目录
- 读写分离详解与实战
- [1 读写分离架构介绍](#1 读写分离架构介绍)
-
- [1.1 读写分离原理](#1.1 读写分离原理)
- [1.2 读写分离应用方案](#1.2 读写分离应用方案)
- [2 MySQL主从同步](#2 MySQL主从同步)
-
- [2.1 主从同步原理](#2.1 主从同步原理)
- [2.2 一主一从架构搭建](#2.2 一主一从架构搭建)
- [3 Sharding-JDBC实现读写分离](#3 Sharding-JDBC实现读写分离)
-
- [3.1 数据准备](#3.1 数据准备)
- [3.2 环境准备](#3.2 环境准备)
-
- 1) 创建实体类 创建实体类)
- 2) 创建Mapper 创建Mapper)
- [3.3 配置读写分离](#3.3 配置读写分离)
- [3.4 读写分离测试](#3.4 读写分离测试)
- [3.5 事务读写分离测试](#3.5 事务读写分离测试)
- [4 负载均衡算法](#4 负载均衡算法)
-
- [4.1 一主两从架构](#4.1 一主两从架构)
- [4.2 负载均衡测试](#4.2 负载均衡测试)
读写分离详解与实战
1 读写分离架构介绍
1.1 读写分离原理
**读写分离原理:**读写分离就是让主库处理事务性操作,从库处理select查询。数据库复制被用来把事务性查询导致的数据变更同步到从库,同时主库也可以select查询。
注意: 读写分离的数据节点中的数据内容是一致。
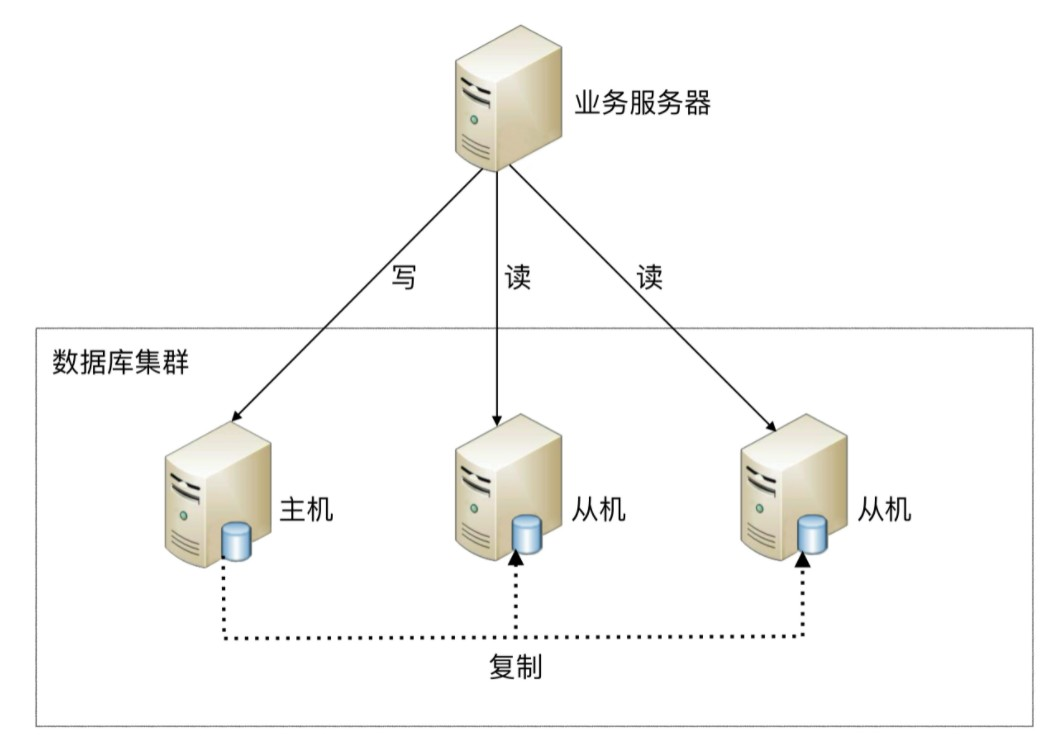
读写分离的基本实现:
-
主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
-
读写分离是根据 SQL 语义的分析
,将读操作和写操作分别路由至主库与从库。 -
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。
-
使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行
将用户表的写操作和读操路由到不同的数据库
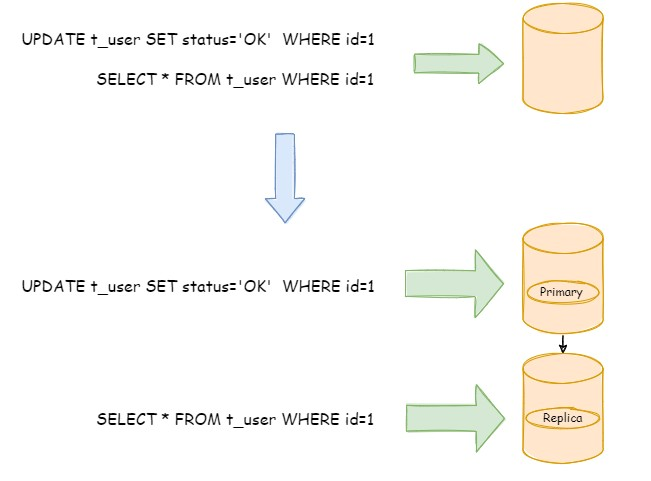
1.2 读写分离应用方案
在数据量不是很多的情况下,我们可以将数据库进行读写分离,以应对高并发的需求,通过水平扩展从库,来缓解查询的压力。如下:
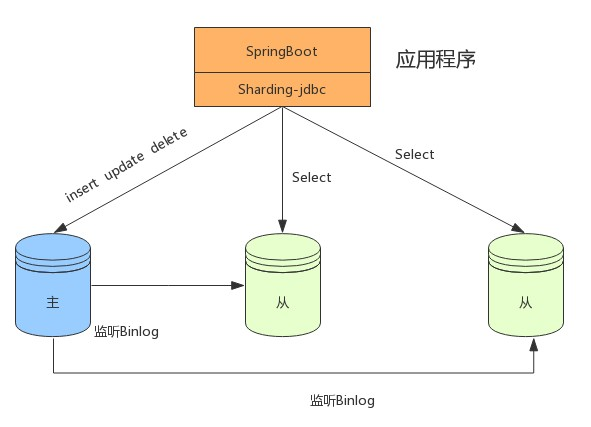
分表+读写分离
在数据量达到500万的时候,这时数据量预估千万级别,我们可以将数据进行分表存储。

分库分表+读写分离
在数据量继续扩大,这时可以考虑分库分表,将数据存储在不同数据库的不同表中,如下:
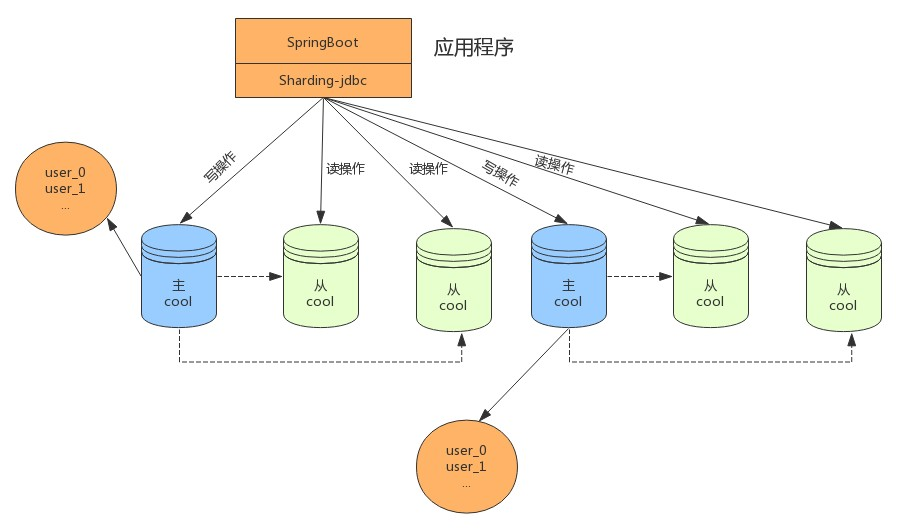
读写分离虽然可以提升系统的吞吐量和可用性,但同时也带来了数据不一致的问题,包括多个主库之间的数据一致性,以及主库与从库之间的数据一致性的问题。 并且,读写分离也带来了与数据分片同样的问题,它同样会使得应用开发和运维人员对数据库的操作和运维变得更加复杂。
透明化读写分离所带来的影响,让使用方尽量像使用一个数据库一样使用主从数据库集群,是ShardingSphere读写分离模块的主要设计目标。
主库、从库、主从同步、负载均衡
-
核心功能
-
提供一主多从的读写分离配置。仅支持单主库,可以支持独立使用,也可以配合分库分表使用
-
独立使用读写分离,支持SQL透传。不需要SQL改写流程
-
同一线程且同一数据库连接内,能保证数据一致性。如果有写入操作,后续的读操作均从主库读取。
-
基于Hint的强制主库路由。可以强制路由走主库查询实时数据,避免主从同步数据延迟。
-
-
不支持项
- 主库和从库的数据同步
- 主库和从库的数据同步延迟
- 主库双写或多写
- 跨主库和从库之间的事务的数据不一致。建议在主从架构中,事务中的读写均用主库操作。
2 MySQL主从同步
2.1 主从同步原理
读写分离是建立在MySQL主从复制基础之上实现的,所以必须先搭建MySQL的主从复制架构。

