嵌入式之协议解析
1. 前言
1.1 为什么嵌入式需要规范的协议解析?
嵌入式系统是硬件与软件的通信枢纽 ,设备间的交互依赖UART/SPI/I2C等物理层通信,以及Modbus/CAN/自定义协议等应用层协议,协议解析是嵌入式数据交互的核心环节 。
嵌入式开发面临字节流无边界、数据异步接收、硬件资源受限、工业环境干扰大 等问题,规范的协议解析并非单纯的代码实现,而是保证数据可靠传输、解决粘包丢包、适配硬件实时性、简化业务与通信解耦的工程化方案。
| 嵌入式通信痛点 | 协议解析的解决思路 |
|---|---|
| 字节流无边界(串口/网口粘包) | 设计定长/帧头帧尾/长度域帧结构,实现帧的精准拆分 |
| 异步数据接收(中断/DMA触发) | 环形缓冲区缓存原始数据,异步接收+同步解析分离 |
| 工业环境干扰(数据错乱/丢包) | 增加校验域(CRC/和校验),实现错误帧过滤与重传 |
| 资源受限(内存/算力不足) | 轻量级状态机解析,静态内存分配,避免复杂算法 |
| 多设备协议兼容(传感器/网关) | 分层解析架构,物理层与应用层解耦,适配多协议 |
| 实时性要求高(工业控制) | 中断级数据接收,解析逻辑极简,避免耗时操作 |
1.2 嵌入式协议解析三大核心原则
嵌入式协议解析的设计需贴合硬件特性,摒弃桌面/服务器端的复杂实现,核心遵循三大原则,所有解析方案均围绕这三大原则展开:
| 原则 | 核心定义 | 实现要求 |
|---|---|---|
| 可靠性 | 保证接收到的数据帧无错、无丢、无粘包,错误帧能快速识别 | 必须包含帧界定符+校验域,实现粘包拆分、错误帧过滤 |
| 轻量级 | 解析逻辑低内存、低CPU占用,适配嵌入式资源受限场景 | 用状态机/查表法替代复杂库,静态缓冲区替代动态分配 |
| 实时性 | 数据接收后快速解析、快速分发,满足工业控制的延时要求 | 异步接收与同步解析分离,解析层仅做数据提取,不处理业务 |
1.3 常见通信协议层级划分
嵌入式的协议解析基于分层思想 ,从物理层到应用层逐步解析,不同层级的解析目标不同,核心关注应用层的帧解析(嵌入式开发的核心工作)。以下是嵌入式最常用的协议层级划分,以及各层级的核心解析目标:
| 协议层级 | 常见协议/接口 | 解析目标 |
|---|---|---|
| 物理层 | UART/RS485/I2C/SPI | 硬件驱动接收原始字节流,完成电平/波特率/时序适配 |
| 链路层 | CAN/LIN/以太网MAC | 完成数据帧的物理层封装/解封装,实现底层错误检测 |
| 网络层/传输层 | IP/UDP/TCP | 轻量级实现,完成数据包的路由/粘包处理 |
| 应用层 | Modbus-RTU/TCP、MQTT、自定义协议 | 嵌入式协议解析核心:完成帧的拆分、校验、数据提取与业务分发 |
本文核心聚焦 :应用层协议解析的工程化实现,包含自定义协议设计、经典解析方法、工业协议实战、嵌入式适配优化等核心内容,贴合实际开发场景。
2. 协议基础:帧结构设计与常用校验
2.1协议帧设计核心:让字节流有"边界"
物理层(如串口)传输的是无边界的字节流 ,无法直接区分"一帧数据"的开始与结束,这是粘包、丢包、帧错位的根本原因。
协议帧 是将原始字节流封装为有固定格式的数据包 ,通过帧界定符 让解析端能精准拆分出单帧数据,是协议解析的基础前提 。
帧结构设计遵循极简原则 ,拒绝冗余字段,核心包含5大基础字段 (可根据需求裁剪),字段顺序固定以降低解析复杂度:
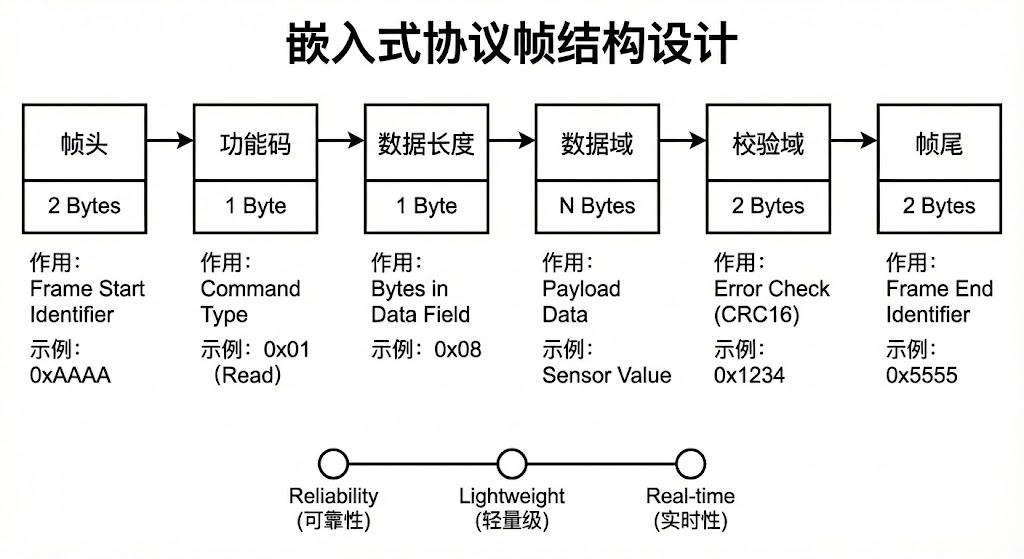
| 帧字段 | 核心作用 | 设计要求 | 常用取值/类型 |
|---|---|---|---|
| 帧头 | 帧的开始标识,触发解析开始 | 1-2字节,取非数据常用值(如0xAA、0x55),避免与数据冲突 | 0xAA、0x55AA、0xFE |
| 功能码 | 标识帧的业务类型(读/写/上报/应答) | 1字节,便于解析后快速分发到对应业务模块 | 0x01(读)、0x02(写)、0x03(上报) |
| 数据长度 | 标识数据域的字节数(可选,不定长帧必备) | 1-2字节,根据最大数据量选择(2字节支持最大65535字节) | 0x04(数据域4字节) |
| 数据域 | 实际业务数据(如传感器值、控制指令) | 长度灵活,定长/不定长均可,数据格式统一(如大端/小端) | 温湿度值(0x1906=25.06℃)、控制指令(0x01=启动) |
| 校验域 | 验证帧的完整性,过滤干扰导致的错误帧 | 1-2字节,轻量级校验算法,避免复杂计算 | CRC8/CRC16、和校验、异或校验 |
| 帧尾 | 帧的结束标识,完成帧的拆分(可选,帧头+长度域可替代) | 1-2字节,与帧头配合,进一步提升帧界定的可靠性 | 0x55、0xAA55、0xFF |
2.2 常用轻量级校验算法(附C++实现)
嵌入式协议解析的校验算法需满足算力受限要求 ,优先选择计算快、代码量少、校验可靠性足够 的轻量级算法,以下是3种最常用的校验算法,按可靠性从低到高、计算复杂度从低到高排序,可根据场景选择:
(1)和校验(Sum Check)
- 核心思想:将帧中参与校验的所有字节相加,取低8/16位作为校验值,解析端重新计算并对比;
- 特点 :代码极简、计算最快,适合低干扰场景(如板内I2C/SPI通信);
- 缺点:校验可靠性低,易出现"数据错乱但和值不变"的情况。
(2)异或校验(XOR Check)
- 核心思想:将帧中参与校验的所有字节依次异或,最终结果作为校验值;
- 特点 :代码极简、计算快,可靠性略高于和校验,适合简单板间通信;
- 缺点:对连续相同字节的错乱校验效果差。
(3)CRC校验(Cyclic Redundancy Check)
- 核心思想 :基于多项式除法的循环冗余校验,常用CRC8/CRC16(CRC32极少用);
- 特点 :校验可靠性高,能检测出绝大多数数据错乱,适合工业现场高干扰场景(如RS485/Modbus);
- 缺点:代码略复杂(可复用标准代码),计算量略高于和/异或校验(嵌入式完全可接受)。
代码示例:常用校验算法(C++轻量级实现)
cpp
#include <cstdint>
#include <array>
// 校验算法工具类(单例饿汉式,核心硬件适配,ISR兼容)
class CheckSumUtil {
private:
CheckSumUtil() = default;
CheckSumUtil(const CheckSumUtil&) = delete;
CheckSumUtil& operator=(const CheckSumUtil&) = delete;
static CheckSumUtil instance_;
// CRC16-Modbus标准多项式:0x8005,初始值0xFFFF,反向输出
const uint16_t CRC16_POLY = 0x8005;
const uint16_t CRC16_INIT = 0xFFFF;
public:
static CheckSumUtil& getInstance() { return instance_; }
// 8位和校验:计算data中所有字节的和,取低8位
uint8_t sumCheck8(const std::array<uint8_t, 128>& data, uint8_t len) {
