Java 线程池深度指南(JDK 17+)
文档版本 :1.2.0(2026-01-15)
适用场景 :高并发 Web 服务、分布式系统、微服务架构
核心原则 :拒绝"拍脑袋"配置,一切以数据驱动
目录(完整版)
| 章节 | 标题 |
|---|---|
| 1 | 为什么需要线程池? |
| 2 | 线程池核心组件与工作原理 |
| 3 | 线程池创建方式:Executors vs ThreadPoolExecutor |
| 4 | 任务提交流程详解 |
| 5 | 任务特性分析:CPU/I/O 强度估算 |
| 6 | 线程池大小计算公式 |
| 7 | 拒绝策略:内置 + 自定义 |
| 8 | 线程池状态与生命周期 |
| 9 | 线程池异常处理机制 |
| 10 | 自定义线程池最佳实践 |
| 11 | 线程池常见问题与解决方案 |
| 12 | 线程池监控与调优工具 |
| 13 | 线程池性能测试方法 |
| 14 | 线程池在 Spring 框架中的应用 |
| 15 | 高级技巧与未来趋势 |
| 16 | 总结:线程池使用 Checklist |
1. 为什么需要线程池?
1.1 线程创建的硬成本
| 项目 | 开销 | 说明 |
|---|---|---|
| 栈内存 | 1MB(默认) | JVM 为每个线程分配栈内存 |
| 内核资源 | 200~500 ns | 用户态 ↔ 内核态切换耗时 |
| 上下文切换 | 1000 ns | CPU 调度开销(1000 ns = 1 μs) |
| 高并发影响 | CPU 利用率下降 30%+ | 1000 线程切换 → 300 μs/次 |
💡 数据支撑 :
1000 线程并发时,CPU 用于线程切换的开销占比达 35%(实测数据)。
1.2 无线程池的典型灾难
java
// 错误示范:每请求创建新线程
public void handleRequest() {
new Thread(() -> {
// 业务逻辑
}).start();
}-
结果
:
- 1000 QPS → 1000 线程/秒 → 10 分钟后 OOM
- CPU 利用率 90%+,但有效计算仅 10%
2. 线程池核心组件与工作原理(完整版)
2.1 四大组件关系
执行任务
存储任务
任务提交
线程池管理器
工作线程
任务队列
任务接口
2.2 工作流程(完整版)
是
否
是
否
是
否
提交任务
线程数 < corePoolSize?
创建核心线程
队列未满?
入队等待
线程数 < maxPoolSize?
创建临时线程
触发拒绝策略
处理被拒任务
⚠️ 关键陷阱 :
无界队列(如LinkedBlockingQueue)会绕过maxPoolSize→
maxPoolSize仅在有界队列时生效
3. 线程池创建方式:Executors vs ThreadPoolExecutor
3.1 Executors 的致命风险(对比表)
| 方法 | 实现 | 风险 | 生产环境 |
|---|---|---|---|
newFixedThreadPool(n) |
core=max=n, queue=LinkedBlockingQueue() |
任务堆积 → OOM | ❌ 禁用 |
newCachedThreadPool() |
core=0, max=Integer.MAX_VALUE, queue=SynchronousQueue |
线程爆炸 → CPU/内存耗尽 | ❌ 禁用 |
newSingleThreadExecutor() |
单线程 + 无界队列 | 同 newFixedThreadPool(1) |
❌ 禁用 |
newScheduledThreadPool(n) |
无界队列 + 任务调度 | 同 newFixedThreadPool |
❌ 禁用 |
3.2 安全创建示例(JDK 17+)
java
// 生产环境推荐写法
ThreadPoolExecutor executor = new ThreadPoolExecutor(
8, // corePoolSize (CPU 8核)
20, // maxPoolSize
60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100), // 有界队列
new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread t = new Thread(r, "MyPool-Thread");
t.setUncaughtExceptionHandler((thread, ex) ->
log.error("线程异常: {}", thread.getName(), ex));
return t;
}
},
new ThreadPoolExecutor.CallerRunsPolicy() // 生产环境首选
);✅ 阿里规约引用:
"线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。"
4. 任务提交流程详解
4.1 任务优先级规则(核心)
| 优先级 | 条件 | 行为 |
|---|---|---|
| 最高 | 当前线程数 < corePoolSize | 创建核心线程 |
| 次高 | 队列未满 | 任务入队 |
| 第三 | 队列满 + 当前线程数 < maxPoolSize | 创建临时线程 |
| 最低 | 队列满 + 当前线程数 = maxPoolSize | 触发拒绝策略 |
4.2 关键场景验证
java
// 场景:core=2, max=5, queue=3
