📌 本文核心:拆解旗讯OCR在报告识别、规则配置、数据解析与系统对接的核心技术亮点,适配企业级文档数字化场景,助力开发者快速理解其技术价值与落地逻辑。
在企业数字化转型过程中,非结构化文档的高效处理 始终是降本增效的关键卡点。传统人工录入、通用OCR工具普遍存在精准度不足、适配性差、无法对接业务系统等问题,尤其在行业报告、复杂表格、专业公式场景下难以满足需求。旗讯OCR以"技术适配场景"为核心,构建了覆盖"识别-解析-提取-对接"的全链路解决方案,本文将从技术实现与功能落地角度,详细拆解其核心能力。
一、高精度报告识别:攻克复杂场景识别痛点
旗讯OCR针对行业报告的多样性,通过多重技术优化实现"精准识别+高效核对",解决传统OCR在复杂格式下的适配难题。
1.1 可视化识别管理与结果呈现
系统提供识别完成列表 功能,以文件缩略图、识别状态、唯一文件编号为核心维度,支持多条件快速检索,大幅降低批量文档的管理成本。更关键的是,识别结果采用1:1版式还原技术,完美复刻原报告的排版、表格布局与文字格式,无需反复对照原文件即可完成初步核对。
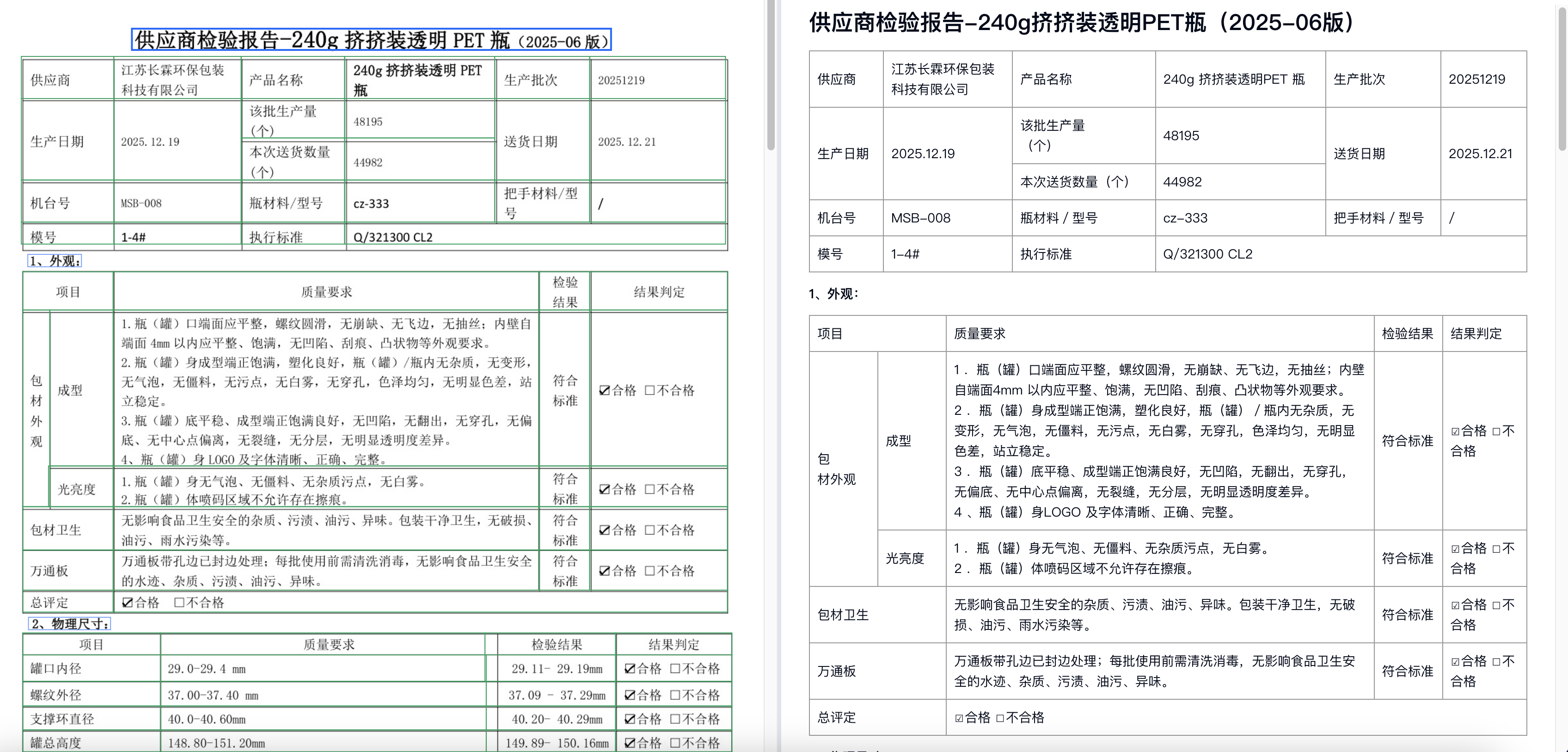
1.2 双重核对机制提升数据准确性
为解决OCR识别误差校验难题,内置两大辅助功能:
-
识别置信度色块标注:通过色值分级(如红色低置信、绿色高置信)直观标记识别内容,用户可快速锁定低置信度数据进行针对性纠偏,避免全量核对的低效操作。
-
双栏联动定位 :左侧展示原始文档、右侧呈现识别结果,点击右侧任意内容可实时跳转至左侧对应位置,核对效率较传统人工对照模式提升50%以上。
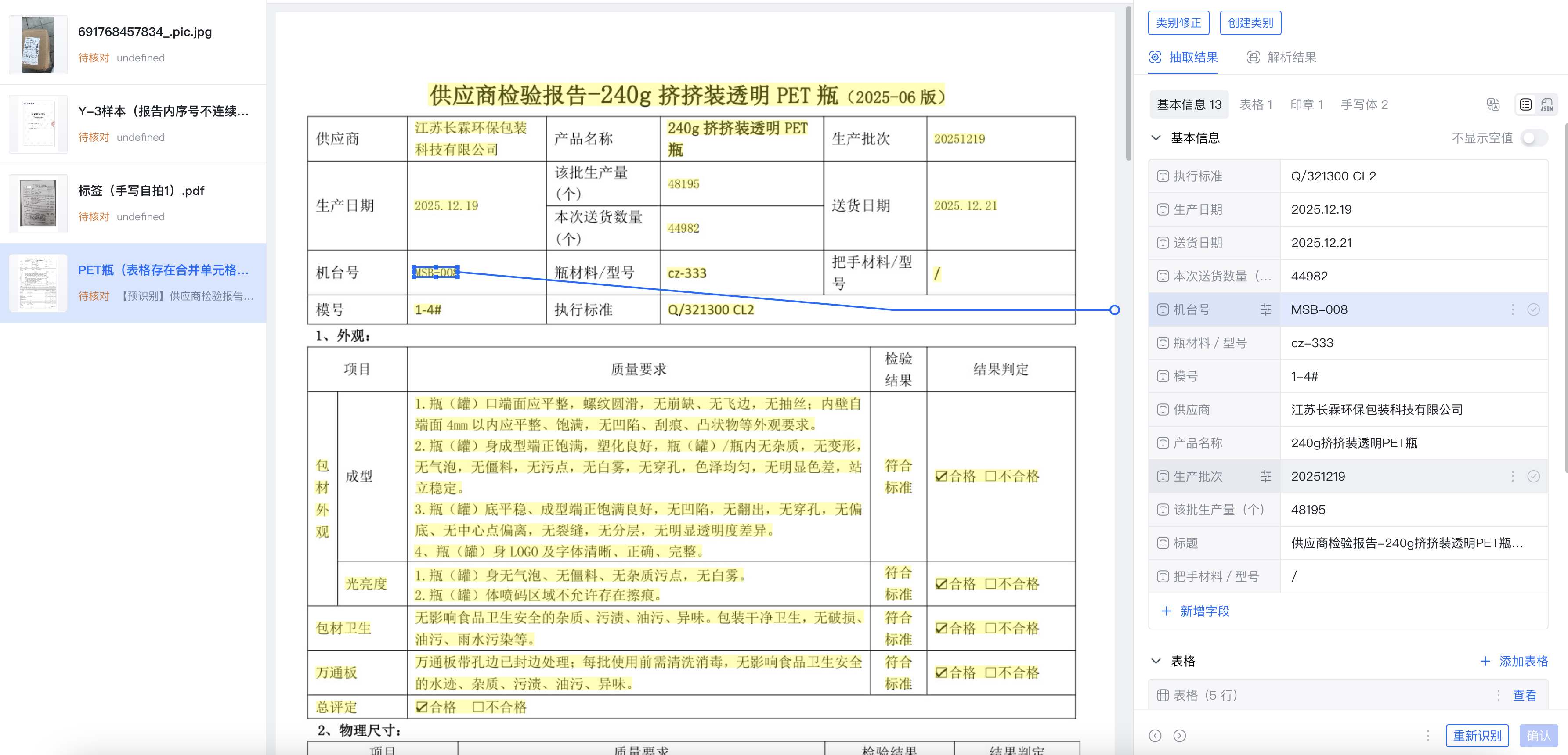
1.3 复杂表格与多格式适配能力
针对跨页表格、变形文档等核心痛点,采用多重技术组合方案:
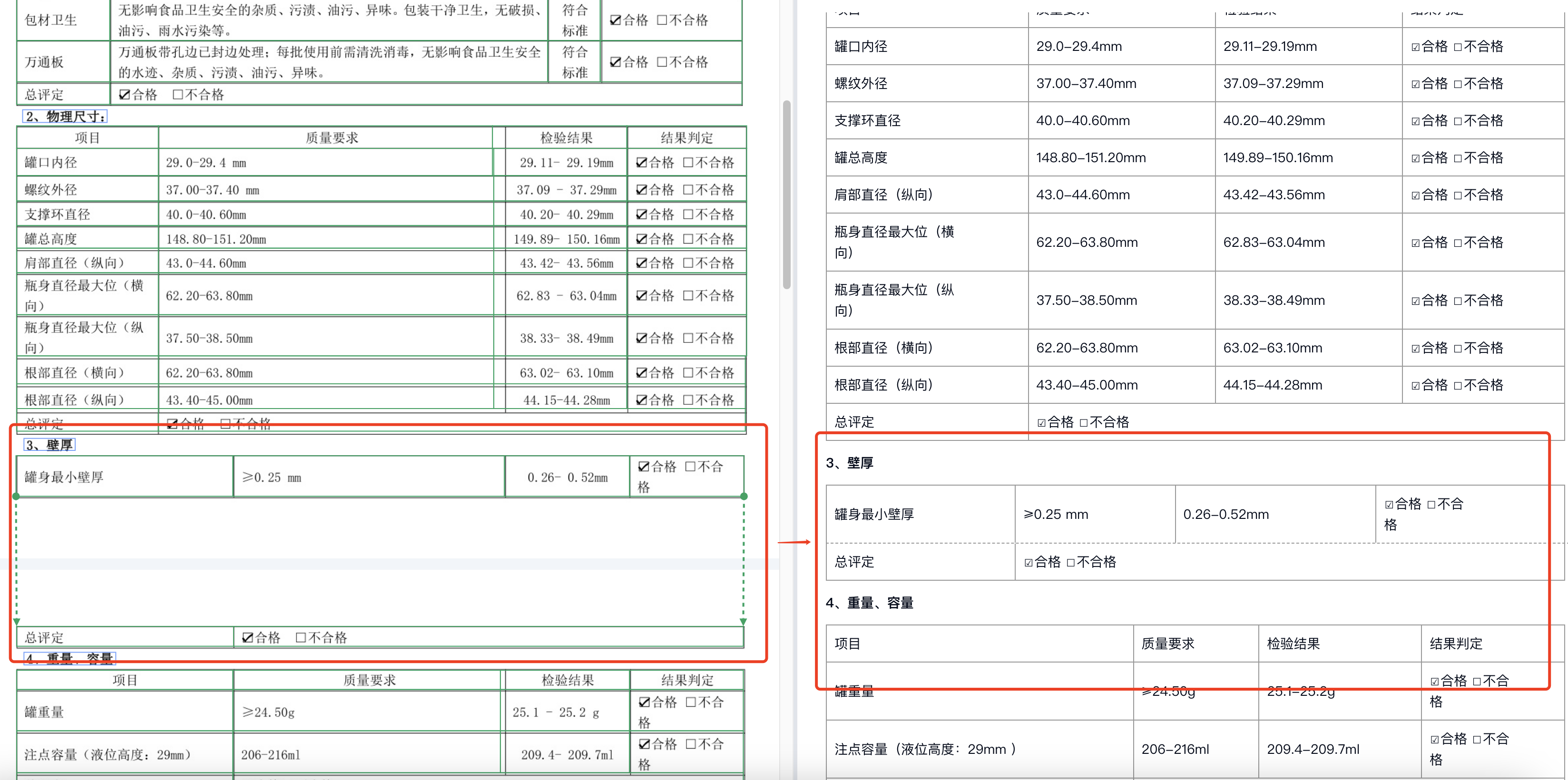
-
跨页表格智能合并:自动检测PDF跨页表格断点,结合单元格边框特征、数字序列连续性、文本语义及表头重复标识,精准判断行列延伸逻辑,实现跨页表格无错位合并。
-
结构化还原与误差校准:严格保留表头层级、单元格合并规则与数据格式,配合图像矫正算法,修正分页扫描偏移、文档变形等问题,确保行列对齐与数据精准。
-
全格式兼容 :同时支持扫描版PDF(OCR字符提取)与原生PDF(结构化数据直接读取),适配不同排版、不同来源的文档需求。
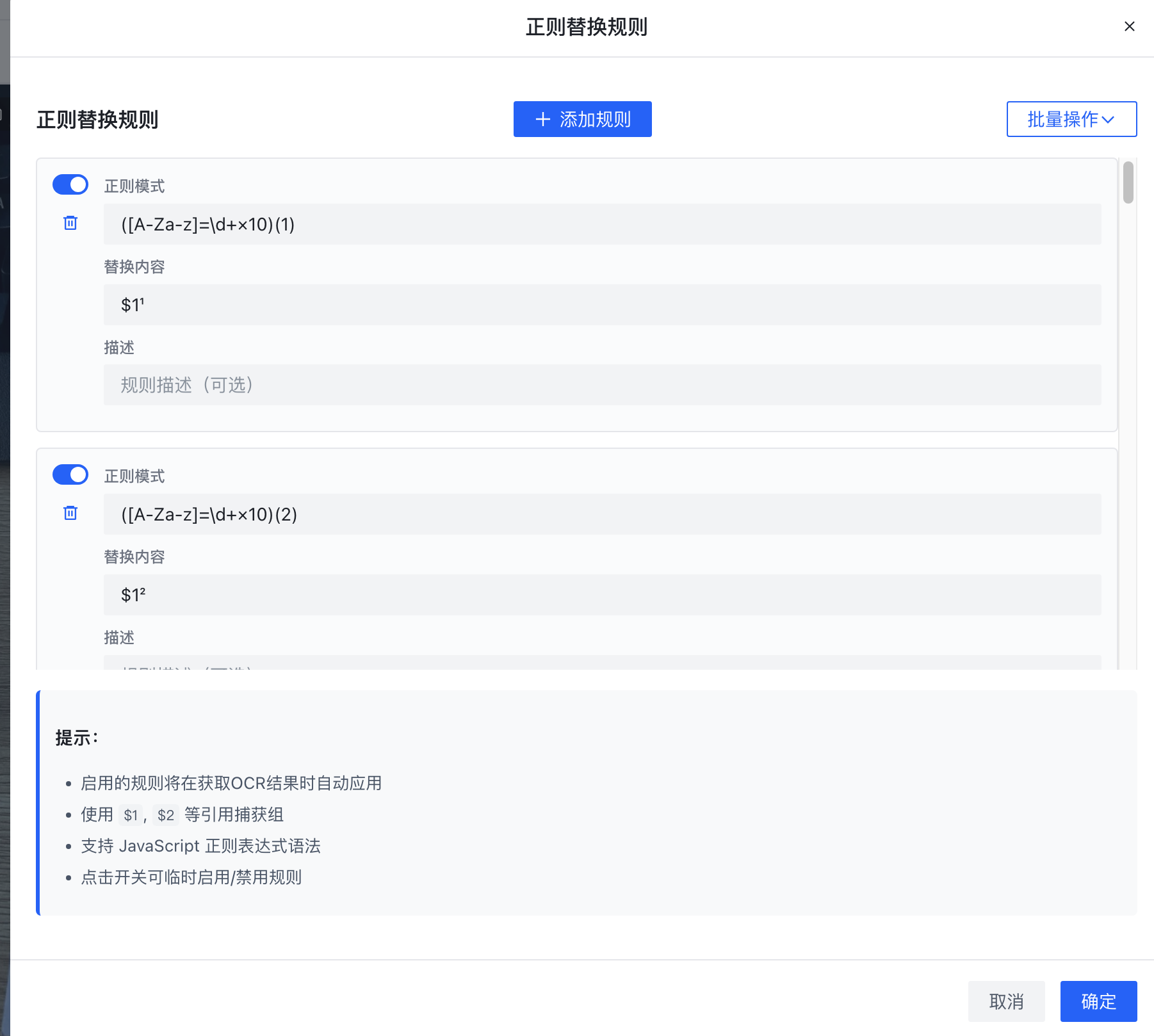
二、灵活规则配置:适配多行业专业场景需求
通用OCR的核心短板的是无法适配行业专属格式,旗讯OCR通过可自定义规则配置,实现从"识别字符"到"规范内容"的升级,覆盖多领域专业需求。