uint8_t sum = 0;
for (uint8_t i = 0; i < len; i++) sum += data[i];
return sum & 0xFF;
}
// 8位异或校验:计算data中所有字节的异或
uint8_t xorCheck8(const std::array<uint8_t, 128>& data, uint8_t len) {
uint8_t xor_val = 0;
for (uint8_t i = 0; i < len; i++) xor_val ^= data[i];
return xor_val;
}
// CRC16-Modbus校验
uint16_t crc16Modbus(const std::array<uint8_t, 128>& data, uint8_t len) {
uint16_t crc = CRC16_INIT;
for (uint8_t i = 0; i < len; i++) {
crc ^= (uint16_t)data[i] << 8;
for (uint8_t j = 0; j < 8; j++) {
if (crc & 0x8000) crc = (crc << 1) ^ CRC16_POLY;
else crc <<= 1;
}
}
return crc & 0xFFFF;
}
};
// 饿汉式单例初始化,程序启动时创建,ISR可调用
CheckSumUtil CheckSumUtil::instance_;3. 协议解析核心方法(附C++实现)
应用层协议解析的核心目标 是:从异步接收的原始字节流中,精准拆分出完整的协议帧 ,并完成校验与数据提取。
根据帧结构的不同,嵌入式最常用的解析方法分为4类 ,从简单到复杂依次为:定长帧解析、帧头帧尾型不定长帧解析、长度域型不定长帧解析、流解析(状态机),每一种方法均提供特性分析、C++代码实现、适用场景,并贴合硬件特性(如串口、环形缓冲区、静态内存)。
3.1 方法1:定长帧解析
核心介绍
定长帧是最简单的协议帧结构 ,整帧数据的字节数固定不变 ,解析端只需按固定长度从字节流中截取数据,完成校验即可,无需帧头/帧尾/长度域(可按需加简单校验)。
定长帧解析是入门级解析方法,代码极简、解析效率最高、资源占用最低,是板内通信、简单传感器通信的首选。
核心特性
- 优点:代码极简、解析速度最快、无粘包处理成本、内存占用极低;
- 缺点:灵活性差,数据量变化时需修改帧长度,不适合数据量不固定的场景;
- 关键要求:发送端与接收端帧长度必须严格一致,否则会导致帧错位;
- 适配校验:优先和校验/异或校验(足够用),高干扰场景可加CRC8。
代码示例:串口定长帧解析(C++)
cpp
#include <iostream>
#include <cstdint>
#include <array>
#include <unistd.h>
#include <fcntl.h>
#include <termios.h>
// 定长帧配置:板内串口通信,帧长8字节(固定)
const uint8_t FIX_FRAME_LEN = 8;
// 串口设备节点
const char* SERIAL_DEV = "/dev/ttyS0";
// 串口初始化(标准配置,9600-8-N-1)
int serialInit(const char* dev) {
int fd = open(dev, O_RDWR | O_NOCTTY | O_NDELAY);
if (fd < 0) { std::cerr << "串口打开失败" << std::endl; return -1; }
struct termios opt;
tcgetattr(fd, &opt);
cfsetispeed(&opt, B9600); cfsetospeed(&opt, B9600);
opt.c_cflag |= CLOCAL | CREAD;
opt.c_cflag &= ~CSIZE; opt.c_cflag |= CS8;
opt.c_cflag &= ~PARENB; opt.c_cflag &= ~CSTOPB;
tcsetattr(fd, TCSANOW, &opt);
return fd;
}
// 定长帧解析核心函数(嵌轻量级,静态缓冲区)
bool fixFrameParse(int serial_fd, std::array<uint8_t, FIX_FRAME_LEN>& frame_data) {
// 按固定长度读取串口数据
int read_len = read(serial_fd, frame_data.data(), FIX_FRAME_LEN);
if (read_len != FIX_FRAME_LEN) {
std::cerr << "定长帧读取失败,实际读取:" << read_len << "字节" << std::endl;
return false;
}
// 校验:取前7字节和校验,第8字节为校验位(定长帧标配)
CheckSumUtil& check_util = CheckSumUtil::getInstance();
uint8_t calc_sum = check_util.sumCheck8(frame_data, FIX_FRAME_LEN-1);
uint8_t recv_sum = frame_data[FIX_FRAME_LEN-1];
if (calc_sum != recv_sum) {
std::cerr << "定长帧校验失败,计算:0x" << std::hex << (int)calc_sum
<< " 接收:0x" << (int)recv_sum << std::dec << std::endl;
return false;
}
std::cout << "定长帧解析成功,数据:";
for (uint8_t i = 0; i < FIX_FRAME_LEN-1; i++) {
std::cout << "0x" << std::hex << (int)frame_data[i] << " ";
}
std::cout << std::dec << std::endl;
return true;
}
// 测试函数
void testFixFrameParse() {
std::cout << "===== 定长帧解析测试 =====" << std::endl;
int serial_fd = serialInit(SERIAL_DEV);
if (serial_fd < 0) return;
std::array<uint8_t, FIX_FRAME_LEN> frame_data;
while (1) {
if (fixFrameParse(serial_fd, frame_data)) break;
usleep(10000); // 10ms轮询,轻量级方式
}
close(serial_fd);
}适用场景
- 板内近距离通信(UART/I2C/SPI),如MCU与板载传感器、显示屏的通信;
- 数据量固定的简单业务,如温湿度传感器定时上报(固定4字节数据)、设备状态查询(固定2字节返回);
- 资源极度受限的嵌入式系统(如51单片机、小型MCU),优先选择定长帧解析。
3.2 方法2:帧头帧尾型不定长帧解析
