注:本文为 "Expression Problem" 相关合辑。
英文引文,机翻未校。
如有内容异常,请看原文。
The Expression Problem and its solutions
表达式问题及其解决方案
Eli Bendersky May 12, 2016 at 05:44
The craft of programming is almost universally concerned with different types of data and operations/algorithms that act on this data 1. Therefore, it's hardly surprising that designing abstractions for data types and operations has been on the mind of software engineers and programming-language designers since... forever.
编程这门技艺几乎普遍围绕各类数据,以及作用于这些数据的操作或算法展开 1。因此,为数据类型与操作设计抽象概念,自始至终都是软件工程师与编程语言设计者关注的课题,这一点不足为奇。
Yet I've only recently encountered a name for a software design problem which I ran into multiple times in my career. It's a problem so fundamental that I was quite surprised that I haven't seen it named before. Here is a quick problem statement.
然而,我在职业生涯中多次遇到一类软件设计问题,却直到最近才得知它的正式名称。这类问题具备基础性特征,此前我竟从未见过它被命名,这让我颇感意外。下文是对该问题的简要陈述。
Imagine that we have a set of data types and a set of operations that act on these types. Sometimes we need to add more operations and make sure they work properly on all types; sometimes we need to add more types and make sure all operations work properly on them. Sometimes, however, we need to add both - and herein lies the problem. Most of the mainstream programming languages don't provide good tools to add both new types and new operations to an existing system without having to change existing code. This is called the "expression problem". Studying the problem and its possible solutions gives great insight into the fundamental differences between object-oriented and functional programming and well as concepts like interfaces and multiple dispatch.
假设我们拥有一组数据类型,以及一组作用于这些类型的操作。某些场景下,我们需要新增操作,并确保这些操作可在所有类型上正常执行;某些场景下,我们需要新增类型,并确保所有已有操作可在这些新类型上正常执行。但在部分场景中,我们需要同时完成上述两类新增操作------这正是问题的核心所在。多数主流编程语言未能提供完善工具,支持在不修改现有代码的前提下,向已有系统同时新增数据类型与操作。这类问题被定义为表达式问题。对该问题及其潜在解决方案的研究,能够清晰揭示面向对象编程与函数式编程之间的本质差异,同时也可深入理解接口与多重派发等概念。
A motivating example
引例
As is my wont, my example comes from the world of compilers and interpreters. To my defense, this is also the example used in some of the seminal historic sources on the expression problem, as the historical perspective section below details.
按照我一贯的示例选取逻辑,本节示例来源于编译器与解释器领域。需要说明的是,正如下文"历史背景"部分所详述的,部分关于表达式问题的经典历史文献也采用了这一示例。
Imagine we're designing a simple expression evaluator. Following the standard interpreter design pattern, we have a tree structure consisting of expressions, with some operations we can do on such trees. In C++ we'd have an interface every node in the expression tree would have to implement:
假设我们需要设计一个简易的表达式求值器。遵循标准的解释器设计模式,我们构建由表达式构成的树形结构,同时定义若干可作用于该树形结构的操作。在 C++ 语言中,我们需要定义一个接口,表达式树中的每个节点均需实现该接口:
class Expr {
public:
virtual std::string ToString() const = 0;
virtual double Eval() const = 0;
};This interface shows that we currently have two operations we can do on expression trees - evaluate them and query for their string representations. A typical leaf node expression:
该接口表明,当前我们可对表达式树执行两项操作:求值,以及获取其字符串表示形式。以下是一个典型的叶子节点表达式:
class Constant : public Expr {
public:
Constant(double value) : value_(value) {}
std::string ToString() const {
std::ostringstream ss;
ss << value_;
return ss.str();
}
double Eval() const {
return value_;
}
private:
double value_;
};And a typical composite expression:
以下是一个典型的组合表达式:
class BinaryPlus : public Expr {
public:
BinaryPlus(const Expr& lhs, const Expr& rhs) : lhs_(lhs), rhs_(rhs) {}
std::string ToString() const {
return lhs_.ToString() + " + " + rhs_.ToString();
}
double Eval() const {
return lhs_.Eval() + rhs_.Eval();
}
private:
const Expr& lhs_;
const Expr& rhs_;
};Until now, it's all fairly basic stuff. How extensible is this design? Let's see... if we want to add new expression types ("variable reference", "function call" etc.), that's pretty easy. We just define additional classes inheriting from Expr and implement the Expr interface (ToString and Eval).
截至目前,上述均为基础实现。那么该设计的可扩展性如何?我们不妨分析一下:若需新增表达式类型(如"变量引用""函数调用"等),操作会十分简便。我们只需定义额外的类,使其继承 Expr 并实现该接口中的 ToString 与 Eval 方法即可。
However, what happens if we want to add new operations that can be applied to expression trees? Right now we have Eval and ToString, but we may want additional operations like "type check" or "serialize" or "compile to machine code" or whatever.
但当我们需要新增可作用于表达式树的操作 时,情况会如何?当前我们仅实现了 Eval 与 ToString 操作,但实际应用中可能还需要类型检查、序列化、编译为机器码等其他操作。
It turns out that adding new operations isn't as easy as adding new types. We'd have to change the Expr interface, and consequently change every existing expression type to support the new method(s). If we don't control the original code or it's hard to change it for other reasons, we're in trouble.
事实证明,新增操作远不如新增类型简便。我们必须修改 Expr 接口,进而修改所有已有表达式类型的定义,使其支持新增的方法。若我们无法控制原始代码,或因其他原因难以完成修改,系统扩展便会陷入困境。
In other words, we'd have to violate the venerable open-closed principle , one of the main principles of object-oriented design, defined as:
换言之,这一操作违背了久负盛名的开闭原则------该原则是面向对象设计的核心原则之一,其定义如下:
software entities (classes, modules, functions, etc.) should be open for extension, but closed for modification
软件实体(类、模块、函数等)应面向扩展开放,面向修改关闭
The problem we're hitting here is called the expression problem , and the example above shows how it applies to object-oriented programming.
我们在此处遇到的问题即为表达式问题,上述示例展现了该问题在面向对象编程中的具体表现。
Interestingly, the expression problem bites functional programming languages as well. Let's see how.
值得注意的是,函数式编程语言同样无法规避表达式问题,只是其表现形式有所不同。下文将具体分析。
The expression problem in functional programming
函数式编程中的表达式问题
Update 2018-02-05: a new post discusses the problem and its solutions in Haskell in more depth.
更新于 2018-02-05: 一篇新博文深入探讨了该问题在 Haskell 语言中的表现形式及解决方案。
Object-oriented approaches tend to collect functionality in objects (types). Functional languages cut the cake from a different angle, usually preferring types as thin data containers, collecting most functionality in functions (operations) that act upon them. Functional languages don't escape the expression problem - it just manifests there in a different way.
面向对象方法倾向于将功能封装于对象(即类型)内部。而函数式语言则采用不同的设计思路:通常将类型作为轻量级数据容器,将大部分功能封装于作用于这些类型的函数(即操作)中。函数式语言同样无法规避表达式问题,只是其表现形式有所不同。
To demonstrate this, let's see how the expression evaluator / stringifier looks in Haskell. Haskell is a good poster child for functional programming since its pattern matching on types makes such code especially succinct:
为具体说明这一点,我们不妨看看表达式求值器与字符串化工具在 Haskell 语言中的实现方式。Haskell 是函数式编程的典型代表,其类型模式匹配特性可大幅简化此类代码的编写:
module Expressions where
data Expr = Constant Double
| BinaryPlus Expr Expr
stringify :: Expr -> String
stringify (Constant c) = show c
stringify (BinaryPlus lhs rhs) = stringify lhs
++ " + "
++ stringify rhs
evaluate :: Expr -> Double
evaluate (Constant c) = c
evaluate (BinaryPlus lhs rhs) = evaluate lhs + evaluate rhsNow let's say we want to add a new operation - type checking. We simply have to add a new function typecheck and define how it behaves for all known kinds of expressions. No need to modify existing code.
假设我们需要新增一项操作------类型检查。我们只需添加一个新的 typecheck 函数,并定义其作用于所有已知表达式类型的逻辑即可,无需修改任何现有代码。
On the other hand, if we want to add a new type (like "function call"), we get into trouble. We now have to modify all existing functions to handle this new type. So we hit exactly the same problem, albeit from a different angle.
但当我们需要新增类型(如"函数调用")时,问题便会显现:我们必须修改所有已有函数,使其适配该新类型。由此可见,函数式编程中同样存在表达式问题,只是问题的表现角度与面向对象编程相反。
The expression problem matrix
表达式问题矩阵
A visual representation of the expression problem can be helpful to appreciate how it applies to OOP and FP in different ways, and how a potential solution would look.
通过可视化方式呈现表达式问题,有助于清晰理解该问题在面向对象编程与函数式编程中的不同表现形式,同时也能明确潜在解决方案的设计思路。
The following 2-D table (a "matrix") has types in its rows and operations in its columns. A matrix cell row, col is checked when the operation col is implemented for type row:
下述二维表格(即矩阵)的行代表类型,列代表操作。当某一行对应的类型实现了某一列对应的操作时,矩阵中该单元格(row, col)将被标记:
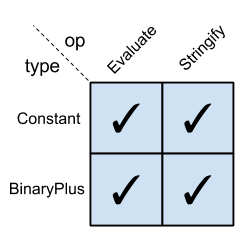
Basic expression problem matrix demonstarting the starting point
展示初始状态的基础表达式问题矩阵
In object-oriented languages, it's easy to add new types but difficult to add new operations:
在面向对象编程语言中,新增类型的操作简便,但新增操作的难度较高:
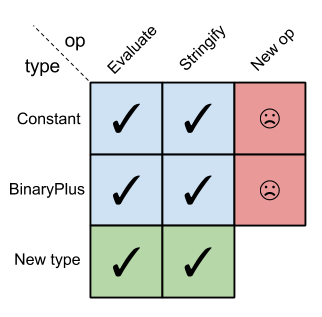
OOP expression problem matrix
面向对象编程的表达式问题矩
Whereas in functional languages, it's easy to add new operations but difficult to add new types:
而在函数式编程语言中,新增操作的操作简便,但新增类型的难度较高:
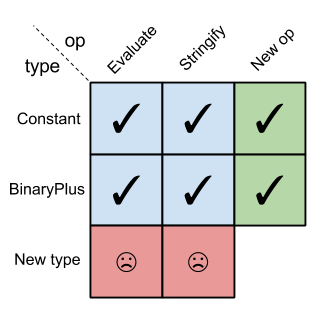
FP expression problem matrix
函数式编程的表达式问题矩阵
A historical perspective
历史背景
The expression problem isn't new, and has likely been with us since the early days; it pops its head as soon as programs reach some not-too-high level of complexity.
表达式问题并非新兴问题,它大概率自编程领域发展初期便已存在;只要程序的复杂度达到一定阈值,该问题便会显现。
It's fairly certain that the name expression problem comes from an email sent by Philip Wadler to a mailing list deailing with adding generics to Java (this was back in the 1990s).
可以确定的是,表达式问题这一名称来源于 Philip Wadler 在 20 世纪 90 年代发送至一个关于 Java 泛型扩展的邮件列表的一封邮件。
In that email, Wadler points to the paper "Synthesizing Object-Oriented and Functional Design to Promote Re-Use" by Krishnamurthi, Felleisen and Friedman as an earlier work describing the problem and proposed solutions. This is a great paper and I highly recommend reading it. Krishnamurthi et.al., in their references, point to papers from as early as 1975 describing variations of the problem in Algol.
