VsusFL:基于变量怀疑度的新手程序故障定位方法
基本信息
The Journal of Systems & Software 2023
博客贡献人
谷雨
作者
Zheng Li, Shumei Wu, Yong Liu, Jitao Shen, Yonghao Wu, Zhanwen Zhang, Xiang Chen
标签
Novice programs, Fault localization, Variable value sequence, Sequence mapping
新手程序;故障定位;变量值序列;序列映射
摘要
自动定位错误语句是高效学习编程的一项关键需求。现有大多数自动化故障定位技术是在商业项目或知名开源项目上开发和评估的,在新手程序上表现不佳。本文提出一种面向新手程序的新型故障定位技术 VsusFL(基于变量怀疑度的故障定位方法)。该技术受人工程序调试过程的启发,充分利用变量值序列的特性:通过追踪变量值的变化,判断变量的中间状态是否正确,进而为新手程序报告潜在的错误语句。本文实现了 VsusFL,并在 422 个真实的错误新手程序上开展实证研究。实验结果表明,在 TOP-1、TOP-3 和 TOP-5 指标上,VsusFL 的性能显著优于 Grace、ANGELINA、VSBFL、基于频谱的故障定位(SBFL)和基于变量的故障定位(VFL)。具体而言,相较于表现最佳的基准方法 Grace,VsusFL 在上述三个指标上分别能多定位 90%、35% 和 9% 的错误语句。此外,通过分析 VsusFL 与其他技术的相关性,发现它们之间存在弱相关性 ------ 这是因为不同技术在不同程序上各有优势,意味着通过策略性整合 VsusFL 与其他方法,有望进一步提升故障定位性能。
1. 引言
信息技术的快速普及为程序设计教育与培训带来了新的机遇。友好的人机交互编程方法是高效学习编程的关键,而其中最核心的需求之一是在编程过程中准确定位故障并提供有价值的反馈。
通常,新手在学习编程的过程中会遇到各类故障。其中,编译错误、运行时错误等非逻辑错误,现代编译器一般能检测到甚至自动修复。但对于能够成功编译的逻辑错误,开发者通常需要在程序中插入断言,通过追踪错误的变量值来查找错误语句。然而,新手往往缺乏编程经验,难以通过人工调试快速、准确地定位和修复故障。
提升学生编程效率的一个有效途径是自动化调试。软件调试通常包括三个阶段:程序检查、故障定位和错误修复。在调试过程中,故障定位是最耗时的环节之一,也是错误修复的前提,这促使众多学者对自动化故障定位技术展开研究。现有自动化故障定位技术已被开发者广泛使用,其核心是生成可疑实体(如语句或函数)列表,且大多数错误实体通常排在列表前列(Pearson 等,2017)。目前已提出多种不同的故障定位方法:例如,Abreu 等(2007)利用覆盖信息为每个语句分配不同的怀疑度;Moon 等(2014)、Papadakis 和 Le Traon(2015)通过变异程序来定位故障;Zhou 等(2012)提出 BugLocator 方法,利用信息检索技术定位相关的错误文件。
尽管已有大量研究针对成熟开源项目和商业软件中的故障定位技术展开,但由新程序员编写的新手程序尚未得到充分研究。现有研究指出,新手程序与商业或开源环境中有经验开发者编写的程序存在显著差异。新手程序员倾向于回避复杂操作(认为这些操作难度较高),且常使用重复的代码结构,而非更复杂的函数 / 类。因此,新手程序通常自定义函数和分支结构较少,大部分代码集中在少数语句块中。这最终导致传统故障定位技术在新手程序的故障识别中表现不佳。
传统故障定位技术应用于新手程序的主要挑战在于,它们依赖于执行路径和测试用例结果。这些直接或间接依赖覆盖信息的技术,在测试用例能为语句提供更多独特信息时更有效 ------ 因为它们可以通过对比通过和失败测试用例的执行路径,缩小故障定位的范围。然而,新手程序的自定义函数和分支结构有限,代码被约束在单个或少数几个语句块中,导致所有测试用例的执行路径较为相似。这种相似性使得测试用例的执行路径和结果完全相同或近乎相同。因此,若高频执行的代码块中包含故障,所有受影响的测试用例都可能失败,许多故障定位技术便无法在新手程序中取得理想效果。例如,Qi 等(2013)在 15 种主流故障定位技术上对真实新手程序进行实验,结果表明这些技术表现较差;Araujo 等(2016)尝试将基于频谱的故障定位(SBFL)应用于新手程序,发现近 40% 的新手程序甚至无法满足有效故障定位技术的前提条件,因为其中部分程序无法通过任何一个测试用例。
因此,传统故障定位方法难以通过对比执行路径和结果来区分新手程序中的测试用例差异。基于此,有必要提出一种新型故障定位方法,从其他角度分析测试用例的差异,从而实现新手程序中故障的精准定位。观察发现,在人工程序调试过程中,开发者通常会使用断点调试,判断测试用例执行过程中变量的变化是否符合预期。变量变化与预期的偏差往往意味着程序存在故障,且这一过程不受代码语句块或程序分支的影响。基于这一观察,我们推测:对比变量序列是区分新手程序中测试用例的可行方案,且有助于实现高精度的故障定位。因此,本文提出的方法需满足两个核心要求:(1)自动追踪变量值的变化;(2)自主判断变量中间状态的正确性。
对于第一个要求,静态和动态程序分析可帮助识别变量及变量值序列(即变量的中间值)。对于第二个要求,需要获取变量的正确中间值,但若无程序的正确版本,这一目标无法实现。为获取足够数量的正确程序版本,我们从在线评测(OJ)系统中收集了大量代码。OJ 系统通过执行教师准备的测试用例来评估程序正确性:若程序成功处理所有测试用例并生成预期输出,则判定为正确。因此,每个 OJ 测试题目会收到学生提交的多个正确程序版本,通过执行这些版本可获取变量中间值的正确参考。此外,我们还注意到,由于不同程序员的解题思路存在差异(Corbett 和 Anderson,2001),这些正确版本可能存在较大不同。因此,有必要设计一种有效方法,为错误的新手程序匹配对应的正确版本。
基于上述见解,本文提出一种新型故障定位技术 VsusFL(基于变量怀疑度的故障定位方法),用于自动定位新手程序中的错误语句。为模拟人工调试过程,VsusFL 首先通过静态分析识别程序中使用的变量;随后,开发工具 "CppSnooper",通过程序插桩收集程序的变量值序列,并记录变量值序列中每个值对应的行号;接着,设计匹配算法,基于变量映射的相似性为同一新手题目匹配正确版本;最后,对比错误程序与正确程序的变量值序列,通过识别可能导致故障的变量值,计算每个语句的怀疑度。