核心介绍
帧头帧尾型是嵌入式最常用的不定长帧结构 ,通过唯一的帧头(如0xAA)和帧尾(如0x55) 界定一帧数据的开始与结束,解析端从字节流中查找"帧头开始→帧尾结束"的完整数据段,即为一帧有效数据。
该方法解决了定长帧灵活性差 的问题,数据域长度可动态变化,是嵌入式板间通信、工业现场通信的主流选择(如RS485)。
核心特性
- 优点:灵活性高、数据域长度可动态变化、帧界定清晰、代码实现简单;
- 缺点:需处理帧头/帧尾与数据冲突的问题(如数据中出现0xAA/0x55),需做转义处理;
- 关键要求:帧头/帧尾需选择非数据常用值 ,若数据中可能出现帧头/帧尾,必须实现字节转义(如0xAA→0xAB 0x01);
- 适配校验:优先CRC8/CRC16(工业场景),简单场景可加和校验。
代码示例:帧头帧尾型不定长帧解析(C++)
cpp
#include <iostream>
#include <cstdint>
#include <array>
#include <vector>
#include <unistd.h>
// 帧头帧尾配置
const uint8_t FRAME_HEAD = 0xAA;
const uint8_t FRAME_TAIL = 0x55;
// 最大帧长:限制最大帧长,避免内存溢出
const uint8_t MAX_FRAME_LEN = 64;
// 接收缓冲区:静态数组
std::array<uint8_t, 128> recv_buf;
uint8_t buf_idx = 0;
// 帧头帧尾型不定长帧解析核心函数(状态机思想,轻量级)
bool headTailFrameParse(uint8_t data) {
// 步骤1:将新接收的字节加入缓冲区
if (buf_idx >= recv_buf.size()) { buf_idx = 0; std::cerr << "接收缓冲区溢出" << std::endl; return false; }
recv_buf[buf_idx++] = data;
// 步骤2:查找帧尾,且缓冲区中存在帧头
bool has_head = false;
uint8_t head_idx = 0;
for (uint8_t i = 0; i < buf_idx; i++) {
if (recv_buf[i] == FRAME_HEAD) { has_head = true; head_idx = i; }
// 找到帧尾,且前面有帧头:提取完整帧
if (has_head && recv_buf[i] == FRAME_TAIL) {
uint8_t frame_len = i - head_idx + 1;
if (frame_len < 3 || frame_len > MAX_FRAME_LEN) { // 最小帧:头+校验+尾(3字节)
buf_idx = 0; has_head = false;
std::cerr << "帧长非法:" << (int)frame_len << std::endl;
return false;
}
// 提取完整帧
std::array<uint8_t, MAX_FRAME_LEN> frame_data;
for (uint8_t j = 0; j < frame_len; j++) frame_data[j] = recv_buf[head_idx + j];
// 清空缓冲区(处理下一包)
buf_idx = 0;
// 步骤3:CRC16校验(帧头到数据域,最后2字节为CRC16)
CheckSumUtil& check_util = CheckSumUtil::getInstance();
uint16_t calc_crc = check_util.crc16Modbus(frame_data, frame_len - 2);
uint16_t recv_crc = (frame_data[frame_len-2] << 8) | frame_data[frame_len-1];
if (calc_crc != recv_crc) {
std::cerr << "CRC校验失败,计算:0x" << std::hex << calc_crc
<< " 接收:0x" << recv_crc << std::dec << std::endl;
return false;
}
// 步骤4:解析成功,提取业务数据(帧头后到校验前)
std::cout << "帧头帧尾型帧解析成功,帧长:" << (int)frame_len
<< " 业务数据:";
for (uint8_t j = 1; j < frame_len-3; j++) {
std::cout << "0x" << std::hex << (int)frame_data[j] << " ";
}
std::cout << std::dec << std::endl;
return true;
}
}
return false;
}
// 模拟LoRa异步接收(真实场景:中断/DMA触发此函数)
void simulateLoRaRecv(uint8_t* data, uint8_t len) {
for (uint8_t i = 0; i < len; i++) {
headTailFrameParse(data[i]);
}
}
// 测试函数
void testHeadTailFrameParse() {
std::cout << "\n===== 帧头帧尾型不定长帧解析测试 =====" << std::endl;
// 模拟LoRa发送的一帧数据:头(0xAA)+功能码(0x03)+数据(0x1906)+CRC16(0x789A)+尾(0x55)
uint8_t test_data[] = {0xAA, 0x03, 0x19, 0x06, 0x78, 0x9A, 0x55};
simulateLoRaRecv(test_data, sizeof(test_data)/sizeof(test_data[0]));
}适用场景
- 板间远距离通信(RS485、LoRa、4G),如工业传感器与网关、设备与云平台的通信;
- 数据量动态变化的业务,如传感器批量上报、设备控制指令(不同指令数据量不同);
- 工业现场高干扰场景,帧头帧尾+CRC16的组合能保证数据可靠性。
3.3 方法3:长度域型不定长帧解析
核心介绍
长度域型是最灵活、最可靠的不定长帧结构 ,结合了定长帧的解析高效 和帧头帧尾型的灵活性 ,通过帧头+长度域 界定帧的范围:帧头标识帧开始,长度域标识后续数据的总字节数,解析端找到帧头后,读取长度域的值,再按该值截取后续字节,即为完整帧。
该方法是工业标准协议的主流选择(如CAN),无需处理帧头/帧尾与数据的冲突,解析效率高于帧头帧尾型。
核心特性
- 优点:灵活性高、解析效率高、无需字节转义、帧界定可靠,是工业标准协议的首选;
- 缺点:代码实现略复杂,需严格保证长度域的正确性(长度域错乱会导致帧错位);
- 关键要求:长度域的取值范围必须明确,解析端需校验长度域的合法性(如不超过最大帧长),避免内存溢出;
- 适配校验:优先CRC16(工业标准),如Modbus-RTU的CRC16校验。
代码示例:长度域型不定长帧解析(Linux C++)
cpp
#include <iostream>