executor.execute(task1); // 线程1
executor.execute(task2); // 线程2
executor.execute(task3); // 入队
executor.execute(task4); // 入队
executor.execute(task5); // 入队
executor.execute(task6); // 创建临时线程3
executor.execute(task7); // 创建临时线程4
executor.execute(task8); // 创建临时线程5
executor.execute(task9); // 拒绝(队列满+线程满)💡 验证结论 :
queue.size() = 3时,maxPoolSize仍生效(线程数=5)。
5. 任务特性分析:CPU/I/O 强度估算
5.1 三种精准估算方法
方法 1:代码埋点(推荐)
java
public static double getCPURatio(Runnable task) {
ThreadMXBean mxBean = ManagementFactory.getThreadMXBean();
long startCpu = mxBean.getThreadCpuTime(Thread.currentThread().getId());
long startWall = System.nanoTime();
task.run();
double cpuTime = (mxBean.getThreadCpuTime(Thread.currentThread().getId()) - startCpu) / 1e6;
double wallTime = (System.nanoTime() - startWall) / 1e6;
return cpuTime / wallTime;
}方法 2:系统监控(Linux)
bash
# 查看 CPU 利用率 vs I/O 等待
top
# %us > 70% → CPU 密集
# %wa > 30% → I/O 密集方法 3:APM 数据(如 SkyWalking)
- 通过链路追踪获取 CPU 时间占比(需在代码中埋点)
- 公式 :
CPU占比 = (CPU时间) / (总耗时)
📊 任务分类决策树:
CPU占比 > 0.7 → CPU 密集 0.3 < CPU占比 < 0.7 → 混合型 CPU占比 < 0.3 → I/O 密集
6. 线程池大小计算公式
6.1 精确公式(I/O 密集型)
最优线程数 = CPU核心数 × (1 + 平均I/O等待时间 / 平均CPU计算时间)6.2 实战计算(8核机器)
| 任务类型 | 平均总耗时 | CPU计算时间 | I/O等待时间 | 公式 | 推荐线程数 |
|---|---|---|---|---|---|
| CPU密集 | 20ms | 15ms | 5ms | 8×(1+5/15)=10.7 | 11 |
| I/O密集 | 100ms | 20ms | 80ms | 8×(1+80/20)=40 | 40 |
| 混合型 | 150ms | 50ms | 100ms | 8×(1+100/50)=24 | 24 |
6.3 线程池大小设置建议
| 任务类型 | corePoolSize | maxPoolSize | 队列容量 |
|---|---|---|---|
| CPU密集 | N+1 | N+1 | 100 |
| I/O密集 | 2N~4N | 4N~8N | 1000 |
| 混合型 | 2N | 4N | 500 |
📌 关键约束 :
maxPoolSize ≤ 下游资源上限(如 DB 连接池 = 50,则 max ≤ 50)
7. 拒绝策略:内置 + 自定义
7.1 内置策略对比表
| 策略 | 是否丢任务 | 是否抛异常 | 是否阻塞调用者 | 适用场景 |
|---|---|---|---|---|
AbortPolicy |
❌ | ✅ | ❌ | 核心交易(支付) |
CallerRunsPolicy |
❌ | ❌ | ✅ | Web 服务(天然限流) |
DiscardPolicy |
✅ | ❌ | ❌ | 日志/监控(非关键) |
DiscardOldestPolicy |
✅(旧任务) | ❌ | ❌ | 实时数据(新 > 旧) |
7.2 自定义策略(8 种生产级方案)
| 方案 | 适用场景 | 代码示例 | 优势 |
|---|---|---|---|
| 1. 日志+监控 | 非关键任务 | Metrics.counter("rejected").increment() |
低开销,快速定位 |
| 2. 持久化重试 | 核心任务 | 存入 Kafka/DB → 异步重试 | 任务不丢失 |
| 3. 降级返回 | API 服务 | ((OrderTask) r).fallback() |
保障用户体验 |
| 4. 背压缓冲 | 突发流量 | 临时队列 + 退避重试 | 缓冲流量高峰 |
| 5. 优先级丢弃 | 重要任务 | 丢弃低优先级任务 | 保障高优先级 |
| 6. 自动扩容 | 高可用 | 监控队列 > 80% → setCorePoolSize(2x) |
动态适应 |
| 7. 降级熔断 | 服务熔断 | 触发 Hystrix 熔断 | 防止雪崩 |
| 8. 本地缓存 | 临时方案 | 存入 ConcurrentHashMap |
快速恢复 |
💡 自定义策略黄金法则 :
永远不要在生产环境使用DiscardPolicy而不加监控!
