目录
[1 HTTP](#1 HTTP)
[1.1.1 报文流动](#1.1.1 报文流动)
[1.1.2 报文的组成部分](#1.1.2 报文的组成部分)
[1.1.3 HTTP请求](#1.1.3 HTTP请求)
[1.1.4 HTTP响应](#1.1.4 HTTP响应)
[1.1.5 HTTP请求方法](#1.1.5 HTTP请求方法)
[1.1.6 状态码](#1.1.6 状态码)
[1.2 连接管理](#1.2 连接管理)
[1.2.1 TCP连接](#1.2.1 TCP连接)
[1.2.1.1 三步握手](#1.2.1.1 三步握手)
[1.2.1.2 TCP协议缺陷](#1.2.1.2 TCP协议缺陷)
[1.2.1.3 四次挥手](#1.2.1.3 四次挥手)
[1.2.2 TCP数据传输](#1.2.2 TCP数据传输)
[1.2.2.1 传输原理](#1.2.2.1 传输原理)
[1.2.2.2 滑动窗口协议](#1.2.2.2 滑动窗口协议)
[1.2.3 TCP性能](#1.2.3 TCP性能)
[1.2.4 串行事务处理](#1.2.4 串行事务处理)
[1.2.4 并行连接](#1.2.4 并行连接)
[1.2.5 持久连接](#1.2.5 持久连接)
[1.2.6 管道化连接](#1.2.6 管道化连接)
[1.3 发展历程](#1.3 发展历程)
[1.4 HTTP2新特性](#1.4 HTTP2新特性)
[1.4.1 二进制分帧(frame)](#1.4.1 二进制分帧(frame))
[1.4.2 头部压缩(HPACK)](#1.4.2 头部压缩(HPACK))
[1.4.3 多路复用(Multiplexing)](#1.4.3 多路复用(Multiplexing))
[1.4.4 服务器推送(Server Push)](#1.4.4 服务器推送(Server Push))
[1.4.5 http2.0性能瓶颈](#1.4.5 http2.0性能瓶颈)
[1.4.6 安全风险](#1.4.6 安全风险)
[2 HTTPS](#2 HTTPS)
[2.1 概念](#2.1 概念)
[2.2 架构图](#2.2 架构图)
[2.3 HTTPS工作原理](#2.3 HTTPS工作原理)
[2.3.1 对称加密算法](#2.3.1 对称加密算法)
[2.3.2 非对称加密算法](#2.3.2 非对称加密算法)
[2.3.3 数字签名](#2.3.3 数字签名)
[2.3.4 证书](#2.3.4 证书)
[2.3.5 完整的 HTTPS 的通信](#2.3.5 完整的 HTTPS 的通信)
[2.4 CA证书制作实战](#2.4 CA证书制作实战)
[2.4.1 OpenSSL](#2.4.1 OpenSSL)
[2.4.2 过程](#2.4.2 过程)
[2.4.3 颁发证书](#2.4.3 颁发证书)
[2.4.4 使用 SSL证书](#2.4.4 使用 SSL证书)
1 HTTP
1.1HTTP报文
HTTP 报文是在 HTTP 应用程序之间发送的数据块( 用于 HTTP 协议交互的信
息)。请求端(客户端)的 HTTP 报文叫做请求报文,响应端(服务器端)的
叫做响应报文。
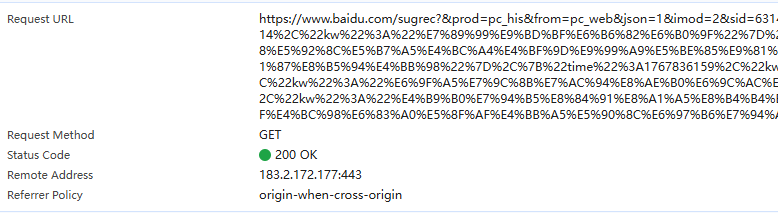 Remote Address:访问目标URL解析出来的IP地址,443:表示当前https协议。
Remote Address:访问目标URL解析出来的IP地址,443:表示当前https协议。
Referrer Policy : Referrer用户指明当前请求的来源页面,对于同源的请求,会发送完整的url作为引用地址,防盗链。
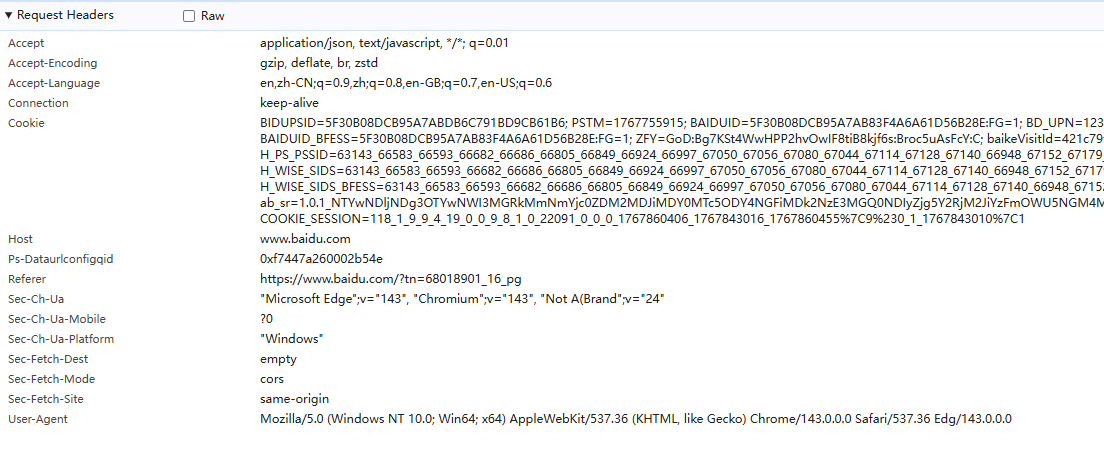
accept:请求可以支持的响应格式列表信息
accept-encoding:告知服务器本地浏览器支持是压缩方式
sec-fetch-dest:期望获得什么类型的资源
sec-fetch-mode :cors,表示浏览器在发起跨域请求
sec-fetch-site:表示一个请求发起的来源和目标资源来源之间的关系,
crosssite:跨域请求,same-origin:同源请求。
user-agent:描述浏览器的信息
1.1.1 报文流动
HTTP 使用术语流入(inbound) 和流出(outbound) 来描述事务处理(transaction)的方向。报文流入源端服务器, 工作完成之后, 会流回用户的 Agent 代理中
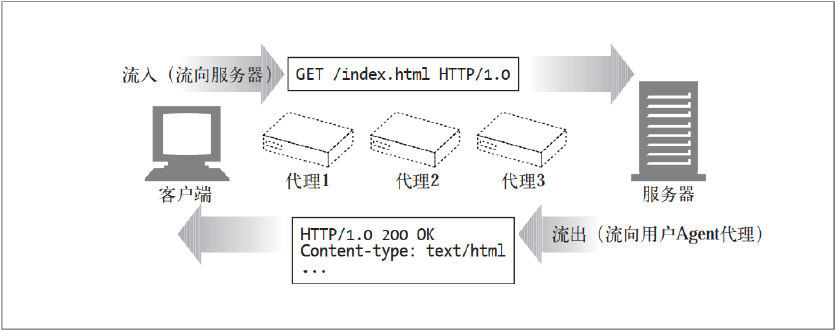
报文流入源端服务器并流回到客户端
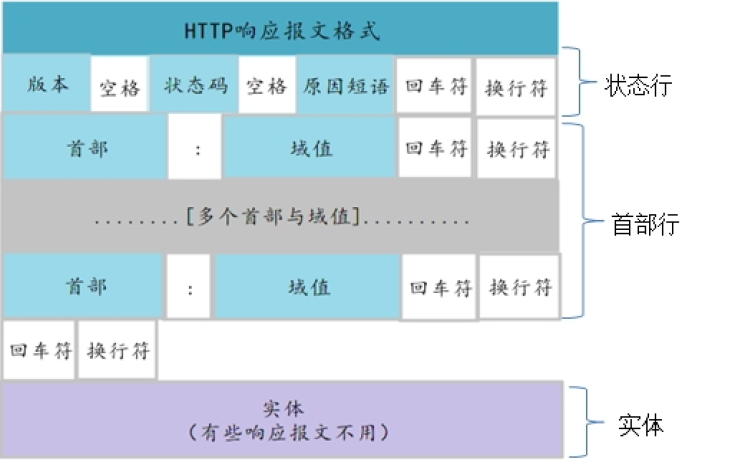
1.1.2 报文的组成部分
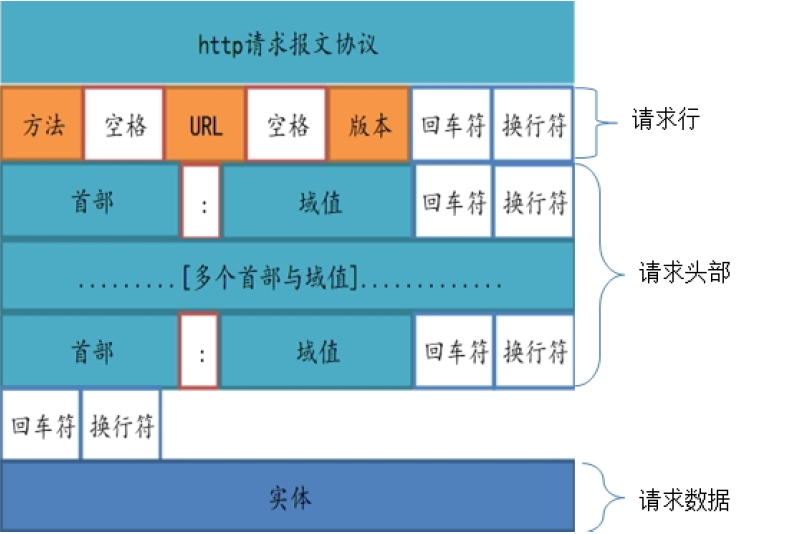
HTTP 报文是简单的格式化数据块。 每条报文都包含一条来自客户端的请求,或者一条来自服务器的响应。 它们由三个部分组成:
-
对报文进行描述的起始行(start line)
-
包含属性的首部(header)块
-
以及可选的包含数据的主体(body) 部分

(1)所有的 HTTP 报文都可以分为两类: 请求报文(request message) 和响应报文(response message)。 请求报文会向 Web 服务器请求一个动作。响应报文会将请求的结果返回给客户端。 请求和响应报文的基本报文结构相同。

请求报文的格式:
响应报文的格式
(4)HTTP消息由采用ASCII编码的多行文本构成。在HTTP/1.1及早期版本中,这些消息通过连接公开地发送。在HTTP/2中,为了优化和性能方面的改进,曾经可人工阅读的消息被分到多个HTTP帧中。
Web 开发人员或网站管理员,很少自己手工创建这些原始的HTTP消息︰ 由软件、浏览器、 代理或服务器完成。他们通过配置文件(用于代理服务器或服务器),API (用于浏览器)或其他接口提供HTTP消息。

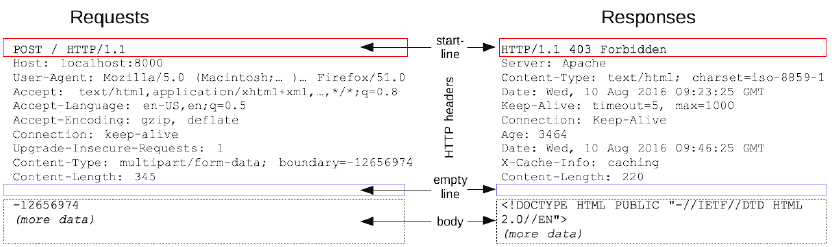
(5)HTTP 请求和响应具有相似的结构,由以下部分组成︰
- 一行起始行用于描述要执行的请求,或者是对应的状态,成功或失败,这个起始行总是
单行的。
-
一个可选的HTTP头集合指明请求或描述消息正文。
-
一个空行指示所有关于请求的元数据已经发送完毕。
-
一个可选的包含请求相关数据的正文 (比如HTML表单内容),或者响应相关的文档。
正文的大小有起始行的HTTP头来指定。
起始行和 HTTP 消息中的HTTP 头统称为请求头,而其有效负载被称为消息正文。
1.1.3 HTTP请求
(1)起始行
HTTP请求是由客户端发出的消息,用来使服务器执行动作。起始行 (start-line)
包含三个元素:
-
一个 HTTP 方法,一个动词 ([ GET , PUT 或者 POST ) 或者一个名词 (像HEAD或者OPTIONS ), 描述要执行的动作. 例如, GET 表示要获取资源, POST 表示向服务器推送数据 (创建或修改资源)。
-
请求目标 (request target),通常是一个URL,或者是协议、端口和域名的绝对路径,通常以请求的环境为特征。请求的格式因不同的 HTTP 方法而异。它可以是:
- 一个完整的URL,被称为 绝对形式 (absolute form),主要在使用 GET方法连接到代理时使用。
GET http://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1 - 由域名和可选端口(以':' 为前缀)组成的 URL 的 authority component,称为 authority form。 仅在使用 CONNECT 建立 HTTP 隧道时才使用。
CONNECT developer.mozilla.org:80 HTTP/1.1 - 星号形式 (asterisk form),一个简单的星号( '*' ),配合 OPTIONS 方法使用,代表整个服务器。
OPTIONS * HTTP/1.1
- HTTP 版本 (HTTP version),定义了剩余报文的结构,作为对期望的响应版本的指示符。
(2)Headers
来自请求的 HTTP headers遵循和 HTTP header 相同的基本结构:不区分大小写的字符串,紧跟着的冒号 (':') 和一个结构取决于 header 的值。 整个header(包括值)由一行组成,这一行可以相当长。
(3)Body
请求的最后一部分是它的 body。不是所有的请求都有一个 body:例如获取资源的请求,GET,HEAD,DELETE 和 OPTIONS,通常它们不需要 body。 有些请求将数据发送到服务器以便更新数据:常见的的情况是 POST 请求(包含HTML 表单数据)。
1.1.4 HTTP响应
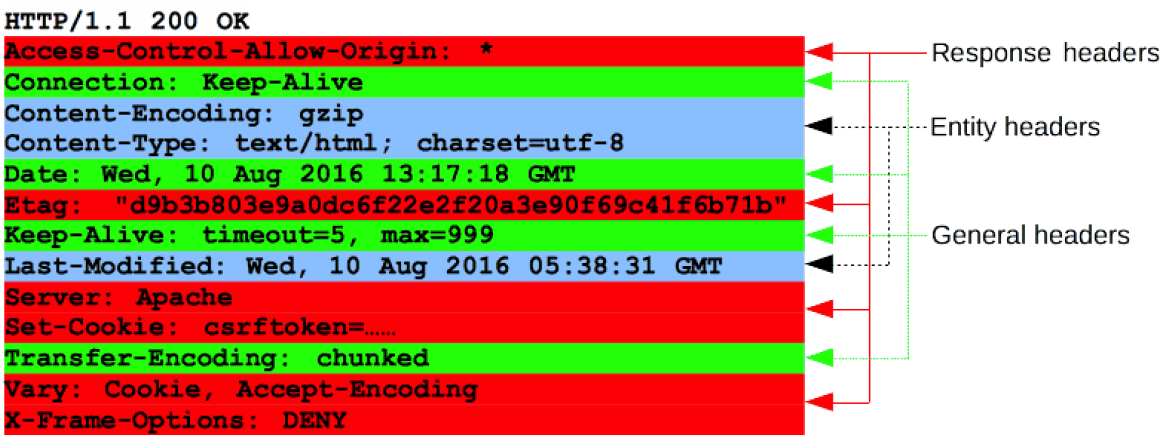
(1)状态行
HTTP 响应的起始行被称作 状态行 (status line),包含以下信息:
- 协议版本,通常为 HTTP/1.1。
- 状态码 (status code),表明请求是成功或失败。常见的状态码是 200 ,404 ,或 302 。
- 状态文本 (status text)。一个简短的,纯粹的信息,通过状态码的文本描述,帮助人们理解该 HTTP 消息。
一个典型的状态行看起来像这样: HTTP/1.1 404 Not Found 。
(2)Headers
响应的 HTTP headers:不区分大小写的字符串,紧跟着的冒号 ( ':' ) 和一个结构取决于 header 类型的值。 整个 header(包括其值)表现为单行形式。
(3)Body
响应的最后一部分是 body。不是所有的响应都有 body。
1.1.5 HTTP请求方法
请求的起始行以方法作为开始, 方法用来告知服务器要做些什么。

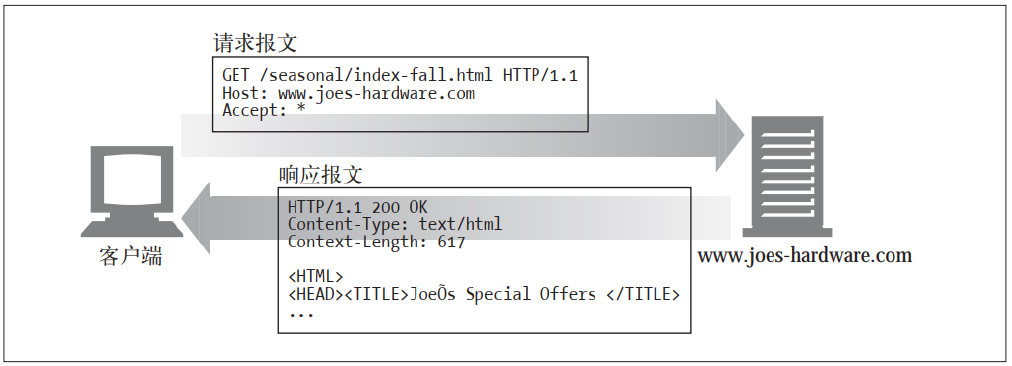
(1)GET
GET 是最常用的方法。 通常用于请求服务器发送某个资源。 HTTP/1.1 要求服务器实现此方法。
(2)HEAD
HEAD 方法与 GET 方法的行为很类似, 但服务器在响应中只返回首部。 不会返回实体的主体部分。 这就允许客户端在未获取实际资源的情况下, 对资源的首部进行检查。 使用 HEAD, 可以:
- 在不获取资源的情况下了解资源的情况(比如, 判断其类型) ;
- 通过查看响应中的状态码, 看看某个对象是否存在;
- 通过查看首部, 测试资源是否被修改了。
服务器开发者必须确保返回的首部与 GET 请求所返回的首部完全相同。 遵循HTTP/1.1 规范, 就必须实现 HEAD 方法。

(3)PUT
与 GET 从服务器读取文档相反, PUT 方法会向服务器写入(更新)文档。
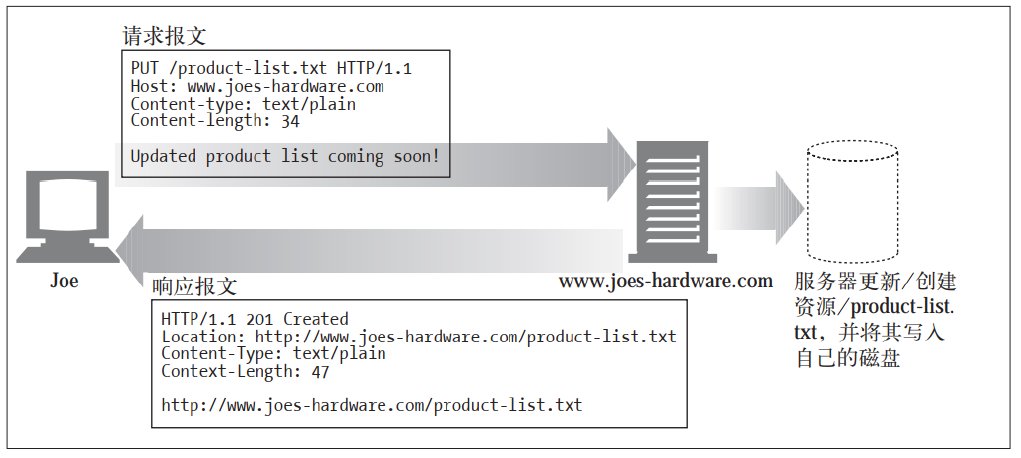
PUT 方法的语义就是让服务器用请求的主体部分来创建一个由所请求的 URL 命名的新文档, 或者, 如果那个 URL 已经存在的话, 就用这个主体来替代它。
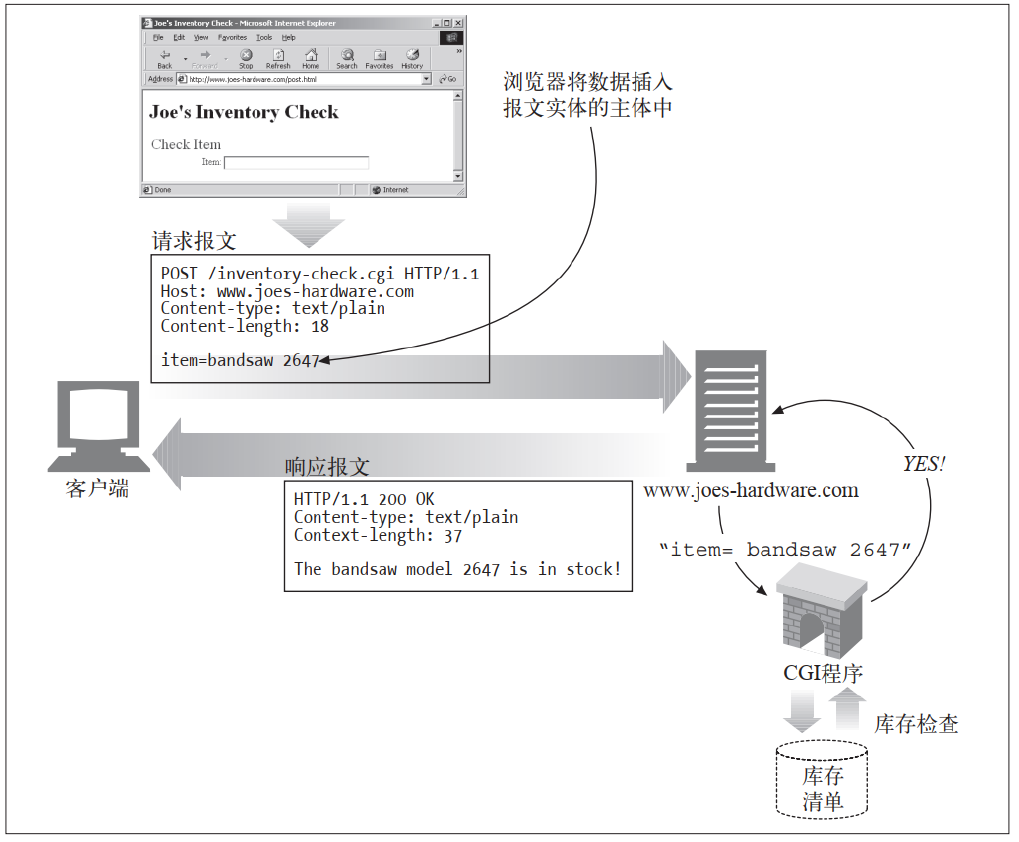
(4)POST
POST 方法起初是用来向服务器输入数据的 。 实际上, 通常会用它来支持HTML的表单。 表单中填好的数据通常会被送给服务器处理。
(5)TRACE
TRACE客户端发起一个请求时, 这个请求可能要穿过防火墙、 代理、 网关或其他一些应用程序。 每个中间节点都可能会修改原始的 HTTP 请求。 TRACE 方法允许客户端在最终将请求发送给服务器时, 看看它变成了什么样子。TRACE 请求会在目的服务器端发起一个"环回" 诊断。 行程最后一站的服务器会弹回一条TRACE 响应, 并在响应主体中携带它收到的原始请求报文。 这样客户端就可以查看在所有中间 HTTP 应用程序组成的请求 / 响应链上, 原始报文是否, 以及
如何被毁坏或修改过
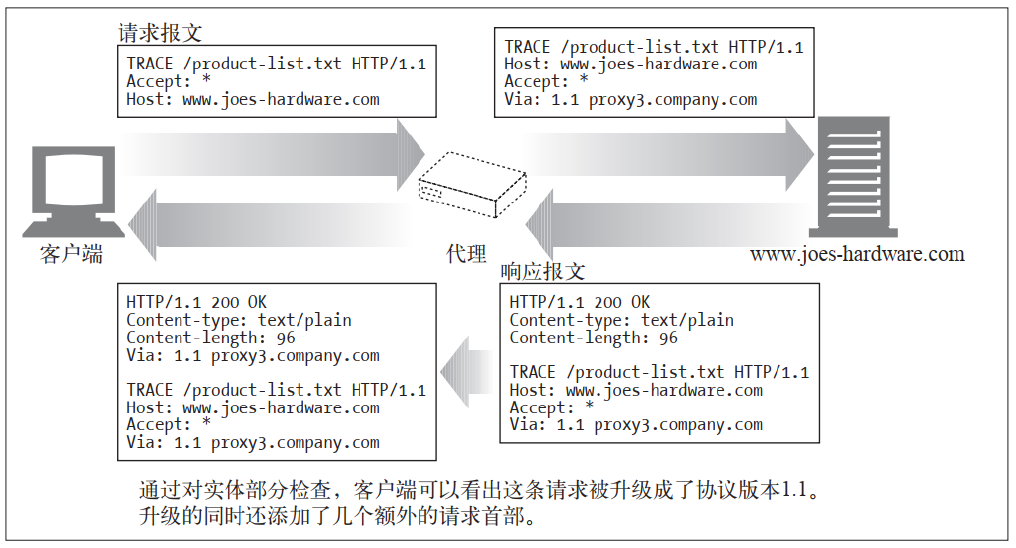
TRACE 方法主要用于诊断; 也就是说, 用于验证请求是否如愿穿过了请求 / 响应链。
(6)OPTIONS
OPTIONS 方法请求 Web 服务器告知其支持的各种功能。 可以询问服务器通常支持哪些方法, 或者对某些特殊资源支持哪些方法。
(7)DELETE
DELETE 方法所做的事情就是请服务器删除请求 URL 所指定的资源。