在该邮件中,Wadler 提及 Krishnamurthi、Felleisen 与 Friedman 合著的论文《融合面向对象与函数式设计以促进复用》,称其是较早描述该问题并提出解决方案的文献。这是一篇极具参考价值的论文,我强烈建议读者深入研读。Krishnamurthi 等人在参考文献中,甚至追溯至 1975 年的论文,这些文献描述了该问题在 Algol 语言中的同类表现形式。
Flipping the matrix with the visitor pattern
基于访问者模式的矩阵反转
So far the article has focused on the expression problem , and I hope it's clear by now. However, the title also has the word solution in it, so let's turn to that.
截至目前,本文的讨论聚焦于表达式问题 本身,希望相关内容已被读者充分理解。不过,本文标题中还包含解决方案这一关键词,接下来我们将就此展开论述。
It's possible to kinda solve (read on to understand why I say "kinda") the expression problem in object-oriented languages; first, we have to look at how we can flip the problem on its side using the visitor pattern. The visitor pattern is very common for this kind of problems, and for a good reason. It lets us reformulate our code in a way that makes it easier to change in some dimensions (though harder in others).
在面向对象语言中,我们可以"在一定程度上"解决表达式问题(继续阅读即可理解我使用"在一定程度上"这一表述的原因)。首先,我们需要了解如何利用访问者模式反转问题的约束方向。访问者模式在解决此类问题时应用广泛,这是有充分理由的:它能够重构代码,使其在特定维度具备更优的可修改性(尽管这会提升另一维度的修改难度)。
For the C++ sample shown above, rewriting it using the visitor pattern means adding a new "visitor" interface:
针对上文展示的 C++ 示例,若要基于访问者模式进行重写,我们需要新增一个"访问者"接口:
class ExprVisitor {
public:
virtual void VisitConstant(const Constant& c) = 0;
virtual void VisitBinaryPlus(const BinaryPlus& bp) = 0;
};And changing the Expr interface to be:
同时,我们需要将 Expr 接口修改为如下形式:
class Expr {
public:
virtual void Accept(ExprVisitor* visitor) const = 0;
};Now expression types defer the actual computation to the visitor, as follows:
此时,表达式类型会将具体的计算逻辑委托给访问者实现,示例如下:
class Constant : public Expr {
public:
Constant(double value) : value_(value) {}
void Accept(ExprVisitor* visitor) const {
visitor->VisitConstant(*this);
}
double GetValue() const {
return value_;
}
private:
double value_;
};
// ... similarly, BinaryPlus would have
//
// void Accept(ExprVisitor* visitor) const {
// visitor->VisitBinaryPlus(*this);
// }
//
// ... etc.A sample visitor for evaluation would be 2:
以下是一个用于求值的访问者示例 2
class Evaluator : public ExprVisitor {
public:
double GetValueForExpr(const Expr& e) {
return value_map_[&e];
}
void VisitConstant(const Constant& c) {
value_map_[&c] = c.GetValue();
}
void VisitBinaryPlus(const BinaryPlus& bp) {
bp.GetLhs().Accept(this);
bp.GetRhs().Accept(this);
value_map_[&bp] = value_map_[&(bp.GetLhs())] + value_map_[&(bp.GetRhs())];
}
private:
std::map<const Expr*, double> value_map_;
};It should be obvious that for a given set of data types, adding new visitors is easy and doesn't require modifying any other code. On the other hand, adding new types is problematic since it means we have to update the ExprVisitor interface with a new abstract method, and consequently update all the visitors to implement it.
显然,针对一组既定的数据类型,新增访问者(即新增操作)的过程十分简便,且无需修改其他任何代码。但新增类型的操作则较为繁琐:我们需要更新 ExprVisitor 接口,添加对应的抽象方法,并修改所有访问者以实现该方法。
So it seems that we've just turned the expression problem on its side: we're using an OOP language, but now it's hard to add types and easy to add ops, just like in the functional approach. I find it extremely interesting that we can do this. In my eyes this highlights the power of different abstractions and paradigms, and how they enable us to rethink a problem in a completely different light.
由此可见,我们实际上只是反转了表达式问题的约束方向:虽然使用的是面向对象编程语言,但现在新增类型的难度变高,新增操作的难度变低,这与函数式编程的特性趋于一致。这种转换方式极具研究价值,在我看来,它体现了不同抽象范式的强大能力,以及这些范式如何帮助我们从全新视角重新审视问题。
So we haven't solved anything yet; we've just changed the nature of the problem we're facing. Worry not - this is just a stepping stone to an actual solution.
需要明确的是,我们并未从根本上解决问题,只是改变了所面临问题的表现形式。不过无需担心------这是实现最终解决方案的重要铺垫。
Extending the visitor pattern
访问者模式的扩展
The following is code excerpts from a C++ solution that follows the extended visitor pattern proposed by Krishnamurthi et. al. in their paper; I strongly suggest reading the paper (particularly section 3) if you want to understand this code on a deep level. A complete code sample in C++ that compiles and runs is available here.
以下代码片段摘自一个 C++ 解决方案,该方案遵循 Krishnamurthi 等人在其论文中提出的扩展访问者模式。若需深入理解该代码的设计逻辑,我强烈建议读者研读该论文(尤其是第三节内容)。完整的可编译运行的 C++ 代码示例可参考此处。
Adding new visitors (ops) with the visitor pattern is easy. Our challenge is to add a new type without upheaving too much existing code. Let's see how it's done.
基于访问者模式,新增访问者(即新增操作)的过程十分简便。我们当前的挑战在于,如何在最小化修改现有代码的前提下新增类型。下文将具体说明实现思路。
One small design change that we should make to the original visitor pattern is use virtual inheritance for Evaluator, for reasons that will soon become obvious:
我们需要对原始访问者模式做出一处细微的设计调整:为 Evaluator 类采用虚继承,原因将在下文说明:
class Evaluator : virtual public ExprVisitor {
// .. the rest is the same
};Now we're going to add a new type - FunctionCall:
接下来,我们将新增一个类型------FunctionCall:
// This is the new ("extended") expression we're adding.
class FunctionCall : public Expr {
public:
FunctionCall(const std::string& name, const Expr& argument)
: name_(name), argument_(argument) {}
void Accept(ExprVisitor* visitor) const {
ExprVisitorWithFunctionCall* v =
dynamic_cast<ExprVisitorWithFunctionCall*>(visitor);
if (v == nullptr) {
std::cerr << "Fatal: visitor is not ExprVisitorWithFunctionCall\n";
exit(1);
}
v->VisitFunctionCall(*this);
}
private:
std::string name_;
const Expr& argument_;
};Since we don't want to modify the existing visitors, we create a new one, extending Evaluator for function calls. But first, we need to extend the ExprVisitor interface to support the new type:
由于我们不希望修改已有访问者,因此需要创建一个新的访问者类,通过扩展 Evaluator 以支持函数调用类型。在此之前,我们需要扩展 ExprVisitor 接口以适配该新类型:
class ExprVisitorWithFunctionCall : virtual public ExprVisitor {
public:
virtual void VisitFunctionCall(const FunctionCall& fc) = 0;
};Finally, we write the new evaluator, which extends Evaluator and supports the new type:
最后,我们编写新的求值器类,该类继承 Evaluator 并支持上述新类型:
class EvaluatorWithFunctionCall : public ExprVisitorWithFunctionCall,
public Evaluator {
public:
void VisitFunctionCall(const FunctionCall& fc) {
std::cout << "Visiting FunctionCall!!\n";
}
};Multiple inheritance, virtual inheritance, dynamic type checking... that's pretty hard-core C++ we have to use here, but there's no choice. Unfortunately, multiple inheritance is the only way C++ lets us express the idea that a class implements some interface while at the same time deriving functionality from another class. What we want to have here is an evaluator (EvaluatorWithFunctionCall) that inherits all functionality from Evaluator, and also implements the ExprVisitorWithFunctionCall interface. In Java, we could say something like:
多重继承、虚继承、动态类型检查......我们在此处使用的是 C++ 语言的高阶特性,但这是别无选择的做法。遗憾的是,多重继承是 C++ 中唯一能够实现"类既实现某接口,又从另一类继承功能"这一需求的方式。我们此处需要的是一个求值器(EvaluatorWithFunctionCall),它既要继承 Evaluator 的全部功能,又要实现 ExprVisitorWithFunctionCall 接口。在 Java 语言中,我们可以通过如下方式实现这一需求:
class EvaluatorWithFunctionCall extends Evaluator implements ExprVisitor {
// ...
}But in C++ virtual multiple inheritance is the tool we have. The virtual part of the inheritance is essential here for the compiler to figure out that the ExprVisitor base underlying both Evaluator and ExprVisitorWithFunctionCall is the same and should only appear once in EvaluatorWithFunctionCall. Without virtual, the compiler would complain that EvaluatorWithFunctionCall doesn't implement the ExprVisitor interface.
但在 C++ 中,我们只能借助虚多重继承这一工具。其中,虚继承的特性至关重要------它能确保编译器将 Evaluator 与 ExprVisitorWithFunctionCall 共同继承的 ExprVisitor 基类视为同一个实例,且在 EvaluatorWithFunctionCall 中仅存在一份。若未使用虚继承,编译器会报错,提示 EvaluatorWithFunctionCall 未实现 ExprVisitor 接口。
This is a solution, alright. We kinda added a new type FunctionCall and can now visit it without changing existing code (assuming the virtual inheritance was built into the design from the start to anticipate this approach). Here I am using this "kinda" word again... it's time to explain why.
这确实是一种解决方案。我们在一定程度上实现了 FunctionCall 类型的新增,并且能够在不修改现有代码的前提下访问该类型(前提是设计之初便已引入虚继承,以预留该扩展方式)。此处我再次使用了"在一定程度上"这一表述......是时候解释其原因了。
This approach has multiple flaws, in my opinion:
在我看来,该方案存在诸多缺陷:
-
Note the
dynamic_castinFunctionCall::Accept. It's fairly ugly that we're forced to mix in dynamic checks into this code, which should supposedly rely on static typing and the compiler. But it's just a sign of a larger problem.注意
FunctionCall::Accept方法中的dynamic_cast操作。这段本应依赖静态类型与编译器校验的代码,却不得不引入动态检查,这无疑破坏了代码的简洁性。而这仅仅是更深层次设计问题的一个表象。 -
If we have an instance of an
Evaluator, it will no longer work on the whole extended expression tree since it has no understanding ofFunctionCall. It's easy to say that all new evaluators should rather beEvaluatorWithFunctionCall, but we don't always control this. What about code that was already written? What aboutEvaluators created in third-party or library code which we have no control of?若我们拥有一个
Evaluator类的实例,该实例将无法作用于扩展后的完整表达式树,因为它无法识别FunctionCall类型。尽管我们可以要求所有新的求值器都采用EvaluatorWithFunctionCall类型,但实际开发中我们无法完全控制这一约束。那么,对于已编写完成的代码该如何处理?对于第三方库中创建的、我们无法控制的Evaluator实例又该如何处理? -
The virtual inheritance is not the only provision we have to build into the design to support this pattern. Some visitors would need to create new, recursive visitors to process complex expressions. But we can't anticipate in advance which dynamic type of visitor needs to be created. Therefore, the visitor interface should also accept a "visitor factory" which extended visitors will supply. I know this sounds complicated, and I don't want to spend more time on this here - but the Krishnamurthi paper addresses this issue extensively in section 3.4
虚继承并非支持该模式的唯一前置设计。部分访问者可能需要创建递归访问者来处理复杂表达式,但我们无法提前预知需要创建的访问者的动态类型。因此,访问者接口还需集成"访问者工厂",由扩展后的访问者提供该工厂的实现。我知道这一逻辑听起来十分复杂,此处不再展开论述------但 Krishnamurthi 的论文在 3.4 节中对该问题进行了详细探讨。
-
Finally, the solution is unwieldy for realistic applications. Adding one new type looks manageable; what about adding 15 new types, gradually over time? Imagine the horrible zoo of
ExprVisitorextensions and dynamic checks this would lead to.最后,该方案在实际应用中的实用性较差。新增单个类型时,方案尚且具备可操作性;但如果随着时间推移需要新增 15 个乃至更多类型呢?不难想象,这会导致
ExprVisitor的扩展类与动态检查逻辑变得杂乱无章,形成一个难以维护的复杂体系。
Yeah, programming is hard. I could go on and on about the limitations of classical OOP and how they surface in this example 3. Instead, I'll just present how the expression problem can be solved in a language that supports multiple dispatch and separates the defintion of methods from the bodies of types they act upon.
