摘要
本文是2025 级研究生选修课《动手学 AI:人工智能通识与实践》的全模块系统性总结,核心目标是梳理课程 12 个章节的核心理论知识,形成 "认知→基础→核心→应用→伦理" 的结构化知识体系,便于后续复习检索。内容遵循课程知识脉络,覆盖 AI 本质与发展、问题求解算法、机器学习范式、深度学习架构、大语言模型原理、多模态 AI 与智能体、行业应用及伦理治理等核心模块,聚焦知识点的体系化梳理与沉淀。
- 课程学生学习链接(需账号登录):https://www.chaoxing.com/
- 同步内容的阿里云公开学习链接:https://university.aliyun.com/lesson/ai-general,可搭配视频回看深化理解。
一、AI 通识入门:本质、发展与分类(课程 1-2 章)
核心:建立 AI 的基础认知,明确技术边界与发展脉络
1.1 人工智能的本质定义
- 核心定义:人工智能是用计算机模拟、延伸和扩展人类智能的技术集合,核心是 "让机器完成那些如果由人来做则需要智能的事情",不要求机器具备自主意识,仅需实现 "智能做事" 的效果。
- 核心特征:区别于传统计算机技术的 "确定性逻辑",AI 具有高度不确定性、高度复杂性,核心是在有限计算资源下获得近似最优解。
1.2 人工智能的两大分类
|--------------|-------------------------|-----------------|-------------------|
| 分类 | 核心目标 | 本质区别 | 典型场景 |
| 强人工智能(科幻 AI) | 研制与人类同等甚至更优的智能机器,具备自主意识 | 拥有自主意识,目的是 "造人" | 科幻电影中的智能机器人 |
| 弱人工智能(科学 AI) | 让机器在特定任务中展现智能,辅助人类工作 | 无自主意识,目的是 "造工具" | 语音助手、图像识别、大模型文本生成 |
1.3 人工智能的三大发展阶段
- 推理期(1956 年 - 20 世纪 60 年代中后期):核心是逻辑推理(Logic Reasoning),出发点是 "数学家真聪明",典型成就为自动定理证明系统(如西蒙与纽厄尔的 "Logic Theorist" 系统),依赖人工编写逻辑规则实现智能。
- 知识期(20 世纪 70 年代 - 20 世纪 90 年代初期):核心是知识工程(Knowledge Engineering),出发点是 "知识就是力量",典型成就为专家系统(如费根鲍姆等人的 "DENDRAL" 系统),通过构建知识库和推理规则解决专业领域问题。
- 学习期(20 世纪 90 年代 - 至今):核心是机器学习(Machine Learning),出发点是 "让系统自己学",通过海量数据训练模型,让机器自主学习规律,无需人工编写复杂规则,是当前大模型技术的核心发展阶段。
二、AI 底层逻辑:问题求解与算法基础(课程 3 章)
核心:理解 AI 解决问题的基础思维,铺垫后续技术原理
2.1 计算思维与问题求解
- 计算的本质:利用计算机解决问题的过程,具有组合性(通过简单操作指令组合完成复杂任务)和通用性(同一台计算机加载不同程序可解决不同问题)。
- 问题求解的核心逻辑:遵循 "理论 - 实验 - 观察 - 归纳 - 推理" 的现代科学思想,将复杂问题转化为计算机可执行的算法步骤,借助计算理论将数学解析转化为简单指令组合。
2.2 经典算法:迭代与递归