#include <cstdint>
#include <array>
#include <unistd.h>
// 长度域型帧配置
const uint8_t FRAME_HEAD = 0x01; // 从站地址(Modbus-RTU帧头)
const uint8_t MAX_FRAME_LEN = 64;
// 接收缓冲区与索引:静态全局,异步接收必备
std::array<uint8_t, 128> recv_buf;
uint8_t buf_idx = 0;
// 解析状态:0-空闲,1-找到帧头,2-读取长度域,3-读取数据域
uint8_t parse_state = 0;
// 长度域型不定长帧解析核心函数(状态机)
bool lenFieldFrameParse(uint8_t data) {
// 步骤1:缓冲区溢出保护
if (buf_idx >= recv_buf.size()) { buf_idx = 0; parse_state = 0; std::cerr << "接收缓冲区溢出" << std::endl; return false; }
recv_buf[buf_idx++] = data;
switch (parse_state) {
case 0: // 空闲状态:查找帧头(Modbus-RTU从站地址)
if (data == FRAME_HEAD) {
parse_state = 1;
std::cout << "找到帧头(从站地址):0x" << std::hex << (int)data << std::dec << std::endl;
}
break;
case 1: // 找到帧头:读取功能码,下一字节为数据长度(Modbus-RTU简化版)
parse_state = 2;
break;
case 2: // 读取长度域:获取数据域字节数
{
uint8_t data_len = data;
// 校验长度域合法性:不超过最大帧长,且能容纳校验位
if (data_len == 0 || data_len + 4 > MAX_FRAME_LEN) { // 头+功能码+长度+数据+CRC16(4字节基础)
buf_idx = 0; parse_state = 0;
std::cerr << "长度域非法:" << (int)data_len << std::endl;
return false;
}
// 计算完整帧长:头(1)+功能码(1)+长度(1)+数据(data_len)+CRC16(2)
uint8_t frame_len = 1 + 1 + 1 + data_len + 2;
// 等待接收完整帧
if (buf_idx >= frame_len) {
parse_state = 3;
}
}
break;
case 3: // 接收完整帧:CRC16校验+解析
{
uint8_t frame_len = buf_idx;
std::array<uint8_t, MAX_FRAME_LEN> frame_data;
for (uint8_t i = 0; i < frame_len; i++) frame_data[i] = recv_buf[i];
// CRC16校验(帧头到数据域,最后2字节为CRC)
CheckSumUtil& check_util = CheckSumUtil::getInstance();
uint16_t calc_crc = check_util.crc16Modbus(frame_data, frame_len - 2);
uint16_t recv_crc = (frame_data[frame_len-2] << 8) | frame_data[frame_len-1];
if (calc_crc == recv_crc) {
std::cout << "长度域型帧解析成功,帧长:" << (int)frame_len
<< " 从站地址:0x" << std::hex << (int)frame_data[0]
<< " 功能码:0x" << (int)frame_data[1] << std::dec << std::endl;
// 解析成功,重置状态
buf_idx = 0; parse_state = 0;
return true;
} else {
std::cerr << "CRC校验失败,计算:0x" << std::hex << calc_crc
<< " 接收:0x" << recv_crc << std::dec << std::endl;
buf_idx = 0; parse_state = 0;
return false;
}
}
break;
default:
buf_idx = 0; parse_state = 0;
break;
}
return false;
}
// 模拟RS485异步接收(中断/DMA触发)
void simulateRS485Recv(uint8_t* data, uint8_t len) {
for (uint8_t i = 0; i < len; i++) {
lenFieldFrameParse(data[i]);
}
}
// 测试函数
void testLenFieldFrameParse() {
std::cout << "\n===== 长度域型不定长帧解析测试 =====" << std::endl;
// 模拟Modbus-RTU数据:从站(0x01)+功能码(0x03)+长度(0x02)+数据(0x0001)+CRC16(0x840A)
uint8_t test_data[] = {0x01, 0x03, 0x02, 0x00, 0x01, 0x84, 0x0A};
simulateRS485Recv(test_data, sizeof(test_data)/sizeof(test_data[0]));
}适用场景
- 工业标准协议解析(Modbus-RTU/TCP、CAN、Profinet),嵌入式工业网关、PLC、工业传感器的核心通信方式;
- 对解析效率和可靠性要求高的场景,如工业控制、车载通信、智能电网;
- 数据量动态变化且易出现帧头/帧尾冲突的场景,长度域型无需转义,解析更高效。
3.4 方法4:流解析(状态机通用解析框架)
核心介绍
流解析是协议解析的通用框架 ,基于有限状态机(FSM) 实现,将解析过程拆分为多个状态 (如空闲、找帧头、读长度、读数据、找帧尾、校验),每接收一个字节,根据当前状态和字节值切换到下一个状态 ,直到进入"解析完成"状态,输出完整帧。
流解析是前三种方法的通用抽象 ,定长帧、帧头帧尾型、长度域型均可基于状态机实现,是嵌入式复杂协议解析的标准方案,能完美解决粘包、丢包、帧错位等问题。
核心特性
- 优点:通用性强、能处理所有帧结构、抗干扰能力强、完美解决粘包丢包,是嵌入式复杂协议的首选;
- 缺点:代码实现略复杂,需合理设计状态机,避免状态过多导致逻辑臃肿;
- 关键要求:状态机的状态划分需简洁(建议不超过8个状态),每个状态仅处理单一逻辑,避免状态跳转混乱;
- 适配场景:所有协议解析场景,尤其是复杂自定义协议、工业标准协议。
3.5 嵌入式协议解析核心方法对比表
| 解析方法 | 核心帧结构 | 核心优点 | 核心缺点 | 解析效率 | 嵌入式适用场景 | 工业协议参考 |
|---|---|---|---|---|---|---|
