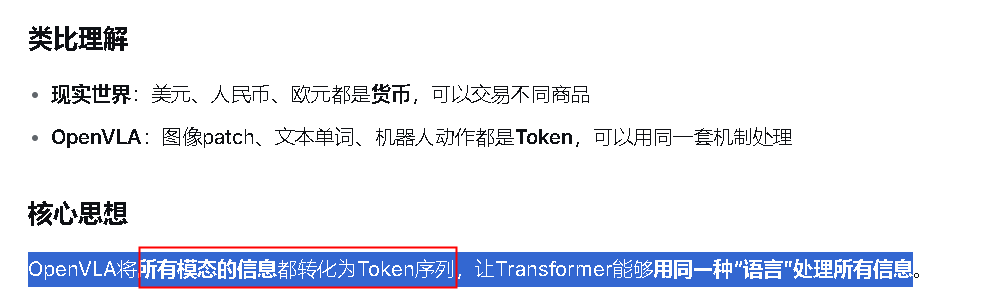
一.由预训练的VLM到VLA
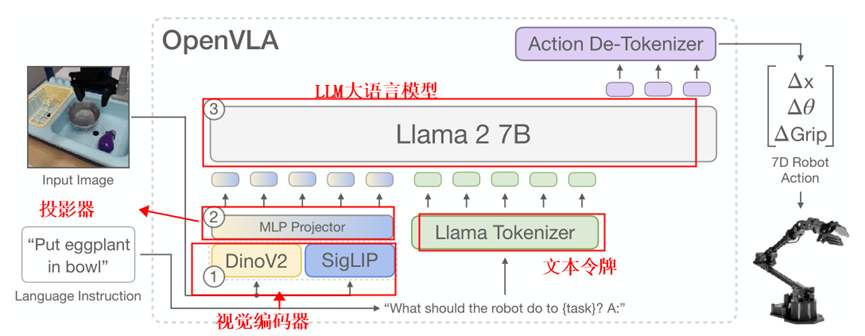
Openvla是基于Prismatic-7B的预训练VLM模型进行训练的。其将动作进行离散化。将训练数据中每个维度动作范围的1%~99%区间的长度(如我dx范围为-10cm~20cm),那么将这个区间以256等分为小区间(1-256)对应了分割后的离散值。那么就可以把连续动作离散后进行训练。


二.VLM的理解
VLM是VLA的框架主干。这里用的是Prismatic-7B,如图1所示。VLM由视觉编码器(DinoV2和SigLIP组成),投影器和LLM(大预言模型)组成

各部分的作用如下:


其中视觉编码器利用了SinLIP-DinoV2的网络,空间理解能力更强,导致Prismatic-7B的VLM相较于其他VLM有更好的效果
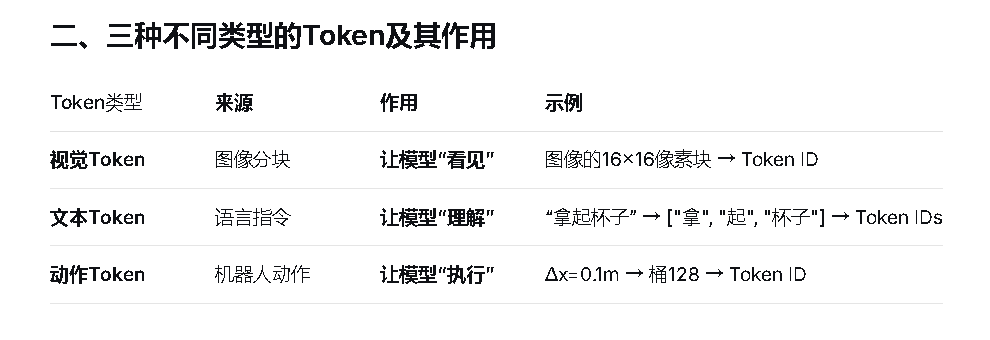
三.Token令牌的理解