为促进语音技术多元化发展、推动AI在特殊语音场景下的研究与落地,希尔贝壳 联合昆山杜克大学 正式开源 "AISHELL-6-Whisper 语料库"。作为稀缺的耳语---正常音平行对齐资源,本数据集的发布旨在填补相关领域开源数据的空白,为学术界与工业界在低资源语音、多模态交互等前沿方向提供关键数据支持,共同构建更丰富、更包容的语音智能生态。


数据地址: https://www.aishelltech.com/aishell_6_Whisper
论文地址: https://arxiv.org/pdf/2509.23833v1
数据说明
语料库在安静的录音棚环境中采集,包含约29.8小时的耳语语音与平行录制的29.5小时正常语音,和同步采集的唇动视频。
该语料库包含 167 名说话人,每位说话人朗读约 10 到 20 分钟不重复的诗歌文本。其中,121 名参与者使用高保真麦克风和同步的 RGB 相机进行录制,其余 46 名参与者仅录制音频信号。音频采用单通道高保真麦克风(Neumann U87)采集(48kHz,16-bit),背景噪声水平低于 20dB。如下图:
我们将数据集按大约 4:1:1 的比例划分为训练集、验证集和测试集,确保各子集在年龄和性别上分布均衡。这三个子集之间没有说话人重叠。另外,该语料库提供句级别的文本标注,耳语音频和正常语音音频路径的对应关系文件,及各说话人信息的文件。
试验说明
我们提出了一个基于Whisper-Flamingo架构的视听语音识别基线模型。该模型引入了并行训练策略,使模型能够同时处理耳语与正常语音,并通过一个轻量级投影层对齐两种语音的嵌入表示,从而有效补偿耳语频谱特征的缺失。同时,我们结合了来自AV-HuBERT的视觉特征,利用门控交叉注意力机制将唇部运动信息融入识别过程中,构建了一个统一的多模态耳语识别框架。
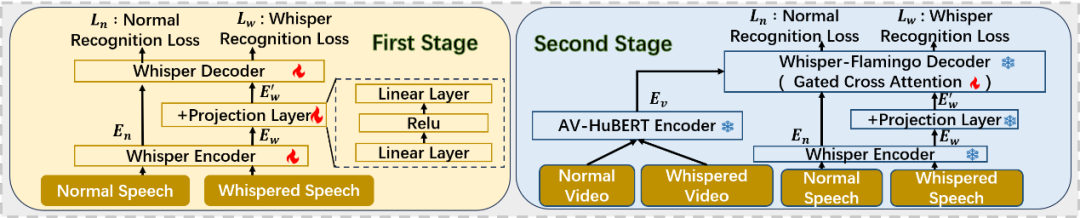
图**1 模型架构
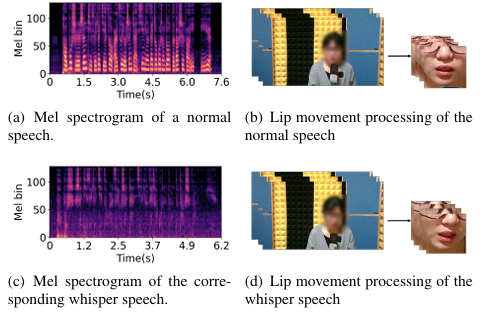
下图展示了经过处理的音频和视频数据示例,包括正常语音与对应耳语语音的梅尔频谱图,以及音频对应的可视化唇部运动。语音频谱图中观察到的显著差异,尤其是基频缺失的现象,证明了传统语音识别系统在处理耳语语音时具有声学挑战性。
实验结果表明,该模型在我们构建的AISHELL6-Whisper测试集上,耳语识别字错误率低至4.13% ,正常语音为1.11% 。此外,在公开的wTIMIT英语耳语数据集上进行跨语言评估时,模型同样取得了当前最优性能,表现出良好的泛化能力。
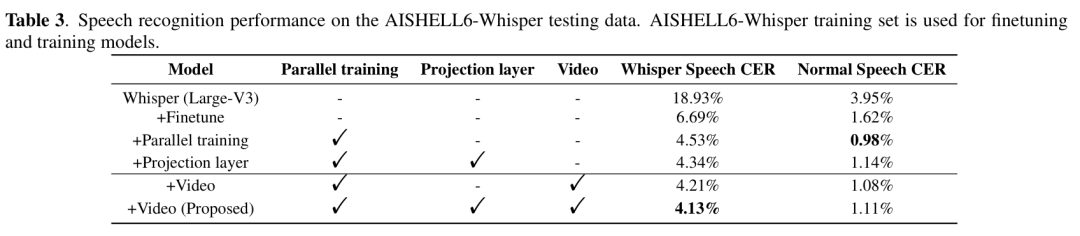
图2AISHELL6-Whisper**测试集实验结果