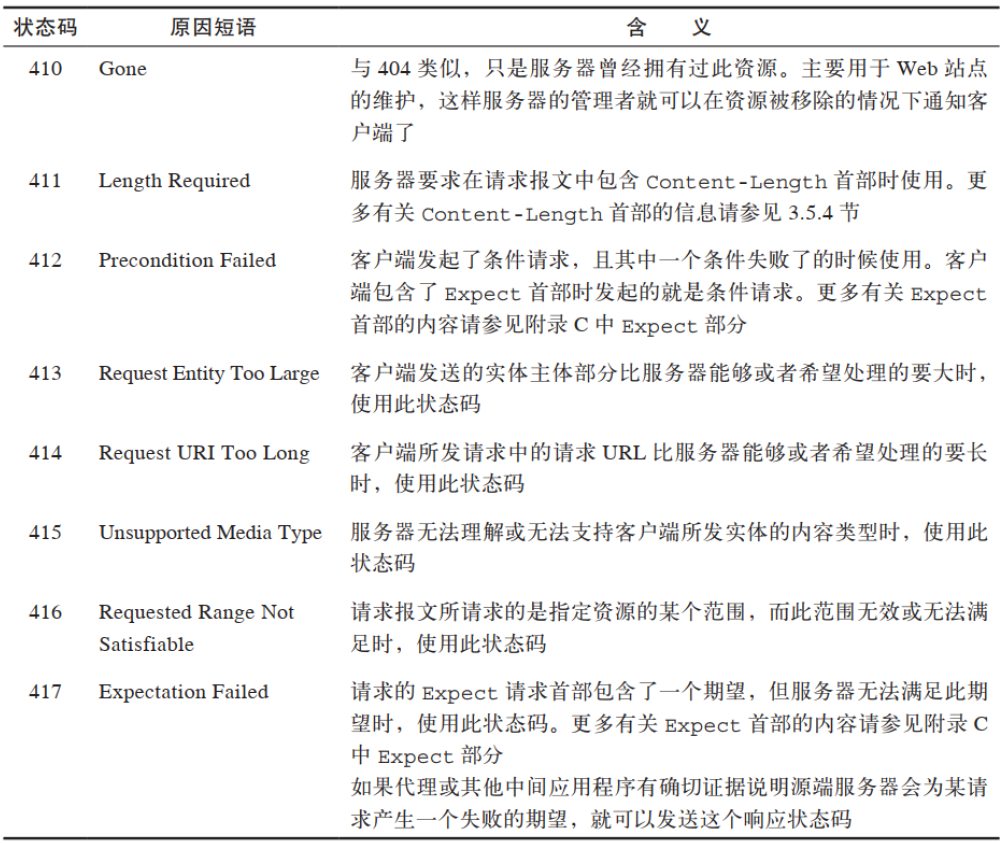
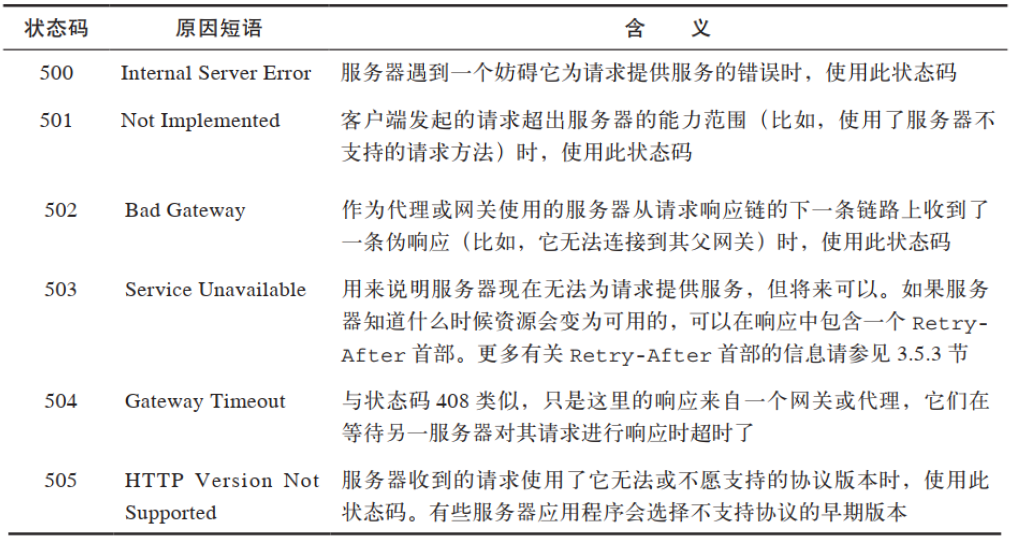
1.1.6 状态码
方法是用来告诉服务器做什么事情的, 状态码则用来告诉客户端,事情执行的结果。状态码位于响应的起始行中。 服务器通常会返回一个数字状态和一个可读的状态。 数字码便于程序进行差错处理, 而原因短语则更便于人们理解。
- 200 到 299 之间的状态码表示成功。
- 300 到 399 之间的代码表示资源已经被移走
- 400 到 499 之间的代码表示客户端的请求出错
- 500 到 599 之间的代码表示服务器出错
状态码分类:

常见状态码:

(1)成功状态码
客户端发起请求时, 这些请求通常都是成功的。 服务器有一组用来表示成功的状态码, 分别对应于不同类型的请求。

(2)重定向状态码
重定向状态码要么告知客户端使用替代位置来访问他们所感兴趣的资源, 要么就提供一个替代的响应而不是资源的内容。
如果资源已被移动, 可发送一个重定向状态码告知客户端资源已被移走, 以及现在可以在哪里找到目标资源。
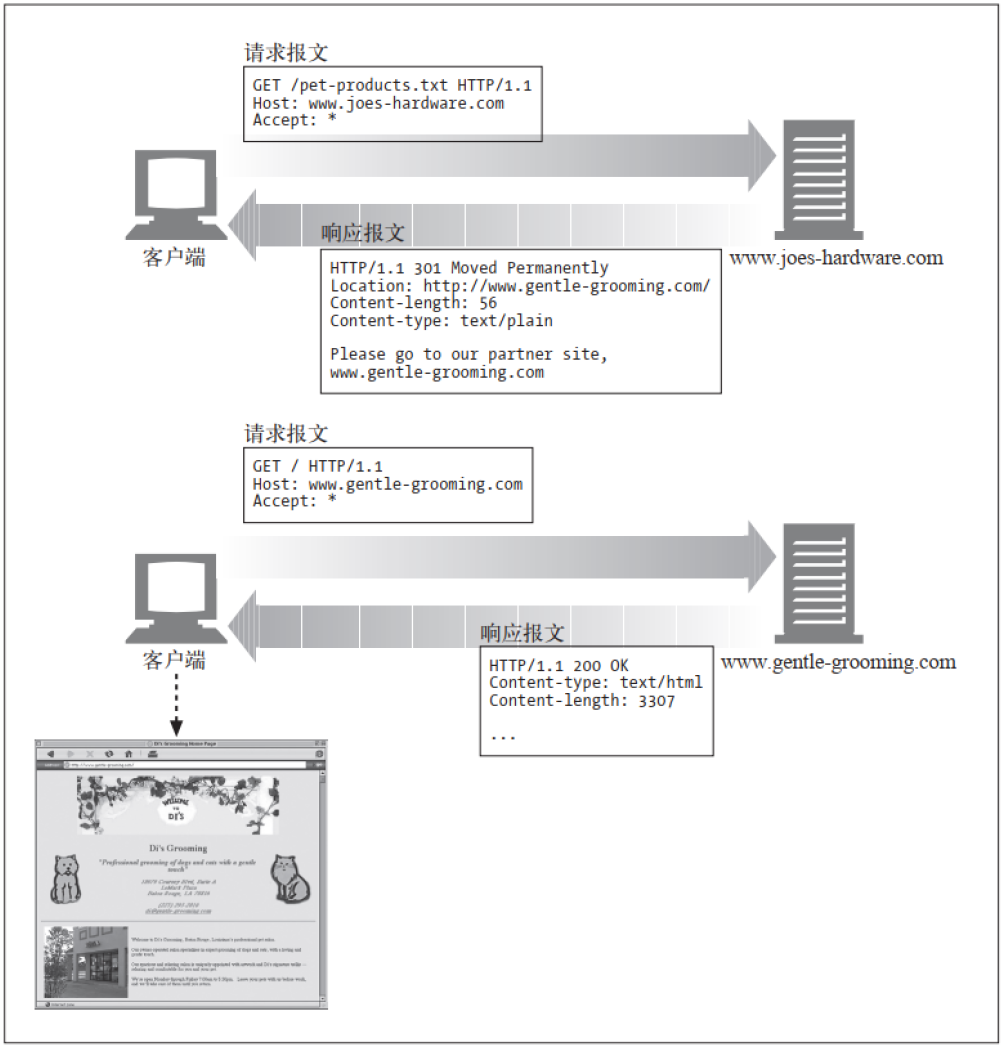
使用场景:
web应用支持https,客户端访问http://www.baidu.com,服务器收到请求之后(Nginx)发现请求的是http请求,可以返回301告知浏览器重新发出请求。
重定向状态码与原因短语:
- 301 redirect: 301 代表永久性转移(Permanently Moved)
- 302 redirect: 302 代表暂时性转移(Temporarily Moved )
301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,这个地址可以从响应的Location首部中获取(用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)------这是它们的共同点。
他们的不同在于。301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存旧的网址。

(3)客户端错误状态码
有时客户端会发送一些服务器无法处理的东西, 比如格式错误的请求报文, 或者最常见的是, 请求一个不存在的 URL。浏览网页时, 我们都看到过臭名昭著的 404 Not Found 错误码------这只是服务器在告诉我们, 它对我们请求的资源一无所知。

(4)服务器错误状态码
有时客户端发送了一条有效请求, 服务器自身却出错了。 这可能是客户端碰上了服务器的缺陷, 或者服务器上的子元素, 比如某个网关资源, 出了错。代理尝试着代表客户端与服务器进行交流时, 经常会出现问题。
1.2 连接管理
1.2.1 TCP连接
HTTP 通信由 TCP/IP 承载的, TCP/IP 是全球计算机及网络设备都在使用的一种常用的分组交换网络分层协议集。 客户端应用程序可以打开一条 TCP/IP 连接,连接到可能运行在世界任何地方的服务器应用程序。 一旦连接建立, 在客户端和服务器的计算机之间交换的报文就永远不会丢失、 受损或失序。