在实证研究中,我们选取 422 个真实的错误新手程序作为实验对象,并选取 5 种最先进的轻量级故障定位方法作为基准:Grace、ANGELINA、SBFL、VFL(基于变量的故障定位)和 VSBFL(基于变量值序列的故障定位)。实验结果表明,VsusFL 的性能优于所有基准方法。具体而言,相较于表现最佳的两种故障定位技术 Grace 和 VSBFL,VsusFL 在 TOP-1、TOP-3 和 TOP-5 指标上分别多定位 90%、35%、9% 和 265%、43%、12% 的错误语句,但在 A-EXAM 指标上略逊于两者。值得注意的是,VsusFL 与其他故障定位技术(尤其是 VSBFL)存在弱相关性,这意味着两者具有结合的潜力。进一步实验表明,将 VsusFL 与 VSBFL 结合后,故障定位性能可得到进一步提升。
本文的主要贡献如下:
- 提出一种新型故障定位方法 VsusFL,用于自动定位新手程序中的错误语句。
- 实现了 VsusFL,并在来自 33 个题目的 422 个真实新手程序上开展实证研究。实验结果表明,该方法在 TOP-1、TOP-3 和 TOP-5 指标上优于现有最先进的故障定位技术。
- 发现 VsusFL 与其他故障定位技术存在弱相关性,证实了结合这些技术的潜力,并提出三种结合方法以进一步提升故障定位性能。
(重现包:为方便其他研究者复现实验,我们在 GitHub 上共享了实验对象和方法的源代码。1)
2. 背景与相关工作
2.1. 程序调试
程序调试被定义为查找程序中的故障并修复的过程,通常包括三个阶段:程序检查、故障定位和错误修复。程序调试要求开发者不仅熟悉程序的设计目的,还需掌握其结构,这带来了诸多挑战。对于缺乏编程经验的新手而言,这一过程难度更大。因此,利用自动化程序调试技术可帮助开发者更快地定位故障或修复程序。
近年来,已开发多款工具自动生成反馈,以辅助教师和新手。例如,Gulwani 等(2018)开发了 Clara 工具,通过聚类追踪集群中的程序修复过程,并尝试修复其他程序;Python Tutor可可视化程序的运行过程。然而,这些工具无法告知新手程序失败的原因及错误语句可能的位置。因此,专门针对故障定位的自动化调试技术至关重要。故障定位通常是调试过程中最耗时、最繁琐的环节,且自动化程序修复的成功也在很大程度上依赖于自动化故障定位的准确性。因此,实现一种面向新手程序的有效自动化故障定位技术具有重要意义。
2.2. 故障定位
研究者已提出多种故障定位技术,如基于频谱的故障定位(SBFL)、基于变异的故障定位(MBFL)、动态程序切片、基于历史的故障定位和基于学习的故障定位。部分研究者还尝试结合多种技术:例如,Jiang 等(2019)将 SBFL 与统计调试相结合;Lou 等(2020a)利用自动化程序修复来提升故障定位性能。
基于频谱的故障定位(SBFL)
SBFL 因其简洁性、有效性和低计算成本,受到研究者的广泛关注。具体而言,SBFL 通过所有测试用例执行被测程序,收集每个测试用例的覆盖信息和执行结果(即通过或失败);随后,利用这些信息通过怀疑度公式计算程序中每个语句的怀疑度;最后,根据怀疑度对语句排序 ------ 语句在怀疑度列表中的排名越高,包含故障的概率越大。已设计多种有效的怀疑度公式来提升 SBFL 的性能,如 Jaccard、Tarantula、Ochiai、OP2和 Dstar。
然而,尽管 SBFL 效率较高,其精准度不如其他故障定位方法。例如,部分语句的怀疑度计算结果可能相同(即平局问题),这会给新手带来较大困难和不便。此外,新手程序中的平局问题更为严重,因此需要额外的特征来帮助新手定位故障。
基于学习的故障定位
深度学习在软件测试中的应用,推动了多项故障定位相关研究,如 Grace、DEEPRL4FL、ALBFL和 DeepFL。例如,Grace 将代码及代码与测试用例之间的覆盖关系表示为图,然后利用图神经网络根据该图预测错误方法。然而,现有最先进的这类方法仅关注方法级别的故障定位,忽略了语句级别的故障定位。因此,由于学生程序规模较小,需要更细致的语句级定位,这类技术难以应用于学生程序。此外,部分信息(如变异信息)的收集耗时较长,而其他信息(如部分研究中使用的错误报告和代码变更历史)并非总能获取,这限制了它们在新手程序中的应用。
基于值的故障定位
与本文方法类似的技术包括 VFL和 VSBFL,两者均利用变量信息辅助故障定位。具体而言,VFL 首先提取源代码中出现的变量和函数调用信息,然后根据变量与测试用例之间的覆盖关系,为单个变量和函数调用分配怀疑比例,进而计算单个语句的怀疑度。事实上,由于新手对函数和封装的理解不足,故障定位技术难以利用新手程序中的函数调用信息。此外,VFL 仍依赖覆盖信息为变量分配怀疑度,这与 SBFL 在新手程序中面临相同的问题 ------ 即当变量之间的覆盖差异不明确时,VFL 无法有效定位故障。类似地,VSBFL 通过对比错误程序和正确程序中的变量值序列,为变量分配怀疑度,进而为包含该变量的每个程序语句赋予相同的怀疑度。因此,VSBFL 仍无法有效区分不同语句的怀疑度。
此外,ANGELINA是一款支持天使调试的工具,也是一种利用更精细信息的故障定位技术。与本文提出的 VsusFL 不同,ANGELINA 在表达式级别工作:对于每个表达式,ANGELINA 分析是否可修改其结果,以逆转失败测试用例的结果同时保持通过测试用例的结果不变,符合该条件的表达式被识别为潜在的修复表达式。然而,此类分析需要符号推理,计算成本较高且可扩展性有限。
2.3. 新手程序的反馈生成方法
已有多种技术用于为新手提供反馈,现有研究通常侧重于基于故障定位,协助新手识别错误语句或修复程序。
新手程序的故障定位
近年来,部分研究将深度学习应用于提升学生程序的故障定位效果,包括 NBL和 FFL。NBL 是一种基于深度学习的语义故障定位技术,旨在利用失败测试用例定位错误程序中的故障。其核心步骤为:首先将程序表示为抽象语法树(AST),然后利用树卷积神经网络预测程序是否能通过给定测试用例,最后利用神经预测归因根据预测结果推断故障位置。与 Grace 类似,FFL 通过增加时间和计算资源消耗,利用更多信息定位学生程序中的故障:具体而言,FFL 通过 AST 和覆盖信息,将程序的语法和语义信息整合为图表示,然后利用图神经网络预测错误语句。尽管这些技术具有一定效果,但它们的成功往往依赖于大量数据的可用性,而这些数据并非总能获取。