| 定长帧解析 | 固定字节数帧 | 代码极简、解析最快、内存占用最低 | 灵活性差、数据量固定 | ★★★★★ | 板内通信、简单传感器、资源极度受限系统 | 板载I2C/SPI自定义协议 |
| 帧头帧尾型不定长帧解析 | 帧头+数据+校验+帧尾 | 灵活性高、帧界定清晰、实现简单 | 需处理字节转义、易受数据冲突影响 | ★★★★☆ | 板间远距离通信、LoRa/4G、简单自定义协议 | LoRa/RS485自定义协议 |
| 长度域型不定长帧解析 | 帧头+功能码+长度域+数据+校验 | 灵活性高、解析高效、无需转义 | 长度域错乱易导致帧错位 | ★★★★★ | 工业标准协议、高可靠性板间通信 | Modbus-RTU、CAN |
| 流解析(状态机) | 基于状态机抽象所有帧结构 | 通用性强、抗干扰、解决所有通信问题 | 代码实现略复杂、需设计状态机 | ★★★★☆ | 复杂自定义协议、工业标准协议、所有场景 | Modbus-TCP、MQTT、复杂自定义协议 |
4. 协议解析核心架构:异步接收+同步解析
嵌入式通信的数据接收是异步的 (如串口中断、DMA、LoRa接收中断),而协议解析是同步的 (需完整的字节流才能解析),若直接在中断中做解析,会导致中断阻塞、实时性下降 (解析逻辑可能耗时)。
协议解析的标准架构 是:异步接收 + 同步解析 + 环形缓冲区缓存 ,将"数据接收"和"协议解析"解耦,中断仅做数据接收和缓冲区写入 ,解析逻辑在主线程/任务 中执行,这是保证实时性和可靠性的核心设计。
4.1 核心架构分层设计
协议解析架构分为5层 ,从下到上逐步实现,层与层之间解耦,修改某一层不影响其他层,符合"高内聚、低耦合"的工程化要求:
| 架构分层 | 核心职责 | 实现要求 | 硬件/软件适配 |
|---|---|---|---|
| 物理层驱动 | 硬件底层接收/发送原始字节流,完成波特率/时序/电平适配 | 中断/DMA实现,无耗时操作,快速响应 | UART/RS485/LoRa驱动、Linux设备节点(/dev/ttyS0) |
| 环形缓冲区 | 缓存异步接收的原始字节流,解决"接收快、解析慢"的问题 | 静态内存实现、先进先出(FIFO)、无锁/轻锁 | C++静态数组实现,避免动态分配 |
| 帧检测层 | 从环形缓冲区中提取字节,基于状态机完成帧的拆分 | 轻量级状态机、仅做帧拆分,不做校验/解析 | 定长/帧头帧尾/长度域帧的通用帧检测 |
| 帧解析层 | 对拆分后的完整帧做校验、数据提取、格式转换 | 仅做数据处理,不处理业务逻辑,极简高效 | CRC校验、字节序转换(大端→小端)、数据提取 |
| 业务分发层 | 将解析后的有效数据分发到对应业务模块 | 根据功能码分发,业务与通信完全解耦 | 传感器数据上报、设备控制指令执行、数据存储 |
4.2 核心组件:环形缓冲区(C++实现)
环形缓冲区(Circular Buffer)是异步接收+同步解析 的核心组件 ,解决了"接收端速度快、解析端速度慢"导致的数据丢失问题,是协议解析的必备组件 。
环形缓冲区需满足:静态内存分配、先进先出、无锁操作(单读单写)、溢出保护,以下是C++轻量级实现,适配单读单写场景(中断写、主线程读,无需加锁)。
代码示例:环形缓冲区(C++静态实现)
cpp
#include <cstdint>
#include <array>
#include <atomic>
// 环形缓冲区配置:单读单写(中断写、主线程读),无锁,静态内存
const uint32_t CIRC_BUF_SIZE = 256;
using CircBufType = std::array<uint8_t, CIRC_BUF_SIZE>;
class CircularBuffer {
public:
CircularBuffer() : head_(0), tail_(0) {}
~CircularBuffer() = default;
// 写入一个字节(中断中调用,无锁,单写)
bool write(uint8_t data) {
uint32_t next_head = (head_ + 1) % CIRC_BUF_SIZE;
if (next_head == tail_) { return false; } // 缓冲区满
buf_[head_] = data;
head_ = next_head;
return true;
}
// 读取一个字节(主线程调用,无锁,单读)
bool read(uint8_t& data) {
if (head_ == tail_) { return false; } // 缓冲区空
data = buf_[tail_];
tail_ = (tail_ + 1) % CIRC_BUF_SIZE;
return true;
}
// 清空缓冲区
void clear() {
head_ = 0;
tail_ = 0;
}
// 获取缓冲区有效数据长度
uint32_t getLen() {
return (head_ - tail_ + CIRC_BUF_SIZE) % CIRC_BUF_SIZE;
}
private:
CircBufType buf_; // 静态缓冲区
std::atomic<uint32_t> head_; // 写指针,原子操作避免编译器重排
std::atomic<uint32_t> tail_; // 读指针,原子操作避免编译器重排
};
// 全局环形缓冲区实例(饿汉式,中断可调用)
CircularBuffer g_circ_buf;4.3 完整架构代码示例:C++协议解析全流程
cpp
#include <iostream>
#include <cstdint>
#include <unistd.h>
#include <fcntl.h>
// 复用之前的:CheckSumUtil、CircularBuffer、g_circ_buf
// 帧配置:长度域型(Modbus-RTU简化版)
const uint8_t FRAME_HEAD = 0x01;
const uint8_t MAX_FRAME_LEN = 64;
// 解析状态机:0-空闲,1-找帧头,2-读功能码,3-读长度域,4-读数据域,5-校验完成
uint8_t g_parse_state = 0;
std::array<uint8_t, MAX_FRAME_LEN> g_frame_buf;
uint8_t g_frame_idx = 0;
uint8_t g_data_len = 0;
// 步骤1:物理层驱动------串口中断接收(模拟,真实场景为硬件中断)
void serialRecvIsr(int serial_fd) {
uint8_t data;
while (read(serial_fd, &data, 1) > 0) {
// 中断中仅做:写入环形缓冲区,无其他耗时操作
if (!g_circ_buf.write(data)) {
std::cerr << "环形缓冲区满,数据丢失" << std::endl;
}
}
}
// 步骤2:帧检测+帧解析------状态机解析(主线程执行,同步解析)
bool frameParseFsm() {
uint8_t data;
while (g_circ_buf.read(data)) { // 从环形缓冲区读取字节
