本文旨在利用<GPT_SoVITS>进行语音合成,基于录制的源音频文件(.MP3),然后编辑目标音频的文本,融合生成目标音频。
开源工具平台:<GPT_SoVITS> https://github.com/RVC-Boss/GPT-SoVITS
1. 下载部署<GPT_SoVITS>
此开源支持各种系统,包括Windows,Linux, MacOS等,可以根据实际需求进行下载。本文以Windows为例,进封装exe使用进行阐述。
1.1 github下载
旨在希望在Windows下直接运行,按照下述截图下载Windows软件包。
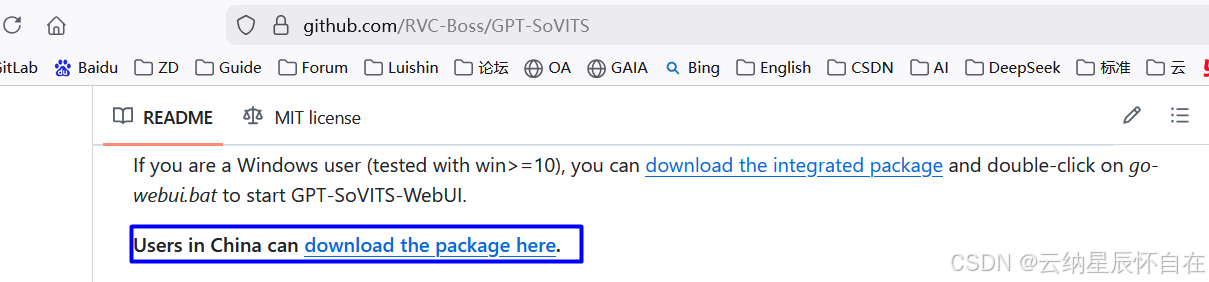
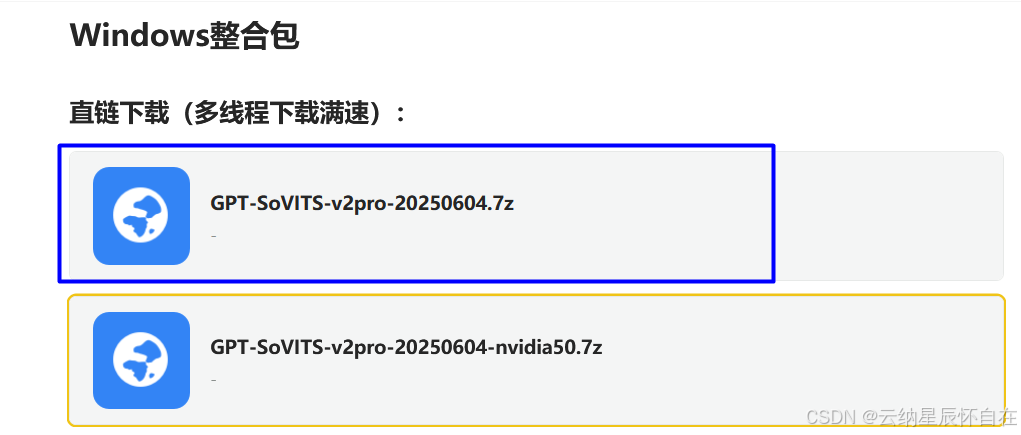
1.2 下载本地后直接解压缩
1.3 配置部署
Install the program by running the following commands:
bash
conda create -n GPTSoVits python=3.10
conda activate GPTSoVits
pwsh -F install.ps1 --Device <CU126|CU128|CPU> --Source <HF|HF-Mirror|ModelScope> [--DownloadUVR5]上述亦可跳过,前提是PC上以提前安装Python 3.10.