没错,编程从来都不是一件容易的事。我可以就经典面向对象编程的局限性,以及这些局限性在本示例中的具体体现展开长篇大论 3。但在此处,我更想向读者展示:在支持多重派发,且方法定义与类型主体相分离的编程语言中,表达式问题该如何解决。
Solving the expression problem in Clojure
Clojure 中的表达式问题解决方案
There are a number of ways the expression problem as displayed in this article can be solved in Clojure using the language's built-in features. Let's start with the simplest one - multi-methods.
利用 Clojure 语言的内置特性,我们可以通过多种方式解决本文所讨论的表达式问题。首先,我们从最简单的方式------多方法开始介绍。
First we'll define the types as records:
首先,我们将类型定义为记录:
(defrecord Constant [value])
(defrecord BinaryPlus [lhs rhs])Then, we'll define evaluate as a multimethod that dispatches upon the type of its argument, and add method implementations for Constant and BinaryPlus:
随后,我们将 evaluate 定义为一个多方法,使其基于参数的类型进行派发,并为 Constant 与 BinaryPlus 类型实现对应的方法:
(defmulti evaluate class)
(defmethod evaluate Constant
[c] (:value c))
(defmethod evaluate BinaryPlus
[bp] (+ (evaluate (:lhs bp)) (evaluate (:rhs bp))))Now we can already evaluate expressions:
此时,我们已经可以执行表达式求值操作:
user=> (use 'expression.multimethod)
nil
user=> (evaluate (->BinaryPlus (->Constant 1.1) (->Constant 2.2)))
3.3000000000000003Adding a new operation is easy. Let's add stringify:
新增操作的过程十分简便。接下来,我们新增 stringify 操作:
(defmulti stringify class)
(defmethod stringify Constant
[c] (str (:value c)))
(defmethod stringify BinaryPlus
[bp]
(clojure.string/join " + " [(stringify (:lhs bp))
(stringify (:rhs bp))]))Testing it:
验证该操作:
user=> (stringify (->BinaryPlus (->Constant 1.1) (->Constant 2.2)))
"1.1 + 2.2"How about adding new types? Suppose we want to add FunctionCall. First, we'll define the new type. For simplicity, the func field of FunctionCall is just a Clojure function. In real code it could be some sort of function object in the language we're interpreting:
那么新增类型的操作又该如何实现?假设我们需要新增 FunctionCall 类型。首先,我们定义该新类型。为简化实现,FunctionCall 的 func 字段被设定为一个 Clojure 函数;在实际场景中,该字段可以是我们所解释的语言中的某种函数对象:
(defrecord FunctionCall [func argument])And define how evaluate and stringify work for FunctionCall:
随后,我们定义 evaluate 与 stringify 操作作用于 FunctionCall 类型的逻辑:
(defmethod evaluate FunctionCall
[fc] ((:func fc) (evaluate (:argument fc))))
(defmethod stringify FunctionCall
[fc] (str (clojure.repl/demunge (str (:func fc)))
"("
(stringify (:argument fc))
")"))Let's take it for a spin (the full code is here):
让我们运行验证一下(完整代码可参考此处):
user=> (def callexpr (->FunctionCall twice (->BinaryPlus (->Constant 1.1)
(->Constant 2.2))))
#'user/callexpr
user=> (evaluate callexpr)
6.6000000000000005
user=> (stringify callexpr)
"expression.multimethod/twice@52e29c38(1.1 + 2.2)"It should be evident that the expression problem matrix for Clojure is:
由此可见,Clojure 语言的表达式问题矩阵如下:
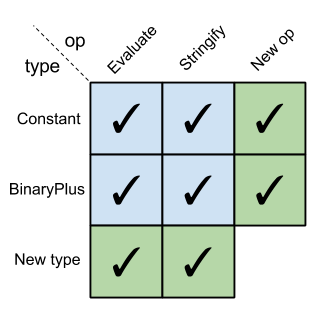
Expression problem matrix in Clojure
Clojure 语言的表达式问题矩阵
We can add new ops without touching any existing code. We can also add new types without touching any existing code. The code we're adding is only the new code to handle the ops/types in question. The existing ops and types could come from a third-party library to which we don't have source access. We could still extend them for our new ops and types, without ever having to touch (or even see) the original source code 4.
我们可以在不修改任何现有代码的前提下新增操作,也可以通过同样的方式新增类型。我们新增的代码,仅仅是用于处理目标操作或目标类型的逻辑。即便已有操作与类型来自我们无法获取源代码的第三方库,我们仍然可以对其进行扩展,以适配新的操作与类型,且无需修改(甚至无需查看)原始代码 4。
Is multiple dispatch necessary to cleanly solve the expression problem?
多重派发是否是优雅解决表达式问题的必要条件?
I've written about multiple dispatch in Clojure before, and in the previous section we see another example of how to use the language's defmulti/defmethod constructs. But is it multiple dispatch at all? No! It's just single dispatch, really. Our ops (evaluate and stringify) dispatch on a single argument - the expression type) 5.
我此前曾撰文介绍 Clojure 中的多重派发,在上一节中,我们也看到了 defmulti/defmethod 这一语法结构的使用示例。但这真的属于多重派发吗?答案是否定的!实际上,这仅仅是单派发 :我们定义的操作(evaluate 与 stringify)仅基于单个参数(即表达式类型)进行派发 5。
If we're not really using multiple dispatch, what is the secret sauce that lets us solve the expression problem so elegantly in Clojure? The answer is - open methods. Note a crucial difference between how methods are defined in C++/Java and in Clojure. In C++/Java, methods have to be part of a class and defined (or at least declared) in its body. You cannot add a method to a class without changing the class's source code.
既然我们并未真正使用多重派发,那么 Clojure 能够优雅解决表达式问题的关键机制究竟是什么?答案是------开放方法。请注意 C++/Java 与 Clojure 在方法定义方式上的一个关键差异:在 C++/Java 中,方法必须作为类的一部分,在类的主体中进行定义(或至少进行声明)。若不修改类的源代码,我们无法为该类新增方法。
In Clojure, you can. In fact, since data types and multimethods are orthogonal entities, this is by design. Methods simply live outside types - they are first class citizens, rather than properties of types. We don't add methods to a type , we add new methods that act upon the type . This doesn't require modifying the type's code in any way (or even having access to its code).
而在 Clojure 中,我们可以做到这一点。事实上,由于数据类型与多方法是相互正交的实体,这种设计是语言的固有特性。方法独立于类型存在------它们是一等公民,而非类型的附属属性。我们并非将方法添加到类型中 ,而是新增作用于该类型的方法。这一过程无需以任何方式修改类型的代码(甚至无需获取该类型的代码)。
Some of the other popular programming languages take a middle way. In languages like Python, Ruby and JavaScript methods belong to types, but we can dynamically add, remove and replace methods in a class even after it was created. This technique is lovingly called monkey patching . While initially enticing, it can lead to big maintainability headaches in code unless we're very careful. Therefore, if I had to face the expression problem in Python I'd prefer to roll out some sort of multiple dispatch mechanism for my program rather than rely on monkey patching.
其他部分主流编程语言则采取了折中方案。在 Python、Ruby、JavaScript 等语言中,方法归属于类型,但即便类已经创建完成,我们仍然可以动态地为其新增、删除或替换方法。这种技术被形象地称为猴子补丁。尽管该技术在初期颇具吸引力,但如果使用不当,会给代码的维护带来极大麻烦。因此,若我需要在 Python 中解决表达式问题,我更倾向于为程序实现某种多重派发机制,而非依赖猴子补丁。
Another Clojure solution - using protocols
Clojure 的另一解决方案------基于协议
Clojure's multimethods are very general and powerful. So general, in fact, that their performance may not be optimal for the most common case - which is single dispatch based on the type of the sole method argument; note that this is exactly the kind of dispatch I'm using in this article. Therefore, starting with Clojure 1.2, user code gained the ability to define and use protocols - a language feature that was previously restricted only to built-in types.
Clojure 的多方法具备极强的通用性与扩展性。但正是由于其通用性过强,在处理最常见的场景时,性能可能无法达到最优------这种场景即基于单一方法参数的类型进行单派发;请注意,本文所采用的正是这种派发方式。因此,从 Clojure 1.2 版本开始,用户代码获得了定义和使用协议的能力------该特性此前仅适用于内置类型。
Protocols leverage the host platform's (which in Clojure's case is mostly Java) ability to provide quick virtual dispatch, so using them is a very efficient way to implement runtime polymorphism. In addition, protocols retain enough of the flexibility of multimethods to elegantly solve the expression problem. Curiously, this was on the mind of Clojure's designers right from the start. The Clojure documentation page about protocols lists this as one of their capabilities:
协议利用宿主平台(对 Clojure 而言,主要是 Java 平台)提供的快速虚派发能力,是实现运行时多态的一种高效方式。同时,协议保留了多方法足够的灵活性,能够优雅地解决表达式问题。有趣的是,Clojure 的设计者从一开始便考虑到了这一特性。Clojure 的协议官方文档将其列为协议的核心能力之一:
... Avoid the 'expression problem' by allowing independent extension of the set of types, protocols, and implementations of protocols on types, by different parties. ... do so without wrappers/adapters
通过允许不同参与方独立扩展类型集、协议集,以及类型上的协议实现,规避表达式问题。并且无需使用包装器或适配器。
Clojure protocols are an interesting topic, and while I'd like to spend some more time on them, this article is becoming too long as it is. So I'll leave a more thorough treatment for some later time and for now will just show how protocols can also be used to solve the expression problem we're discussing.
Clojure 协议是一个极具研究价值的话题,尽管我希望就此展开更多论述,但本文的篇幅已经过长。因此,我将把更深入的探讨留到以后,此处仅展示如何使用协议解决我们所讨论的表达式问题。
The type definitions remain the same:
类型的定义保持不变:
(defrecord Constant [value])
(defrecord BinaryPlus [lhs rhs])However, instead of defining a multimethod for each operation, we now define a protocol . A protocol can be thought of as an interface in a language like Java, C++ or Go - a type implements an interface when it defines the set of methods declared by the interface. In this respect, Clojure's protocols are more like Go's interfaces than Java's, as we don't have to say a-priori which interfaces a type implements when we define it.
