使用FastAPI和Uvicorn这两个库来部署模型,假设已预先下载Llama2库,安装路径为:
/home/runUser/llama/atom-7B一、定位accelerate_server.py 文件路径
运行仓库中的accelerate_server.py脚本启动API服务
(pytorch) runUser@**:~$ python accelerate_server.py --model_path /home/runUser/llama/atom-7B --gpus "0" --infer_dtype "int16" --model_source "llama2_chinese"
python: can't open file '/home/runUser/accelerate_server.py': [Errno 2] No such file or directory提示找不到文件accelerate_server.py,使用find命令查找文件路径
(pytorch) runUser@**:~$ find /home/runUser/ -name "accelerate_server.py"
/home/runUser/install_model/Llama-Chinese/scripts/api/accelerate_server.pycd到文件路径,就可以执行脚本命令了
二、TypeError: LlamaForCausalLM.init() got an unexpected keyword argument 'use_flash_attention_2'
运行脚本报错如下:
(pytorch) runUser@l**:~/install_model/Llama-Chinese/scripts/api$ python accelerate_server.py --model_path /home/runUser/llama/atom-7B --gpus "0" --infer_dtype "float16" --model_source "llama2_chinese"
/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/sklearn/utils/_param_validation.py:14: UserWarning: A NumPy version >=1.22.4 and <2.3.0 is required for this version of SciPy (detected version 2.3.0)
from scipy.sparse import csr_matrix, issparse
get_world_size:1
`torch_dtype` is deprecated! Use `dtype` instead!
Traceback (most recent call last):
File "/home/runUser/install_model/Llama-Chinese/scripts/api/accelerate_server.py", line 182, in <module>
model = AutoModelForCausalLM.from_pretrained(args.model_path, **kwargs,trust_remote_code=True,use_flash_attention_2=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/transformers/models/auto/auto_factory.py", line 597, in from_pretrained
return model_class.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/transformers/modeling_utils.py", line 288, in _wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/transformers/modeling_utils.py", line 5106, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: LlamaForCausalLM.__init__() got an unexpected keyword argument 'use_flash_attention_2'在accelerate_server.py文件,182行如下图所示:
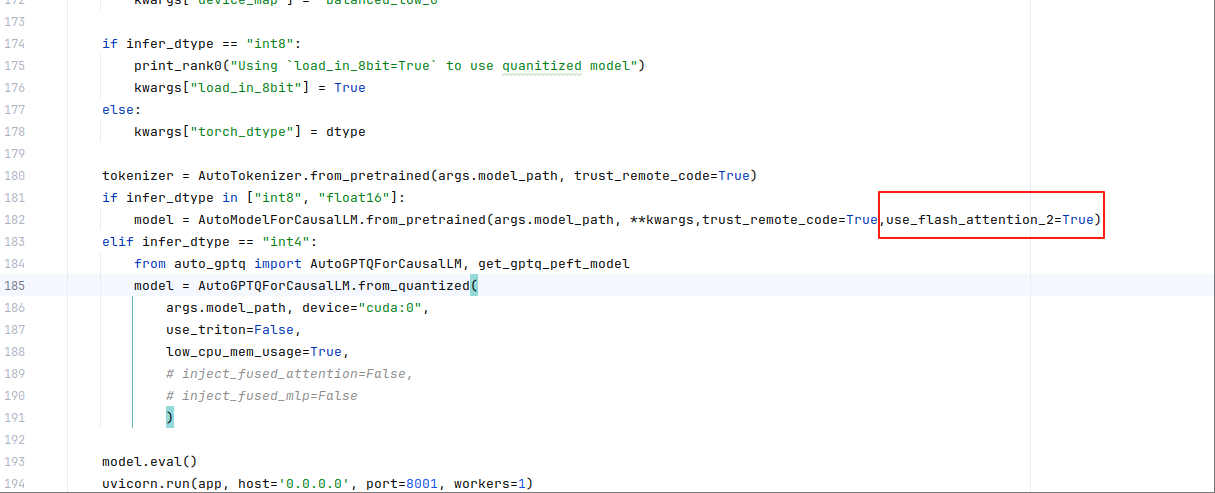
删除**use_flash_attention_2=True,**可以消除这个错误,运行成功
(pytorch) runUser@**:~/install_model/Llama-Chinese/scripts/api$ python accelerate_server.py --model_path /home/runUser/llama/atom-7B --gpus "0" --infer_dtype "float16" --model_source "llama2_chinese"
/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/sklearn/utils/_param_validation.py:14: UserWarning: A NumPy version >=1.22.4 and <2.3.0 is required for this version of SciPy (detected version 2.3.0)
from scipy.sparse import csr_matrix, issparse
get_world_size:1
`torch_dtype` is deprecated! Use `dtype` instead!
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:03<00:00, 1.04s/it]
Some parameters are on the meta device because they were offloaded to the cpu.