此外,这些技术需要大量的时间和计算资源投入,尤其是为每个题目训练专用网络才能达到最佳效果。与 NBL 和 FFL 相比,本文提出的 VsusFL 是一种轻量级技术:仅需变量值相关信息,且通过提供的工具可轻松获取变量值信息,无需额外人工干预。
新手程序的程序修复
部分研究侧重于通过修复错误语句来修复新手程序,典型代表包括 InFix、Clara以及 Singh 等(2013)提出的技术。Endres 等(2019)提出 InFix,一种用于自动修复新手程序输入的随机搜索算法。InFix 无需测试用例和特殊注释,而是利用新手程序员常用的模式自动生成输入修复方案。Gulwani 等提出 Clara,旨在通过聚类已有的正确新手解决方案来修复新手程序:Clara 从每个聚类中选择目标程序,通过基于追踪的修复过程,学习如何修复新的错误尝试。Lou 等(2020b)提出一种为新手自动提供反馈的技术,可补充基于人工和测试用例的技术:该技术利用描述潜在修正的错误模型和基于约束的合成,计算新手错误解决方案的最小修正。以往大多数研究需要模型训练,这需要大量的新手程序样本(通常为数千个),部分研究还需为每个题目单独训练。与这些研究相比,VsusFL 仅需数十个程序即可定位故障,且在本研究中对任何题目均具有通用性。
3. 激励示例
测试场景
为更好地阐述研究动机,首先介绍测试场景。随着计算机技术的发展和编程教育的普及,各类在线编程平台应运而生,包括 Leetcode、Codechef、Codeforces、Jutge 和 BUCTCoder。这些平台允许教师发布编程任务(题目),并为学生提供在线编程环境以提交代码。为使平台能自动评估代码正确性,教师需提供相应的测试用例。由于这些测试用例通常为人工创建,数量一般有限:成功通过所有测试用例的代码被视为正确,因此可能存在多个正确代码版本。学生提交的所有代码(包括正确和错误程序)均存储在数据库中。对于错误程序,平台会将失败的测试用例反馈给学生,但如果学生未收到关于故障位置的提示,可能难以调试程序。
激励示例
为更直观地说明现有故障定位技术的局限性,本节给出三个激励示例。图 1 展示了三个新手编写的程序,其故障分别位于简单表达式(SE)、条件表达式(CD)和循环结构(Loops)中。我们用红色虚线框标出这些故障,并在注释中以绿色提供正确代码。此外,表 1 进一步提供了三个激励示例的测试用例和覆盖情况详情:"st" 列表示语句的行号,"Coverage" 列表示失败测试用例(ft)和通过测试用例(pt)的语句级覆盖情况;"S""V" 和 "Vsus" 列分别表示通过 Jaccard(Jaccard,1901,SBFL 中最常用的公式之一)、VFL和本文方法 VsusFL 计算得到的语句故障概率排名,其中错误语句以灰色突出显示。

图 1 :激励示例:(a)故障位于简单表达式(SE);(b)故障位于条件表达式(CD);(c)故障位于循环语句(Loops)
表1:涵盖激励示例,其中'S'、'V'和'Vsus'分别代表 SBFL 、VFL和VsusFL

其他故障定位技术的表现
遗憾的是,如表 1 所示,SBFL 无法在 TOP-1 中定位任何错误语句 ------ 因为它通常将被更多失败测试用例覆盖、更少通过测试用例覆盖的语句视为更可疑。事实上,新手缺乏编程经验,可能不熟悉函数和封装等概念,他们编写的代码往往由一个或多个代码块组成。在这种情况下,失败测试用例或通过测试用例可能覆盖大部分代码,导致 SBFL 做出错误判断。此外,SBFL 无法区分覆盖信息相似的语句,容易出现平局问题。例如,在表 1 的三个示例中,由于多个语句的怀疑度相同,SBFL 为它们分配了相同的排名。与 Jaccard 类似,其他现有 SBFL 公式由于遵循相同的排名逻辑,也无法将错误语句排在正确语句之前。值得注意的是,SBFL 在 CD 中的故障定位表现相对较好,错误语句排名进入 TOP-2,这可能是因为分支结构中的覆盖信息更具区分度(如表 1 所示)。另一类示例是 VFL:使用 Tarantula(Jones 等,2002,最广泛使用的公式之一),VFL 也无法在 TOP-1 中发现这些故障。如第 2 节分析,VFL 直接利用测试用例的覆盖情况和通过 / 失败结果为变量分配怀疑度,这使其在新手程序中面临与 SBFL 相同的问题 ------ 尤其是当变量的覆盖情况相似时,VFL 无法区分它们的怀疑度,限制了其在新手程序中的实用性。
综上,当测试用例的执行过程和结果无法为不同语句提供可区分的信息时,直接或间接依赖覆盖信息的故障定位技术的效果会受到挑战。
本文方法 VsusFL 的表现
与上述故障定位技术不同,本文方法从变量值序列的角度开展故障定位。考虑错误程序中所有变量的值序列,并以与当前错误程序相似的正确程序中所有变量的值序列为参考,通过评估每个变量值出现故障的概率,高效估计每个语句产生错误值的概率。这使得 VsusFL 在测试用例稀疏时,仍能获取更有效的细粒度信息,避免因语句覆盖情况相似而无法区分的问题。
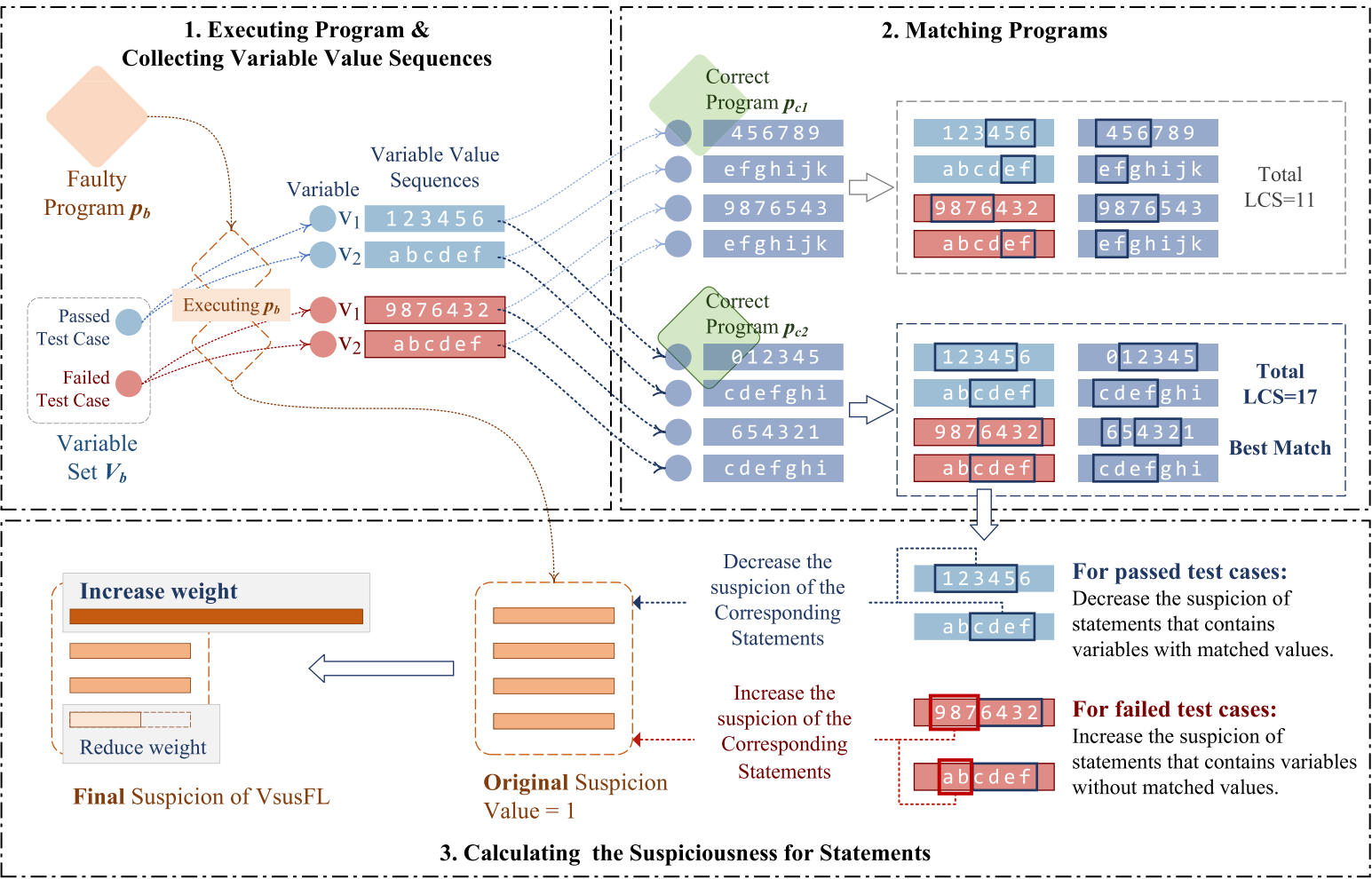
图2:VSFL框架
4. 方法设计
在现代教育场景中,教师常使用在线评测(OJ)系统辅助教学。在 OJ 系统中,每个题目可能包含大量正确程序,这些程序存储在 OJ 系统的数据库中。VsusFL 旨在将这些样本与错误程序进行对比,以定位故障。图 2 展示了 VsusFL 的框架:首先通过执行测试用例获取错误程序的变量值序列;然后在 "匹配相似程序" 环节,将错误程序与实现相似逻辑的正确程序进行匹配;最后在 "故障定位" 环节,判断变量值的正确性并计算程序语句的怀疑度,从而定位目标错误程序中的错误语句。
为提升 VsusFL 的效率,我们使用 "CppSnooper" 预处理并存储 OJ 平台上正确程序的变量值序列,且在本研究中进一步增强了该工具捕获变量值对应行号的能力。本节后续部分将先介绍相关预备知识,再详细阐述各步骤的具体实现。