2. 运行<GPT_SoVITS>
2.1 运行< go-webui.bat**>**
在解压缩目录下运行<go-webui.bat>. 然后自动调用运行python

浏览器自动打开<GPT_SoVITS WebUI >
2.2 WebUI设置
按照下图步骤进行设置
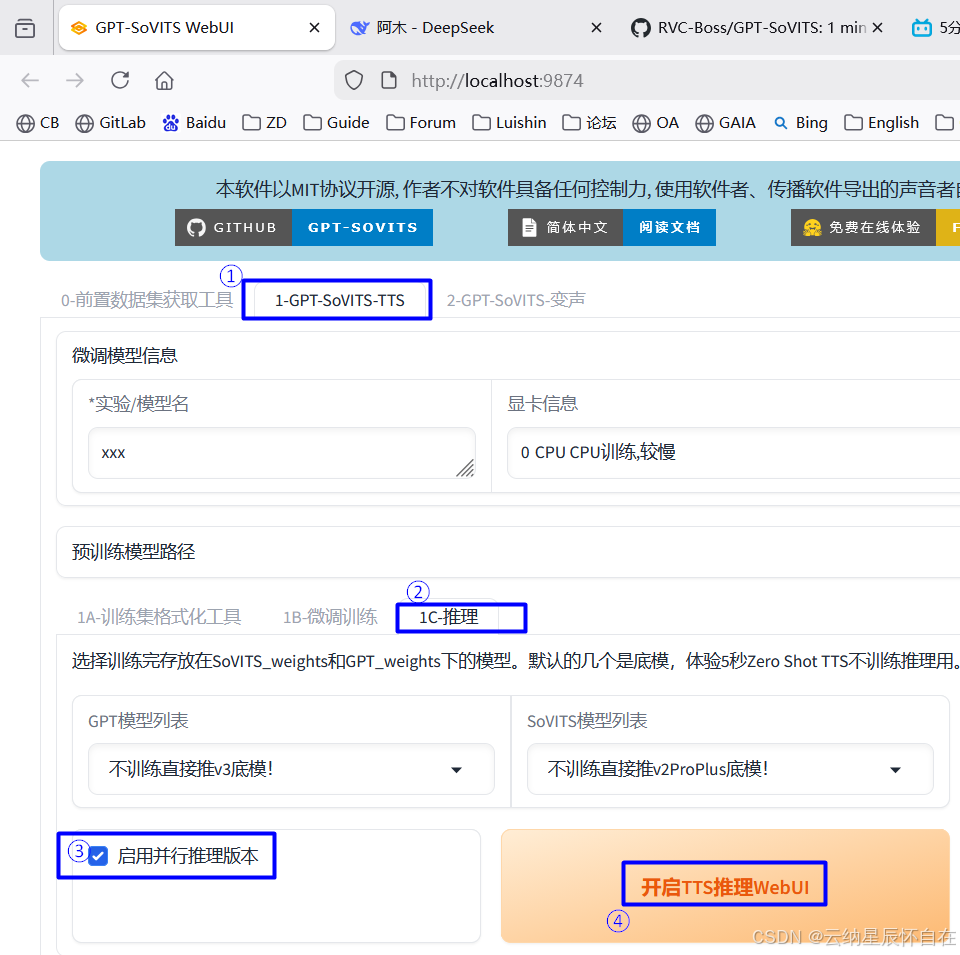
