新年刚至,陈天桥携手代季峰率先打响开源大模型的第一枪。
正式发布其自研的旗舰版搜索智能体模型------MiroThinker 1.5,堪称智能体模型领域的最强小钢炮。
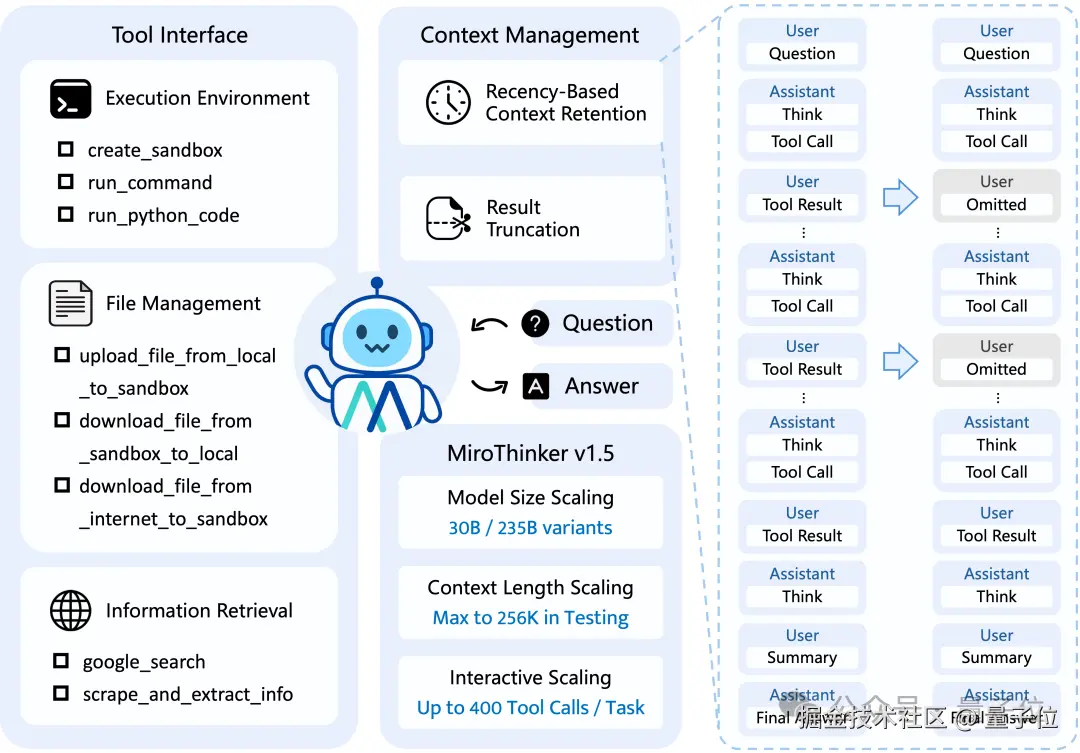
最直观的还是基准测试上的性能评测:
在面对 GPT-5-High、Gemini-3-Pro、DeepSeek-V3.2 等一系列国内外顶尖模型,MiroThinker 1.5 在四项基准测试中的表现都毫不逊色:
-
HLE-Text_(人类终极测试)_:39.2%
-
BrowseComp_(网页检索类大模型基准测试)_:69.8%
-
BrowseComp-ZH_(BrowseComp 的中文适配版本)_:71.5%
-
GAIA-Val-165_(GAIA 基准测试验证集)_:80.8%
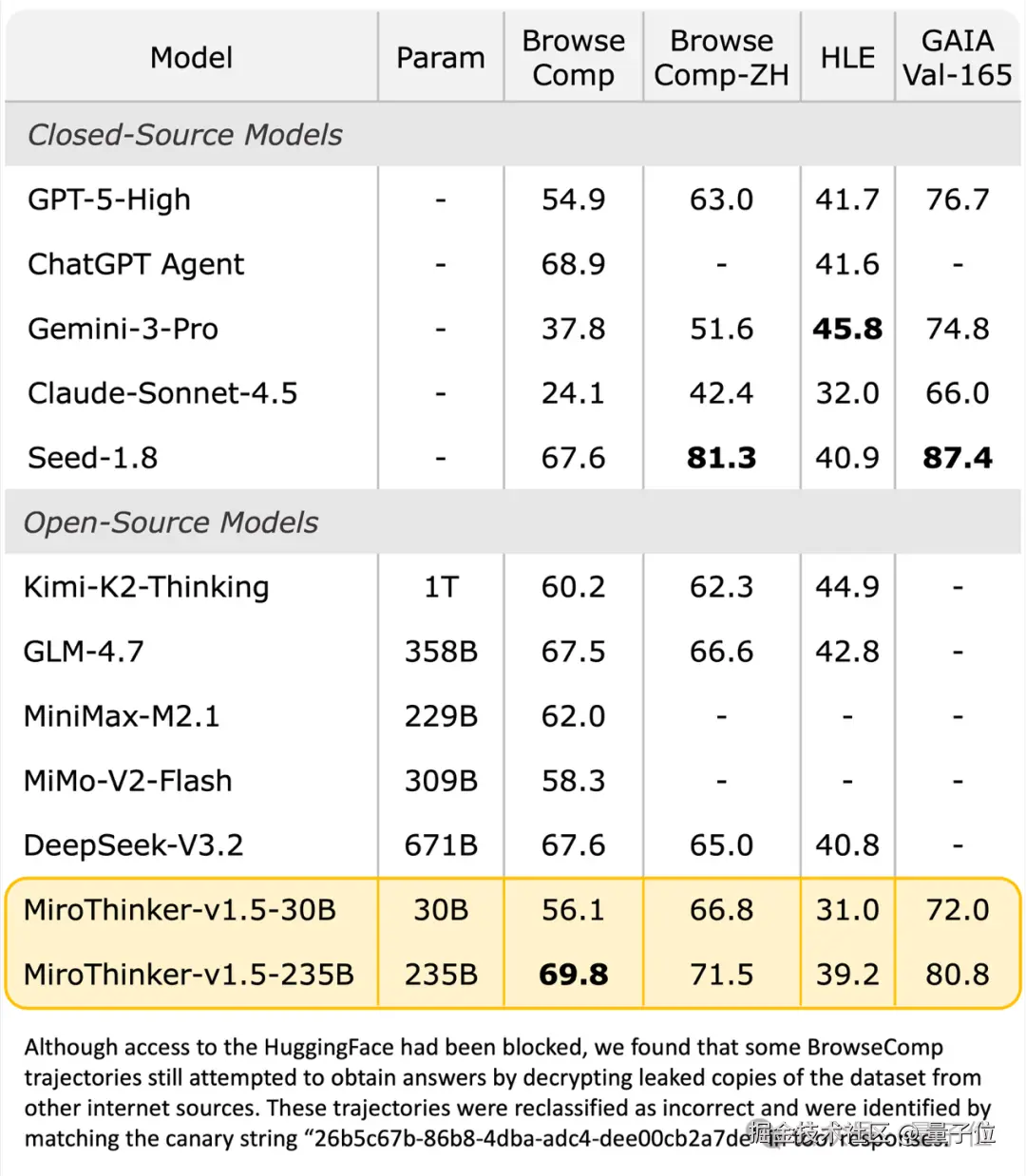
尤其是在 BrowseComp 上,直接刷新了 ChatGPT-Agent 保持的榜单纪录,强势跻身全球第一梯队。
