以下回答采用了**"场景+原理+方案+兜底"**的结构,这是面试官最喜欢的回答逻辑。
一、 核心架构与选型篇
1. 为什么 Kafka 比 RabbitMQ 吞吐量高那么多? (底层原理深挖)
面试官潜台词: 你懂不懂操作系统的零拷贝、顺序写和Page Cache?
深度回答:
Kafka 能够达到百万级 TPS,主要依赖于操作系统底层的几个核心优化:
顺序写磁盘 (Sequential Write):
Kafka 强制将消息追加到日志文件末尾(Append Only)。机械硬盘的顺序写速度(约 600MB/s)远高于随机写(约 100KB/s),甚至可以媲美内存随机写。这避免了磁盘磁头的频繁寻道。
零拷贝 (Zero Copy):
传统读写:磁盘 -> 内核Buffer -> 用户Buffer -> Socket Buffer -> 网卡。数据拷贝 4 次,上下文切换 4 次。
Kafka (sendfile):利用 Linux sendfile 系统调用,直接从 Page Cache 拷贝到 Socket Buffer(或者网卡支持 SG-DMA 时直接到网卡)。数据拷贝减少到 2 次或 0 次 CPU 拷贝,上下文切换减少到 2 次。
Page Cache(页缓存):
Kafka 大量利用操作系统的 Page Cache,而不是 JVM 堆内存。这避免了 JVM GC 带来的停顿(STW),且重启服务后缓存依然存在。
批量发送与压缩:
Producer 不是一条条发,而是攒一批(Batch)再发,并且支持 GZIP/Snappy 压缩,极大地减少了网络 I/O 开销。
2. 消息队列的 Push(推)模式和 Pull(拉)模式有什么区别?RocketMQ/Kafka 选了哪种?
面试官潜台词: 你懂不懂流控和长轮询?
深度回答:
Push 模式(如 ActiveMQ, RabbitMQ):
优点:实时性极高,Broker 收到消息立马推给消费者。
缺点:容易造成消费者被压垮。如果生产速度远超消费速度,消费者缓冲区爆满,导致 OOM 或宕机。
Pull 模式(如 Kafka):
优点:消费者掌握主动权,根据自己的处理能力(Capacity)来拉取数据,天然的"背压"机制。
缺点:如果 Broker 没有消息,消费者会频繁空轮询,浪费 CPU 和网络资源。
RocketMQ/Kafka 的优化(长轮询 Long Polling):
它们本质是 Pull 模式,但结合了 Push 的实时性。
机制:Consumer 发起拉取请求,如果 Broker 有数据,立马返回;如果没数据,Broker Hold 住请求(例如 5秒),一旦有新消息到达或超时,再返回结果。这既解决了空轮询浪费,又保证了毫秒级的实时性。
二、 高可靠与一致性篇(重难点)
3. 如何保证消息绝对不丢失?(全链路分析)
面试官潜台词: 别只说持久化,我要听 Producer、Broker、Consumer 三个阶段的配合。
深度回答:
要保证 100% 不丢失,必须牺牲性能,从三个阶段入手:
生产阶段(Producer):
ACK 机制:发送消息时,必须等待 Broker 的确认。
Kafka:设置 acks=all(或 -1),表示 Leader 和所有 ISR(同步副本)都写入成功才算发送成功。
RocketMQ:使用同步发送模式,并检查 SendResult 为 SEND_OK。
失败重试:设置重试次数,如果报错则自动重发。
存储阶段(Broker):
刷盘策略:
同步刷盘 (Sync Flush):消息写入内存后,强制调用 fsync 落盘才返回 ACK。这是最安全的,但 TPS 会掉到几千。
异步刷盘 (Async Flush):通常生产环境为了性能选这个,但有断电丢数据风险。配合多副本机制来容错。
多副本/集群:
Kafka:min.insync.replicas > 1,确保至少 2 个副本写入成功。
RocketMQ:主从架构,开启同步双写(Sync Master),主节点写完同步给从节点才返回成功。
消费阶段(Consumer):
手动 ACK (Manual Commit):绝对禁止自动提交 offset。
逻辑:先执行业务逻辑(写库、计算),成功后再调用 ACK/Commit。
坑:如果业务成功但 ACK 失败,会导致消息重复消费,所以业务必须做幂等性。
4. 分布式事务:如何实现最终一致性?(RocketMQ 事务消息原理)
面试官潜台词: 微服务之间怎么做数据一致性?比如下单扣库存。
深度回答:
基于 RocketMQ 的事务消息(2PC 的变种)是标准解法:
发送半消息 (Half Message):
A 系统(生产者)先发一条"半消息"给 Broker。Broker 收到后持久化,但对消费者不可见(消费者拉不到)。
执行本地事务:
A 系统收到 Broker 确认后,执行本地数据库操作(如扣款)。
提交/回滚 (Commit/Rollback):
如果本地事务成功,A 系统向 Broker 发送 Commit,Broker 将消息标记为可见,B 系统(消费者)就能收到了。
如果本地事务失败,A 系统发送 Rollback,Broker 删除该消息。
核心兜底:回查机制 (Check Back):
问题:如果 A 系统执行完本地事务,挂了,没来得及发 Commit 怎么办?