主从复制的用途
-
实时灾备,用于故障切换
-
读写分离,提供查询服务
-
备份,避免影响业务
主从部署必要条件
- 主库开启binlog日志(设置log-bin参数)
- 主从server-id不同
- 从库服务器能连通主库
主从复制的原理
- Mysql 中有一种日志叫做 binlog日志(二进制日志)。这个日志会记录下所有修改了数据库的SQL 语句(insert,update,delete,create/alter/drop table, grant 等等)。
- 主从复制的原理其实就是把主服务器上的 binlog日志复制到从服务器上执行一遍,这样从服务器上的数据就和主服务器上的数据相同了。
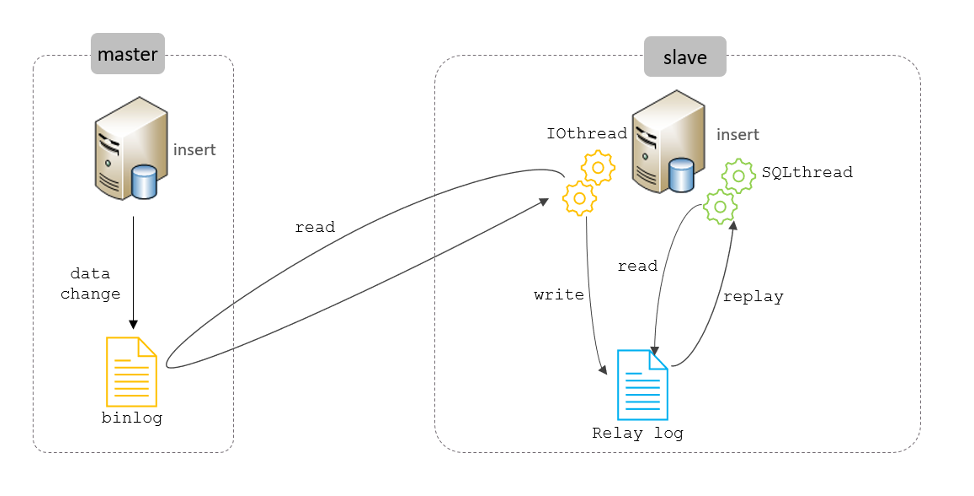
- 主库db的更新事件(update、insert、delete)被写到binlog
- 主库创建一个binlog dump thread,把binlog的内容发送到从库
- 从库启动并发起连接,连接到主库
- 从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
- 从库启动之后,创建一个SQL线程,从relay log里面读取内容,执行读取到的更新事件,将更新内容写入到slave的db
2.2 一主一从架构搭建
Mysql的主从复制至少是需要两个Mysql的服务,当然Mysql的服务是可以分布在不同的服务器上,也可以在一台服务器上启动多个服务。
准备:
| 主机 | 角色 | 用户名 | 密码 |
|---|---|---|---|
| 192.168.116.129 | master | root | 123456 |
| 192.168.116.128 | slave | root | 123456 |
第一步 master中和slave创建数据库
sql
-- 创建数据库
CREATE DATABASE itcast;主库中配置
① 修改配置文件 /etc/my.cnf
cmd
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 -- 232-1,默认为1
server-id=1
#是否只读,1 代表只读, 0 代表读写
read-only=0
#指定同步的数据库
binlog-do-db=itcast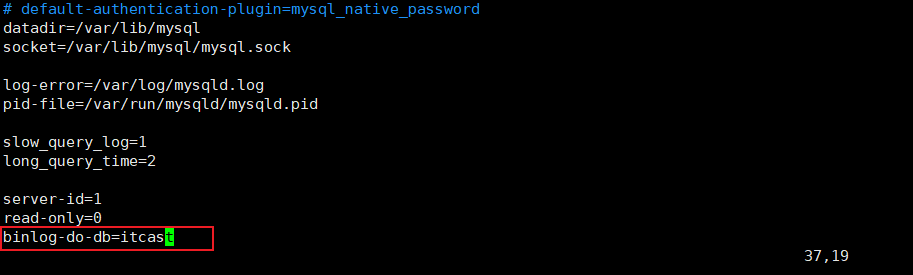
② 重启MySQL服务器
systemctl restart mysqld③ 登录mysql,创建远程连接的账号,并授予主从复制权限
bash
#创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务
create user 'itcast'@'%' IDENTIFIED WITH mysql_native_password BY 'Itcast@123456';
#为 'itcast'@'%' 用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'itcast'@'%';
④ 通过指令,查看二进制日志坐标
sql
show master status;
字段含义说明:
- file : 从哪个日志文件开始推送日志文件
- position : 从哪个位置开始推送日志
- binlog_ignore_db : 指定不需要同步的数据库
从库配置
① 修改配置文件 /etc/my.cnf
bash
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 -- 2^32-1,和主库不一样即可
server-id=2
#是否只读,1 代表只读, 0 代表读写
read-only=1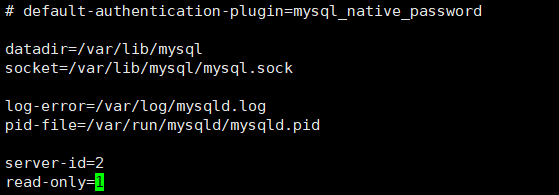
② 重新启动MySQL服务
sql
systemctl restart mysqld③ 登录mysql,设置主库配置
SOURCE_LOG_FILE和SOURCE_LOG_POS设置的是主库中刚才查询出来的
