前言
在当今的分布式系统架构中,消息队列已经成为不可或缺的核心组件。Apache Kafka作为一款高吞吐量、低延迟的分布式消息系统,被广泛应用于大数据处理、日志收集、流式处理等场景。
一、Kafka是什么?
Apache Kafka是一个分布式流处理平台,最初由LinkedIn公司开发,后来贡献给了Apache基金会。Kafka具有以下核心特性:
- 高吞吐量:每秒可以处理百万级的消息
- 低延迟:毫秒级的端到端延迟
- 高可用性:通过副本机制保证数据不丢失
- 可扩展性:支持水平扩展,轻松应对业务增长
- 持久化:消息持久化到磁盘,支持消息回溯
Kafka应用场景
- 消息队列:实现应用解耦、异步处理、流量削峰
- 日志收集:集中收集应用日志,支持实时分析
- 流式处理:与Flink配合实现实时数据处理
- 事件溯源:记录业务状态变更历史
- 分布式事务:实现最终一致性事务
二、Kafka核心概念
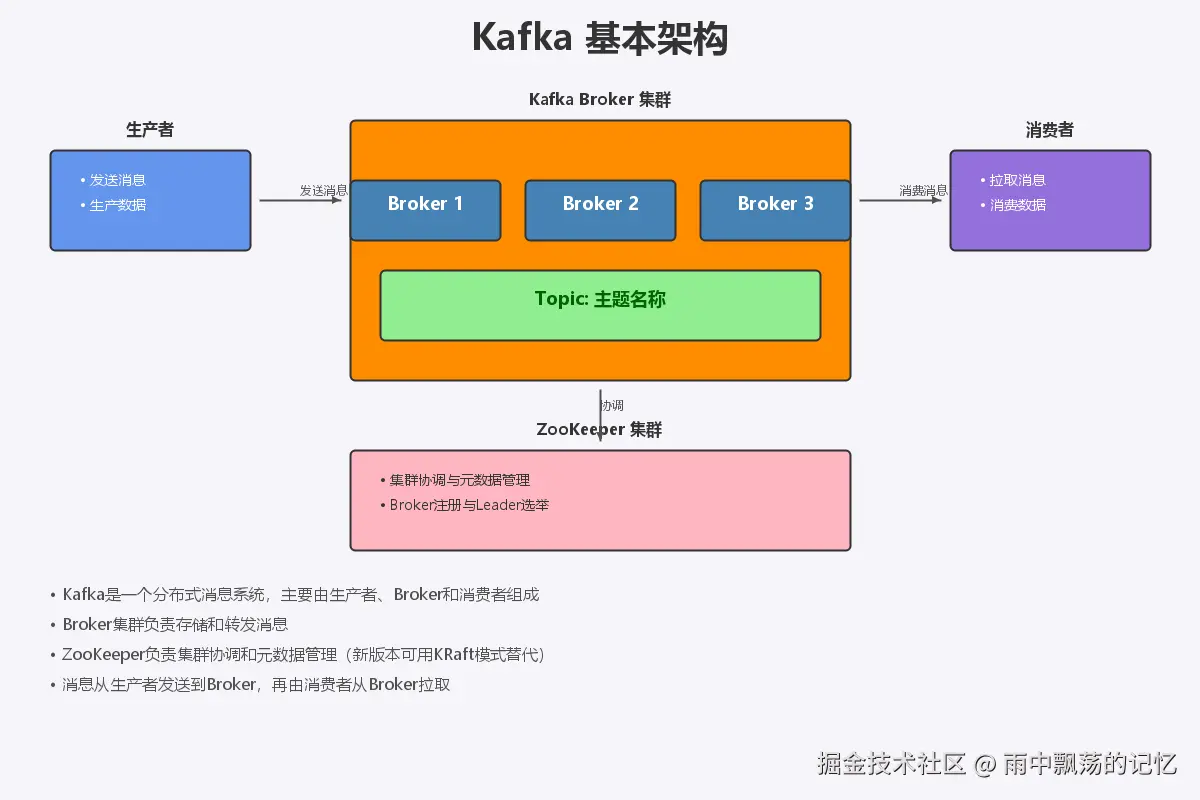
2.1 基本架构
Kafka集群由多个Broker组成,生产者(Producer)向Kafka发送消息,消费者(Consumer)从Kafka消费消息。以下是Kafka的基本架构:
- Broker:Kafka服务节点,负责存储和转发消息
- Topic:消息的主题,逻辑上的消息分类
- Partition:分片,Topic被分割成多个分区,实现并行处理
- Replica:副本,每个分区可以有多个副本,提供容错能力
- Producer:生产者,负责发送消息到Kafka
- Consumer:消费者,从Kafka拉取并处理消息
- Consumer Group:消费者组,实现消息的负载均衡
2.2 分区与副本机制
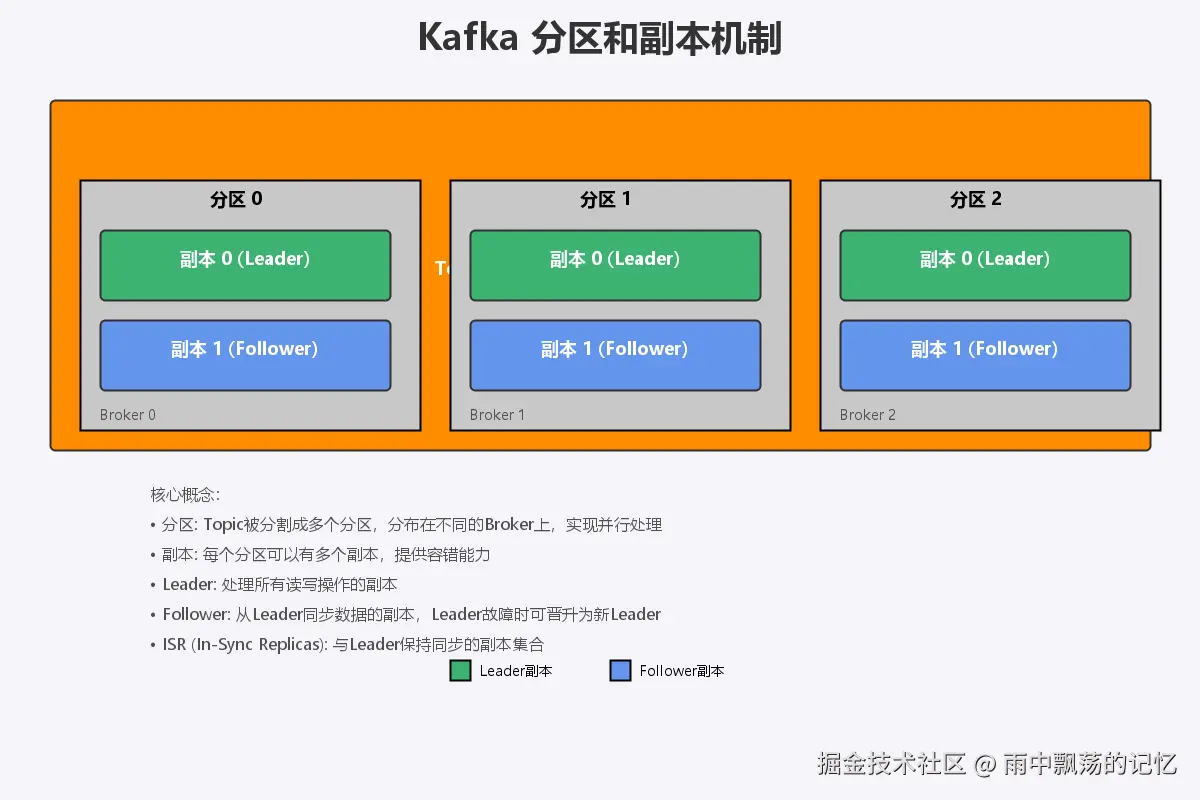
**分区(Partition)**是Kafka实现高吞吐量的关键。一个Topic可以分为多个分区,每个分区是一个有序的消息队列。分区的好处包括:
- 并行处理:多个生产者可以并行写入不同分区
- 提高吞吐量:多个消费者可以并行消费不同分区
- 负载均衡:分区分布在不同的Broker上,均衡负载
**副本(Replica)**机制保证数据的高可用性:
- Leader副本:处理所有读写操作
- Follower副本:从Leader同步数据,Leader故障时可晋升为新Leader
- ISR(In-Sync Replicas):与Leader保持同步的副本集合
2.3 消息传递语义
Kafka支持三种消息传递语义: 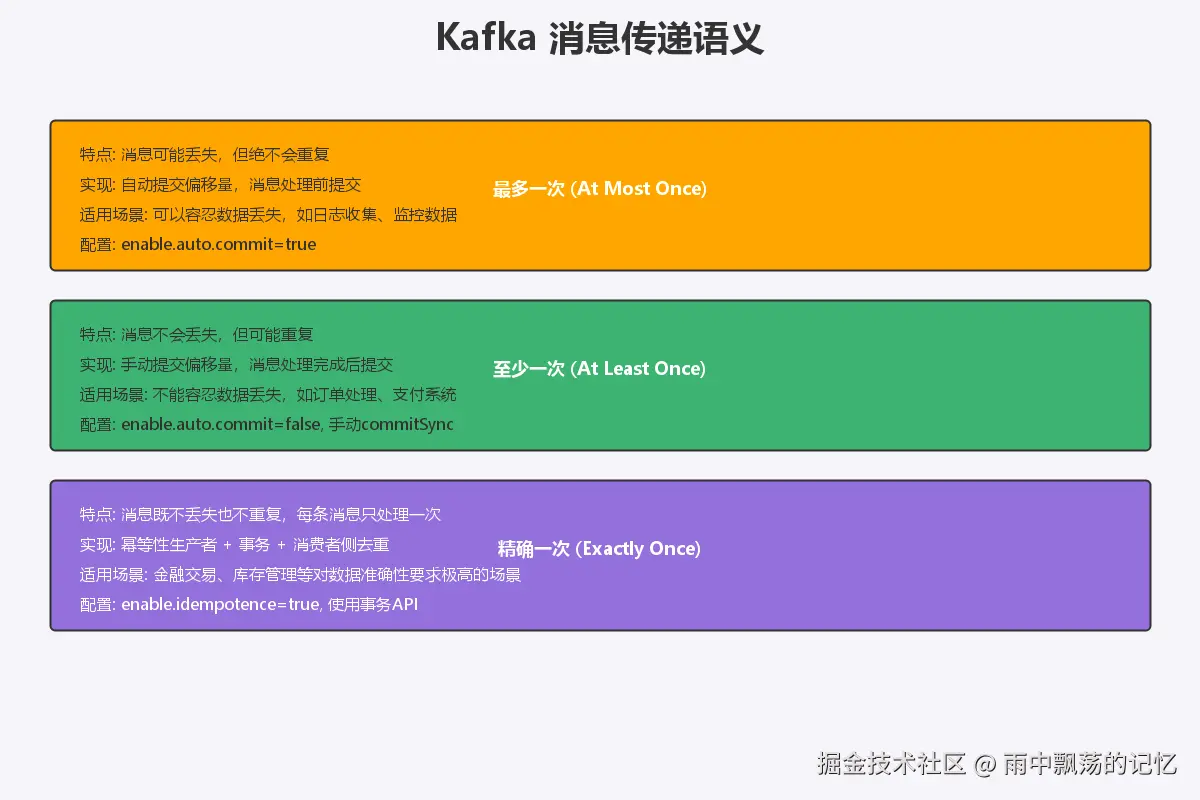
-
最多一次(At Most Once)
- 消息可能丢失,但绝不会重复
- 适用场景:可以容忍数据丢失,如日志收集、监控数据
- 配置:
enable.auto.commit=true
-
至少一次(At Least Once)
- 消息不会丢失,但可能重复
- 适用场景:不能容忍数据丢失,如订单处理、支付系统
- 配置:
enable.auto.commit=false,手动提交偏移量
-
精确一次(Exactly Once)
- 消息既不丢失也不重复,每条消息只处理一次
- 适用场景:金融交易、库存管理等对数据准确性要求极高的场景
- 配置:
enable.idempotence=true,使用事务API
三、Kafka生产者详解
3.1 生产者工作流程

Kafka生产者发送消息的完整流程:
- 创建生产者:配置bootstrap.servers、序列化器等参数
- 构建消息记录:创建ProducerRecord对象
- 序列化:将Java对象序列化为字节数组