解决:Broker 发现某条半消息长时间(如 1 分钟)未提交,会主动询问 A 系统:"这单到底成功没?" A 系统检查本地数据库,根据结果重新提交 Commit 或 Rollback。
三、 生产事故与疑难杂症篇
5. 线上消息积压了几百万条,如何快速处理?
面试官潜台词: 这是一个非常经典的生产事故题,考察应急能力。
深度回答:
不能单纯加机器,因为 Kafka/RocketMQ 的消费并行度取决于分区(Partition/Queue)的数量。如果分区只有 10 个,你加 100 个消费者也没用,90 个会闲着。
紧急处理方案(三步走):
方案一:理论方案
修复消费者:先排查 Consumer 为什么慢(是死锁了?还是数据库慢?),修复 Bug。
临时扩容(核心步骤):
现有消费者逻辑修改:不处理业务,只负责拿消息,然后快速转发到一个**新的、拥有 10 倍分区数(Topic)**的临时队列中。
部署一套临时的 Consumer 集群(比如 100 个节点),专门消费这个临时 Topic,执行真正的业务逻辑。
恢复:积压数据消费完后,切回原架构。
- 消息队列如何保证顺序性?(全局顺序 vs 分区顺序)
方案二、实际解决方案
"临时建立新Topic + 转发消息" 这个方案,虽然是很多教科书和博客里的"标准答案",但在真实的线上 P0 级故障处理中,往往远水解不了近渴。
为什么说它牵强?
开发成本高:半夜三更还得写代码、改配置、发布新服务,风险极大。
资源调度慢:去哪瞬间找几十台机器来部署临时消费者?
架构限制:如果瓶颈在下游数据库(比如 MySQL 已经被打挂了),你转发得再快,最后写入还是死。
结合实际生产经验,处理百万级消息积压,通常是按以下 "止血 -> 降级 -> 优化 -> 扩容" 的顺序来操作的:
第一步:排查瓶颈(止血)
不要盲目扩容,先看下游死没死。
大多数积压不是因为消费者太少,而是因为消费者依赖的下游资源(DB、Redis、第三方接口)慢了或挂了。
场景 A:下游数据库被打挂(CPU 100% 或锁死)。
动作:这时候你加消费者没用,只会加速数据库死亡。必须暂停消费,先救数据库。
场景 B:第三方接口超时(例如发短信、调外部支付)。
动作:第三方挂了,你重试也没用。直接熔断该逻辑。
第二步:业务降级(最快手段)
这是实战中最有效、最常用的手段。
如果是逻辑太重导致消费慢,能不能先扔掉非核心逻辑?
开关降级:
代码里通常会有配置中心(如 Nacos/Apollo)的开关。
比如:原本逻辑是 写库 + 发短信 + 积分 + 统计。
操作:打开降级开关,变成 只写库。短信、积分、统计全部跳过(或者只打个简日志,回头再补)。
效果:单条消息处理耗时从 200ms 降到 10ms,消费速度提升 20 倍,积压迅速消化。
第三步:参数调优(低成本提速)
如果不涉及代码变更,通过调整配置能否提速?
