🎙️ Identity-Aware Multimodal Voice Agent (M-RAG-Voice)
一个具备声纹身份感知 、动态长期记忆 和端云混合推理能力的智能语音助手框架。
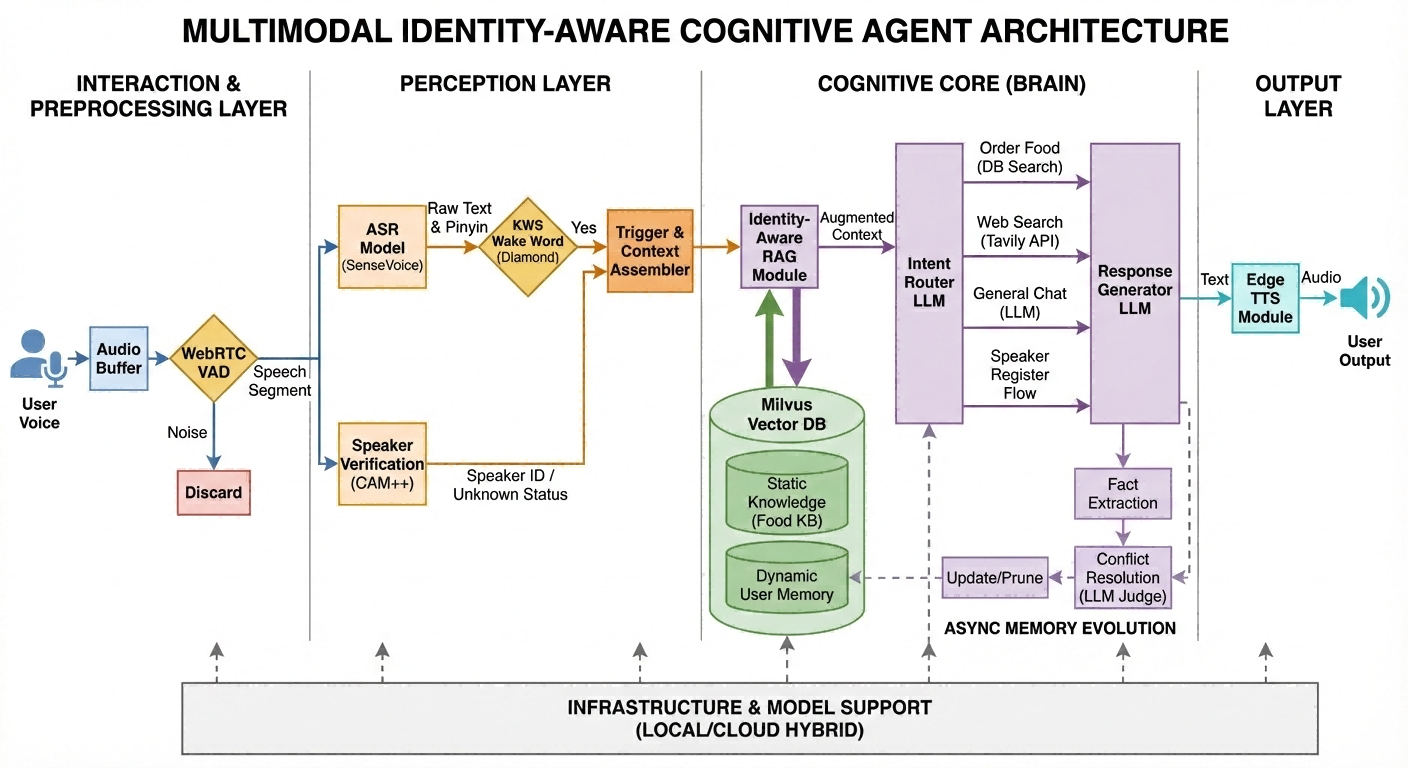
🏗️ 系统架构
系统采用 Audio-Text-Audio 闭环架构,并嵌入了身份(Identity)层:
📖 项目简介
这是一个探索性的多模态语音交互系统。不同于传统的语音助手,该项目集成了声纹识别 (Speaker Verification) 和 RAG (检索增强生成) 技术。它不仅能听懂"你在说什么",还能识别"你是谁",并根据不同用户的身份调用专属的长期记忆库(如饮食习惯、历史偏好),提供高度个性化的回答。
✨ 核心特性
- 👥 多用户声纹识别: 集成 CAM++ 模型,支持 1:N 声纹匹配。自动区分"主人"与"访客",支持语音指令注册新用户。
- 🧠 动态进化记忆: 基于 Milvus 向量数据库构建用户画像。具备"冲突裁决"机制,自动利用 LLM 分析新旧记忆冲突,实现记忆的自我更新与修正。
- ⚡ 端云混合架构 :
- 端侧 (Local): 运行高频、低延迟任务(VAD, ASR-SenseVoice, SV-CAM++, TTS)。
- 云侧/端侧灵活性: LLM (DeepSeek/Qwen) 支持本地部署或 API 调用,平衡隐私与性能。
- 🛠️ 智能意图路由: 能够区分闲聊、点餐(查询本地知识库)、联网搜索(Tavily)和系统指令。
github : 项目开源地址