- 迭代:通过重复执行相同逻辑逐步逼近目标结果,典型案例为二分查找 ------ 每次验证可能范围中间的数,根据反馈缩小查找范围,最终快速找到目标,核心是 "逐步缩小问题规模"。
- 递归:将复杂问题分裂为规模更小的同类子问题,解决子问题后合并结果,典型案例为归并排序 ------ 基本结束条件是数据表仅有 1 个数据项(自然有序),核心步骤为 "分裂→递归排序→归并",体现 "大事化小,小事化了" 的算法思想。
2.3 优化问题与搜索策略
- 优化问题的核心:找到某些问题的最优解,是计算机科学中许多算法的设计目标。
- 枚举策略:从所有可能的情况中搜索答案,核心流程为:确定变量→明确变量取值范围→枚举所有组合→检验组合是否满足条件→输出符合条件的解,适用于问题规模较小、变量取值有限的场景。
- 贪心策略:通过每一步选择局部最优解,最终拼接得到全局可行解,适用于无需严格全局最优、追求高效求解的场景。
三、机器学习:AI 的核心学习范式(课程 4 章)
核心:掌握 AI "数据驱动规律" 的核心逻辑,区分三大学习类型
3.1 机器学习的本质定义
- 核心逻辑:当手上有蕴含特定规律的海量数据时,通过计算机算法分析数据、提取规律,并将规律用于后续同类问题的解决,核心是 "数据驱动规律发现",无需人工编写固定规则。
- 与人工智能、深度学习的关系:人工智能是技术总纲,机器学习是人工智能的核心实现方式,深度学习是机器学习的子集(基于多层神经网络的机器学习方法),三者是 "包含 - 被包含" 的关系。
3.2 机器学习的三大核心范式
|----------|--------------------|-------------|--------------|
| 范式类型 | 核心逻辑 | 数据特征 | 典型任务 |
| 有监督学习 | 学习 "输入数据→标签" 的映射关系 | 数据附带明确标签 | 分类、回归、情感分析 |
| 无监督学习 | 自主挖掘数据的隐含结构 | 数据无标签 | 聚类、异常检测、数据降维 |
| 强化学习 | 通过 "奖励 / 惩罚" 优化行为 | 无固定数据,与环境交互 | 自动驾驶、机器人控制 |
3.3 机器学习的核心流程
- 数据准备:收集数据、清洗数据(处理缺失值、异常值)、划分训练集与测试集;
- 模型选择:根据任务类型选择合适的模型(如分类任务选逻辑回归、聚类任务选 K-Means);
- 模型训练:用训练数据投喂模型,通过损失函数计算预测误差,借助梯度下降等优化算法调整模型参数;
- 模型评估:用测试数据验证模型性能(如分类任务用准确率、回归任务用均方误差);
- 模型部署:将训练好的模型应用于实际场景,处理新数据并输出结果。
四、深度学习:大模型的技术基础(课程 5 章)
核心:理解大模型的 "神经网络骨架"****(实战中,Transformer 架构是搭建企业级大模型的核心骨架,CNN 可直接用于图像识别接口开发,RNN 适用于短文本情感分析场景)
4.1 神经网络的核心概念
- 感知机:神经网络的基本单元,核心逻辑是 "输入→加权计算→激活输出",接收多个输入信号,通过权重分配和激活函数处理后输出单一结果,是构成复杂神经网络的基础。
- 深度学习的定义:基于 "多层神经网络堆叠" 的机器学习方法,层数越多,模型能处理的语义和数据复杂度越高,核心是通过深层网络自动提取数据的多层级特征(浅层特征→复杂特征)。
4.2 核心神经网络结构演进
|----------------|----------------|----------------|------------------|-------------|
