在日常办公和学习中,PDF文件的处理需求十分常见------查看文档信息、提取文本、合并/拆分文件、旋转页面、加密/解密等,频繁切换不同工具既低效又繁琐。本文介绍的这款Python脚本,基于pypdf库一站式整合了7类核心PDF操作,无需依赖第三方软件,轻量且易用。
代码文件:
我用夸克网盘给你分享了「pdf操作代码」,点击链接或复制整段内容,打开「夸克APP」即可获取。
链接:https://pan.quark.cn/s/d475ef0a40ad
核心特性与技术栈
1. 技术基础
- 核心库 :
pypdf(PDF文件的读取、写入、编辑核心逻辑);tkinter(Python内置GUI库,提供文件选择、路径保存等可视化交互);os/sys(文件路径处理、系统交互)。 - 运行环境 :Python 3.6+,无需额外复杂配置,安装依赖即可使用(
pip install pypdf)。
我使用的版本信息 :
Python版本: 3.10.11
OS模块: 内置模块
Sys模块: 内置模块
Tkinter版本: 8.6.12
PyPDF版本: 6.5.0
2. 核心功能总览
脚本以交互式菜单为入口,涵盖7大高频PDF操作:
| 功能编号 | 功能名称 | 核心作用 |
|---|---|---|
| 1 | 查看PDF信息 | 提取PDF元数据(文件名、页数、标题、作者、创建/修改日期等)并可视化输出 |
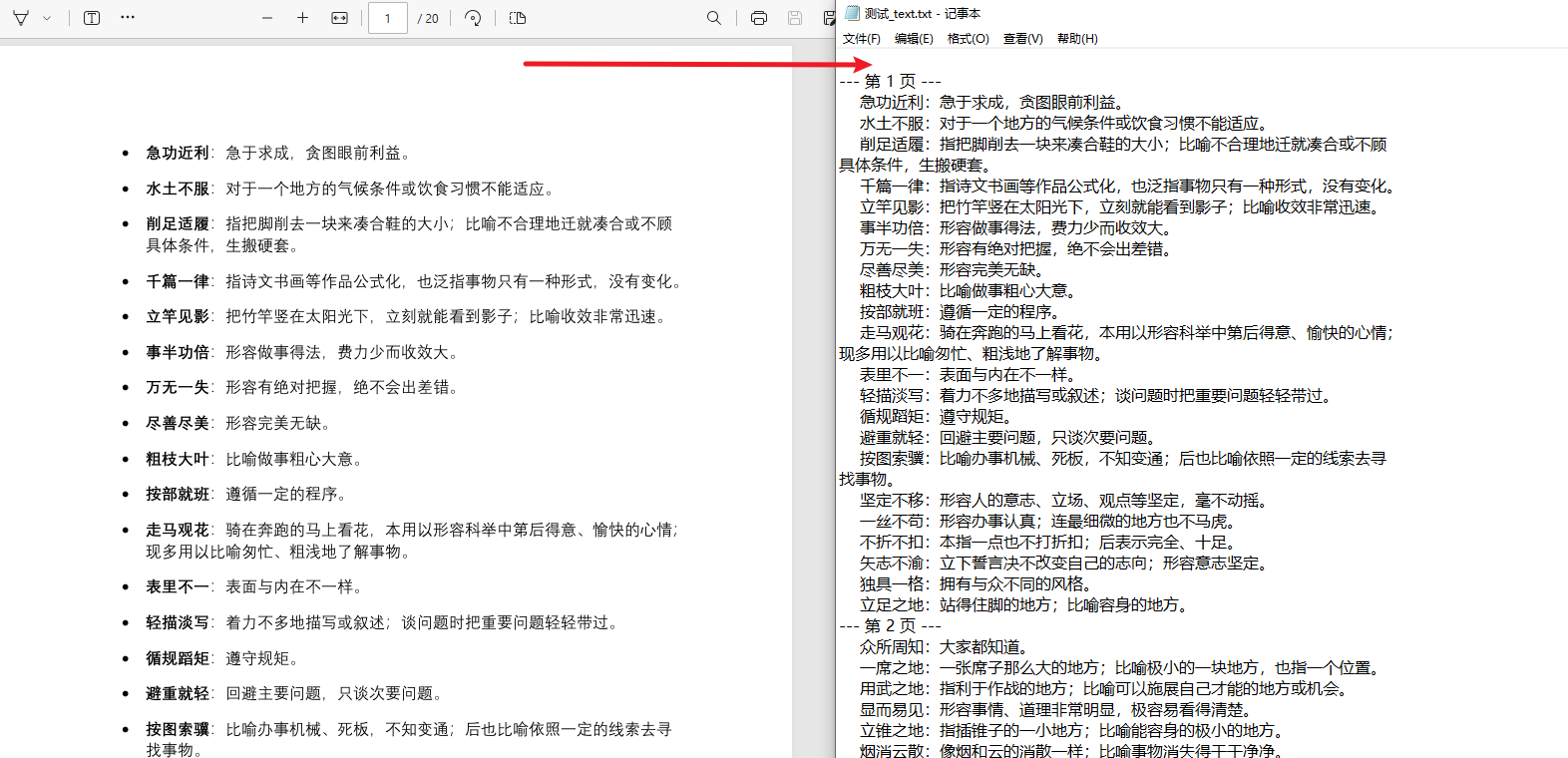
| 2 | 提取PDF文本 | 批量提取PDF所有页面文本,保存为UTF-8编码的TXT文件,按页码分隔文本内容 |
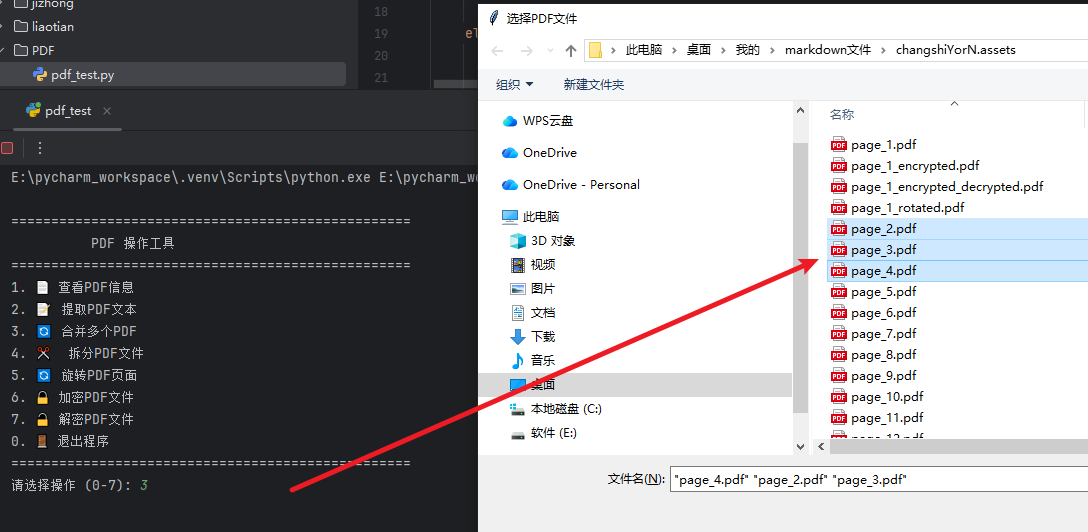
| 3 | 合并多个PDF | 选择多个PDF文件,按选择顺序合并为单个PDF,支持自定义输出文件名 |
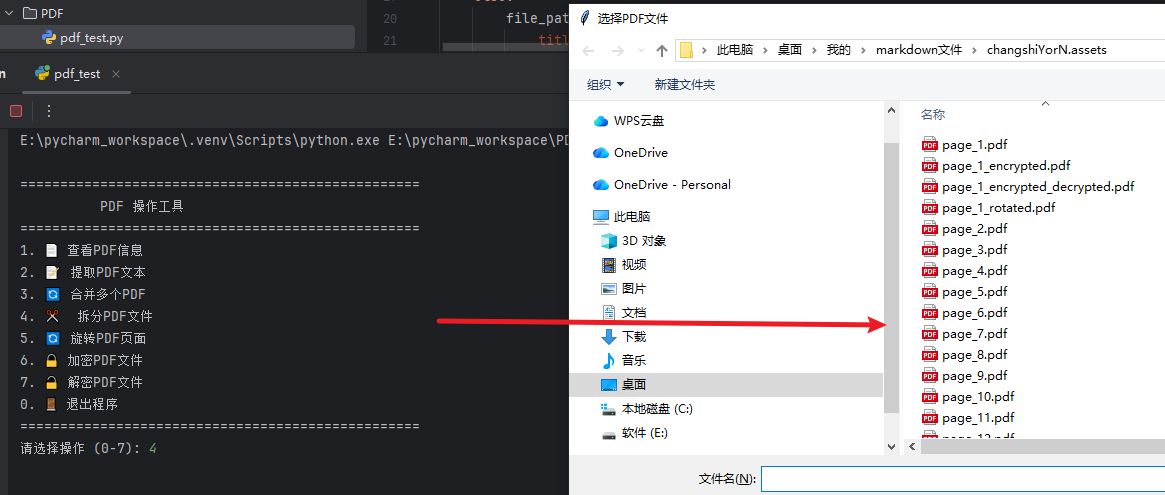
| 4 | 拆分PDF文件 | 将单个PDF按页码拆分为独立的单页PDF文件,自定义输出目录 |
| 5 | 旋转PDF页面 | 按指定角度(90/180/270°)旋转PDF所有页面,生成新文件 |
| 6 | 加密PDF文件 | 为PDF设置打开密码,保护文件不被随意查看 |
| 7 | 解密PDF文件 | 输入正确密码,移除PDF的加密保护,生成无密码的新文件 |
关键功能
1. 脚本通过tkinter封装了通用的文件选择函数,避免命令行操作的繁琐:
select_pdf_files():支持单选/多选PDF文件,返回文件路径列表;select_output_path():自定义输出文件名称和保存路径,默认补充.pdf后缀;askdirectory():拆分PDF时选择输出目录,适配批量文件保存场景。
2. 核心操作实现逻辑
以"合并PDF"和"解密PDF"为例,理解核心逻辑:
(1)PDF合并(merge_pdfs函数)
python
def merge_pdfs():
pdf_files = select_pdf_files(multiple=True) # 多选PDF