- 分区器选择:根据消息键选择目标分区
- 压缩处理:可选择压缩算法减少网络传输
- 批量缓存:消息进入缓冲区,等待批量发送
- 发送到Broker:将消息发送到Kafka集群
- 等待确认:根据acks配置等待Broker确认
- 处理回调:异步处理发送结果
3.2 生产者核心配置
java
// 创建生产者配置
Properties props = new Properties();
// Kafka集群地址(必填)
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 序列化器配置(必填)
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 消息确认机制(重要)
// acks=0: 不等待确认,可能丢数据
// acks=1: 等待Leader确认(默认)
// acks=all: 等待所有副本确认,最安全但性能最低
props.put(ProducerConfig.ACKS_CONFIG, "all");
// 重试次数
props.put(ProducerConfig.RETRIES_CONFIG, 3);
// 批量发送大小(字节)
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// 发送等待时间(毫秒)
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
// 缓冲区大小(字节)
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// 开启幂等性,防止消息重复
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);3.3 生产者示例代码
同步发送消息
java
// 创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 创建消息记录
ProducerRecord<String, String> record =
new ProducerRecord<>("demo-topic", "key1", "这是一条同步消息");
// 同步发送(会阻塞直到收到响应)
try {
RecordMetadata metadata = producer.send(record).get();
System.out.println("消息发送成功 - 分区: " + metadata.partition() +
", 偏移量: " + metadata.offset());
} catch (InterruptedException | ExecutionException e) {
System.err.println("消息发送失败: " + e.getMessage());
}异步发送消息
java
// 异步发送(不阻塞,通过回调处理结果)
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
// 发送成功
System.out.println("消息发送成功 - 偏移量: " + metadata.offset());
} else {
// 发送失败
System.err.println("消息发送失败: " + exception.getMessage());
}
}
});发送JSON消息
java
ObjectMapper mapper = new ObjectMapper();
// 创建业务对象
Map<String, Object> orderData = new HashMap<>();
