目录
我们这里所有的类都存放在下面的的detail.hpp里面
一.简单日志宏实现
意义:快速定位程序运⾏逻辑出错的位置。
项⽬在运⾏中可能会出现各种问题,出问题不可怕,关键的是要能找到问题,并解决问题。
解决问题的⽅式:
- gdb调试:逐步调试过于繁琐,缓慢。主要⽤于程序崩溃后的定位。
- 系统运⾏⽇志分析:在任何程序运⾏有可能逻辑错误的位置进⾏输出提⽰,快速定位逻辑问题的位置。
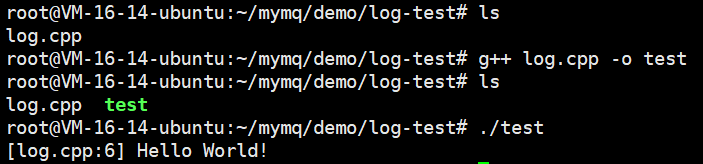
我们日志宏的代码都存放到这个log.hpp
封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
例如: 17.22.58 log.cpp:12打开文件失败
那么具体怎么实现呢?
那么还记得
您可以把__FILE__和__LINE__理解为两个"魔法标记",它们的作用是在编译时,由编译器自动填入当前代码所在的位置信息。
它们的具体含义如下:
- FILE
- 它是什么:它是一个字符串常量。
- 它代表什么:它代表了**当前源代码文件的完整路径名或文件名。**编译器在处理这行代码时,会将它替换成当前源文件的名字。例如,如果你的文件叫做 main.c,那么 FILE 就会被替换为 "main.c"。在某些编译环境中,它可能会包含完整的文件路径,如 "D:/project/src/main.c"。
- LINE
- 它是什么:它是一个整数常量。
- 它代表什么:它代表了**当前代码在源文件中的行号。**编译器会将它替换成一个数字,这个数字就是这行代码(即 LINE 这行本身)在文件中的具体行数。如果你把这段代码移动到文件的第50行,那么 LINE 的值在下次编译时就会变成50。
cpp
#include<iostream>
//封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [17.22.58 log.cpp:12]打开文件失败
int main()
{
printf("[%s:%d] Hello World!\n",__FILE__,__LINE__);
}
可以看到。还是很不错的
但是还有一个系统事件呢!这个怎么搞?
我们需要学习一些新的东西
1. time() 函数 - 获取时间戳
cpp
time_t t = time(nullptr);作用:
- time() 函数返回从 1970年1月1日00:00:00 UTC(Unix纪元)到当前时间的秒数
- 这个秒数被称为 "时间戳" 或 "Unix时间戳"
- time_t 是一个整数类型(通常是 long int),用于存储这个秒数
参数:
- nullptr(或 NULL)表示我们不需要将时间戳存储到额外的地方
- 如果传入一个 time_t 类型变量的地址,函数也会把时间戳写入那个地址
类比:
想象一个从1970年1月1日开始计时的巨大秒表,time() 就是按下秒表查看当前累积秒数的按钮。
2. localtime() 函数 - 转换成本地时间结构
cpp
struct tm* ptm = localtime(&t);作用:
- 将 time() 得到的秒数(时间戳)转换成本地时间的各个组成部分
- 返回一个指向 tm 结构体的指针,这个结构体包含了年、月、日、时、分、秒等各个字段
tm 结构体包含的字段:
- tm_sec - 秒 (0-59)
- tm_min - 分 (0-59)
- tm_hour - 时 (0-23)
- tm_mday - 一个月中的第几天 (1-31)
- tm_mon - 月 (0-11,0代表1月)
- tm_year - 年(从1900年开始的年数,2023年就是123)
- tm_wday - 一周中的第几天 (0-6,0代表周日)
- tm_yday - 一年中的第几天 (0-365)
- tm_isdst - 夏令时标志
重要注意事项:
- localtime() 返回的是指向静态内存区域的指针,这意味着:
- 每次调用 localtime() 都会覆盖上次的结果
- 不需要手动释放这个指针指向的内存
如果需要保存结果,应该复制结构体的内容,而不是直接保存指针
3. strftime() 函数 - 格式化时间字符串
cpp
strftime(time_str, 31, "%H:%M:%S", ptm);作用:
将 tm 结构体中的时间信息按照指定的格式字符串格式化成可读的字符串
参数详解:
- time_str:目标字符数组,用于存放格式化后的字符串
- 31:最多写入的字符数(包括结尾的空字符\0)
- "%H:%M:%S":格式控制字符串
ptm:指向 tm 结构体的指针
常用格式说明符:
- %H:24小时制的小时 (00-23)
- %I:12小时制的小时 (01-12)
- %M:分钟 (00-59)
- %S:秒 (00-59)
- %p:AM/PM 指示符
- %Y:4位数的年份
- %y:2位数的年份
- %m:月份 (01-12)
- %d:日 (01-31)
- %A:完整的星期几名称
- %a:缩写的星期几名称
- %B:完整的月份名称
- %b或%h:缩写的月份名称
示例格式:
- "%Y-%m-%d %H:%M:%S" → "2023-12-25 14:30:45"
- "%a %b %d %H:%M:%S %Y" → "Mon Dec 25 14:30:45 2023"
我们就能写出下面这个
cpp
#include<iostream>
#include<ctime>
//封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [17.22.58 log.cpp:12]打开文件失败
int main()
{
time_t t=time(nullptr);
struct tm* ptm=localtime(&t);
char time_str[32];
strftime(time_str,31,"%H:%M:%S",ptm);
printf("[%s][%s:%d] Hello World!\n",time_str,__FILE__,__LINE__);
}
但是我们不能每次调用的时候都写这么多代码吧
那么我们就需要将它封装成宏函数
此外,我们还需要了解一些宏函数相关的知识
在 C/C++ 中,宏函数必须定义在一行内,或者通过反斜杠(\)进行换行连接。
cpp
// ✅ 正确的多行写法(使用反斜杠续行)
#define COMPLEX_MACRO(a, b, c) do { \
int result = (a) + (b); \
if (result > (c)) { \
printf("Too big: %d\n", result); \
} else { \
printf("OK: %d\n", result); \
} \
} while(0)
// 这样子写也行,但是可读性极其差劲
#define COMPLEX_MACRO_ONE_LINE(a, b, c) do { int result = (a) + (b); if (result > (c)) { printf("Too big: %d\n", result); } else { printf("OK: %d\n", result); } } while(0)C99标准引入了不定参数宏,允许宏接受可变数量的参数。语法类似于可变参数函数,使用 ... 表示可变参数部分,并在替换部分使用 VA_ARGS 来引用这些参数。
cpp
#define PRINT(...) printf(__VA_ARGS__)
int main() {