1.2.1.1 三步握手
TCP协议目的是为了保证数据能在两端准确连续的流动,可以想象两个建立起TCP通道的设备就如同接起了一根水管,数据就是水管中的水由一头流向另一头。然而TCP为了能让一个设备连接多根"水管",让一个设备能同时与多个设备交互信息,它必须要保证不同水管之间不会产生串联或相互影响为了确保数据能够正确分发,TCP用一种叫做TCB,也叫传输控制块的数据结构把发给不同设备的数据封装起来,我们可以把该结构看做是信封。一个TCB数据块包含了数据发送双方对应的socket信息以及拥有装载数据的缓冲区。在两个设备要建立连接发送数据之前,双方都必须要做一些准备工作,分配内存建立起TCB数据块就是连接建立前必须要做的准备工作。
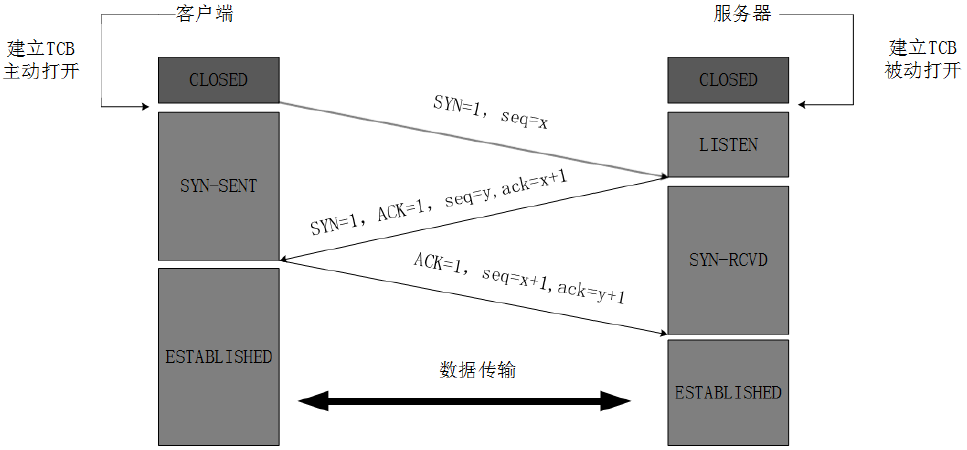
(0)准备工作
最开始的时候客户端和服务器都是处于CLOSED状态。主动打开连接的为客户端,被动打开连接的是服务器。
TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态
(1)一次握手:
TCP客户进程也是先创建传输控制块TCB,然后向服务器发出连接请求报文,这是报文首部中的同部位SYN=1,同时选择一个初始序列号 seq=x 。
此时,TCP客户端进程进入了 SYN-SENT(同步已发送状态)状态。TCP规定,SYN报文段(SYN=1的报文段)不能携带数据,但需要消耗掉一个序号。
(2)二次握手:
TCP服务器收到请求报文后,如果同意连接,则发出确认报文。确认报文中应该 ACK=1,SYN=1,确认号是ack=x+1,同时也要为自己初始化一个序列号seq=y,此时,TCP服务器进程进入了SYN-RCVD(同步收到)状态。这个报文也不能携带数据,但是同样要消耗一个序号。
ACK为1表示确认号有效,为0表示报文中不包含确认信息
(3)三次握手:
TCP客户进程收到确认后,还要向服务器给出确认。确认报文的ACK=1,ack=y+1,自己的序列号seq=x+1,此时,TCP连接建立,客户端进入ESTABLISHED(已建立连接)状态。TCP规定,ACK报文段可以携带数据,但是如果不携带数据则不消耗序号。
当服务器收到客户端的确认后也进入established状态,此后双方就可以开始通信了。
注:tcp建立连接需要三次握手,SYN是发送标志位,ACK是确认标志位.
为什么TCP客户端最后还要发送一次确认呢?
主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。
如果使用的是两次握手建立连接,假设有这样一种场景,客户端发送了第一个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了,由于TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数据,然后关闭连接。此时此前滞留的那一次请求连接,网络通畅了到达了服务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务器再次建立连接,这将导致不必要的错误和资源的浪费。
如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由于服务器收不到确认,就知道客户端并没有请求连接。
为什么要3次握手?
换个易于理解的视角来看为什么要3次握手。
客户端和服务端通信前要进行连接,3次握手的作用就是双方都能明确自己和对方的收、发能力是正常的。
第一次握手:客户端发送网络包,服务端收到了。这样服务端就能得出结论:客户端的发送能力、服务端的接收能力是正常的。
第二次握手:服务端发包,客户端收到了。这样客户端就能得出结论:服务端的接收、发送能力,客户端的接收、发送能力是正常的。
- 从客户端的视角来看,我接到了服务端发送过来的响应数据包,说明服务端接收到了我在第一次握手时发送的网络包,并且成功发送了响应数据包,这就说明,服务端的接收、发送能力正常。
- 而另一方面,我收到了服务端的响应数据包,说明我第一次发送的网络包成功到达服务端,这样,我自己的发送和接收能力也是正常的。
第三次握手:客户端发包,服务端收到了。这样服务端就能得出结论:客户端的接收、发送能力,服务端的发送、接收能力是正常的。 第一、二次握手后,服务端并不知道客户端的接收能力以及自己的发送能力是否正常。而在第三次握手时,服务端收到了客户端对第二次握手作的回应。从服务端的角度,我在第二次握手时的响应数据发送出去了,客户端接收到了。所以,我的发送能力是正常的。而客户端的接收能力也是正常的。
经历了上面的三次握手过程,客户端和服务端都确认了自己的接收、发送能力是正常的。之后就可以正常通信了。
1.2.1.2 TCP协议缺陷
DDOS又称为分布式拒绝服务,全称是Distributed Denial of Service。DDOS本是利用合理的请求造成服务器资源过载,导致服务不可用。常见的DDOS攻击有SYN flood(SYN flood)、UDP flood、ICMP、flood等,其中SYN flood是一种最为经典的DDOS攻击。SYN flood如此猖獗是因为它利用了TCP协议设计中的缺陷,而TCP/IP协议是整个互联网的基础,牵一发而动全身,如今想要修复这样的缺陷几乎成为不可能的事情。
SYN flood攻击原理:
- SYN flood在攻击时,首先伪造大量的源IP地址,分别向服务器端发送大量的SYN包。
- 服务器端返回SYN/ACK包,因为源地址是伪造的,所以伪造的IP并不会应答。
- 服务器端没有收到伪造IP的回应,会重试3~5次并且等待一个SYN Time(---般为30秒至2分钟),如果超时则丢弃这个连接。
- 攻击者大量发送这种伪造源地址的SYN请求,服务器端将会消耗非常多的资源来处理这种半连接,同时还要不断地对这些IP进行SYN+ACK重试。
- 最后的结果是服务器无暇理睬正常的连接请求,导致拒绝服务。
1.2.1.3 四次挥手
数据传输完毕后,双方都可释放连接。最开始的时候,客户端和服务器都是处于established(表示连接已经建立)状态,然后客户端主动关闭,服务器被动关闭。
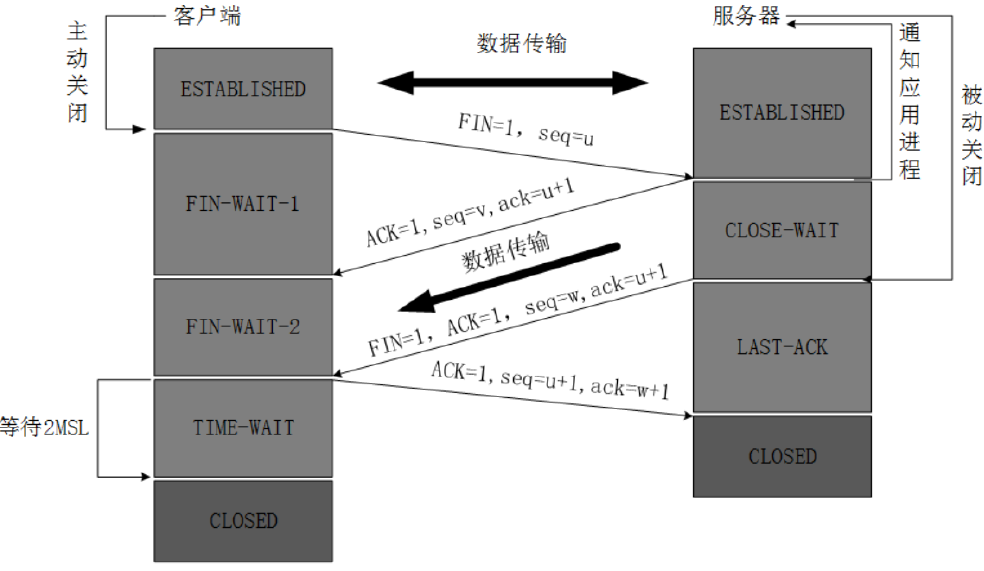
-
客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1(FIN表示关闭连接,SYN表示建立连接),其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
-
服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1(确认序号为收到的序号加1),并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
CLOSE_WAIT:表示在等待关闭状态 -
客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
-
服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
-
客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2*MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
-
服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。而这两种状态的区别是:FIN_WAIT_1状态实际上是当SOCKET在ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET即进入到FIN_WAIT_1状态。而当对方回应ACK报文后,则进入到FIN_WAIT_2状态
四次挥手简洁版:
- TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送。
- 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
- 服务器关闭客户端的连接,发送一个FIN给客户端。
- 客户端发回ACK报文确认,并将确认序号设置为收到序号加1。
为什么客户端最后还要等待2MSL?
MSL(Maximum Segment Lifetime),TCP允许不同的实现可以设置不同的MSL值。
去向ACK消息最大存活时间(MSL) + 来向FIN消息的最大存活时间(MSL)。这恰恰就是**2MSL( Maximum Segment Life)。
第一,保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK报文可能丢失,站在服务器的角度看来,我已经发送了FIN+ACK报文请求断开了,客户端还没有给我回应,应该是我发送的请求断开报文它没有收到,于是服务器又会重新发送一次,而客户端就能在这个2MSL时间段内收到这个重传的报文,接着给出回应报文,并且会重启2MSL计时器。
第二,等待2MSL时间,客户端就可以放心地释放TCP占用的资源、端口号。如果不等,释放的端口可能会重连刚断开的服务器端口,这样依然存活在网络里的老的TCP报文可能与新TCP连接报文冲突,造成数据冲突,为避免此种情况,需要耐心等待网络老的TCP连接的活跃报文全部死翘翘,2MSL时间可以满足这个需求(尽管非常保守)!
为什么建立连接是三次握手,关闭连接确是四次挥手呢?
建立连接的时候, 服务器在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。
关闭连接时,服务器收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必已经将全部数据都发送给对方了,所以己方可以立即关闭,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送,从而导致多了一次。
如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
1.2.2 TCP数据传输
1.2.2.1 传输原理
TCP通过 " 发送 --- 应答 (ACK确认)"来确保传输的可靠性,它是端到端传输的。
TCP传输是分段的,一个HTTP响应报文会被操作系统切成多个MSS(Maximum Segment Size)大小的段,直到接收端接受到完整的报文为止。在此过程中,报文分段按照顺序进行发送,每个报文段在发送时,会做顺序编号,以便能够完整正确地组装。
MSS:Maximum Segment Size 最大报文段长度,是TCP协议的一个选项,用于在TCP连接建立时,收发双方协商通信时每一个报文段所能承载的最大数据长度(不包括文段头)。如果MSS选项数据为512,则表示该报文段的发送方可以处理的最大报文段长度为512字节(不包括TCP与IP协议头长度)。主机一般默认MSS为536字节
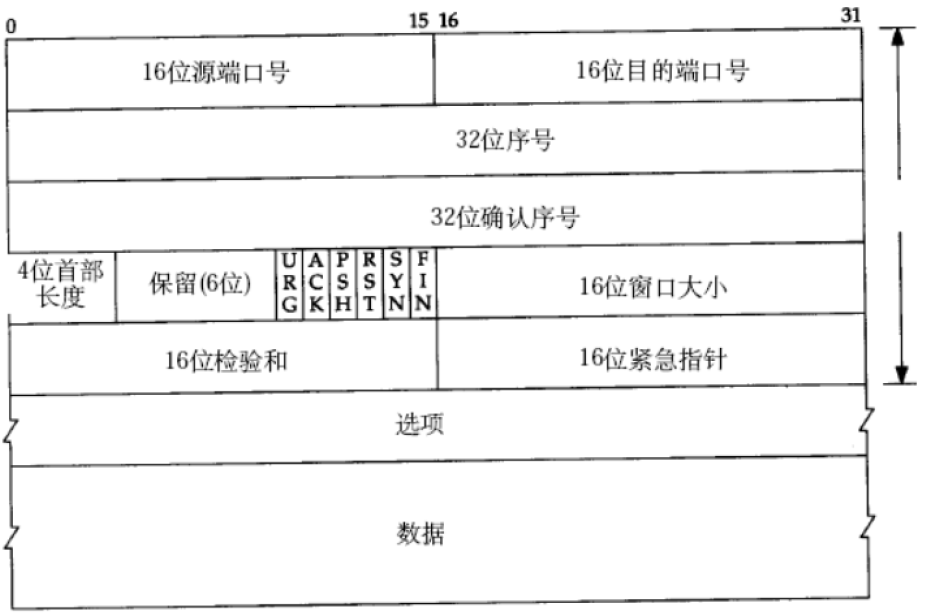
端口号:
- 表示同一个计算机上的不同进程
- 源端口号和目标端口号都是占用了两个字节
- TCP的源端口号和目标端口号预计IP报文中的源IP和目标IP确认一条唯一的TCP连接
序号:
4个字节
确认序号:
ack,占四个字节
控制位:
URG、ACK、PSH、RST、SYN、FIN
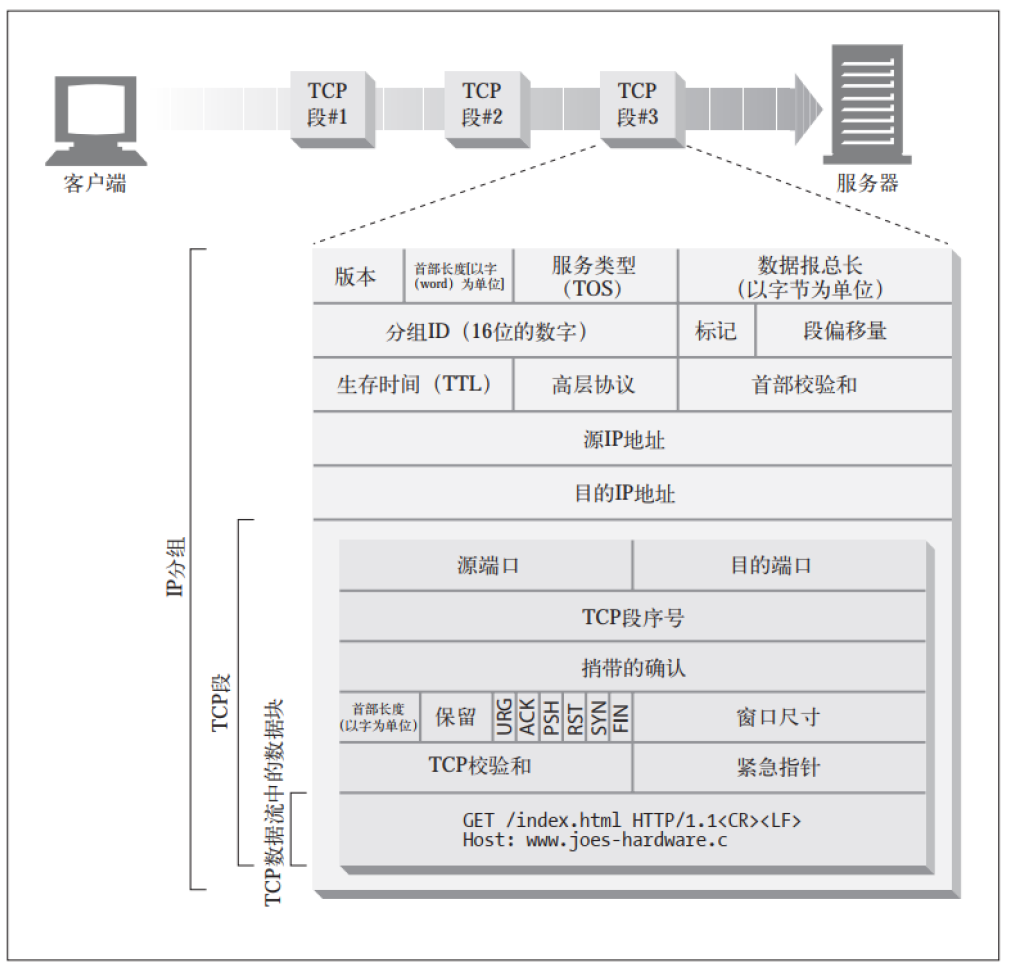
TCP 的数据是通过名为 IP 分组( 或 IP 数据报) 的小数据块来发送的。HTTP就是"HTTP over TCP over IP" 这个"协议栈" 中的最顶层了。 其安全版本 HTTPS就是在 HTTP 和 TCP 之间插入了一个( 称为 TLS 或 SSL的) 密码加密层。
HTTP 要传送一条报文时, 会以流的形式将报文数据的内容通过一条打开的TCP 连接按序传输。 TCP 收到数据流之后, 会将数据流砍成被称作段的小数据块, 并将段封装在 IP 分组中, 通过因特网进行传输。 所有这些工作都是由TCP/IP 软件来处理的, HTTP 程序员什么都看不到。
每个 TCP 段都是由 IP 分组承载, 从一个 IP 地址发送到另一个 IP 地址的。 每个 IP分组中都包括:
- 一个 IP 分组首部(通常为 20 字节)
- 一个 TCP 段首部(通常为 20 字节)
- 一个 TCP 数据块(0 个或多个字节)
IP 首部包含源和目的 IP 地址、 长度和其他一些标记。 TCP 段的首部包含了TCP端口号、 TCP 控制标记, 以及用于数据排序和完整性检查的一些数字值。
TCP 连接是通过 4 个值来识别的:
< 源 IP 地址、 源端口号、 目的 IP 地址、 目的端口号 >
这 4 个值一起唯一地定义了一条连接。 两条不同的 TCP 连接不能在同一时刻拥
有 4 个完全相同的地址组件值
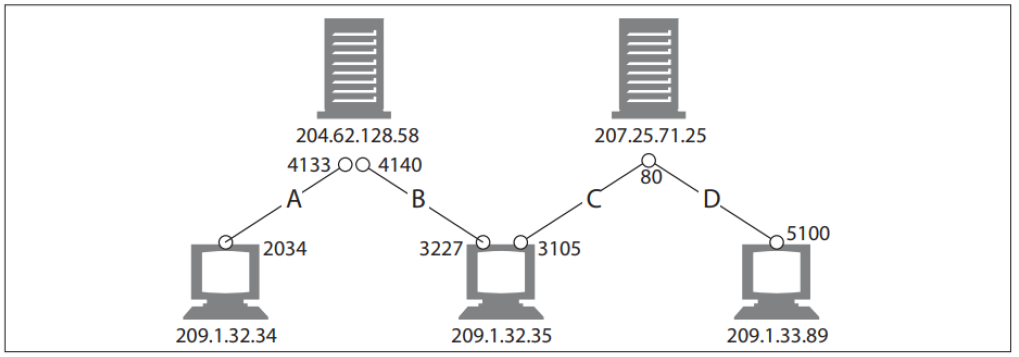
有些连接共享了相同的目的端口号(C 和 D 都使用目的端口号 80)。 有些连接使用了相同的源 IP 地址(B 和 C)。 有些使用了相同的目的 IP 地址(A 和 B,C和 D)。 但没有两个不同连接所有的 4 个值都一样。
1.2.2.2 滑动窗口协议
将TCP与UDP这样的简单传输协议区分开来的两种协议不同的传输数据的质量。
TCP对于发送数据进行跟踪,这种数据管理需要协议有以下两大关键功能:
可靠性 :保证数据确实到达目的地。如果未到达,能够发现并重传。
数据流控:管理数据的发送速率,以使接收设备不致于过载。
要完成这些任务,整个协议操作是围绕滑动窗口确认机制来进行的。因此,理解了滑动窗口,也就是理解了TCP。
(1)在我们滑动窗口协议之前,我们如何来保证发送方与接收方之间,每个包都能被收到,并且是按次序的呢?
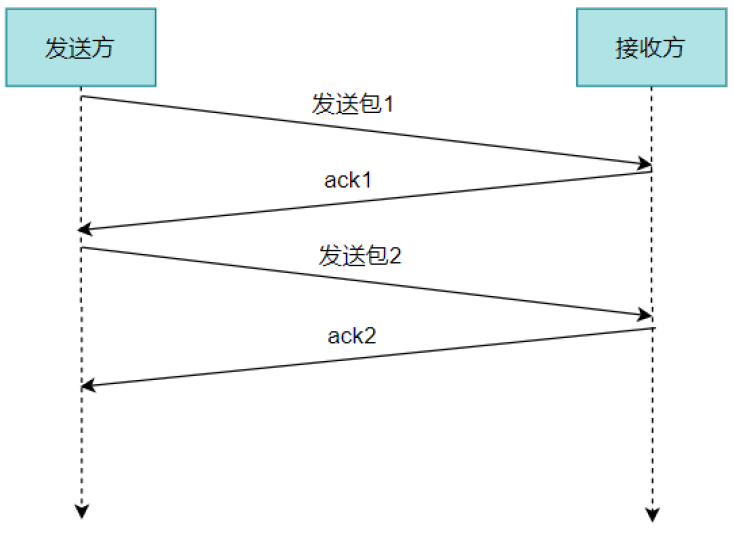
问题:吞吐量非常的低。我们发完包1,一定要等确认包1,我们才能发送第二个包。
(2)那么我们就不能先连发几个包等他一起确认吗?这样的话速度更快,吞吐量更高
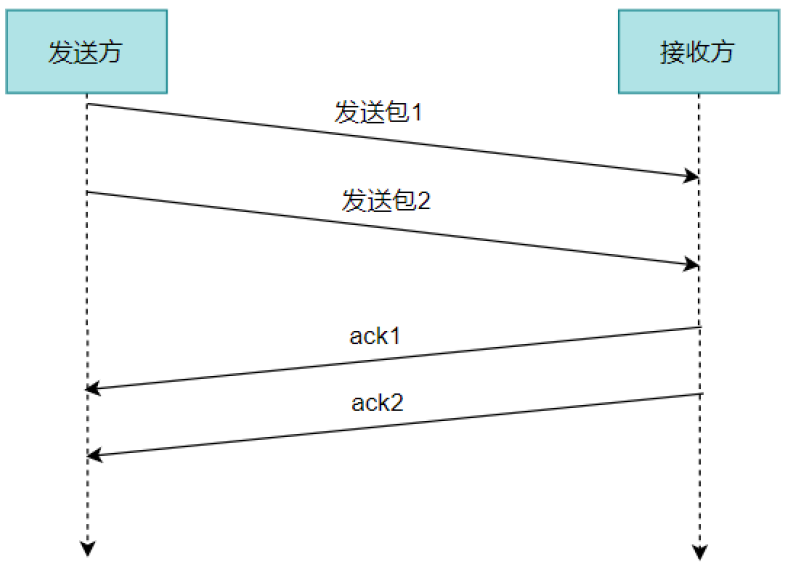
问题:如果过多的源同时以很快的速度发送大量的数据包,而此时接收方并没有如此高的接收数据的能力,因此极易导致网络的拥塞。
(3)滑动窗口协议(Sliding Window Protocol)
该协议是 TCP协议 的一种应用,用于网络数据传输时的流量控制,以避免拥塞的发生。该协议允许发送方在停止并等待确认前发送多个数据分组。由于发送方不必每发一个分组就停下来等待确认。因此该协议可以加速数据的传输,提高网络吞吐量。滑动窗口算法其实和这个是一样的,只是用的地方场景不一样。
如果我们在任一时间点对于这一过程做一个"快照",那么我们可以将TCP buffer中的数据分为以下四类,并把它们看作一个时间轴:
- 已发送已确认 数据流中最早的字节已经发送并得到确认。这些数据是站在发送设备的角度来看的。
- 已发送但尚未确认 已发送但尚未得到确认的字节。发送方在确认之前,不认为这些数据已经被处理。
- 未发送而接收方已Ready 设备尚未将数据发出,但接收方根据最近一次关于发送方一次要发送多少字节确认自己有足够空间。发送方会立即尝试发送。
- 未发送而接收方Not Ready 由于接收方not ready,还不允许将这部分数据发出。
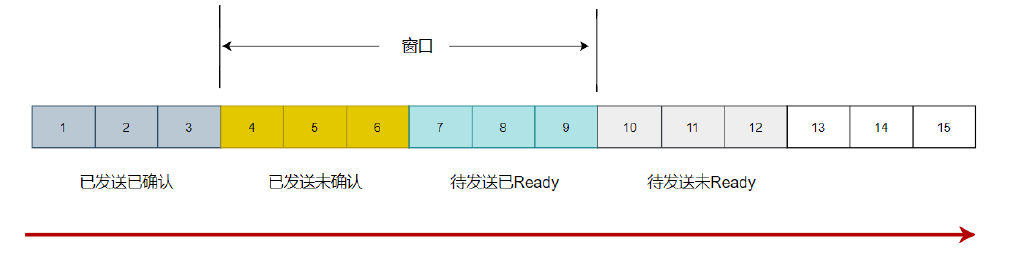
说明:
- 灰色1号2号3号包已经发送完毕,并且已经收到Ack。这些包就已经是过去式。
- 4、5、6号包是黄色的,表示已经发送了。但是并没有收到对方的Ack,所以也不知道接收方有没有收到。
- 7、8、9号包是淡蓝色的。是我们还没有发送的。这些淡蓝色也就是我们接下来马上要发送的包。
- 后面的10-15还没有被读进内存。要等4号-9号包有接下来的动作后,我们的包才会继续往下发送。
正常情况:
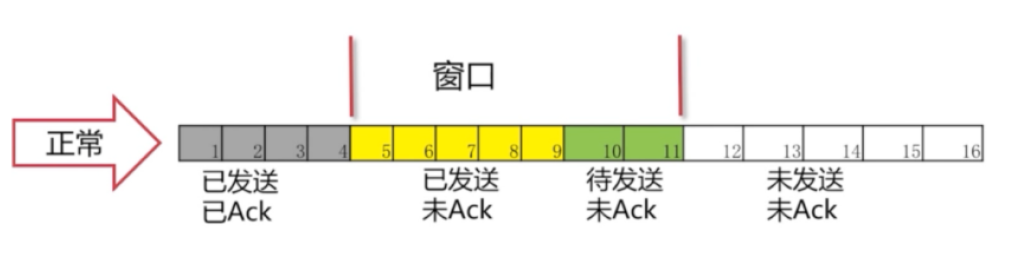
可以看到4号包对方已经被接收到,所以被涂成了灰色。"窗口"就往右移一格。我们就把11号包读进了我们的缓存。进入了"待发送"的状态。8、9号包已经变成了黄色,表示已经发送出去了。接下来的操作就是一样的了,确认包后,窗口往后移继续将未发送的包读进缓存,把"待发送"状态的包变为"已发送"。
丢包情况:
有可能我们包(5-11)发过去,对方的Ack丢了。也有可能我们的包并没有发送过去。从发送方角度看就是我们没有收到Ack。
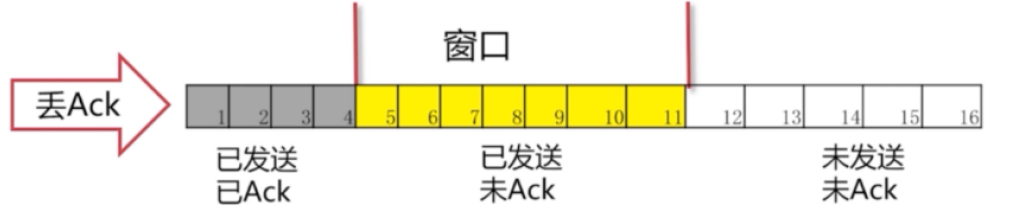
发生的情况:一直在等Ack。如果一直等不到的话,我们也会把读进缓存的待发送的包也一起发过去。但是,这个时候我们的窗口已经发满了。所以并不能把12号包读进来,而是始终在等待5号包的Ack。
问题:如果我们这个Ack始终不来怎么办呢?
超时重发/重传:
原理是在发送某一个数据以后就开启一个计时器,在一定时间内如果没有得到发送的数据报的ACK报文,那么就重新发送数据,直到发送成功为止。
影响超时重传机制协议效率的一个关键参数是重传超时时间(RTO,Retransmission TimeOut)。RTO的值被设置过大过小都会对协议造成不利影响。
- RTO设长了,重发就慢,没有效率,性能差。
- RTO设短了,重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
- 连接往返时间(RTT,Round Trip Time),指发送端从发送TCP包开始到接收它的立即响应所消耗的时间。
在 Unix 以及 Windows 系统中,最初其重发超时的默认值一般设置为6秒(重发时间必须是0.5秒的倍数)左右。数据被重发之后若还是收不到确认应答,则进行再次发送。此时,等待确认应答的时间将会以2倍、4倍的指数函数延长。
此外,数据也不会被无限、反复地重发。达到一定重发次数之后,如果仍没有任何确认应答返回,就会判断为网络或对端主机发生了异常,强制关闭连接,并且通知应用通信异常强行终止。
1.2.3 TCP性能
HTTP 紧挨着 TCP, 位于其上层, 所以 HTTP 事务的性能在很大程度上取决于底层TCP 通道的性能。
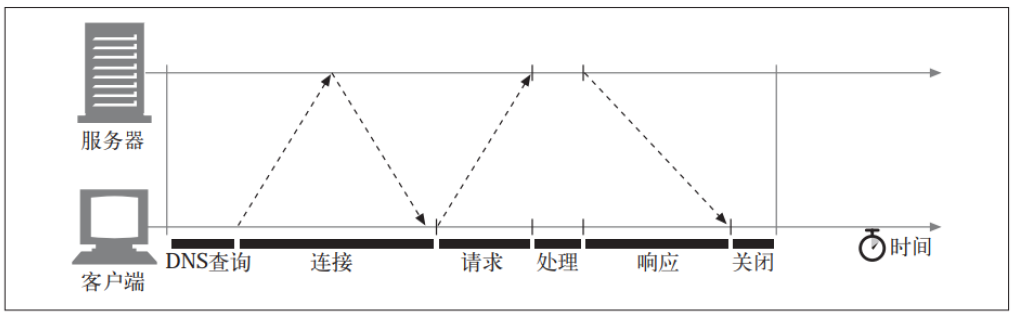
HTTP 事务的时延有以下几种主要原因。
- 通过 DNS 解析系统将 URI 中的主机名转换成一个 IP地址要花费对应的时间
- 每条新的 TCP 连接都会有连接建立时延,但如果有数百个 HTTP 事务的话, 这个时间消耗值会快速地叠加上去。
- 网络传输请求报文及服务器处理请求报文都需要时间。
- Web 服务器会回送 HTTP 响应的花费时间。
这些网络时延的大小取决于硬件速度、 网络和服务器的负载, 请求和响应报文的尺寸, 以及客户端和服务器之间的距离。 TCP 协议的技术复杂性也会对时延产生巨大的影响。
性能聚焦区域:
- TCP 连接建立握手;
- TCP 慢启动拥塞控制;
- TCP 延迟确认算法;
- Nagle 算法;
(1)TCP连接的握手时延