// 单位标准化映射规则示例(用户可自定义扩展) { "unstandard_unit": ["cm2", "molL-1", "m3/h"], "standard_unit": ["cm²", "mol·L⁻¹", "m³/h"], "industry": ["化工", "机械", "环保"] } // 公式下标补全规则示例 { "formula_rule": [ {"source": "H2O", "target": "H₂O", "industry": "水质检测"}, {"source": "σmax", "target": "σₘₐₓ", "industry": "力学检测"} ] }
具体规则配置能力包括三方面:
-
单位关联规则:用户预设行业角标单位映射表,系统自动将不规范表述转化为标准格式,覆盖化学、物理、材料等多领域核心单位。
-
公式语义规则:基于行业属性智能补全下标、符号格式,确保专业公式的语义准确性,避免因格式错误导致的数据误用。
-
生僻字配置规则 :支持自定义生僻字修正方案,精准修正专业文档中特殊字符的识别错误,解决行业专属术语识别难题。
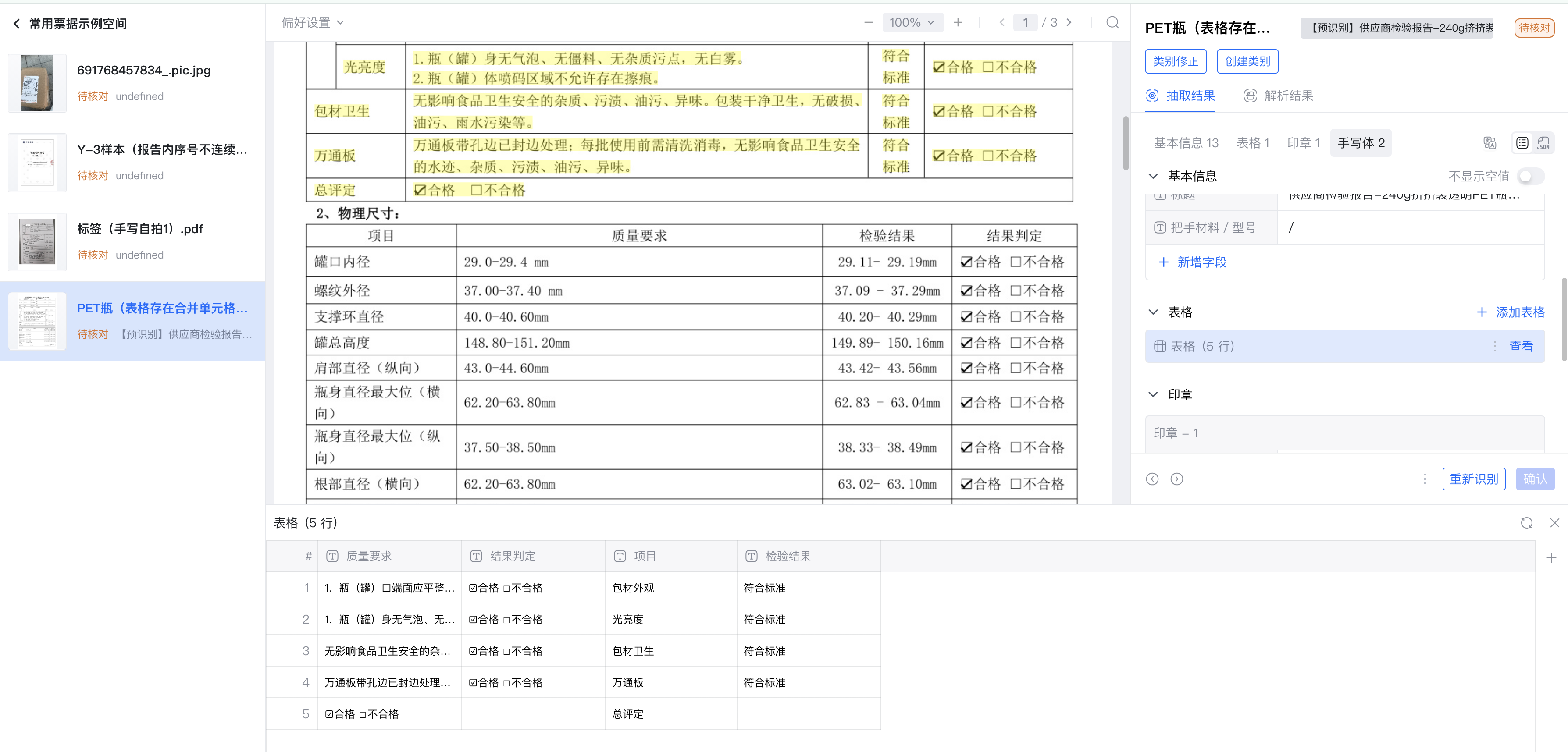
三、深度文档解析:构建结构化数据基础
旗讯OCR不止于"文字识别",更聚焦"结构解析",将非结构化文档转化为可编辑、可分析的结构化数据,为后续业务处理提供支撑。
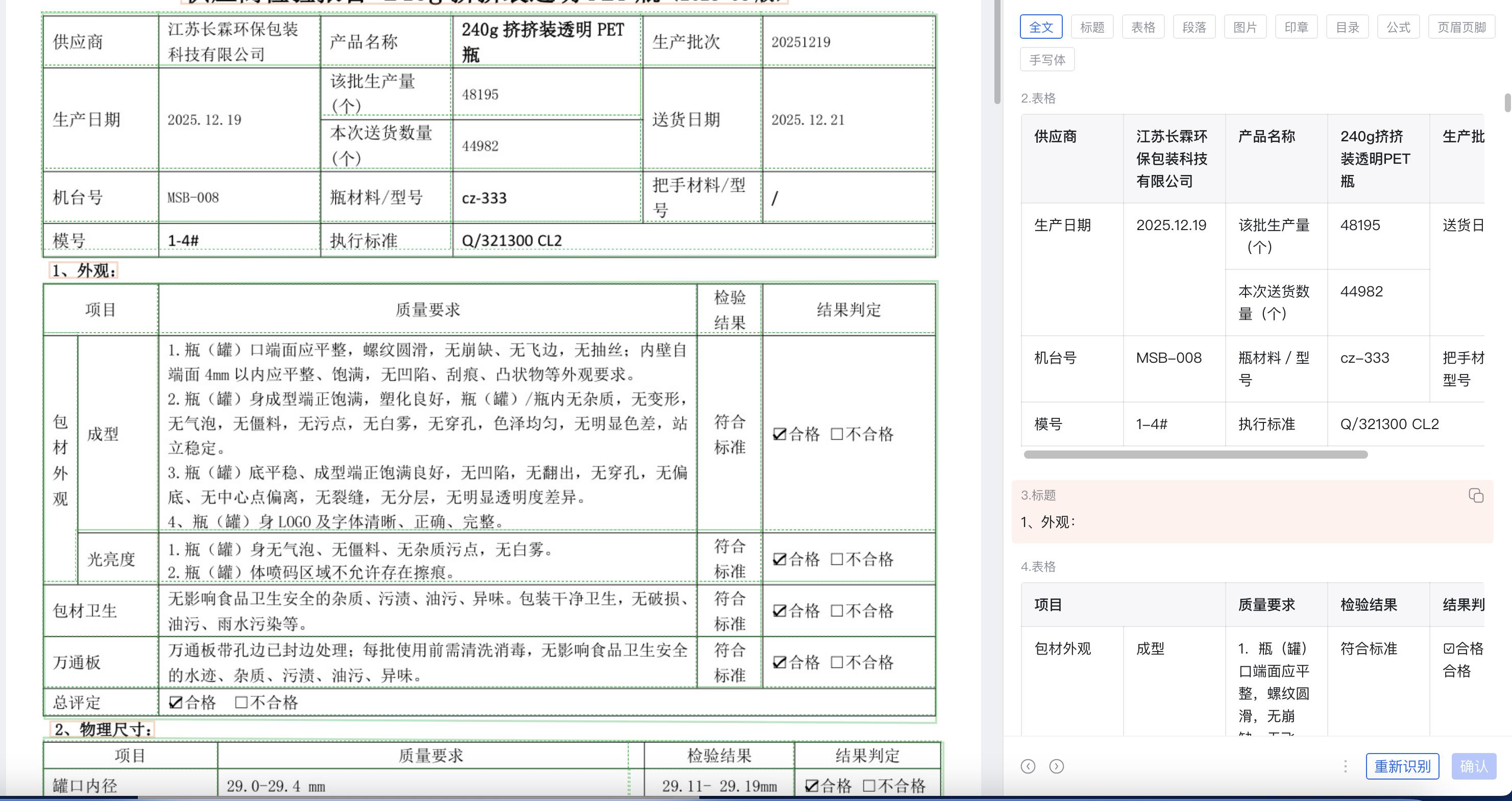
3.1 结构化解析技术
通过底层算法拆解文档结构,将PDF、图片等格式转化为包含文本段落、表格内容、公式表达式、页眉页脚、手写字符的结构化数据,打破非结构化文档的数据孤岛。
3.2 精细化元素提取