PRINT("Hello, %s!\n", "world");
PRINT("Number: %d\n", 42);
return 0;
}注意:在C语言中,字符串常量相邻会自动连接成一个字符串
因为format是一个字符串参数,在预处理时,它会被替换成用户传入的字符串,然后与周围的字符串连接,形成一个完整的格式字符串。
cpp
#define LOG(format, ...) printf("[%s:%d] " format "\n", __FILE__, __LINE__, __VA_ARGS__)
// 使用示例
int x = 42;
LOG("Value: %d", x);
cpp
// 宏展开后的代码:
printf("[%s:%d] " "Value: %d" "\n", __FILE__, __LINE__, x);
// 编译器会处理为:
printf("[%s:%d] Value: %d\n", __FILE__, __LINE__, x);现在我们就去封装我们的日志打印宏
cpp
// 日志级别定义
#define LDBG 0 // 调试级别
#define LINF 1 // 信息级别
#define LERR 2 // 错误级别
// 默认日志级别(低于此级别的日志将不会被输出)
#define LDEFAULT LDBG // 当前设置为调试级别
// 主日志宏定义
// level: 日志级别
// format: 格式化字符串
// ...: 可变参数列表
#define LOG(level, format, ...) {\
// 检查当前日志级别是否满足输出条件
if (level >= LDEFAULT){\
// 获取当前时间
time_t t = time(NULL);\
// 转换为本地时间结构
struct tm *lt = localtime(&t);\
// 时间字符串缓冲区
char time_tmp[32] = {0};\
// 格式化时间为"月-日 时:分:秒"格式
strftime(time_tmp, 31, "%m-%d %T", lt);\
// 输出日志信息到标准输出
// 格式: [时间][文件名:行号] 用户自定义信息
fprintf(stdout, "[%s][%s:%d] " format "\n", time_tmp, __FILE__, __LINE__, __VA_ARGS__);\
}\
}
// 调试日志宏(级别为LDBG)
#define DLOG(format, ...) LOG(LDBG, format, __VA_ARGS__);
// 信息日志宏(级别为LINF)
#define ILOG(format, ...) LOG(LINF, format, __VA_ARGS__);
// 错误日志宏(级别为LERR)
#define ELOG(format, ...) LOG(LERR, format, __VA_ARGS__);但是现在还有一个问题。
如果说我传递的是只是两个参数进去
cpp
LOG(LDBG,"hello World");那么宏函数的不定参数就会报错啊。
上面的LOG宏定义中,format 和 ... 是分开的,这样调用时就需要至少两个参数(level和format),然后可变参数至少一个(因为__VA_ARGS__至少需要一个参数)。
- 使用C99标准中的__VA_ARGS__,并确保在调用时至少提供一个参数(但这样就不能完全省略可变参数)。
- 使用##VA_ARGS(GCC扩展),这样当可变参数为空时,就没有一点问题。
如果你希望允许可变参数为空,则需要使用**##VA_ARGS**。
cpp
#define LDBG 0
#define LINF 1
#define LERR 2
#define LDEFAULT LDBG
#define LOG(level, format, ...) {\
if (level >= LDEFAULT){\
time_t t = time(NULL);\
struct tm *lt = localtime(&t);\
char time_tmp[32] = {0};\
strftime(time_tmp, 31, "%m-%d %T", lt);\
fprintf(stdout, "[%s][%s:%d] " format "\n", time_tmp, __FILE__, __LINE__, ##__VA_ARGS__);\
}\
}
#define DLOG(format, ...) LOG(LDBG, format, ##__VA_ARGS__);
#define ILOG(format, ...) LOG(LINF, format, ##__VA_ARGS__);
#define ELOG(format, ...) LOG(LERR, format, ##__VA_ARGS__);这样子编译就不会报错了。
测试代码
cpp
// 最简单的使用方式
int main() {
// 使用简化宏,只需要传递一个字符串(两个参数:宏本身+字符串)
DLOG("这是一个简单的调试消息");
ILOG("这是一个信息消息");
ELOG("这是一个错误消息");
// 带参数的用法
int x = 10, y = 20;
DLOG("x = %d, y = %d", x, y);
return 0;
}
完全没有问题
二.Json序列化/反序列化工具类实现
2.1.原理讲解
不知道大家还记不记得我们JsonCpp库是如何进行序列化和反序列化的?
序列化
当需要将一个Json::Value对象序列化为JSON字符串时,使用jsoncpp库的程序通常会执行以下步骤(基于下面的代码示例和新版jsoncpp库的接口):
准备数据:
- 创建一个Json::Value对象,并根据需要向其添加键值对、数组、嵌套对象等。
创建序列化器:
- **使用Json::StreamWriterBuilder对象的newStreamWriter方法创建一个Json::StreamWriter的智能指针。**这个序列化器将负责将Json::Value对象转换为JSON格式的字符串。
准备输出流:
- **创建一个输出流对象,如std::stringstream,用于存储序列化后的JSON字符串。**也可以使用其他输出流,如std::ofstream来写入文件。
执行序列化:
- 调用Json::StreamWriter智能指针的write方法,将Json::Value对象作为参数传入,并指定输出流。write方法会遍历Json::Value对象的结构,并将其转换为JSON格式的字符串,然后写入到指定的输出流中。
获取和使用JSON字符串:
- 如果使用了std::stringstream,可以通过调用其str方法来获取序列化后的JSON字符串。然后,可以将这个字符串用于各种目的,如打印到控制台、发送到网络、保存到文件等。
这些步骤概述了使用jsoncpp库将Json::Value对象序列化为JSON字符串的典型过程。
我们看个例子
cpp
/*
json 序列化示例
*/
#include <iostream> // 引入标准输入输出流库
#include <sstream> // 引入字符串流库
#include <memory> // 引入内存管理库(用于智能指针)
#include <jsoncpp/json/json.h> // 引入jsoncpp库,用于JSON处理
int main()
{
// 定义并初始化一个常量字符指针,指向字符串"小明"
// 定义一个整型变量并初始化为18,表示年龄
int age = 18;
// 定义一个浮点型数组,存储三门课程的成绩