但与为每个操作定义一个多方法不同,我们此处定义的是协议。协议可以类比为 Java、C++、Go 等语言中的接口------当一个类型实现了接口所声明的所有方法时,即表示该类型实现了该接口。在这一点上,Clojure 的协议更接近 Go 语言的接口,而非 Java 的接口:我们无需在定义类型时,预先声明该类型实现了哪些接口。
Let's start with the Evaluatable protocol, that consists of a single method - evaluate:
首先,我们定义 Evaluatable 协议,该协议仅包含一个方法------evaluate:
(defprotocol Evaluatable
(evaluate [this]))Another protocol we'll define is Stringable:
接下来,我们定义另一个协议------Stringable:
(defprotocol Stringable
(stringify [this]))Now we can make sure our types implement these protocols:
随后,我们为上述类型实现这些协议:
(extend-type Constant
Evaluatable
(evaluate [this] (:value this))
Stringable
(stringify [this] (str (:value this))))
(extend-type BinaryPlus
Evaluatable
(evaluate [this] (+ (evaluate (:lhs this)) (evaluate (:rhs this))))
Stringable
(stringify [this]
(clojure.string/join " + " [(stringify (:lhs this))
(stringify (:rhs this))])))The extend-type macro is a convenience wrapper around the more general extend - it lets us implement multiple protocols for a given type. A sibling macro named extend-protocol lets us implement the same protocol for multiple types in the same invocation 6.
extend-type 宏是更通用的 extend 宏的封装,它支持为单个类型实现多个协议。与之对应的 extend-protocol 宏,则支持在一次调用中为多个类型实现同一个协议 6。
It's fairly obvious that adding new data types is easy - just as we did above, we simply use extend-type for each new data type to implement our current protocols. But how do we add a new protocol and make sure all existing data types implement it? Once again, it's easy because we don't have to modify any existing code. Here's a new protocol:
显然,新增数据类型的操作十分简便------正如我们上文所做的那样,只需通过 extend-type 宏为每个新数据类型实现现有协议即可。但如果我们需要新增一个协议,并确保所有已有数据类型都实现该协议,该如何操作?答案同样简便,因为我们无需修改任何现有代码。以下是一个新协议的定义:
(defprotocol Serializable
(serialize [this]))And this is its implementation for the currently supported data types:
以下是该协议在当前支持的数据类型上的实现:
(extend-protocol Serializable
Constant
(serialize [this] [(type this) (:value this)])
BinaryPlus
(serialize [this] [(type this)
(serialize (:lhs this))
(serialize (:rhs this))]))This time, extending a single protocol for multiple data types - extend-protocol is the more convenient macro to use.
此次我们需要为多个数据类型扩展同一个协议,extend-protocol 宏是更便捷的选择。
Small interfaces are extensibility-friendly
小型接口提升可扩展性
You may have noted that the protocols (interfaces) defined in the Clojure solution are very small - consisting of a single method. Since adding methods to an existing protocol is much more problematic (I'm not aware of a way to do this in Clojure), keeping protocols small is a good idea. This guideline comes up in other contexts as well; for example, it's good practice to keep interfaces in Go very minimal.
读者可能已经注意到,Clojure 解决方案中定义的协议(即接口)都非常精简------仅包含单个方法。由于向已有协议中新增方法的操作存在诸多限制(据我所知,Clojure 中没有直接实现该操作的方式),因此保持协议的精简是一种良好的设计习惯。该原则同样适用于其他场景,例如在 Go 语言中,保持接口的简洁性也是推荐的编程实践。
In our C++ solution, splitting the Expr interface could also be a good idea, but it wouldn't help us with the expression problem, since we can't modify which interfaces a class implements after we've defined it; in Clojure we can.
在我们的 C++ 解决方案中,拆分 Expr 接口同样是一种不错的思路,但这无法帮助我们解决表达式问题------因为在类定义完成后,我们无法修改该类所实现的接口;而在 Clojure 中,我们可以做到这一点。
footnote
"Types of data" and "operations" are two terms that should be fairly obvious to modern-day programmers. Philip Wadler, in his discussion of the expression problem (see the "historical perspective" section of the article) calls them "datatypes" and "functions". A famous quote from Fred Brooks's The Mythical Man Month (1975) is "Show me your flowcharts and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won't usually need your flowcharts; they'll be obvious."
"数据类型"与"操作"是现代程序员熟知的两个术语。Philip Wadler 在其关于表达式问题的论述中(见本文"历史背景"部分),将其称为"数据类型"与"函数"。Fred Brooks 在《人月神话》(1975 年)中有一句经典论述:"展示你的流程图,隐藏你的数据表,我仍会感到困惑;展示你的数据表,我通常无需查看流程图------其逻辑将一目了然。"
Note the peculiar way in which data is passed between Visit* methods in a Expr* -> Value map kept in the visitor. This is due to our inability to make Visit* methods return different types in different visitors. For example, in Evaluator we'd want them to return double, but in Stringifier they'd probably return std::string. Unfortunately C++ won't let us easily mix templates and virtual functions, so we have to resort to either returning void* the C way or the method I'm using here. Curiously, in their paper Krishnamurthi et.al. run into the same issue in the dialect of Java they're using, and propose some language extensions to solve it. Philip Wadler uses proposed Java generics in his approach.
请注意访问者中通过 Expr* -> Value 映射表,在不同 Visit* 方法间传递数据的特殊方式。这是由于我们无法使不同访问者的 Visit* 方法返回不同类型的值:例如,Evaluator 中的 Visit* 方法需要返回 double 类型,而 Stringifier 中的 Visit* 方法则可能需要返回 std::string 类型。遗憾的是,C++ 难以兼顾模板与虚函数的混合使用,因此我们不得不采用两种方式:要么像 C 语言那样返回 void* 类型,要么采用本文所使用的映射表方式。有趣的是,Krishnamurthi 等人在其论文中,在他们所使用的 Java 方言里也遇到了同类问题,并提出了一些语言扩展方案来解决该问题。而 Philip Wadler 在其方案中,则使用了当时处于提案阶段的 Java 泛型特性。
3 I can't resist, so just in brief: IMHO inheritance is only good for a very narrow spectrum of uses, but languages like C++ hail it as the main extension mechanism of types. But inheritance is deeply flawed for many other use cases, such as implementations of interfaces. Java is a bit better in this regard, but in the end the primacy of classes and their "closed-ness" make a lot of tasks - like the expression problem - very difficult to express in a clean way. |
我忍不住想补充几句:在我看来,继承仅适用于极窄的应用场景,但 C++ 等语言却将其视为类型扩展的主要机制。然而,继承在接口实现等诸多场景中存在显著缺陷。Java 在这方面略有优化,但归根结底,类的核心地位及其"封闭性",使得许多任务(例如表达式问题)难以通过简洁的方式实现。
In fact, there are plenty of examples in which the Clojure implementation and the standard library provide protocols that can be extended by the user for user-defined types. Extending user-written protocols and multimethods for built-in types is trivial. As an exercise, add an evaluate implementation for java.lang.Long, so that built-in integers could participate in our expression trees without requiring wrapping in a Constant.
事实上,Clojure 语言实现与标准库中存在大量协议示例,用户可基于这些协议扩展自定义类型。为内置类型扩展用户编写的协议与多方法的操作极为简便。作为练习,读者可尝试为 java.lang.Long 类型添加 evaluate 实现,使内置整数无需封装为 Constant 类型即可参与表达式树的计算。
FWIW, we can formulate a multiple dispatch solution to the expression problem in Clojure. The key idea is to dispatch on two things: type and operation. Just for fun, I coded a prototype that does this which you can see here. I think the approach presented in the article - each operation being its own multimethod - is preferable, though.
补充说明:我们确实可以在 Clojure 中设计表达式问题的多重派发解决方案。其核心思路是基于两个维度进行派发:类型与操作。出于兴趣,我编写了一个原型实现,可参考此处。不过,我认为本文提出的方案(为每个操作定义独立的多方法)更为可取。
The sharp-eyed reader will notice a cool connection to the expression problem matrix. extend-type can add a whole new row to the matrix, while extend-protocol adds a column. extend adds just a single cell.
细心的读者会发现其与表达式问题矩阵的关联:extend-type 可向矩阵中新增一整行(对应新增类型),extend-protocol 可新增一整列(对应新增操作),而 extend 仅新增单个单元格(对应为特定类型实现特定协议方法)。
On the Composite and Interpreter design patterns
组合模式与解释器模式详解
Eli Bendersky May 05, 2016 at 05:04
I often see references to the interpreter design pattern in papers related to programming language design. This short post is here to help me remember what this pattern reference usually means, as well as document its relation to the composite design pattern.
在编程语言设计相关的论文中,我经常看到对"解释器模式"的提及。这篇短文旨在帮助我梳理该模式的常见含义,并阐述其与"组合模式"之间的关联。
The short Wikipedia definition of the interpreter design pattern is:
维基百科对解释器模式的简要定义为:
Given a language, define a representation for its grammar along with an interpreter that uses the representation to interpret sentences in the language.
给定一门语言,定义其语法的表示形式,并实现一个解释器,利用该表示形式解释语言中的句子。
On the page dedicated to the pattern, it also says:
在解释器模式的专属维基百科页面中,还提到:
The syntax tree of a sentence in the language is an instance of the composite pattern and is used to evaluate (interpret) the sentence for a client.
该语言中句子的语法树是组合模式的实例,用于为客户端对句子进行求值(解释)。
As a compiler hacker, all of this sounds very familiar. Indeed, if you've ever written an interpreter or compiler for a programming language or a domain-specific language - even a simple one - you've almost certainly used both the interpreter and composite patterns.
作为一名编译器开发者,这些内容对我而言都十分熟悉。事实上,只要你曾为编程语言或领域特定语言(即使是简单的语言)编写过解释器或编译器,就几乎必然同时用到过解释器模式和组合模式。
Suppose we have a very simple language for evaluating mathematical expressions, and we want to write an interpreter for it. Using the classical compiler work-flow we'll tokenize the language, parse it to produce a syntax tree and then either interpret this tree directly or compile it down to some lower-level representation. For the purpose of this post, we'll assume:
假设我们有一门用于计算数学表达式的极简语言,现需为其编写解释器。按照经典的编译器工作流程,我们会先对语言进行词法分析、语法分析以生成语法树,随后要么直接解释该语法树,要么将其编译为更低级的表示形式。本文将基于以下假设展开:
-
Direct evaluation (interpretation) on the tree is used. A compiler would use exactly the same pattern, except that it would emit some sort of code instead of direct results.
采用对语法树直接求值(解释执行)的方式。编译器会采用完全相同的模式,区别仅在于其会生成某种代码而非直接输出结果。
-
We don't care about how the tree is constructed, i.e. the syntax of the language. This post's code sample starts with the constructed syntax tree in memory and focuses on how it's represented and interpreted.
暂不关注语法树的构建过程(即语言的语法规则)。本文的代码示例将以内存中已构建完成的语法树为起点,重点讲解其表示方式与解释逻辑。
With this in mind, here's a simple C++ program that represents expressions and evaluates them. I'll show the code piecemeal to explain what it does; the full code sample is available here.