4.1. 预备知识
匹配相似程序的关键步骤是获取变量值序列并计算这些序列之间的相似度。为更好地描述方法,下面给出变量值序列及其关系的形式化定义。
4.1.1. 变量值序列
被测新手程序通过测试套件执行时,会生成一系列变量值序列。这些序列可用于评估两个程序的相似度(尤其是当它们的实现存在相似性时)。需注意的是,由于算法和数据结构的差异,两个采用不同方法实现的正确程序,其变量值序列可能存在显著差异;但当两个程序的实现相似时,它们的变量值序列往往更相近,因此可通过变量值序列评估程序相似度。
考虑目标 OJ 题目 Q,其测试套件 T 包含 k 个测试用例,程序集合为 P。程序
中包含
个变量,构成变量集合
。这些参数是本文技术的重要组成部分,下面依次给出形式化定义。
定义 1:测试套件 T 中的测试用例 用于验证被测程序的正确性,由标准输入
和预期输出
组成。
例如,提交程序 进行验证时,OJ 会执行
并输入标准输入
;若执行结果与预期输出
一致,则测试用例
对
而言通过,否则失败。
定义 2:程序集合 P 由正确程序集合 和错误程序集合
组成。
当程序通过所有测试用例时,视为正确程序;当程序至少未通过一个测试用例时,视为错误程序。需注意的是,部分提交的程序可能存在运行时错误或编译错误,无法生成有效执行结果 ------ 本研究不考虑此类程序,因为现有 OJ 系统可有效识别它们。此外,众多故障定位研究已采用此类被测程序筛选策略。
定义 3:变量值序列是变量的值记录列表。对于程序、变量
(
)和测试用例
,
的初始值为
,第 m 次变化后的值为
,则
中
的变量值序列为
(其中变量共发生 M 次变化)。
具体而言,变量变化指程序执行过程中变量值的更新,反映了程序的底层算法设计和数据结构,代表程序处理数据和执行操作时变量状态的修改。第 m 次变化后的值即变量经过 m 次更新后的取值。通过分析变量值序列,可捕获程序执行过程中变量值的变化情况,进而利用这些信息评估程序相似度 ------ 因为这些序列能反映程序的固有特征。
4.1.2. 序列间的关系
两个程序可通过变量值序列进行映射,序列间的相似度决定了程序间的相似度。本小节后续部分将给出相关定义。
定义 4:两个变量在每个测试用例下的相似度可通过最长公共子序列(LCS)计算。LCS 用于判断两个字符串的相似程度:对于程序 中的变量
、程序
中的变量
和测试用例
,
和
的最长公共子序列为 LCS (
,
,
,
,
),其长度为 S (
,
,
,
,
)。
图 3 通过示例说明 LCS 计算过程:假设 E (,
,
) = {1,2,3,4,5},E (
,
,
) = {0,1,3,5,7},则 LCS (
,
,
,
,
) = {1,3,5},S (
,
,
,
,
) = 3(即 LCS 的长度为 3)。
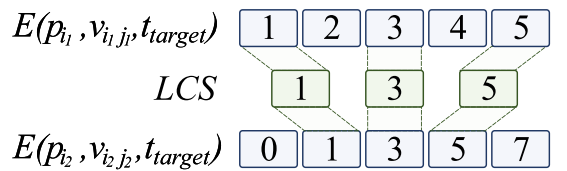
图 3: LCS 计算示例
定义 5:对于多个测试用例,两个变量的相似度为各测试用例下 LCS 长度的总和。考虑测试套件 T,变量 和
的相似度计算如下:
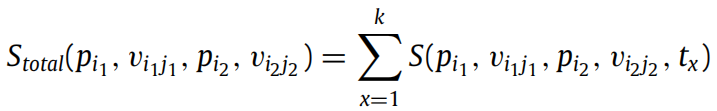
根据定义 5,变量间的相似度可用于评估程序间的语义相似度。但当变量 的序列包含变量
的序列时,尽管此时
(
,
,
,
,
) 的值可能很高,两者的语义仍可能不同。因此,为解决这一问题,进一步设计归一化相似度计算公式(定义 6)。
定义 6:对于多个测试用例,两个变量的归一化相似度为各测试用例下 LCS 长度的总和除以两个序列长度的总和。考虑测试套件 T,变量 和
的归一化相似度计算如下:
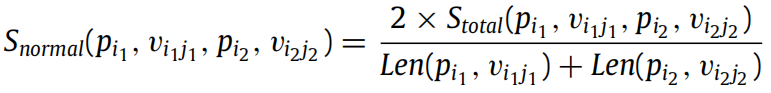
其中,Len 表示变量在所有测试用例下变量值序列的长度总和,计算如下:
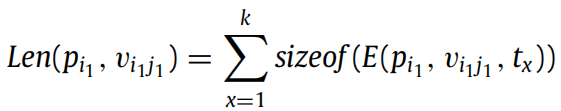
最终,通过计算多个变量间的相似度,可得到程序间的相似度(详见下一节)。
4.2. 匹配相似程序
新手调试代码中的故障时,可能会观察变量值是否与预期一致 ------ 这种推断故障可能位置的方式是常见的人工调试方法,其本质类似于对比错误程序和正确程序的变量值序列:变量值存在差异的语句更可能包含故障。但该方式的有效性基于以下两个前提:
- 两个程序的实现逻辑相似;
- 用于对比的两个变量功能相似。
为确保这两个前提成立,需获取变量和程序的匹配关系,找到逻辑相似的程序和功能相似的变量,以保证后续故障定位技术的性能。然而,当新手提交错误程序时,人工匹配程序并不现实 ------ 因为 OJ 系统中每个题目存在多个不同实现的正确程序。若随机选择程序,无法保证程序间的相似度,后续对比也将失去意义。因此,可利用变量值序列寻找与目标错误程序逻辑相似的正确程序:两个程序的变量变化过程越相似,其逻辑越相近。
算法 1 描述了程序匹配的过程。该算法的输入为目标错误程序 和正确样本程序集合
(已预处理以获取对应的变量值序列),输出为匹配的程序集合
。具体步骤如下:
- 对
进行静态分析,提取其包含的变量集合
- 遍历
- 选择与
- 返回 Sim (

需注意的是,还需计算失败测试用例下的 LCS------ 因为有时一个简单故障(如循环起始值错误)会导致程序在所有测试用例上失败,但此时两个程序的逻辑仍可能相似。若仅计算通过测试用例下的 LCS,将无法匹配到正确程序。
下面以图 4 中的错误程序 p1 和正确程序 p2 为例,说明程序相似度的计算过程。p1 包含变量 a、b、n,p2 包含变量 x、y、m;测试用例输入分别为 "5 3""206 4""388 6""666 5",两个程序的变量值序列如表 2 所示。

图 4 :程序示例:(a)错误程序 p1;(b)正确程序 p2
表 2 变量值序列
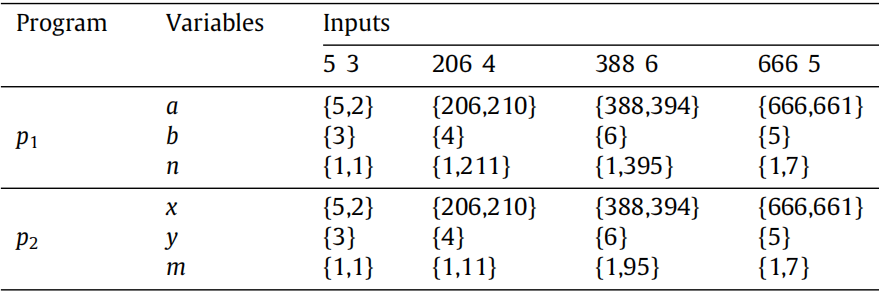
获取变量值序列后,计算 p1 中每个变量与 p2 中每个变量的最长公共子序列长度。例如,当测试用例 = "206 4" 时,计算得到 S (p1, a, p2, x,
) = 2,S (p1, b, p2, y,
) = 1,S (p1, n, p2, m,
) = 1,其余变量对的结果均为 0。通过计算其余测试用例下的数据,最终得到:
(p1, a, p2, x) = 8,
(p1, b, p2, y) = 4,
(p1, n, p2, m) = 6,其余变量对的结果均为 0。
随后,构建 bipartite 图(如表 3 所示):行对应 p1 的变量 a、b、n,列对应 p2 的变量 x、y、m;a 与 x 之间的边权重为 8(对应表 3 中 a 行 x 列的 "8"),依此类推。连接所有边后,通过 bipartite 图匹配得到匹配结果:a 匹配 x,b 匹配 y,n 匹配 m,三条边的权重分别为 8、4、6。最后,根据定义 6 计算归一化相似度: (p1, a, p2, x) = 1,
(p1, b, p2, y) = 1,
(p1, n, p2, m) = 0.75。将三个相似度值相加,得到 p1 与 p2 的最终相似度(1+1+0.75=2.75)。
表 3 变量间的 LCS 及映射结果

4.3. 基于变量怀疑度的故障定位
若直接向新手展示错误程序匹配到的正确程序,对提升新手的编程能力帮助有限 ------ 因为新手需要知道自己程序中错误语句的位置,而非简单获取正确答案。此外,新手可能会抄袭提供的正确程序,这与编程教育的初衷相悖。
因此,有必要提供精准的故障定位信息。算法 2 详细描述了该过程:给定错误程序 、正确程序集合
和测试套件 T,VsusFL 首先根据 4.2 节计算的相似度,从
中筛选出与
相似的正确程序集合 Sim (
)(步骤 1-2);然后从 Sim (
) 中选择一个正确程序
作为参考,用于评估变量值的正确性(步骤 3);根据 4.2 节得到的变量匹配关系,确定
中每个变量
在
中的对应变量
(步骤 6);计算测试用例 t 下
和
的最长公共子序列 LCS (
,
,
,
, t)(步骤 8);我们推测,对于变量
,出现在 LCS (
,
,
,
, t)中的值大概率是正确的。为进一步确定程序中的故障位置,将每个变量
的变量值序列 E (
,
, t) 与 LCS LCS (
,
,
,
, t) 进行对比(步骤 9-18)。

具体而言,所有语句的变量怀疑度初始化为 - 1(步骤 4)。若测试用例 t 执行失败,且语句 st 中 的值未出现在 LCS (
,
,
,
, t) 中,则 st 包含故障的概率较高。用系数 α(取值范围为 0-1)表示错误变量值对语句怀疑度的影响权重:α 越接近 0,变量值对语句怀疑度的影响越大;α 越接近 1,影响越小。类似地,2-α 表示正确变量值对语句怀疑度的影响权重。因此,将语句 st 的怀疑度乘以 α(本研究中 α 设为 0.8),以提高其怀疑度(步骤 11-13)。反之,若测试用例 t 执行成功,且语句 st 中
的值出现在 LCS (
,
,
,
, t) 中,则将语句 st 的怀疑度乘以系数 (2-α),以降低其怀疑度(步骤 14-16)。需注意的是,变量值与语句的映射通过本文提供的工具 "CppSnooper" 自动实现。
在所有测试用例下的所有变量值序列对比完成后,若所有语句的变量怀疑度均未发生变化,则将输出语句的怀疑度乘以 α------ 因为此时推测计算过程中无故障,故障更可能出现在输出语句中(步骤 20-26)。
图 4 :程序示例:(a)错误程序 p1;(b)正确程序 p2
表 2 变量值序列
表 3 变量间的 LCS 及映射结果
仍以图 4 中的错误程序为例,表 2 展示了生成的变量值序列,表 3 展示了变量间的匹配关系。所有语句的怀疑度初始化为 - 1。当测试用例 = "206 4" 时,根据定义 4 得到三个变量对的最长公共子序列:LCS (p1, a, p2, x,
) = {206, 210},LCS (p1, b, p2, y,
) = {4},LCS (p1, n, p2, m,
) = {1}。将错误程序中的变量值序列与最长公共子序列对比,发现变量 a 和 b 的值序列与对应的 LCS 完全一致,但变量 n 的值序列中 "211" 未出现在 LCS (p1, n, p2, m,
) 中,且该测试用例执行失败,因此将产生该值的第 7 行语句的变量怀疑度乘以 0.8。同理,对于测试用例
= "388 6",第 7 行语句的变量怀疑度需再次乘以 0.8。反之,对于通过的测试用例
= "5 3" 和
= "666 5",由于变量值均出现在最长公共子序列中,所有产生这些变量值的语句的变量怀疑度需乘以 1.2。最终得到的结果如表 4 所示。
表 4 变量怀疑度及最终排名

注:"✓" 表示测试用例通过且该语句产生的变量值出现在最长公共子序列中;"×" 表示测试用例失败且该语句产生的变量值未出现在最长公共子序列中。
如表 4 所示,实际的错误语句(第 7 行)在最终排名中位列第一,故障定位成功。
5. 实验设计
5.1. 研究问题
为评估 VsusFL 的有效性,设计以下三个研究问题:
RQ1:VsusFL 在新手程序的故障定位中效果如何?
本研究问题旨在验证 VsusFL 定位新手程序故障的能力。为回答该问题,开展一系列实证研究,将 VsusFL 与其他最先进的故障定位技术进行对比,包括 Grace、ANGELINA、VSBFL)、SBFL和 VFL。需注意的是,ANGELINA 不支持 C++ 语言,因此其实验仅局限于 C 语言程序。此外,未选择 MBFL和,因为它们耗时过长,无法为新手提供及时反馈;同时忽略了基于错误报告的故障定位方法(如 BugLocator、BRTracer和 DeepFL),因为这些方法所需的错误报告在新手程序中无法获取。
RQ2:VsusFL 在不同类别新手程序上的表现如何?
本研究问题旨在探究 VsusFL 在不同类别新手程序上的性能,分析其适用性并为进一步提升性能提供研究方向。为回答该问题,将实验对象分为三类(简单表达式、条件语句、循环语句),然后对比 VsusFL 与其他基准方法在不同类别实验对象上的故障定位性能。
RQ3:VsusFL 与 VSBFL 的结合效果如何?
本研究问题旨在探究 VsusFL 是否能进一步提升使用不同信息的其他技术的性能。具体而言,首先通过分析 VsusFL 与其他技术的相关性,探索它们结合的可能性;然后采用三种方法将 VsusFL 与 VSBFL 结合,验证是否能有效提升两者的故障定位性能。
5.2. VsusFL 与 VSBFL 的结合方法