增加批量大小(Batch Size):
原理:原本一次数据库插入一条,改成积攒 100 条消息,一次 Batch Insert。
效果:数据库 TPS 压力骤减,消费速度起飞。
增加并发线程数:
原理:很多消费者默认是单线程或小线程池。如果 CPU 和内存还有富余,直接调大消费线程数(concurrency)。
注意:前提是下游数据库扛得住。
第四步:扩容(K8s 时代的操作)
如果下游没问题,纯粹是计算量大导致消费不过来,且Topic 的分区(Partition)数足够多。
操作:
直接在 K8s 上修改 Deployment 的副本数(Replicas),从 10 个扩到 50 个。
前提:Kafka 的 Partition 数量必须 >= 消费者数量。如果 Partition 只有 10 个,你扩容到 50 个消费者,有 40 个是空闲的(这就回到了那个"教科书方案"存在的意义:为了突破 Partition 限制)。
第五步:暴力丢弃(死马当活马医)
如果积压的消息是非核心数据(如日志、监控埋点、即时性要求极高的通知),且积压导致磁盘快满了,影响了新消息的写入。
操作:
直接重置 Offset(位点),跳过积压的消息,直接消费最新的。
或者写一个脚本,快速消费但不处理(只打印日志),先把队列清空,保住服务可用性。
6. 消息队列如何保证顺序性?(全局顺序 vs 分区顺序)
面试官潜台词: 分布式系统里,顺序和性能是互斥的,看你如何取舍。
深度回答:
全局顺序:
方案:Topic 只能设 1 个 Partition(队列),Consumer 也只能有 1 个。
后果:系统退化成单线程,吞吐量极低,完全失去了 MQ 的高并发优势。生产环境几乎不用。
局部顺序(分区顺序):
方案:在发送消息时,利用路由键(Routing Key / Sharding Key)。
例子:电商订单。我们将 OrderId 取模(OrderId % PartitionCount),保证同一个订单号的所有状态变更消息(下单、支付、发货)都进入同一个 Partition。
消费端:一个 Partition 只能被一个 Consumer 线程消费,从而保证了该订单内部的顺序。
消费端多线程的坑:
如果 Consumer 内部开启多线程处理(为了加速),顺序又乱了。
解决:在 Consumer 内存中维护多个内存队列,根据 OrderId Hash 到不同的内存队列,每个内存队列由一个线程处理。
- 消息重复消费了怎么办?(幂等性设计)
面试官潜台词: MQ 只能保证"至少一次(At Least Once)",不能保证"恰好一次",业务层必须兜底。
深度回答:
重复消费是不可避免的(网络抖动导致 ACK 丢失)。解决方案不在 MQ,而在业务层:
数据库唯一索引(最强硬):
比如插入流水表,将 MessageID 或 BizID 设为唯一索引。重复插入会报 DuplicateKeyException,捕获忽略即可。
Redis 分布式锁/Set:
处理前先查 Redis SetNX(MsgID),成功则执行,失败则说明处理过。
注意:Redis 数据可能丢失,不如数据库稳。
状态机 CAS:
更新订单状态时带上前置条件:UPDATE order SET status = 'PAID' WHERE id = 100 AND status = 'UNPAID'。如果已经被消费过变成了 PAID,这条 SQL 影响行数为 0,自然保证了幂等。
三款主流 MQ(RabbitMQ、Kafka、RocketMQ)诞生的背景完全不同,导致它们的设计侧重点天差地别。