output_path = select_output_path(default_name="merged.pdf")
writer = PdfWriter()
for pdf_file in pdf_files:
reader = PdfReader(pdf_file)
for page in reader.pages:
writer.add_page(page) # 逐页添加到新PDF
writer.write(output_path) # 写入合并后的文件核心逻辑:通过PdfReader读取每个源PDF的页面,再通过PdfWriter逐页添加,最终写入新文件,保证合并顺序与选择顺序一致。
(2)PDF解密(decrypt_pdf函数)
python
def decrypt_pdf(pdf_path):
reader = PdfReader(pdf_path)
if not reader.is_encrypted: # 先校验是否加密
print("❌ 该PDF文件未加密")
return False
password = input("🔓 请输入PDF密码: ").strip()
if not reader.decrypt(password): # 密码验证
print("❌ 密码错误")
return False
# 解密后生成新文件
writer = PdfWriter()
for page in reader.pages:
writer.add_page(page)
writer.write(output_path)核心逻辑:先校验PDF加密状态,验证密码后,将解密后的页面重新写入新文件,实现"移除密码保护"。
3. 异常处理与用户反馈
所有功能均封装在try-except块中,捕获文件读取、路径选择、密码错误等异常,并通过清晰的符号提示(✅/❌)反馈操作结果:
- 操作成功:提示保存路径,例如
✅ PDF合并完成,已保存至: xxx.pdf; - 操作失败:明确报错原因,例如
❌ 密码错误/❌ 无效的旋转角度; - 用户取消操作:友好提示,例如
❌ 用户取消了保存。
使用流程
- 运行脚本:直接执行
pdf_test.py; - 选择功能:输入0-7的数字选择对应操作(0为退出);
- 可视化操作:根据提示选择PDF文件/输出路径/输入密码等;
- 查看结果:操作完成后控制台会输出结果,文件保存至指定路径。
提取PDF文本 :
拆分pdf:
文件加密:
合并:
py
import os
import sys
import tkinter as tk
from tkinter import filedialog, messagebox
from pypdf import PdfReader, PdfWriter
def select_pdf_files(multiple=False):
root = tk.Tk()
root.withdraw() # 隐藏主窗口
if multiple:
file_paths = filedialog.askopenfilenames(
title="选择PDF文件",
filetypes=[("PDF文件", "*.pdf"), ("所有文件", "*.*")]
)
