1. 介绍
网站地址:Hugging Face -- The AI community building the future.
1.1. 使用和注册
- 使用需要使用科学上网
- 注册时容易注册失败,需要将科学上网切换到台湾地区可以增加成功率
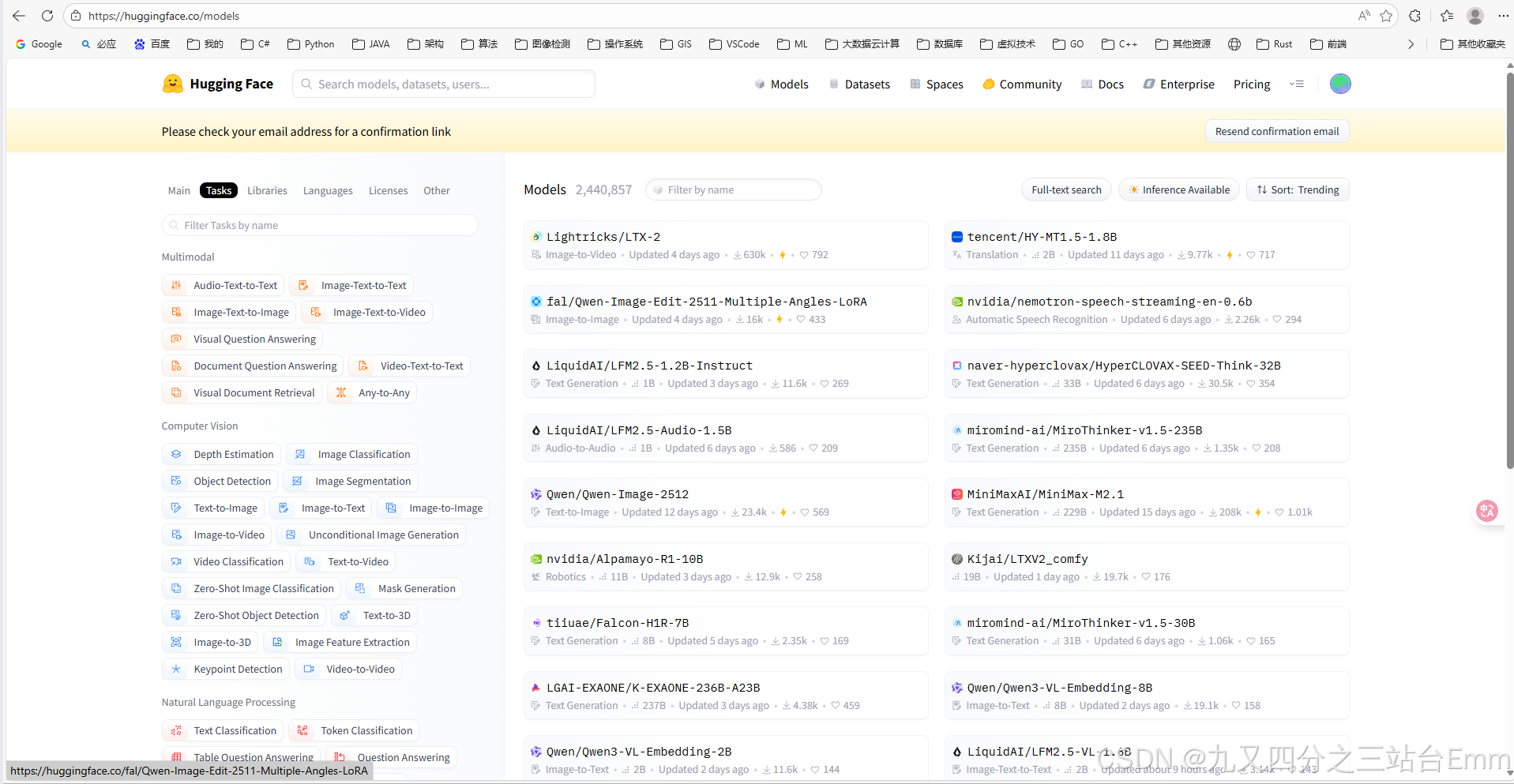
1) 首页的核心定位:Hub 的入口与"发现"面板
官方对 Hub 的定义是:一个集中分享、探索、发现、实验开源机器学习成果的平台,并给出规模级别(模型、数据集、应用数量)用于说明其生态体量。首页用"Browse 2M+ models / Browse 500k+ datasets / Browse 1M+ applications"等入口把这三大资产直接暴露出来。 (Hugging Face)
你可以把首页理解为四件事的聚合:
-
发现(Discovery) :本周趋势模型、热门 Spaces、热门数据集等"流行度视图"。 (Hugging Face)
-
资产入口(Hub Objects) :Models / Datasets / Spaces 三大类资源的统一入口。 (Hugging Face)
-
工具与生态(Open Source Stack) :Transformers、Diffusers、Safetensors、Tokenizers、PEFT、TGI、Accelerate 等开源组件的导览。 (Hugging Face)
-
生产化(Production/Enterprise) :Inference Providers、Inference Endpoints、团队/企业方案与定价入口。 (Hugging Face)
2) 顶部导航:你在首页就能明确"Hub 的信息架构"
首页顶部导航把 Hugging Face 的产品面分成:
-
Models / Datasets / Spaces:三类核心托管对象
-
Docs:文档中心
-
Enterprise / Pricing:企业方案与定价
-
账户入口(Log in / Sign up) (Hugging Face)
这意味着 Hugging Face 的"主业务对象"不是单一模型库,而是一个以Git 仓库化资产 为核心的协作平台(模型、数据集、应用都以仓库形式组织)。 (Hugging Face)
3) 首页的三大内容区:Models / Spaces / Datasets(趋势与入口)
A. Trending Models(本周趋势模型)
首页会列出本周热门模型条目,并显示诸如"更新时间、热度/使用量"等概览指标,提供"Browse 2M+ models"的跳转入口。 (Hugging Face)
进一步进入 Models 体系后,模型被存储在仓库中,继承 Hub 仓库的协作能力,并具备便于发现与使用的属性(例如任务标签、库适配等)。 (Hugging Face)
B. Trending Spaces(热门应用/演示)
首页会展示正在运行或基于特定算力配额(例如 ZeroGPU)运行的热门 Spaces,并提供"Browse 1M+ applications"的入口。 (Hugging Face)
Spaces 的官方定位是:用于托管机器学习 Demo 应用、展示作品集、对外演示与协作开发。 (Hugging Face)
Spaces 支持多种 SDK/框架,其中 Gradio 与 Streamlit 是最常见的两类。 (Hugging Face)
C. Trending Datasets(热门数据集)
首页同样列出数据集趋势条目并提供"Browse 500k+ datasets"入口。 (Hugging Face)
数据集在 Hub 上的定位是:社区策展的数据资产集合,通常配套 Dataset Card,并可能提供 Dataset Viewer 来浏览样本与字段。 (Hugging Face)
4) "The Home of Machine Learning"区:Hub 的协作价值主张
首页在中段用几段"平台价值"描述 Hub 的主张:
- 协作平台(collaboration platform):托管并协作开发公开模型、数据集、应用
- Move faster:配合 HF 开源栈更快落地
- 多模态覆盖 :文本、图像、视频、音频、3D 等任务范式 (Hugging Face)
这里体现 Hugging Face 的差异点:它不只提供"下载模型",还强调围绕模型/数据/应用的协作闭环 。而"仓库化"是实现协作与可追溯的基础。 (Hugging Face)
5) "Accelerate your ML"区:从社区到生产(推理与算力产品)
首页把"生产化能力"主要拆成三块:
A. Team & Enterprise(安全与治理)
强调企业级安全与治理能力(例如访问控制、支持、审计等),并给出团队方案起价。 (Hugging Face)
B. Inference Providers(统一 API 的"多提供商推理")
Inference Providers 的官方描述是:通过统一 API 访问大量模型,并由多家推理提供商供给算力,同时集成到 Hugging Face 客户端 SDK。 (Hugging Face)
C. Inference Endpoints(专用托管推理服务)
Inference Endpoints 的官方描述聚焦在"生产部署体验":减少基础设施配置与运维,把注意力放在模型与用户上。 (Hugging Face)
同时,它可以从 Hub 上的模型直接构建 Endpoint,并支持通过 huggingface_hub 进行编程化管理。 (Hugging Face)
6) "Our Open Source"区:首页列出的开源组件意味着什么
首页把 Hugging Face 的开源栈以"目录"方式列出(例如 Transformers、Diffusers、Safetensors、Tokenizers、PEFT、Text Generation Inference、Accelerate 等)。 (Hugging Face)
从首页信息架构可以读出一个重要结论:
- Hub(huggingface.co)是"资产与协作层" (托管模型/数据/应用,提供权限、版本、展示与分发) (Hugging Face)
- 开源库是"训练/推理/分发的工具层" (Transformers/Diffusers/Tokenizers/PEFT/TGI/Accelerate 等在本地或云端运行) (Hugging Face)
- Endpoints/Providers 是"生产托管与算力层" (把工具层以托管形态提供出来) (Hugging Face)
7) 账号与定价:你需要知道的"使用边界"
首页给出 Pricing 入口;定价页描述 Hub 的免费层定位为"探索、实验、协作与构建",并强调其 Git 协作属性与内建 ML 功能。 (Hugging Face)
企业/团队文档则说明了 Team/Enterprise 在 Spaces/Jobs 等方面的功能差异与配额(例如运行单元、ZeroGPU 配额、Dev Mode、Custom domain 等)。 (Hugging Face)
8) 你访问 huggingface.co 首页时,最常见的 6 种"正确打开方式"
- 找模型 :从首页"Browse models"进入 Models,按任务/参数规模/许可证/框架筛选。 (Hugging Face)
- 找数据集 :进入 Datasets,结合 Dataset Viewer 快速验数。 (Hugging Face)
- 找可用 Demo :进入 Spaces,直接试用社区应用或 fork 修改。 (Hugging Face)
- 做展示/交付 :把你的模型或应用做成 Space(Gradio/Streamlit),用于演示与共享。 (Hugging Face)
- 做生产推理 :走 Inference Providers(统一 API)或 Inference Endpoints(专用部署)。 (Hugging Face)
- 做团队治理 :上 Team/Enterprise 以获得安全、权限、审计与支持等能力。 (Hugging Face)