orderData.put("orderId", "ORD20240112001");
orderData.put("userId", "U001");
orderData.put("amount", 299.99);
orderData.put("timestamp", System.currentTimeMillis());
// 转换为JSON
String jsonMessage = mapper.writeValueAsString(orderData);
// 发送JSON消息
ProducerRecord<String, String> record =
new ProducerRecord<>("order-topic", orderData.get("orderId").toString(), jsonMessage);
producer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.println("订单消息发送成功: " + orderData.get("orderId"));
}
});事务消息
java
// 初始化事务生产者
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-transactional-id");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 初始化事务
producer.initTransactions();
try {
// 开始事务
producer.beginTransaction();
// 发送多条消息(原子操作)
producer.send(new ProducerRecord<>("order-topic", "order-1", "创建订单"));
producer.send(new ProducerRecord<>("inventory-topic", "item-1", "扣减库存"));
producer.send(new ProducerRecord<>("notification-topic", "user-1", "发送通知"));
// 提交事务(所有消息都成功)或 回滚事务(任何消息失败)
producer.commitTransaction();
System.out.println("事务提交成功");
} catch (Exception e) {
// 发生异常,回滚事务
producer.abortTransaction();
System.err.println("事务回滚: " + e.getMessage());
}四、Kafka消费者详解
4.1 消费者工作流程
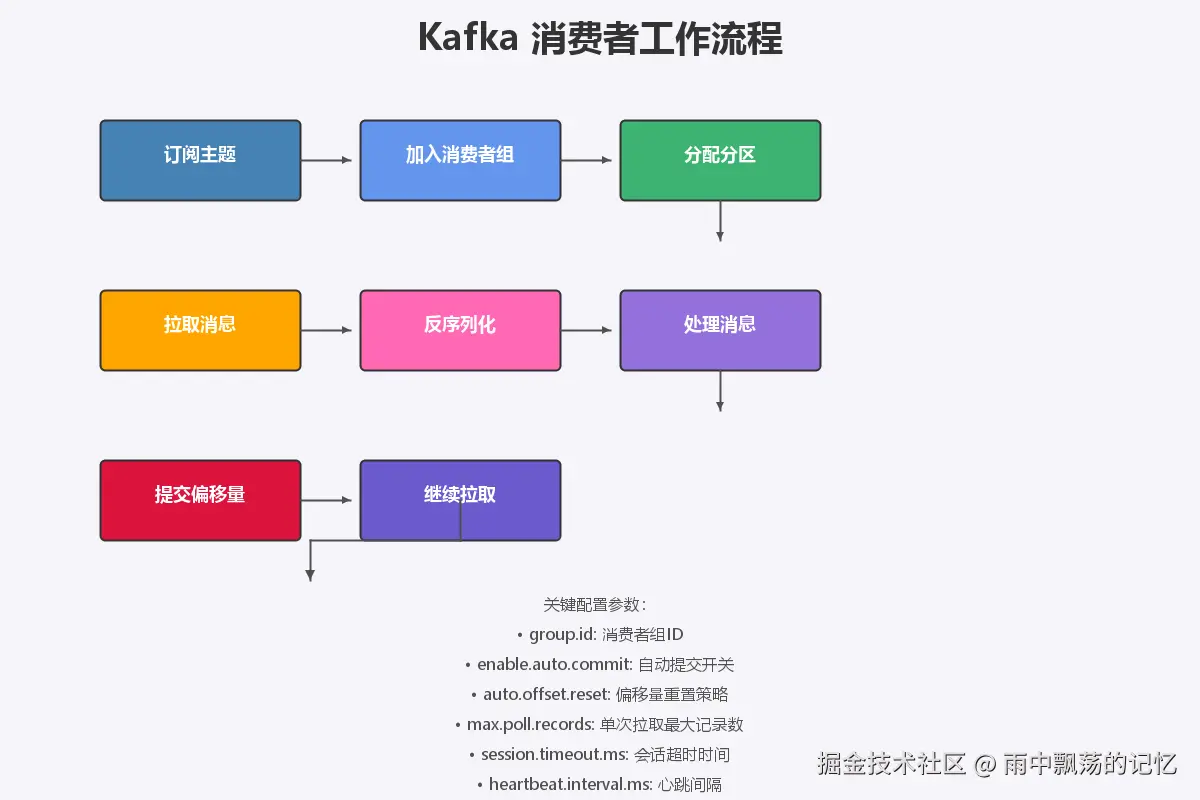
Kafka消费者消费消息的完整流程:
- 订阅主题:消费者订阅要消费的Topic
- 加入消费者组:通过协调器加入消费者组
- 分配分区:协调器为消费者分配分区
- 拉取消息:从分配的分区拉取消息
- 反序列化:将字节数组反序列化为Java对象
- 处理消息:执行业务逻辑
- 提交偏移量:将已消费的偏移量提交给Kafka
- 继续拉取:循环拉取新消息
4.2 消费者核心配置
java
// 创建消费者配置
Properties props = new Properties();
// Kafka集群地址(必填)
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 消费者组ID(必填)
// 同一组的消费者会共同消费消息,实现负载均衡