基于上述前提,以下是一个用于表示表达式并执行求值的简单C++程序。我将分段展示代码并解释其功能,完整代码可参考。
We'll start with an abstract interface called Expr which all syntax elements have to implement:
首先定义一个名为Expr的抽象接口,所有语法元素都必须实现该接口:
cpp
// Maps symbol names to their values. An expression is evaluated in the context
// of a symbol table, in order to assign concrete values to variables referenced
// within it.
// 符号表:将符号名称映射到对应的值。表达式在符号表的上下文环境中求值,
// 以此为表达式中引用的变量分配具体值。
typedef std::map<std::string, double> SymbolTable;
// Abstract interface for expressions in the language.
// 语言中表达式的抽象接口。
class Expr {
public:
// Evaluate the expression in the context of the given symbol table, which
// is to be used to resolve (or update) variable references.
// 在指定符号表的上下文环境中对表达式求值,符号表用于解析(或更新)变量引用。
virtual double Eval(SymbolTable* st) const = 0;
};
And some simple expression kinds:
以下是几种简单的表达式类型:
cpp
class Constant : public Expr {
public:
Constant(double value) : value_(value) {}
double Eval(SymbolTable* st) const {
return value_;
}
private:
double value_;
};
class VarRef : public Expr {
public:
VarRef(const char* varname) : varname_(varname) {}
double Eval(SymbolTable* st) const {
// Ignore errors: assuming the symbol is defined.
// 忽略错误:假设符号已定义。
return (*st)[varname_];
}
private:
std::string varname_;
};
Expressions such as constants and variable references are often called terminal , or leaf expressions, since they don't contain other expressions within them. Let's add a more complex, non-leaf expression:
常量、变量引用这类表达式通常被称为"终结符表达式"或"叶子表达式",因为它们内部不包含其他表达式。下面我们添加一种更复杂的非叶子表达式:
cpp
// A function type for computing the result of a binary operation.
// 用于计算二元运算结果的函数类型。
typedef std::function<double(double, double)> BinaryFunction;
class BinaryOp : public Expr {
public:
BinaryOp(BinaryFunction func, const Expr& lhs, const Expr& rhs)
: func_(func), lhs_(lhs), rhs_(rhs) {}
double Eval(SymbolTable* st) const {
return func_(lhs_.Eval(st), rhs_.Eval(st));
}
private:
BinaryFunction func_; // 二元运算函数
const Expr& lhs_; // 左操作数表达式
const Expr& rhs_; // 右操作数表达式
};
Note how BinaryOp implements the same interface as the leaf expressions. Its Eval defers to the Eval method of its constituent left-hand-side and right-hand-side expressions. This is an embodiment of the Composite design pattern, defined as:
注意,BinaryOp 与叶子表达式实现了相同的接口,其 Eval 方法会委托给组成它的左、右操作数表达式的 Eval 方法执行。这正是组合模式的体现,组合模式的定义为(参考链接:https://en.wikipedia.org/wiki/Composite_pattern):
... describes that a group of objects is to be treated in the same way as a single instance of an object. The intent of a composite is to "compose" objects into tree structures to represent part-whole hierarchies. Implementing the composite pattern lets clients treat individual objects and compositions uniformly.
......将一组对象视为单个对象的实例进行处理。组合模式的目的是将对象组合成树形结构,以表示"部分-整体"的层次关系。实现组合模式后,客户端可以统一对待单个对象和对象组合。
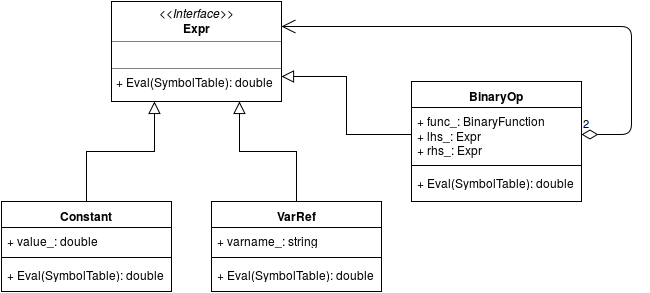
In the language of the Composite pattern, there are leaf and composite classes, both of which are components . In our example, a Constant is a leaf, and so is a VarRef. A BinaryOp is a composite. Both inherit from Expr, which is the component .
在组合模式的术语体系中,存在"叶子类"和"组合类",二者均属于"组件类"。在我们的示例中,Constant 和 VarRef 是叶子类,BinaryOp 是组合类,它们均继承自组件类 Expr。
The core of the composite pattern manifests here in the uniform interface (Expr) implemented by both Constant ("individial object" in the definition quoted above) andBinaryOp ("composition").
组合模式的核心就体现在:Constant(对应定义中的"单个对象")和 BinaryOp(对应定义中的"对象组合")实现了统一的接口(Expr)。
I'm not a big fan of UML, but since this is design patterns we're talking about, I couldn't help myself . Here's our class diagram described in UML. Note the close conceptual resemblance to the UML diagram on the Composite Pattern Wikipedia page.
我并不热衷于UML图,但既然讨论的是设计模式,就忍不住画了一个;-)以下是用UML表示的类图,其概念与组合模式维基百科页面上的UML图高度相似。
Finally, let us see these classes in action. Here's a main function that hand-assembles a simple expression and evaluates it. This is a toy for demonstration purposes; in a real program, the syntax tree would be built automatically, most likely by a parser.
最后,我们来看这些类的实际应用。以下是一个main函数,它手动构造了一个简单表达式并执行求值。这仅为演示用例,在实际程序中,语法树通常由解析器自动构建。
cpp
int main(int argc, const char** argv) {
// Define a couple of constants and a reference to the variable 'A'.
// 定义两个常量和一个变量'A'的引用。
std::unique_ptr<Expr> c1(new Constant(2.0));
std::unique_ptr<Expr> c2(new Constant(3.3));
std::unique_ptr<Expr> v(new VarRef("A"));
// Define a binary expression representing "2.0 * 3.3 + A"
// 定义表示"2.0 * 3.3 + A"的二元表达式
std::unique_ptr<Expr> e1(new BinaryOp(std::multiplies<double>(), *c1, *c2));
std::unique_ptr<Expr> e2(new BinaryOp(std::plus<double>(), *e1, *v));
// Evaluate in the context of a symbol table where A has the value 1.1
// 在符号表上下文(A的值为1.1)中求值
SymbolTable st{{"A", 1.1}};
std::cout << e2->Eval(&st) << "\n";
return 0;
}
The expression tree created by this code is:
上述代码构建的表达式树如下:
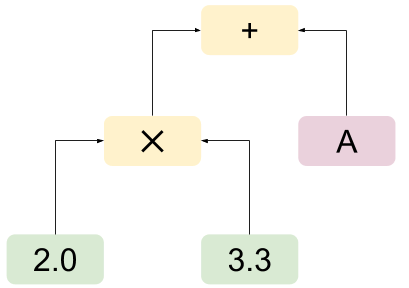
It is then evaluated with the context of A = 1.1, and the result is 7.7, as expected.
在 A = 1.1 的上下文环境中求值,结果与预期一致,为7.7。
Finally, I'll mention that while this example is very typical of a scenario in which I usually encounter these two patterns, it's by no means the only one.
最后需要说明的是,尽管该示例是我常见的两种模式应用场景,但绝非唯一场景。
The Composite pattern has life outside interpreters, of course. It's useful whenever a group of objects can be handled in a uniform manner as a single object. For example, in the world of graphics we may have shape objects that can be moved, rotated, and so on; we may want to treat a "group of shapes" similarly (move all shapes within it equally, rotate the group, etc). This calls for the use of the composite pattern where all shapes, as well as a "shape group" derive from a common component interface.
当然,组合模式的应用并不局限于解释器。只要一组对象可以被当作单个对象统一处理,组合模式就具备实用价值。例如,在图形领域,我们可能有可移动、旋转的图形对象;同时希望以相同方式处理"图形组"(移动组内所有图形、旋转整个组等)。这种场景就适合使用组合模式------让所有图形和"图形组"都继承自同一个组件接口。
The Interpreter pattern is useful whenever a problem can be described by a language of any sort. Some examples are SQL or other logical query methods, regular expressions, many kinds of rule-based systems, etc.
当某个问题可通过某种语言进行描述时,解释器模式就会发挥作用。典型例子包括SQL及其他逻辑查询方法、正则表达式、各类基于规则的系统等。
An Analysis and Discussion of Solutions to the Expression Problem Across Programming Languages
跨编程语言的表达式问题解决方案分析与探讨
KEVIN TIAN, Stanford University
凯文·田,斯坦福大学
COLIN WEI, Stanford University
科林·魏,斯坦福大学
The "expression problem" in programming language design refers to the following phenomenon that occurs in naive implementations in functional or object-oriented programming languages: suppose we have a set of object classes, and a set of methods that the classes support. Then, while requiring that existing code not be modified, it is often simple to extend the code to include either an additional method (to be supported by all existing classes), or an additional class (to support all existing functions), but not both. Various solutions to this problem have been proposed in different programming languages, each with their unique sets of tradeoffs and features. In this paper we aim to provide a unified discussion and analysis on case studies of these solutions in Java, C++, Clojure, and OCaml. We also provide a novel solution which arises naturally in object-oriented languages by considering the duality of functions and objects in the expression problem. Our implementations can be found at https://github.com/cwein3/CS242Proj/.
编程语言设计中的"表达式问题"指的是在函数式或面向对象编程语言的朴素实现中出现的如下现象:假设我们有一组对象类,以及这些类所支持的一组方法。那么,在要求不修改现有代码的前提下,通常可以轻松地扩展代码以添加一个额外的方法(由所有现有类支持)或一个额外的类(支持所有现有函数),但无法同时实现这两种扩展。不同编程语言中已提出多种该问题的解决方案,每种方案都有其独特的权衡取舍和特性。本文旨在对 Java、C++、Clojure 和 OCaml 中的这些解决方案案例进行统一讨论与分析。我们还通过考虑表达式问题中函数与对象的二元性,提出了一种在面向对象语言中自然形成的新型解决方案。相关实现代码可在 https://github.com/cwein3/CS242Proj/ 获取。
Additional Key Words and Phrases:
补充关键词与短语:
Expression problem, functional programming language, object oriented programming language
表达式问题、函数式编程语言、面向对象编程语言
ACM Reference Format:
ACM 参考文献格式:
Kevin Tian and Colin Wei. 2017. An Analysis and Discussion of Solutions to the Expression Problem Across Programming Languages. 1, 1 (December 2017), 7 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn
凯文·田、科林·魏. 2017. 跨编程语言的表达式问题解决方案分析与探讨. 1, 1 (2017年12月), 7 页. https://doi.org/10.1145/nnnnnnn.nnnnnnn
1 INTRODUCTION
1 引言
The expression problem is now a classical problem in program language design, because in many ways it captures the expressibility of a language. The problem is as follows: consider a chunk of code that consists of some m m m "object classes" and n n n "functions", such that each object class should support its own implementation of each function. A simple example that we will use throughout this survey (and will call the "shapes example") is the situation where the object classes are different types of shapes (for example, Triangle, Square, Hexagon, ...) and the functions are computations which are specific to the type of shape (for example, angle, area, or perimeter calculation). The classic difficulty described by the expression problem arises when we try to extend the code to include either 1) an additional class which supports all existing functions, or 2) an additional method which is supported by all existing classes, both without modifying or duplicating existing code. The problem can be motivated by considering the following: clearly, if we are to add an additional function, we must write at least m m m pieces of additional code to describe the implementation for each existing class (and similar for adding classes); a solution to the expression problem must do the minimal amount of additional implementation in both of these cases.