switch (g_parse_state) {
case 0: // 空闲:找帧头
if (data == FRAME_HEAD) {
g_frame_buf[g_frame_idx++] = data;
g_parse_state = 1;
}
break;
case 1: // 找帧头成功:读功能码
g_frame_buf[g_frame_idx++] = data;
g_parse_state = 2;
break;
case 2: // 读功能码成功:读长度域
g_data_len = data;
if (g_data_len == 0 || g_data_len + 4 > MAX_FRAME_LEN) {
g_frame_idx = 0; g_parse_state = 0;
return false;
}
g_frame_buf[g_frame_idx++] = data;
g_parse_state = 3;
break;
case 3: // 读长度域成功:读数据域
g_frame_buf[g_frame_idx++] = data;
if (g_frame_idx >= 3 + g_data_len) { // 头+功能码+长度 + 数据域
g_parse_state = 4;
}
break;
case 4: // 读数据域成功:读CRC16并校验
g_frame_buf[g_frame_idx++] = data;
if (g_frame_idx >= 3 + g_data_len + 2) { // +CRC16(2)
// CRC16校验
CheckSumUtil& check_util = CheckSumUtil::getInstance();
uint16_t calc_crc = check_util.crc16Modbus(g_frame_buf, g_frame_idx - 2);
uint16_t recv_crc = (g_frame_buf[g_frame_idx-2] << 8) | g_frame_buf[g_frame_idx-1];
if (calc_crc == recv_crc) {
g_parse_state = 5;
} else {
g_frame_idx = 0; g_parse_state = 0;
std::cerr << "CRC校验失败" << std::endl;
return false;
}
}
break;
case 5: // 解析完成:返回有效帧
std::cout << "协议解析全流程成功,完整帧:";
for (uint8_t i = 0; i < g_frame_idx; i++) {
std::cout << "0x" << std::hex << (int)g_frame_buf[i] << " ";
}
std::cout << std::dec << std::endl;
// 重置状态,准备解析下一帧
g_frame_idx = 0; g_parse_state = 0;
return true;
}
}
return false;
}
// 步骤3:业务分发层------根据功能码分发业务
void businessDispatch(const std::array<uint8_t, MAX_FRAME_LEN>& frame, uint8_t len) {
uint8_t func_code = frame[1];
switch (func_code) {
case 0x03: // 读数据指令
std::cout << "业务分发:执行读数据指令,传感器值:0x" << std::hex
<< (int)frame[3] << (int)frame[4] << std::dec << std::endl;
break;
case 0x06: // 写数据指令
std::cout << "业务分发:执行写数据指令,设置值:0x" << std::hex
<< (int)frame[3] << (int)frame[4] << std::dec << std::endl;
break;
default:
std::cerr << "业务分发:不支持的功能码:0x" << std::hex << (int)func_code << std::dec << std::endl;
break;
}
}
// 主函数:协议解析全流程
int main() {
// 1. 初始化串口
int serial_fd = serialInit(SERIAL_DEV);
if (serial_fd < 0) return -1;
// 2. 主循环:标准主循环
while (1) {
// 2.1 模拟串口中断接收(真实场景为硬件中断)
serialRecvIsr(serial_fd);
// 2.2 帧解析(同步)
if (frameParseFsm()) {
// 2.3 业务分发
businessDispatch(g_frame_buf, g_frame_idx);
}
usleep(10000); // 10ms轮询
}
close(serial_fd);
return 0;
}5. 协议解析的优化与适配策略
协议解析的核心是在资源受限、实时性要求高、工业环境干扰大 的前提下,保证解析的可靠性和效率 ,单纯的基础解析实现无法满足实际场景,需结合硬件特性做针对性优化 。
以下是6个协议解析的核心优化策略,覆盖内存、算力、实时性、抗干扰等痛点。
5.1 硬件层优化:中断+DMA接收,减少CPU占用
物理层的数据接收优先使用中断+DMA 方式,替代传统的"轮询接收",DMA(直接存储器访问)能在不占用CPU 的情况下,将硬件接收到的字节流直接写入内存(环形缓冲区),仅在接收完成后触发一次中断,通知CPU处理。
优化效果 :CPU占用率从轮询的50%+降至5%以下,大幅提升系统实时性,是高速通信 的标配。
适配:Linux下可通过设备树配置DMA,裸机开发可直接配置硬件DMA寄存器,UART/RS485/LoRa均支持DMA接收。
5.2 内存层优化:静态内存分配,拒绝动态申请
嵌入式系统无垃圾回收(GC) ,动态内存分配(new/malloc)会导致内存碎片、内存泄漏、分配失败 ,尤其是在长期运行的工业设备中,内存碎片会逐步导致系统崩溃。
优化策略:
- 所有缓冲区(接收缓冲区、帧缓冲区、环形缓冲区)均使用静态数组/
std::array实现,拒绝std::vector/动态数组; - 所有类的实例均使用栈分配/饿汉式单例,拒绝堆分配;
- 限制最大帧长,避免缓冲区溢出,所有缓冲区长度均为2的幂次(如64、128、256),提升内存访问效率。
5.3 解析层优化:状态机极简设计,避免冗余逻辑
协议解析的状态机状态数越少越好 (建议不超过8个),每个状态仅处理单一逻辑 ,避免状态跳转混乱和冗余逻辑,解析层仅做帧拆分、校验、数据提取 ,不处理任何业务逻辑。
优化策略:
- 状态机的每个状态仅判断1-2个核心条件(如是否为帧头、长度域是否合法);
- 校验算法使用预编译的标准代码(如CRC16-Modbus),避免运行时动态计算;
- 字节序转换(大端→小端)使用位运算,替代复杂的库函数。
5.4 抗干扰优化:多重错误检测,过滤无效帧
