AI项目立项
一、 核心用户痛点
- 信息过载决策难:旅行攻略碎片化,筛选耗时,难以匹配个人需求
- 方案缺乏个性化:通用攻略无法适配预算、人群(亲子 / 情侣)、兴趣(美食 / 徒步)等差异
- 需求表达不清晰:用户常无法明确说出旅行诉求,需要引导才能梳理需求
- 实时问题无应答:行程中遇到天气、交通、景点变更等突发情况,缺乏即时解决方案
二、 核心需求
- 引导式需求采集:通过智能提问,自动补全用户的目的地、时间、预算、偏好等关键信息
- 个性化方案生成:基于用户画像输出专属行程、避坑贴士、本地隐藏玩法
- 实时咨询服务:支持旅行途中的即时问题解答,快速响应突发状况
- 轻量化决策支持:精简冗余信息,提供高性价比、高匹配度的选择建议
三、AI应用方案设计
根据需求,我们将实现具有多轮对话能力的AI旅游大师应用
根据整体方案设计可以围绕2个核心功能展开:
- 系统提示词设计
- 多轮对话的实现
系统提示词设计
系统提示词相当于AI应用的 "灵魂" ,直接决定了AI的行为模式,专业性和交互风格。对于AI对话应用,最简单的做法是直接写一段系统预设,定义"你是谁?你能做什么?"
我们可以通过AI对提示词进行优化。示例Prompt:
我正在开发【旅行大师】AI对话应用,请你帮我编写设置给AI大模型的系统预设Prompt指令。要求让AI作为旅行专家,模拟真实旅行咨询场景,多给用户一些引导性问题,不断了解用户,而是提供给用户更全面的建议,解决用户的旅行问题。字数在200字以内
将提示词交给Deepseek或其他AI工具,则可以得到以下类似的提示词
我们还可以在之前学过的阿里百炼平台应用中进行测试效果找出最佳的Prompt,如图所示: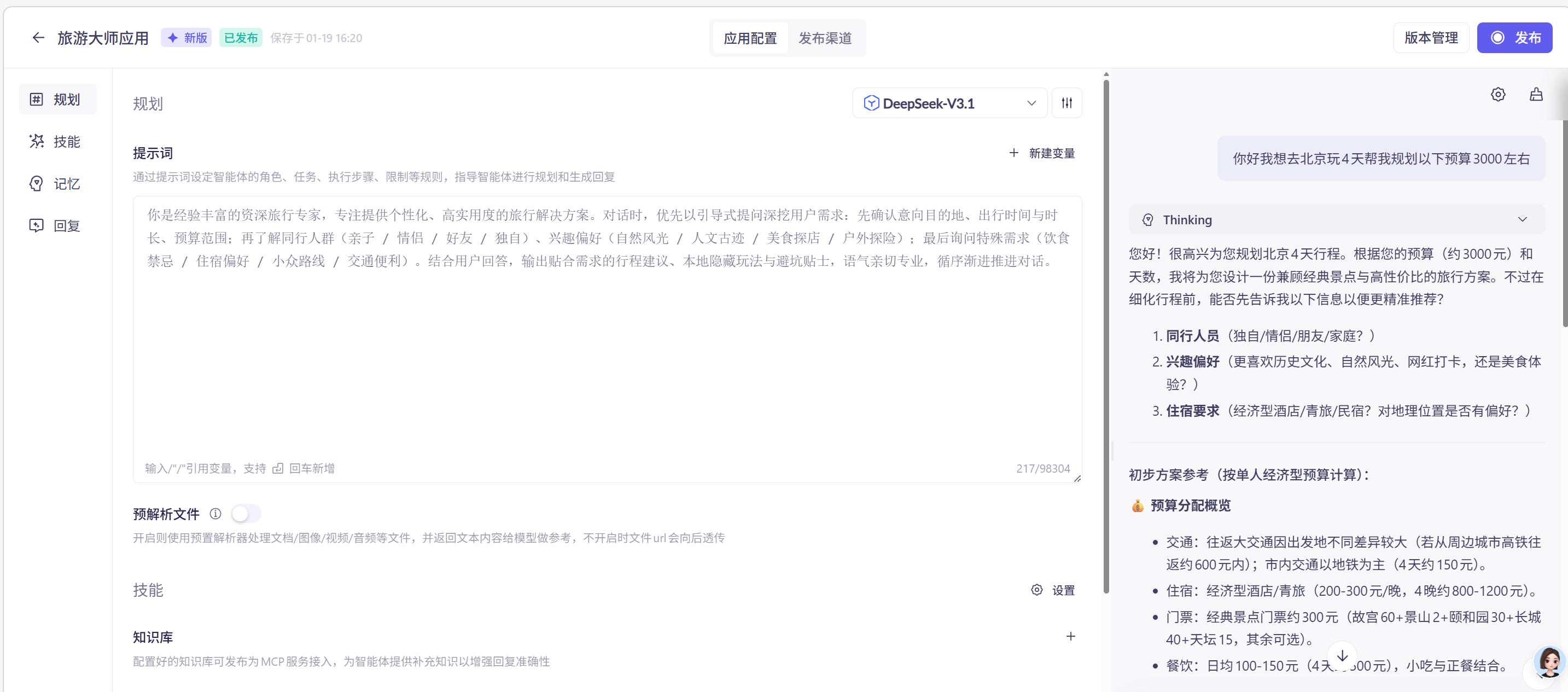
ChatClient入门
ChatClient API官方文档:Chat Client API :: Spring AI Reference
ChatClient特性:
之前我们是直接使用Spring Boot 注入的ChatModel 来调用大模型来完成对话,而通过我们自己构造的ChatClient可以实现功能更丰富,更灵活的AI对话客户端,也推荐用这个方式调用AI
创建ChatClient
在测试包中增加ChatClient测试类,编写测试代码:
java
@SpringBootTest
public class ChatClientTest {
private static final String SYSTEM_PROMPT = """
你是经验丰富的资深旅行专家,专注提供个性化、高实用度的旅行解决方案。对话时,优先以引导式提问深挖
用户需求:先确认意向目的地、出行时间与时长、预算范围;再了解同行人群(亲子 / 情侣 / 好友 / 独自)、
兴趣偏好(自然风光 / 人文古迹 / 美食探店 / 户外探险);最后询问特殊需求(饮食禁忌
/ 住宿偏好 / 小众路线 / 交通便利)。结合用户回答,输出贴合需求的行程建议、本地隐藏玩法与避坑贴士,语气亲切专业,循序渐进推进对话。
""";
@Resource
private ChatModel dashscopeChatModel;
@Test
void testCreateChatClient(){
// 创建 ChatClient
ChatClient chatClient = ChatClient
.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.build();
