时,Prisma 会自动维护诸如@updatedAt这样的字段,让更新时间的逻辑从业务代码中彻底消失。
删除:对应delete()和deleteMany()方法。delete()方法同样需要唯一条件,确保你删除的是一条明确的数据;deleteMany()方法则允许批量删除。这里 Prisma 的优势在于:删除行为会受到 schema 中关系定义的约束。例如我们在 Post 和 User 的关系中配置了 onDelete: Cascade,那么当我们删除用户时,Prisma 会配合数据库自动删除关联的文章,保证数据不会"断链"。这些规则不是写在业务代码里的,而是写在 schema 中,由 Prisma 和数据库共同维护。
对应的代码逻辑如下。
ts
// src/index.ts
// 查询所有用户
const users = await prisma.user.findMany()
// users 是 User[]
// 按唯一字段查询单个用户(如 email)
const user = await prisma.user.findUnique({
where: {
email: 'test@test.com'
}
})
// user 是 User | null
// 根据唯一字段(id 或 email)修改用户信息
const updatedUser = await prisma.user.update({
where: {
email: 'test@test.com'
},
data: {
password: 'new-password'
}
})
// 返回修改后的用户对象
// 根据唯一字段删除用户
const deletedUser = await prisma.user.delete({
where: {
email: 'test@test.com'
}
})
// 返回被删除的用户对象总体来说,增删改查除了最基础的用法,还有很多丰富的进阶的方法或者扩展的方式(例如通过where限制条件),唯一的区别是操作的细度不同。正常的增删改查是不需要通过prisma generate命令去重新生成数据库客户端代码的,是否执行prisma generate命令基本上取决于我们是否修改并更新schema.prisma文件。
7.6.4 查询参数
如果通过where限制条件,可利用面向对象的方式,更加灵活的去使用。例如当多条操作的限制条件一致是,可将where抽象出来,并通过TypeScript的类型提示来辅助我们。例如我想要限制的目标对象是Post对象,就可以从generated文件夹下的prisma文件夹的models文件夹(内有Post.ts和User.ts文件)中拿到对应的代码提示,这是通过prisma generate命令自动生成类型提示文件。
ts
// src/index.ts
// 引入环境变量
import 'dotenv/config'
// 引入适配器
import { PrismaPg } from '@prisma/adapter-pg'
import { PrismaClient } from './generated/prisma/client.ts'
import type { UserWhereInput } from './generated/prisma/models/User.ts'
// 连接的数据库地址,通过环境变量读取
const connectionString = `${process.env.DATABASE_URL}`
const adapter = new PrismaPg({ connectionString })
const prisma = new PrismaClient({ adapter })
const main = async () => {
await prisma.$connect()
console.log('连接数据库成功')
const where: UserWhereInput = {
email: {
// 包含的查询
contains: "test",
}
}
// 查询符合条件的用户
const users = await prisma.user.findMany({
where: where
})
// 查询符合条件的数据有几条
const count = await prisma.user.count({ where })
console.log(users, count)
}
main()并且通过对象的语法糖写法,可以将{where:where}简写成{where}。除此之外还可以包含子集的查询。
ts
const users = await prisma.user.findMany({ where: where })
// 语法糖写法
const count = await prisma.user.count({ where })排序和数据库中的操作方式类似,通过orderBy进行排序。
ts
const users = await prisma.user.findMany({
orderBy: {
email: 'asc' // 升序:asc 降序:desc
}
})而如果想进行多个条件的排序,则需要换成数组,不能使用对象的形式。会根据数组中的对象顺序去排序,例如下方示例中,先通过email去排序,在以上排序基础上,再通过posts去排序。
ts
const users = await prisma.user.findMany({
orderBy: [
// 多个条件的排序
{ email: 'asc' },
{ posts: { _count: 'desc' } }
]
})如果想要分页获取数据,要怎么做?这是一个经典的案例,前端传入两个参数,第几页以及每页多少条数据。后端再返回对应的数据给前端。在后端,通过skip跳过数据后,然后通过take获取需要的数据数量。
ts
// 前端传递的参数 第2页以及每页10条数据,