TCP 连接握手需要经过以下几个步骤。
- 请求新的 TCP 连接时, 客户端要向服务器发送一个小的 TCP 分组(通常是 40 ~60 个字节)。 这个分组中设置了一个特殊的 SYN 标记, 说明这是一个连接请求。
- 如果服务器接受了连接, 就会对一些连接参数进行计算, 并向客户端回送一个TCP 分组, 这个分组中的 SYN 和 ACK 标记都被置位, 说明连接请求已被接受
- 客户端向服务器回送一条确认信息, 通知它连接已成功建立。现在的 TCP栈都允许客户端在这个确认分组中发送数据。
(2)延迟确认(ACK)
由于网络自身无法确保可靠的分组传输( 如果网络设备超负荷的话, 可以随意丢弃分组), 所以 TCP 实现了自己的确认机制来确保数据的成功传输。每个 TCP 段都有一个序列号和数据完整性校验和。 服务端收到完好的TCP段时,都会向发送者回送小的确认报文。 如果发送者没有在指定的窗口时间内收到确认信息, 发送者就认为分组已损毁或丢失, 并重发数据。
由于确认报文很小, 所以 TCP 允许在发往相同方向的输出数据分组中对其进行"捎带"。 TCP 将返回的确认信息与输出的数据分组结合在一起, 可以更有效地利用网络。 为了增加确认报文找到同向传输数据分组的可能性, 很多 TCP栈都实现了一种"延迟确认" 算法。 延迟确认算法会在一个特定的窗口时间( 通常是 100 ~ 200 毫秒) 内将输出确认存放在缓冲区中, 以寻找能够捎带它的
输出数据分组。 如果在那个时间段内没有输出数据分组, 就将确认信息放在单独的分组中传送。
但是当希望有相反方向回传分组的时候, 偏偏没有那么多。 通常, 延迟确认算法会引入相当大的时延。
(3)TCP慢启动
慢启动算法思路:
主机开发发送数据报时,如果立即将大量的数据注入到网络中,可能会出现网络的拥塞。慢启动算法就是在主机刚开始发送数据报的时候先探测一下网络的状况,如果网络状况良好,发送方每发送一次文段都能正确的接受确认报文段。那么就从小到大的增加拥塞窗口的大小,即增加发送窗口的大小, 用于防止因特网的突然过载和拥塞。
TCP 慢启动限制了一个 TCP 端点在任意时刻可以传输的分组数。 简单来说, 每成功接收一个分组, 发送端就有了发送另外两个分组的权限。 如果某个HTTP 事务有大量数据要发送, 是不能一次将所有分组都发送出去的。 必须发送一个分组, 等待确认; 然后可以发送两个分组, 每个分组都必须被确认,这样就可以发送四个分组了,以此类推。 这种方式被称为"打开拥塞窗口"。
(4)Nagle算法与TCP_NODELAY
TCP/IP协议中,无论发送多少数据,总是要在数据前面加上协议头,同时,对方接收到数据,也需要发送ACK表示确认。为了尽可能的利用网络带宽,TCP总是希望尽可能的发送足够大的数据。(一个连接会设置MSS参数,因此,TCP/IP希望每次都能够以MSS尺寸的数据块来发送数据)。Nagle算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块。如果 TCP 发送了大量包含少量数据的分组, 网络的性能就会严重下降。
Nagle算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块。
- Nagle 算法鼓励发送全尺寸的数据段:Nagle 算法试图在发送一个分组之前, 将大量TCP 数据绑定在一起, 以提高网络效率。
- 一个 TCP 连接上最多只能有一个未被确认的未完成的小分组,在该分组ACK 到达之前不能发送其他的小分组。如果其他分组仍然在传输过程中,就将那部分数据缓存起来。
- 只有当挂起分组被确认, 或者缓存中积累了足够发送一个全尺寸分组的数据时, 才会将缓存的数据发送出去。
Nagle 算法会引发几种 HTTP 性能问题。 首先, 小的 HTTP 报文可能无法填满一个分组, 可能会因为等待那些永远不会到来的额外数据而产生时延。 其次, Nagle 算法与延迟确认之间的交互存在问题------Nagle 算法会阻止数据的发送, 直到有确认分组抵达为止, 但确认分组自身会被延迟确认算法延迟 100~ 200 毫秒。
HTTP 应用程序常常会在自己的栈中设置参数 TCP_NODELAY, 禁用Nagle 算法,提高性能。(Tomcat通过server.xml进行设置,默认为true)
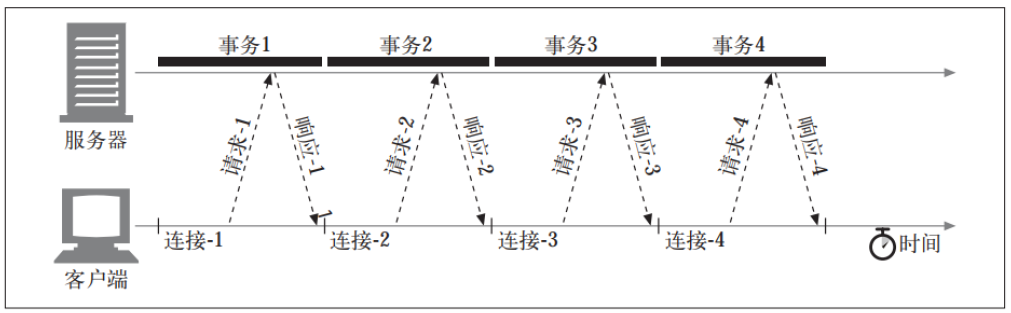
1.2.4 串行事务处理
如果只对连接进行简单的管理, TCP 的性能时延可能会叠加起来。 比如, 假设有一 个包含了 3 个嵌入图片的 Web 页面。 浏览器需要发起 4 个 HTTP 事务来显示此页面:1 个用于顶层的 HTML 页面, 3 个用于嵌入的图片。 如果每个事务都需要(串行地建立) 一条新的连接, 那么连接时延和慢启动时延就会叠加起来 。
除了串行加载引入的实际时延之外, 加载一幅图片时, 页面上其他地方都没有动静也会让人觉得速度很慢。 用户更希望能够同时加载多幅图片。 10串行加载的另一个缺点是, 有些浏览器在对象加载完毕之前无法获知对象的尺寸,而且它们可能需要尺寸信息来决定将对象放在屏幕的什么位置上, 所以在加载了足够多的对象之前, 无法在屏幕上显示任何内容。 在这种情况下, 可能浏览器串行装载对象的进度很正常, 但用户面对的却是一个空白的屏幕, 对装载的进度一无所知。
还有几种现存和新兴的方法可以提高 HTTP 的连接性能:
- 并行连接
通过多条 TCP 连接发起并发的 HTTP 请求。 - 持久连接
重用 TCP 连接, 以消除连接及关闭时延。 - 管道化连接
通过共享的 TCP 连接发起并发的 HTTP 请求。
1.2.4 并行连接
如前所述, 浏览器可以先完整地请求原始的 HTML 页面, 然后请求第一个嵌入对象, 然后请求第二个嵌入对象等, 以这种简单的方式对每个嵌入式对象进行串行处理。 但这样实在是太慢了!
HTTP 允许客户端(浏览器)打开多条TCP连接, 并行地执行多个 HTTP 事务(每个TCP连接处理一个HTTP事务)。 在这个例子中, 并行加载了四幅嵌入式图片, 每个事务都有自己的 TCP 连接。 页面上的每个组件都包含一个独立的HTTP 事务
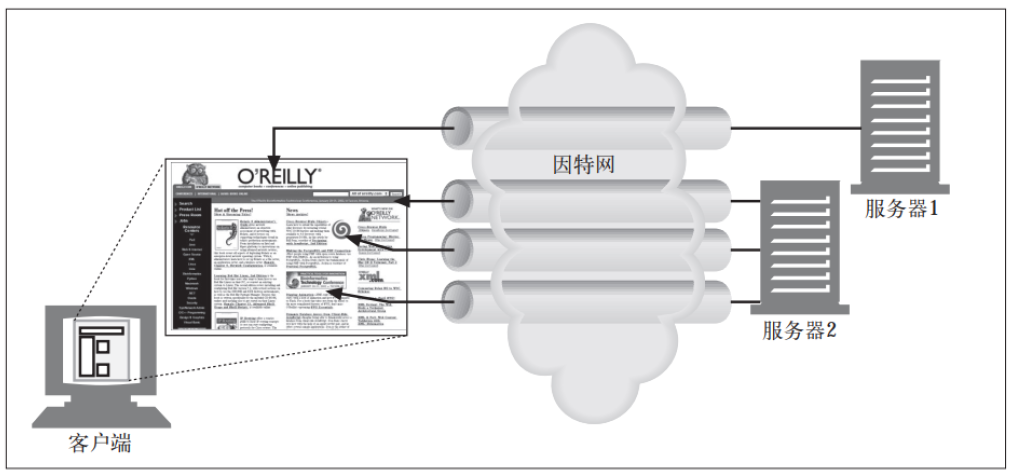
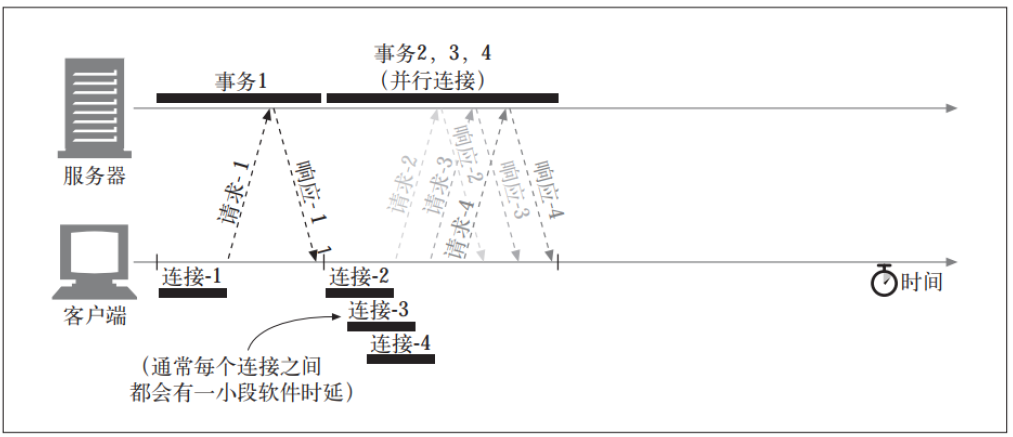
并行连接不一定更快 :
打开大量连接会消耗很多内存资源, 从而引发自身的性能问题。 复杂的 Web页面可能会有数十或数百个内嵌对象。 客户端可能可以打开数百个连接, 但 Web服务器通常要同时处理很多其他用户的请求, 所以很少有 Web 服务器希望出现这样的情况。 一百个用户同时发出申请, 每个用户打开 100 个连接, 服务器就要负责处理10 000 个连接。 这会造成服务器性能的严重下降。 对高负荷的代理来说也同样如此。
实际上, 浏览器确实使用了并行连接, 但它们会将向同一个域名请求的并行连接的总数限制为一个较小的值。
浏览器同域名请求的最大并发数限制:
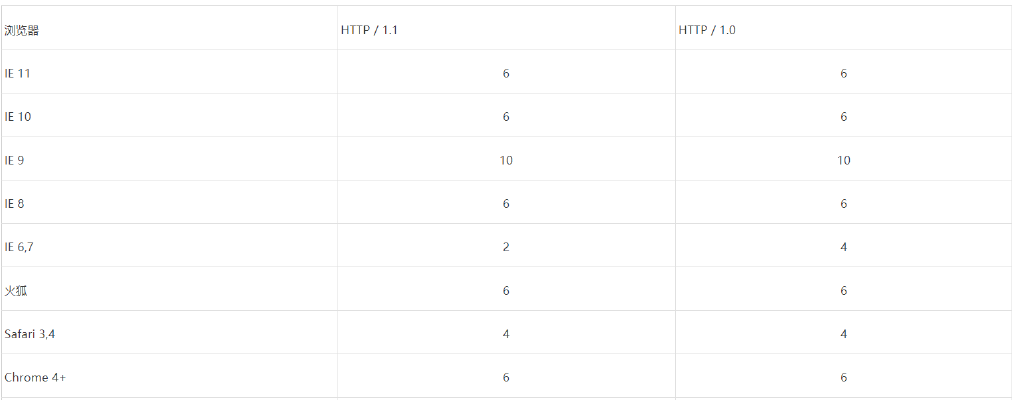
1.2.5 持久连接
Web 客户端经常会打开到同一个站点的连接。 比如, 一个 Web 页面上的大部分内嵌图片通常都来自同一个 Web 站点, 而且相当一部分指向其他对象的超链通常都指向同一个站点。 因此, 初始化了对某服务器 HTTP 请求的应用程序很可能会在不久的将来对那台服务器发起更多的请求(比如, 获取在线图片)。这种性质被称为站点局部性(site locality)。
HTTP/1.1(以及 HTTP/1.0 的各种增强版本) 允许 HTTP 设备在事务处理结束之后将 TCP 连接保持在打开状态, 以便为未来的 HTTP 请求重用现存的连接。在事务处理结束之后仍然保持在打开状态的 TCP 连接被称为持久连接。 非持久连接会在每个事务结束之后关闭。 持久连接会在不同事务之间保持打开状态,直到客户端或服务器决定将其关闭为止。
重用已对目标服务器打开的空闲持久连接, 就可以避开缓慢的连接建立阶段。而且,已经打开的连接还可以避免慢启动的拥塞适应阶段, 以便更快速地进行数据的传输。
Connection: Keep-Alive
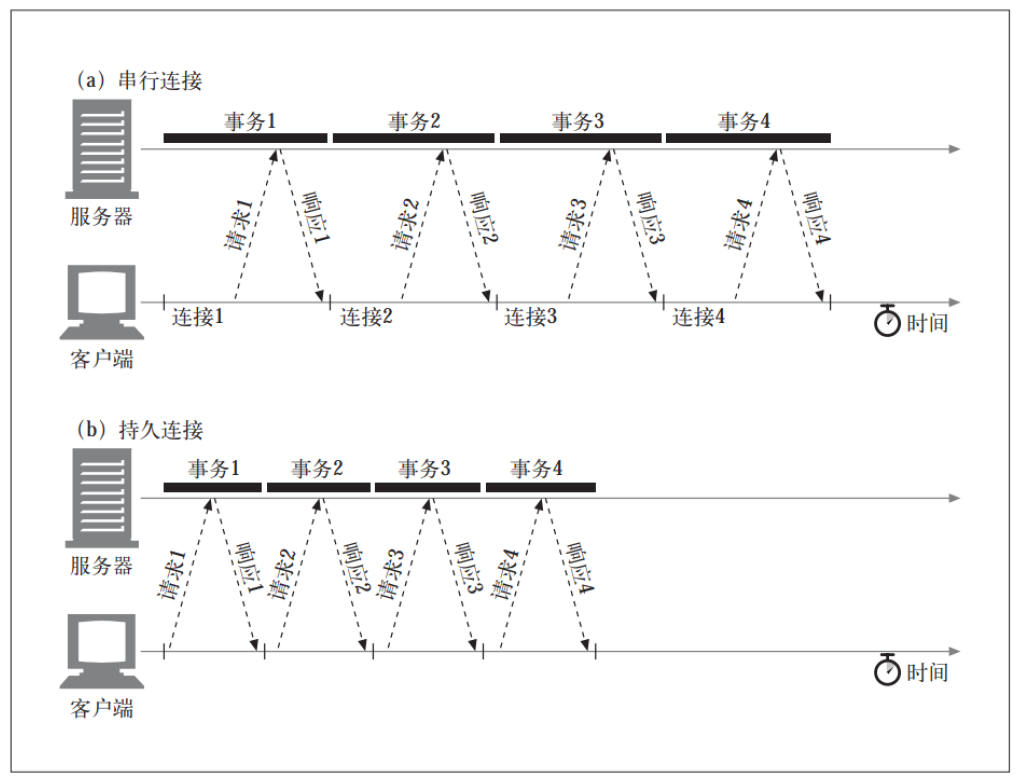
在持久连接中,每一个HTTP请求都是串行的。每个请求的发送都必须等待上一个请求的响应。
1.2.6 管道化连接
HTTP/1.1 允许在持久连接上使用管道化(pipeline)技术。 这是相对于 keepalive连接的又一性能优化。
在响应到达之前, 可以将多条请求放入队列。 当第一条请求通过网络流向另一端的服务器时, 第二条和第三条请求也可以开始发送了。 在高时延网络条件下, 这样做可以降低网络的环回时间, 提高性能。
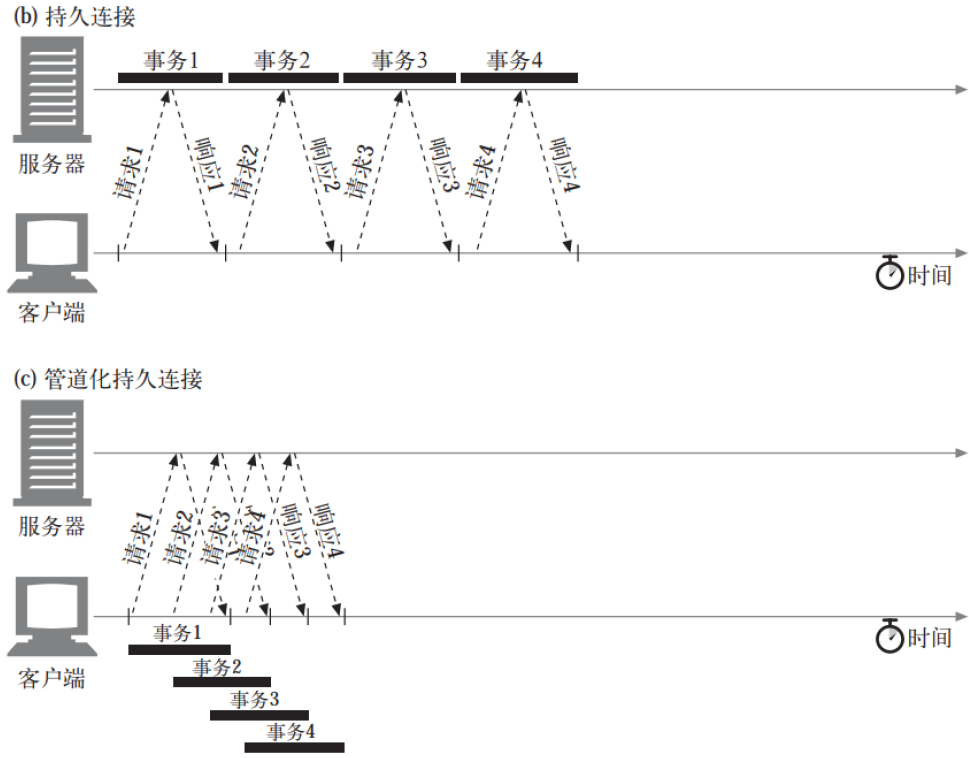
对管道化连接有几条限制:
- 必须按照与请求相同的顺序回送 HTTP 响应(如果顺序发送了请求1/2/3,那么无论服务器处理哪个请求更快,相应的时候必须按照请求的顺序响应)。 HTTP 报文中没有序列号标签, 因此如果收到的响应失序了, 就没办法将其与请求匹配起来了。此时容易引起一个问题:头部阻塞。
- HTTP 客户端必须做好连接会在任意时刻关闭的准备。 如果客户端打开了一条持久连接, 并立即发出了 10 条请求,服务器可能在只处理了5 条请求之后关闭连接,剩下的 5 条请求会失败,客户端必须能够应对这些过早关闭连接的情况, 重新发出这些请求。
- 只有幂等的请求能够被管线化。HTTP 客户端不应该用管道化的方式发送会产生副作用的请求(比如 POST)。 由于无法安全地重试 POST 这样的非幂等请求, 所以出错时, 就存在某些方法永远不会被执行的风险。
1.3 发展历程
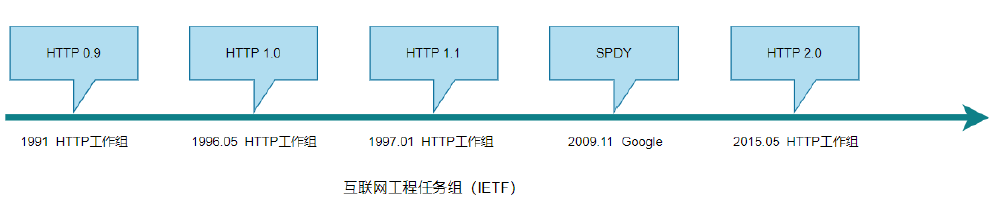
(1)HTTP/0.9:
-
只有一个命令 GET
-
没有HEADER等描述数据的信息
-
服务器发送完毕内容,就关闭TCP连接。一个HTTP事务要使用一个TCP连接。
(2)HTTP/1.0:
-
增加了很多命令
-
增加了status code (描述服务端处理请求的状态的)和 header
-
多字符集支持、多部分发送、权限、缓存等
-
缺陷:
第一点是: 连接无法实现真正意义上的复用(Connection :keep-Alive,默认false)
第二点是: Head-Of-Line Blocking(HOLB,队头/线头/头部阻塞)
(3)HTTP/1.1
-
持久连接/长连接
-
pipeline管道化技术
-
头部增加Host
(4)SPDY
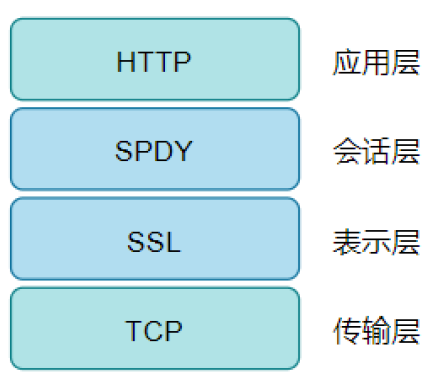
SPDY 没有完全改写 HTTP 协议,而是在 TCP/IP 的应用层与运输层之 间通过新加会话层的形式运作。同时考虑到安全性问题,SPDY 规定通信中使用 SSL。
SPDY 以会话层的形式加入,控制对数据的流动,但还是采用 HTTP 建立通信连接,改层工作在SSL层之上、HTTP层之下。
- 二进制分帧
- 首部压缩(Header Compression)
- 多路复用
- 对请求划分优先级
- 服务器推送流(即Server Push技术)
(5)HTTP/2
- 二进制分帧
- 首部压缩(Header Compression)
- 多路复用
- 对请求划分优先级
- 服务器推送流(即Server Push技术)
(6)HTTP Working-Group 以 SPDY/2 为基础,开发 HTTP/2。但是,HTTP/2跟 SPDY 仍有不同的地方,主要是以下两点:
- HTTP/2 支持明文 HTTP 传输,而 SPDY 强制使用 HTTPS
- HTTP/2 消息头的压缩算法采用 HPACK,而非 SPDY 采用的 DEFLATE
1.4 HTTP2新特性
- 对1.x协议语意的完全兼容
- 性能的大幅提升
1.4.1 二进制分帧(frame)
HTTP2.0性能增强的核心:二进制分帧。
HTTP 2.0最大的特点: 不会改动HTTP 的语义,HTTP 方法、状态码、URI 及首部字段,等等这些核心概念上一如往常,却能致力于突破上一代标准的性能限制,改进传输性能,实现低延迟和高吞吐量。而之所以叫2.0,是在于新增的二进制分帧层。
在二进制分帧层上,HTTP 2.0 会将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码 ,其中HTTP1.x的首部信息会被封装到Headers帧,而我们的request body则封装到Data帧里面。帧是数据传输的最小单位,以二进制传输代替原本的明文传输。
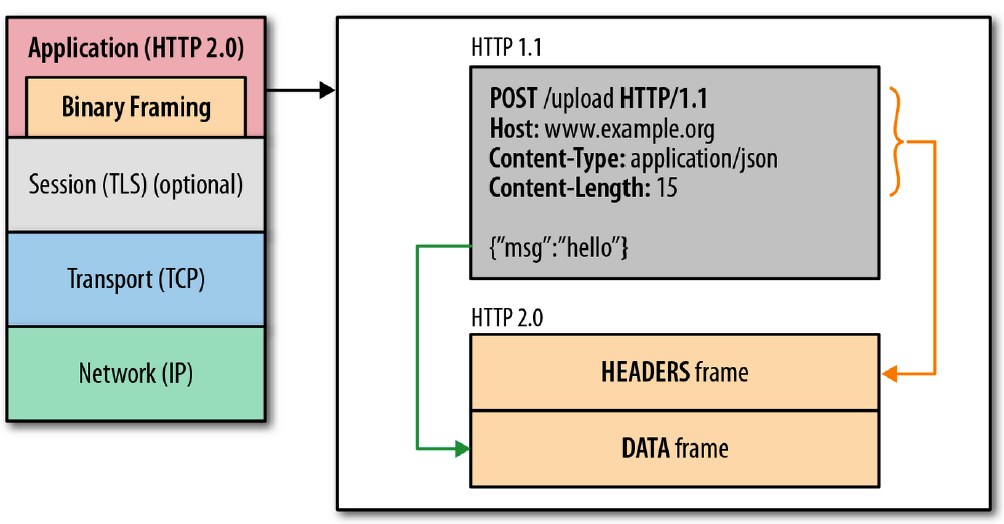
HTTP 2.0 所有的通信都在一个连接(TCP连接)上完成,这个连接可以承载任意数量的双向数据流。相应地,每个数据流以消息的形式发送,而消息由一或多个帧组成,这些帧可以乱序发送,然后再根据每个帧首部的流标识符重新组装。
**HTTP性能的关键在于低延迟而不是高带宽!**大多数HTTP 连接的时间都很短,而且是突发性的,但TCP 只在长时间连接传输大块数据时效率才最高。HTTP 2.0 通过让所有数据流共用同一个连接,可以更有效地使用TCP 连接,让高带宽也能真正的服务于HTTP的性能提升。
单连接多资源方式的好处:
- 可以减少服务连接压力,内存占用少了,连接吞吐量大了
- 由于 TCP 连接减少而使网络拥塞状况得以改观;
- 慢启动时间减少,拥塞和丢包恢复速度更快。
HTTP/2 的四个概念:
- Connection:1 个 TCP 连接,包含 1 个或者多个 stream。所有通信都在一个 TCP 连接上完成,此连接可以承载任意数量的双向数据流。
- Stream:一个双向通信的数据流,包含 1 条或者多条 Message。每个数据流都有一个唯一的标识符和可选的优先级信息,用于承载双向消息。流是连接中的一个虚拟信道,可以承载双向消息传输。每个流有唯一整数标识符。为了防止两端流ID冲突,客户端发起的流具有奇数ID,服务器端发起的流具有偶数ID。
- Message:消息是指逻辑上的HTTP消息(请求/响应)。一系列数据帧组成了一个完整的消息。比如一系列DATA帧和一个HEADERS帧组成了请求消息。
- Frame:最小通信单位,以二进制压缩格式存放内容。来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
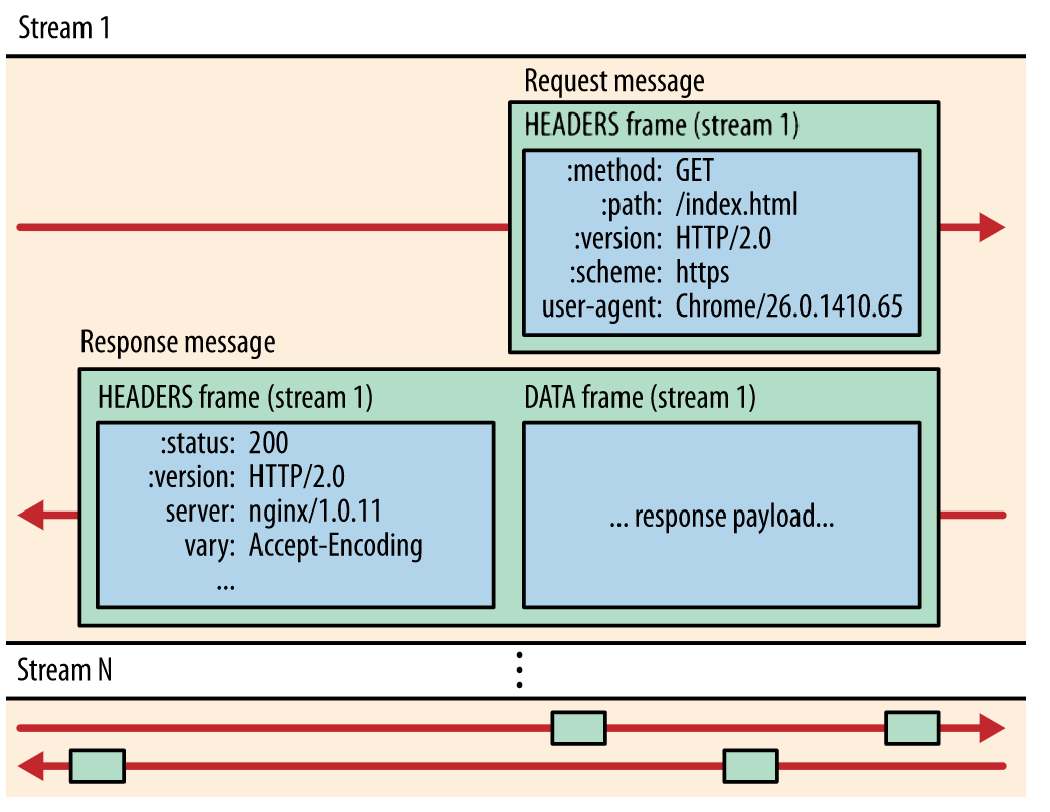
Frame 由 Frame Header 和 Frame Payload 两部分组成。所有帧都以固定的 9字节大小的头作为帧开始,后跟可变长度的有效载荷 payload。
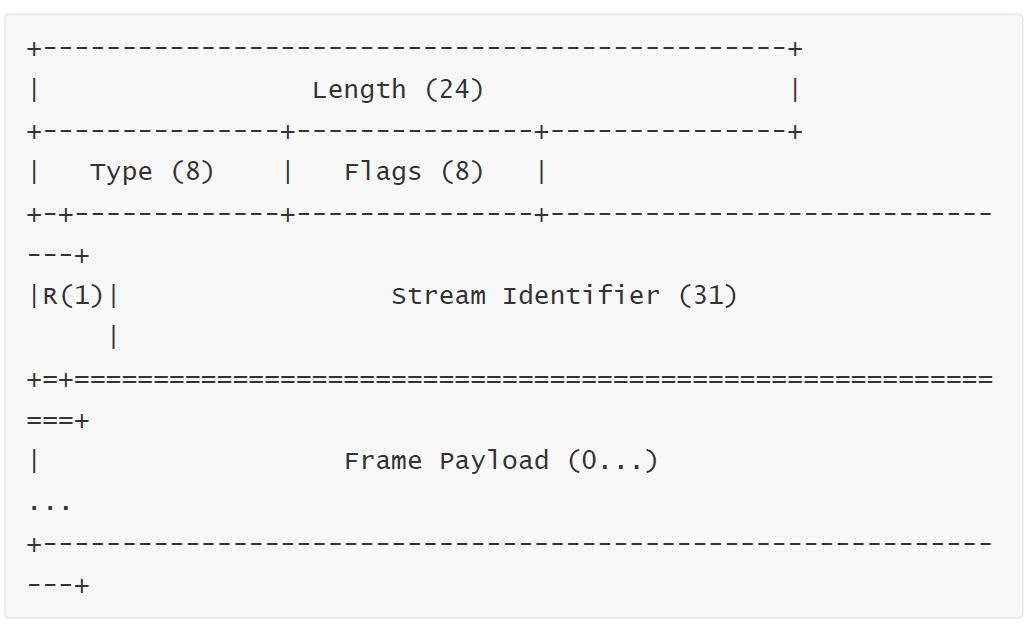
帧头的字段定义如下:
- Length:
帧有效负载的长度(数据的长度,不包含头部),注意:帧头的 9 个八位字节不包含在此长度值中。 - Type:
这 8 位用来表示帧类型的。帧类型确定帧的格式和语义。实现方必须忽略并丢弃任何类型未知的帧。
bash
DATA: 用于传输HTTP消息体
HEADERS:用户传输关于流的额外的首部字段
PRIORITY:用户指定或者重新指定引用资源的优先级
RST_STRING:用于通知流的非正常终止
SETTINGS:用于通知两端通信方式的数据配置
PUSH_PROMISE:用于发出创建流和服务器引用资源的要约
PING:用于计算往返时间,执行"活性"检查
GOAWAY:用于通知对端停止在当前连接的创建流
WINDOW_UPDATE:用于针对个别流或个别连接实现流量控制
CONTINUATION:用于继续一系列首部块片段- Flags:
标志位,常用的标志位有 END_HEADERS 表示头数据结束,相当于 HTTP/1里头后的空行("\r\n")。 - R:
保留的 1 位。该位的语义未定义,发送时必须保持未设置 (0x0),接收时必须忽略。 - Stream Identifier:
流标识符,表示为无符号 31 位整数。由客户端发起的流必须使用奇数编号的流标识符;那些由服务器发起的必须使用偶数编号的流标识符。DATA 帧必须与某一个流相互关联。
stream ID 的作用:
1.实现多路复用的关键。接收端的实现可以根据这个 ID 并发、组装消息。同一个 stream 内 frame 必须是有序的。
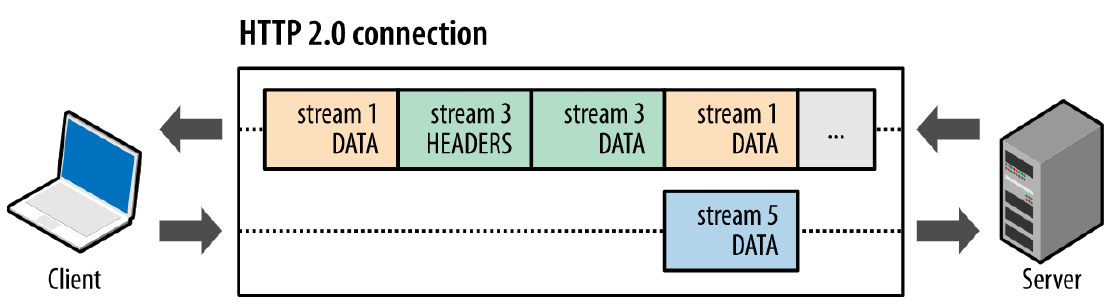
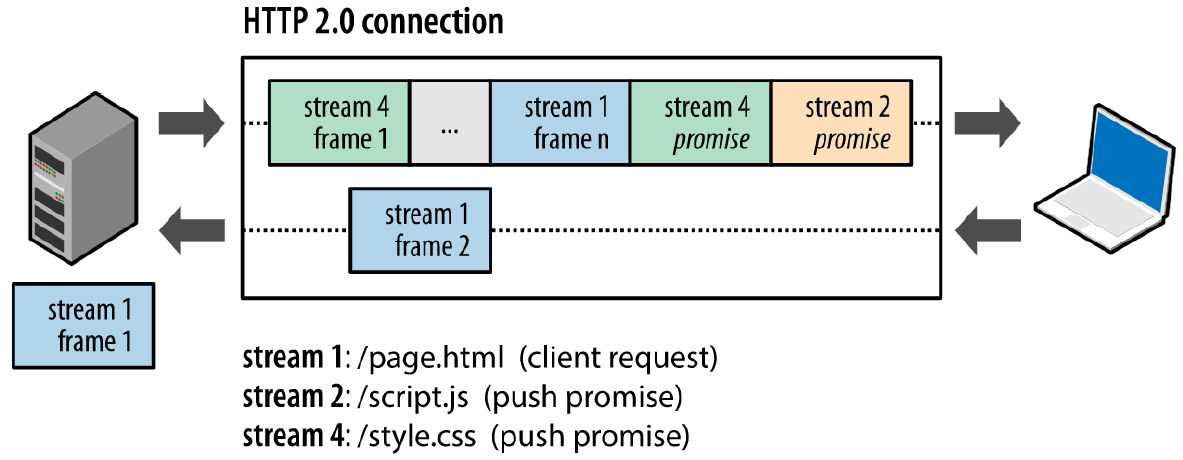
2.推送依赖性请求的关键。客户端发起的流是奇数编号,服务端发起的流是偶数编号。
1.4.2 头部压缩(HPACK)
为什么要压缩?
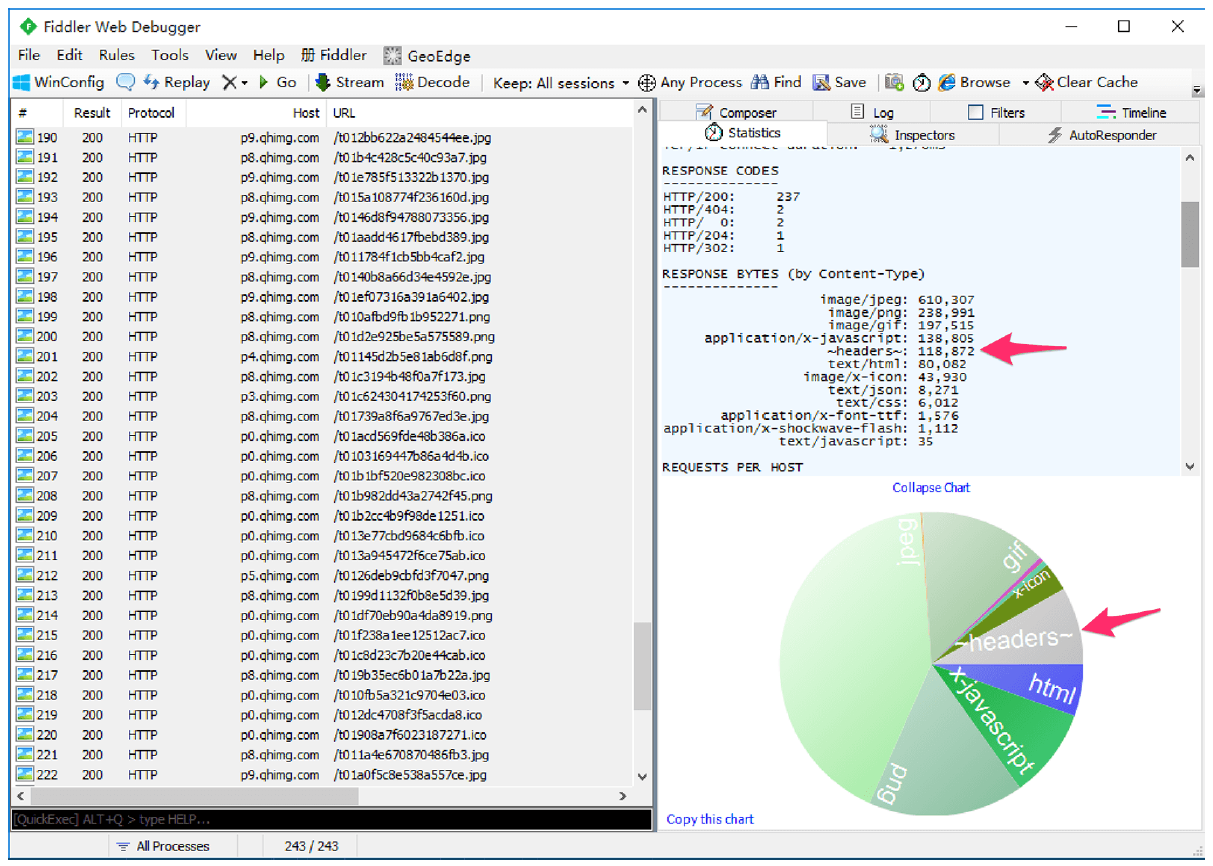
在 HTTP/1 中,HTTP 请求和响应都是由「状态行、请求 / 响应头部、消息主体」三部分组成。一般而言,消息主体都会经过 gzip 压缩,或者本身传输的就是压缩过后的二进制文件(例如图片、音频),但状态行和头部却没有经过任何压缩,直接以纯文本传输。
根据 HTTP Archive 的统计,当前平均每个页面都会产生上百个请求。越来越多的请求导致消耗在头部的流量越来越多,尤其是每次都要传输 UserAgent、Cookie 这类不会频繁变动的内容,完全是一种浪费。
以下是我随手打开的一个页面的抓包结果。可以看到,传输头部的网络开销超过 100kb,比 HTML 还多:
HTTP/2协议中定义了 HPACK,这是一种新的压缩方法,它消除了多余的header 字段,将漏洞限制到已知的安全攻击,并且在受限的环境中具有有限的内存需求。HPACK 格式特意被设计成简单且不灵活的形式:两种特性都降低了由于实现错误而引起的互操作性或安全性问题的风险;没有定义扩展机制,只能通过定义完整的替换来更改格式。
需要注意的是,http 2.0关注的是首部压缩,而我们常用的gzip等是报文内容(body)的压缩,二者不仅不冲突,且能够一起达到更好的压缩效果。
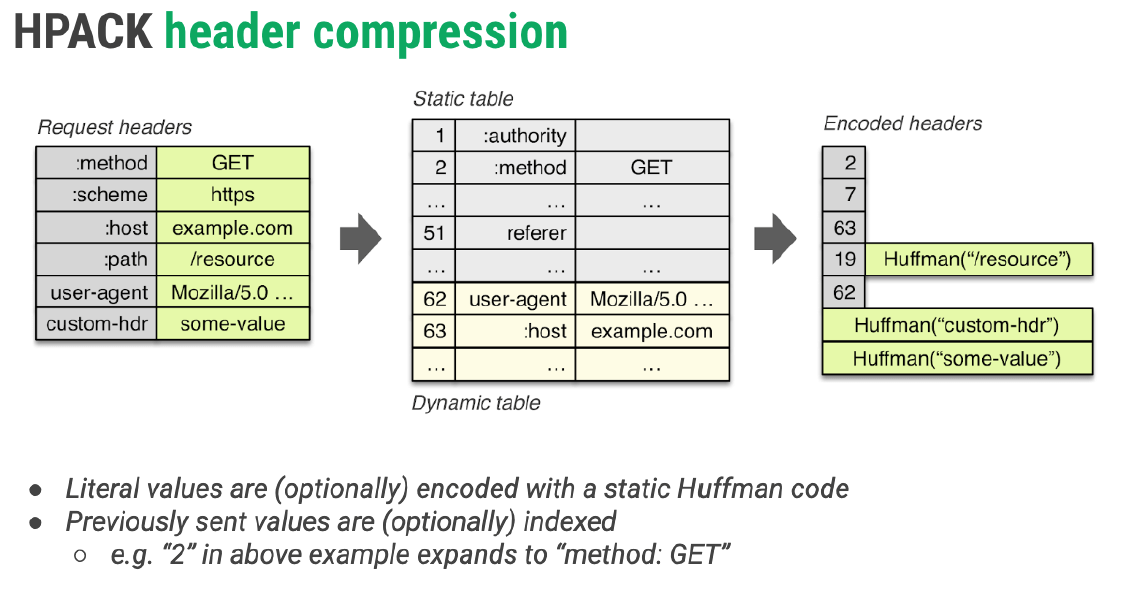
(1)如何进行头部压缩
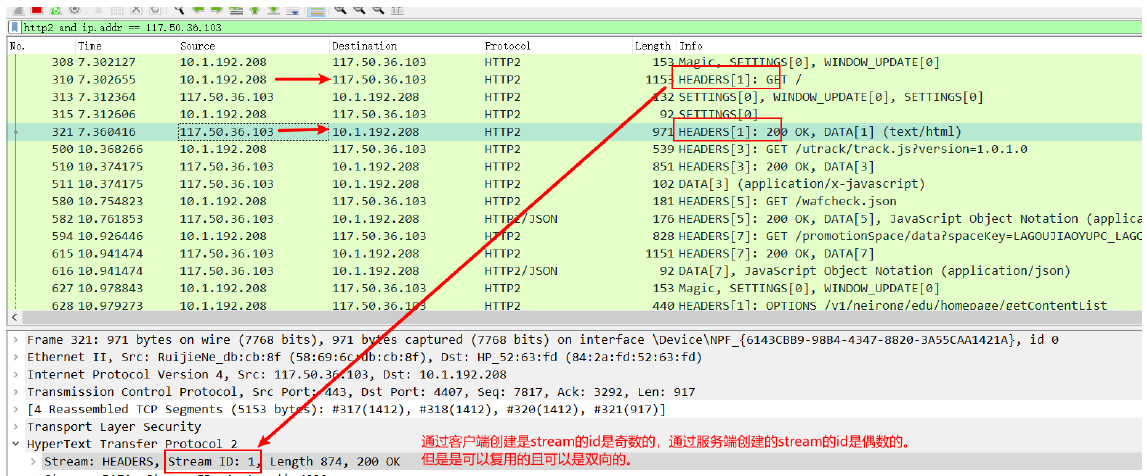
简单说,HPACK头部压缩需要在支持 HTTP/2 的浏览器和服务端之间:
- 维护一份相同的静态表(Static Table),包含常见的头部名称,以及常见的头部名称与值的组合(静态表内容共61项,索引号1-61);
- 维护一份相同的动态表(Dynamic Table),当一个header name 或者header value在静态表中不存在,会被插入动态表中,可以动态地添加内容(动态表索引从62开始);
○ 客户端和服务端会共同维护一份动态表
○第一次发送的时候需要明文发送(要经过Huffman编码),第二次及第N次发送索引号 - 对不存在的头部使用哈夫曼编码(Huffman Coding),并动态缓存到索引(动态表)
(2)静态表
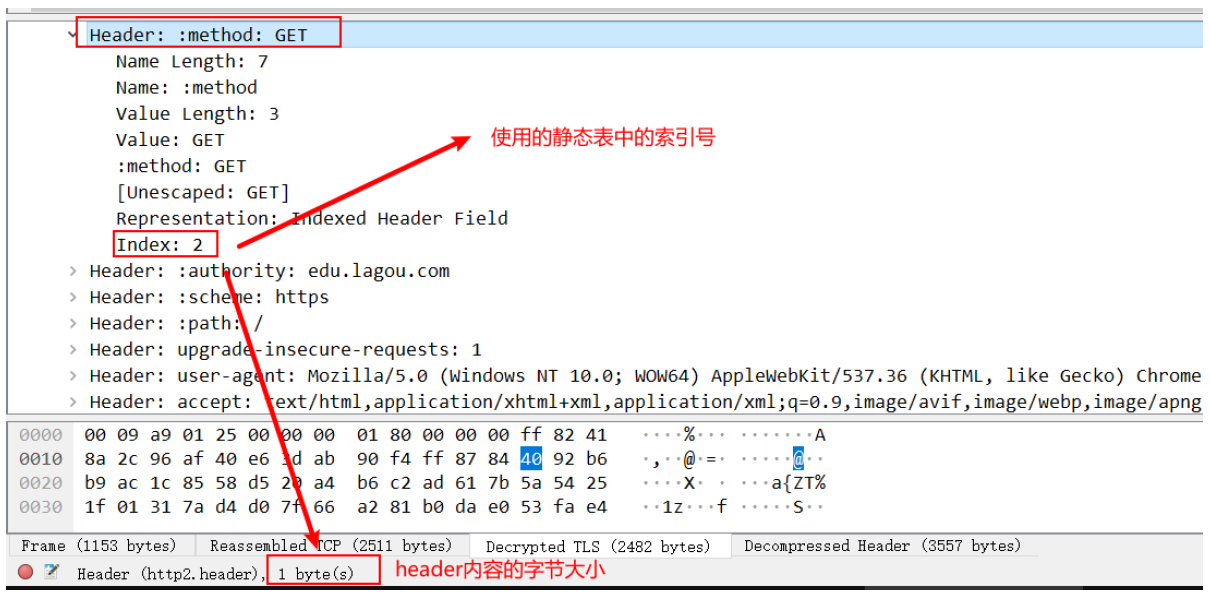
一个预定义且不可更改的 header 字段列表。先定义好的内容,只有固定的几十个值,如果要发送的值符合静态表时,用对应的 Index 替换即可,这样就大大压缩了头部的大小,如果遇到不在静态表中的值,就会用到动态表。
bash
+-------+-----------------------------+---------------+
| Index | Header Name | Header Value |
+-------+-----------------------------+---------------+
| 1 | :authority | |
| 2 | :method | GET |
| 3 | :method | POST |
| 4 | :path | / |
| 5 | :path | /index.html |
| 6 | :scheme | http |
| 7 | :scheme | https |
| 8 | :status | 200 |
| 9 | :status | 204 |
| 10 | :status | 206 |
| 11 | :status | 304 |
| 12 | :status | 400 |
| 13 | :status | 404 |
| 14 | :status | 500 |
| 15 | accept-charset | |
| 16 | accept-encoding | gzip, deflate |
| 17 | accept-language | |
| 18 | accept-ranges | |
| 19 | accept | |
| 20 | access-control-allow-origin | |
| 21 | age | |
| 22 | allow | |
| 23 | authorization | |
| 24 | cache-control | |
| 25 | content-disposition | |
... ...
| 60 | via | |
| 61 | www-authenticate | |
+-------+-----------------------------+---------------+
(3)动态索引
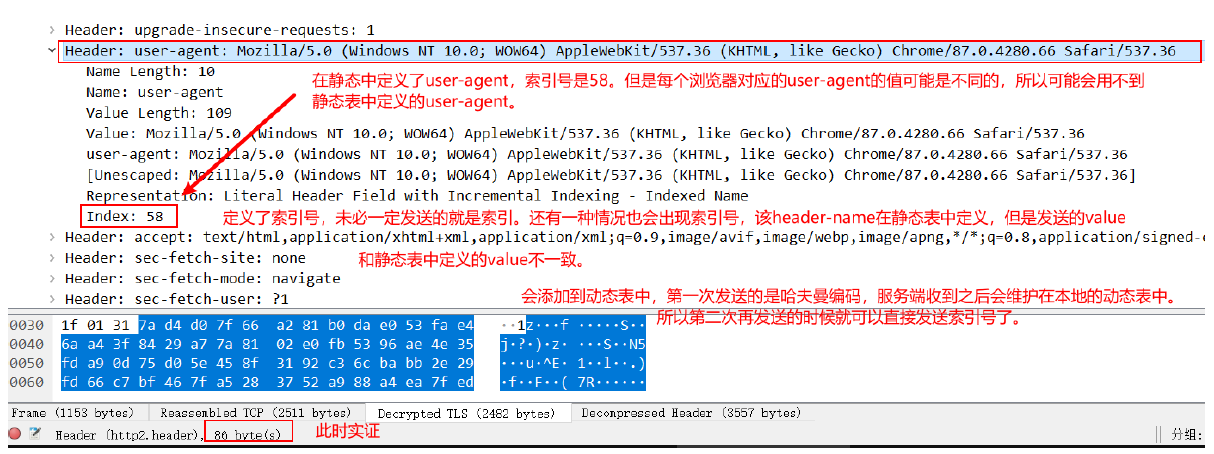
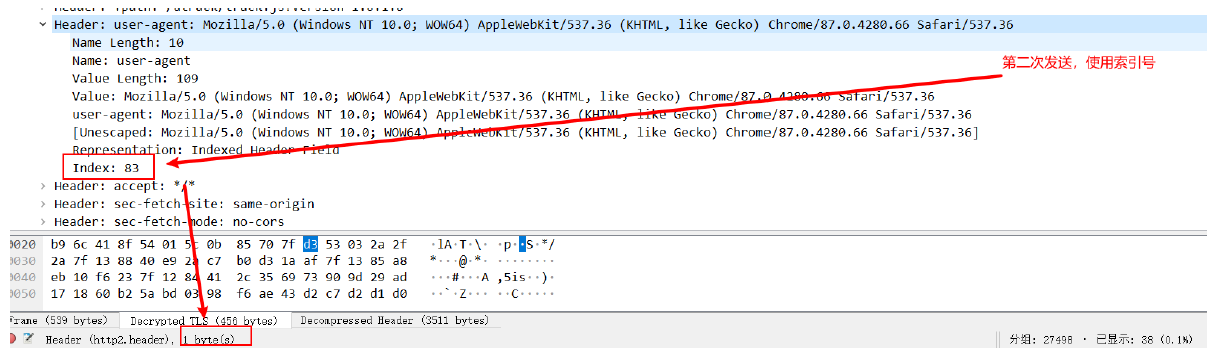
- 动态表是一个由先进先出的队列维护的有空间限制的表,同样维护的是头部与对应的索引。
- 每个动态表只针对一个连接(TCP),每个连接的压缩解压缩的上下文有且仅有一个动态表。
- 那么动态表就是,当一个头部没有出现过的时候,会把他插入动态表中,索引从62开始。
1.4.3 多路复用(Multiplexing)
http1.1中,浏览器客户端在同一时间,针对同一域名下的请求有一定数量的限制,超过限制数目的请求会被阻塞。这也是为何一些站点会有多个静态资源CDN 域名的原因之一。
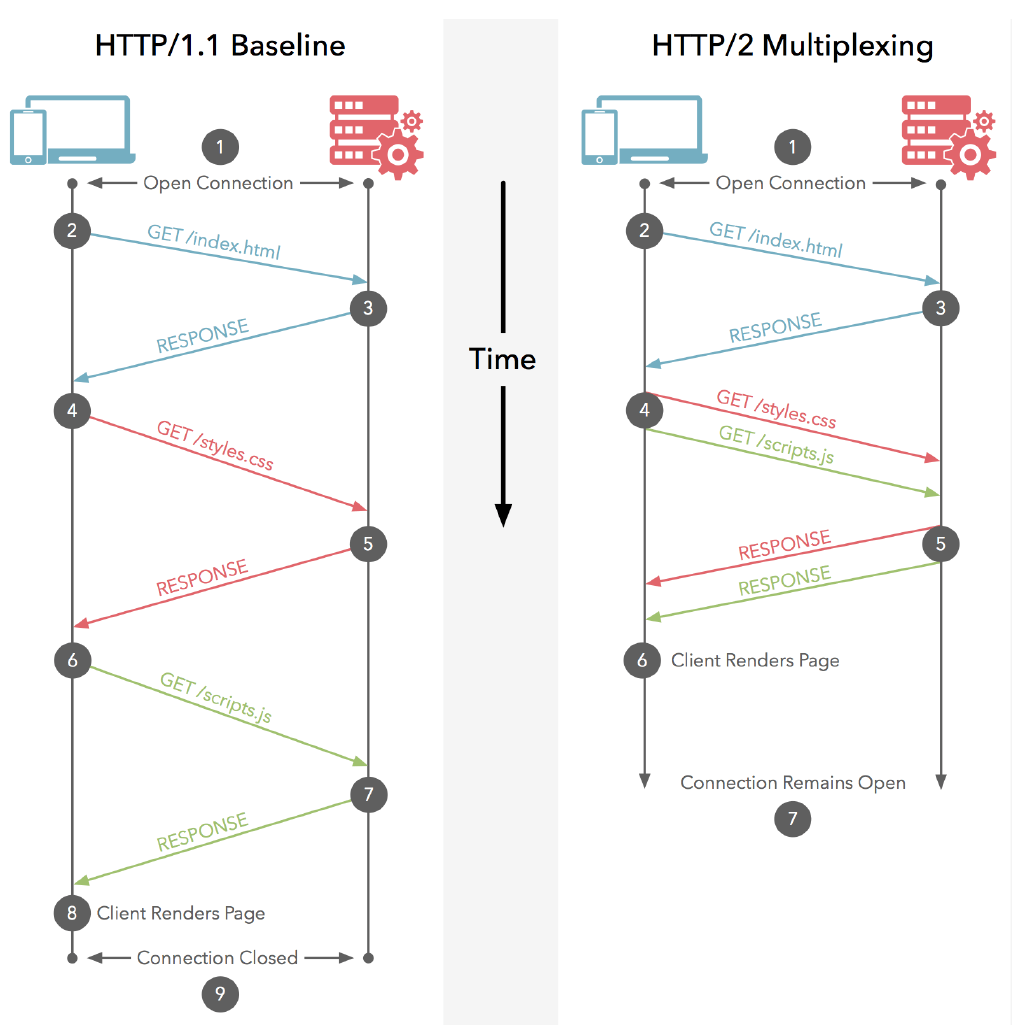
http 2.0 连接都是持久化的,而且客户端与服务器之间也只需要一个连接(每个域名一个连接)即可。http2连接可以承载数十或数百个流的复用,多路复用意味着来自很多流的数据包能够混合在一起通过同样连接传输。当到达终点时,再根据不同帧首部的流标识符重新连接将不同的数据流进行组装。
websocket 原生协议由于没有这个 stream ID 类似的字段,所以它原生不支持多路复用。在同一个 stream 内部的 frame 由于没有其他的 ID 编号了,所以无法乱序,必须有序,无法并发。
单个 HTTP/2 连接可以包含多个并发打开的 stream 流,任一一个端点都可
能交叉收到来自多个 stream 流的帧。
- stream 流可以单方面建立和使用,也可以由客户端或服务器共享。任何一个端都可以关闭 stream 流。
- 在 stream 流上发送帧的顺序非常重要。收件人按照收到的顺序处理帧。特别是,HEADERS 和 DATA 帧的顺序在语义上是重要的。
- stream 流由整数标识。stream 流标识符是由发起流的端点分配给 stream流的。
1.4.4 服务器推送(Server Push)
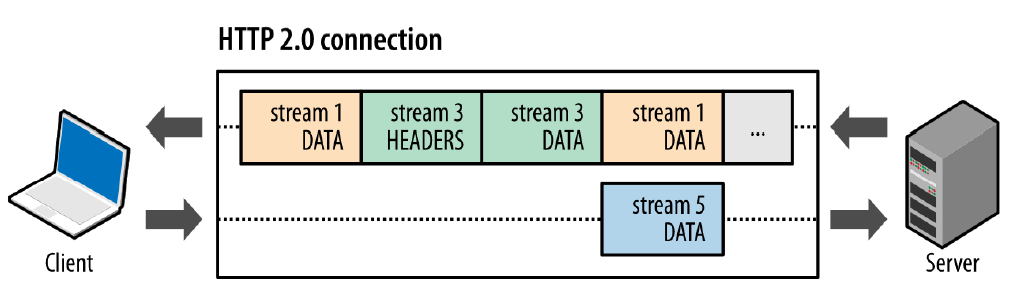
服务器可以对一个客户端请求发送多个响应,服务器向客户端推送资源无需客户端明确地请求。并且,服务端推送能把客户端所需要的资源伴随着index.html一起发送到客户端,省去了客户端重复请求的步骤。
正因为没有发起请求,建立连接等操作,所以静态资源通过服务端推送的方式可以极大地提升速度。Server Push 让 http1.x 时代使用内嵌资源的优化手段变得没有意义;如果一个请求是由你的主页发起的,服务器很可能会响应主页内容、logo 以及样式表,因为它知道客户端会用到这些东西,这相当于在一个HTML 文档内集合了所有的资源。
不过与之相比,服务器推送还有一个很大的优势:可以缓存!也让在遵循同源的情况下,不同页面之间可以共享缓存资源成为可能。
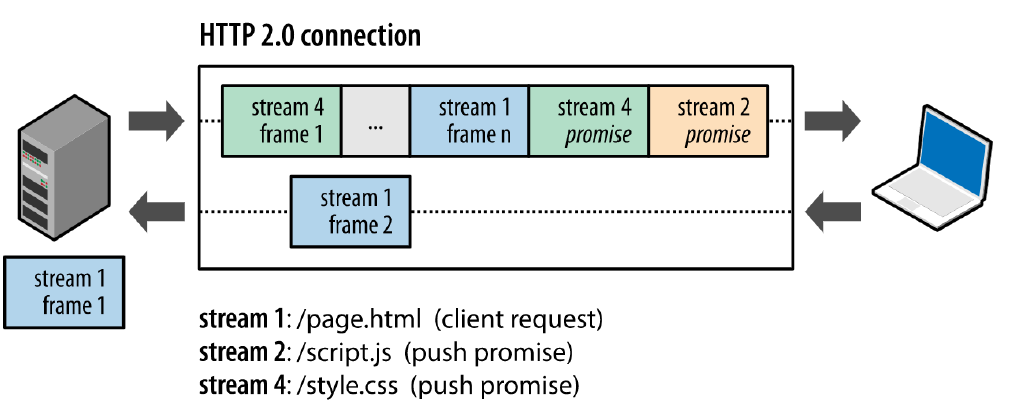
注意两点:
1、推送遵循同源策略;
2、这种服务端的推送是基于客户端的请求响应来确定的。
当服务端需要主动推送某个资源时,便会发送一个 Frame Type 为 PUSH_PROMISE 的 Frame,里面带了 PUSH 需要新建的 Stream ID。意思是告诉客户端:接下来我要用这个 ID 向你发送东西,客户端准备好接着。客户端解析 Frame 时,发现它是一个 PUSH_PROMISE 类型,便会准备接收服务端要推送的流。
1.4.5 http2.0性能瓶颈
启用http2.0后会给性能带来很大的提升,但同时也会带来新的性能瓶颈。因为现在所有的压力集中在底层一个TCP连接之上,TCP很可能就是下一个性能瓶颈,比如单个TCP packet丢失导致整个连接阻塞,无法逃避,此时所有消息都会受到影响。
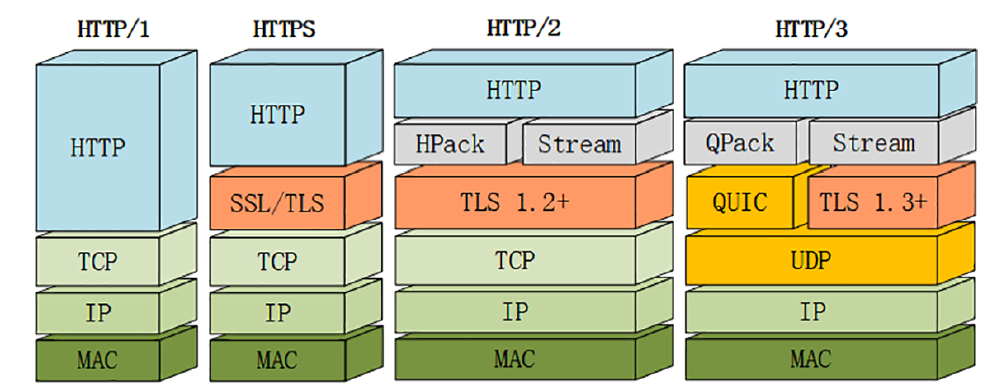
注:QUIC协议代替TCP协议中关于可靠、流量控制的部分
1.4.6 安全风险
- 窃听风险:通信使用明文,明文报文不具备保密性,内容可能被窃听
- 冒充风险:不验证通信方的身份(不进行身份验证),有可能遇到伪装
- 篡改风险:无法证明报文的完整性,有可能已遭篡改
2 HTTPS
2.1 概念
HTTPS(HyperText Transfer Protocol over Secure Socket Layer)超文本传输安全协议, 近两年Google、Baidu、Facebook 等这样的互联网巨头,不谋而合地开始大力推行 HTTPS, 国内外的大型互联网公司很多也都已经启用了全站 HTTPS,这也是未来互联网发展的趋势。
为鼓励全球网站的 HTTPS 实现,一些互联网公司都提出了自己的要求:
- Google 已调整搜索引擎算法,让采用 HTTPS 的网站在搜索中排名更靠前;
- 从 2017 年开始,Chrome 浏览器已把采用 HTTP 协议的网站标记为不安全网站;
- 苹果要求 2017 年 App Store 中的所有应用都必须使用 HTTPS 加密连接;
- 当前国内炒的很火热的微信小程序也要求必须使用 HTTPS 协议;
- 新一代的 HTTP/2 协议的支持需以 HTTPS 为基础。
因此在不久的将来,全网 HTTPS 势在必行。
(1)作用
- 对数据进行加密,并建立一个信息安全通道,来保证传输过程中的数据安全;
- 对网站服务器进行真实身份认证。
(2)使用特征
我们经常会在Web的登录页面和购物结算界面等使用HTTPS通信。
使用HTTPS通信时,不再用http:// ,而是改用https:// 。另外,当浏览器访问HTTPS通信有效的Web网站时,浏览器的地址栏内会出现一个带锁的标记。
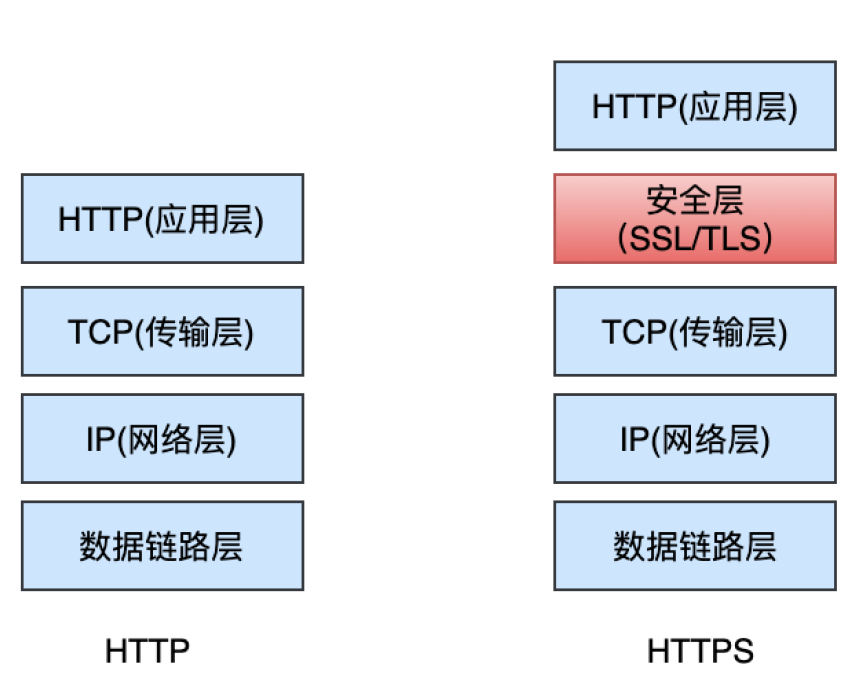
2.2 架构图
HTTPS并非是应用层一个新的协议,通常 HTTP 直接和 TCP 通信,HTTPS则先和安全层(SSL/TLS)通信,然后安全层再和 TCP 层通信。
SSL/TLS协议就是为了解决上面提到的HTTP存在的问题而生的,下面我们来看一下它是怎么解决的:
- 所有的信息都是加密传输的,第三方无法窃听
- 配备身份验证(服务端程序),防止身份被冒充
- 具有校验机制,一旦被篡改,通信双方会立刻发现
2.3 HTTPS工作原理
HTTPS是身披SSL/TLS外壳的HTTP
TLS全称传输层安全协议Transport Layer Security Protocol,TLS/SSL是一种加密通道的规范。
| 协议版本 | 描述 |
|---|---|
| SSL 1.0 | 存在严重的安全漏洞,从未公开过 |
| SSL 2.0 | 2.0版本在1995年2月发布,但因为存在数个严重的安全漏洞而被 3.0版本替代 |
| SSL 3.0 | 3.0版本在1996年发布 |
| TLS 1.0 | IETF对SSL3.0进行了标准化,并添加了少数机制(但是几乎和 SSL3.0无差异) |
| TLS 1.1 | LS 1.1在RFC 4346中定义,于2006年4月发表 |
| TLS 1.2 | TLS 1.2在RFC 5246中定义,于2008年8月发表 |
| TLS 1.3 | TLS 1.3在RFC 8446中定义,于2018年8月发表 |
TLS协议是由TLS记录协议(TLS record Protocol)和TLS握手协议(TLS handshake Protocol)这两层协议叠加而成的。
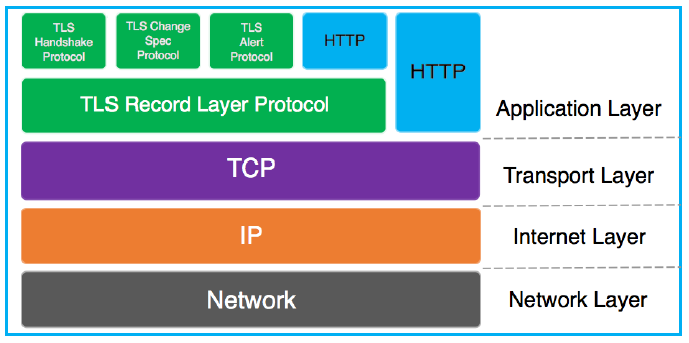
- 记录协议:TLS Record protocol
○ TLS记录协议位于TLS握手协议的下层,是负责使用对称密码对消息进行加密通信的部分
○ 加密使用的密钥是通过握手协议在服务器和客户端之间协商决定的 - 握手协议:TLS Handshaking Protocols由TLS Change Ciper Spec Protocol(密码规格变更协议)和TLS Alert Protocol(警告协议)组成
○ 负责在客户端和服务器之间协商决定密码算法和共享密钥。
○ 密码规格变更协议负责向通信对象传达变更密码方式的信号,当协议中途发生错误时, 就会通过警告协议传达给对方。
○ 警告协议是TLS握手协议负责在发送错误时将错误传达给对方。
HTTPS和HTTP协议相比提供了
- 数据完整性:内容传输经过完整性校验
- 数据隐私性:内容经过对称加密,每个连接生成一个唯一的加密密钥
- 身份认证:第三方无法伪造服务端(客户端)身份
其中,数据完整性和隐私性由TLS Record Protocol保证,身份认证由TLS Handshaking Protocols实现。
理解HTTPS前需要理解这些概念:对称加密、非对称加密、摘要算法、数字签名、证书、认证中心(CA - Certificate Authority)
2.3.1 对称加密算法
(1)定义:
采用单钥密码系统的加密方法,同一个密钥可以同时用作信息的加密和解密,这种加密方法称为对称加密,也称为单密钥加密。
(2)要素:
原文、秘钥、算法
秘钥:在密码学中是一个定长的字符串、需要根据加密算法确定其长度
(3)工作过程:
对称加密通常使用的是相对较小的密钥,一般小于256 bit。因为密钥越大,加密越强,但加密与解密的过程越慢。如果你只用1 bit来做这个密钥,那黑客们可以先试着用0来解密,不行的话就再用1解;但如果你的密钥有1 MB大,黑客们可能永远也无法破解,但加密和解密的过程要花费很长的时间。密钥的大小既要照顾到安全性,也要照顾到效率。
bash
加密:明文 + 密钥 -> 密文
解密:密文 + 密钥 -> 明文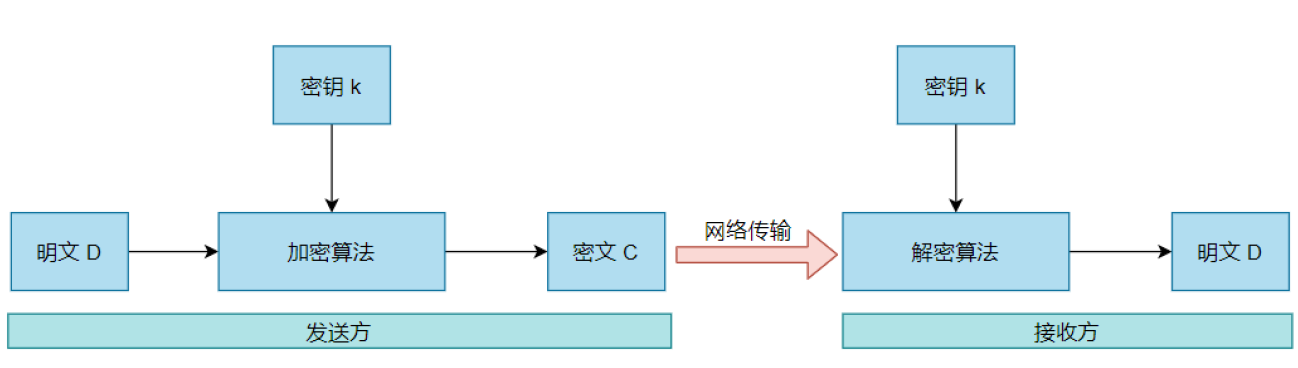
(4)算法
DES(Data Encryption Standard):数据加密标准(现在用的比较少,因为它的加密强度不够,能够暴力破解)
3DES:原理和DES几乎是一样的,只是使用3个密钥,对相同的数据执行三次加密,增强加密强度。(缺点:要维护3个密钥,大大增加了维护成本)
AES(Advanced Encryption Standard):高级加密标准,用来替代原先的DES,目前美国国家安全局使用的,苹果的钥匙串访问采用的就AES加密。是现在公认的最安全的加密方式,是对称密钥加密中最流行的算法。
AES128和AES256主要区别是密钥长度不同(分别是128bits,256bits)、加密处理轮数不同(分别是10轮,14轮),后者强度高于前者。
(5)特点
优点:算法公开、计算量小、加密速度快、加密效率高。
缺点:相对来说不算特别安全,只有一把钥匙,密文如果被拦截,且密钥也被劫持,那么,信息很容易被破译。
(6)推演
为了防止上述现象的发生,人们想到一个办法:对传输的信息加密(即使黑客截获,也无法破解)
加密公式: f1 ( key(密钥),data ) = X(密文)
解密公式: f2 ( key(密钥),X(密文) ) = data