float score[] = {77.5, 88, 93.6};
// 定义一个Json::Value对象,作为JSON数据的根节点
Json::Value root;
// 向root中添加一个键值对,键为"name",值为name所指向的字符串
root["name"] ="xiaoming";
// 向root中添加一个键值对,键为"age",值为整型变量age
root["age"] = age;
// 向root中添加一个键为"成绩"的数组,并依次添加score数组中的元素
// 使用append函数向数组中插入数据
root["chengji"].append(score[0]);
root["chengji"].append(score[1]);
root["chengji"].append(score[2]);
// 创建一个Json::StreamWriterBuilder对象,用于配置StreamWriter的创建
Json::StreamWriterBuilder swb;
// 使用swb的newStreamWriter方法创建一个StreamWriter的智能指针
// std::unique_ptr是一个智能指针,它会在离开作用域时自动释放所管理的资源
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());
// 创建一个字符串流对象,用于存储序列化后的JSON字符串
std::stringstream ss;
// 调用StreamWriter的write方法,将Json::Value对象序列化为JSON字符串,并写入到字符串流中
sw->write(root, &ss);
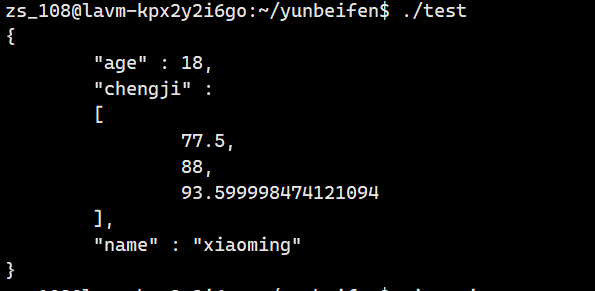
// 从字符串流中提取出序列化后的JSON字符串,并输出到标准输出流(控制台)
std::cout << ss.str() << std::endl;
return 0;
}
反序列化
- 工作机制
- 当需要将一个JSON格式的字符串解析为程序对象时,可以使用CharReader 类。
- 首先,通过 CharReaderBuilder 类创建一个 CharReader 对象的实例。
- 然后,调用该实例的 parse 函数,传入字符数组的起始和结束指针、一个指向 Value 对象的指针和一个指向字符串的指针(用于存储错误信息)。
- 在解析过程中,Reader 或 CharReader 类会遍历JSON文档,并根据JSON的语法规则构建相应的 Value 对象结构。如果遇到错误(如语法错误、类型不匹配等),解析器会停止解析,并通过返回值或错误信息字符串来指示错误。
- 解析成功后,调用者可以访问 Value 对象来获取解析后的JSON数据。
JSON的反序列化(也称为解析)是将JSON格式的字符串数据转换回其对应的程序数据结构(如对象、数组、键值对等)的过程。在jsoncpp库中,这一过程主要通过Json::CharReader(或其派生类)的parse方法来实现。以下是对jsoncpp库中JSON反序列化实现过程的详细解释:
JSON字符串准备:
- 首先,你需要有一个包含JSON数据的字符串。这个字符串可能来自文件、网络请求、用户输入等。
Json::Value对象创建:
- 创建一个Json::Value对象,它将用于存储解析后的JSON数据。Json::Value是jsoncpp库中的一个核心类,用于表示JSON中的各种数据类型(如对象、数组、字符串、数字等)。
CharReader配置与创建:
- 使用Json::CharReaderBuilder来配置并创建一个Json::CharReader对象(或其派生类)。CharReaderBuilder允许你设置一些解析选项,但大多数情况下,你可以使用默认设置。
- Json::CharReader是负责实际解析JSON字符串的类。它通过其parse方法来完成解析工作。
调用parse方法:
- 调用Json::CharReader对象的parse方法,将JSON字符串、字符串的起始和结束指针、Json::Value对象的引用以及一个用于存储错误信息的字符串的引用作为参数传入。
- parse方法会尝试将JSON字符串解析为Json::Value对象表示的数据结构。如果解析成功,Json::Value对象将被填充为相应的数据;如果解析失败,错误信息将被存储在提供的字符串中。
检查解析结果:
- 解析完成后,你需要检查parse方法的返回值来确定解析是否成功。如果返回true,则表示解析成功;如果返回false,则表示解析失败,并且你可以通过提供的错误信息字符串来获取详细的错误信息。
访问解析后的数据:
- 一旦解析成功,你就可以使用Json::Value对象提供的各种方法来访问和操作解析后的数据了。例如,你可以使用operator\[\]来访问对象中的键或数组中的元素,并使用asString()、asInt()、asDouble()等方法来将数据转换为适当的类型。
在jsoncpp库的内部实现中,Json::CharReader的parse方法会逐字符地分析JSON字符串,并根据JSON的语法规则构建相应的Json::Value对象。这个过程涉及到对JSON各种数据类型的识别和处理(如对象、数组、字符串、数字、布尔值、null等),以及对JSON语法错误(如缺少引号、括号不匹配、逗号放错位置等)的检测和报告。
main.cpp
cpp
/*
json 反序列化示例
*/
#include <iostream> // 引入标准输入输出流库
#include <string> // 引入字符串库
#include <memory> // 引入内存管理库(用于智能指针)
#include <jsoncpp/json/json.h> // 引入jsoncpp库,用于JSON处理
int main()
{
// 定义一个字符串,存储JSON格式的文本数据
std::string str = R"({"姓名":"小黑", "年龄":19, "成绩":[58.5, 44, 20]})";
// 创建一个Json::Value对象,用于存储解析后的JSON数据
Json::Value root;
// 创建一个Json::CharReaderBuilder对象,用于配置CharReader的创建
Json::CharReaderBuilder crb;
// 使用crb的newCharReader方法创建一个CharReader的智能指针
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());
// 定义一个字符串,用于存储解析过程中可能发生的错误信息
std::string err;
// 调用CharReader的parse方法,尝试将字符串str解析为JSON数据,并存储在root中
// parse方法的参数包括:待解析的字符串的起始指针、结束指针、存储解析结果的Json::Value对象的指针、存储错误信息的字符串的指针
bool ret = cr->parse(str.c_str(), str.c_str() + str.size(), &root, &err);
// 检查解析是否成功
if(ret == false)
{
// 如果解析失败,输出错误信息并返回-1
std::cout << "parse error: " << err << std::endl;
return -1;
}
// 从解析后的JSON数据中提取"姓名"字段的值,并作为字符串输出
std::cout << root["姓名"].asString() << std::endl;