return list(file_paths) if file_paths else []
else:
file_path = filedialog.askopenfilename(
title="选择PDF文件",
filetypes=[("PDF文件", "*.pdf"), ("所有文件", "*.*")]
)
return file_path if file_path else None
def select_output_path(default_name="output.pdf"):
root = tk.Tk()
root.withdraw() # 隐藏主窗口
output_path = filedialog.asksaveasfilename(
title="保存输出文件",
defaultextension=".pdf",
initialfile=default_name,
filetypes=[("PDF文件", "*.pdf"), ("所有文件", "*.*")]
)
return output_path if output_path else None
def get_pdf_info(pdf_path):
try:
reader = PdfReader(pdf_path)
info = reader.metadata
print("\n📄 PDF文件信息:")
print(f"文件名: {os.path.basename(pdf_path)}")
print(f"总页数: {len(reader.pages)}")
print(f"标题: {info.title if info.title else '无'}")
print(f"作者: {info.author if info.author else '无'}")
print(f"主题: {info.subject if info.subject else '无'}")
print(f"关键词: {info.keywords if info.keywords else '无'}")
print(f"创建者: {info.creator if info.creator else '无'}")
print(f"生产者: {info.producer if info.producer else '无'}")
print(f"创建日期: {info.creation_date if info.creation_date else '无'}")
print(f"修改日期: {info.modification_date if info.modification_date else '无'}")
return True
except Exception as e:
print(f"❌ 错误:{str(e)}")
return False
def extract_text(pdf_path):
"""提取PDF文本"""
try:
reader = PdfReader(pdf_path)
text = ""
print(f"\n📝 正在提取 {os.path.basename(pdf_path)} 的文本...")
for page_num, page in enumerate(reader.pages, 1):