具备极高的元素识别精度,可无遗漏提取文档核心内容,不仅实现文档的数字化存储,更能为后续数据抽取、智能分析提供高质量基础数据,推动文档处理从"数字化"向"智能化"跨越。
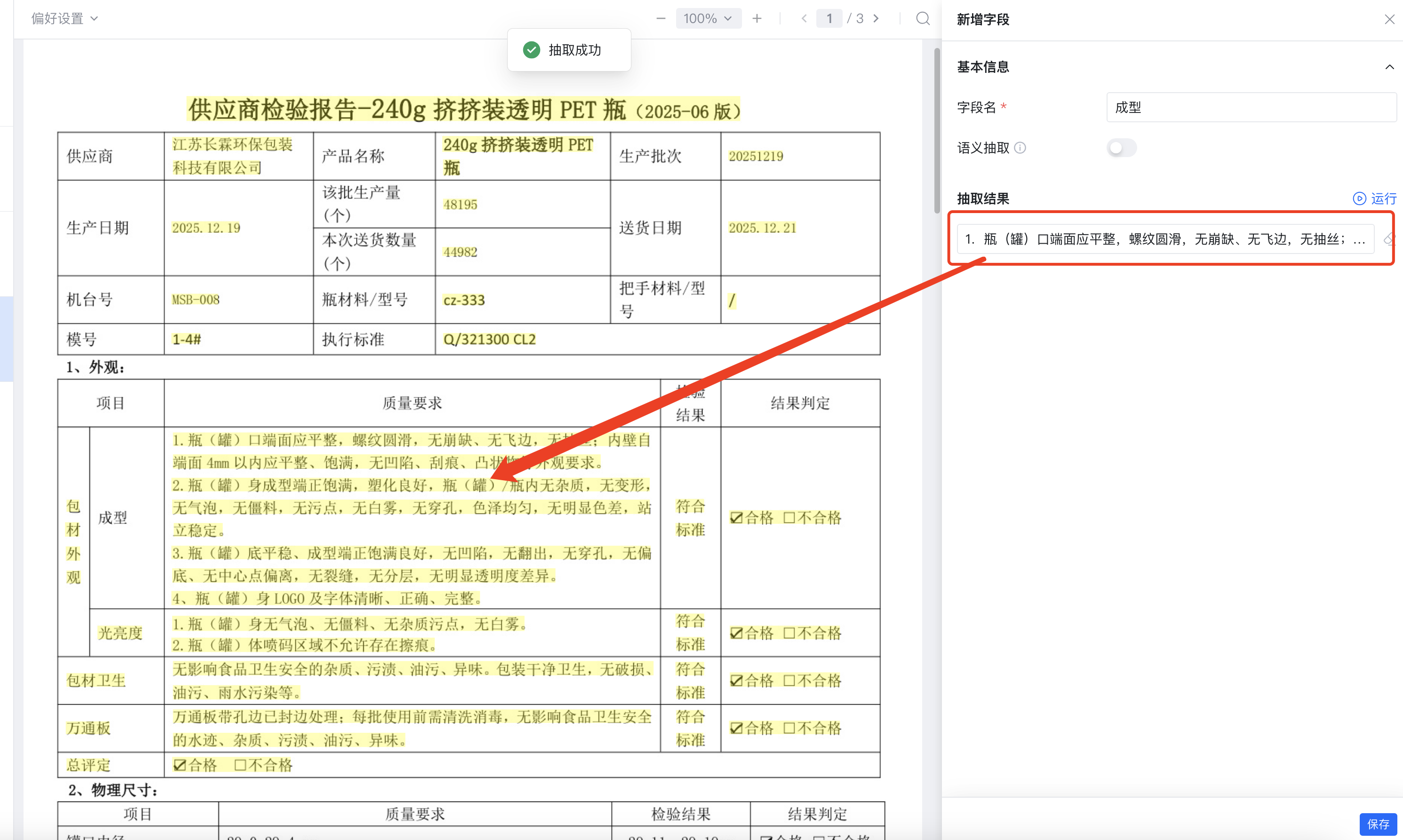
四、智能数据提取:个性化适配业务场景
基于解析后的结构化数据,提供灵活的提取能力,支持用户根据业务需求定制字段规则,实现核心数据的自动化捕获。
4.1 双重提取模式
-
结构化抽取:依据预设字段信息,自动从分类后文档中抽取基本信息、表格数据等结构化内容,无需人工干预。
-
特征提取:自动提取文档关键字、特征文本,辅助字段抽取与后续人工审核,提升提取准确性。
4.2 个性化字段配置
兼顾通用性与个性化需求:
-
预设各类文档核心基础字段(如检验报告的外观、物理尺寸、壁厚等),满足行业通用场景。
-
支持字段批量增删改,可灵活配置识别抽取 、语义抽取两种提取方式,适配不同企业的个性化业务需求。
-