| 网络结构 | 核心创新点 | 优势 | 不足 | 典型适用场景 |
| CNN(卷积神经网络) | 局部特征提取 + 参数共享 | 减少参数数量,训练高效 | 无法处理长文本时序依赖 | 图像识别、语音处理 |
| RNN(循环神经网络) | 引入时序依赖,传递上下文状态 | 能处理文本、语音等时序数据 | 梯度消失 / 爆炸,长文本易遗忘 | 短文本分类、语音识别 |
| Transformer 架构 | 自注意力机制 + 并行计算 | 解决长文本依赖,支持并行计算 | 计算复杂度随文本长度呈平方增长 | 大语言模型、长文本生成 |
五、大模型的核心:自然语言处理与大语言模型(课程 6-7 章)
核心:拆解大模型的 "黑盒",掌握文本理解与生成的核心原理
5.1 自然语言处理(NLP)的本质
- 核心目标:搭建人类自然语言与计算机语言之间的桥梁,让计算机实现对自然语言的理解(如文本分类、情感分析)和生成(如文本创作、机器翻译)。
- 核心挑战:自然语言具有歧义性、灵活性、上下文依赖性,需通过技术手段将非结构化的语言数据转化为计算机可处理的格式。
5.2 大语言模型的核心原理
- 输入处理流程:文本→Token 化→向量转换(Embedding)。首先将文本拆分为最小语义单位(Token,如中文词汇、英文单词),再通过 Embedding 层将 Token 转换为数值向量,使计算机能够理解和计算。
- 自注意力机制:大语言模型的核心,通过计算每个 Token 与其他所有 Token 的关联权重(注意力得分),明确文本内部的语义关联(如指代关系、逻辑关系),让模型理解文本的语义结构。
- 文本生成逻辑:采用 "自回归生成" 方式,解码器逐 Token 生成输出内容,每次生成时基于前文信息和模型学习到的语言规律,选择概率最高的下一个 Token,确保生成内容的连贯性和逻辑性。
5.3 生成式人工智能与 Prompt 工程
- 生成式 AI 的核心:区别于传统 "检索式 AI",基于学习到的语言规律生成全新内容,而非简单匹配已有数据,具备创造力和灵活性。
- Prompt 工程的本质:给模型的 "任务指令 + 上下文",核心原则是 "明确任务、提供上下文、设定格式"。模型的推理过程是 "根据 Prompt 从训练学到的规律中匹配最优结果",有效的 Prompt 能大幅提升生成结果的准确性和符合度。
- 模型幻觉:生成式 AI 的常见问题,指模型生成与事实不符的内容,根源是模型输出基于训练数据的统计规律,而非真实世界的事实查询,需通过事实校验机制规避。
六、生成式人工智能:从 "理解" 到 "创造"(课程 8 章)
核心:掌握 AI 的 "内容创造能力",区分不同形态的生成技术
6.1 生成式人工智能的核心定义
生成式 AI 是能 "基于学习到的规律生成全新内容" 的 AI 技术,区别于传统 "检索式 AI"(仅匹配已有数据),核心是通过模型学习数据的分布规律,自主生成符合逻辑、风格一致的新内容。
6.2 生成式 AI 的核心类型(按内容形态)
|-----------|-------------------|----------------------|
| 生成类型 | 核心技术基础 | 典型应用场景 |
| 文本生成 | Transformer 大语言模型 | 文案创作、代码生成、机器翻译 |
| 图像 / 视频生成 | GAN(生成对抗网络)、扩散模型 | 图像创作、视频剪辑、虚拟数字人 |