表达式问题现已成为编程语言设计中的经典问题,因为它在诸多方面反映了一种语言的表达能力。该问题具体如下:考虑一段由 m m m 个"对象类"和 n n n 个"函数"组成的代码,每个对象类都应支持每个函数的专属实现。本研究中将全程使用一个简单示例(称为"形状示例"):对象类为不同类型的形状(例如三角形、正方形、六边形等),函数为特定于形状类型的计算(例如角度、面积或周长计算)。表达式问题所描述的经典难点在于,当我们尝试扩展代码以实现以下两种情况之一时:1)添加一个支持所有现有函数的新类;2)添加一个被所有现有类支持的新方法,且两种情况都不允许修改或重复现有代码。该问题的核心诉求可通过以下思考理解:显然,若要添加一个新函数,我们至少需要编写 m m m 段额外代码,为每个现有类描述该函数的实现(添加类时同理);表达式问题的解决方案必须在这两种情况下都仅需最少的额外实现工作。
The reason this problem is typically difficult is because most programming languages make one of these cases easy, and the other hard. For example, in functional languages, adding functions is easy, but adding classes is difficult -- naively, it requires retroactively modifying existing functions. Conversely, in object-oriented languages, adding objects is easy, but it is difficult to add a function without touching existing code. Since the problem has been proposed, there have been many workaround solutions that were discovered, which vary in simplicity, safety, and performance overhead. We aim to provide a survey of these methods in four languages, which we hope will serve as comprehensive case studies and illustrate why this problem is not as intimidating as it may appear. As far as we can tell, solutions fall under one of four general frameworks: object algebras, visitors, type classes, and multi-methods. We provide implementations of solutions falling under these frameworks in programming language settings that we found illuminating, benchmark the solutions, and then conclude by suggesting a novel approach and giving a discussion.
该问题通常难以解决的原因在于,大多数编程语言仅能使其中一种扩展情况变得简单,而另一种则较为困难。例如,在函数式语言中,添加函数很容易,但添加类却很困难------朴素实现下,这需要回溯修改现有函数。相反,在面向对象语言中,添加对象很容易,但要在不改动现有代码的情况下添加函数却十分困难。自该问题被提出以来,人们已发现多种变通解决方案,这些方案在简洁性、安全性和性能开销方面各有差异。本文旨在对这四种语言中的这些方法进行综述,希望能提供全面的案例研究,并阐明为何该问题并不像看上去那样令人望而生畏。据我们所知,解决方案可归为四大通用框架之一:对象代数(object algebras)、访问者模式(visitors)、类型类(type classes)和多方法(multi-methods)。我们在具有启发意义的编程语言环境中实现了这些框架下的解决方案,对其进行了性能基准测试,最后提出了一种新方法并进行了讨论。
2 OBJECT ALGEBRAS
2 对象代数
Oliveira and Cook 2012 introduce the concept of object algebras in order to solve the expression problem. According to Oliveira and Cook 2012, the advantage of object algebras is that they can be easily implemented in commonly used object-oriented languages such as Java and C#. The object algebras framework is relatively simple and does not require complex typing features.
Oliveira 和 Cook 于 2012 年提出了对象代数的概念,以解决表达式问题。根据 Oliveira 和 Cook(2012)的研究,对象代数的优势在于其可在 Java 和 C# 等常用面向对象语言中轻松实现。该框架相对简单,无需复杂的类型特性。
Consider the shapes example. To implement object algebras, we would first define a ShapeAlg interface, which defines a function that implements the desired behavior for each type of shape: triangle(), square(), etc. Next, "factories" for different operations will implement this interface. For example, to implement the area computation, we would first define an Area interface which has a single function, area(). Then we could define an AreaFactory that implements ShapeAlg and constructs an Area object that implements area() in a manner that is specific to the shape type.
以形状示例为例。要实现对象代数,我们首先定义一个 ShapeAlg 接口,该接口为每种形状类型定义一个实现所需行为的函数:triangle()、square() 等。接下来,不同操作的"工厂"将实现该接口。例如,要实现面积计算,我们首先定义一个 Area 接口,该接口包含一个单一函数 area()。然后,我们可以定义一个 AreaFactory,它实现 ShapeAlg 并构造一个 Area 对象,该对象以特定于形状类型的方式实现 area() 方法。
The expression problem is now solved because to add new shape types, we can simply extend the ShapeAlg interface to support a new function for that shape type. For example, to add support for hexagons, we can extend ShapeAlg to the ShapeAlgWithHexagon interface, which also includes a hexagon() function. We would then extend the already-existing factories to implement the new hexagon() function. Adding a new operation is easy too: we simply create a new factory for that operation. For example, to add the perimeter operation, we would create a Perimeter interface of objects which include the perimeter function, and then we would create a PerimeterFactory which creates Perimeter objects.
此时表达式问题得到了解决,因为要添加新的形状类型,我们只需扩展 ShapeAlg 接口,为该形状类型添加一个新函数即可。例如,要支持六边形,我们可以将 ShapeAlg 扩展为 ShapeAlgWithHexagon 接口,该接口还包含一个 hexagon() 函数。然后,我们扩展已有的工厂以实现新的 hexagon() 函数。添加新操作也同样简单:只需为该操作创建一个新工厂。例如,要添加周长计算操作,我们可以创建一个包含 perimeter 函数的 Perimeter 接口对象,然后创建一个 PerimeterFactory 来构造 Perimeter 对象。
We implement our shapes setting using object algebras in order to provide a qualitative and quantitative evaluation of this solution to the expression problem. We use Java for our implementation. In our implementation, we explore both aspects of extensibility: we add a new angle calculation operation on top of the already existing area and perimeter operations, and we add a new hexagon shape. We then benchmark our code as follows: we construct 1000000 1000000 1000000 random shapes, and then perform our area, perimeter, and angle computations for each of these random shapes. This is the benchmark that will be used throughout the rest of the paper to test performance. For the object algebras setting, we compare against a standard object oriented solution.
为了对该表达式问题解决方案进行定性和定量评估,我们基于对象代数实现了形状示例。实现语言采用 Java。在实现中,我们探究了可扩展性的两个方面:在已有的面积和周长计算操作基础上添加了新的角度计算操作,并添加了新的六边形形状。然后,我们对代码进行了如下性能基准测试:构造 1000000 1000000 1000000 个随机形状,然后对每个随机形状执行面积、周长和角度计算。本文后续将统一使用该基准测试来评估性能。在对象代数方案中,我们将其与标准的面向对象解决方案进行了对比。
Qualitatively, we find that the object algebras framework is indeed very easy to use once one understands it. In particular, the implementation did not require an advanced knowledge of extensibility and object oriented principles beyond the basic understanding that one could gain from an introductory computer science class. Object algebras also did not require any advanced object oriented features to implement.
定性分析表明,一旦理解了对象代数框架,它确实非常易于使用。具体而言,该实现无需超出计算机科学入门课程所教授的基础概念之外的、关于可扩展性和面向对象原理的高级知识。对象代数的实现也不需要任何高级的面向对象特性。
We do note that object algebras make certain aspects of object oriented programming more unwieldy, however. For the pure object oriented implementation, in our benchmarks we simply created a Triangle, Square, etc. object depending on the shape type. Then to perform calculations on our shapes, we simply called shape.CalcArea(), shape.CalcPerimeter(), and so on, without having to worry about the specific type of shape. However, since object algebra implementation did not have a notion of a shape object, we had to make several type-specific function calls for each shape. For example, to create a triangle, we had to call AreaFactory.triangle(), PerimeterFactory.triangle(), AngleFactory.triangle(). Perhaps there is a more clever way to circumvent this issue, but the object oriented approach certainly seems more natural and simpler in this case. This could become a hassle in more complicated projects that need to support multiple different operation types at once.
然而,我们也注意到,对象代数使面向对象编程的某些方面变得更加繁琐。在纯面向对象实现中,我们在基准测试中只需根据形状类型创建 Triangle、Square 等对象。然后,要对这些形状执行计算,只需调用 shape.CalcArea()、shape.CalcPerimeter() 等方法,而无需担心形状的具体类型。但由于对象代数实现中没有形状对象的概念,我们必须为每个形状进行多次特定于类型的函数调用。例如,要创建一个三角形,我们必须调用 AreaFactory.triangle()、PerimeterFactory.triangle()、AngleFactory.triangle()。或许存在更巧妙的方法来规避此问题,但在这种情况下,面向对象方法显然更自然、更简单。在需要同时支持多种不同操作类型的更复杂项目中,这可能会成为一个麻烦。
Quantitatively, we also found that the object algebras implementation suffered runtime losses compared to the object oriented approach. The object algebras implementation took around 2.5 2.5 2.5 times longer to perform the same operations. We hypothesize that this might be because the object algebras implementation is required to make a separate object for computing area, perimeter, and angle, instead of just a single shape object.
定量分析方面,我们发现与面向对象方法相比,对象代数实现存在运行时性能损失。对象代数实现执行相同操作所需的时间约为面向对象方法的 2.5 2.5 2.5 倍。我们推测,这可能是因为对象代数实现需要为面积、周长和角度计算分别创建独立的对象,而不是仅使用一个单一的形状对象。
| Object Algebras | Object Oriented | |
|---|---|---|
| Runtime (seconds) | 0.327 | 0.139 |
Fig. 1 : We show the average runtime, in seconds, of our shapes benchmark for both the object algebras and object oriented implementations. Times are averaged over 10 trials in order to reduce variance.
图 1:展示了对象代数和面向对象实现的形状基准测试平均运行时间(以秒为单位)。为减少方差,时间取 10 次试验的平均值。
3 VISITOR FRAMEWORK
3 访问者框架
The visitor pattern Krishnamurthi et al. 1998 is an older solution to the expression problem than object algebras, and object algebras are similar to the visitor pattern in many ways. The visitor pattern applies functional programming ideas to solve the expression problem in object-oriented languages. Both the visitor pattern and object algebras invert the object oriented paradigm by defining objects for the different operations we wish to perform and then defining functions corresponding to each type. However, object algebras claim to remove some of the overhead involved in the visitor pattern, namely the need for "accept" methods, while the visitor pattern seems more object-oriented in nature.
访问者模式Krishnamurthi 等人,1998是比对象代数更早的表达式问题解决方案,且对象代数在许多方面与访问者模式相似。访问者模式运用函数式编程思想来解决面向对象语言中的表达式问题。访问者模式和对象代数都通过为我们希望执行的不同操作定义对象,然后为每种类型定义相应的函数,从而颠覆了面向对象范式。然而,对象代数声称消除了访问者模式中的部分开销,即无需"accept"方法,而访问者模式在本质上似乎更具面向对象特性。
To implement the visitor pattern in the shapes setting, we first define a ShapesVisitor interface that has functions VisitTriangle(), VisitSquare(), etc., for each type of shape. These visit functions will take in a shape object and perform the desired operation on that object. For example, to implement area computation, we could define the AreaVisitor class which will implement VisitTriangle(), etc., to correctly compute the area for the specific shape. This idea is very similar to the approach taken by object algebras; however, the visitor pattern differs in the sense that we also need to define a Shapes interface with the function Accept. The purpose of the Accept function is to take in a visitor and call the visitor's operation on itself: for example, a Triangle class would implement the Accept function by taking in a generic ShapesVisitor and calling VisitTriangle() on itself. In a way, the visitor framework implements functional programming in an object oriented language by mapping different operations to various function objects.