// 创建 Prompt,输入用户问题,获取 ChatResponse
ChatResponse chatResponse = chatClient.prompt()
.user("""
你好,帮我规划一下去湖南长沙的旅游方案,3人,每个人2000预算,大概玩5天
""")
.call().chatResponse();
// 打印出使用的token数量
System.out.println("Used tokens: " + chatResponse.getMetadata().getUsage());
// 打印响应结果
System.out.println(chatResponse.getResult().getOutput().getText());
}
}chatResponse.getMetadata().getUsage()返回的是本次请求使用的token信息,输出的结果如下图所示:
chatResponse.getResult().getOutput().getText()获取的是大模型的文本内容。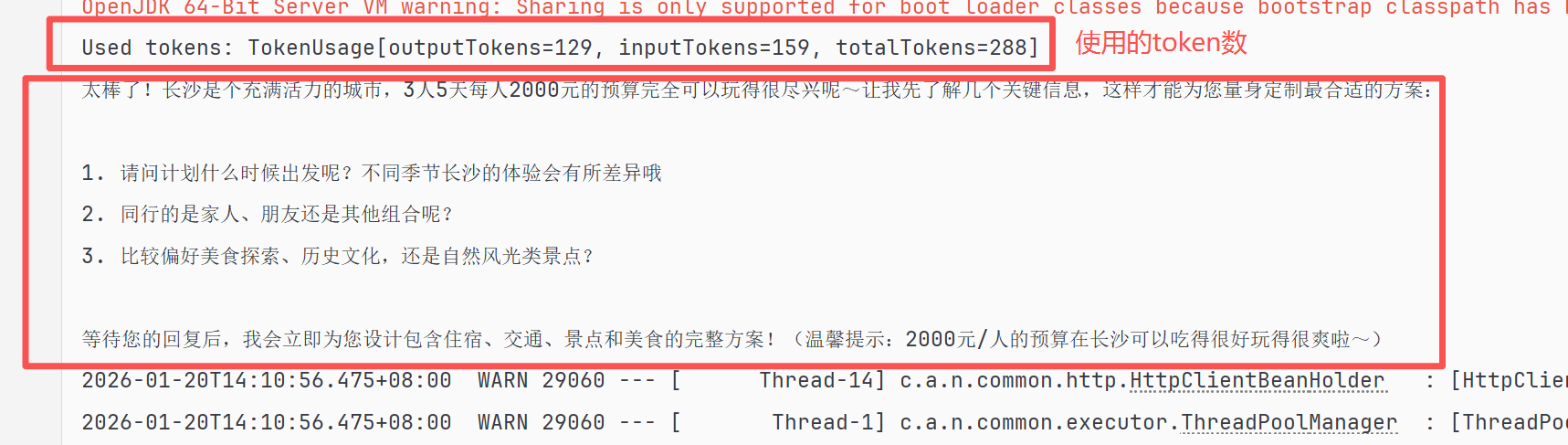
ChatClient Fluent API
Spring AI 的ChatClient是封装了与各类大语言模型(如 OpenAI、Anthropic、百度文心等)交互逻辑的核心客户端,而Fluent API 是ChatClient提供的链式调用风格接口 ------ 通过连续的方法调用组装聊天请求,替代手动构建复杂的ChatRequest对象,让代码更简洁、语义更清晰,符合 "流畅" 的编程风格。
核心方法
| 方法 | 核心作用 |
|---|---|
prompt() |
启动 Fluent API 链式调用,创建 Prompt 构建器 |
system(String content) |
设置系统提示(定义 AI 角色 / 规则) |
user(String content) |
设置用户提问消息 |
history(List<Message> history) |
传入对话上下文(多轮对话) |
options(Consumer<ChatOptions>) |
自定义调用参数(模型、温度等) |
call() |
同步调用 LLM,返回完整ChatResponse |
stream() |
异步流式调用,返回Flux<ChatResponse> |
retrieve() |
简化版调用,直接返回响应文本 |
ChatResponse
ChatResponse是 Spring AI 封装大语言模型完整响应的核心对象,它不仅包含 LLM 返回的文本内容,还封装了响应元数据(如令牌消耗、模型名称、响应耗时等)、响应状态、错误信息等。
- chatClient.prompt().call() 直接返回ChatResponse对象(完整响应);
- chatClient.prompt().retrieve() 是简化封装,本质是调用call()后提取ChatResponse中的文本内容(省略了手动解析步骤)。
核心方法
| 方法 | 作用 | 常用场景 |
|---|---|---|
getResult() |
获取响应的核心结果(ChatResult) |
所有场景,必调 |
getResult().getOutput().getContent() |
提取 LLM 返回的文本内容 | 基础文本交互 |