sql
CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.116.129', SOURCE_USER='itcast',SOURCE_PASSWORD='Itcast@123456',SOURCE_LOG_FILE='binlog.000014', SOURCE_LOG_POS=479;
上述是8.0.23中的语法。如果mysql是 8.0.23 之前的版本,执行如下SQL:
sql
CHANGE MASTER TO MASTER_HOST='192.168.116.129', MASTER_USER='itcast',
MASTER_PASSWORD='Itcast@123456', MASTER_LOG_FILE='binlog.000014',
MASTER_LOG_POS=479;| 参数名 | 含义 | 8.0.23之前 |
|---|---|---|
| SOURCE_HOST | 主库IP地址 | MASTER_HOST |
| SOURCE_USER | 连接主库的用户名 | MASTER_USER |
| SOURCE_PASSWORD | 连接主库的密码 | MASTER_PASSWORD |
| SOURCE_LOG_FILE | binlog日志文件名 | MASTER_LOG_FILE |
| SOURCE_LOG_POS | binlog日志文件位置 | MASTER_LOG_POS |
④ 开启同步操作
sql
start replica ; #8.0.22之后
start slave ; #8.0.22之前
⑤ 查看主从同步状态
sql
show replica status ; #8.0.22之后
show slave status ; #8.0.22之前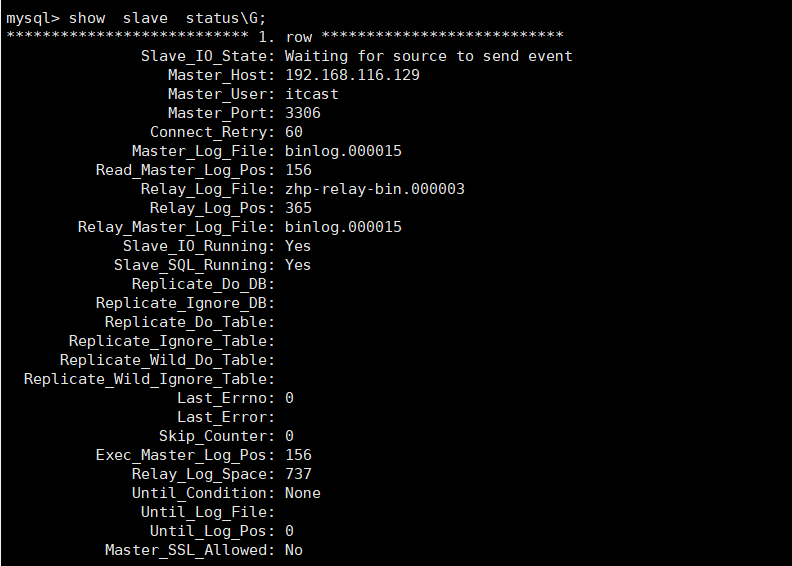
Replica_IO_Running: Yes和Replica_SQL_Running: Yes说明配置成功
测试:
在主库中itcast数据库中执行如下:
sql
-- 创建表
CREATE TABLE users (
id INT(11) PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20) DEFAULT NULL,
age INT(11) DEFAULT NULL
);
-- 插入数据
INSERT INTO users VALUES(NULL,'user1',20);
INSERT INTO users VALUES(NULL,'user2',21);
INSERT INTO users VALUES(NULL,'user3',22);查看从库是否已经将users表和数据同步过来
3 Sharding-JDBC实现读写分离
Sharding-JDBC读写分离则是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库。它提供透明化读写分离,让使用方尽量像使用一个数据库一样使用主从数据库集群。
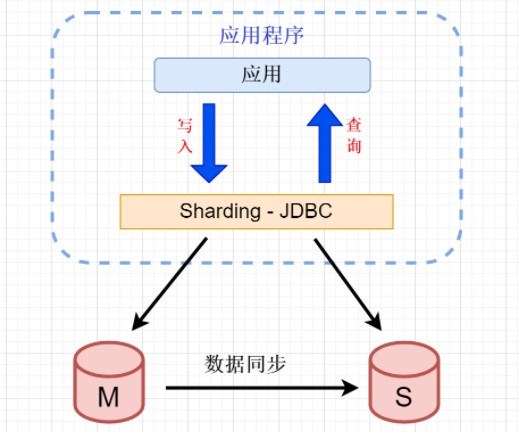
3.1 数据准备
为了实现Sharding-JDBC的读写分离,首先,要进行mysql的主从同步配置。在上面的课程中我们已经配置完成了.
- 在主服务器中的 itcast数据库 创建商品表
sql
CREATE TABLE `products` (
`pid` bigint(32) NOT NULL AUTO_INCREMENT,
`pname` varchar(50) DEFAULT NULL,
`price` int(11) DEFAULT NULL,
`flag` varchar(2) DEFAULT NULL,
PRIMARY KEY (`pid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8- 主库新建表之后,从库会根据binlog日志,同步创建.
主库:
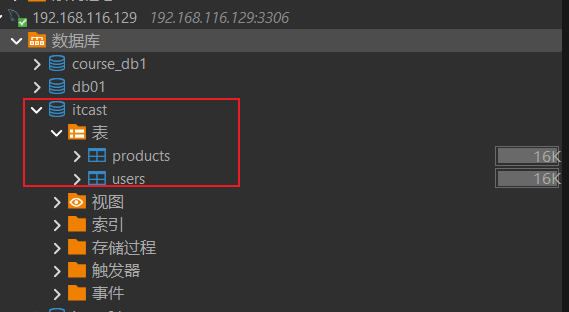
从库:

3.2 环境准备
1) 创建实体类
java
@TableName("products")
@Data
public class Products {
@TableId(value = "pid",type = IdType.AUTO)
private Long pid;
private String pname;
private int price;
private String flag;
}2) 创建Mapper
java
@Mapper
public interface ProductsMapper extends BaseMapper<Products> {
}3.3 配置读写分离
application.properties:
properties
# 应用名称
spring.application.name=shardingjdbc-table-write-read
#===============数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=master,slave
#数据源1
spring.shardingsphere.datasource.slave.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave.url = jdbc:mysql://192.168.116.128:3306/itcast?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.slave.username = root
spring.shardingsphere.datasource.slave.password = 123456
#数据源2
spring.shardingsphere.datasource.master.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.url = jdbc:mysql://192.168.116.129:3306/itcast?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.master.username = root
spring.shardingsphere.datasource.master.password = 123456
# 读写分离类型,如: Static,Dynamic, ms1 包含了 m1 和 s1
spring.shardingsphere.rules.readwrite-splitting.data-sources.ms1.type=Static
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.ms1.props.write-data-source-name=master
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.ms1.props.read-data-source-names=slave
# 打印SQl
spring.shardingsphere.props.sql-show=true负载均衡相关配置
3.4 读写分离测试
java
//插入测试
@Test
public void testInsertProducts(){
Products products = new Products();
products.setPname("电视机");
products.setPrice(100);
products.setFlag("0");
productsMapper.insert(products);
}
java
@Test
public void testSelectProducts(){
QueryWrapper<Products> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("pname","电视机");