我用拟人化和场景化的方式帮你重新梳理一遍,保证你读完脑子里有个清晰的画面。
- RabbitMQ:严谨的"英国管家"
出身:电信行业,基于 AMQP(高级消息队列协议)标准开发,用 Erlang 语言写的(Erlang 专为高并发交换机设计)。
性格:优雅、严谨、灵活,但干不了重活。
核心记忆点:路由(Routing) 和 低延迟。
它的特长(怎么记):
想象一个高级管家,手里拿着一封信(消息)。
Exchange(交换机):他非常聪明,能根据信封上的各种规则(Routing Key),把信精准地分发给不同的少爷(队列)。比如"只要是红色的信给大少爷,蓝色的给二少爷,带星号的给所有人"。这是 RabbitMQ 最强的地方,路由规则极其强大。
极低延迟:反应非常快,微秒级响应。
它的短板:
吞吐量低:因为处理得太精细,每秒只能处理几万条。
消息堆积能力差:管家手里拿不了太多信,如果信太多(消息积压),他的处理速度会直线下降,甚至崩溃。
适用场景:
中小规模系统。
需要复杂路由逻辑(比如根据不同日志级别发给不同服务)。
对实时性要求极高(如实时控制指令)。
- Kafka:狂暴的"运煤卡车"
出身:LinkedIn,为了处理海量的用户行为日志(Log)而生。
性格:粗犷、吞吐量极大、不拘小节。
核心记忆点:吞吐量 和 流处理。
它的特长(怎么记):
想象一辆巨大的运煤卡车(或者传送带)。
Batch(批量):它不在乎每一块煤(消息)长什么样,它是一铲子一铲子(批量)装车的。
顺序读写 + 零拷贝:它直接在高速公路上狂奔,不走弯路(利用磁盘顺序写和 OS 零拷贝),速度快到起飞。
Partition(分区):如果一辆车不够,就搞 100 辆车(分区)并行跑。
它的短板:
时效性稍差:因为要凑够一铲子才发车(批量发送),所以会有毫秒级的延迟。
功能简单:不支持复杂的路由,不支持重试,不支持死信队列(原生),就是单纯的"传输管道"。
适用场景:
大数据领域。
日志收集(ELK)。
用户行为追踪。
流式计算(结合 Flink/Spark)。
- RocketMQ:全能的"电商特种兵"
出身:阿里巴巴,为了抗住"双11"这种变态流量而生。
性格:可靠、全能、抗揍。
核心记忆点:业务功能 和 稳定性。
它的特长(怎么记):
想象一个在双11指挥作战的物流指挥官。
削峰填谷:面对双11的洪峰,它能抗住极高的并发(十万级 TPS),而且堆积了几亿条消息性能也不会下降(这是它比 RabbitMQ 强的地方)。
业务功能丰富:它懂业务,支持事务消息(保证付钱和发货一致)、延时消息(下单30分钟不支付自动取消)、消息回溯(刚才发错了,重新发一遍)。
Java 生态:它是 Java 写的,国内大厂(阿里系)都在用,出了问题方便看源码改 Bug。
它的短板:
中庸:吞吐量比 Kafka 略低一点(但也足够高了),路由比 RabbitMQ 弱一点(只支持简单的 Tag 过滤)。
生态:出了中国圈子,国际上流行度不如 Kafka 和 RabbitMQ。
适用场景:
核心业务链路(订单、交易、支付)。
金融级应用(对数据可靠性要求极高)。
中国互联网公司的首选。
-
一张表总结(面试背这个)
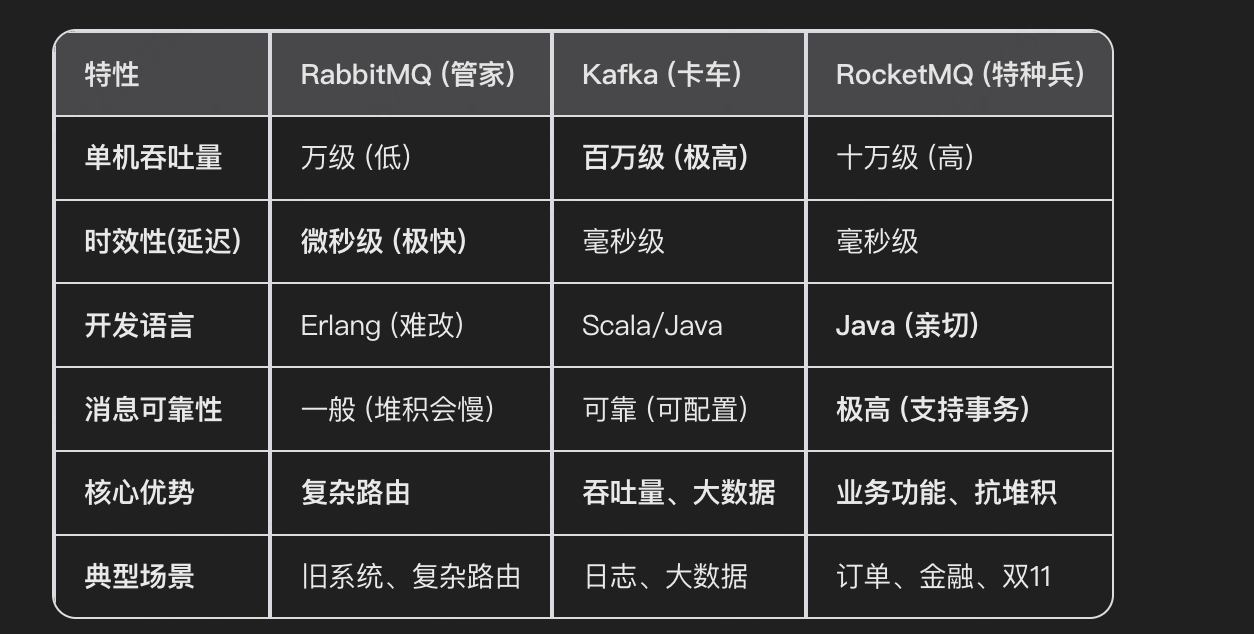
-
怎么选?(一句话决策)
要处理日志、大数据、监控数据? -> 闭眼选 Kafka。
是核心交易业务(订单、支付),且团队是 Java 技术栈? -> 首选 RocketMQ。
系统规模不大,但逻辑复杂,需要灵活的消息分发? -> 选 RabbitMQ。