聪明的你是不是早就猜到了这一篇,小望所归下consumeQueue她来啦!
ConsumeQueue
这是咱们消息消费队列 ,消息到了咱们commitlog将被异步转发到consumequeue,来方便消费;毕竟生产了消息不被消费,那纯是海底捞月---------白费劲;大家会不会好奇呀,这个队列是什么队列,这个Queue呀是某opic的一个queue
通过queue名字,大家的第六感应该能想到这里面应该有一个异步,咱们rocketmq为了提高消息存储性能,设计了ReputMessageService异步将consumequeue对象构建出来,让FlushConsumeQueueService将consumequeu数据异步写入磁盘;大神的源码两个异步设计大概能想出来这个性能是多高了,当然涉及到异步过程也会复杂一些。
大致看一下源码更好理解一些:
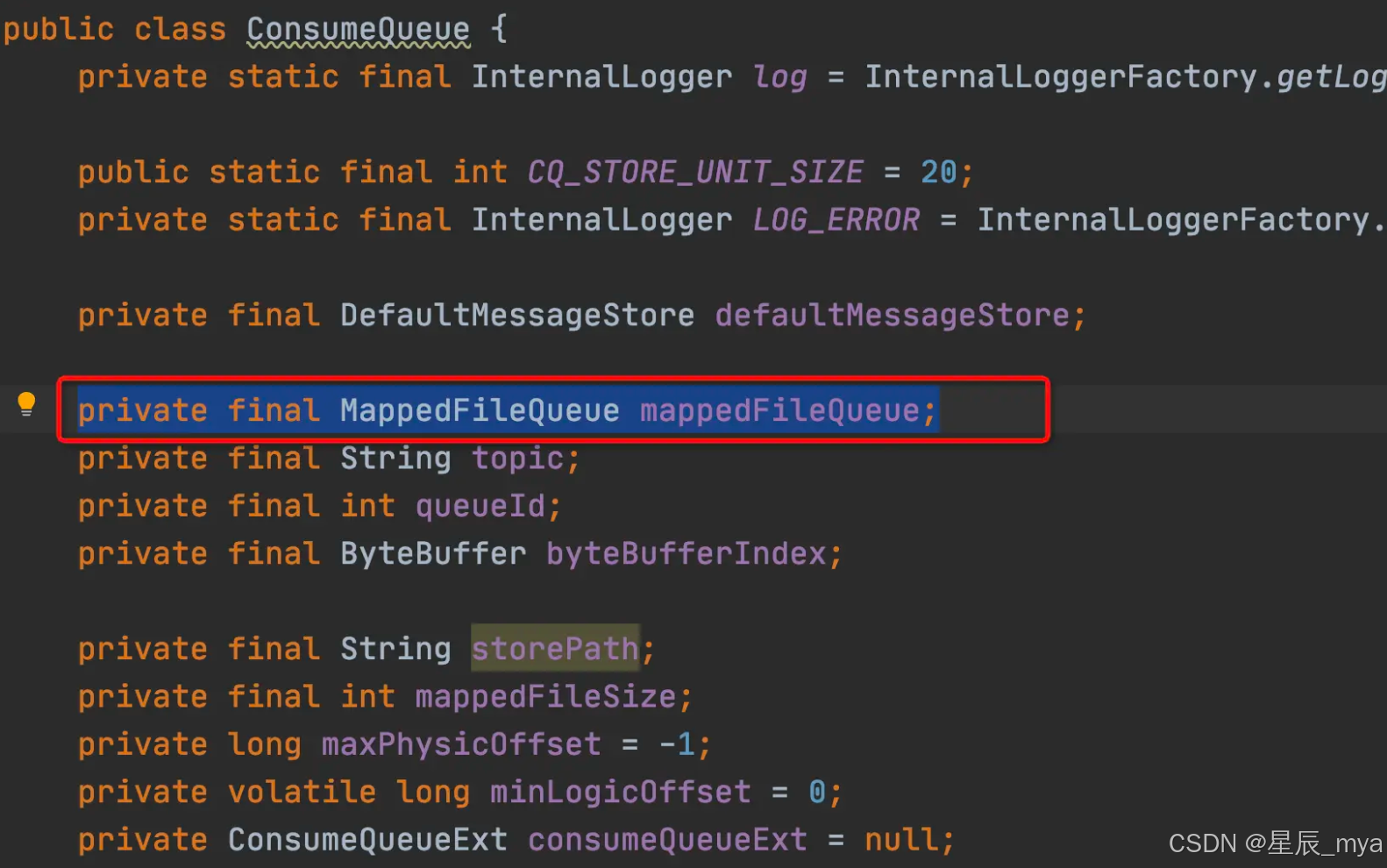
首先咱们看到了MappedFileQueue,不难猜到读写consumequeue是借助MappedFile,自然也是要借助buffer了,这都写到明面上了,再说都一个团队写的,没必要整其他的多余的 显得生分不和了
当然咱们上面commitlog已经将信息给了buffer在刷到磁盘,所以consumequeue没必要再存一份占用资源,所以consumequeue存储了
1、offset:8字节,路由到queue中的消息在所指定的commitlog中的偏移量(绝对位置);
2、消息大小,4字节,1是头 2是尾巴,这样定位到完整的消息;
3、tagCode:8字节,消息tag的hash(MurmurHash2 算法,做一个标记方便订阅的时候好定位、过滤,毕竟订阅了再在大海中捞针那可不地道)
┌───────────────────────────────────────────────────────────────────┐
│ ConsumeQueue 文件(QueueId=0,文件名=000000) │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ 索引项1(20字节) │ │
│ │ ┌──────────┬──────────┬──────────┐ │ │
│ │ │物理偏移量│ 消息长度 │ 标签哈希 │ │ │
│ │ │ 8字节 │ 4字节 │ 8字节 │ │ │
│ │ └──────────┴──────────┴──────────┘ │ │
│ ├─────────────────────────────────────────────────────────────┤ │
│ │ 索引项2(20字节) │ │
│ │ ┌──────────┬──────────┬──────────┐ │ │
│ │ │物理偏移量│ 消息长度 │ 标签哈希 │ │ │
│ │ │ 8字节 │ 4字节 │ 8字节 │ │ │
│ │ └──────────┴──────────┴──────────┘ │ │
│ ├─────────────────────────────────────────────────────────────┤ │
│ │ 索引项3(20字节) ...... 索引项N │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ └─────────────────────────────────────────────────────────────────┘可以看出这个文件里面干货满满!消费点很密,为了更多的消息,文件里面都没有分隔符,就应了那就"约定大于配置"大家都是20字节,到节了就让位!