List<Products> products = productsMapper.selectList(queryWrapper);
products.forEach(System.out::println);
}
3.5 事务读写分离测试
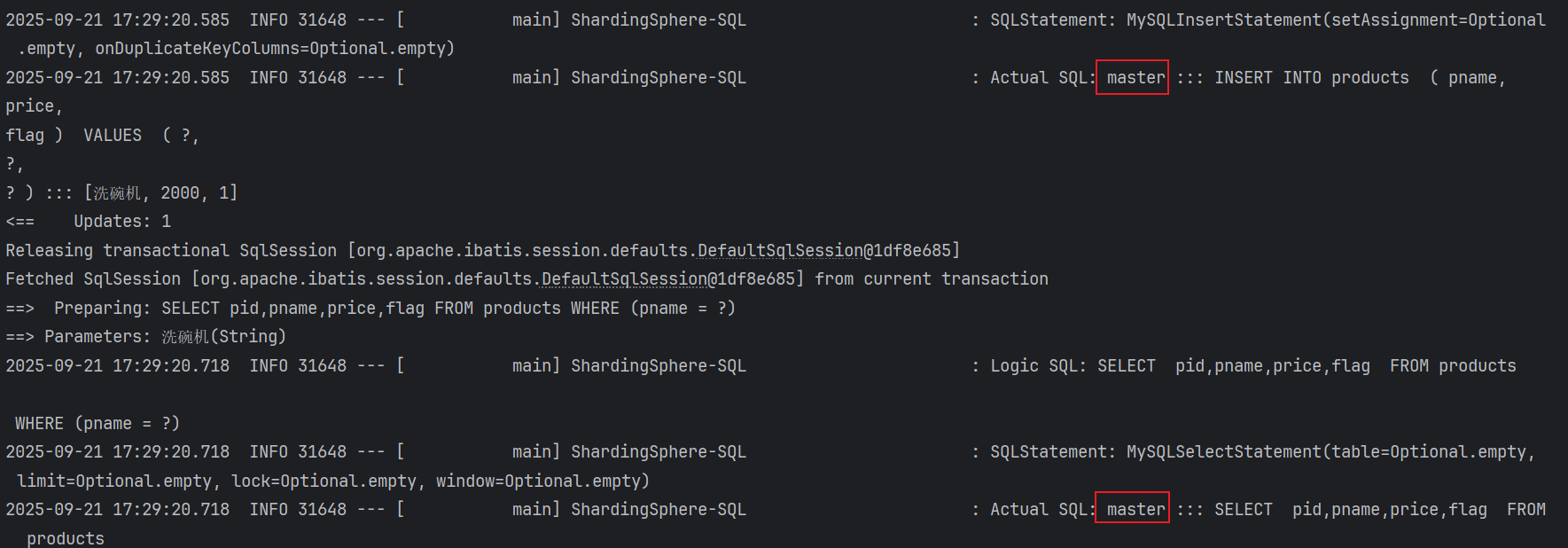
为了保证主从库间的事务一致性,避免跨服务的分布式事务,ShardingSphere-JDBC的主从模型中,事务中的数据读写均用主库。
- 不添加@Transactional:insert对主库操作,select对从库操作
- 添加@Transactional:则insert和select均对主库操作
- **注意:**在JUnit环境下的@Transactional注解,默认情况下就会对事务进行回滚(即使在没加注解@Rollback,也会对事务回滚)
java
//事务测试
@Transactional //开启事务
@Test
public void testTrans(){
Products products = new Products();
products.setPname("洗碗机");
products.setPrice(2000);
products.setFlag("1");
productsMapper.insert(products);
QueryWrapper<Products> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("pname","洗碗机");
List<Products> list = productsMapper.selectList(queryWrapper);
list.forEach(System.out::println);
}
4 负载均衡算法
4.1 一主两从架构
上边再搭建一主一从时用到过129和128两个服务器,再操作之前先还原两个服务器的主从架构,分别在两个服务器上执行下边的sql
sql
STOP SLAVE;
RESET SLAVE ALL;
准备:
| 主机 | 角色 | 用户名 | 密码 |
|---|---|---|---|
| 192.168.116.129 | master | root | 123456 |
| 192.168.116.128 | slave | root | 123456 |
| 192.168.116.130 | slave | root | 123456 |
第一步 master中和slave创建数据库
sql
-- 创建数据库
CREATE DATABASE itcast;主库中配置
① 修改配置文件 /etc/my.cnf
cmd
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 -- 232-1,默认为1
server-id=1
#是否只读,1 代表只读, 0 代表读写
read-only=0
#指定同步的数据库
binlog-do-db=itcast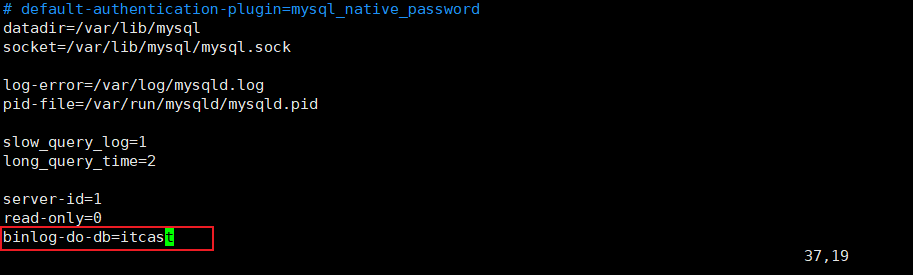
② 重启MySQL服务器
systemctl restart mysqld③ 登录mysql,创建远程连接的账号,并授予主从复制权限
bash
#创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务
create user 'itcast'@'%' IDENTIFIED WITH mysql_native_password BY 'Itcast@123456';
#为 'itcast'@'%' 用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'itcast'@'%';
④ 通过指令,查看二进制日志坐标
sql
show master status;
字段含义说明:
- file : 从哪个日志文件开始推送日志文件
- position : 从哪个位置开始推送日志