// 从解析后的JSON数据中提取"年龄"字段的值,并作为整数输出
std::cout << root["年龄"].asInt() << std::endl;
// 获取"成绩"字段(一个数组)的大小
int sz = root["成绩"].size();
// 遍历"成绩"数组,并输出每个元素的值
for(int i = 0; i < sz; i++)
{
std::cout << root["成绩"][i].asDouble() << std::endl; // 注意:这里使用asDouble()来确保输出浮点数的精度
}
// 程序正常结束,返回0
return 0;
}
那么很快,我们就能实现我们的JSON工具类
JSON工具类代码
cpp
// JSON序列化和反序列化工具类
class JSON
{
public:
// 将Json::Value对象序列化为JSON格式字符串
// 参数:
// val: 要序列化的Json::Value对象
// body: 输出参数,序列化后的JSON字符串
// 返回值:
// bool: 序列化成功返回true,失败返回false
static bool serialize(const Json::Value &val, std::string &body)
{
// 创建字符串流用于构建JSON字符串
std::stringstream ss;
// 创建StreamWriterBuilder工厂类对象,用于创建StreamWriter
Json::StreamWriterBuilder swb;
// 使用工厂创建StreamWriter对象
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());
// 将Json::Value对象写入字符串流
int ret = sw->write(val, &ss);
// 检查序列化是否成功
if (ret != 0)
{
// 序列化失败,记录错误日志
ELOG("json serialize failed!");
return false;
}
// 从字符串流中获取序列化后的JSON字符串
body = ss.str();
return true;
}
// 将JSON格式字符串反序列化为Json::Value对象
// 参数:
// body: 要反序列化的JSON格式字符串
// val: 输出参数,反序列化后的Json::Value对象
// 返回值:
// bool: 反序列化成功返回true,失败返回false
static bool unserialize(const std::string &body, Json::Value &val)
{
// 创建CharReaderBuilder工厂类对象,用于创建CharReader
Json::CharReaderBuilder crb;
// 存储解析过程中的错误信息
std::string errs;
// 使用工厂创建CharReader对象
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());
// 解析JSON字符串,将其转换为Json::Value对象
// 参数说明:
// body.c_str(): JSON字符串的起始位置
// body.c_str() + body.size(): JSON字符串的结束位置
// &val: 输出参数,解析得到的Json::Value对象
// &errs: 输出参数,解析过程中的错误信息
bool ret = cr->parse(body.c_str(), body.c_str() + body.size(), &val, &errs);
// 检查反序列化是否成功
if (ret == false)
{
// 反序列化失败,记录错误日志(包含错误信息)
ELOG("json unserialize failed : %s", errs.c_str());
return false;
}
return true;
}
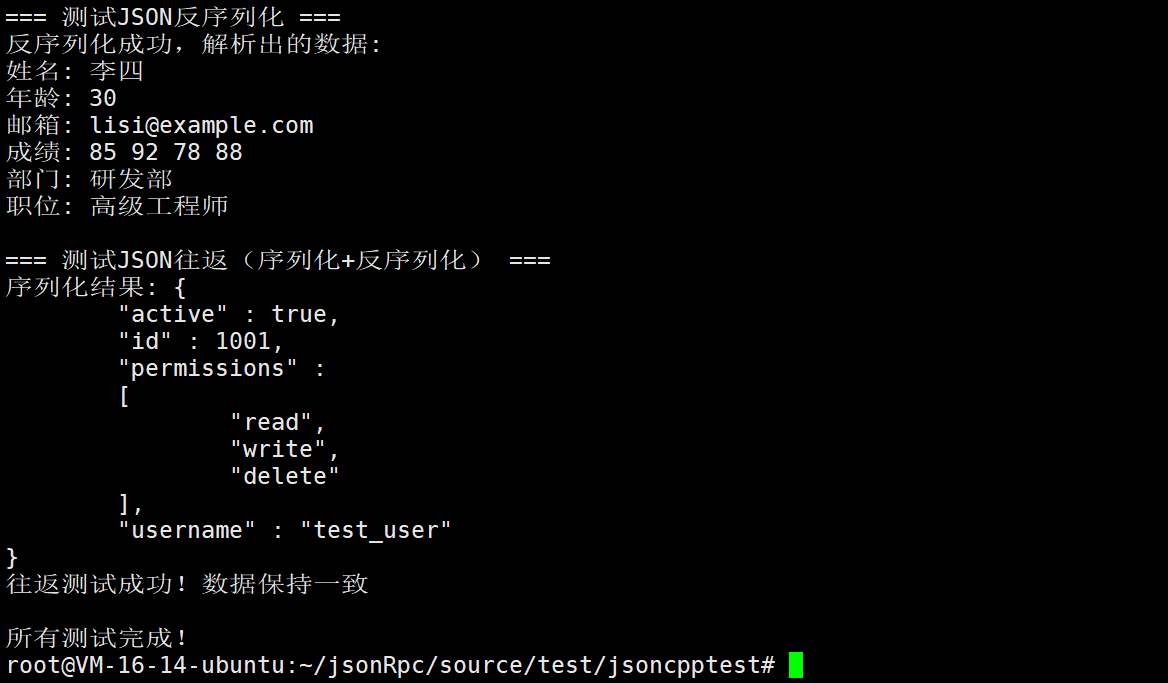
};2.2.测试
现在,我们就写一个测试程序来进行测试一下
cpp
// 测试JSON类的使用示例
#include <iostream>
#include <string>
#include "../../common/detail.hpp"
using namespace bitrpc;
//序列化测试
void test_json_serialize() {
std::cout << "=== 测试JSON序列化 ===" << std::endl;
// 创建一个复杂的JSON对象
Json::Value root;
root["name"] = "张三";
root["age"] = 25;
root["is_student"] = false;
// 添加数组
Json::Value hobbies(Json::arrayValue);
hobbies.append("篮球");
hobbies.append("阅读");
hobbies.append("编程");
root["hobbies"] = hobbies;
// 添加嵌套对象
Json::Value address;
address["city"] = "北京";
address["street"] = "中关村大街";
address["zipcode"] = "100080";
root["address"] = address;
// 序列化JSON对象
std::string json_str;
bool result = JSON::serialize(root, json_str);
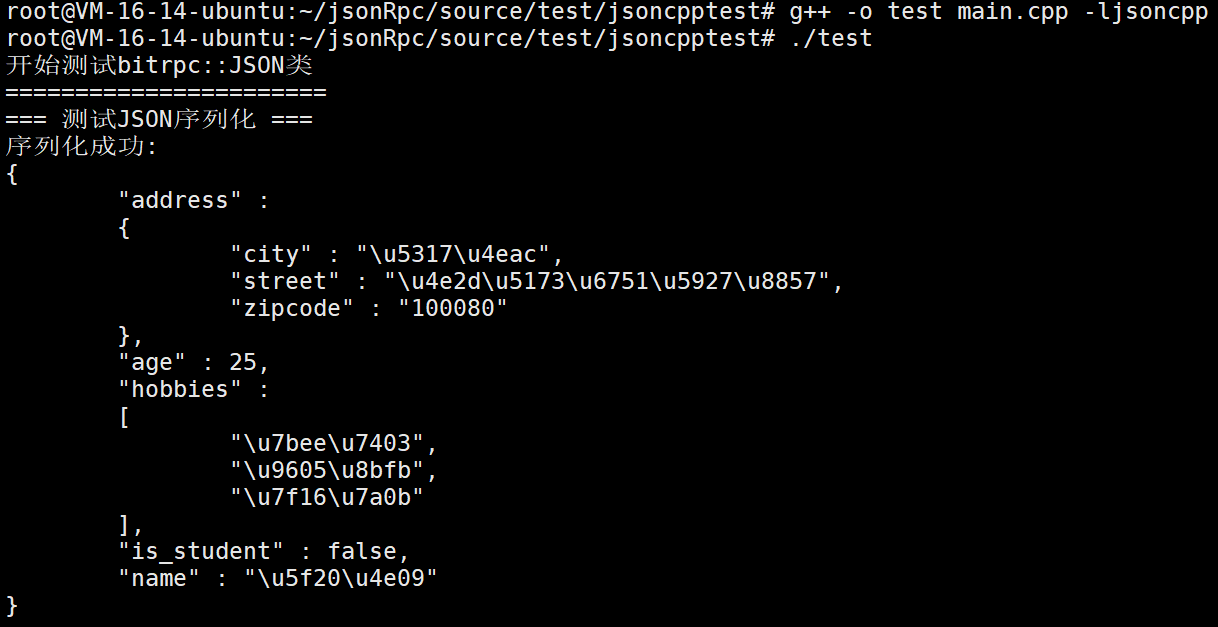
if (result) {
std::cout << "序列化成功:" << std::endl;
std::cout << json_str << std::endl;
} else {
std::cout << "序列化失败" << std::endl;
}
}
//反序列化测试
void test_json_unserialize() {
std::cout << "\n=== 测试JSON反序列化 ===" << std::endl;
// 一个合法的JSON字符串
std::string json_str = R"({
"name": "李四",
"age": 30,
"email": "lisi@example.com",
"scores": [85, 92, 78, 88],
"info": {
"department": "研发部",
"position": "高级工程师"
}
})";
Json::Value root;
bool result = JSON::unserialize(json_str, root);
if (result) {
std::cout << "反序列化成功,解析出的数据:" << std::endl;
// 提取并显示数据
if (root.isMember("name")) {
std::cout << "姓名: " << root["name"].asString() << std::endl;
}
if (root.isMember("age")) {
std::cout << "年龄: " << root["age"].asInt() << std::endl;
}
