序言
SpringAI 提供了一套抽象方法,屏蔽了底层对各种模型的复杂操作,具体的调用,调整,模板由Springai来执行.我打算通过SpringAI为媒介开始研究下人工智能在我们项目中的应用,所以该系列会包含一些基础的人工智能的知识cuiyaonan2000@163.com
参考资料:
相关概念
模型
AI 模型是旨在处理和生成信息的算法,通常模仿人类认知功能。通过从大型数据集中学习模式和见解,这些模型可以进行预测,生成文本、图像或其他输出,从而增强各行业的各种应用。
AI 模型有许多不同的类型,每种都适用于特定的用例。虽然 ChatGPT 及其生成式 AI 功能通过文本输入和输出吸引了用户,但许多模型和公司提供了多样化的输入和输出。在 ChatGPT 之前,许多人对文本到图像生成模型如 Midjourney 和 Stable Diffusion 感到着迷。
下表根据模型的输入和输出类型对其进行了分类
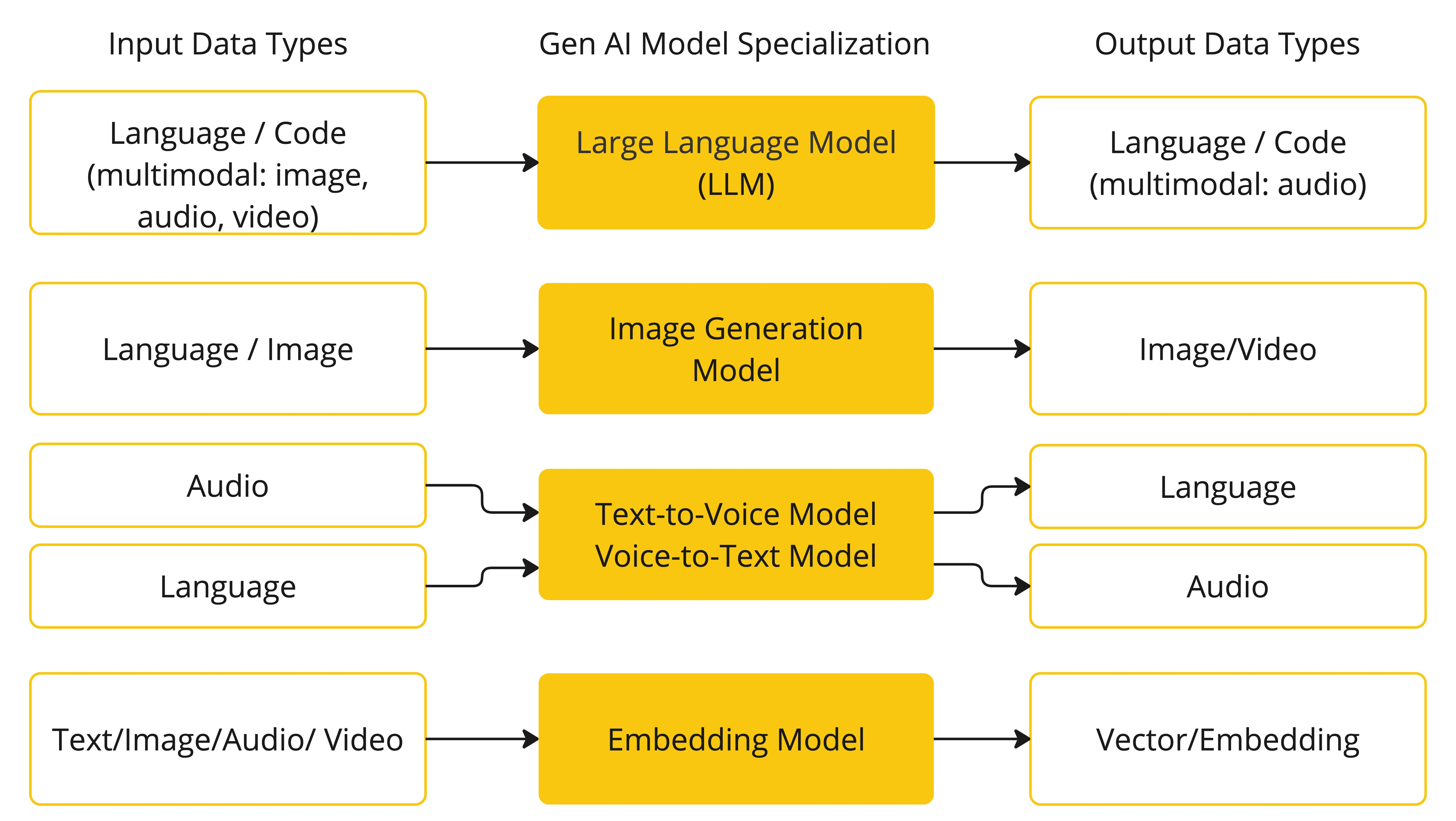
Spring AI 目前支持处理语言、图像和音频作为输入和输出的模型。上表中最后一行,接受文本作为输入并输出数字的,通常被称为嵌入文本(此处感觉有点怪,数字其实也就是文本,应该是覆盖包含的为什么要单独拿出来说cuiyaonan2000@163.com),它代表了 AI 模型中使用的内部数据结构。Spring AI 支持嵌入以实现更高级的用例。
提示(prompte)
Spring AI 里的提示(Prompt) ,核心就是开发者写给 AI 模型的 "指令 / 问题 / 上下文 + 任务要求" 的文本内容 ,是驱动 AI 模型生成对应结果的核心输入,和我们日常用 ChatGPT 时输入的提问 / 指令本质完全一致,只是在 Spring AI 框架中,Prompt 被封装成了标准化的编程对象,适配 Java/Spring 开发的工程化场景。
简单说:日常用 AI 的 "输入框文字"= Spring AI 里的 "Prompt",框架只是把这个 "文字" 做了结构化封装,方便开发者在代码中灵活配置、传递和复用。
Spring AI 中 Prompt 的核心特点(和原生 AI Prompt 的区别)
- 结构化封装 :不是单纯的字符串,而是
Prompt类对象,包含核心内容(Content) + 可选的参数配置(Parameters) + 元数据(Metadata),比如可以给 Prompt 设置温度(temperature)、最大生成长度(maxTokens)等模型参数,直接绑定到指令上。 - 工程化复用:支持把 Prompt 写在配置文件(yml/properties)、模板文件(Thymeleaf/FreeMarker)中,而非硬编码在代码里,方便多场景复用、动态修改,符合 Spring 的 "配置与代码分离" 思想。
- 支持模板化 :Spring AI 内置 Prompt 模板(
PromptTemplate),可以像写动态页面一样,给 Prompt 设置占位符 ,运行时动态填充参数,比如:模板:"请分析{productName}的市场趋势,重点关注{industry}领域"运行时填充参数后,生成最终 Prompt:"请分析AI服务器的市场趋势,重点关注云计算领域" - 多模态支持 :如果对接多模态 AI 模型(如图文生成、视觉问答),Spring AI 的 Prompt 还能封装图片 / 音频等非文本内容,和文字指令组合成多模态输入。
java
// 1. 简单Prompt:纯文字指令(和日常提问一致)
Prompt prompt1 = new Prompt("请用Java代码示例说明Spring AI的Prompt用法");
// 2. 模板化Prompt:动态填充参数
PromptTemplate promptTemplate = new PromptTemplate("请解释{tech}的核心原理,要求{detailLevel}");
Map<String, Object> params = new HashMap<>();