当第四步点击<开启TTS推理WebUI>后,浏览器自动弹出另一网页:http://localhost:9872/
后续都在该Web进行操作。
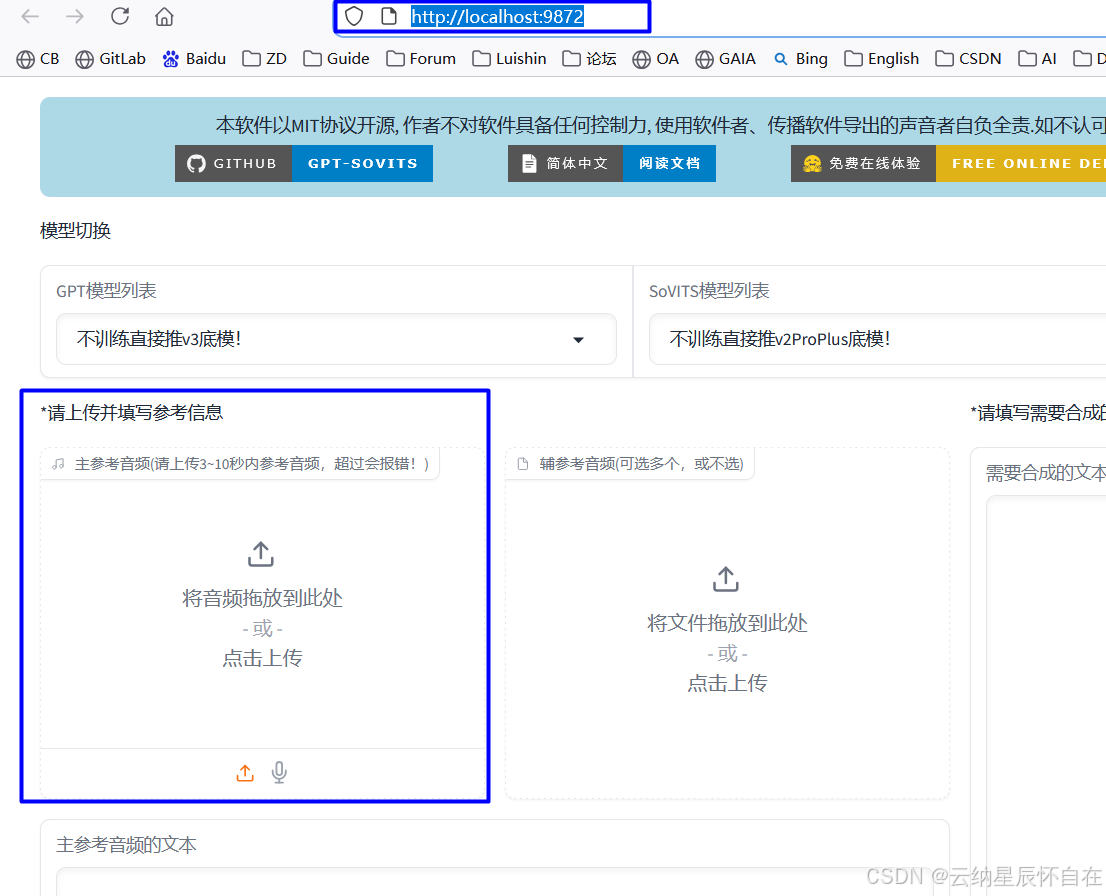
3. 音频AI融合操作
3.1 上传参考音频
上传需要去模仿融合的音效,可以录入音频文本文字,也可以不录入,但对融合效果有影响。
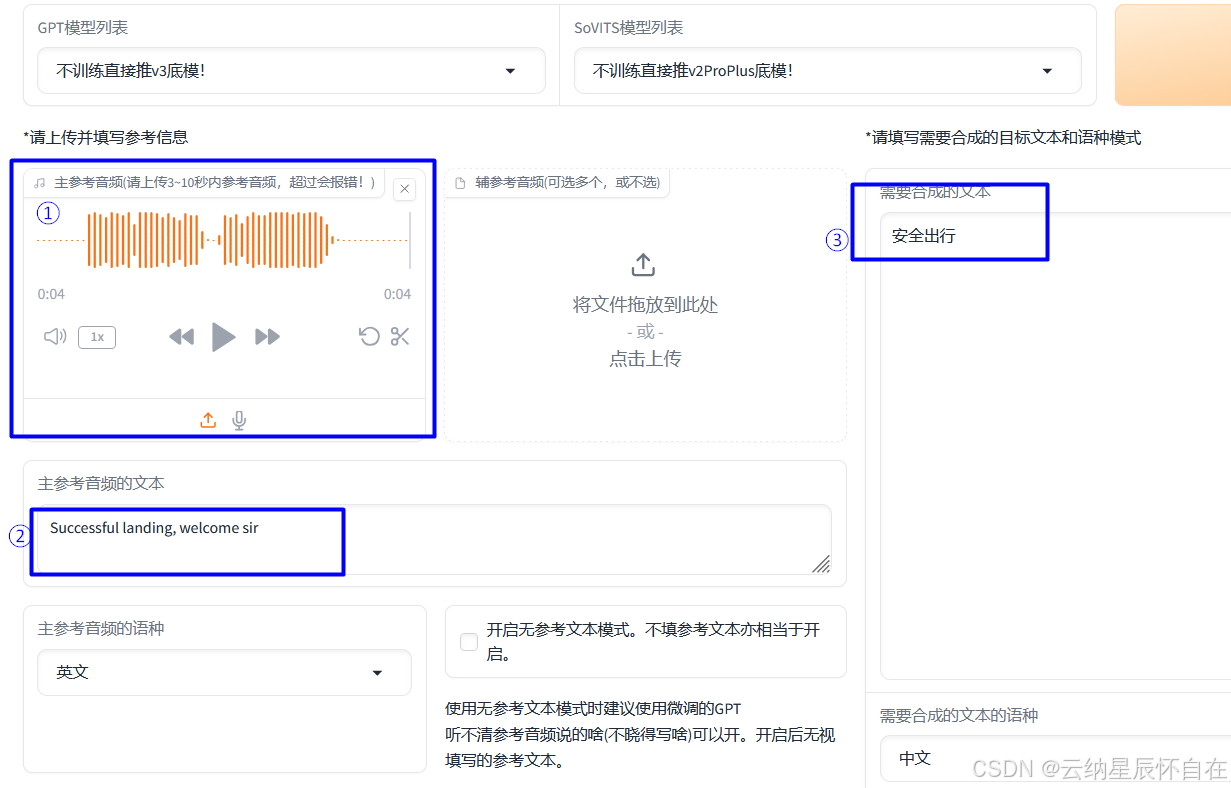