if (root.isMember("email")) {
std::cout << "邮箱: " << root["email"].asString() << std::endl;
}
// 处理数组
if (root.isMember("scores") && root["scores"].isArray()) {
std::cout << "成绩: ";
for (const auto& score : root["scores"]) {
std::cout << score.asInt() << " ";
}
std::cout << std::endl;
}
// 处理嵌套对象
if (root.isMember("info")) {
std::cout << "部门: " << root["info"]["department"].asString() << std::endl;
std::cout << "职位: " << root["info"]["position"].asString() << std::endl;
}
} else {
std::cout << "反序列化失败" << std::endl;
}
}
void test_json_round_trip() {
std::cout << "\n=== 测试JSON往返(序列化+反序列化) ===" << std::endl;
// 创建原始对象
Json::Value original;
original["id"] = 1001;
original["username"] = "test_user";
original["active"] = true;
Json::Value permissions(Json::arrayValue);
permissions.append("read");
permissions.append("write");
permissions.append("delete");
original["permissions"] = permissions;
// 序列化
std::string serialized;
JSON::serialize(original, serialized);
std::cout << "序列化结果: " << serialized << std::endl;
// 反序列化
Json::Value deserialized;
JSON::unserialize(serialized, deserialized);
// 比较关键字段
if (deserialized["id"].asInt() == original["id"].asInt() &&
deserialized["username"].asString() == original["username"].asString() &&
deserialized["active"].asBool() == original["active"].asBool()) {
std::cout << "往返测试成功!数据保持一致" << std::endl;
} else {
std::cout << "往返测试失败!数据不一致" << std::endl;
}
}
int main() {
std::cout << "开始测试bitrpc::JSON类" << std::endl;
std::cout << "=======================" << std::endl;
// 设置日志级别为调试,以便看到所有日志
#undef LDEFAULT
#define LDEFAULT LDBG
// 运行各种测试
test_json_serialize();
test_json_unserialize();
test_json_round_trip();
std::cout << "\n所有测试完成!" << std::endl;
return 0;
}
三.UUID工具类实现
UUID(通用唯一识别码,Universally Unique Identifier)是一种用于确保全局唯一性的标识符标准。
我们将根据下面这3个步骤来生成我们的UUID
一、基本结构设计
生成器采用16字节(32位十六进制字符) 的复合结构,分为两个部分:
- 前8字节:完全随机数,确保全局唯一性
- 后8字节:顺序递增的序号,增强可读性和可追溯性
二、生成过程详解
第一步:生成随机部分(前8字节)
- 使用高质量的随机数生成器(std::random_device和std::mt19937_64)生成真正的随机数
- 生成8个0-255之间的随机整数,每个整数对应一个字节,八个整数对应八个字节
- 将每个字节转换为2位十六进制字符串,不足两位时前面补零
- 在特定的位置(第4、6、8个字节后)插入连字符"-",初步形成8-4-4的格式
第二步:生成序号部分(后8字节)
- 使用原子计数器seq确保线程安全,序号从1开始递增
- 每次调用uuid()函数时,原子性地获取并递增序号
- 将64位序号的8个字节从高位到低位依次提取
- 每个字节同样转换为2位十六进制字符串,前面补零
- 在倒数第2个字节后(即16个十六进制字符的第6个字节后)插入连字符"-"
第三步:格式拼接
- 前8字节随机部分已形成:XXXXXXXX-XXXX-XXXX-(注意最后的连字符)
- 后8字节序号部分形成:XXXXXXXX-XXXX格式
- 两部分直接拼接,最终形成:XXXXXXXX-XXXX-XXXX-XXXXXXXX-XXXX的格式
话不多说,我们先看看随机数是怎么生成的
cpp
#include <iostream>
#include <random>
int main() {
// 创建random_device对象
std::random_device rd;
// 生成一个随机数
int random_number = rd();
std::cout << "随机数: " << random_number << std::endl;
// 再生成一个
int another_random = rd();
std::cout << "另一个随机数: " << another_random << std::endl;
return 0;
}
但是这个随机数是机器随机数,根据硬件生成的,每次生成都需要访问硬件,生成效率低下
这个时候我们就需要学习一个新的随机数生成算法
std::mt19937:
-
这是一个伪随机数生成器,使用梅森旋转算法,周期非常长(2^19937-1),速度很快。
-
它需要种子来初始化,一旦初始化,就可以快速生成高质量的伪随机数序列。
cpp
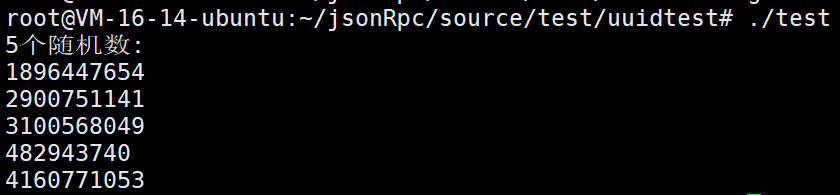
#include <iostream>
#include <random>
int main() {
// 第一步:创建random_device获取高质量随机种子
std::random_device rd;
// 第二步:用random_device的输出来初始化mt19937
std::mt19937 generator(rd());
// 第三步:使用generator生成随机数
std::cout << "5个随机数:" << std::endl;
for (int i = 0; i < 5; i++) {
// 注意:这里调用的是generator(),不是rd()
std::cout << generator() << std::endl;
}
return 0;
}
还是很不错的吧
但是我们需要生成8个0-255之间的随机整数,我们怎么生成指定范围的随机数呢?
