目录
[(一)xarray Dataset 封装](#(一)xarray Dataset 封装)

若觉得代码对您的研究 / 项目有帮助,欢迎点击打赏支持!需要完整代码的朋友,打赏后可在后台私信(复制文章标题发给我),我会尽快发您完整可运行代码,感谢支持!
本代码聚焦气候研究中的关键量化分析需求,通过 Python 科学计算栈与专业气候指数库,实现网格化气象数据模拟、核心气候指数计算(PET、SPI、SPEI)及可视化对比 ,为干旱监测、水资源评估提供高效的技术实现方案。整体技术流程遵循 "数据构建→数据处理→指数计算→可视化" 的逻辑链,依赖多库协同完成专业化分析。
一、核心依赖库与功能分工
| 依赖库 | 核心作用 |
|---|---|
numpy |
数组运算核心,负责数据生成、维度调整、随机扰动添加等底层计算 |
pandas |
时间序列处理,快速构建标准化的月度时间轴,为气象数据提供时间坐标支撑 |
xarray |
多维气象数据封装与索引,支持按经纬度、时间快速筛选格点数据,适配气候数据的多维特性 |
matplotlib.pyplot |
结果可视化,绘制指数时间序列对比图,直观呈现干旱等级变化 |
climate_indices |
专业气候指数计算库,内置 Thornthwaite 蒸散量、SPI、SPEI 等成熟算法,简化专业计算流程 |
 本程序所使用到的Python库
本程序所使用到的Python库
二、基础参数构建与维度适配
(一)时间与空间范围定义
首先明确分析的时间跨度与空间覆盖范围,为后续数据模拟奠定基础:
python
# 构建30年月度时间序列(1991-2020),共360个时间节点
times = pd.date_range("1991-01-01", "2020-12-31", freq="MS")
# 设定2×2网格化经纬度(聚焦特定区域,减少计算量)
lats = np.array([30.0, 31.0])
lons = np.array([110.0, 111.0])(二)季节信号构建与维度修复(核心技术点)
气象数据具有显著季节性(如夏季降水多、气温高),需构建季节周期信号,同时解决维度对齐问题:
python
# 提取月份信息并转换为numpy数组,生成正弦周期信号(模拟季节变化)
month_values = times.month.values
seasonal_cycle = np.sin(2 * np.pi * month_values / 12)
# 维度扩展:将(360,)转为(360, 1, 1),确保与后续(360, 2, 2)格点数据可广播运算
seasonal_cycle_3d = seasonal_cycle[:, None, None]关键逻辑:季节信号通过正弦函数生成,周期为 12 个月,取值范围 -1,1,维度扩展是为了满足 "时间 × 纬度 × 经度" 三维数据的运算兼容性,避免维度不匹配报错。
三、网格化气象数据模拟
为规避真实气象数据的获取依赖,通过 "基础值 + 季节调制 + 随机扰动" 的方式生成符合气候规律的模拟数据:
(一)降水数据模拟(单位:mm)
python
np.random.seed(42) # 固定随机种子,保证结果可复现
# 基础降水(50mm)+ 季节调制(放大季节差异)+ 随机误差(模拟气象不确定性)
precip_base = 50 + 40 * seasonal_cycle_3d
precip_data = np.maximum(0, precip_base + np.random.normal(0, 15, (len(times), len(lats), len(lons))))核心约束 :使用np.maximum(0, ...)确保降水数据非负 ------ 符合实际气象场景中 "降水不可能为负" 的物理意义,避免数据失真。
(二)气温数据模拟(单位:℃)
python
# 基础气温(15℃)+ 季节调制(10倍季节信号,强化冬夏温差)+ 随机扰动
temp_data = 15 + 10 * seasonal_cycle_3d + np.random.normal(0, 2, (len(times), len(lats), len(lons)))数据特征:气温波动幅度(标准差 2)小于降水(标准差 15),更贴合实际气象数据的变异规律。
四、数据封装与单点数据提取
(一)xarray Dataset 封装
将分散的降水、气温数据与坐标信息整合为结构化数据集,方便后续按维度筛选:
python
ds = xr.Dataset(
{
"precip": (["time", "lat", "lon"], precip_data),
"temp": (["time", "lat", "lon"], temp_data),
},
coords={"time": times, "lat": lats, "lon": lons},
)优势 :封装后可通过ds.precip.sel(lat=30.0, lon=110.0)快速提取指定格点数据,无需手动处理数组索引,大幅提升效率。
(二)单点数据筛选(聚焦关键格点)
选择 30.0°N、110.0°E 格点的时间序列数据,用于后续指数计算(单点分析更易聚焦气候变化趋势):
python
selected_lat = ds.lat.values[0]
# 提取该格点的气温、降水月度时间序列(长度360)
temp_series = ds.temp.sel(lat=selected_lat, lon=110.0).values
precip_series = ds.precip.sel(lat=30.0, lon=110.0).values五、核心气候指数计算(专业算法落地)