params.put("tech", "Spring AI");
params.put("detailLevel", "通俗易懂,适合入门");
Prompt prompt2 = promptTemplate.create(params); // 填充后生成最终Prompt
// 3. 带模型参数的Prompt:设置生成规则
PromptOptions options = PromptOptions.builder()
.temperature(0.2) // 低温度,生成结果更确定
.maxTokens(500) // 限制最大生成长度
.build();
Prompt prompt3 = new Prompt("总结Spring AI的核心功能", options);
// 4. 调用AI模型:把Prompt传入模型,获取生成结果
AiResponse response = aiModel.call(prompt3);
System.out.println(response.getGeneration().getText());框架把 Prompt 拆成了更细的结构化组件,方便精细化控制:---这个就是springai中为每个提示设置的一个角色,用于ai区分角色,比如那些是用户问题,哪些是ai回答的,哪些时候需要根据上下文进行回答cuiyaonan2000@163.com
- UserMessage:用户指令(核心内容,对应我们的提问)
- SystemMessage:系统提示词(给 AI 设定角色 / 规则,比如 "你是一名 Java 开发讲师,回答需结合 Spring 框架")
- AssistantMessage:AI 的历史回复(用于多轮对话,传递上下文)
- PromptOptions:模型生成参数(温度、最大长度、顶 P 等)
嵌入
嵌入是文本、图像或视频的数值表示,用于捕获输入之间的关系
Spring AI 里的Embedding(嵌入 / 向量嵌入) ,核心就是把文本、图片 这类人类能看懂的非结构化信息 ,转换成计算机 / AI 模型能理解的数字向量(一串浮点数,比如[0.23, -0.56, 1.08, ...]) ,本质是AI 的 "语言翻译器" ------ 把人类语言翻译成机器能计算、对比、匹配的数学语言,这是 AI 实现语义搜索、相似度匹配、内容聚类、RAG(检索增强生成)的底层核心能力。
AI 模型(比如大模型)本身无法直接理解 "文字的意思",只能处理数字。
- 传统方式判断内容相似:靠关键词匹配(比如 "苹果手机" 和 "苹果水果",字面都有 "苹果",会被判定为相似,但语义完全不同);
- Embedding 方式判断:靠语义向量匹配("苹果手机" 和 "苹果水果" 的向量数值差异极大,机器能精准判定为不相似;而 "苹果手机" 和 "iPhone" 的向量高度相似,机器能识别出语义一致)。
java
// 1. 注入Spring AI封装的嵌入模型(以OpenAI为例,配置api-key即可)
@Autowired
private EmbeddingModel embeddingModel;
public void testEmbedding() {
// 2. 输入需要生成嵌入的文本(可单句/多句,框架支持批量)
List<String> texts = List.of(
"苹果手机的续航怎么样?",
"iPhone的电池能用多久?",
"苹果水果的含糖量高吗?"
);
// 3. 生成Embedding向量(核心一步,框架帮你调用底层模型)
List<Embedding> embeddings = embeddingModel.embed(texts);
// 4. 提取向量数组(机器能理解的"数学身份证")
for (int i = 0; i < texts.size(); i++) {
float[] vector = embeddings.get(i).getEmbedding(); // 核心:浮点型向量数组