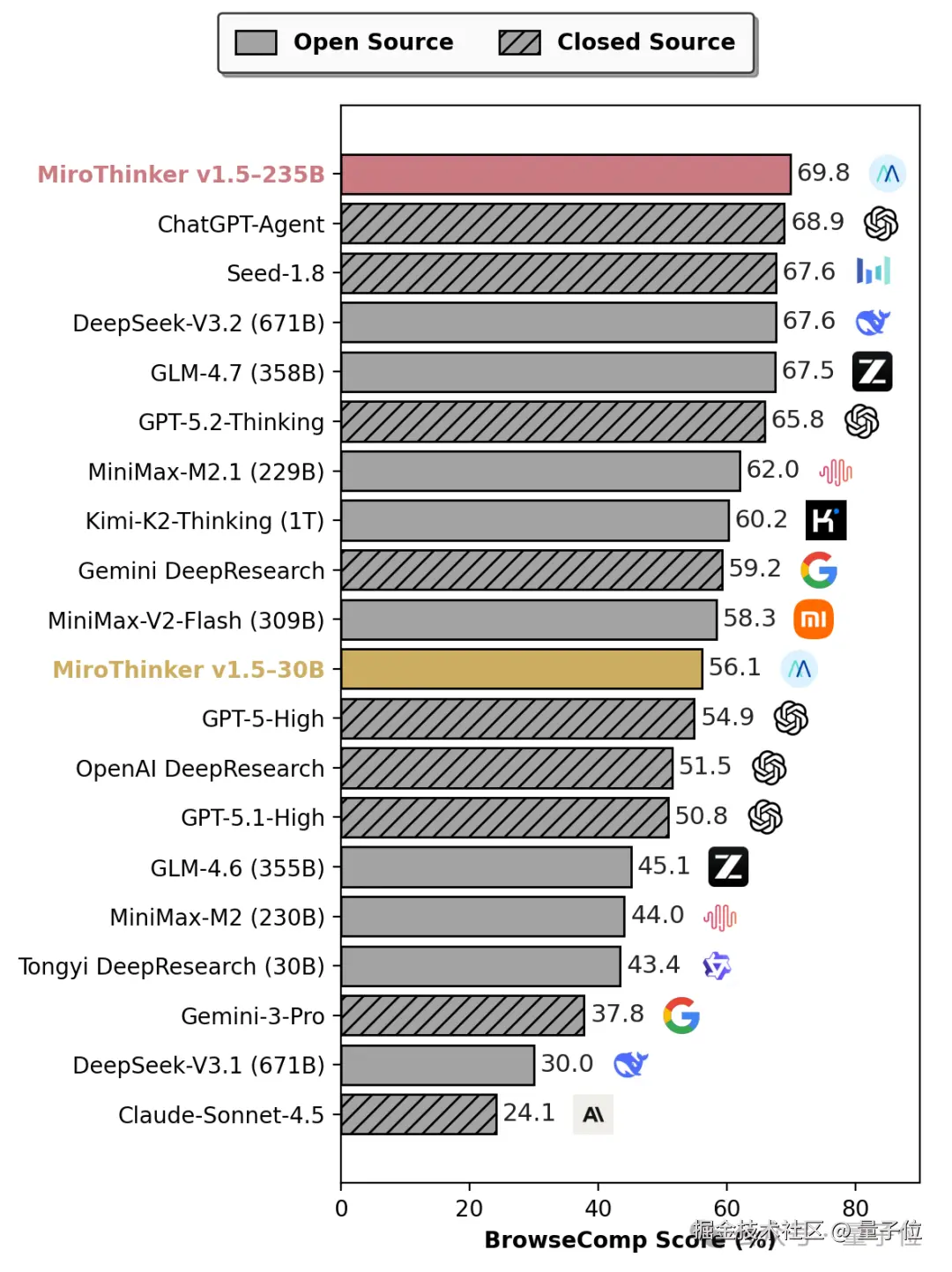
但要知道 MiroThinker 1.5 的参数规模只有它们的 1/30,仅 30B 和 235B 大小。
换句话说,在全行业大模型都在卷参数规模和上下文长度时,MiroThinker 1.5 直接用高智效比跑出了相近甚至更好的效果,原因就在于它抓住了这股 "巧劲":
给答案不靠死记硬背,而是通过大量深入的外部世界交互来逐步提升推理能力。
比如将 MiroThinker-v1.5-30B 和 1T 参数的 Kimi-K2-Thinking 对比,不仅在 BrowseComp-ZH 测试中实现了 4.5% 的性能超越,在推理成本上,MiroThinker 1.5 的单条调用成本更是低至 $0.07,只有 Kimi 的 1/20。
不止如此,MiroThinker 1.5 的推理速度也显著优于 Kimi-K2-Thinking,足以见得 "大" 不等于 "强",叠参数也并非大模型的唯一通解。
值得关注的是,它对开发者也相当友好,上线即开源。