本研究采用三种方法结合 VsusFL 与 VSBFL:对于错误程序中的每个语句,通过 VsusFL 获取其变量怀疑度,通过 VSBFL 获取其语句怀疑度,然后通过结合方法得到语句的最终怀疑度。由于不同技术的怀疑度取值范围差异较大,需根据公式(1)将所有怀疑度归一化到 0-1 之间:
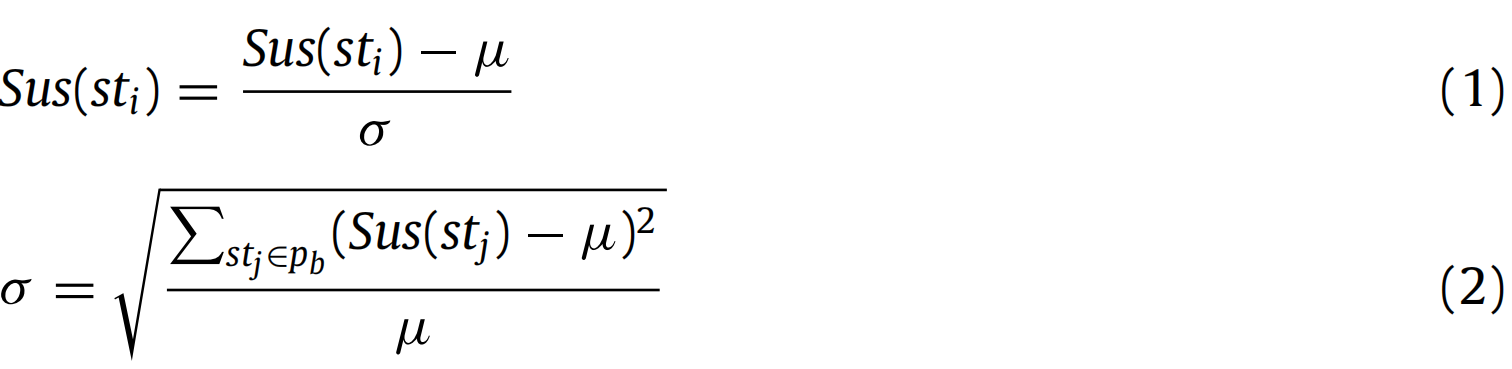
其中,μ 为故障定位技术计算得到的错误程序 中所有语句怀疑度的平均值。
设语句 st 的变量怀疑度(VsusFL 计算)为 sus₁,语句怀疑度(VSBFL 计算)为 sus₂,sus (st) 为集成方法得到的最终怀疑度,三种结合方法如下:
-
线性结合:计算过程如公式(3)所示,系数 β 的取值范围为 0-1,步长为 0.1。
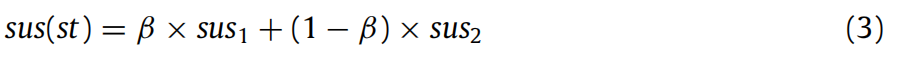
-
乘法结合:如公式(4)所示,将两种故障定位方法计算的怀疑度整合,得到语句 st 的最终怀疑度。在每个怀疑度前加 1 是为了避免怀疑度为 0,导致另一个怀疑度失效。sus(st)=
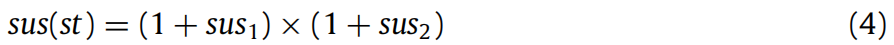
-
多项式回归:一种机器学习算法。当存在多个自变量时,多元回归分析可通过指定多项式的最高次项 r,拟合如公式(5)所示的曲线 ------ 其中自变量 st 表示错误程序中的每个语句,st = <sus₁, sus₂>。
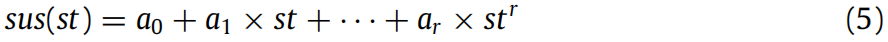
多项式回归的优势在于,可通过增加 r 的值直至满足需求,来逼近曲线。实际上,多项式回归能处理相当一类非线性问题,因为任何函数都可通过多项式逼近。为准确评估多项式回归的性能,实验中采用 5 折交叉验证(5-fold cross validation)。
5.3. 实验对象
本研究采用 Yi 等(2017)共享的数据集作为实验对象。该数据集已得到广泛认可,并被多项先前研究采用。数据集中的程序由印度坎普尔理工学院(IIT-K)的 C 语言入门课程新手程序员编写。
此外,通过真实教育环境中活跃使用的学生编程平台,补充了新手 C++ 程序,进一步扩充数据集。
最终,实验对象来源于 33 个题目。排除 76 个超时、运行时错误或无法通过 GCC 编译的程序后,共得到 422 个程序,包含 664 个故障。
表 5 展示了实验对象的详细信息:根据标注,这些题目分为三类(简单表达式、条件语句、循环或嵌套循环),对应程序数量分别为 56 个、154 个和 162 个;同时列出了程序使用的编程语言和代码长度(LOC),代码长度范围为 9 行至 211 行以上。选择该数据集作为实验对象的原因是,其中包含的故障来自真实场景,而非人工生成(如 SIR),且数据集包含大量不同类别的程序。
表 5 数据集中的题目信息

5.4. 评估指标
5.4.1. EXAM 分数
EXAM 分数(EXAM)定义为定位到第一个错误语句前需要检查的语句比例,常用于评估故障定位技术的准确性 ------EXAM 值越低,找到错误语句所需检查的语句越少,对应的故障定位技术性能越好。具体计算公式如下:
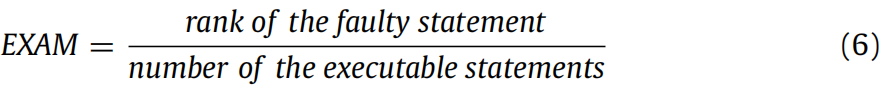
简言之,EXAM 等于错误语句占可执行语句总数的比例,可量化开发者定位单个错误语句的工作量。
然而,部分语句的怀疑度可能相同,导致出现平局问题。本研究采用最差排名表示语句的最终排名 ------ 这一策略已被先前的故障定位算法广泛用于处理平局问题。以错误语句 s 为例,A 表示程序中怀疑度高于 s 的语句数量,B 表示怀疑度与 s 相同的语句数量,则错误语句 s 的最终排名为 A+B。
此外,该公式在多故障程序中会受到影响。因此,将原始 EXAM 扩展为平均检查量(A-EXAM),如公式(7)所示,用于计算开发者定位多故障程序中所有故障的工作量:

其中,EXAM (n) 为排名列表中第 n 个错误语句的 EXAM 值,N 为错误语句的总数。A-EXAM 值越小,说明故障定位技术的效果越好。
5.4.2. TOP-N
TOP-N 表示算法将所有错误语句排在排名列表前 N 位的程序数量 ------TOP-N 值越高,开发者定位错误语句所需的工作量越少,对应的故障定位技术性能越好。根据先前研究,开发者通常只会查看排名列表前几位的语句,因此 TOP-N 指标至关重要。例如,近期一项研究发现,超过 70% 的开发者在实际软件调试中仅检查 TOP-5 排名的语句。因此,与先前研究一致,本研究主要关注 TOP-1、TOP-3 和 TOP-5。
6. 结果分析
6.1. RQ1:VsusFL 的有效性
为评估 VsusFL 的性能,将 Grace、SBFL、ANGELINA、VFL 和 VSBFL 作为基准方法,分别统计它们的实验结果(如表 6 所示)。为使结果更直观,图 5 进一步展示了上述技术在 TOP-N 指标上的性能。实际上,开发者通常只关注怀疑度列表顶部的少数语句,因此 TOP-N 指标能更好地反映故障定位技术的有效性。
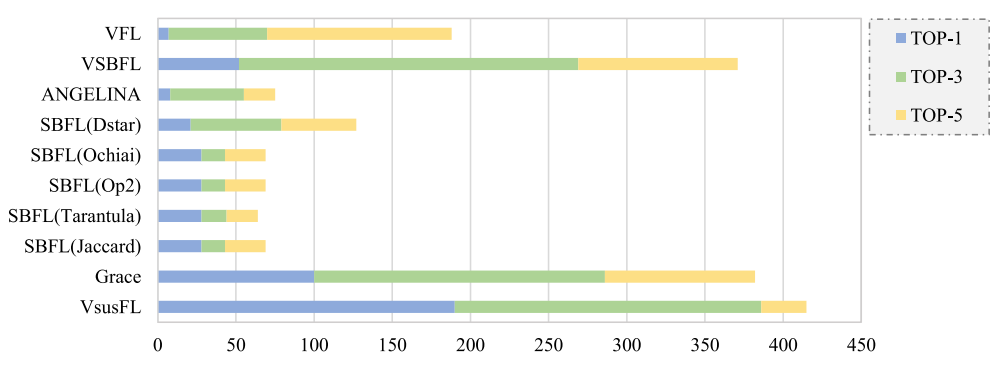
图 5 TOP-N 指标下的故障定位性能对比
如图 5 所示,VsusFL 在 TOP-1、TOP-3 和 TOP-5 指标上显著优于所有对比基准方法。相较于表现最佳的两种技术(Grace 和 VSBFL),VsusFL 在各指标上的性能分别提升了 90%、35%、9% 和 265%、43%、12%;与 SBFL、VFL、ANGELINA 相比,性能提升更为显著。
表6:各项技术的性能表现
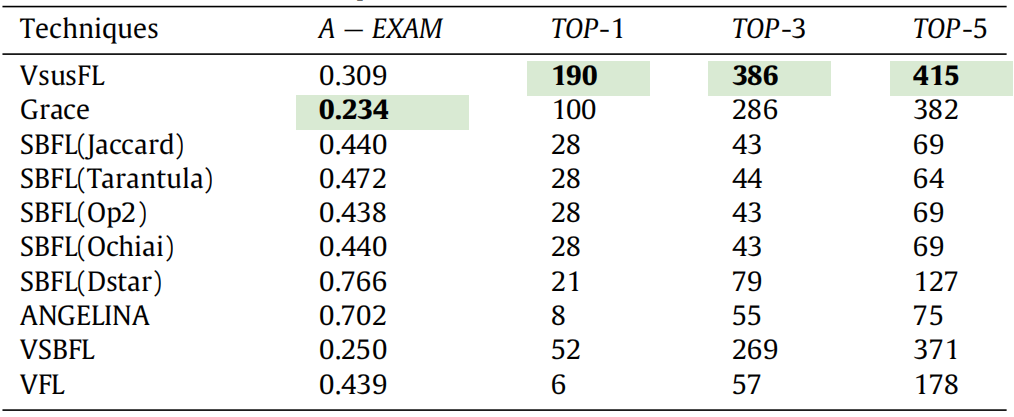
此外,从表 6 中可得出以下结论:(1)基于值的故障定位技术(如 VFL、VSBFL、VsusFL)在几乎所有指标上均优于传统 SBFL 公式;(2)基于学习的故障定位技术 Grace 在观测指标上优于 VSBFL、VFL、ANGELINA 和传统 SBFL;(3)VsusFL 在 TOP-N 指标上优于所有对比基准方法,但在 A-EXAM 指标上弱于 Grace 和 VSBFL。