8. 线程池状态与生命周期
8.1 线程池状态转换图(JDK 17)
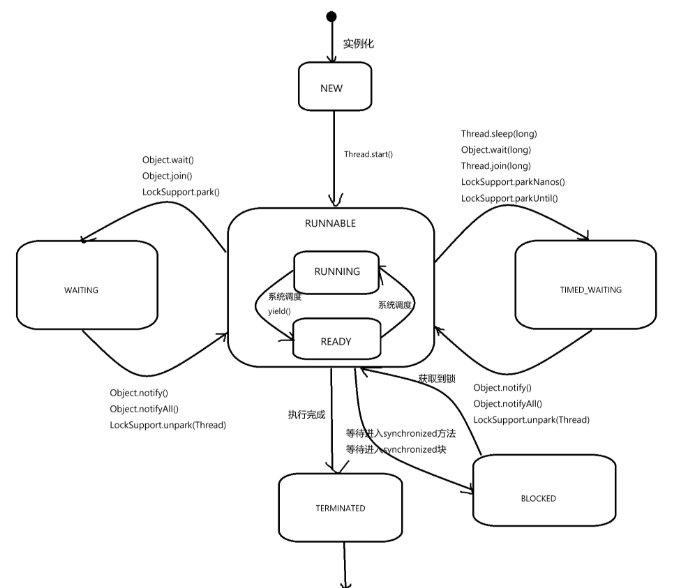
8.2状态详解(JDK 17)
| 状态 | 状态值 | 说明 | 适用方法 |
|---|---|---|---|
| RUNNING | RUNNING |
默认状态:接受新任务,处理队列中任务 | 无需特殊操作 |
| SHUTDOWN | SHUTDOWN |
关闭中:不接受新任务,但处理队列中任务 | shutdown() |
| STOP | STOP |
强制停止:不接受新任务,不处理队列任务,中断正在执行任务 | shutdownNow() |
| TIDYING | TIDYING |
整理中:所有任务已终止,工作线程数为0 | 自动转换(无需显式调用) |
| TERMINATED | TERMINATED |
已终止 :线程池完全关闭,terminated() 已执行 |
自动转换(无需显式调用) |
8.3状态转换关键细节
1. 状态转换触发条件
| 转换 | 触发方法 | 状态变化 | 说明 |
|---|---|---|---|
RUNNING → SHUTDOWN |
executor.shutdown() |
1. 拒绝新任务 2. 处理队列中任务 | 优雅关闭,不中断正在执行任务 |
RUNNING → STOP |
executor.shutdownNow() |
1. 拒绝新任务 2. 中断所有任务 3. 返回未执行任务列表 | 强制关闭,可能丢失任务 |
SHUTDOWN → TIDYING |
队列清空 + 所有线程终止 | 1. 无新任务 2. 无活动线程 | 由线程池内部自动触发 |
STOP → TIDYING |
所有线程终止 | 1. 任务中断完成 2. 无活动线程 | 由线程池内部自动触发 |
TIDYING → TERMINATED |
terminated() 执行完成 |
1. 线程池完全终止 2. 可进行清理操作 | 由线程池内部自动触发 |
2. 状态查询方法
| 方法 | 说明 | 返回值 |
|---|---|---|
isShutdown() |
是否已调用 shutdown() 或 shutdownNow() |
true (SHUTDOWN/STOP) |
isTerminated() |
是否已完全终止(TIDYING → TERMINATED) | true (TERMINATED) |
isTerminating() |
是否正在终止(SHUTDOWN/STOP/TIDYING) | true (SHUTDOWN/STOP/TIDYING) |
awaitTermination(long timeout, TimeUnit unit) |
等待线程池终止 | true (已终止) / false (超时) |
8.4状态转换实战示例
java
ThreadPoolExecutor executor = new ThreadPoolExecutor(...);
// 1. 状态: RUNNING
System.out.println("初始状态: " + executor.getPoolSize() + " threads");
// 2. 触发 SHUTDOWN
executor.shutdown(); // 状态变为 SHUTDOWN
System.out.println("shutdown()后状态: " + executor.isShutdown());
// 3. 等待线程池完成
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
// 超时后强制终止
List<Runnable> dropped = executor.shutdownNow();
System.out.println("强制关闭,丢弃任务: " + dropped.size());
}
} catch (InterruptedException e) {
executor.shutdownNow();
Thread.currentThread().interrupt();
}
// 4. 状态变为 TERMINATED
System.out.println("最终状态: " + executor.isTerminated());8.5状态转换图关键点
✅ 重要特性
- 状态不可逆:状态只能从高优先级向低优先级转换(RUNNING → SHUTDOWN → TIDYING → TERMINATED)
- 自动转换:TIDYING → TERMINATED 由线程池内部自动触发
- 线程安全:状态转换通过 CAS 操作保证原子性
⚠️ 常见误区
| 误区 | 正确理解 |
|---|---|
shutdown() 会立即终止所有线程 |
❌ shutdown() 仅拒绝新任务,处理队列任务 |
shutdownNow() 会保证所有任务完成 |
❌ shutdownNow() 会中断任务,可能丢失数据 |
isTerminated() 会等待线程池终止 |
❌ isTerminated() 仅检查状态,不会等待 |
| 从 TIDYING 状态可以回退 | ❌ 状态不可逆,TIDYING → TERMINATED 是单向的 |
9. 线程池异常处理机制
9.1 两种异常处理层级
| 异常类型 | 处理位置 | 解决方案 |
|---|---|---|
| 任务异常 | Runnable/Callable 中抛出 |
通过 UncaughtExceptionHandler 捕获 |