System.out.println(texts.get(i) + " 的向量长度:" + vector.length); // 如OpenAI的向量长度是1536
}
// 5. 核心场景:计算两个文本的语义相似度(Spring AI内置工具类,直接调用)
Embedding e1 = embeddingModel.embed("苹果手机的续航怎么样?").get(0);
Embedding e2 = embeddingModel.embed("iPhone的电池能用多久?").get(0);
Embedding e3 = embeddingModel.embed("苹果水果的含糖量高吗?").get(0);
// 计算相似度(返回值0~1,越接近1,语义越相似)
double sim12 = VectorUtils.cosineSimilarity(e1.getEmbedding(), e2.getEmbedding()); // 约0.9+(高度相似)
double sim13 = VectorUtils.cosineSimilarity(e1.getEmbedding(), e3.getEmbedding()); // 约0.1-(几乎不相似)
System.out.println("苹果手机 vs iPhone:" + sim12);
System.out.println("苹果手机 vs 苹果水果:" + sim13);
}应用(区别于promote,embed其实是提供promote的基础,现有embed才有promote)
场景 1:RAG(检索增强生成)------ 让大模型回答 "你的业务数据"
这是 Spring AI 中 Embedding最核心的应用(几乎所有企业级 AI 开发都会用到)。
- 痛点:大模型本身只有训练数据,不知道你的公司知识库、业务文档、数据库数据,直接提问会 "胡说八道";
- 解决方案(RAG):
- 先把你的业务文档(如产品手册、FAQ)批量生成 Embedding,存储到向量数据库(如 Pinecone、Milvus、Chroma);
- 用户提问时,先把问题生成 Embedding,去向量数据库检索语义最相似的文档片段;
- 把 "检索到的业务文档 + 用户问题" 组合成 Prompt,传给大模型;
- 大模型基于业务文档回答问题,保证答案的准确性和时效性。
- 核心:Embedding 实现了 "用户问题" 和 "业务文档" 的语义匹配,能精准找到相关的参考资料。
场景 2:语义搜索 ------ 替代传统关键词搜索,实现 "懂意思的搜索"
- 传统搜索:用户搜 "iPhone 续航",只能找到包含 "iPhone" 和 "续航" 关键词的内容,漏搜 "苹果手机电池能用多久";
- 语义搜索(基于 Embedding):用户搜 "iPhone 续航",先把问题生成 Embedding,去向量库检索语义相似的内容,能精准匹配 "苹果手机的电池能用多久""苹果 15 的续航表现" 等内容,搜索结果更智能。
场景 3:内容聚类 / 分类 ------ 自动把相似的文本归为一类
比如你有大量用户反馈,需要自动分类为 "功能问题""体验问题""建议":
- 把所有用户反馈生成 Embedding;
- 基于向量的相似度做聚类算法(Spring AI 可结合第三方算法库);
- 机器自动把语义相似的反馈归为一类,无需人工标注关键词,分类更精准。
场景 4:重复内容检测 ------ 精准识别语义重复的文本
比如检测用户重复提问、文章抄袭、评论灌水:
- 不是靠 "文字完全一样",而是靠语义相似;
- 比如 "这个产品怎么用?" 和 "请问该如何使用这款产品?",文字不同但语义一致,Embedding 的相似度接近 1,能精准判定为重复内容。
Token(令牌)
Token 是 AI 模型工作方式的基本组成部分。在输入时,模型将单词转换为 token。在输出时,它们将 token 转换回单词。
Token 的本质(脱离 Spring AI 也通用)