通过详细分析结果原因发现,VSBFL 在某种意义上可将变量怀疑度与语句怀疑度结合,而 Grace 利用了代码结构、语句类型和覆盖信息等多种信息。通过整合多源信息,它们在 TOP-10 指标上能定位更多故障 ------VSBFL 和 Grace 在 TOP-10 中分别能定位 477 个和 506 个故障,比 VsusFL 多 57 个和 84 个。另一方面,VsusFL 在 TOP-1、TOP-3 和 TOP-5 指标上大幅优于 Grace 和 VSBFL,但在 A-EXAM 和 TOP-10 指标上表现不佳,这看似矛盾的结果源于:VsusFL 能利用变量值提供的细粒度信息,在特定类型的新手程序上取得良好性能,因此能将大量错误语句排在怀疑度列表前列,但也会将部分错误语句排在列表末尾。
这些结果表明,VsusFL 与对比基准方法存在差异 ------VsusFL 能有效区分程序语句,不会受平局问题困扰。总体而言,VsusFL 在新手程序的故障定位中表现最佳。
6.2. RQ2:VsusFL 在不同类别新手程序上的有效性
数据集中的程序分为三类:简单表达式(SE)、条件语句(CD)和循环语句(Loops)。故障定位技术在不同类别程序上的性能可能存在差异。
表 7: 不同类别程序上各技术的性能表现
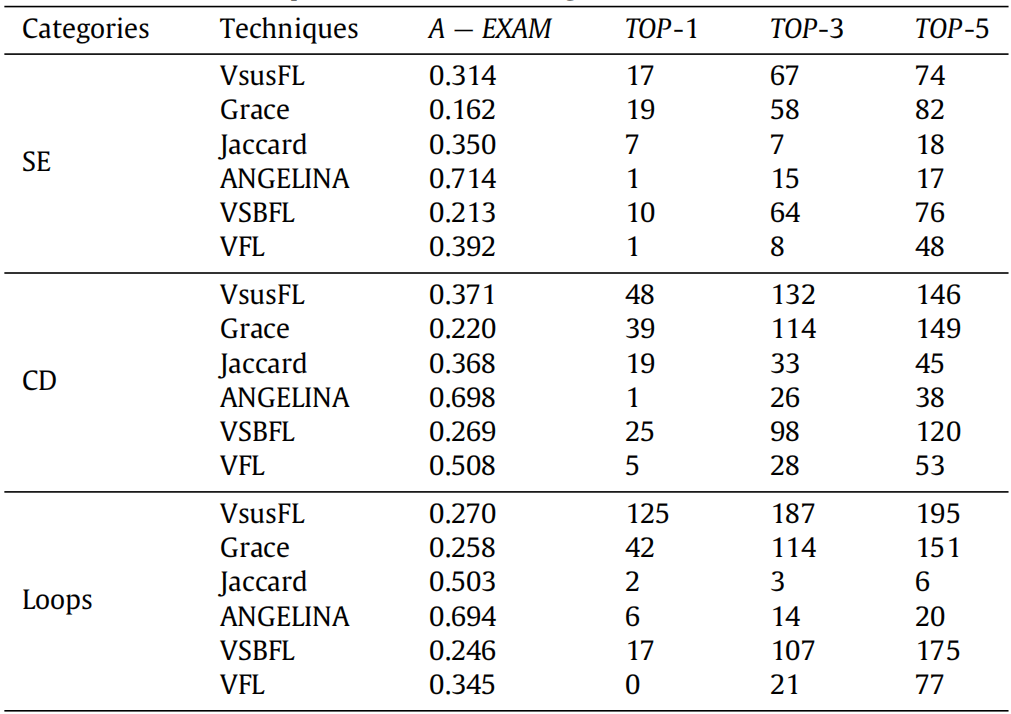
表 7 展示了不同故障定位技术在不同类别程序上的性能。为简化表格,仅选择表现最佳的 Jaccard 公式代表 SBFL。从表中可看出,在 TOP-1、TOP-3 和 TOP-5 指标上,VsusFL 在几乎所有类别中均优于 VSBFL、Grace、ANGELINA、SBFL 和 VFL:在 SE 类别中,VsusFL 与 Grace 表现相近,但优于其他基准方法;在 CD 类别中,VsusFL 略优于 Grace,且显著优于其他基准方法;在 Loops 类别中,VsusFL 远优于 Grace 和其他基准方法。我们认为,随着新手程序中变量值提供的信息丰富度和数量增加,VsusFL 的有效性会进一步提升。
另一个发现是,VSBFL 在 TOP-1 和 TOP-3 指标上略逊于 Grace,但在 TOP-5 指标上与 Grace 表现相当。此外,值得注意的是,SBFL 在 CD 代码上的表现优于 SE 和 Loops,这支持了第 1 节和第 3 节的分析 ------CD 程序通常具有更多分支结构,使测试用例能为语句提供更多可区分的信息,从而提升 SBFL 的有效性。综上,这些结果与 RQ1 的结论一致。
6.3. RQ3:结合技术的性能
本研究问题旨在探索将 VsusFL 与其他故障定位技术结合的可能性。若两种技术擅长识别相同类型的故障,则它们具有相关性;反之,若两种技术相关性较低,可能提供不同的信息,结合后有望取得优于单独使用任一技术的效果。
表 8 展示了 VsusFL 与其他技术之间的 p 值和效应量(d 值):p 值基于 422 个程序中各技术提供的 A-EXAM 值,通过 Wilson 双侧检验计算得出;效应量通过科恩 d 值(Sullivan 和 Feinn,2012;Grissom 和 Kim,2005)衡量。根据 Grissom 和 Kim(2005)的定义,d 值在 0.147-0.33 之间为小效应,0.33-0.474 之间为中等效应,大于 0.474 为大效应,反映了观测效应的程度。
表 8:各故障定位技术与 VsusFL 的相关性分析(p 值和科恩 d 值)
(p 值 < 0.05 和大 d 值已突出显示)

表 8 中包含 8 组不同技术对,其中仅 3 组的 p 值超过显著性水平 α=0.05,表现出统计显著相关性;其余技术对的 p 值小于 0.05,表明它们之间无统计显著相关性。此外,VsusFL 与 VSBFL、VsusFL 与 SBFL(Jaccard、Op2、Ochiai)的 d 值较大,意味着它们之间存在统计显著差异且效应量较大。尤其是 VsusFL 与 VSBFL 的效应量大于其他技术对,表明两者的差异更为显著。此外,如表 6 所示,VSBFL 在故障定位上的表现优于 SBFL。
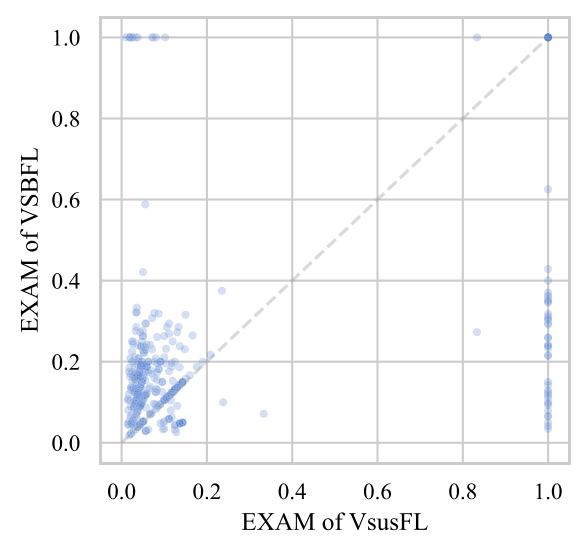
图 6: VsusFL 与 VSBFL 的相关性散点图:点的 X 和 Y 值分别表示两种技术在同一错误程序上的 A-EXAM 值,A-EXAM 反映用户定位所有错误语句的工作量
为更直观地分析 VsusFL 与 VSBFL 的相关性,图 6 展示了两者的散点图:图中包含 422 个点(每个点对应数据集中的一个错误程序),点的坐标 (x, y) 表示在该程序上 VsusFL 的 A-EXAM 值为 x,VSBFL 的 A-EXAM 值为 y。
图 6 中,许多点位于左上和右下区域,这表明存在大量错误程序:其中一种技术表现良好,而另一种技术表现不佳。这一模式说明两种技术不存在正相关性,且各自有望提供对方无法获取的独特信息。
进一步计算 VsusFL 与 VSBFL 的相关系数为 0.2308------ 接近 0 的相关系数通常表明相关性几乎可忽略,而接近 - 1 或 1 的相关系数表示强相关性。0.2308 的值接近 0,意味着 VsusFL 与 VSBFL 之间存在弱线性相关性。
上述结果表明,两者可能为彼此提供独特信息,这也为后续结合两种技术以提升故障定位准确性提供了理论支持。
接下来,采用 5.2 节介绍的三种结合方法将 VsusFL 与 VSBFL 结合,并评估不同系数下结合故障定位技术的性能。
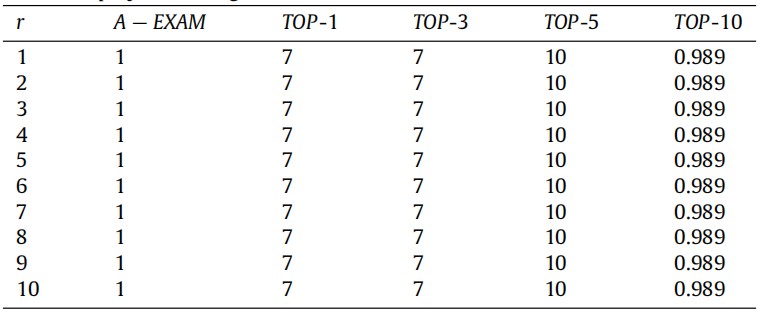
表 9: 线性结合的效果
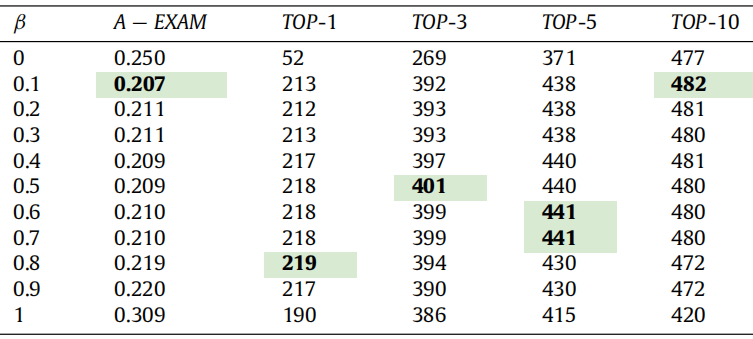
表 9 展示了不同 β 值下线性结合方法的效果(最佳表现结果已加粗)。从表中可看出,将 VsusFL 与 VSBFL 结合后,两者的性能均得到显著提升:以 A-EXAM 为指标时,β=0.1 时性能最佳,相较于 VSBFL 提升 17.2%,相较于 VsusFL 提升 33%;以 TOP-N 为评估指标时,β=0.5 时性能最佳,在 TOP-1、TOP-3、TOP-5 和 TOP-10 指标上,相较于 VSBFL 分别提升 319%、49%、19%、1%,相较于 VsusFL 分别提升 15%、4%、6%、14%。与先前表现最佳的技术 Grace 相比,采用线性结合方法后的性能也有所提升:TOP-1 指标提升 118%,A-EXAM 指标提升 11.5%。