props.put(ConsumerConfig.GROUP_ID_CONFIG, "demo-group");
// 反序列化器配置(必填)
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 自动提交偏移量
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交间隔(毫秒)
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 偏移量重置策略
// earliest: 从最早的消息开始消费
// latest: 从最新的消息开始消费(默认)
// none: 如果没有之前的偏移量,则抛出异常
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 单次poll最大记录数
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "500");
// poll最大间隔时间(超过此时间消费者会被认为失效)
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, "300000");
// 会话超时时间
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");4.3 消费者示例代码
基本消费逻辑
java
// 创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
consumer.subscribe(Collections.singletonList("demo-topic"));
try {
while (true) {
// 拉取消息(最多等待1秒)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println("收到消息:");
System.out.println(" 分区: " + record.partition());
System.out.println(" 偏移量: " + record.offset());
System.out.println(" 键: " + record.key());
System.out.println(" 值: " + record.value());
// 处理消息(业务逻辑)
processMessage(record);
}
}
} finally {
consumer.close();
}手动提交偏移量
java
// 关闭自动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("demo-topic"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
try {
// 处理消息
processMessage(record);
// 处理成功后,同步提交偏移量
Map<TopicPartition, OffsetAndMetadata> offset =
Map.of(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1));
consumer.commitSync(offset);
} catch (Exception e) {
// 处理失败,不提交偏移量,下次会重新消费
System.err.println("处理消息失败: " + e.getMessage());
}
}
}
} finally {