- binlog_ignore_db : 指定不需要同步的数据库
从库192.168.116.128配置
① 修改配置文件 /etc/my.cnf
bash
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 -- 2^32-1,和主库不一样即可
server-id=2
#是否只读,1 代表只读, 0 代表读写
read-only=1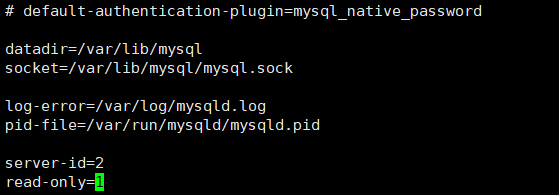
② 重新启动MySQL服务
sql
systemctl restart mysqld③ 登录mysql,设置主库配置
SOURCE_LOG_FILE和SOURCE_LOG_POS设置的是主库中刚才查询出来的
sql
CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.116.129', SOURCE_USER='itcast',SOURCE_PASSWORD='Itcast@123456',SOURCE_LOG_FILE='binlog.000031', SOURCE_LOG_POS=156;
上述是8.0.23中的语法。如果mysql是 8.0.23 之前的版本,执行如下SQL:
sql
CHANGE MASTER TO MASTER_HOST='192.168.116.129', MASTER_USER='itcast',
MASTER_PASSWORD='Itcast@123456', MASTER_LOG_FILE='binlog.000031',
MASTER_LOG_POS=156;| 参数名 | 含义 | 8.0.23之前 |
|---|---|---|
| SOURCE_HOST | 主库IP地址 | MASTER_HOST |
| SOURCE_USER | 连接主库的用户名 | MASTER_USER |
| SOURCE_PASSWORD | 连接主库的密码 | MASTER_PASSWORD |
| SOURCE_LOG_FILE | binlog日志文件名 | MASTER_LOG_FILE |
| SOURCE_LOG_POS | binlog日志文件位置 | MASTER_LOG_POS |
④ 开启同步操作
sql
start replica ; #8.0.22之后
start slave ; #8.0.22之前
⑤ 查看主从同步状态
sql
show replica status ; #8.0.22之后
show slave status ; #8.0.22之前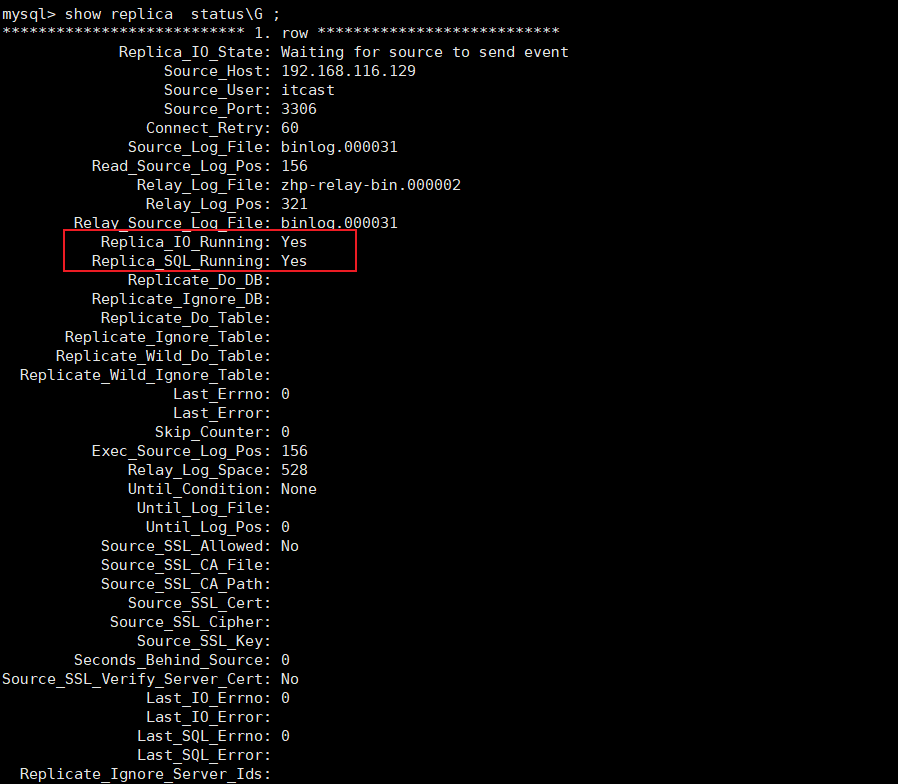
Replica_IO_Running: Yes和Replica_SQL_Running: Yes说明配置成功
从库192.168.116.130配置
① 修改配置文件 /etc/my.cnf
bash
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 -- 2^32-1,和主库不一样即可
server-id=3
#是否只读,1 代表只读, 0 代表读写
read-only=1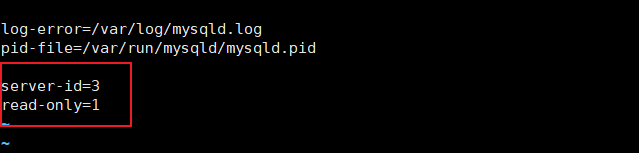
② 重新启动MySQL服务
sql
systemctl restart mysqld③ 登录mysql,设置主库配置
SOURCE_LOG_FILE和SOURCE_LOG_POS设置的是主库中刚才查询出来的
sql
CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.116.129', SOURCE_USER='itcast',SOURCE_PASSWORD='Itcast@123456',SOURCE_LOG_FILE='binlog.000031', SOURCE_LOG_POS=156;
上述是8.0.23中的语法。如果mysql是 8.0.23 之前的版本,执行如下SQL:
sql