要在形状示例中实现访问者模式,我们首先定义一个 ShapesVisitor 接口,该接口为每种形状类型提供 VisitTriangle()、VisitSquare() 等函数。这些访问函数将接收一个形状对象,并对该对象执行所需的操作。例如,要实现面积计算,我们可以定义 AreaVisitor 类,该类将实现 VisitTriangle() 等方法,以正确计算特定形状的面积。这一思路与对象代数采用的方法非常相似;然而,访问者模式的不同之处在于,我们还需要定义一个包含 Accept 函数的 Shapes 接口。Accept 函数的作用是接收一个访问者,并调用访问者针对自身的操作:例如,Triangle 类实现 Accept 函数时,会接收一个通用的 ShapesVisitor 并调用其 VisitTriangle() 方法。在某种程度上,访问者框架通过将不同操作映射到各种函数对象,在面向对象语言中实现了函数式编程。
To create new types in the visitor framework, we would again extend the shapes visitor interface to account for the additional type. For example, to add hexagons, we would extend ShapesVisitor to the ShapesVisitorWithHexagon interface, which contains a VisitHexagon() function. To add new operations, we could simply write a new visitor.
要在访问者框架中创建新类型,我们只需扩展形状访问者接口以适配该新类型。例如,要添加六边形,我们将 ShapesVisitor 扩展为 ShapesVisitorWithHexagon 接口,该接口包含一个 VisitHexagon() 函数。要添加新操作,只需编写一个新的访问者即可。
We implement the visitor framework in C++, defining the shapes family and area, perimeter, and angle operations. We benchmark our code in the same manner as our object algebra implementation: we generate 1000000 1000000 1000000 random shapes and then perform all three operations for each shape. For this experiment, we have three different implementations: a standard object oriented implementation, an inextensible visitor framework implementation, and an extensible visitor framework implementation. The inextensible visitor framework supports the addition of new operations, but does not have the object oriented programming bells and whistles needed to support additional types. Our implementations follow the outline provided in Bendersky 2016.
我们在 C++ 中实现了访问者框架,定义了形状家族以及面积、周长和角度计算操作。我们采用与对象代数实现相同的方式进行基准测试:生成 1000000 1000000 1000000 个随机形状,然后对每个形状执行所有三种操作。在本实验中,我们有三种不同的实现:标准的面向对象实现、不可扩展的访问者框架实现和可扩展的访问者框架实现。不可扩展的访问者框架支持添加新操作,但缺乏支持新类型所需的面向对象编程的额外特性。我们的实现遵循了Bendersky 2016中提供的框架。
We first provide our qualitative evaluation of the visitor framework. The visitor framework does seem to be more cumbersome to implement than standard object oriented programming, as it is also more counterintuitive (in our opinions) than the object algebras framework. However, because it is also more object-oriented than the object algebras framework, it avoided the problem with the object algebras framework discussed earlier. In particular, we did not need to call several different functions everytime we created a new shape. We instead could create a single Shape object each time, and when actually performing computations, call shape -> Accept(areavisitor), etc. This gave a minor ease-of-implementation advantage over object algebras.
首先,我们对访问者框架进行定性评估。访问者框架的实现似乎比标准的面向对象编程更繁琐,而且在我们看来,它也比对象代数框架更违反直觉。然而,由于它比对象代数框架更具面向对象特性,因此避免了前面讨论的对象代数框架存在的问题。具体而言,我们无需在每次创建新形状时调用多个不同的函数。相反,每次我们都可以创建一个单一的 Shape 对象,在实际执行计算时,调用 shape -> Accept(areavisitor) 等方法即可。这使得访问者框架相比对象代数在实现便捷性上具有轻微优势。
Quantitatively, we found that the visitor pattern performed worse than standard object oriented programming in terms of runtime. Again, we attribute this to increased overhead because the visitor pattern requires us to pass more objects around, thus requiring more operations.
定量分析方面,我们发现访问者模式在运行时性能上不如标准的面向对象编程。同样,我们将这归因于开销的增加,因为访问者模式需要传递更多的对象,从而导致更多的操作。
| Object Oriented | Inextensible Visitor | Extensible Visitor | |
|---|---|---|---|
| Runtime (seconds) | 0.142 | 0.211 | 0.301 |
Fig. 2 : We show the average runtime, in seconds, of our shapes benchmark for the object oriented and visitor pattern implementations. Times are averaged over 10 trials in order to reduce variance.
图 2:展示了面向对象和访问者模式实现的形状基准测试平均运行时间(以秒为单位)。为减少方差,时间取 10 次试验的平均值。
4 TYPE CLASSES
4 类型类
Type classes are a very lightweight solution to the expression problem in statically typed languages. The specific case study we consider is implementing polymorphic variants in OCaml, a functional language. We follow a solution outlined in Kalmbach 2016.
类型类是静态类型语言中解决表达式问题的一种非常轻量级的方案。我们考虑的具体案例研究是在函数式语言 OCaml 中实现多态变体。我们遵循了Kalmbach 2016中概述的解决方案。
Recall that the difficulty described by the expression problem in functional languages is that when we try to add an additional class, we cannot modify existing functions to handle this new case. A simple work-around would look as follows: suppose we have an interface type Shape defined as type shape = Triangle of float | Square of float and a function area which takes a Shape (by the existing definition), and handles the Triangle and Square cases separately. Now we want to add a new type of Shape, namely a Hexagon, and modify area appropriately to handle it. To do so, we would like to make a new method new_area which takes type: Shape | Hexagon, and has two cases: if the input to new_area is a Shape by the old definition, then we just call the old method on the input; otherwise, we handle the Hexagon case separately. This sort of wrapper framework is also extremely analogous to the visitor framework in object-oriented programming.
回想一下,函数式语言中表达式问题所描述的难点在于,当我们尝试添加一个新类时,无法修改现有函数来处理这个新情况。一个简单的变通方法如下:假设我们有一个接口类型 Shape,定义为 type shape = Triangle of float | Square of float,还有一个函数 area,它接收一个(根据现有定义的)Shape,并分别处理 Triangle 和 Square 情况。现在我们想要添加一种新的 Shape 类型,即 Hexagon,并相应地修改 area 以处理它。为此,我们可以创建一个新方法 new_area,其接收的类型为 Shape | Hexagon,并包含两种情况:如果 new_area 的输入是旧定义的 Shape,则直接调用旧方法处理该输入;否则,单独处理 Hexagon 情况。这种包装器框架与面向对象编程中的访问者框架也极为相似。
Type classes essentially formalize this idea of extendible types. More specifically, in OCaml this is done by defining Shape as a polymorphic variant, with type shape = ['Triangle of float | 'Square of float]. Any method which takes in a Shape as an argument technically has the type [> 'Triangle of float | 'Square of float], which means a type larger than that of our pre-defined Shape. Thus, we are able to retroactively add classes and define new functions to support them, which take in this "larger type" as input. For example, we could write let new_area s = match s with shape as x -> area x | 'Hexagon len -> 6.0 *. len *. len *. (sqrt 3.0) /. 4.0.
类型类本质上是将这种可扩展类型的思想形式化。更具体地说,在 OCaml 中,这是通过将 Shape 定义为多态变体来实现的,即 type shape = ['Triangle of float | 'Square of float]。从技术上讲,任何接收 Shape 作为参数的方法都具有类型 [> 'Triangle of float | 'Square of float],这意味着该类型是比我们预定义的 Shape 更大的类型。因此,我们能够回溯性地添加类,并定义新函数来支持它们,这些新函数接收这种"更大的类型"作为输入。例如,我们可以编写 let new_area s = match s with shape as x -> area x | 'Hexagon len -> 6.0 *. len *. len *. (sqrt 3.0) /. 4.0(六边形面积公式)。
Qualitatively, type classes are very lightweight, and essentially do a minimal amount of work, with the polymorphic variant handling all of the typing interpretation. However, there are a few difficulties with this solution. As with all variations of the "wrapper" framework of solutions, it can become quite difficult to carry around a new copy of every function every time we add a class. Furthermore, type safety is somewhat sacrificed, and the inelegant workaround to this consists of annotating every function declaration with types, which can get complicated. A more concise compromise in OCaml is the extensible variant type, where we can formally modify the type Shape to include the Hexagon case, with type shape = .. and type shape += Hexagon of float.
定性分析表明,类型类非常轻量级,本质上只需执行最少的工作,所有的类型解释都由多态变体处理。然而,该解决方案存在一些难点。与所有"包装器"框架的变体一样,每次添加一个类时,都需要携带每个函数的新副本,这会变得相当困难。此外,类型安全性在一定程度上受到了牺牲,而解决这一问题的非优雅变通方法是为每个函数声明添加类型注解,这可能会变得很复杂。在 OCaml 中,一种更简洁的折中方案是可扩展变体类型,我们可以通过 type shape = .. 和 type shape += Hexagon of float 来正式修改 Shape 类型,将 Hexagon 情况包含进来。
Quantitatively, we observed a slight performance hit in our simple example, but we think the performance hit due to overhead will likely be larger the more class extensions there are that need to be supported. We compare an implementation using polymorphic variants with a baseline, which simply declares all the classes and functions in one go and does not support retroactive modification. We attribute the overhead to having to follow different pointers to old functions in the new function definitions.
定量分析方面,在我们的简单示例中,我们观察到了轻微的性能下降,但我们认为,需要支持的类扩展越多,由于开销导致的性能下降可能会越大。我们将使用多态变体的实现与一个基准实现进行了对比,该基准实现一次性声明所有类和函数,不支持回溯修改。我们将开销归因于在新函数定义中必须跟随指向旧函数的不同指针。
| Polymorphic Variants | Baseline | |
|---|---|---|
| Runtime (seconds) | 0.977 | 0.861 |
Fig. 3 : We show the average runtime, in seconds, of our shapes benchmark for both the baseline and polymorphic variants implementations. Times are averaged over 20 trials in order to reduce variance.
图 3:展示了基准实现和多态变体实现的形状基准测试平均运行时间(以秒为单位)。为减少方差,时间取 20 次试验的平均值。
5 MULTIMETHODS
5 多方法
Up to this point, solutions we have discussed have followed a fairly similar skeleton: they roughly consist of creating new functions which case on input to call the existing function, or handle new cases, in order to support adding new object classes. This begs the question: what if we relax the problem setting by allowing functions to retroactively be modified by cases? In particular, it would be most convenient if we were able to define some function, say defmulti area class, where class can be cased on retroactively. In a functional programming language, this maintains the feature that adding new functions is simple, but furthermore it lends itself to the easy adding of classes.