缺陷:
加密和解密同用一个密钥,加密和解密都会用到密钥,没有密钥就无法对密码解密,反过来说,任何人只要持有密钥就能解密。
改进:比如服务器为每一个客户端请求的TCP连接生成一个唯一的key

缺陷:
不同的客户端、服务器数量庞大,所以双方都需要维护大量的密钥,维护成本很高
因每个客户端、服务器的安全级别不同,密钥极易泄露
2.3.2 非对称加密算法
(1)简介:
非对称加密是计算机通信安全的基石,保证了加密数据不会被破解。
非对称加密算法需要两个密钥:公开密钥(public key) 和私有密(private key)公开密钥和私有密钥是一对
(2)特点:
如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密。
如果用私有密钥对数据进行加密,只有用对应的公开密钥才能解密。
由于其算法复杂,而使得加密、解密速度没有对称加密解密的速度快。有两种密钥,其中一个是公开的,这样就可以不需要像对称密码那样传输对方的密钥了,这样安全性就大了很多。
(3)常用算法:
RSA、DSA、ECDSA
(4)推演 - 非对称加密
公钥加密:f1 ( publicKey,data ) = X
私钥解密:f2 ( privateKey,X ) = data
私钥加密:f3 ( privateKey,data) = X
公钥解密:f1 ( publicKey,X) = data
私钥保存在服务端,公钥保存在客户端,私钥永远不对外暴露
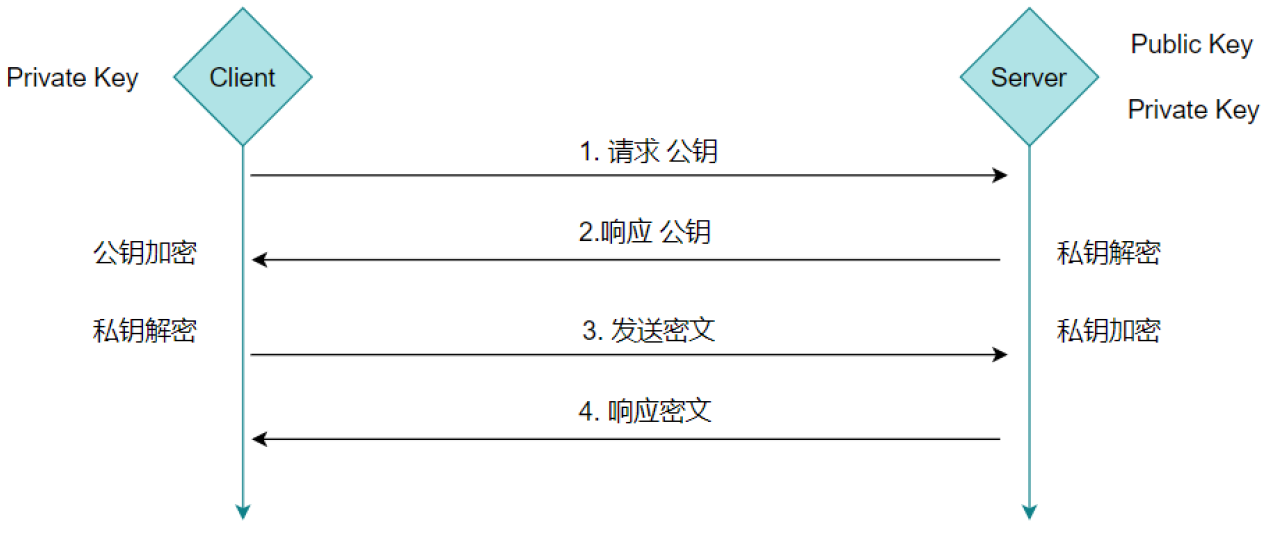
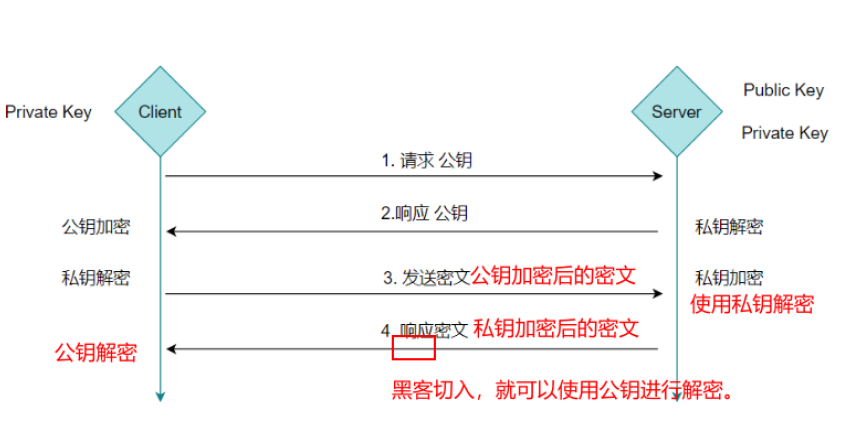
缺陷:
公钥是公开的(也就是黑客也会有公钥),所以第 ④ 步私钥加密的信息,如果被黑客截获,其可以使用公钥进行解密,获取其中的内容。
(5)推演 - 对称加密和非对称加密
非对称加密既然也有缺陷,那我们就将对称加密,非对称加密两者结合起来,取其精华、去其糟粕,发挥两者的各自的优势。
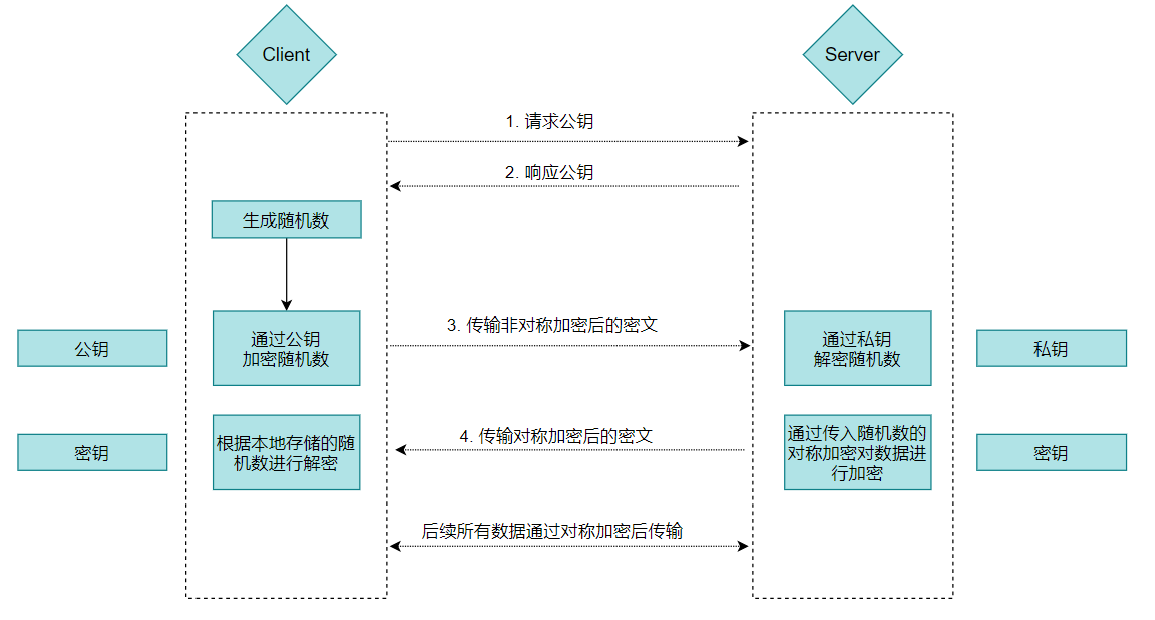
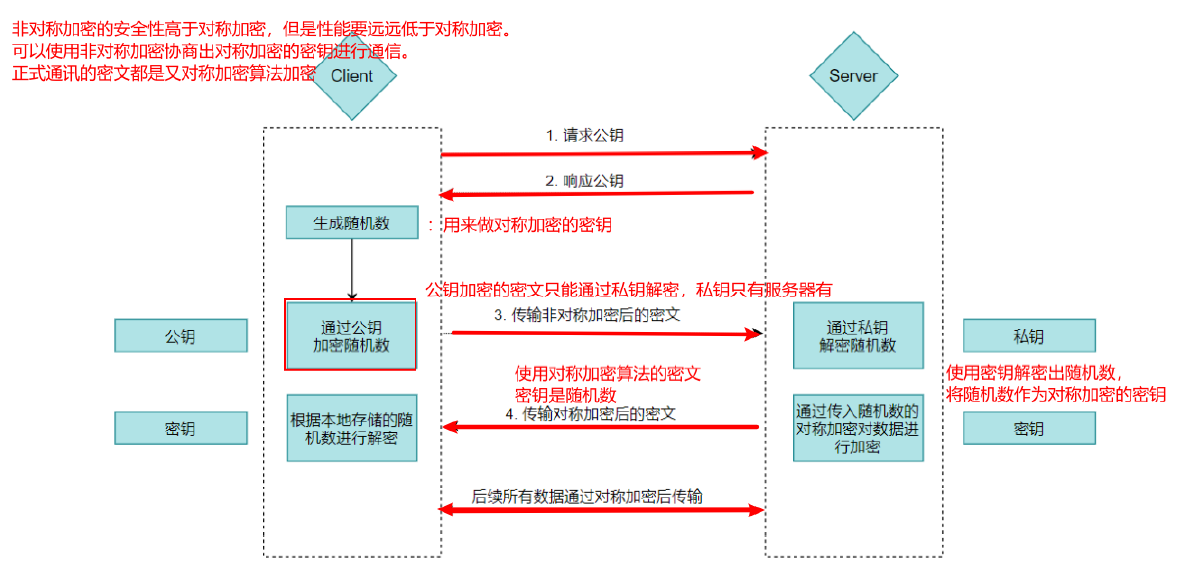
解决问题:
通过对称加密和非对称加密的组合使用,解决内容可能被窃听的问题
存在缺陷:
解决报文可能遭篡改问题
解决通信方身份可能被伪装的问题
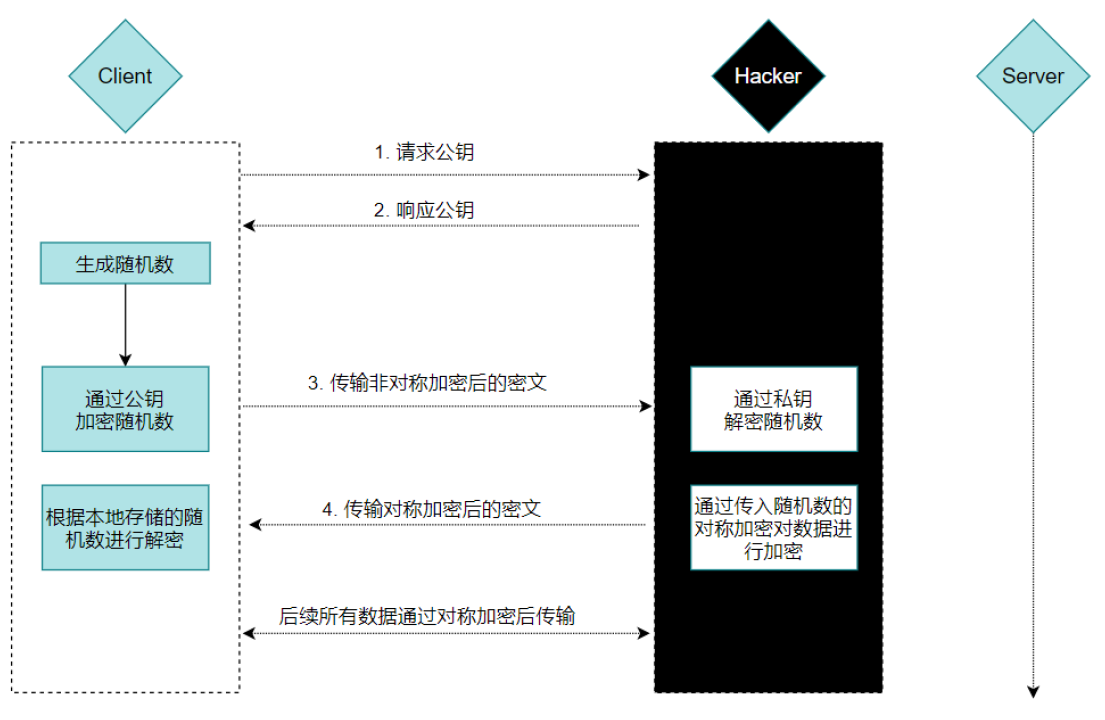
解决方案:
解决报文可能遭篡改问题------数字签名
解决通信方身份可能被伪装的问题------数字证书
2.3.3 数字签名
(1)数字签名有两种功能:
能确定消息确实是由发送方签名并发出来的,因为别人假冒不了发送方的签名。
数字签名能确定消息的完整性,证明数据是否未被篡改过。
(2)数字签名如何生成
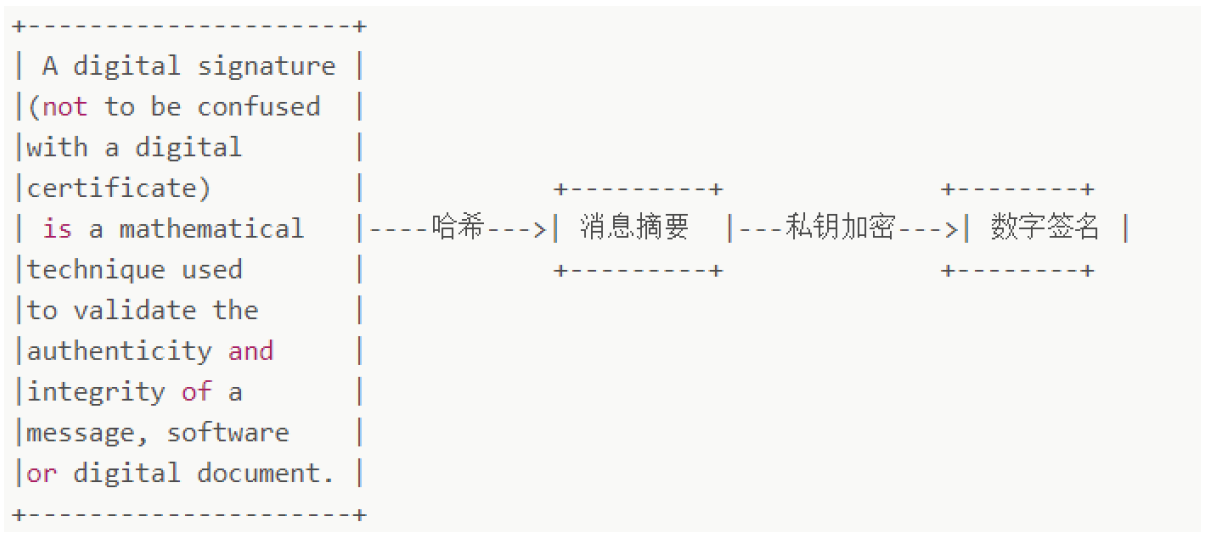
将要发送的数据先用Hash算法(摘要算法、散列算法)生成消息摘要,然后用发送者的私钥加密生成数字签名,与原文一起传送给接收者。
接下来就是接收者校验数字签名的流程了。
(3)校验数字签名流程