内置异常提示配置 ,用户可设置字段缺失、格式错误等异常场景的提醒规则,实现异常数据自动预警,提升复核效率。
五、无缝数据对接:打通业务全流程闭环
企业级OCR工具的核心价值在于"数据可用",旗讯OCR通过标准化数据处理与业务系统联动,实现从识别到应用的全流程自动化。
5.1 标准化数据输出
将识别抽取的结构化数据进行JSON格式化处理 ,生成关联清晰的标准化数据,可直接对接ERP、MES、LIMS等各类业务系统,无需人工二次录入,避免数据流转中的误差。
5.2 数据质量管控机制
建立数据错误提醒机制,与业务系统深度联动后,自动对标业务标准校验数据,发现不符合规范的数据时即时发出异常提示,精准定位问题数据,从源头避免不合格数据流入业务流程,保障业务决策准确性。
六、核心优势与行业价值
相较于通用OCR产品,旗讯OCR的核心竞争力体现在**"场景定制化"** 与**"全链路能力"**:从行业专属的角标处理、公式修正规则,到业务系统无缝对接方案,均围绕行业文档特性优化,真正实现"识别精准、格式规范、数据可用"。
在制造业、化工、医疗、金融等领域,可大幅提升报告处理效率(预计降低60%以上人工成本)、降低误差率(精度可达99%+),推动企业数据资产化升级。未来结合AI大模型与行业知识库,还将实现检测数据的智能分析与预警,从数据处理工具升级为企业质量管控与决策的核心支撑。
📌 总结与延伸
旗讯OCR通过"精准识别-灵活配置-深度解析-智能提取-系统对接"的全链路设计,完美解决了行业文档数字化过程中的核心痛点。对于企业而言,选择此类工具不仅是提升效率,更是为数字化转型构建坚实的数据基础。
后续可进一步探索其与AI大模型的融合场景,实现文档数据的自动分析、异常预警与智能决策,赋能更多复杂业务场景。
🔖 标签:#OCR技术 #文档数字化 #企业级解决方案 #数据结构化 #旗讯OCR