const page = 2
const pageSize = 10
//1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
const users = await prisma.user.findMany({
skip: (page - 1) * pageSize, // 跳过10条数据
take: pageSize, // 取10条数据
where: where
})在Prisma中,像 where、orderBy、select、include 这些查询参数(Query Arguments)被称为Prisma Client 查询参数对象(Query Arguments Object)。它们是Prisma定义的一套查询 DSL(领域特定语言),用来描述"你想怎么查数据"。
常见的查询参数对象有如下6种:
(1)过滤条件where:等值查询、范围查询、模糊查询,关系过滤。
(2)排序规则orderBy:排序结果(使用对象),多字段排序(使用数组)。
(3)字段选择select:描述"我只要哪些字段",会直接影响返回值的 TypeScript 类型。
(4)关联加载include:描述"是否一起查关联表"。
(5)分页控制skip/take:描述"从哪开始,取多少条"。
(6)去重distinct:描述"按某字段去重"。
7.6.5 事务
事务是数据库非常经典的概念。事务是一个或一系列操作的最小逻辑单元。在这个逻辑单元中的所有语句,要不都执行成功,要么都执行失败,不存在任何中间状态,一旦事务执行失败,那么所有的操作都会被撤销,一旦事务执行成功,那么所有的操作结果都会被保存。
学习事务有一个经典的案例,转账操作,即A向B转账200元。A账户余额有1000元,B账户余额0元,在这个基础上查询A账户余额,看金额是否大于200元,满足条件则先从A账户扣款200元,然后再向B账户增加200元。
如果没有数据库事务为我们保驾护航,那么在上面转账过程中间任何一步出现了问题,无论是网络异常还是服务器宕机等,都是需要我们工程师自己去考虑各种异常边界情况来保证双方账户金额的准确性,防止例如A账户扣款了,结果B账户没变化等情况,这直接导致我们编程的复杂性急剧上升。
所以,有了数据库层面的事务保证,能够降低我们的开发难度,很多问题交给事务去处理就好了。而事务不是天生就有的,事务的产生其实是为了当应用程序访问数据库的时候,事务能够简化我们的编程模型,不需要我们去考虑各种各样的潜在错误和并发问题。
在Prisma中,通过$transaction() API来完成事务的操作,有两种使用方式,如图7-14所示。

图7-14 $transaction API使用方式
通过事务来完成转账操作代码示例如下。
ts
/**
* 场景说明:
* A 向 B 转账 200 元
* A 初始余额:1000
* B 初始余额:0
* 只有当 A.balance >= 200 时,才允许转账
*/
/* ============================
一、顺序事务(Sequential)
============================ */
await prisma.$transaction([
// 1️⃣ 查询 A 账户余额
prisma.account.findUnique({
where: { id: 'A' },
select: { balance: true }
}),
// 2️⃣ A 扣除 200
prisma.account.update({
where: { id: 'A' },
data: {
balance: { decrement: 200 }
}
}),
// 3️⃣ B 增加 200
prisma.account.update({
where: { id: 'B' },
data: {
balance: { increment: 200 }
}
})
])
/**
* 特点:
* - 只能传 Prisma 查询
* - 顺序执行
* - ❌ 无法写 if / 校验逻辑
* - 更适合「已确定一定要执行的 SQL 操作」
*/
/* ============================
二、交互式事务(Interactive)
============================ */
await prisma.$transaction(async (tx) => {
// 1️⃣ 查询 A 的余额
const accountA = await tx.account.findUnique({
where: { id: 'A' }
})
// 2️⃣ 余额校验(普通 JS 逻辑)
if (!accountA || accountA.balance < 200) {
throw new Error('余额不足,转账失败')
}
// 3️⃣ A 扣款 200
await tx.account.update({
where: { id: 'A' },
data: {
balance: { decrement: 200 }
}
})
// 4️⃣ B 收款 200
await tx.account.update({
where: { id: 'B' },
data: {
balance: { increment: 200 }
}
})
})
/**
* 特点:
* - ✅ 可以写 if / try-catch / 循环
* - ✅ 可以混合业务逻辑
* - 出错自动回滚
* - 转账 / 下单 / 扣库存 等强一致场景首选
*/7.6 Prisma Schema规则
Prisma Schema 的所有规则,只来自一个地方:Prisma Schema Language(PSL)文档。Prisma官方文档明确的把用JavaScript操作数据库的方式当成一门语言,而不是"配置文件"。
我们需要记住两个核心文档:
(1)Schema 总览:www.prisma.io/docs/orm/re...