page_text = page.extract_text()
if page_text:
text += f"\n--- 第 {page_num} 页 ---\n"
text += page_text
# 保存提取的文本
output_path = select_output_path(default_name=os.path.splitext(os.path.basename(pdf_path))[0] + "_text.txt")
if output_path:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(f"✅ 文本提取完成,已保存至: {output_path}")
else:
print("❌ 用户取消了保存")
return False
return True
except Exception as e:
print(f"❌ 错误:{str(e)}")
return False
def merge_pdfs():
"""合并多个PDF文件"""
try:
pdf_files = select_pdf_files(multiple=True)
if not pdf_files:
print("❌ 未选择任何PDF文件")
return False
output_path = select_output_path(default_name="merged.pdf")
if not output_path:
print("❌ 用户取消了保存")
return False
writer = PdfWriter()
print(f"\n🔄 正在合并 {len(pdf_files)} 个PDF文件...")
for pdf_file in pdf_files:
reader = PdfReader(pdf_file)
for page in reader.pages:
writer.add_page(page)
print(f" ✅ 已添加: {os.path.basename(pdf_file)}")
writer.write(output_path)
print(f"\n✅ PDF合并完成,已保存至: {output_path}")
return True
except Exception as e:
print(f"❌ 错误:{str(e)}")
return False
def split_pdf(pdf_path):
"""拆分PDF文件"""
try:
reader = PdfReader(pdf_path)
num_pages = len(reader.pages)
# 选择输出目录
root = tk.Tk()
root.withdraw()
output_dir = filedialog.askdirectory(title="选择输出目录")
if not output_dir:
print("❌ 用户取消了操作")
return False
print(f"\n✂️ 正在拆分 {os.path.basename(pdf_path)} ({num_pages}页)...")