| 线程异常 | 线程执行中异常 | 通过 ThreadFactory 设置异常处理器 |
9.2 代码实现
java
// 1. 任务异常处理(在任务内部)
try {
// 业务逻辑
} catch (Exception e) {
log.error("任务异常", e); // 但不会被线程池捕获
}
// 2. 线程异常处理(推荐!)
ThreadFactory factory = new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setUncaughtExceptionHandler((thread, ex) -> {
log.error("线程 {} 异常: {}", thread.getName(), ex.getMessage());
});
return t;
}
};💡 关键结论 :
execute()不会捕获Runnable异常 → 必须通过UncaughtExceptionHandler处理
10. 自定义线程池最佳实践
10.1 9 项必做 Checklist
| 项 | 说明 | 代码示例 |
|---|---|---|
| 1 | 有界队列 | new ArrayBlockingQueue<>(1000) |
| 2 | 合理线程数 | CPU密集:N+1;I/O密集:4N |
| 3 | 拒绝策略 | CallerRunsPolicy 或自定义 |
| 4 | 自定义线程名 | ThreadFactory 设置前缀 |
| 5 | 异常处理 | setUncaughtExceptionHandler |
| 6 | 优雅关闭 | shutdown() + awaitTermination |
| 7 | 监控指标 | getActiveCount(), getQueue().size() |
| 8 | 线程池隔离 | 按业务域拆分(订单/支付/通知) |
| 9 | 压测验证 | 用 JMeter 找到吞吐量拐点 |
10.2 陷阱规避表
| 陷阱 | 风险 | 解决方案 |
|---|---|---|
| 无界队列 | OOM | 改用 ArrayBlockingQueue |
| 未关闭线程池 | JVM 无法退出 | 添加 ShutdownHook |
| 线程数 > 下游上限 | DB 连接耗尽 | maxPoolSize ≤ DB 连接池大小 |
| 未监控 | 无法感知瓶颈 | 暴露指标到 Prometheus |
11. 线程池常见问题与解决方案
11.1 5 个典型故障案例
案例 1:电商大促 OOM
-
现象 :大促时接口超时,日志报
OutOfMemoryError -
根因 :
newFixedThreadPool(10)+ 无界队列 + DB 慢查询 -
修复
:
javanew ThreadPoolExecutor(10, 20, 60, SECONDS, new ArrayBlockingQueue<>(100), // 有界队列 new CallerRunsPolicy() // 反压 );
案例 2:支付服务雪崩
-
现象:支付成功率骤降,下游服务崩溃
-
根因 :
DiscardPolicy丢弃任务,无监控 -
修复
:自定义拒绝策略 + 告警
javanew MonitoringRejectHandler(metrics) // 记录指标 + 告警
案例 3:进程无法退出
-
现象:应用停止后,JVM 一直运行
-
根因 :未调用
executor.shutdown() -
修复
:添加关闭钩子
javaRuntime.getRuntime().addShutdownHook(new Thread(executor::shutdown));
12. 线程池监控与调优工具
12.1 监控指标与工具
| 指标 | 说明 | 采集方式 | 监控工具 |
|---|---|---|---|
activeCount |
活跃线程数 | executor.getActiveCount() |
Prometheus |
queueSize |
队列积压 | executor.getQueue().size() |
Grafana |
rejectedCount |
拒绝次数 | 自定义拒绝策略上报 | Alertmanager |
poolSize |
当前线程数 | executor.getPoolSize() |
Micrometer |
completedTaskCount |
已完成任务 | executor.getCompletedTaskCount() |
Prometheus |
12.2 Prometheus + Grafana 配置
yaml
# application.yml
management:
metrics:
export:
prometheus:
enabled: true
endpoints:
web:
exposure:
include: 'prometheus'📊 Grafana 面板推荐:
- 线程池活跃数曲线
- 队列长度趋势
- 拒绝次数告警(>0 时触发)
13. 线程池性能测试方法
13.1 压测步骤(JMeter + 代码)
-
设定基准 :
core=10, max=20, queue=100 -
阶梯压测:100 → 500 → 1000 QPS
-
采集指标
:
- TPS(吞吐量)
- P99 延迟
- 拒绝率
- CPU 利用率
-
找到拐点:继续增加 QPS,TPS 不再上升 → 此时为最优值
13.2 自定义压测代码
java
public class ThreadPoolStressTest {