consumer.close();
}消费JSON消息
java
ObjectMapper mapper = new ObjectMapper();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
try {
// 解析JSON消息
Map<String, Object> orderData =
mapper.readValue(record.value(), new TypeReference<Map<String, Object>>() {});
String orderId = (String) orderData.get("orderId");
Double amount = (Double) orderData.get("amount");
// 处理订单
System.out.println("处理订单: " + orderId + ", 金额: " + amount);
// 提交偏移量
consumer.commitSync();
} catch (Exception e) {
System.err.println("JSON解析失败: " + e.getMessage());
}
}
}指定分区消费
java
// 手动指定分区(不使用消费者组的自动分配)
TopicPartition partition0 = new TopicPartition("demo-topic", 0);
TopicPartition partition1 = new TopicPartition("demo-topic", 1);
consumer.assign(Arrays.asList(partition0, partition1));
// 查看分区位置
Set<TopicPartition> partitions = consumer.assignment();
System.out.println("当前分配的分区: " + partitions);五、完整消息流转流程
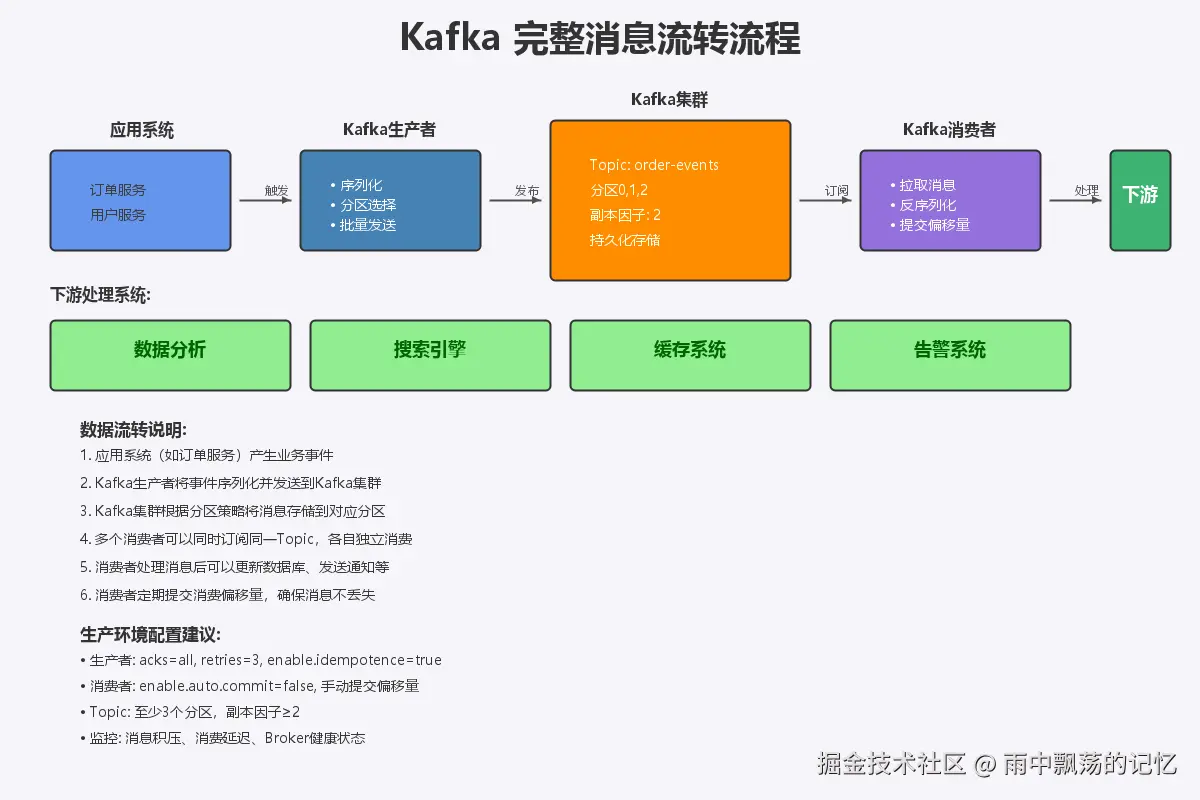
下面是一个完整的Kafka消息流转示例,展示从订单创建到多系统消费的完整链路:
5.1 订单服务(生产者)
java
public class OrderProducer {
private final KafkaProducer<String, String> producer;
public OrderProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
this.producer = new KafkaProducer<>(props);
}
/**
* 创建订单并发送消息
*/
public void createOrder(Order order) {
try {
ObjectMapper mapper = new ObjectMapper();
String orderJson = mapper.writeValueAsString(order);
// 发送订单创建事件
ProducerRecord<String, String> record =
new ProducerRecord<>("order-events", order.getOrderId(), orderJson);
producer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.println("订单事件发送成功: " + order.getOrderId());
// 记录到数据库