| 音频生成 | 深度学习音频模型 | 语音合成、音乐创作、声纹克隆 |
| 多模态生成 | 跨模态模型(如 CLIP) | 文本生成图像、图像生成描述、语音生成视频 |
七、计算机视觉:AI 如何 "看世界"(课程 9 章)
核心:理解 AI 的 "视觉感知能力",掌握图像 / 视频处理的技术逻辑
7.1 计算机视觉的核心定义
计算机视觉是让计算机 "理解图像 / 视频内容" 的 AI 技术,核心是将图像 / 视频转化为计算机可处理的数值信息,实现 "目标识别、场景理解、内容分析" 等功能,是 AI 感知世界的核心分支之一。
7.2 计算机视觉的核心挑战
- 图像的歧义性:同一物体在不同角度、光照、遮挡下呈现不同形态(如 "猫" 在逆光、遮挡时易被误识别);
- 高维数据处理:图像是像素组成的高维数据,处理时需平衡 "精度" 与 "计算效率";
- 语义理解鸿沟:计算机能识别 "像素特征",但难理解图像的高层语义(如识别 "杯子" 易,理解 "杯子是用来装水的" 难)。
7.3 计算机视觉的发展历程
- 早期(20 世纪 60-80 年代):基于手工特征提取(如边缘检测、形状匹配),仅能处理简单场景;
- 中期(20 世纪 90 年代 - 2010 年):基于机器学习(如 SVM、决策树),结合手工特征实现基础目标识别;
- 现代(2012 年至今):基于深度学习(如 CNN、Transformer),通过海量图像数据训练模型,实现高精度的复杂场景识别(如人脸识别、自动驾驶视觉感知)。
7.4 计算机视觉的典型应用
- 安防领域:人脸识别、智能监控;
- 自动驾驶:车道线检测、障碍物识别;
- 医疗领域:医学影像诊断(如 CT 影像的肿瘤识别);
- 消费领域:拍照搜物、图像美化。
八、数据应用与可视化:AI 的 "数据支撑"(课程 10 章)
核心:明确数据是 AI 的 "燃料",掌握数据可视化的核心方法
8.1 数据应用与可视化的核心定位
数据是 AI 的 "燃料",而数据可视化是 "让数据更易被理解" 的工具 ------AI 依赖数据训练模型,可视化则帮助人类直观理解 AI 的分析结果、模型决策逻辑。
8.2 数据可视化的核心方法(按数据类型)
|-----------|--------------------|---------------|
| 数据类型 | 可视化方法 | 典型场景 |
| 高维数据 | 降维可视化(如 PCA、t-SNE) | 机器学习特征分布分析 |
| 时空 / 时序数据 | 折线图、热力图、地图轨迹 | 疫情传播趋势、用户行为路径 |
| 网络 / 层次数据 | 节点图、树状图、桑基图 | 社交关系网络、组织架构分析 |
8.3 智能可视分析的价值
智能可视分析是 "AI + 可视化" 的结合:AI 负责处理海量数据、提取核心规律,可视化负责将规律以直观形式呈现,帮助人类快速理解复杂信息(如 "用 AI 分析千万级用户行为数据,再通过可视化呈现用户群体的行为特征")。
九、智能体:生成式 AI 的工程化延伸(课程 11 章)
核心:掌握 AI 的 "自主任务能力",理解智能体的架构与落地场景
9.1 智能体(Agent)的核心定义
智能体是 "大模型 + 工具调用 + 记忆机制 + 任务规划" 的组合体,能够自主理解任务、选择工具、执行流程、反馈结果,无需人工干预即可完成复杂的序列任务,是生成式 AI 落地的高阶形态。
9.2 智能体的核心组件