(2)Model / Field / Attribute 说明:www.prisma.io/docs/orm/re...
像7.4小节的表关联中使用了大量@开头的,在官方文档里都属于Attribute(属性指令)。@开头的东西,本质是Prisma Schema 的"编译指令",它们的作用不是给JS/TS用的,而是用来给Prisma提示如何建表、建索引、生成 Client API,处理关联关系以及生成 SQL等等操作的。
在Prisma主要使用的类型有4种,如表7-3所示。
表7-3 Prisma Schema类型分类总结
| 类型 | 例子 | 作用范围 |
|---|---|---|
| 字段属性(Field Attribute) | @id @default() | 单个字段 |
| 模型属性(Model Attribute) | @@unique @@index | 整个模型 |
| 函数 | cuid() now() | 生成默认值 |
| 关系指令 | @relation() | 表关系 |
接下来我们总结一份写 Prisma Schema 时,80%的时候会用到的内容,按照4种类型分类,分别如表7-4、表7-5,表7-4和表7-7所示。
表7-4 Prisma Schema的字段属性表
| 指令 | 作用 | 常见用法说明 |
|---|---|---|
| @id | 主键 | 标记字段为主键 |
| @default(value) | 默认值 | 如 now()、cuid()、autoincrement() |
| @unique | 唯一约束 | 自动创建唯一索引 |
| @updatedAt | 自动更新时间 | 每次更新自动写入当前时间 |
| @map("column_name") | 映射字段名 | Prisma 字段名 ≠ 数据库列名 |
| @db.VarChar(n) | 指定数据库类型 | 精确控制数据库字段类型 |
表7-4 Prisma Schema的函数模型表
| 指令 | 作用 | 示例 |
|---|---|---|
| @@map("table_name") | 映射表名 | 数据库表名不同于 model 名 |
| @@unique(fields) | 复合唯一索引 | @@unique([email, type]) |
| @@index(fields) | 普通索引 | 提高查询性能 |
| @@id(fields) | 复合主键 | 多字段主键 |
表7-3 Prisma Schema的关系指令表
| 指令 | 作用 | 说明 |
|---|---|---|
| @relation | 定义表关系 | 指定外键、引用字段 |
| fields | 当前模型的外键字段 | 如 [userId] |
| references | 关联目标字段 | 如 [id] |
| onDelete | 删除级联策略 | Cascade / Restrict / SetNull |
| onUpdate | 更新级联策略 | Cascade / Restrict |
表7-7 Prisma Schema的函数表
| 函数 | 作用 | 常见场景 |
|---|---|---|
| now() | 当前时间 | createdAt |
| cuid() | 字符串唯一 ID | 分布式友好 |
| uuid() | UUID | 与其他系统兼容 |
| autoincrement() | 自增 ID | 传统整数主键 |
当然啊,我们这并不是应试考试,不需要去背指令,而是会看schema,知道去哪查(官方文档)以及 理解每个指令在数据库层 & Client 层的影响。
推荐的学习顺序如下:
(1)@id / @default / @unique。
(2)一对多关系(@relation)。
(3)@@index / @@unique。
(4)字段映射 @map / @@map。
(5)数据库类型 @db.*。
在这一篇文章中,当然是不会一个指令一个指令的去解释的,我觉得等到在英语AI项目中,根据实际业务情况,有了具体的方向,再去分析会更好,到时候可以结合着官方文档去学习。