saveOrderToDatabase(order);
} else {
System.err.println("订单事件发送失败: " + exception.getMessage());
// 处理失败逻辑
}
});
} catch (Exception e) {
System.err.println("订单创建失败: " + e.getMessage());
}
}
private void saveOrderToDatabase(Order order) {
// 保存到数据库的逻辑
}
public void close() {
producer.close();
}
}5.2 库存服务(消费者)
java
public class InventoryConsumer {
private final KafkaConsumer<String, String> consumer;
public InventoryConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "inventory-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
this.consumer = new KafkaConsumer<>(props);
}
public void start() {
consumer.subscribe(Collections.singletonList("order-events"));
try {
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
try {
// 解析订单消息
ObjectMapper mapper = new ObjectMapper();
Order order = mapper.readValue(record.value(), Order.class);
// 扣减库存
deductInventory(order);
// 处理成功,提交偏移量
consumer.commitSync();
} catch (Exception e) {
System.err.println("库存处理失败: " + e.getMessage());
// 发送到死信队列或记录日志
}
}
}
} finally {
consumer.close();
}
}
private void deductInventory(Order order) {
// 扣减库存的逻辑
System.out.println("扣减库存 - 订单: " + order.getOrderId() +
", 商品: " + order.getProductId());
}
public static void main(String[] args) {
InventoryConsumer consumer = new InventoryConsumer();
consumer.start();
}
}5.3 通知服务(消费者)
java
public class NotificationConsumer {
private final KafkaConsumer<String, String> consumer;
public NotificationConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "notification-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
this.consumer = new KafkaConsumer<>(props);