接收者只有用发送者的公钥才能解密被加密的摘要信息,然后用HASH函数对收到的原文产生一个摘要信息,与上一步得到的摘要信息对比。如果相同,则说明收到的信息是完整的,在传输过程中没有被修改,否则说明信息被修改过,因此数字签名能够验证信息的完整性。
假设消息传递在客户端、服务器之间发生。
服务器将消息连同数字签名一起发送给客户端
客户端接收到消息后,通过校验数字签名,就可以验证接收到的消息就是服务器发送的。
问题:
这个过程的前提是客户端知道服务器的公钥。问题的关键的是,和消息本身一样,公钥不能在不安全的网络中直接发送给客户端,或者说拿到的公钥如何证明是服务器的。此时就需要引入了证书颁发机构(Certificate Authority,简称CA),CA数量并不多,客户端内置了所有受信任CA的证书。
消息摘要算法分为三类:
- MD(Message Digest):消息摘要算法
- SHA(Secure Hash Algorithm):安全散列算法
- MAC(Message Authentication Code):消息认证码
2.3.4 证书
数字证书:是一个经证书认证结构数字签名的包含公开密钥、拥有者信息的文件,有点像生活中的身份证、护照等,是由一个官方的证书颁发机构签发的一组数据。这种证书很难伪造,用于使用者的身份证明。
实际上,我们使用的证书分很多种类型,SSL证书只是其中的一种,SSL证书负责传输公钥。 我们常见的证书根据用途不同大致有以下几种:
- SSL证书,用于加密HTTP协议,也就是HTTPS,TLS。如果一个web应用想要升级为https,需要购买证书。
- 代码签名证书,用于签名二进制文件,比如Windows内核驱动,Firefox插件,Java代码签名等等
- 客户端证书,用于加密邮件
- 双因素证书,网银专业版使用的USB Key里面用的就是这种类型的证书
证书中包含:组织信息、域名信息、公钥(比如拉勾教育的公钥)、证书有效期等信息。
认证过程(升级HTTPS):
- 服务器的运营人员(拉勾网站的运营)向第三方机构CA(或者其代理机构)提交公钥、组织信息、域名等信息并申请认证;
- CA通过线上、线下等多种手段验证申请者提供信息的真实性,如组织是否存在、企业是否合法,是否拥有域名的所有权等;
- 如信息审核通过,CA会向申请者签发认证文件-证书。
证书包含以下信息:
申请者公钥(如拉勾教育的公钥)、申请者的组织信息和个人信息、签发机构 的信息、有效时间、证书序列号等信息的明文,同时包含一个CA机构的数字签名。 其中签名的产生算法:首先,使用散列函数计算公开的明文信息的信息摘要,然后,采用 CA的私钥对信息摘要进行加密,密文即签名;
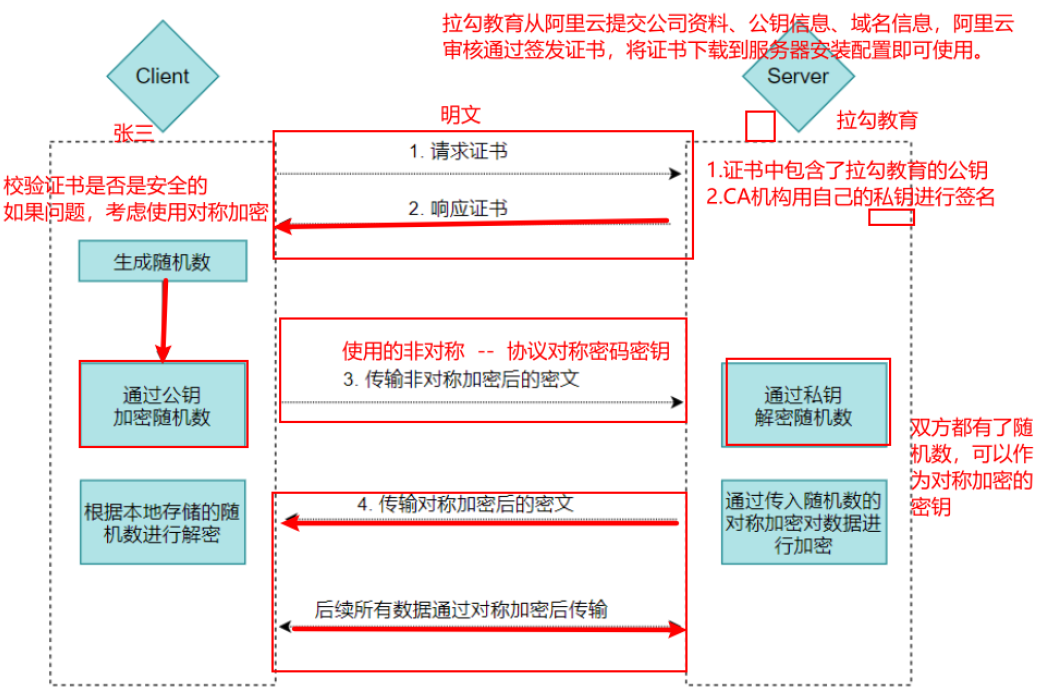
用户向web服务器发起一个安全连接的请求服务器返回经过CA认证的数字证书,证书里面包含了服务器的public key。
用户拿到数字证书,怎么确保CA证书不被劫持,黑客完全可以把一个假的CA证书发给Client,进而欺骗Client,用户如何编写证书真伪?
bash
CA的大杀器就是,CA把自己的CA证书集成在了浏览器和操作系统里面。
Client拿到浏览器或者操作系统的时候,已经有了CA证书,没有必要通过网络获
取,那自然也不存在劫持的问题。
查看浏览器CA证书:设置-->安全检查-->安全-->管理证书
查看操作系统CA证书:certmgr.mscClient 读取证书中的相关的明文信息,采用相同的散列函数计算得到信息摘要,然后利用对应 CA的公钥解密签名数据,对比证书的信息摘要,如果一致,则可以确认证书的合法性,即服务器的公开密钥是值得信赖的。
客户端还会验证证书相关的域名信息、有效时间等信息; 客户端会内置信任CA的证书信息(包含公钥),如果CA不被信任,则找不到对应 CA的证书,证书也会被判定非法。
SSL证书分类:
- DV(域名型SSL):个人站点
- OV(企业型SSL):企业官网
- EV(增强型SSL):对安全需求更强的企业官网、电商、互联网金融网站
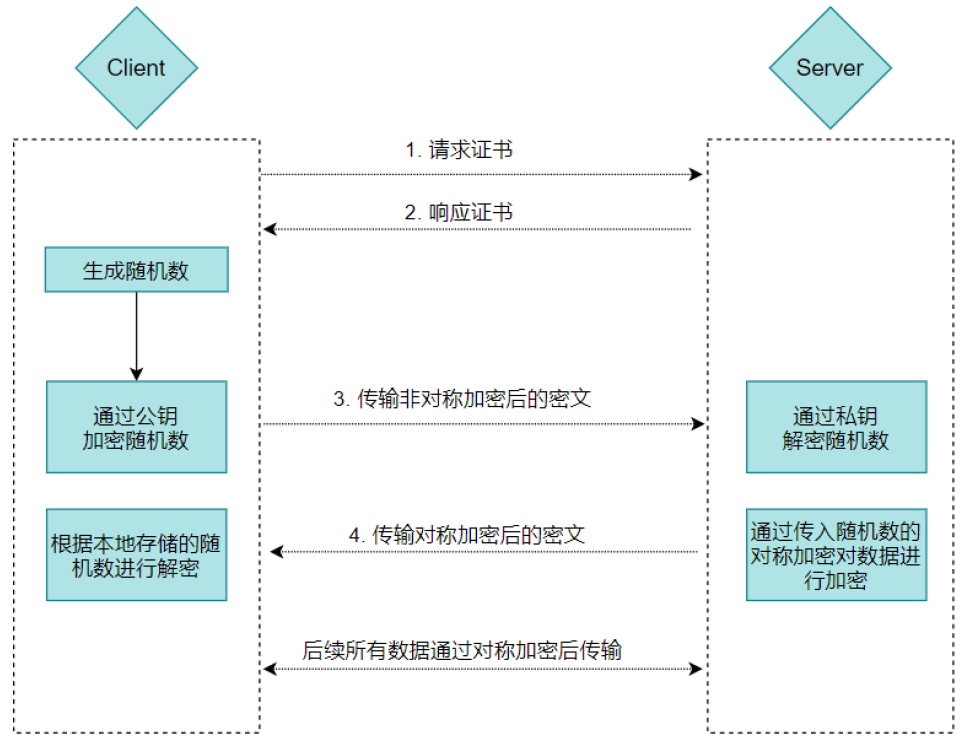
2.3.5 完整的 HTTPS 的通信
TLS握手过程:
明文----->非对称加密----->对称加密
第一步,浏览器给出TLS协议版本号、一个客户端生成的随机数1(Client random),以及客户端支持的加密方法。(明文通讯)
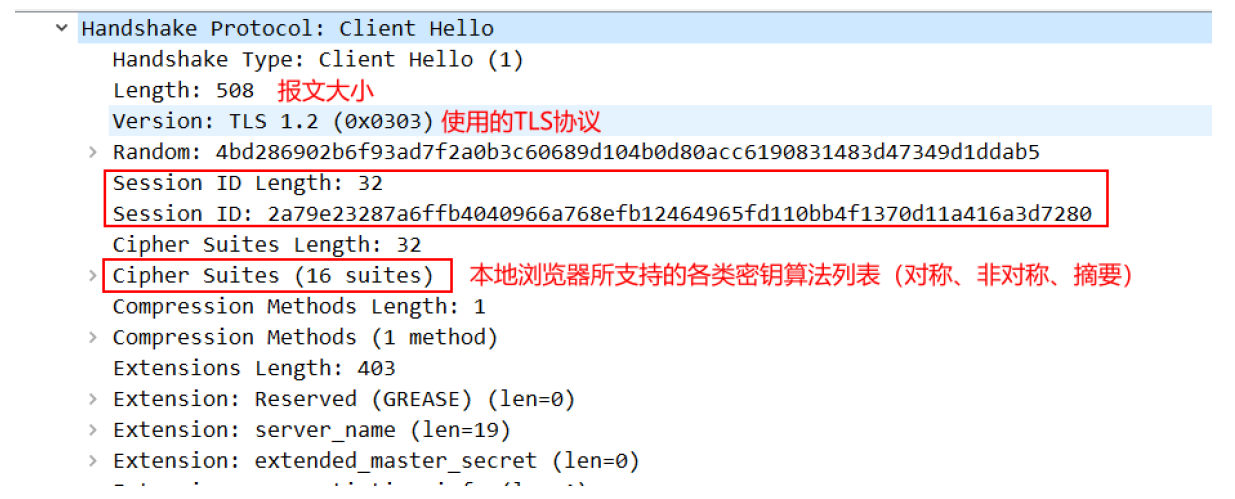
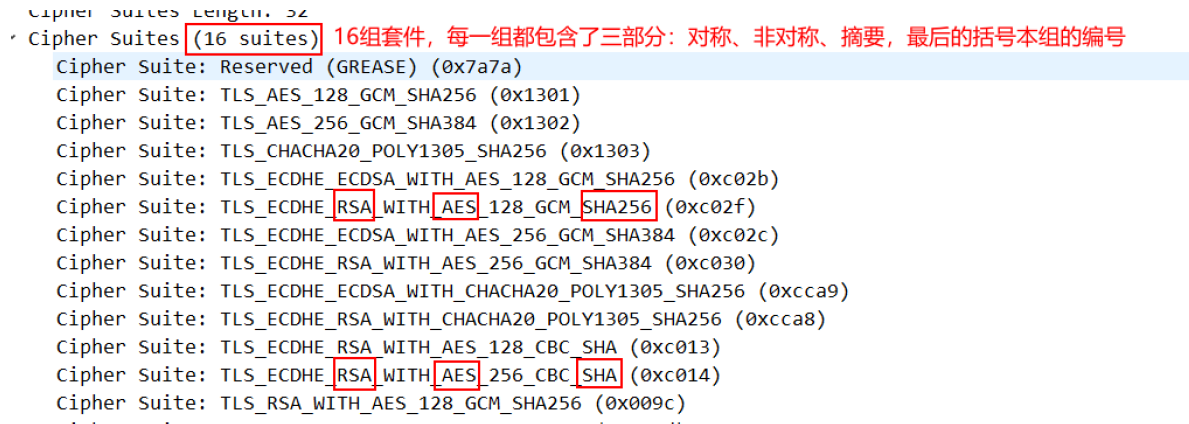
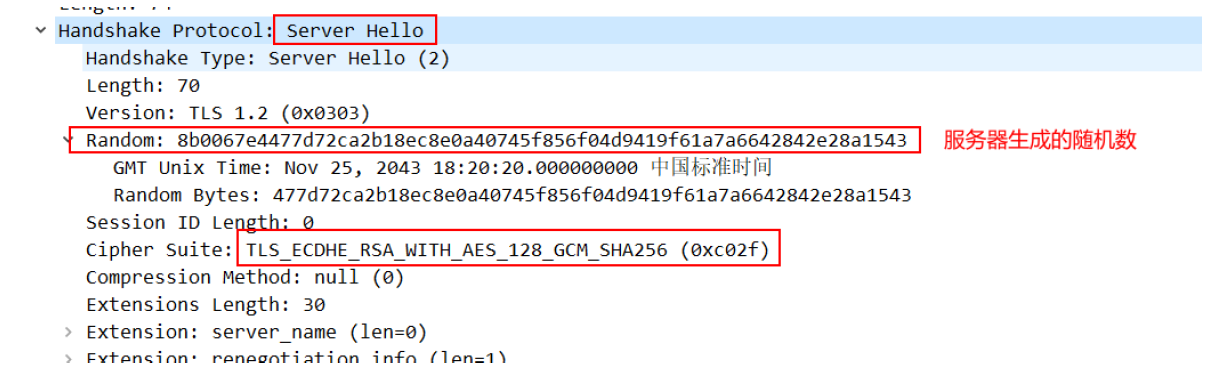
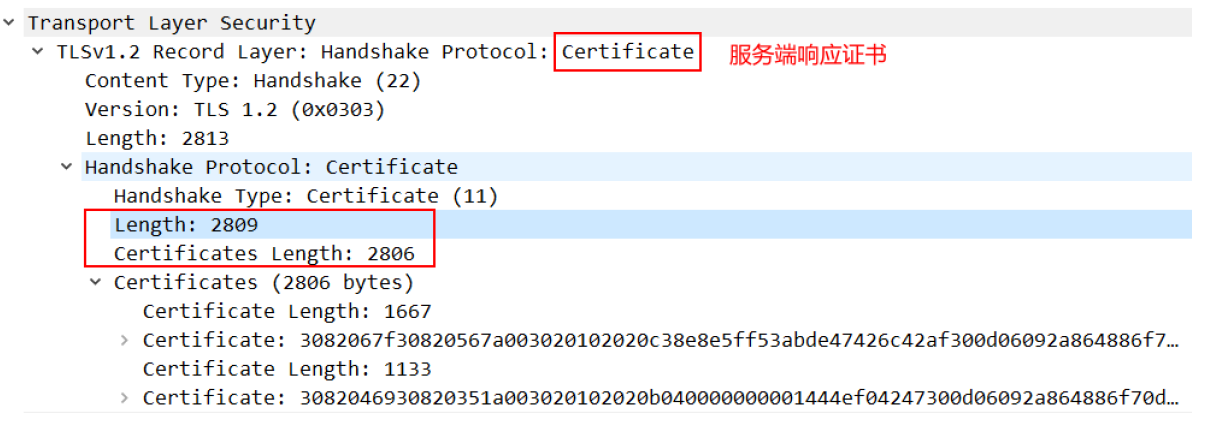
第二步,服务器确认双方使用的加密方法,并给出数字证书、以及一个服务器生成的随机数2(Server random)。(明文通讯)