通过上面结构的介绍,聪明当你应该也能看到咱们consumeQueue的设计目的:为了将不同topic的消息分离,按需要去拉取!
再看咱们queue文件的目录结构:
$HOME/store/consumequeue/{Topic}/{QueueId}/{FileName}
-
queueid逻辑队列id(0开始)
-
fileName表示文件开始的偏移量,也就是20位补0命令
┌───────────────────────────────────────────────────────────────────┐
│ store/consumequeue/ 根目录 │
│ ├─────────────────── TopicA/ (按 Topic 分目录) │
│ │ ├────────────── 0/ (QueueId=0,读写队列分离可配置) │
│ │ │ ├─ 000000 (文件1:逻辑偏移量0开始,固定≈600MB)◄───┐ │
│ │ │ │ ┌─────────────────────────────────────────────┐ │ │
│ │ │ │ │ 索引项1(20字节) │ 索引项2(20字节) │ ... │ │ │
│ │ │ │ │ [物理偏移量] │ [物理偏移量] │ │ │ │
│ │ │ │ │ [消息长度] │ [消息长度] │ │ │ │
│ │ │ │ │ [Tag哈希] │ [Tag哈希] │ │ │ │
│ │ │ │ └─────────────────────────────────────────────┘ │ │
│ │ │ ├─ 000001 (文件2:文件1写满后新建)◄───────────────┘ │
│ │ │ │ ┌─────────────────────────────────────────────┐ │
│ │ │ │ │ 索引项N │ 索引项N+1 │ ... │ 空闲空间 │ │
│ │ │ │ └─────────────────────────────────────────────┘ │
│ │ │ └─ ...... (后续文件按逻辑偏移量命名) │
│ │ ├────────────── 1/ (QueueId=1,独立索引文件) │
│ │ └────────────── N/ (QueueId=N,队列数决定并发消费能力) │
│ └─────────────────── 其他 Topic/ (同理) │
└───────────────────────────────────────────────────────────────────┘
咱们rockermq把偏移量作为文件名这个巧妙,一目了然起到了多个作用,之前commitlog的命名也是这样的逻辑,咱们忘记写了好像,在这里补一下
一个文件默认5.72M,大概有30W条记录;30w也不多再说水满则溢 :恰到好处才是最舒服、快捷的,像money这种,如果拥有的太多,人的嘴角就会控制不住的上扬。
说回到我们的主角consumequeue,根据上面的情况,大家也可能了解了,简单来说咱们可以把她当成索引文件,因为她"别有用心"的设计咱们可以找到主题下的消息,这样消费者来了能够在consumequeue快速找到topic对应log文件偏移量,进而快速定位到消息
consumequeue类似(密集型)索引的设计,很小巧就可以将它读到内存中(小巧的一米八五壮汉),这样消费是不是更快了,这速度如果是真消费,那钱包可要锁好了;当然为了防止数据丢失,consumequeue也会持久化到磁盘,不过本身不大,这持久化不是什么事
调优
1、文件大小调优秀
咱们上面说了默认大小,默认配置是mappedFileSizeConsumeQueue=30W * 20B = 600MB大概30w记录,建议增大到1G(大概可以存50w条记录)这样在文件里面能直接找到更多的数据,不需要切换、IO,当然这要考虑到硬件的感受,一般来说都用到mq了,问题应该不大
2、批量更新
根据上面咱们知道queue的记录固定20字节,批量写就可以减少磁盘io,这用脚趾头都能想出来对吧各位道友;具体呢那当然是在关键地方:写的时候下刀子做手术
- 可以批量发送消息batchSize给他加大
- 异步刷盘,这异步受限制肯定是少些,也不影响主线,这就很懂事,具体配置是flushDiskType=async_flush,flushIntervalCommitLog=2ms提高吞吐(推荐操作 不一定)
3、消息设计要优美
在现在以瘦为美,咱们消息也不能太胖,减少body消息体大小,可以考虑上狠活:压缩gzip/snappy
在那三个里面还有个tagCode可以嚯嚯,合理设计消息tga,起到真正的过滤作用,避免冲突,像数据表你把type列当索引,就2值还拿来当索引,那二叉树得长成什么鬼样子!所以咱们tag要争气,具有"辨识度"好不好!
4、配置参数
broker线程池大小要调整,适当增加线程数SendMessageThreadPool
增加jvm堆内存,对吧,本身以来jdk别不舍得给划拉一亩三分地,万一GC大家谁面子都挂不住
5、客户端
消费者你来消费,首先要有一个良好的态度和方法,你要使用异步拉取模式,这样你也不要写同步死死滴在那嘎达等着,减少阻塞,省的自己闹心
毕竟一个消息也不大,能一回给他们拉过来就批量全拉来,别客气,pullBatchSize