}
public void start() {
consumer.subscribe(Collections.singletonList("order-events"));
try {
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
try {
// 解析订单消息
ObjectMapper mapper = new ObjectMapper();
Order order = mapper.readValue(record.value(), Order.class);
// 发送通知
sendNotification(order);
// 处理成功,提交偏移量
consumer.commitSync();
} catch (Exception e) {
System.err.println("通知发送失败: " + e.getMessage());
}
}
}
} finally {
consumer.close();
}
}
private void sendNotification(Order order) {
// 发送邮件、短信、站内信等
System.out.println("发送订单通知 - 用户: " + order.getUserId() +
", 订单号: " + order.getOrderId());
}
public static void main(String[] args) {
NotificationConsumer consumer = new NotificationConsumer();
consumer.start();
}
}六、最佳实践
6.1 生产者配置
java
// 生产环境推荐配置
Properties props = new Properties();
// 1. 多个Broker地址,防止单点故障
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"broker1:9092,broker2:9092,broker3:9092");
// 2. 使用acks=all确保消息不丢失
props.put(ProducerConfig.ACKS_CONFIG, "all");
// 3. 开启幂等性
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// 4. 设置合理的重试次数
props.put(ProducerConfig.RETRIES_CONFIG, 3);
// 5. 批量发送配置
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 32768);
props.put(ProducerConfig.LINGER_MS_CONFIG, 20);
// 6. 压缩配置(推荐使用snappy或lz4)
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
// 7. 缓冲区配置
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 67108864);
// 8. 超时配置
props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 30000);
props.put(ProducerConfig.DELIVERY_TIMEOUT_MS_CONFIG, 120000);6.2 消费者配置
java
// 生产环境推荐配置
Properties props = new Properties();