例子:生成指定范围的随机数
cpp
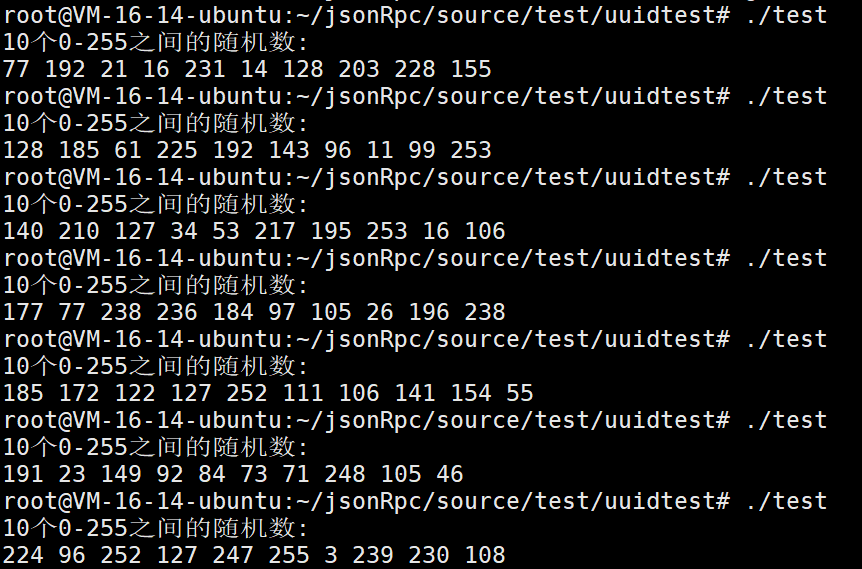
#include <iostream>
#include <random>
int main() {
// 初始化随机数生成器
std::random_device rd;
std::mt19937 generator(rd());
// 生成0-255之间的随机数
std::uniform_int_distribution<int> dist(0, 255);
std::cout << "10个0-255之间的随机数:" << std::endl;
for (int i = 0; i < 10; i++) {
std::cout << dist(generator) << " ";
}
std::cout << std::endl;
return 0;
}
还是很简单的。
那么问题又来了,我们怎么把一个十进制的数字转换成一个十六进制的数呢?
我们使用std::stringstream和std::hex来将十进制整数转换为十六进制字符串。
根据这个思路,我们就能写成下面这个
cpp
#include <iostream>
#include <random>
#include <sstream>
int main() {
// 初始化随机数生成器
std::random_device rd;
std::mt19937 generator(rd());
// 生成0-255之间的随机数
std::uniform_int_distribution<int> dist(0, 255);
std::cout << "10个0-255之间的随机数:" << std::endl;
for (int i = 0; i < 10; i++) {
std::stringstream ss;
ss<<std::hex<<dist(generator);
std::cout << ss.str() << " ";
}
std::cout << std::endl;
return 0;
}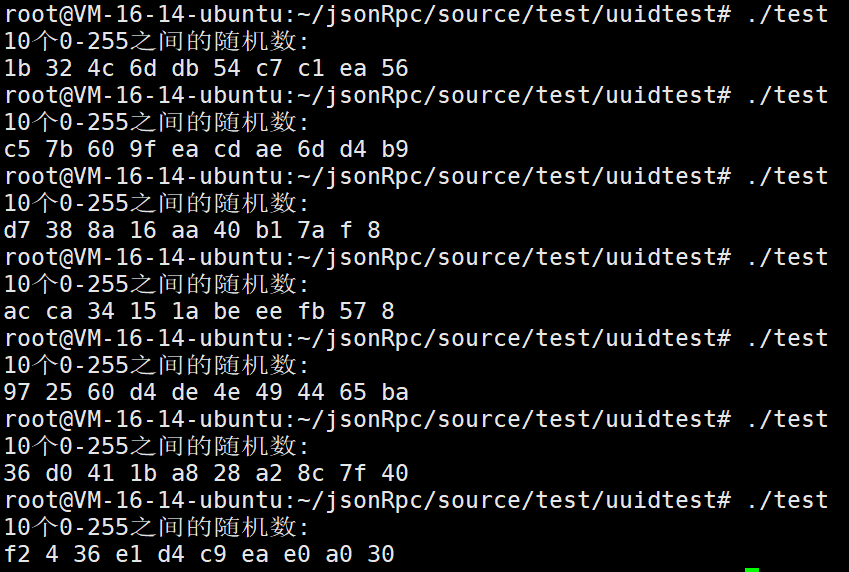
但是我们仔细观察一下:有的随机数只有1位,有的随机数却有2位,我们必须得确保生成的随机数都是2位的
cpp
#include <iostream>
#include <random>
#include <sstream>
#include <iomanip>
int main() {
// 初始化随机数生成器
std::random_device rd;
std::mt19937 generator(rd());
// 生成0-255之间的随机数
std::uniform_int_distribution<int> dist(0, 255);
std::cout << "10个0-255之间的随机数:" << std::endl;
for (int i = 0; i < 10; i++) {
std::stringstream ss;
//带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss<<std::hex<< std::setw(2) << std::setfill('0') <<dist(generator);
std::cout << ss.str() << " ";
}
std::cout << std::endl;
return 0;
}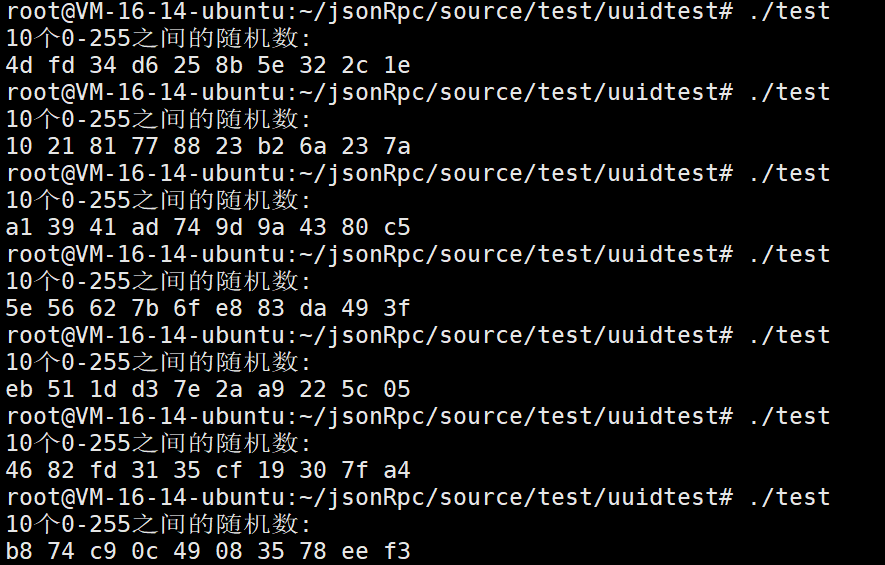
现在我们生成的随机都是2位的。保持格式统一了。
我们前面的目标可是生成8个1-100之间的随机数,一个随机数变成16进制就是XX这样子的,我们按照XXXXXXXX-XXXX-XXXX-(注意最后的连字符)连接起来。
我们现在就能实现了
cpp
#include <iostream>
#include <random>
#include <sstream>
#include <iomanip>
int main()
{
// 初始化随机数生成器
std::random_device rd;
std::mt19937 generator(rd());
// 生成1-100之间的随机数
std::uniform_int_distribution<int> dist(1, 100);
std::stringstream ss; // 注意这个在外面了
// 生成8个1-100之间的随机数,并按照XXXXXXXX-XXXX-XXXX-(注意最后的连字符)连接起来
for (int i = 0; i < 8; i++)
{
if (i == 4 || i == 6)
{
ss << "-";
}
// 带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') << dist(generator);
}
ss<<"-";
std::cout << ss.str() << std::endl;
return 0;
}我们运行看看
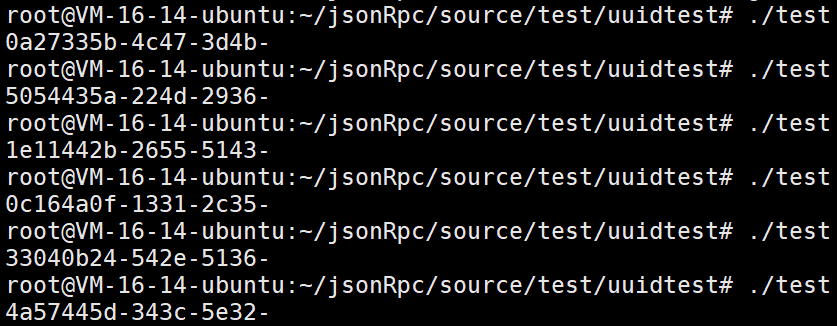
还是很不错的。
但是还是不够的我们还需要实现下面这个
第二步:生成序号部分(后8字节)
- 使用原子计数器seq确保线程安全,序号从1开始递增
- 每次调用uuid()函数时,原子性地获取并递增序号
- 将64位序号的8个字节从高位到低位依次提取
- 每个字节同样转换为2位十六进制字符串,前面补零
- 在倒数第2个字节后(即16个十六进制字符的第6个字节后)插入连字符"-"
这里其实涉及到两个关键操作
- 右移操作(>>)将数字的二进制表示向右移动指定的位数。
- & 0xFF 操作保留最低的8位(1个字节),清空其他位。
我们马上就能实现
cpp
#include <iostream>
#include <random>
#include <sstream>
#include <iomanip>
#include<atomic>
int main() {