工业现场存在电磁干扰、信号衰减、线路接触不良 等问题,会导致数据错乱、丢包、帧错位,仅靠单一的CRC校验无法满足工业级可靠性要求,需实现多重错误检测 。
优化策略:
- 帧长检测:校验帧长是否在合法范围内,过滤过短/过长的无效帧;
- 帧头/帧尾检测:过滤无帧头/帧尾的无效帧;
- 长度域检测:校验长度域是否与实际数据长度一致,过滤长度域错乱的帧;
- CRC校验:工业场景必须使用CRC8/CRC16,过滤数据错乱的帧;
- 超时检测:设置帧接收超时时间(如100ms),超时则清空缓冲区,避免帧错位。
5.5 实时性优化:中断级轻量处理,主线程业务分发
实时性核心 是:中断服务函数(ISR)必须极简 ,中断中仅做数据接收和环形缓冲区写入 ,不做任何解析、校验、业务逻辑,所有耗时操作均放在主线程/任务 中执行。
优化策略:
- ISR的执行时间控制在10us以内,仅包含"读取字节→写入环形缓冲区"的核心逻辑;
- 主线程的解析逻辑使用短轮询(如10ms),避免忙等;
- 业务分发层使用函数指针/回调函数,快速将解析后的数据分发到对应业务模块,避免主线程阻塞。
5.6 可扩展优化:分层解耦,协议与硬件分离
嵌入式设备的硬件和协议可能迭代升级 (如更换通信模块、升级协议版本),若解析代码与硬件/协议紧耦合,会导致升级时修改量大、易引入bug。
优化策略:
- 遵循依赖倒置原则 ,面向接口编程,定义抽象的协议解析接口 和硬件驱动接口;
- 不同的协议(如Modbus-RTU、自定义协议)实现统一的解析接口,不同的硬件(如LoRa、4G)实现统一的驱动接口;
- 业务层仅依赖抽象接口,不依赖具体的协议/硬件实现,更换协议/硬件时仅需替换实现类,无需修改业务代码。
6. 协议解析常见问题与解决方案
协议解析在实际开发中会遇到粘包、丢包、帧错位、校验失败、缓冲区溢出 等问题,这些问题是通信的高频痛点 ,以下是7个最常见的问题,结合工业现场经验给出根本原因和可落地的解决方案:
| 常见问题 | 根本原因 | 解决方案 |
|---|---|---|
| 串口/网口粘包 | 字节流无边界,多个帧连续发送时解析端无法拆分 | 1. 设计规范的帧结构(帧头/帧尾/长度域);2. 发送端帧之间添加短延时(如1ms);3. 基于状态机实现帧的精准拆分 |
| 数据丢包 | 1. 接收缓冲区溢出;2. 中断阻塞导致数据未及时接收;3. 工业干扰导致信号丢失 | 1. 使用环形缓冲区缓存数据;2. 中断+DMA接收,减少CPU占用;3. 增加重传机制(如Modbus的超时重传);4. 优化硬件线路(屏蔽线、接地) |
| 帧错位 | 1. 错误帧未及时过滤;2. 缓冲区未清空;3. 长度域/帧头/帧尾错乱 | 1. 实现多重错误检测,错误帧立即清空缓冲区;2. 解析完成/帧错误后强制重置状态机和缓冲区;3. 帧头/帧尾选择非数据常用值,避免冲突 |
| CRC校验失败 | 1. 工业电磁干扰导致数据错乱;2. 校验算法实现错误;3. 校验范围错误 | 1. 优化硬件线路(屏蔽、接地、波特率匹配);2. 使用标准的CRC校验代码(如Modbus-RTU官方代码);3. 明确校验范围(帧头到数据域,排除校验位) |
| 缓冲区溢出 | 1. 缓冲区长度过小;2. 解析速度慢于接收速度;3. 无溢出保护 | 1. 合理设置缓冲区长度(建议为最大帧长的2-4倍);2. 优化解析逻辑,提升解析速度;3. 实现缓冲区溢出保护,溢出时丢弃旧数据/报警 |
| 字节序错误 | 1. 发送端与接收端字节序不一致(大端/小端);2. 多字节数据解析顺序错误 | 1. 协议中明确字节序(建议使用大端序 ,网络字节序);2. 多字节数据解析时统一转换为本地字节序(位运算/ntohs/ntohl) |
| 解析实时性不足 | 1. 解析逻辑臃肿,包含业务处理;2. 轮询频率过高/过低;3. CPU占用过高 | 1. 解析层与业务层解耦,解析层仅做数据提取;2. 合理设置轮询频率(建议1-10ms);3. 使用中断+DMA接收,减少CPU占用;4. 简化解析逻辑,避免耗时操作 |
7. 协议解析常见问题
7.1 基础题
-
问 :嵌入式通信中,为什么需要设计协议帧?串口传输的字节流有什么问题?
答 :串口传输的是无边界的字节流 ,解析端无法区分一帧数据的开始与结束,会导致粘包、丢包、帧错位;协议帧是将字节流封装为有固定格式的数据包,通过帧头/帧尾/长度域界定帧的边界,让解析端能精准拆分出完整的一帧数据,是解决字节流无边界的根本方法。 -
问 :协议帧的核心字段有哪些?各字段的作用是什么?
答 :核心字段为帧头、功能码、数据长度、数据域、校验域、帧尾(可裁剪);帧头标识帧开始,功能码标识业务类型,数据长度标识数据域字节数,数据域是实际业务数据,校验域验证帧的完整性,帧尾标识帧结束。 -
问 :常用的校验算法有哪些?各自的适用场景是什么?
答:三种核心算法:① 和校验/异或校验:代码极简、计算快,适合板内低干扰场景(I2C/SPI);② CRC8/CRC16:校验可靠性高,能检测出绝大多数数据错乱,适合工业现场高干扰场景(RS485/LoRa/Modbus)。 -
问 :什么是大端序和小端序?协议解析中如何处理字节序问题?
答 :大端序(网络字节序):高字节存低地址,低字节存高地址;小端序(本地字节序):高字节存高地址,低字节存低地址;协议中必须明确字节序 (建议大端序),多字节数据解析时,通过位运算或Linux库函数(ntohs/ntohl)将网络字节序转换为本地字节序。 -
问 :协议解析的三大核心原则是什么?为什么要遵循这些原则?
答:可靠性、轻量级、实时性;嵌入式系统资源受限(内存/算力)、实时性要求高、工业环境干扰大,轻量级保证适配资源受限,可靠性保证数据无错无丢,实时性保证满足工业控制的延时要求。
7.2 进阶题
-
问 :如何解决串口粘包问题?请给出具体的实现方案。
答 :核心方案是设计规范的帧结构,结合状态机实现帧的精准拆分,三种具体方案:① 定长帧:按固定长度截取数据;② 帧头帧尾型:查找帧头→帧尾的完整数据段;③ 长度域型:帧头+长度域界定帧范围;实际开发中优先选择长度域型(无需转义,解析高效),基于有限状态机实现,错误帧立即清空缓冲区。 -
问 :什么是环形缓冲区?协议解析中为什么要使用环形缓冲区?
答 :环形缓冲区是一种先进先出的循环缓冲区,静态内存实现,单读单写无锁;数据接收是异步的 (中断/DMA),解析是同步的,接收速度快于解析速度,环形缓冲区能缓存异步接收的原始字节流,解决"接收快、解析慢"导致的数据丢失问题,实现异步接收与同步解析的解耦。 -
问 :协议解析的标准架构是什么?为什么要采用这种架构?
答 :异步接收+同步解析+环形缓冲区缓存,分层架构(物理层驱动→环形缓冲区→帧检测层→帧解析层→业务分发层);原因:① 中断仅做数据接收,避免中断阻塞,保证实时性;② 分层解耦,修改某一层不影响其他层,提升代码可维护性;③ 业务层与通信层解耦,硬件/协议迭代时修改量最小。 -
问 :有限状态机(FSM)在协议解析中的作用是什么?请设计一个简单的帧头帧尾型解析状态机。
答 :状态机是协议解析的通用框架,将解析过程拆分为多个简单状态,每接收一个字节根据当前状态和字节值切换状态,能完美解决粘包、丢包、帧错位问题;帧头帧尾型状态机设计:0-空闲(找帧头)→1-找到帧头(接收数据)→2-找到帧尾(校验)→3-解析完成/帧错误(重置状态)。 -
问 :嵌入式中实现环形缓冲区时,如何避免缓冲区溢出和空读?如何实现单读单写无锁?