而负责操刀这款模型的正是 MiroMind 团队,此前曾凭借成功预测 Polymarket_(全球最大的去中心化预测市场)_筛选题目,连续登顶 Future X 全球榜首,力压诸多国际顶尖机构和闭源商业模型。
MiroThinker 1.5 的推出,则是在团队已有的技术积累上更进一步,整体预测能力达到 next level。
那么具体效果如何?眼见为实,下面实测见真章。
小参数也能跑进第一梯队
实测之前,先简要介绍一下交互界面。(体验入口:_dr.miromind.ai/_)
和常规的大模型对话窗口一致,点击左下角按钮即可升级为专业模式:内置更大尺寸的模型,同时支持文件上传。
P.S. 界面下方还有一些系统自动推荐的预测问题可供参考。
下面我们先以一个基础的体育赛事预测为例,测试模型对实时信息的捕获和分析能力:
在 2026 年即将举办的世界杯中,考虑到分组名单和球队阵容,请给出胜率预测及可能的原因。

首先给我的第一感受是:快 + 完整。
从输入问题到输出,总耗时两分钟,而且思维过程全部清晰可见。
比如它会先梳理自己所需的全部信息,给出一条合理的预测路径:分组情况→阵容信息→胜率预测。
接着在每一项具体步骤中,反思验证当前内容,并给出修正意见。

根据上一步的反馈,模型会逐渐逼近最合理的答案。

在这一点上,近似于数学的迭代,都是从一个初始猜测值出发,通过反复的过程计算,将结果一步步收敛到真实解。
或者简单来说,就是和面时,水多了加面,面多了加水,最后总能成型。
那么再看输出的结果,和模型一般最后放结论不同,MiroThinker 1.5 直接开门见山,先给整体结论,以及详细的概率统计。(用户体验感 UP!)