INFO: Started server process [54825]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8001 (Press CTRL+C to quit)二、AttributeError: 'DynamicCache' object has no attribute 'seen_tokens'
使用accelerate_client.py脚本向API服务器发送请求,提示:HTTP Error 500: Internal Server Error。后台报错如下所示:
INFO: 127.0.0.1:35030 - "POST /generate HTTP/1.1" 500 Internal Server Error
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/uvicorn/protocols/http/h11_impl.py", line 410, in run_asgi
result = await app( # type: ignore[func-returns-value]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/uvicorn/middleware/proxy_headers.py", line 60, in __call__
return await self.app(scope, receive, send)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/fastapi/applications.py", line 1135, in __call__
await super().__call__(scope, receive, send)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/applications.py", line 107, in __call__
await self.middleware_stack(scope, receive, send)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/middleware/errors.py", line 186, in __call__
raise exc
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/middleware/errors.py", line 164, in __call__
await self.app(scope, receive, _send)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/middleware/exceptions.py", line 63, in __call__
await wrap_app_handling_exceptions(self.app, conn)(scope, receive, send)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/_exception_handler.py", line 53, in wrapped_app
raise exc
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/_exception_handler.py", line 42, in wrapped_app
await app(scope, receive, sender)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/fastapi/middleware/asyncexitstack.py", line 18, in __call__
await self.app(scope, receive, send)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/routing.py", line 716, in __call__
await self.middleware_stack(scope, receive, send)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/routing.py", line 736, in app
await route.handle(scope, receive, send)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/routing.py", line 290, in handle
await self.app(scope, receive, send)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/fastapi/routing.py", line 115, in app
await wrap_app_handling_exceptions(app, request)(scope, receive, send)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/_exception_handler.py", line 53, in wrapped_app
raise exc
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/starlette/_exception_handler.py", line 42, in wrapped_app
await app(scope, receive, sender)
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/fastapi/routing.py", line 101, in app
response = await f(request)
^^^^^^^^^^^^^^^^
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/fastapi/routing.py", line 355, in app
raw_response = await run_endpoint_function(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/fastapi/routing.py", line 243, in run_endpoint_function
return await dependant.call(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/runUser/install_model/Llama-Chinese/scripts/api/accelerate_server.py", line 131, in create_item
generate_ids = model.generate(**generate_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/transformers/generation/utils.py", line 2539, in generate
result = self._sample(
^^^^^^^^^^^^^
File "/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/transformers/generation/utils.py", line 2860, in _sample
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/runUser/.cache/huggingface/modules/transformers_modules/atom-7B/model_atom.py", line 1379, in prepare_inputs_for_generation
past_length = past_key_values.seen_tokens
^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'DynamicCache' object has no attribute 'seen_tokens'在accelerate_server.py文件,182行修改后,如下图所示: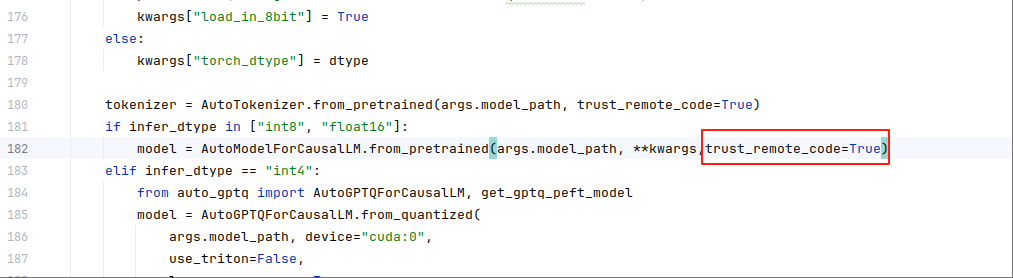
删除trust_remote_code=True,再重启,请求运行成功
INFO: Uvicorn running on http://0.0.0.0:8001 (Press CTRL+C to quit)
generate_kwargs: {'input_ids': tensor([[ 1, 12968, 29901, 29871, 63694, 32164, 13, 2, 1, 4007,
22137, 29901, 29871]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], device='cuda:0'), 'max_new_tokens': 2048, 'do_sample': True, 'top_p': 0.95, 'top_k': 50, 'temperature': 0.3, 'num_beams': 1, 'repetition_penalty': 1.2, 'max_length': 2048}
Both `max_new_tokens` (=2048) and `max_length`(=2048) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
INFO: 127.0.0.1:51542 - "POST /generate HTTP/1.1" 200 OK三、`torch_dtype` is deprecated!,这个不重要,不过我看着不舒服
启动成功的时候,会有警告提示:`torch_dtype` is deprecated!
(pytorch) runUser@**:~/install_model/Llama-Chinese/scripts/api$ python accelerate_server.py --model_path /home/runUser/llama/atom-7B --gpus "0" --infer_dtype "float16" --model_source "llama2_chinese"
/home/runUser/anaconda3/envs/pytorch/lib/python3.12/site-packages/sklearn/utils/_param_validation.py:14: UserWarning: A NumPy version >=1.22.4 and <2.3.0 is required for this version of SciPy (detected version 2.3.0)
from scipy.sparse import csr_matrix, issparse
get_world_size:1
`torch_dtype` is deprecated! Use `dtype` instead!
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:03<00:00, 1.03s/it]
Some parameters are on the meta device because they were offloaded to the cpu.
INFO: Started server process [55362]
INFO: Waiting for application startup.
INFO: Application startup complete.在accelerate_server.py文件,178行,如下图所示:
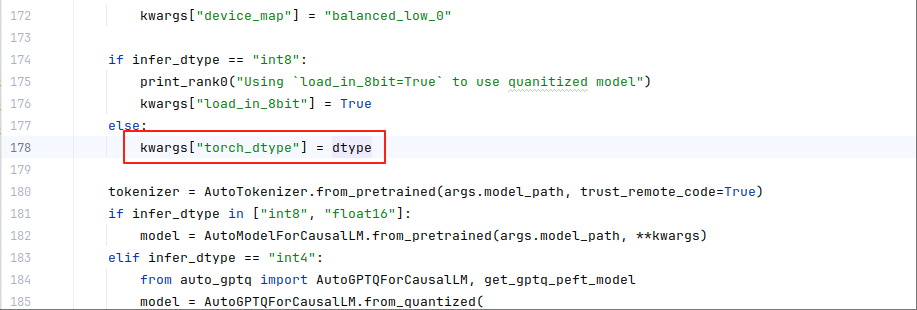
修改为
kwargs["dtype"] = dtype则不会再有提示