CHANGE MASTER TO MASTER_HOST='192.168.116.129', MASTER_USER='itcast',
MASTER_PASSWORD='Itcast@123456', MASTER_LOG_FILE='binlog.000031',
MASTER_LOG_POS=156;| 参数名 | 含义 | 8.0.23之前 |
|---|---|---|
| SOURCE_HOST | 主库IP地址 | MASTER_HOST |
| SOURCE_USER | 连接主库的用户名 | MASTER_USER |
| SOURCE_PASSWORD | 连接主库的密码 | MASTER_PASSWORD |
| SOURCE_LOG_FILE | binlog日志文件名 | MASTER_LOG_FILE |
| SOURCE_LOG_POS | binlog日志文件位置 | MASTER_LOG_POS |
④ 开启同步操作
sql
start replica ; #8.0.22之后
start slave ; #8.0.22之前
⑤ 查看主从同步状态
sql
show replica status ; #8.0.22之后
show slave status ; #8.0.22之前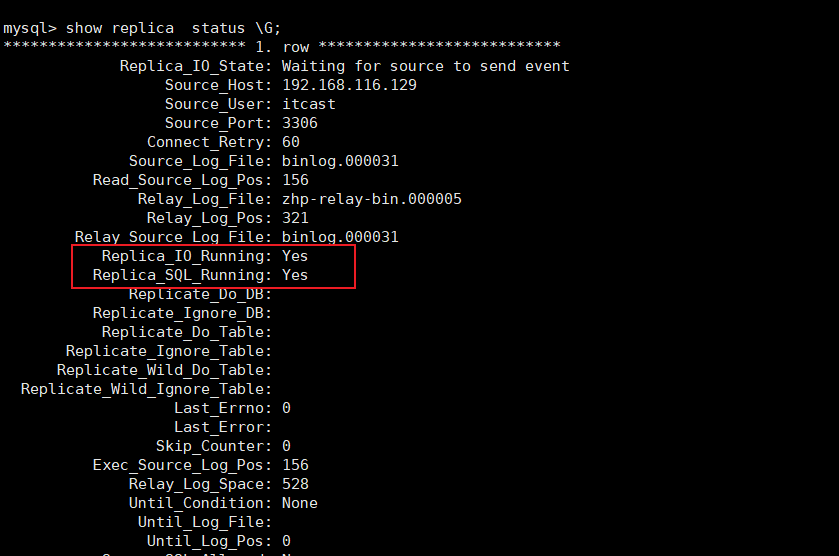
Replica_IO_Running: Yes和Replica_SQL_Running: Yes说明配置成功
测试:
在主库中执行如下:
sql
drop database if exists itcast;
create database itcast;
use itcast;
-- 创建表
CREATE TABLE `products` (
`pid` bigint(32) NOT NULL AUTO_INCREMENT,
`pname` varchar(50) DEFAULT NULL,
`price` int(11) DEFAULT NULL,
`flag` varchar(2) DEFAULT NULL,
PRIMARY KEY (`pid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
insert into products values(1,'拖鞋',20,'1');
insert into products values(2,'拖鞋',20,'1');
insert into products values(3,'拖鞋',20,'1');查看从库是否已经将products表同步过来
4.2 负载均衡测试
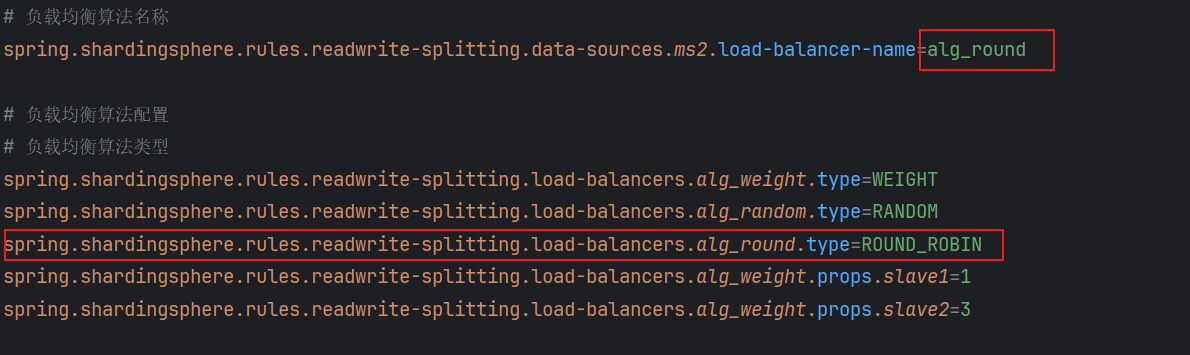
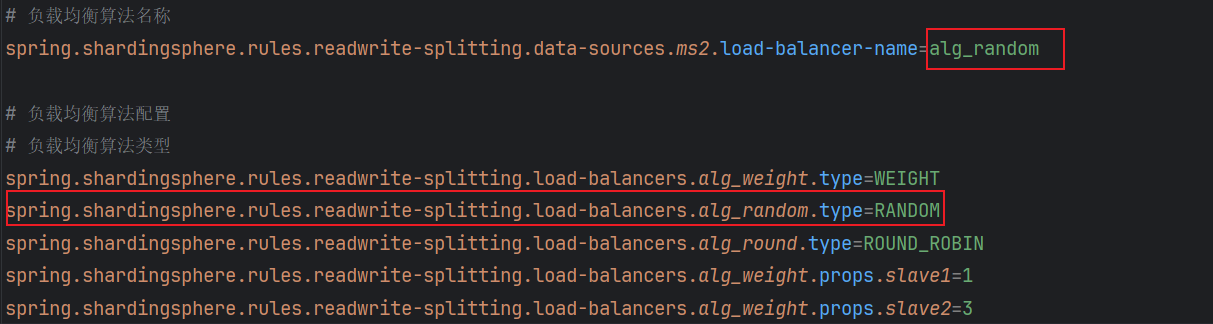
负载均衡算法就是用在如果有多个从库的时候决定查询哪个从库的数据,一共有如下的算法:
-
轮询算法(ROUND_ROBIN)
原理 :按照配置的数据源列表顺序,依次轮流地将请求分发到每一个可用的数据源上
例如,有 2个读库:
read_ds_0、read_ds_1,则请求的分发顺序为:请求1 → read_ds_0 请求2 → read_ds_1 请求3 → read_ds_0 请求4 → read_ds_1 -
随机访问算法(RANDOM)
每次请求时,从所有可用的读数据源中随机选择一个进行访问
-
权重访问算法(WEIGHT)
- 为每个数据源配置一个权重值(如
read_ds_0=3,read_ds_1=1)。 - 使用加权随机算法(如轮盘赌算法),权重越高的数据源被选中的概率越大。
- 例如:
read_ds_0被选中的概率是 75%,read_ds_1是 25%
- 为每个数据源配置一个权重值(如
测试WEIGHT算法配置文件如下:
properties
# 应用名称
spring.application.name=shardingjdbc-table-write-read
#===============数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=master,slave