// 初始化随机数生成器
std::random_device rd;
std::mt19937_64 generator(rd());
// 生成1-100之间的随机数
std::uniform_int_distribution<int> dist(1, 100);
std::stringstream ss;//注意这个在外面了
//生成8个1-100之间的随机数,并按照XXXXXXXX-XXXX-XXXX-(注意最后的连字符)连接起来
for (int i = 0; i < 8; i++) {
//带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') <<dist(generator);
if(i==3 || i==5 || i==7)
{
ss<<"-";
}
}
static std::atomic<size_t> seq(1);//定义一个原子类型的整数,初始化为1
size_t num=seq.fetch_add(1);//size_t是一个八个字节的无符号整型,也就是64位,刚好是我们第二部的的长度
//每次提取最低的8位,一共64位,需要提取8次
for (int i = 7; i >= 0; i--) {
// 步骤1:右移 (i * 8) 位,将目标字节移到最低8位
uint64_t shifted = num >> (i * 8);
// 步骤2:使用 & 0xFF 提取最低8位
uint64_t byte = shifted & 0xFF;
//带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') <<byte;
if(i==6)
{
ss<<"-";
}
}
std::cout << ss.str() <<std::endl;
return 0;
}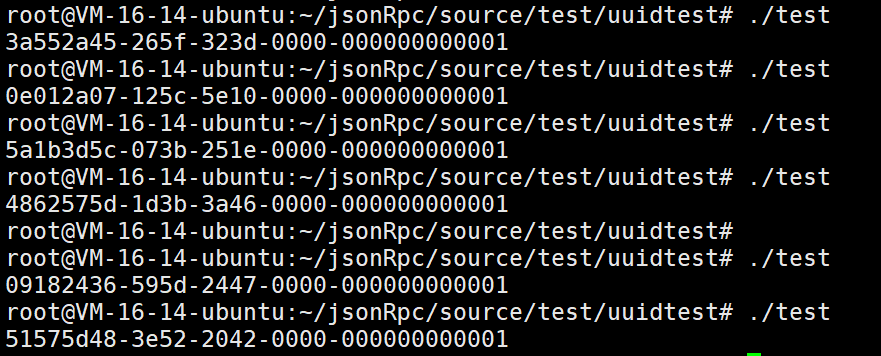
到这里我们就算是写完了
我们把它封装成一个类
cpp
#include <iostream>
#include <random>
#include <sstream>
#include <iomanip>
#include <atomic>
class UUID
{
public:
static std::string uuid()
{
std::stringstream ss;
// 1. 构造一个机器随机数对象
std::random_device rd;
// 2. 以机器随机数为种子构造伪随机数对象
std::mt19937 generator(rd());
// 3. 构造限定数据范围的对象
std::uniform_int_distribution<int> distribution(0, 255);
// 4. 生成8个随机数,按照特定格式组织成为16进制数字字符的字符串
for (int i = 0; i < 8; i++)
{
if (i == 4 || i == 6)
{
ss << "-";
}
ss << std::setw(2) << std::setfill('0') << std::hex << distribution(generator);
}
ss << "-";
// 5. 定义一个8字节序号,逐字节组织成为16进制数字字符的字符串
static std::atomic<size_t> seq(1); // 定义一个原子类型的整数,初始化为1
size_t num = seq.fetch_add(1); // size_t是一个八个字节的无符号整型,也就是64位,刚好是我们第二部的的长度
// 每次提取最低的8位,size_t是8字节,一共64位,需要提取8次
for (int i = 7; i >= 0; i--)
{
// 步骤1:右移 (i * 8) 位,将目标字节移到最低8位
uint64_t shifted = num >> (i * 8);
// 步骤2:使用 & 0xFF 提取最低8位
uint64_t byte = shifted & 0xFF;
// 带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') << byte;
if (i == 6)
{
ss << "-";
}
}
return ss.str();
}
};
int main()
{
for(int i=0;i<20;i++)
{
std::cout << UUIDHelper::uuid() << std::endl;
}
return 0;
}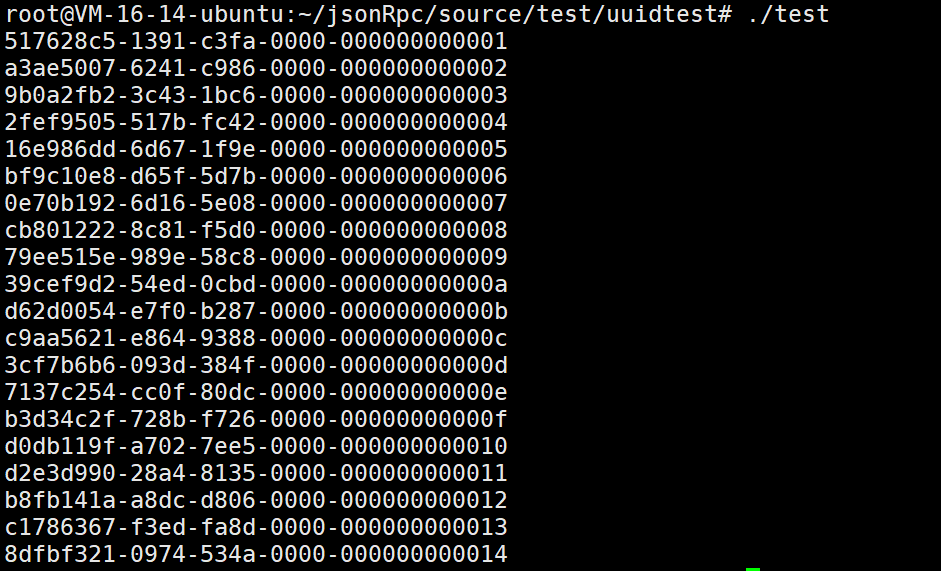
还是很不错的
四.代码整合
至此,我们的detail.hpp就算是写完了。
cpp
/*
实现项目中用到的一些琐碎功能代码
* 日志宏的定义
* json的序列化和反序列化
* uuid的生成
*/
#pragma once
#include <cstdio>
#include <ctime>
#include <iostream>
#include <string>
#include <memory>
#include <random>
#include <sstream>
#include <atomic>
#include <iomanip>
#include <jsoncpp/json/json.h>
namespace bitrpc
{
#define LDBG 0
#define LINF 1
#define LERR 2
#define LDEFAULT LDBG
#define LOG(level, format, ...) \
{ \
if (level >= LDEFAULT) \
{ \
time_t t = time(NULL); \
struct tm *lt = localtime(&t); \
char time_tmp[32] = {0}; \
strftime(time_tmp, 31, "%m-%d %T", lt); \