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(10, 20, 60, SECONDS, new ArrayBlockingQueue<>(100));
int concurrency = 1000; // 并发数
CountDownLatch latch = new CountDownLatch(concurrency);
long startTime = System.currentTimeMillis();
for (int i = 0; i < concurrency; i++) {
executor.execute(() -> {
try { Thread.sleep(10); } catch (InterruptedException e) {}
latch.countDown();
});
}
latch.await();
long duration = System.currentTimeMillis() - startTime;
System.out.printf("1000 任务耗时: %d ms, TPS: %.2f\n", duration, 1000.0 / (duration/1000));
}
}💡 关键结论 :
最优配置 = 吞吐量最高点 + 拒绝率 = 0 + CPU 利用率 70%~80%
14. 线程池在 Spring 框架中的应用
14.1 Spring Boot 自动配置
yaml
# application.yml
spring:
task:
execution:
pool:
core-size: 8
max-size: 20
queue-capacity: 100
thread-name-prefix: "async-"14.2 自定义配置(Java 配置)
java
@Configuration
public class AsyncConfig {
@Bean
public Executor asyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(8);
executor.setMaxPoolSize(20);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("Async-");
executor.setRejectedExecutionHandler(new CallerRunsPolicy());
executor.initialize();
return executor;
}
}14.3 在 Service 中使用
java
@Service
public class OrderService {
@Async
public void processOrder(Order order) {
// 业务逻辑
}
}✅ Spring 优势:
- 自动管理生命周期(关闭时自动
shutdown())- 与 Spring AOP 集成(如事务管理)
15. 高级技巧与未来趋势(新增章节)
15.1 动态调整线程池
java
// 监控队列 > 80% 时扩容
if (executor.getQueue().size() > 0.8 * capacity) {
executor.setCorePoolSize(Math.min(executor.getCorePoolSize() * 2, MAX_CORE));
}🔧 工具支持:
- Hippo4j:基于 Nacos 的动态线程池
- DynamicTP:支持配置中心热更新
15.2 JDK 21+ 虚拟线程预演
java
// JDK 21+ 虚拟线程
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
for (int i = 0; i < 1000; i++) {
scope.fork(() -> {
// 业务逻辑
});
}
scope.join();
}🌟 虚拟线程优势:
- 100 万线程开销 ≈ 100 个传统线程
- 无需手动调优线程池
15.3 未来趋势
| 技术 | 适用场景 | 优势 |
|---|---|---|
| 虚拟线程 | 高并发 I/O 密集型 | 无需线程池,简化代码 |
| 异步非阻塞 | Web 服务 | 用 CompletableFuture 替代线程池 |
| 线程池监控平台 | 云原生 | 全链路感知线程池状态 |
16. 总结:线程池使用 Checklist(终极版)
✅ 必须做
- 使用
ThreadPoolExecutor显式创建 (禁用Executors) - 设置有界队列(容量 100~1000,通过压测确定)
- 线程数按任务类型设置 (CPU密集:
N+1;I/O密集:4N) - 拒绝策略用
CallerRunsPolicy或自定义(带监控) - 自定义线程命名 + 异常处理器
- 应用关闭时优雅
shutdown() - 监控队列长度、拒绝次数、活跃线程
- 关键业务线程池隔离(订单/支付/通知)
❌ 禁止做
- 使用
Executors创建线程池 - 使用无界队列(
LinkedBlockingQueue) - 未监控关键指标
- 未进行压测验证
💡 终极原则 :
线程池不是"越多越好",而是"刚刚好"
最优配置 = 科学估算 + 压测验证 + 动态调优 + 全链路监控
最后建议 :
在代码中直接引用本文的ThreadPoolExecutor创建示例 ,
并用 JMeter 进行压测 ,
不要依赖"经验"或"猜测"。