#数据源1
spring.shardingsphere.datasource.master.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.url = jdbc:mysql://192.168.116.128:3306/itcast?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.master.username = root
spring.shardingsphere.datasource.master.password = 123456
#数据源2
spring.shardingsphere.datasource.slave1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave1.url = jdbc:mysql://192.168.116.129:3306/itcast?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.slave1.username = root
spring.shardingsphere.datasource.slave1.password = 123456
#数据源3
spring.shardingsphere.datasource.slave2.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave2.url = jdbc:mysql://192.168.116.130:3306/itcast?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.slave2.username = root
spring.shardingsphere.datasource.slave2.password = 123456
# 打印SQl
spring.shardingsphere.props.sql-show=true
# 读写分离类型,如: Static,Dynamic, ms2 包含了 m1 和 s1 s2
spring.shardingsphere.rules.readwrite-splitting.data-sources.ms2.type=static
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.ms2.props.write-data-source-name=master
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.ms2.props.read-data-source-names=slave1,slave2
# 负载均衡算法名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.ms2.load-balancer-name=alg_weight
# 负载均衡算法配置
# 负载均衡算法类型
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.type=WEIGHT
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave1=1
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave2=3
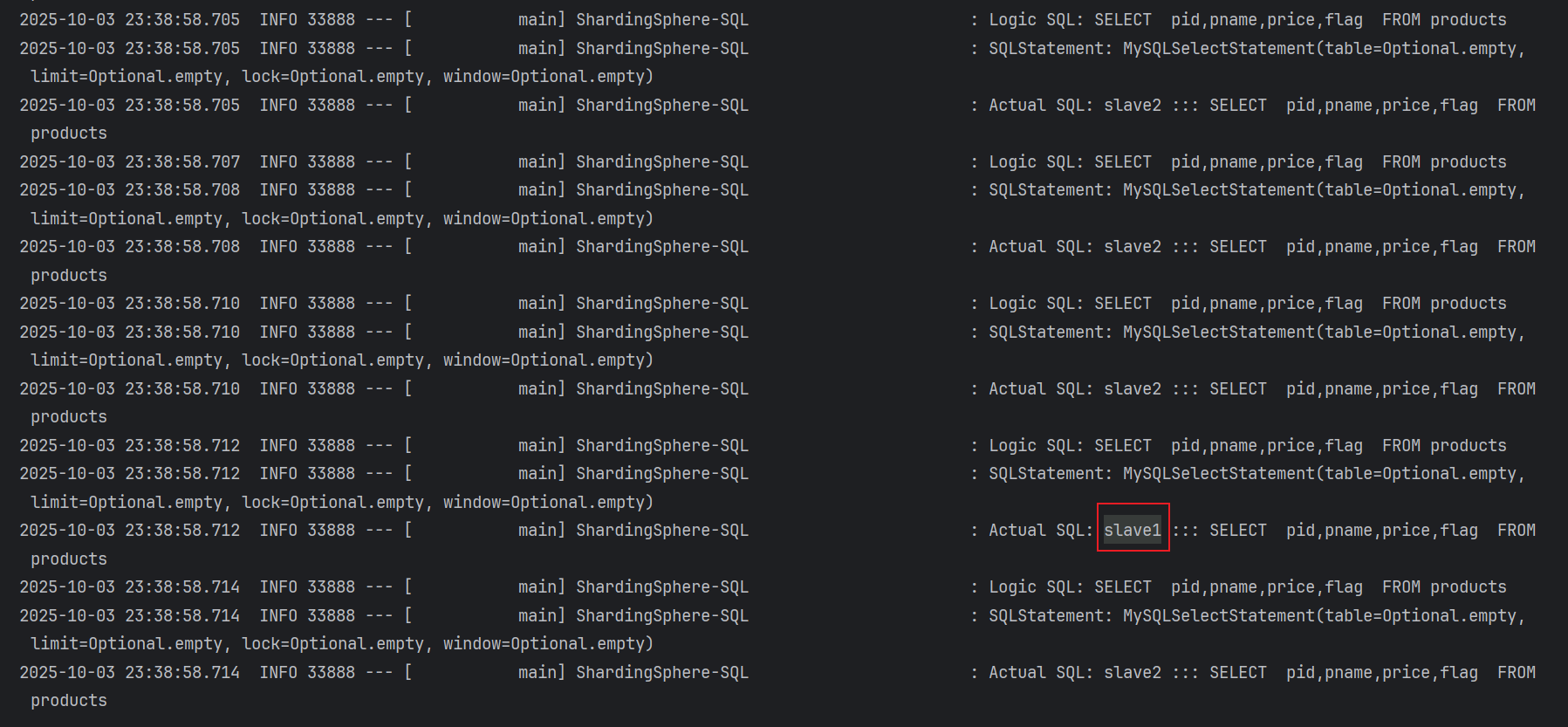
java
@Test
public void testSelectProducts2(){
for (int i = 0; i < 12; i++) {
List<Products> products = productsMapper.selectList(null);
}
}查询结果中有8次从slave2查询4次从slave1查询
RANDOM和ROUND_ROBIN配置方式如下: