Notebook 工作流:可复现实验与科研记录
-
- [0. 先立三条"验收标准"](#0. 先立三条“验收标准”)
- 1) 项目骨架:Notebook 不单独存在 项目骨架:Notebook 不单独存在)
- 2) 环境锁定:复现的第一性原理是"同一依赖集合" 环境锁定:复现的第一性原理是“同一依赖集合”)
-
- [方案 A:`uv`(速度快 + 有 lockfile)](#方案 A:
uv(速度快 + 有 lockfile)) - [方案 B:Conda / mamba(计算生态友好)](#方案 B:Conda / mamba(计算生态友好))
- [方案 A:`uv`(速度快 + 有 lockfile)](#方案 A:
- 3) Notebook 可 review:用 Jupytext 把 Notebook 变成"可 diff 的文本" Notebook 可 review:用 Jupytext 把 Notebook 变成“可 diff 的文本”)
-
- [推荐配置:`ipynb + py:percent`](#推荐配置:
ipynb + py:percent) - [进阶:把 Notebook 也纳入自动检查](#进阶:把 Notebook 也纳入自动检查)
- [推荐配置:`ipynb + py:percent`](#推荐配置:
- 4) 参数化与批量复现:Papermill 把 Notebook 变成"可调参的实验模板" 参数化与批量复现:Papermill 把 Notebook 变成“可调参的实验模板”)
- 5) 把 Notebook 变成"可交付报告":Quarto 的 freeze/caching 思路 把 Notebook 变成“可交付报告”:Quarto 的 freeze/caching 思路)
- 6) 科研记录:把"实验过程"写成可检索的日志,而不是靠记忆 科研记录:把“实验过程”写成可检索的日志,而不是靠记忆)
- 7) 一张图总结:Notebook 可复现工作流 一张图总结:Notebook 可复现工作流)
- 8) 复现检查清单(交付前必做) 复现检查清单(交付前必做))
- 一点评论(也想听听你的做法)
- 下一篇:
很多同学把 Notebook 当成"临时草稿纸":能跑通就行,能出图就行。直到某天你要做这三件事之一------复现实验、交付项目、写论文补材料------你会发现自己面对的是一摞"无法回放的现场"。
我自己在高校/科研机构做数据分析与系统交付时,对 Notebook 的要求只有一句话:
Notebook 不是"写给现在的你",而是"写给两周后的你、合作者、以及审稿人/验收方"。
这篇文章我给你一套可落地的 Notebook 工作流:既能保证"可复现实验",又能形成"科研记录",最后还能沉淀为项目资产(可交付、可验收、可运维)。
0. 先立三条"验收标准"
如果你的 Notebook 工作流满足下面三条,基本就达到了科研与工程的交叉合格线:
- 一键复现:新机器从 0 开始,能在固定环境下跑出相同的关键指标/图表(允许数值微小浮动,但结论一致)。
- 可追溯:每个结果都能追溯到"数据版本 + 代码版本 + 参数 + 环境版本"。
- 可审阅:Notebook 的变更可读、可 review、可 diff,不是二进制黑盒。
接下来所有设计,都围绕这三条展开。
1) 项目骨架:Notebook 不单独存在
我推荐你把 Notebook 放进一个"最小可复现项目结构"里,而不是散落在桌面或一个巨大的 notebooks/ 目录里。
建议结构(科研 + 项目都适用):
text
project/
README.md
pyproject.toml
uv.lock # 或 requirements.lock / environment.yml
data/
raw/ # 原始数据(只读)
interim/ # 清洗中间产物
processed/ # 可建模/可分析数据
notebooks/
00_index.ipynb
01_eda.ipynb
02_features.ipynb
03_model.ipynb
04_report.ipynb
src/
__init__.py
dataset.py
features.py
modeling.py
viz.py
reports/
figures/
tables/
report.qmd # 可选:Quarto 报告入口
runs/
2026-01-07_2205/ # 每次实验的输出目录(参数、指标、模型、日志)
scripts/
run_all.sh
export_report.sh核心原则:
- Notebook 负责"叙事与实验编排",核心逻辑下沉到
src/,这样才能测试、复用、上线。 - 结果输出固定写到
runs/<timestamp>/...,避免"覆盖式写文件"导致不可追溯。
2) 环境锁定:复现的第一性原理是"同一依赖集合"
最常见的"复现失败"并不是你代码写错,而是依赖版本漂移。解决方案不是"我电脑能跑",而是锁定环境。
方案 A:uv(速度快 + 有 lockfile)
uv 支持项目与 lockfile,适合科研和工程混合场景;它提供统一 lockfile(uv.lock)来确保依赖一致性。(Astral 文档)
常用命令示例(概念级,不限定你必须用 uv):
bash
uv init
uv add numpy pandas matplotlib scikit-learn jupyter
uv lock
uv sync方案 B:Conda / mamba(计算生态友好)
如果你做的是重科学计算、CUDA、编译依赖多,Conda 仍然很常见。关键点是:导出并固定环境文件,并在 README 明确 Python 版本、OS、CUDA/驱动范围。
不管你选 A 还是 B,都要做到:
- 环境文件进 Git
- README 写清楚"一键创建环境"的命令
- 每次实验记录环境 hash / lockfile 版本
3) Notebook 可 review:用 Jupytext 把 Notebook 变成"可 diff 的文本"
Notebook 的最大痛点:.ipynb 是 JSON,diff 很难看;多人协作时冲突频繁。