第三步,浏览器确认数字证书有效,然后生成一个新的随机数3(Pre-mastersecret),并使用数字证书中的公钥加密这个随机数,发给服务器。(使用非对称加密算法)
浏览器确认数字证书有效:浏览器和操作系统内部内置了很多CA机构的证书,是否篡改、是否在有效期内、域名和访问的网站是否匹配。
第四步,服务端使用自己的私钥,获取客户端发来的随机数(即Premaster secret)。
双方就都有三个一模一样的随机数,前两个是明文发送的,最后客户端生成的这个是使用证书中的公钥密文发送的。
第五步,客户端和服务器根据约定的加密方法,使用前面的三个随机数经过特定的算法,生成"对话密钥"(session key),用来加密接下来的整个对话过程。
对话密钥,又叫做会话密钥,其实就是讲之前通讯中的三个随机数生成一个密钥(对称加密)
三个随机数----->第三个是使用非对称加密---->相同的算法------->会话密钥
第六步:客户端和服务器都会第一次使用会话密钥加密一个消息发送给对方。
备注:客户端收到服务端发送的Certificate 报文后首先会校验证书的合法性:
- 证书路径信任链逐级校验通过(证书确由可信 CA 认证签发);
- 签名解密成功(确系证书持有者亲笔);
- 从签名解析出的摘要和证书公开内容的摘要一致(证书内容完整,未被篡改);
- 主题子域与 URL 中的 HOST 一致,综上确保访问的网站是来自预期目标服务器且非劫持或钓鱼。
session的恢复:
握手阶段用来建立SSL连接。如果出于某种原因,对话中断,就需要重新握手。
这时有两种方法可以恢复原来的session:一种叫做session ID,另一种叫做session ticket。
session ID的思想很简单,就是每一次对话都有一个编号(session ID)。如果对话中断,下次重连的时候,只要客户端给出这个编号,且服务器有这个编号的记录,双方就可以重新使用已的"对话密钥",而不必重新生成一把。
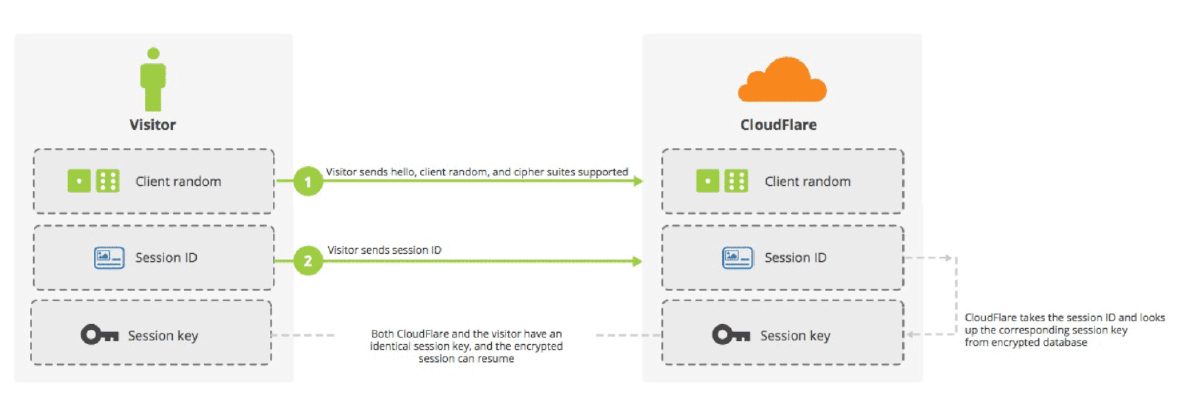
上图中,客户端给出session ID,服务器确认该编号存在,双方就不再进行握手阶段剩余的步骤,而直接用已有的对话密钥进行加密通信。
session ID是目前所有浏览器都支持的方法,但是它的缺点在于session ID往往只保留在一台服务器上。所以,如果客户端的请求发到另一台服务器,就无法恢复对话。session ticket就是为了解决这个问题而诞生的,目前只有Firefox和Chrome浏览器支持。
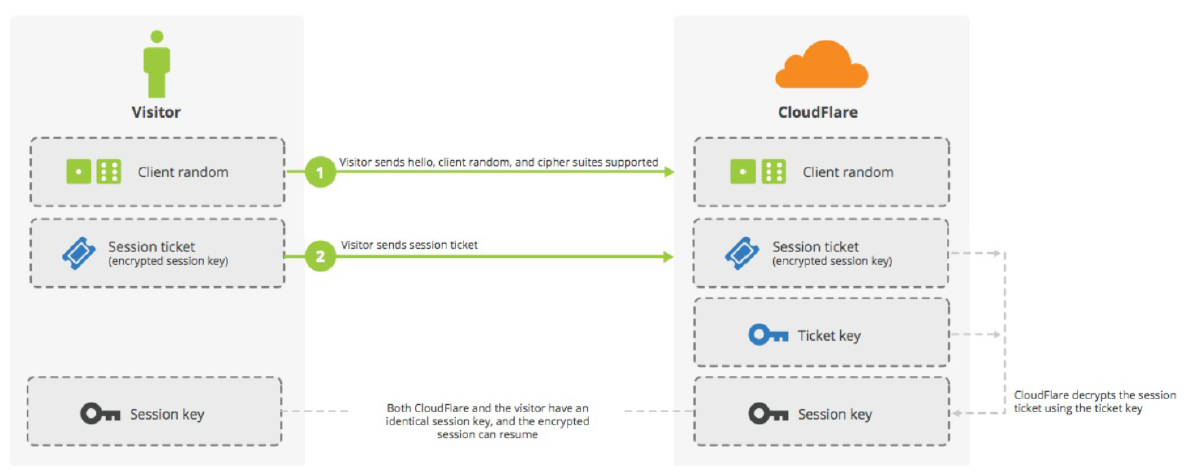
上图中,客户端不再发送session ID,而是发送一个服务器在上一次对话中发送过来的session ticket。这个session ticket是加密的,只有服务器才能解密,其中包括本次对话的主要信息,比如对话密钥和加密方法。当服务器收到session ticket以后,解密后就不必重新生成对话密钥了。
2.4 CA证书制作实战
需求:
自建CA 颁发证书
使用自签名证书来构建安全网络,所谓自签名证书,就是自己扮演 CA 机构,自己给自己的服务器颁发证书。
2.4.1 OpenSSL
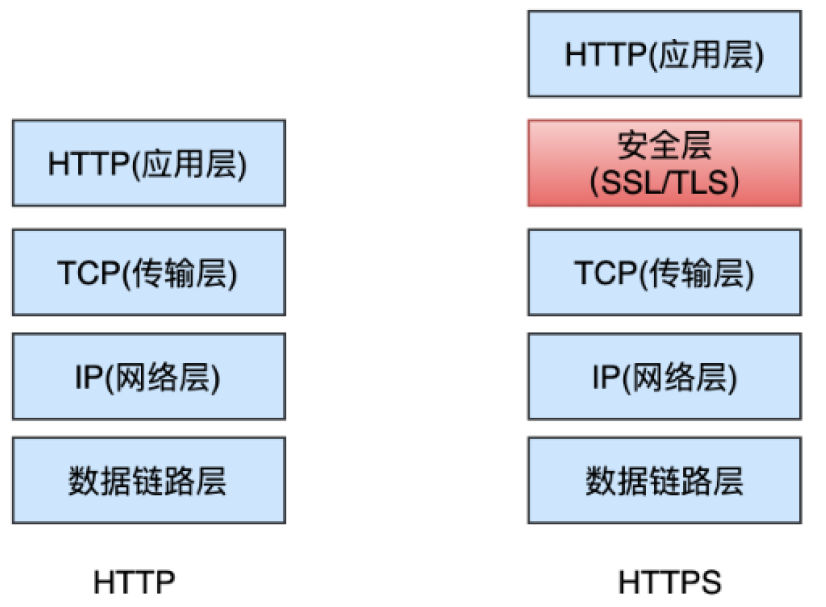
OpenSSL是一个以C语言编写现了SSL与TLS协议的开源的软件库包,应用程序可以使用这个包来进行安全通信,避免窃听,同时确认另一端连线者的身份。这个包广泛被应用在互联网的网页服务器上。OpenSSL支持Linux、Windows、BSD(Unix的衍生系统)、Mac等平台,这使得OpenSSL具有广泛的适用性。
OpenSSL整个软件包大概可以分成三个主要的功能部分:
- 加密算法库
○ 对称加密算法
○ 非对称加密算法
○ 信息摘要算法 - SSL协议库
○ OpenSSL实现了SSL协议的SSLv2和SSLv3,支持了其中绝大部分算法协议
○ OpenSSL也实现了TLSv1.0+ - 应用程序
○ 多功能的命令行工具,可以实现加密解密、密钥生成、密钥和证书管理、自建CA和签名等功能
2.4.2 过程
- CA生成根密钥
- CA生成根证书
- Nginx生成私钥
- Nginx申请证书
- CA签发
- Nginx安装证书,配置
2.4.3 颁发证书
默认情况下Linux操作系统已经内置安装了OpenSSL,可以通过openssl version 查看版本号
但是在使用前,需要注意下当前OpenSSL的库的版本,因为版本1.0.1是一个很重要的风水岭版本,1.0.1是第一个支持TLS1.1和1.2的版本。
(1)修改配置:
在CA目录下创建两个初始文件,维护序列号。通过CA机构签发的每个证书都有一个唯一的序列号。
bash
cd /etc/pki/CA
touch index.txt serial
echo 01 > serial(2)生成根密钥
表示的CA机构的私钥,CA结构签发的每一个证书都要通过自己的私钥进行签名。
bash
cd /etc/pki/CA
#生成一个2048位的密钥
openssl genrsa -out private/cakey.pem 2048(3) 生成根证书
使用req命令生成自签证书
- -new:表示新的申请
- -x509:表示生成自签证书
- -key:指定私钥文件
- -out:保存证书的位置
- -days:指定证书期限
bash
openssl req -new -x509 -key private/cakey.pem -out cacert.pem会提示输入一些内容,因为是私有的,所以可以随便输入(之前修改的openssl.cnf会在这里呈现),最好记住能与后面保持一致。上面的自签证书cacert.pem 应该生成在/etc/pki/CA 下。
(4)为我们的Nginx服务器生成SSL密钥
环境:
192.168.200.16 CA机构服务器
192.168.200.16 Nginx服务器
申请SSL证书本质上就是服务器升级支持HTTPS,非对称加密(公钥和私钥)。
以上都是在CA服务器上做的操作,而且只需进行一次,现在转到nginx服务器上
执行:
安装Nginx
bash
#1.安装该rpm
rpm -ivh
http://nginx.org/packages/centos/7/noarch/RPMS/nginx-releasecentos-
7-0.el7.ngx.noarch.rpm
#安装该rpm后,我们就能在/etc/yum.repos.d/ 目录中看到一个名为
nginx.repo 的文件。
#2.安装完Nginx源后,就可以正式安装Nginx了。
yum install -y nginx
#3.查看所在目录
whereis nginx
bash
cd /etc/nginx/ssl
#为我们的nginx web服务器生成ssl密钥
openssl genrsa -out nginx.key 2048(5)为nginx生成证书签署请求
该过程会生成一个文件,包含了证书相关的信息,但是该文件不是证书,生成证书的请求文件。
该文件需要发送给CA机构,由CA签名后生成一个证书文件。
bash
openssl req -new -key nginx.key -out nginx.csr
...
Country Name (2 letter code) [AU]:CN
State or Province Name (full name) [Some-State]:GD
Locality Name (eg, city) []:SZ
Organization Name (eg, company) [Internet Widgits Pty
Ltd]:COMPANY
Organizational Unit Name (eg, section) []:IT_SECTION
Common Name (e.g. server FQDN or YOUR name)
[]:your.domain.com
Email Address []:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
...同样会提示输入一些内容,其它随便,除了Commone Name 一定要是你要授予证书的服务器域名或主机名,challenge password不填。
(6)私有CA根据请求来签署证书
接下来要把上一步生成的证书请求csr文件,发到CA服务器上,在CA上执行:
bash
openssl ca -in nginx.csr -out nginx.crt
上面签发过程其实默认使用了-cert cacert.pem -keyfile cakey.pem ,这两个文件就是前两步生成的位于/etc/pki/CA 下的根密钥和根证书。将生成的crt证书发回nginx服务器使用。
到此我们已经拥有了建立SSL安全连接所需要的所有文件,并且服务器的crt和key都位于配置的目录下,剩下的是如何使用证书的问题。
2.4.4 使用 SSL证书
(1)Nginx 使用 SSL 证书
在本地安装完成证书(在Nginx服务器配置)也就意味着Java Web应用已经完成了从http到https协议的升级
以 Nginx 为例,在 Nginx 中新建ssl文件夹,将生成的crt和key放入其中,配置文件中加入以下代码:
bash
#修改Nginx的配置文件,安装SSL证书
cd /etc/nginx/conf.d
vi default.conf
listen 443 ssl http2;#https协议监听的端口号是443端口,基
于http2进行工作的。
ssl_certificate /etc/nginx/ssl/nginx.crt; # 指向 ssl
文件夹中的 crt 文件
ssl_certificate_key /etc/nginx/ssl/nginx.key; # 指向
ssl 文件夹中的 key 文件
ssl_session_timeout 5m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
#启用false start加速
ssl_ciphers
AESGCM:ALL:!DH:!EXPORT:!RC4:+HIGH:!MEDIUM:!LOW:!aNULL:!eNULL;
ssl_prefer_server_ciphers on;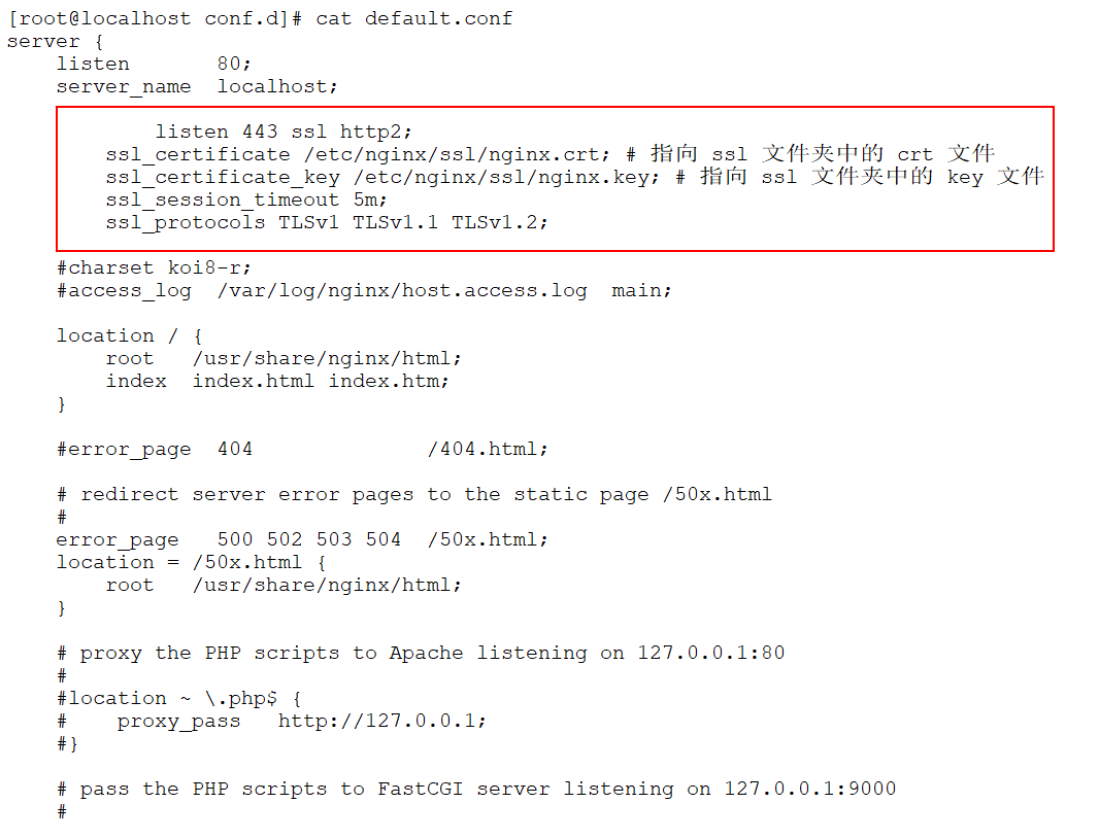
(2)启动Nginx
bash
#切换到可执行目录
cd /usr/sbin/
./nginx
#查看启动状态
ps -ef|grep nginx(3)访问测试
但是,我们自己签发的证书,是不受其他服务器信任的,当发起 curl 请求时,会出现以下情况:证书无效或无法验证错误。
这时候,我们就需要将我们 CA 服务器的根证书导入到这台服务器中。
(4)添加证书:
bash
#安装 ca-certificates package:
yum install ca-certificates
#启用dynamic CA configuration feature:
update-ca-trust force-enable
#将证书文件放到 /etc/pki/ca-trust/source/anchors/ 目录下
mv /etc/pki/CA/cacert.pem /etc/pki/ca-trust/source/anchors/
#执行更新:
update-ca-trust extract(5)修改本地host文件
bash
cd /etc
vi hosts
127.0.0.1 localhost localhost.localdomain localhost4
localhost4.localdomain4
::1 localhost localhost.localdomain localhost6
localhost6.localdomain6
192.168.200.21 yj.com(6)访问测试
curl https://yj.com