表 9 中 β=1 时,A-EXAM 为 0.309,TOP-1 为 190,TOP-3 为 386,TOP-5 为 415,TOP-10 为 420,与单独使用 VsusFL 的性能一致,验证了线性结合方法的合理性。
采用乘法结合时,可得到类似的提升效果:A-EXAM 为 0.304,TOP-1 为 220,TOP-3 为 389,TOP-5 为 415,TOP-10 为 420。与线性结合相同,乘法结合在 TOP-1 和 TOP-3 指标上的故障定位性能得到了有效提升。这些结果充分证明,VsusFL 和 VSBFL 能够相互利用彼此的信息,提升新手程序的故障定位有效性。
与前两种结合方法不同,多项式回归的表现明显较差(如表 10 所示)。此外,从表中可看出,参数变化对其性能影响极小。经深入分析发现,多项式回归方法存在严重的平局问题 ------ 程序中几乎所有语句都被分配了相同的怀疑度,这极大地限制了该结合方法的有效性。
表 10: 多项式回归的效果
综上,实验结果表明,结合方法能有效提升 VsusFL 的故障定位性能,且优于单独使用任何一种故障定位技术。此外,线性结合方法被认为是整合 VsusFL 与其他故障定位技术的最优选择,建议将 β 值设置为 0.5。
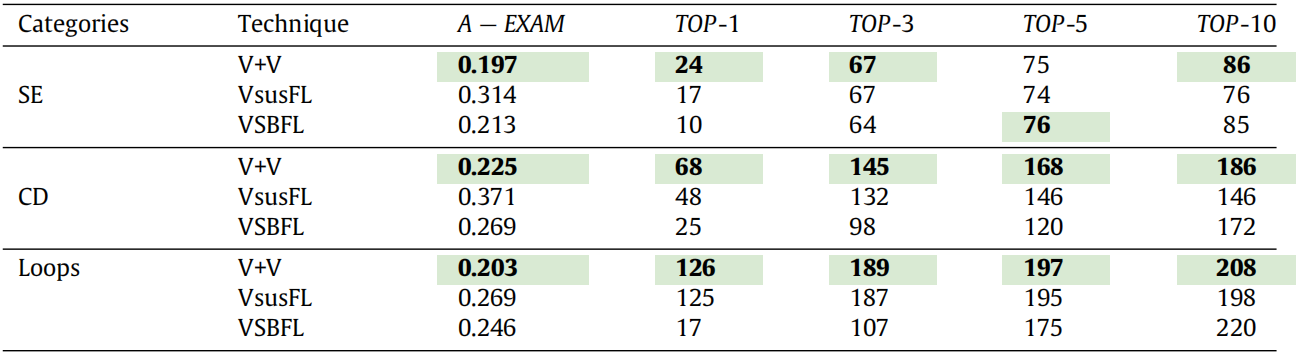
我们进一步探究了最优结合方法(即 β=0.5 的线性结合方法,将 VsusFL 与 VSBFL 结合)在不同类别程序上的有效性,结果如表 11 所示(优于 VsusFL 和 VSBFL 的结果已加粗)。显然,无论程序类别和观测指标如何,该结合方法始终优于 VsusFL、VSBFL,甚至 Grace。此外,该方法在条件语句(CD)和简单表达式(SE)类别中的提升比循环语句(Loops)更为显著。这一发现进一步表明,将 VsusFL 与其他技术整合,可实现更强大的故障定位效果。
表 11: 结合方法(V+V,β=0.5 的线性结合)在不同类别程序上的性能
7. 有效性威胁
7.1. 内部有效性威胁
内部有效性威胁与 VsusFL 及基准技术的潜在实现错误相关。为减轻这一威胁,我们首先采用开源 Python 包 "munkres" 实现基于二分图的程序匹配算法;然后在多个简单程序上运行 VsusFL,验证实现的正确性;此外,直接使用先前研究提供的开源代码;最后,重新实现 SBFL 和 VFL------ 为减少代码中的潜在错误,我们严格按照这些基准技术的原始描述进行实现,并对其进行了仔细测试。
此外,参数选择是影响实证结果的内部威胁之一,系数 α 的配置可能会影响方法的性能。为减轻这一威胁,我们对多种配置进行了实验,最终确定推荐 α 值为 0.8。
7.2. 外部有效性威胁
外部有效性威胁与本文使用的数据集相关。需考虑的是,通过所有测试用例的程序未必完全无错,部分错误语句可能未被触发。为尽量减少这一问题,我们手动检查了数据集中被判定为正确的程序的正确性,因此该威胁的影响有限。
另一个外部威胁来自错误语句的标注位置。例如,数据集的重要来源之一 Yi 等(2017)仅提交了错误程序及对应的正确程序,未标注错误语句的位置。因此,我们手动为每个错误程序标注错误语句,并邀请多名志愿者(包括本文作者)手动检查标注的正确性,以避免可能的标注错误。
7.3. 构念有效性威胁
构念有效性威胁与实验的测量方式相关。为减轻这一威胁,我们采用 EXAM 和 TOP-N 指标评估故障定位性能 ------ 这两种指标已被先前的故障定位研究广泛使用,具有较高的认可度和合理性。
8. 结论
本文提出了一种新型故障定位方法 VsusFL,用于自动定位新手程序中的错误语句。该方法受人工调试过程的启发,利用变量值序列实现新手程序的故障定位。为评估 VsusFL 的有效性,我们在 422 个真实的错误新手程序上开展了实证研究。实验结果表明,VsusFL 的性能优于 Grace、VSBFL、ANGELINA、SBFL 和 VFL:在 TOP-1、TOP-3 和 TOP-5 指标上,VsusFL 相较于 Grace 分别提升了 90%、35% 和 9%,相较于 VSBFL 分别提升了 265%、43% 和 12%。值得关注的是,实验中发现 VsusFL 与其他故障定位技术(尤其是 VSBFL)存在弱相关性。进一步实验表明,将 VsusFL 与其他技术结合后,故障定位性能可得到显著提升。
启发
实验评估时可以进行分类评估,如本文的 "简单表达式、条件语句、循环" 三类场景评估;
利用变量的方法可以与多种其他方法结合,均可取得较好的结果;
可以模拟人工调试逻辑,如本文:借鉴开发者 "断点追踪变量变化" 的习惯,将变量值序列作为核心数据.
BibTex
@article{ WOS:001068770800001,
Author = {Li, Zheng and Wu, Shumei and Liu, Yong and Shen, Jitao and Wu, Yonghao
and Zhang, Zhanwen and Chen, Xiang},
Title = {VsusFL: Variable-suspiciousness-based Fault Localization for novice
programs},
Journal = {JOURNAL OF SYSTEMS AND SOFTWARE},
Year = {2023},
Volume = {205},
Month = {NOV},
DOI = {10.1016/j.jss.2023.111822},
EarlyAccessDate = {AUG 2023},
Article-Number = {111822},
ISSN = {0164-1212},
EISSN = {1873-1228},
ResearcherID-Numbers = {Li, Zheng/L-8594-2015
wu, shumei/NPJ-0540-2025
chen, xiang/AAG-3663-2019},
ORCID-Numbers = {chen, xiang/0000-0002-1180-3891},
Unique-ID = {WOS:001068770800001},
}