AI 模型(比如 GPT-3.5/4、通义千问)不按 "字母 / 汉字 / 单词" 处理文本,而是先把文本拆成 Token------ 你可以把 Token 理解成 "AI 的文字积木",模型用这些积木拼接理解 / 生成文本。
- 英文示例:
"Hello world!"会被拆成["Hello", " world", "!"]3 个 Token; - 中文示例:
"你好,世界!"会被拆成["你好", ",", "世界", "!"]4 个 Token(中文通常一个字 / 一个词是 1 个 Token,少数复杂词会拆成多个); - 特殊规则:空格、标点、表情、数字都会被拆成独立 Token。
不同模型的 Token 拆分规则略有差异,但核心逻辑一致:1 个 Token ≈ 0.75 个英文单词 ≈ 1.5 个中文字符(估算值,用于快速判断长度)
Spring AI 中 Token 的核心作用(为什么要关注它)
Spring AI 作为封装 AI 模型调用的框架,Token 贯穿在Prompt 构建、模型调用、结果返回全流程,核心解决 3 个关键问题:
1. 避免超出模型的 Token 上限(最核心)
每个 AI 模型都有 "上下文窗口(Context Window)",即单次能处理的最大 Token 数(输入 + 输出总和):
- 比如 GPT-3.5 Turbo 的上下文窗口是 4096 Token(免费版),GPT-4 是 8192/32768 Token;
- 如果你的 Prompt(输入)Token 数超过上限,模型会报错,或截断文本(导致上下文丢失)。
2. 控制 AI 模型的输出长度
java
// Spring AI内置的Token计数器(以OpenAI为例)
@Autowired
private OpenAiTokenCounter tokenCounter;
public void countTokens() {
String promptText = "请用Java代码示例说明Spring AI的Token用法,要求通俗易懂";
// 计算文本的Token数
int tokenCount = tokenCounter.count(promptText);
System.out.println("Prompt的Token数:" + tokenCount); // 比如输出28
// 关键:判断是否超出模型上限(比如GPT-3.5 Turbo的4096)
if (tokenCount > 4096) {
System.out.println("Prompt过长,请精简!");
}
}
// Spring AI中设置输出Token上限
PromptOptions options = PromptOptions.builder()
.maxTokens(500) // 限制AI回复最多生成500个Token(≈750个中文字符)
.build();
Prompt prompt = new Prompt("解释Spring AI的核心功能", options);
AiResponse response = aiModel.call(prompt);3. 计算 API 调用成本(付费场景)
主流 AI 模型的收费方式是按 Token 计费(输入 + 输出分别计费):
- 比如 OpenAI 的 GPT-3.5 Turbo:输入 0.5 美元 / 1000 Token,输出 1.5 美元 / 1000 Token;
- Spring AI 的 Token 计数工具能帮你统计每次调用的 Token 数,从而估算成本(尤其企业级项目需控成本)
结构化输出(如何能控制输出的接口)
AI 模型的输出传统上以 java.lang.String 的形式出现,即使您要求回复是 JSON 格式。它可能是一个正确的 JSON,但它不是 JSON 数据结构。它只是一个字符串。此外,在提示中要求"JSON"并不是 100% 准确。
这种复杂性导致了一个专业领域的出现,涉及创建提示以产生预期的输出,然后将生成的简单字符串转换为可用于应用程序集成的可用数据结构。--- 核心应用点cuiyaonan2000@163.com