- 大模型:决策核心,负责语义理解、任务规划和结果生成;
- 工具调用模块:对接外部系统(如数据库查询、API 调用、代码编译工具),扩展智能体的能力边界;
- 记忆机制:存储任务上下文、历史交互记录,支持跨步骤的信息复用;
- 任务规划模块:将复杂任务拆分为可执行的子步骤,规划执行顺序并处理异常情况。
9.3 智能体的典型应用场景
- 智能开发助手:理解需求→生成代码→调用编译工具→检测错误→修复代码;
- 智能客服助手:接收用户咨询→查询知识库→生成回复→记录用户偏好;
- 智能办公助手:整理会议纪要→生成待办事项→对接日程系统→提醒执行。
十、AI 的行业应用与科学价值(课程 12 章)
核心:了解 AI 的实际价值,明确行业落地的核心逻辑
10.1 科学领域的应用(AI for Science)
- 核心价值:利用 AI 技术驱动科学创新的新范式,通过数据、算法和算力的融合,提升科研效率并突破传统学科边界。
- 典型案例:破解蛋白质结构:DeepMind 的 AlphaFold2 在蛋白质结构预测大赛中夺冠,预测精度达到人类利用冷冻电镜观察的水平;
- AI 药物设计:华盛顿大学团队利用 AI 精准从头设计穿过细胞膜的大环多肽分子,开辟全新口服药物设计途径。
10.2 行业落地的核心逻辑
- 核心原则:"AI 作为辅助、允许出错",在多数行业场景中,AI 的定位是提升效率、降低成本,而非完全替代人类,需结合人类判断确保结果准确性。
- 典型行业场景:电商(商品推荐、文案生成)、金融(风险控制、智能投顾)、医疗(影像诊断、药物研发)、工业(智能制造、质量检测)。
十一、AI 伦理挑战与治理(课程 13 章)
核心:规避 AI 的应用风险,掌握伦理治理的核心措施
11.1 核心伦理问题(同步课件内容)
课件明确的 AI 伦理核心问题包括 6 个维度:
- 公平性(Fairness):AI 决策是否公平无偏?(如模型是否对特定群体存在歧视性输出)
- 透明度(Transparency):AI 如何做决策?能解释吗?(即 "黑箱" 问题,模型决策过程难以追溯)
- 问责制(Accountability):出错时谁负责?(开发者、使用者、模型提供商的责任界定)
- 隐私(Privacy):我的数据被如何使用和保护?(训练数据、用户输入中的隐私信息泄露风险)
- 安全(Safety & Security):AI 系统是否可靠、防攻击?(模型被恶意篡改、生成有害内容的风险)
- 人类控制(Human Control):最终决策权在谁手中?(AI 是否会替代人类的关键决策,丧失人类主导权)
11.2 伦理治理的核心措施
- 数据治理:对训练数据和用户输入进行脱敏处理,去除隐私信息,确保数据采集和使用合规;
- 内容审核:建立敏感词拦截、输出内容审核机制,防止生成违法违规内容;
- 偏见矫正:优化训练数据,减少数据中的偏见,在模型设计中加入公平性约束;
- 透明化与可解释性:提升 AI 决策过程的透明度,让用户了解模型输出的依据,便于责任界定;
- 权限管控:明确 AI 系统的决策边界,关键场景保留人类最终决策权,避免完全依赖 AI。
十二、总结:课程知识体系图谱
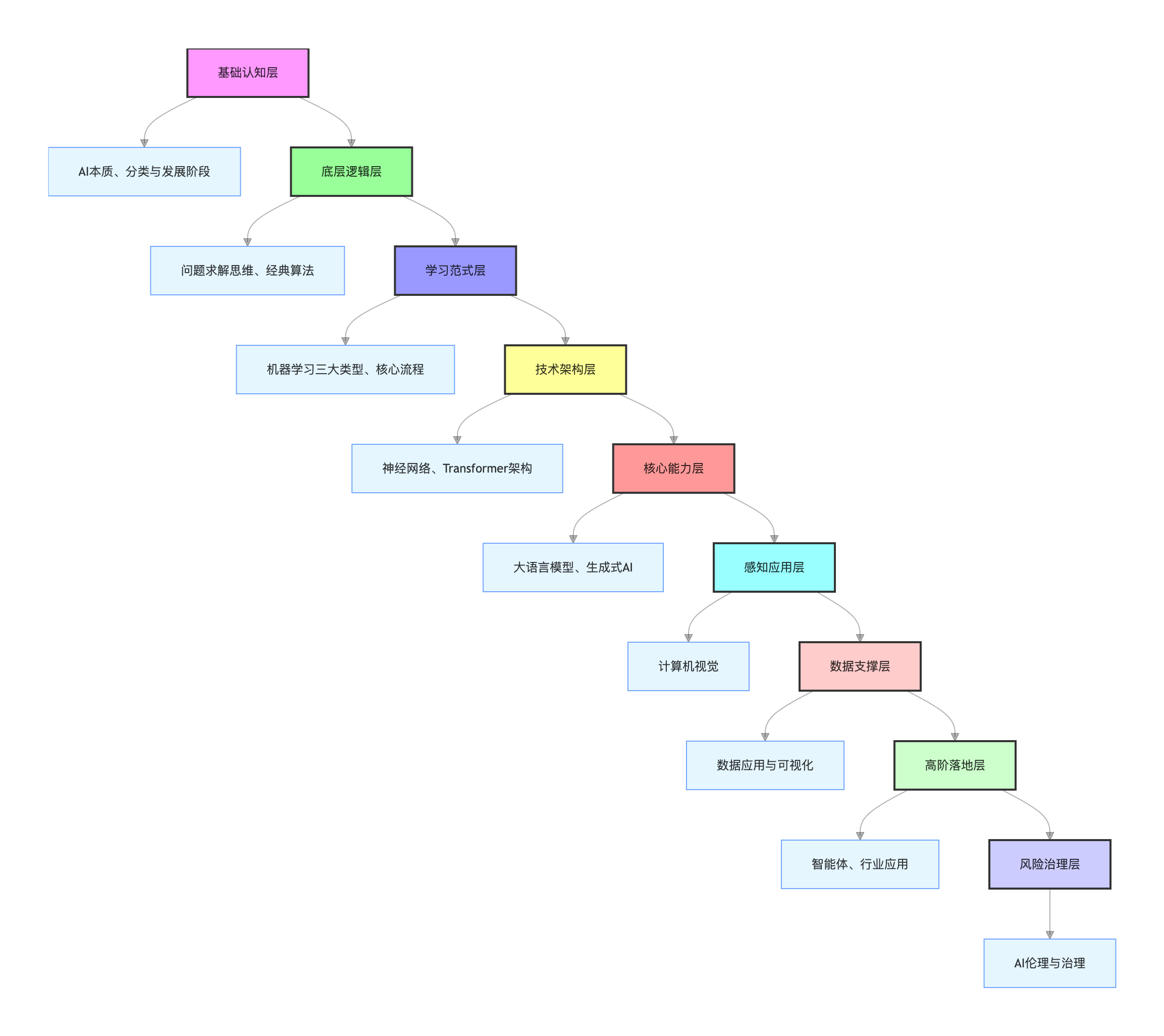
🌟 复习使用指南:
- 快速检索:通过架构图定位模块,再查找对应章节;
- 实战衔接:学习完理论后,可搭配导航页「Java+AI 工程化实践」板块的《Spring AI 1.0 核心功能脉络》,实现 "理论→工具落地";