(一)潜在蒸散量(PET)计算
PET 反映大气蒸发能力,是水资源平衡分析的关键参数,采用 Thornthwaite 经典方法:
python
pet = indices.pet(
temperature_celsius=temp_series,
latitude_degrees=selected_lat,
data_start_year=1991
)参数说明:需输入气温序列、纬度(影响太阳辐射,进而影响蒸散)、数据起始年份,输出月度 PET 序列(单位:mm),前 5 个月结果可初步验证计算合理性。
(二)标准化降水指数(SPI-3)计算
SPI 仅基于降水数据,通过标准化处理量化干旱程度,3 个月尺度(SPI-3)反映短期干旱:
python
spi_3 = indices.spi(
values=precip_series,
scale=3, # 时间尺度:3个月累计降水
distribution=indices.Distribution.gamma, # 降水数据常用分布假设
data_start_year=1991,
calibration_year_initial=1991,
calibration_year_final=2020,
periodicity=compute.Periodicity.monthly
)核心逻辑:先通过 1991-2020 年数据校准伽马分布参数,再将降水数据标准化为正态分布(均值 0、标准差 1),指数为负表示干旱,绝对值越大干旱越严重。
(三)标准化降水蒸散指数(SPEI-6)计算
SPEI 结合降水与蒸散(水分收支平衡),比 SPI 更能反映实际干旱影响,6 个月尺度(SPEI-6)反映中期干旱:
python
spei_6 = indices.spei(
precips_mm=precip_series,
pet_mm=pet,
scale=6,
distribution=indices.Distribution.gamma,
periodicity=compute.Periodicity.monthly,
data_start_year=1991,
calibration_year_initial=1991,
calibration_year_final=2020,
)关键差异:相比 SPI,SPEI 引入 PET 计算水分盈亏(降水 - 蒸散),更贴合作物生长、生态需水等实际场景的干旱评估需求。
六、可视化呈现与结果解读
通过图表直观对比 SPI-3 与 SPEI-6 的变化趋势,标注干旱等级阈值:
python
plt.figure(figsize=(12, 6))
plot_times = ds.time.values
# 绘制两条指数曲线,区分颜色与标签
plt.plot(plot_times, spi_3, label='SPI-3 (Precipitation)', alpha=0.7, color='blue')
plt.plot(plot_times, spei_6, label='SPEI-6 (Water Balance)', alpha=0.7, color='red')
# 添加基准线与干旱阈值(直观判断干旱等级)
plt.axhline(0, color='black', linestyle='-', linewidth=1, label='Normal')
plt.axhline(-1, color='orange', linestyle='--', label='Moderate Drought')
plt.axhline(-1.5, color='red', linestyle='--', label='Severe Drought')
# 图表美化与布局调整
plt.title("Climate Indices Comparison (Synthetic Data)", fontsize=14)
plt.xlabel("Year", fontsize=12)
plt.ylabel("Index Value", fontsize=12)
plt.legend(loc='best', fontsize=10)
plt.grid(True, alpha=0.3)
plt.tight_layout()可视化价值:可快速识别以下信息:
- 曲线低于橙色虚线(y=-1)为中度干旱,低于红色虚线(y=-1.5)为严重干旱;
- 对比两条曲线,若 SPEI-6 比 SPI-3 更负,说明该时段蒸散量大,水分消耗加剧了干旱。
七、应用场景与扩展方向
核心应用场景:
- 气象干旱监测:通过 SPI/SPEI 指数快速判断不同时段的干旱等级,为抗旱决策提供数据支撑;
- 水资源评估:结合 PET 与降水数据,分析区域水分收支平衡,为农业灌溉、水资源调度提供参考;
- 气候趋势分析:长期时间序列的指数变化可反映区域气候干湿变化趋势。
扩展方向:
- 数据替换:将模拟数据替换为真实网格化气象观测数据(如 CMIP6 模式数据、站点插值数据),提升分析的实际应用价值;
- 指数扩展:计算不同尺度(如 1 个月、12 个月)的 SPI/SPEI,分析短期、长期干旱变化;
- 空间可视化:利用 xarray 与 matplotlib 的结合,绘制 SPI/SPEI 的空间分布图,呈现干旱的空间差异。
八、运行结果
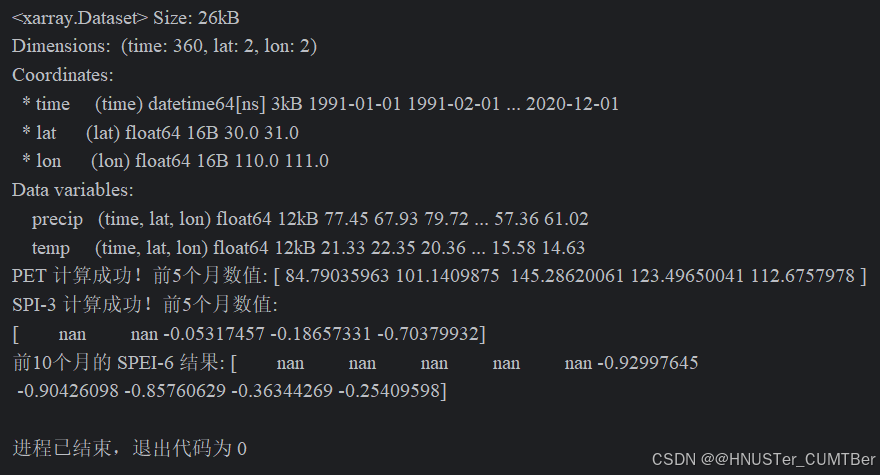 程序输出的计算结果
程序输出的计算结果
 计算结果可视化图像
计算结果可视化图像
若觉得代码对您的研究 / 项目有帮助,欢迎点击打赏支持!需要完整代码的朋友,打赏后可在后台私信(复制文章标题发给我),我会尽快发您完整可运行代码,感谢支持!