然后它会对每一支热门球队都进行一一阐述,包括所在小组情况、各阶段的出线概率和多角度原因,乃至可能遇到的隐患。

即使是一些概率较低的可能性,它也能面面俱到。

不过显然,MiroThinker 1.5 在青春风暴 VS 老将最后一舞里,更支持前者。(doge)
接着我们再预测一个经典问题:GTA 6 什么时候发?
也算是回归陈天桥的老本行了。
GTA 6 明年能按时发布吗?请收集相关线索,给出确定性的回答。

很合理!预测逻辑严谨且层层递进,核心围绕着 R 星官方发布的权威信息,进行了多维度交叉验证,强化结果的可信度。
这次我们再将同样的问题,交给 ChatGPT、Gemini 和 DeepSeek,看看它们又会给出怎样的结果。
- ChatGPT:和 MiroThinker 1.5 的逻辑闭环相似,既遵循了行业规律,也为普通用户提供了建议。

- Gemini:虽然把核心时间说清楚了,但证据支撑不足、缺乏风险提示。

- DeepSeek:和 Gemini 类似,缺少关键背景补充,分析维度也相对单一。

有意思的是,仔细回看 Gemini 和 ChatGPT 的分析过程,它们都不约而同地在解释为什么 2025 年不能发......

一顿操作猛如虎,结果忘了已经 2026。

更深入一步,最后我们尝试将 MiroThinker 1.5 放进专业场景中测试,比如股市预测。
请根据今天 A 股的指数面,情绪面,板块以及前几天的情况,帮我选择一只连板梯队里最有可能晋级的股票。

(注:以下仅为技术展示,不构成投资建议)
同样,MiroThinker 1.5 非常之快,不只是推理速度快,收集新信息的速度也相当快。
在股市这类不确定性强的复杂环境中,MiroThinker 1.5 能够做到有理有据,既不是凭感觉走的玄学赌徒,也不是事后找补的诸葛亮,而是在极度噪声化环境中做到证据集合和可验证的因果推断。

总之实测下来,MiroThinker 1.5 确实是一款区别于市面上同类产品的模型,调用轻松、思考过程可视、逻辑也更严明,不靠单一猜测下定论,而是在不断复盘交互中逐步逼近真相。
u1s1,光冲着这理性全面的证据链,就值得一个点赞。
将交互内化进模型推理,用确定性对抗不确定性
问题是为什么 MiroMind 团队能率先做到这一点?
关键依然在 "大力出奇迹"。
在过去一年里,行业普遍存在的问题是过度依赖堆参数叠资源,本质来说就是让模型吃进更多知识,然后思维链沿着已记住的知识空间一步步往前推。
一旦其中一步发生偏离,后面所有步骤都会随着这个错误累计放大,最终导致整条逻辑链崩坏。
换言之,当模型参数规模到达一定程度后,继续堆资源对模型预测的边际收益只会迅速下降,行业不得不寻找新的智能增长路径。
MiroThinker 1.5 的解法恰恰在于将推理过程和外部环境深度绑定,为每一轮推理都引入一个反馈校验环节,构建起一整条 "推理 - 验证 - 修正" 的循环路径。
首先是将 Interactive Scaling 从原先的推理阶段前移,并内化为训练阶段的核心机制,把模型训练成一个更注重求证、校验和自我修正的探索型 Agent。
范式的转变决定了模型不再局限于内部知识和单次长链推理,而是通过和物理世界建立更深入的交互,以强化自身的行为模式:
- Evidence-Seeking(主动求证):模型会将每个关键判断拆解为可验证子假设,并主动发起对外查询、检索与比对。如果输出缺乏信源支撑,则会受到惩罚。
- Iterative Verification(多轮校验与自我修正):推理过程不再是一次性路径,而是允许反复回溯修正。当发现证据矛盾时,会立即进行调整,而非像传统思维链那样将错误延续下去。
- Anti-Hallucination(对捷径的系统性过滤):对过去一些看似合理但缺乏证据的推理结果给予否定,并标记为低质量推理。相比之下,更关注 "怎样得出答案",而非只是简单的对错。
由此,MiroThinker 1.5 形成了行之有效的本能反应:
对于不确定性问题,先交互再判断;对于高风险结论,先查证再收敛。
模型不再依赖全部的世界知识,也无需那么多的参数支持,就能够按需地向外部世界精准取证,最终促成更小的参数规模,却拥有更高的智能密度。
而这正是 MiroThinker 1.5 推理成本显著降低,但性能始终保持一线水准的根本原因。