答 :① 溢出保护:写数据时判断next_head == tail,满则返回失败;空读保护:读数据时判断head == tail,空则返回失败;② 单读单写无锁:协议解析中,环形缓冲区的写操作在中断中执行 ,读操作在主线程中执行 ,单读单写场景下,使用原子操作(std::atomic)修饰读写指针,避免编译器重排,无需加锁。 -
问 :Modbus-RTU协议的帧结构是什么?如何实现Modbus-RTU的协议解析?
答 :Modbus-RTU帧结构:从站地址(1)+功能码(1)+数据域(n)+CRC16(2);解析实现:① 基于状态机实现,状态分为空闲、找从站地址、读功能码、读数据域、CRC校验;② 找到从站地址后,根据数据域长度截取完整帧;③ 使用标准CRC16-Modbus算法校验;④ 解析完成后根据功能码分发业务。
7.3 实战题
-
问 :在工业现场,你的Modbus-RTU协议解析经常出现CRC校验失败,请问可能的原因有哪些?如何排查和解决?
答 :排查步骤 :① 先排查硬件:用串口助手抓取原始数据,查看是否有数据错乱;检查RS485线路是否接反、是否使用屏蔽线、接地是否良好;波特率/校验位/停止位是否与从站一致;② 再排查软件:检查CRC校验算法是否为标准Modbus-RTU算法(多项式0x8005,初始值0xFFFF);检查校验范围是否正确(从站地址到数据域,排除CRC位);检查数据接收是否有丢包/粘包;
解决方法:① 硬件:更换屏蔽线、做好接地、匹配波特率、检查线路接线;② 软件:使用标准CRC16代码、修正校验范围、优化状态机,错误帧立即清空缓冲区。 -
问 :协议解析中,缓冲区溢出导致数据丢失,请问如何优化?
答 :从缓冲区设计、解析速度、接收速度三个方面优化:① 缓冲区设计:合理设置缓冲区长度(为最大帧长的2-4倍),实现溢出保护(溢出时报警/丢弃旧数据),缓冲区长度设为2的幂次提升访问效率;② 解析速度:优化解析逻辑,简化状态机,解析层与业务层解耦,提升解析效率;③ 接收速度:使用中断+DMA接收,减少CPU占用,避免因CPU繁忙导致解析不及时。 -
问 :嵌入式设备长期运行后,出现协议解析异常,重启后恢复,请问可能的原因有哪些?如何解决?
答 :核心原因 :内存碎片、内存泄漏、缓冲区未清空、状态机死锁;
排查与解决:① 内存:拒绝动态内存分配(new/malloc),所有缓冲区使用静态数组,避免内存碎片和泄漏;② 缓冲区/状态机:解析完成/帧错误/超时后,强制重置状态机和清空缓冲区,避免残留数据导致帧错位;③ 硬件:检查是否有电磁干扰导致的硬件寄存器错乱,添加硬件看门狗,异常时自动重启;④ 代码:添加异常处理,所有错误分支均有重置逻辑。 -
问 :嵌入式Linux下,如何实现串口的中断+DMA接收?与轮询接收相比,有什么优势?
答 :实现步骤 :① 设备树中配置串口的DMA通道(如UART1的RX DMA);② 驱动层中初始化DMA,设置DMA接收缓冲区(环形缓冲区);③ 配置串口接收中断,DMA接收完成后触发中断,通知CPU处理;④ 中断中仅做简单的标志位设置,主线程中读取DMA缓冲区数据并写入环形缓冲区;
优势:DMA接收无需CPU参与,直接将硬件数据写入内存,仅在接收完成后触发一次中断,CPU占用率大幅降低(从50%+降至5%以下),避免轮询接收导致的CPU繁忙,提升系统实时性,适合高速通信场景。 -
问 :协议解析中,如何兼顾可扩展性 和资源受限 的要求?
答:① 分层解耦:遵循依赖倒置原则,定义抽象的协议解析接口和硬件驱动接口,不同协议/硬件实现统一接口,业务层仅依赖抽象接口,扩展时仅需新增实现类;② 轻量级实现:所有代码均为轻量级,静态内存分配,避免复杂库和冗余逻辑;③ 模块化设计:将协议解析封装为独立的模块,模块间低耦合,扩展时不影响原有模块;④ 配置化:将帧结构、波特率、校验算法等配置写入配置文件,无需修改代码即可适配不同协议/硬件。 -
问 :在资源极度受限的嵌入式系统(如128KB RAM,4KB Flash)中,如何实现轻量级的协议解析?
答 :核心是极致轻量化,做减法设计:① 帧结构:优先选择定长帧解析,代码极简、内存占用最低;② 校验算法:使用和校验/异或校验,替代CRC16,减少代码量和计算量;③ 缓冲区:使用极小的静态缓冲区(如64字节),环形缓冲区简化实现;④ 解析逻辑:使用极简的状态机(不超过3个状态),无任何冗余逻辑;⑤ 代码:使用C语言(而非C++),避免STL,代码裸机实现,无操作系统开销。
8. 总结
协议解析是嵌入式通信的核心环节 ,其设计与实现并非单纯的代码编写,而是贴合硬件特性、兼顾资源受限与实时性、解决工业现场实际问题的工程化实践,核心总结如下:
- 帧结构是基础 :无论何种解析方法,都需设计规范的协议帧,优先选择定长帧 (简单场景)、长度域型不定长帧 (工业场景),帧头/帧尾型需做好字节转义,所有帧结构必须包含校验域(工业场景优先CRC16)。
- 状态机是通用框架 :定长帧、帧头帧尾型、长度域型均可基于有限状态机(FSM) 实现,状态机能完美解决粘包、丢包、帧错位等问题,状态机设计需简洁(不超过8个状态),每个状态仅处理单一逻辑。
- 异步接收+同步解析是标准架构 :通过环形缓冲区 实现异步接收与同步解析的解耦,中断仅做数据接收和缓冲区写入,解析逻辑在主线程执行,避免中断阻塞,保证实时性,环形缓冲区需实现静态内存、单读单写无锁、溢出保护。
- 分层解耦是工程化关键 :采用物理层→环形缓冲区→帧检测层→帧解析层→业务分发层的分层架构,层与层之间解耦,修改某一层不影响其他层,硬件/协议迭代时修改量最小,符合 "高内聚、低耦合" 的工程化要求。