解决方案之一:Jupytext 配对(paired notebooks) ------把 .ipynb 同步成 .py:percent 或 .md,让 Git diff 变得可读。(jupytext.readthedocs.io)
推荐配置:ipynb + py:percent
在 pyproject.toml 中加入:
toml
[tool.jupytext]
formats = "ipynb,py:percent"这样你改 Notebook 时,旁边会同步一个 xxx.py,每个 cell 都用 # %% 分隔(对 VS Code/Spyder 也非常友好)。(jupytext.readthedocs.io)
进阶:把 Notebook 也纳入自动检查
Jupytext 支持"导出为脚本后跑测试/静态检查"的工作流,比如用 --check 触发工具链。(jupytext.readthedocs.io)
4) 参数化与批量复现:Papermill 把 Notebook 变成"可调参的实验模板"
科研里你经常要做:不同数据切分、不同阈值、不同特征组合------如果靠手改 Notebook,非常不稳定,也难追溯。
Papermill 的定位就是:参数化 + 执行 Notebook 。(Papermill)
使用方式(关键概念)
- 在 Notebook 里标记一个 cell 为
parameters(Jupyter 的 cell tag)。 - 通过 CLI 或 Python API 传入参数,输出到新的结果 Notebook。
Python API 示例(最常用):(GitHub)
python
import papermill as pm
pm.execute_notebook(
"notebooks/03_model.ipynb",
"runs/2026-01-07_2205/03_model.out.ipynb",
parameters={
"seed": 42,
"test_size": 0.2,
"model_name": "xgboost",
}
)配合你前面提到的 runs/<timestamp>/ 目录,每一次实验都是"参数---结果---输出文件"的闭环。
5) 把 Notebook 变成"可交付报告":Quarto 的 freeze/caching 思路
Notebook 复现面向"研究者";交付报告面向"读者/验收方"。你需要的是:结果稳定、渲染可重复、别人不一定要在本机重跑所有计算也能渲染出报告。
Quarto 的 freeze 会把计算结果缓存到 _freeze/,后续渲染可复用;官方也建议把 _freeze 纳入版本控制,以便他人渲染时不必复现你的计算环境。(Quarto)
你可以把 reports/report.qmd 作为最终交付入口:
- Notebook 负责探索与验证
- Quarto 负责结构化叙事(章节、图表、引用、附录)
- freeze 负责"交付稳定性"
6) 科研记录:把"实验过程"写成可检索的日志,而不是靠记忆
这里给你一个我常用的"科研记录卡片模板"。建议每个 Notebook 顶部放一段 Markdown(或单独维护 logs/),保证你未来能回答这四个问题:我为什么做?我怎么做?我得到了什么?下一步是什么?
实验记录卡片(复制即可用):
markdown
## Experiment Card
- Objective:(目标/假设)
- Dataset:(数据来源、版本、筛选条件)
- Environment:(Python版本、lockfile hash、关键依赖)
- Parameters:(seed、划分比例、阈值、模型配置等)
- Metrics:(主要指标与比较基线)
- Artifacts:(输出文件路径:runs/...)
- Notes:(异常、踩坑、决策理由)
- Next:(下一步实验计划)你会发现:当你写论文 Methods / Appendix、或者做项目验收"过程材料"时,这张卡片就是现成素材。
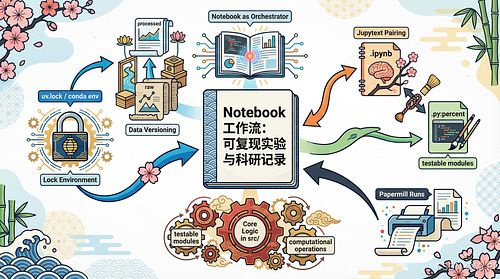
7) 一张图总结:Notebook 可复现工作流
Define Question & Hypothesis
Lock Environment
uv.lock / conda env
Data Versioning
raw -> processed
Notebook as Orchestrator
Jupytext Pairing
ipynb <-> py:percent
Core Logic in src/
testable modules
Papermill Runs
parameter sweep
Artifacts in runs/
metrics/models/plots
Quarto Report
freeze/_freeze
Deliverable & Review
reproducible + traceable
8) 复现检查清单(交付前必做)
交付/投稿前,我建议你至少做一次"冷启动复现":
- 新建虚拟环境,严格用 lockfile 安装依赖
- 从
data/raw开始跑完整流程(或确认缓存策略) - Notebook 全部 "Restart & Run All" 无人工干预
- 关键指标/图表写入
runs/<timestamp>/并带参数与环境信息 - Git diff 可读(Jupytext 或最少清理输出/metadata)
- README 写明:如何复现、如何产出报告、产物在哪
一点评论(也想听听你的做法)
Notebook 工作流做得好不好,最终看两件事:能不能被别人复现 ,以及你自己过一段时间还能不能解释清楚。我见过太多"结果很漂亮,但无法复现"的项目,最后不是输在技术,而是输在工作流与记录方式。
你现在的 Notebook 更像哪一种?
- "草稿纸型":探索快,但回放难
- "实验型":能复现,但叙事弱
- "交付型":能复现、能审阅、能报告
如果你愿意,把你当前的目录结构/Notebook 组织方式(截图或文字)发在评论区,我可以按"可复现 + 可交付"的标准帮你做一次针对性改造建议。