其次是让模型杜绝复述结果,实现未来预测的关键因子------时序敏感训练沙盒。
传统大模型表面上看似是预测,实则只是在知识库里搜索结果并复述出来,或者是使用未来时间范畴的数据超前 "剧透",时序敏感训练沙盒则为模型戴上一个 "紧箍咒",严格约束只能使用当前可见的信息,并做出真实预测。
它可以分为两步,其一是可控数据合成引擎,负责构建覆盖多任务类型的、难度与时间戳可控的数据合成体系。
每一道题目的答案都会随着时间戳动态演化,判断过程会严格限制信息可见性,校验阶段同样也会显式引入时间戳约束,以确保推理逻辑和评分标准都符合真实世界的时间因果关系。
其二是时序敏感训练机制,在每一步训练中都只能访问当前时间戳之前的信息,从机制上彻底杜绝 Future Leakage_(未来信息泄露)_,模型无法超前看到结果。
这样下来,模型就会被迫学会在信息不完备、噪声存在、信号延迟的真实条件下完成推演,并随着新证据的出现不断修正判断。
时间也从原来被忽视的背景变量,升级为塑造模型行为与推理方式的核心约束,使模型更接近真实世界时序的认知与决策过程。
模型的预测能力不再是不可知的黑箱过程,而是可训练强化的关键要素。
当预测被拆解为一系列可约束、可反馈、可修正的行为模式之后,模型能力的上限也随之发生改变:性能提升不再简单取决于参数规模的线性扩张,而开始受益于模型与外部世界交互的方式与效率。
做题家模式 VS 科学家模式
而这套以小搏大的逻辑背后,正是 MiroMind 团队长期以来对 Scaling Law 的再解读。
早在模型 1.0 版本中,MiroMind 就首次系统性提出了除模型规模、上下文长度之外的第三大核心可扩展维度 Interactive Scaling,把智能的增长空间瞄准到外部世界。
V1.5 则是在此基础上,进一步落地融入贯穿训练与推理的全流程。
传统的 Scaling Law,走的是靠大脑更大解决问题的路线,本质上是 "做题家模式",靠记忆和统计,而非真正理解和验证。
反之当模型内化 Interactive Scaling,它就不再是靠概率瞎猜,而是像科学家一样建立起慢思考的研究闭环:提出假设→向外部世界查数据 / 取证→发现对不上→修正假设→再查证,直到证据收敛到合理范围之内。
这样能有效降低 Scaling Law 导致的幻觉,提升可靠性。

所以与其说这是算力的博弈,不如说是底层逻辑的转变在影响算力的着力点:算力没有集中用于模型的知识储备,毕竟知识无限,但算力始终有限。
有限的算力无法覆盖掉全部的知识,所以不妨转换思路,将算力效益最大化,也就是引向该去的地方------对外的信息获取与交互,把智能的扩展维度从 "更大脑袋" 变成"更勤快的手"。
这一点也与 MiroMind 始终强调的发现式智能不谋而合,即在未知条件下重建对世界的理解,抽丝剥茧发现真相而非简单地记住答案。
它不靠全知,而靠会研究、会查证、会修正。它能像顶级情报官一样对外极速取证、对内严苛去伪存真;像严谨研究员一样在不确定性里逼近真相,把 "预测未来" 从特权变成能力。
显然,陈天桥带领下的 MiroMind 已经率先转换赛道,找到了智能 "奇点" 的关键所在,是交互。
P.S. 如果感兴趣的话,可以加入官方社群:
Discord :discord.gg/F7EQFnYscV
微信社群:添加小助手 miromind001
体验网站:dr.miromind.ai/
Github 代码地址:github.com/MiroMindAI/...
MiroFlow 开源框架:github.com/MiroMindAI/...
Hugging Face 模型下载:huggingface.co/miromind-ai...
欢迎在评论区留下你的想法!
--- 完 ---