到目前为止,我们讨论的解决方案都遵循一个相当相似的框架:为了支持添加新的对象类,它们大致都包括创建新函数,这些新函数根据输入情况调用现有函数或处理新情况。这就引出了一个问题:如果我们放宽问题设定,允许通过案例回溯修改函数,会怎么样?特别是,如果我们能够定义某个函数,例如 defmulti area class,其中 class 可以被回溯性地匹配案例,那将是最方便的。在函数式编程语言中,这既保留了添加新函数简单的特性,又使得添加类变得容易。
The case study we consider here is multimethods in Clojure which are a simple feature of the language. Here, we follow a solution outlined in Bendersky 2016. The primary feature which is exploited here is the fact that we can define "open methods", in other words first class methods which are allowed to act on existing and newly-defined types.
我们这里考虑的案例研究是 Clojure 中的多方法,这是该语言的一个简单特性。我们遵循了Bendersky 2016中概述的解决方案。这里利用的主要特性是,我们可以定义"开放方法",换句话说,就是允许作用于现有类型和新定义类型的一等方法。
To give a simple example of how straightforward this solution is in practice, we describe how we implemented area as a multimethod over shapes. We define the method via (defmulti area class) as described above, and define cases on existing classes to the method via (defmethod area Square [s] (* (:length s) (:length s))). If we retroactively define a new class, say (defrecord Hexagon [length]), we are able to modify the casing with (defmethod area Hexagon [h] (* 2.598 (* (:length h) (:length h)))) (注: 2.598 ≈ 3 3 2 2.598 \approx \frac{3\sqrt{3}}{2} 2.598≈233 ,为正六边形面积系数)。
为了简单展示该解决方案在实际应用中的便捷性,我们描述一下如何将 area 实现为形状上的多方法。如上所述,我们通过 (defmulti area class) 定义该方法,并通过 (defmethod area Square [s] (* (:length s) (:length s))) 为现有类定义案例。如果我们回溯性地定义一个新类,例如 (defrecord Hexagon [length]),我们可以通过 (defmethod area Hexagon [h] (* 2.598 (* (:length h) (:length h)))) 修改匹配案例(注: 2.598 ≈ 3 3 2 2.598 \approx \frac{3\sqrt{3}}{2} 2.598≈233 ,为正六边形面积系数)。
Qualitatively, this is definitely the simplest solution to the expression problem we encountered -- implementing it requires essentially no additional work other than declaring that the method in question is a multimethod! This is likely a situation that the makers of Clojure considered in defining the expressibility of the language, and is an advantage to the way it was designed.
定性分析表明,这无疑是我们遇到的最简单的表达式问题解决方案------实现它基本上不需要额外的工作,只需声明相关方法是一个多方法即可!这很可能是 Clojure 的设计者在定义该语言的表达能力时所考虑的情况,也是其设计方式的一个优势。
Quantitatively, the implementation via multimethods vs. a simple baseline (writing separate functions and hardcoding cases to existing classes) had a slight performance drop, but it is not extremely significant, and is likely due to a slight overhead due to the implicit casing of the method definition vs. the explicit casing defined within the method in the baseline.
定量分析方面,与简单的基准实现(编写独立函数并为现有类硬编码案例)相比,多方法实现存在轻微的性能下降,但并不十分显著。这可能是由于方法定义中的隐式案例匹配相比基准实现中方法内的显式案例匹配存在轻微的开销。
| Multimethods | Baseline | |
|---|---|---|
| Runtime (seconds) | 3.935 | 3.680 |
Fig. 4 : We show the average runtime, in seconds, of our shapes benchmark for both the baseline and multimethods implementations. Times are averaged over 20 trials in order to reduce variance.
图 4:展示了基准实现和多方法实现的形状基准测试平均运行时间(以秒为单位)。为减少方差,时间取 20 次试验的平均值。
6 CONCLUSIONS AND DISCUSSION
6 结论与讨论
We analyzed existing solutions to the expressivity problem, which arises in both functional and object oriented programming languages. We implement and benchmark four solutions to the expressivity problem: object algebras, the visitor framework, type classes, and multimethods. Each of these methods cleanly solve the expressivity problem; however, they all present their own tradeoffs too in aspects such as runtime, ease of use, and type safety. We provide a detailed analysis of the tradeoffs involved for each of these solutions to the expressivity problem in our paper.
我们分析了函数式和面向对象编程语言中出现的表达式问题的现有解决方案。我们实现并基准测试了四种表达式问题解决方案:对象代数、访问者框架、类型类和多方法。这些方法都能干净利落地解决表达式问题;然而,它们在运行时性能、易用性和类型安全性等方面也都存在各自的权衡取舍。本文对这些解决方案所涉及的权衡取舍进行了详细分析。
We would like to note that all of these solutions to the expressivity problem are variants of the same core idea. Namely, the idea is that to extend functional programming to allow the addition of types, we can extend our functions so that they behave the original way when given types that were already defined and also accommodate the newly added types. Object oriented languages implement this idea by essentially "inverting" to become more functional and then extending the classes which define this functional behavior. Functional programming languages implement this idea in a more direct manner.
我们需要指出的是,所有这些表达式问题的解决方案都是同一核心思想的变体。也就是说,为了扩展函数式编程以允许添加类型,我们可以扩展函数,使它们在接收已定义类型时表现出原有的行为,同时也能适配新添加的类型。面向对象语言通过本质上"反转"为更具函数式特性,然后扩展定义这种函数式行为的类,来实现这一思想。函数式编程语言则以更直接的方式实现这一思想。
To close, we note that all of these solutions work using the functional viewpoint of programming languages - is there a corresponding object oriented solution? This natural question arises from the realization that the first 3 solutions discussed in this paper all follow a very similar skeleton, where if we want to retroactively modify some function f o l d f_{old} fold to case on some class c n e w c_{new} cnew, it suffices to define a "wrapper function" f n e w f_{new} fnew which has two branches: if the input is of type c n e w c_{new} cnew, define the case within the function body of f n e w f_{new} fnew; otherwise, simply call f o l d f_{old} fold with the same input. For functional programming languages, this is a natural solution, but its relationship to the visitor framework feels unnatural, in the sense that it is an extension to functions despite the visitor framework working on objected-oriented languages.
最后,我们注意到所有这些解决方案都是从编程语言的函数式视角出发的------是否存在相应的面向对象解决方案?这个自然的问题源于一个发现:本文讨论的前三种解决方案都遵循一个非常相似的框架,即如果我们想要回溯性地修改某个函数 f o l d f_{old} fold 以匹配某个类 c n e w c_{new} cnew,只需定义一个"包装函数" f n e w f_{new} fnew,该函数包含两个分支:如果输入是 c n e w c_{new} cnew 类型,则在 f n e w f_{new} fnew 的函数体中定义该案例的处理逻辑;否则,只需将相同的输入传递给 f o l d f_{old} fold 调用即可。对于函数式编程语言来说,这是一种自然的解决方案,但它与访问者框架的关联却显得不自然------尽管访问者框架适用于面向对象语言,但它本质上是对函数的扩展。
To reconcile this inconsistency, we propose the following alternative solution for object-oriented languages, which can be viewed as dual to the solutions discussed in this paper. Suppose we are in an object-oriented framework and we have some class c o l d c_{old} cold which we wish to retroactively modify to support some new function f n e w f_{new} fnew. Then, we posit that it suffices to define a new class c n e w c_{new} cnew which contains an instance of c o l d c_{old} cold as a field, and also a definition for f n e w f_{new} fnew applied in the desired way. In this way, it also supports all previously defined methods without reusing existing code, by simply passing them the computation to the corresponding instance of c o l d c_{old} cold. While it is a simple reversal of several existing solutions, we did not encounter this type of solution in our literature review, and think it may be independently interesting. We hypothesize that it is possible that more overhead is incurred while "layering classes" instead of "layering methods", but it would be interesting to evaluate this type of solution systematically in future work.
为了调和这种不一致性,我们为面向对象语言提出了以下替代解决方案,该方案可被视为本文讨论的解决方案的对偶方案。假设我们处于面向对象框架中,有一个类 c o l d c_{old} cold,我们希望回溯性地修改它以支持某个新函数 f n e w f_{new} fnew。那么,我们认为只需定义一个新类 c n e w c_{new} cnew,该类包含一个 c o l d c_{old} cold 的实例作为字段,并以期望的方式定义 f n e w f_{new} fnew。通过这种方式,新类 c n e w c_{new} cnew 无需复用现有代码即可支持所有先前定义的方法,只需将这些方法的计算任务传递给对应的 c o l d c_{old} cold 实例即可。尽管这只是对现有几种解决方案的简单反转,但我们在文献综述中并未遇到此类解决方案,并且认为它可能具有独立的研究价值。我们推测,与"分层方法"相比,"分层类"可能会产生更多的开销,但未来的工作中对这类解决方案进行系统评估将是一件有趣的事情。
Equal work was performed by both project members.
两位项目成员贡献均等。
ACKNOWLEDGMENTS
致谢
The authors would like to thank Varun and Will for being homies.
作者感谢 Varun 和 Will 两位好友的支持与帮助。
REFERENCES
参考文献
Eli Bendersky. 2016. The Expression Problem and Its Solutions. https://eli.thegreenplace.net/2016/the-expression-problem-and-its-solutions/. (2016).
伊莱·本德斯基. 2016. 表达式问题及其解决方案. https://eli.thegreenplace.net/2016/the-expression-problem-and-its-solutions/. (2016).
Antoine Kalmbach. 2016. The expression problem as a litmus test. http://ane.github.io/2016/01/08/the-expression-problem-as-a-litmus-test.html/. (2016).
安托万·卡尔姆巴赫. 2016. 作为试金石的表达式问题. http://ane.github.io/2016/01/08/the-expression-problem-as-a-litmus-test.html/. (2016).
Shriram Krishnamurthi, Matthias Felleisen, and Daniel P Friedman. 1998. Synthesizing object-oriented and functional design to promote re-use. In European Conference on Object-Oriented Programming. Springer, 91--113.
希拉姆·克里希纳穆尔蒂、马蒂亚斯·费莱森、丹尼尔·P·弗里德曼. 1998. 融合面向对象与函数式设计以促进复用. 见《欧洲面向对象编程会议论文集》. 施普林格出版社, 91-113.
Bruno C d S Oliveira and William R Cook. 2012. Extensibility for the Masses. In European Conference on Object-Oriented Programming. Springer, 2--27.
布鲁诺·C·d·S·奥利维拉、威廉·R·库克. 2012. 面向大众的可扩展性. 见《欧洲面向对象编程会议论文集》. 施普林格出版社, 2-27.
- Expression Problem | 起源、约束及跨范式解决-CSDN博客
https://blog.csdn.net/u013669912/article/details/157069531
via:
-
The Expression Problem and its solutions - 2016
https://eli.thegreenplace.net/2016/the-expression-problem-and-its-solutions/ -
On the Composite and Interpreter design patterns - 2016
https://eli.thegreenplace.net/2016/on-the-composite-and-interpreter-design-patterns -
More thoughts on the Expression Problem in Haskell - 2018
https://eli.thegreenplace.net/2018/more-thoughts-on-the-expression-problem-in-haskell/ -
An Analysis and Discussion of Solutions to the Expression Problem Across Programming Languages - kjtian-colinwei.pdf
https://stanford-cs242.github.io/f17/assets/projects/2017/kjtian-colinwei.pdf
-
Solving the Expression Problem | Rapid7 Blog
https://www.rapid7.com/blog/post/2016/12/07/solving-the-expression-problem/ -
The Expression Problem, Trivially! - Modularity2016.pdf
https://i.cs.hku.hk/~bruno/papers/Modularity2016.pdf