// 1. 多个Broker地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"broker1:9092,broker2:9092,broker3:9092");
// 2. 关闭自动提交,改为手动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 3. 设置合理的超时时间
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 45000);
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 15000);
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 300000);
// 4. 单次拉取数量
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
// 5. 偏移量重置策略
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 6. 最小字节和最大字节配置
props.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG, 1024);
props.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG, 500);6.3 Topic配置
bash
# 创建Topic的最佳实践
kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--topic order-events \
--partitions 3 \
--replication-factor 2 \
--config retention.ms=604800000 \
--config segment.bytes=1073741824 \
--config cleanup.policy=delete
# 配置说明:
# --partitions: 分区数,建议至少3个,可根据消费者数量调整
# --replication-factor: 副本因子,生产环境建议至少2
# retention.ms: 消息保留时间(7天)
# segment.bytes: 分段大小(1GB)
# cleanup.policy: 清理策略(delete或compact)6.4 监控指标
生产者监控指标:
record-send-rate: 消息发送速率record-error-rate: 消息发送错误率request-latency-avg: 请求平均延迟io-wait-time-ns-avg: IO等待时间
消费者监控指标:
records-consumed-rate: 消息消费速率records-lag-max: 最大消息延迟(积压量)commit-latency-avg: 提交偏移量平均延迟heartbeat-rate: 心跳速率
Broker监控指标:
UnderReplicatedPartitions: 副本不足的分区数ActiveControllerCount: 活跃的Controller数量RequestHandlerAvgIdlePercent: 请求处理平均空闲率
七、总结
Kafka作为一款强大的分布式消息系统,在现代微服务架构中扮演着重要角色。本文主要介绍了:
- Kafka的核心概念和架构设计
- 生产者和消费者的配置和使用
- 三种消息传递语义的实现方式
- 完整的Java代码示例
- 最佳实践