fprintf(stdout, "[%s][%s:%d] " format "\n", time_tmp, __FILE__, __LINE__, ##__VA_ARGS__); \
} \
}
#define DLOG(format, ...) LOG(LDBG, format, ##__VA_ARGS__);
#define ILOG(format, ...) LOG(LINF, format, ##__VA_ARGS__);
#define ELOG(format, ...) LOG(LERR, format, ##__VA_ARGS__);
// JSON序列化和反序列化工具类
class JSON
{
public:
// 将Json::Value对象序列化为JSON格式字符串
// 参数:
// val: 要序列化的Json::Value对象
// body: 输出参数,序列化后的JSON字符串
// 返回值:
// bool: 序列化成功返回true,失败返回false
static bool serialize(const Json::Value &val, std::string &body)
{
// 创建字符串流用于构建JSON字符串
std::stringstream ss;
// 创建StreamWriterBuilder工厂类对象,用于创建StreamWriter
Json::StreamWriterBuilder swb;
// 使用工厂创建StreamWriter对象
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());
// 将Json::Value对象写入字符串流
int ret = sw->write(val, &ss);
// 检查序列化是否成功
if (ret != 0)
{
// 序列化失败,记录错误日志
ELOG("json serialize failed!");
return false;
}
// 从字符串流中获取序列化后的JSON字符串
body = ss.str();
return true;
}
// 将JSON格式字符串反序列化为Json::Value对象
// 参数:
// body: 要反序列化的JSON格式字符串
// val: 输出参数,反序列化后的Json::Value对象
// 返回值:
// bool: 反序列化成功返回true,失败返回false
static bool unserialize(const std::string &body, Json::Value &val)
{
// 创建CharReaderBuilder工厂类对象,用于创建CharReader
Json::CharReaderBuilder crb;
// 存储解析过程中的错误信息
std::string errs;
// 使用工厂创建CharReader对象
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());
// 解析JSON字符串,将其转换为Json::Value对象
// 参数说明:
// body.c_str(): JSON字符串的起始位置
// body.c_str() + body.size(): JSON字符串的结束位置
// &val: 输出参数,解析得到的Json::Value对象
// &errs: 输出参数,解析过程中的错误信息
bool ret = cr->parse(body.c_str(), body.c_str() + body.size(), &val, &errs);
// 检查反序列化是否成功
if (ret == false)
{
// 反序列化失败,记录错误日志(包含错误信息)
ELOG("json unserialize failed : %s", errs.c_str());
return false;
}
return true;
}
};
class UUID
{
public:
static std::string uuid()
{
std::stringstream ss;
// 1. 构造一个机器随机数对象
std::random_device rd;
// 2. 以机器随机数为种子构造伪随机数对象
std::mt19937 generator(rd());
// 3. 构造限定数据范围的对象
std::uniform_int_distribution<int> distribution(0, 255);
// 4. 生成8个随机数,按照特定格式组织成为16进制数字字符的字符串
for (int i = 0; i < 8; i++)
{
if (i == 4 || i == 6)
{
ss << "-";
}
ss << std::setw(2) << std::setfill('0') << std::hex << distribution(generator);
}
ss << "-";
// 5. 定义一个8字节序号,逐字节组织成为16进制数字字符的字符串
static std::atomic<size_t> seq(1); // 定义一个原子类型的整数,初始化为1
size_t num = seq.fetch_add(1); // size_t是一个八个字节的无符号整型,也就是64位,刚好是我们第二部的的长度
// 每次提取最低的8位,size_t是8字节,一共64位,需要提取8次
for (int i = 7; i >= 0; i--)
{
// 步骤1:右移 (i * 8) 位,将目标字节移到最低8位
uint64_t shifted = num >> (i * 8);
// 步骤2:使用 & 0xFF 提取最低8位
uint64_t byte = shifted & 0xFF;
// 带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') << byte;
if (i == 6)
{
ss << "-";
}
}
return ss.str();
}
};
}这个过程还是很简单的