3.2 编辑目标音频文字
如上图所示,中英文均支持。
3.3 合成语音
提供诸多AI配置参数,可以基于实际音效进行参数调优。最后点击"合成语音"。
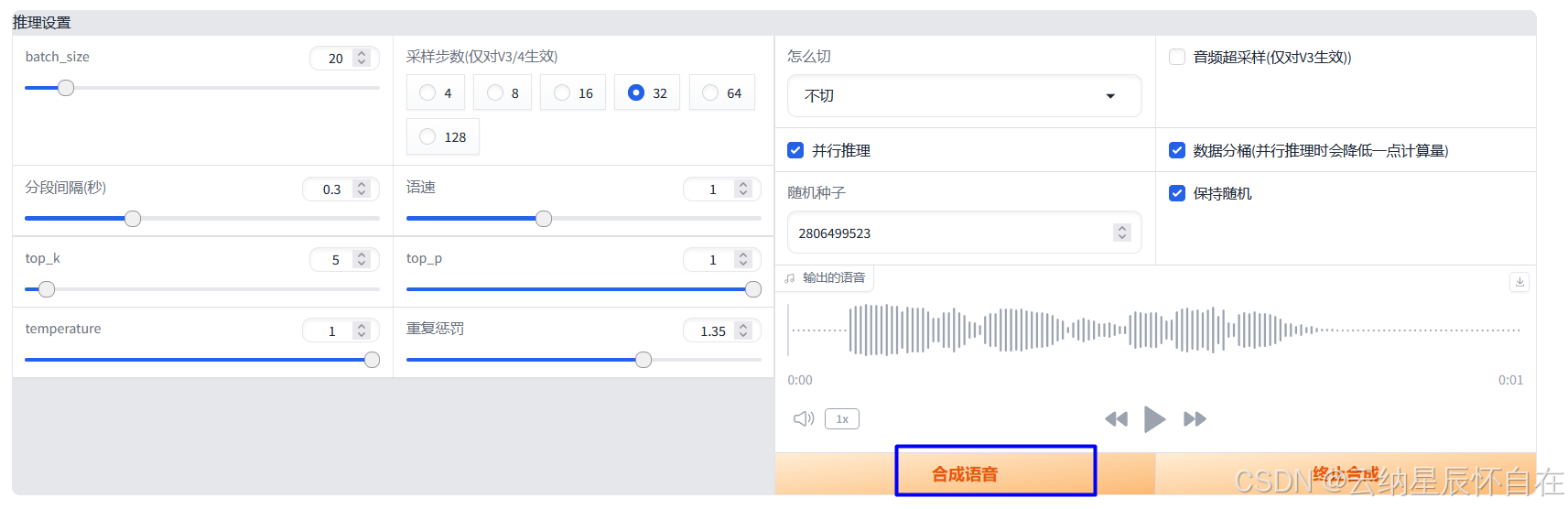
最后,可以通过右上方<**下载>**按钮进行音频下载。

如若github下载有阻碍,可以评论区留言,发资源链接。