# 按页拆分
for page_num in range(num_pages):
writer = PdfWriter()
writer.add_page(reader.pages[page_num])
output_filename = os.path.join(output_dir, f"page_{page_num + 1}.pdf")
writer.write(output_filename)
print(f" ✅ 已保存第 {page_num + 1} 页")
print(f"\n✅ PDF拆分完成,所有页面已保存至: {output_dir}")
return True
except Exception as e:
print(f"❌ 错误:{str(e)}")
return False
def rotate_pages(pdf_path):
"""旋转PDF页面"""
try:
reader = PdfReader(pdf_path)
writer = PdfWriter()
# 获取旋转角度
rotation = input("\n🔄 请输入旋转角度 (90/180/270): ").strip()
if rotation not in ["90", "180", "270"]:
print("❌ 无效的旋转角度,请输入90、180或270")
return False
rotation = int(rotation)
output_path = select_output_path(default_name=os.path.splitext(os.path.basename(pdf_path))[0] + "_rotated.pdf")
if not output_path:
print("❌ 用户取消了保存")
return False
print(f"\n🔄 正在旋转 {os.path.basename(pdf_path)} 的所有页面...")
for page in reader.pages:
page.rotate(rotation)
writer.add_page(page)
writer.write(output_path)
print(f"✅ PDF旋转完成,已保存至: {output_path}")
return True
except Exception as e:
print(f"❌ 错误:{str(e)}")
return False
def encrypt_pdf(pdf_path):
try:
reader = PdfReader(pdf_path)
writer = PdfWriter()
# 获取密码
password = input("\n🔒 请输入PDF密码: ").strip()
if not password:
print("❌ 密码不能为空")
return False
output_path = select_output_path(default_name=os.path.splitext(os.path.basename(pdf_path))[0] + "_encrypted.pdf")
if not output_path:
print("❌ 用户取消了保存")
return False
print(f"\n🔒 正在加密 {os.path.basename(pdf_path)}...")
# 添加所有页面
for page in reader.pages:
writer.add_page(page)
# 加密PDF
writer.encrypt(password)
writer.write(output_path)
print(f"✅ PDF加密完成,已保存至: {output_path}")
return True
except Exception as e:
print(f"❌ 错误:{str(e)}")
return False
def decrypt_pdf(pdf_path):
"""解密PDF文件"""
try:
reader = PdfReader(pdf_path)
# 检查是否加密
if not reader.is_encrypted:
print("❌ 该PDF文件未加密")
return False
# 获取密码
password = input("\n🔓 请输入PDF密码: ").strip()
# 尝试解密
if not reader.decrypt(password):
print("❌ 密码错误")
return False
output_path = select_output_path(default_name=os.path.splitext(os.path.basename(pdf_path))[0] + "_decrypted.pdf")
if not output_path:
print("❌ 用户取消了保存")
return False
writer = PdfWriter()
print(f"\n🔓 正在解密 {os.path.basename(pdf_path)}...")
# 添加所有页面
for page in reader.pages:
writer.add_page(page)
writer.write(output_path)
print(f"✅ PDF解密完成,已保存至: {output_path}")
return True
except Exception as e:
print(f"❌ 错误:{str(e)}")
return False
def show_menu():
"""显示主菜单"""
while True:
print("\n" + "="*50)
print(" PDF 操作工具")
print("="*50)
print("1. 📄 查看PDF信息")
print("2. 📝 提取PDF文本")
print("3. 🔄 合并多个PDF")
print("4. ✂️ 拆分PDF文件")
print("5. 🔄 旋转PDF页面")
print("6. 🔒 加密PDF文件")
print("7. 🔓 解密PDF文件")
print("0. 🚪 退出程序")
print("="*50)
choice = input("请选择操作 (0-7): ").strip()
if choice == "0":
print("\n👋 感谢使用,再见!")
break
elif choice in ["1", "2", "4", "5", "6", "7"]:
# 需要选择单个PDF文件的操作
pdf_path = select_pdf_files(multiple=False)
if not pdf_path:
print("❌ 未选择任何PDF文件")
continue
if choice == "1":
get_pdf_info(pdf_path)
elif choice == "2":
extract_text(pdf_path)
elif choice == "4":
split_pdf(pdf_path)
elif choice == "5":
rotate_pages(pdf_path)
elif choice == "6":
encrypt_pdf(pdf_path)
elif choice == "7":
decrypt_pdf(pdf_path)
elif choice == "3":
# 合并PDF操作
merge_pdfs()
else:
print("❌ 无效的选择,请重新输入")
input("\n按回车键继续...")
if __name__ == "__main__":
show_menu()