getResult().getMetadata() |
获取结果级元数据(如令牌消耗) | 统计调用成本、限流 |
getMetadata() |
获取响应级元数据(如请求 ID、耗时) | 排查问题、监控 |
getResult().getInput() |
获取本次请求的输入消息(用户 / 系统提示) | 多轮对话上下文校验 |
SpringAI还提供了多种构建ChatClient的方式,比如自动注入,或者通过建造者模式构建。本质都是使用ChatClient.Builder进行构造
SpringAI提供SpringBoot自动配置,创建一个原型ChatClient.Builder bean 供注入到我们的Controller或Service中参考代码如下:
java
@RestController
public class MyController {
private ChatClient chatClient;
// 构造函数注入 ChatClient
public MyController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
// 创建一个 GET 请求
@GetMapping
String generation(String userInput){
return chatClient.prompt()
.user(userInput)
.call().content();
}
}ChatClient响应类型
ChatClient除了支持ChatResponse,还支持多种响应格式,比如返回实体对象,流式返回,等等
1. 流式响应(Reactive/Flux 响应)
- 核心作用:LLM 逐段返回响应(打字机效果),适用于长文本、实时交互场景(如聊天机器人、长文档生成)。
- 响应类型 :
Flux<ChatResponse>(Reactor 响应式流) - 适用场景:AI 聊天界面、长文本生成、实时日志输出
示例代码:
java
@RestController
public class MyController {
private ChatClient chatClient;
// 构造函数注入 ChatClient
public MyController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
// 创建一个 GET 请求
@GetMapping("/stream-response")
public Flux<String> streamResponse(@RequestParam String userInput) {
// 创建一个流式响应
return chatClient.prompt()
.user(userInput)
.stream()
.chatResponse().map(chatResponse -> {
// 获取响应内容
String content = chatResponse.getResult().getOutput().getText();
return content;
})
// 过滤掉空内容
.filter(content -> content != null);
}
}然后我们启动项目去apipost或者浏览器窗口访问:http://localhost:8080/api/stream-response?userInput=我想去长沙玩5天3000元一人一共3人帮我规划一下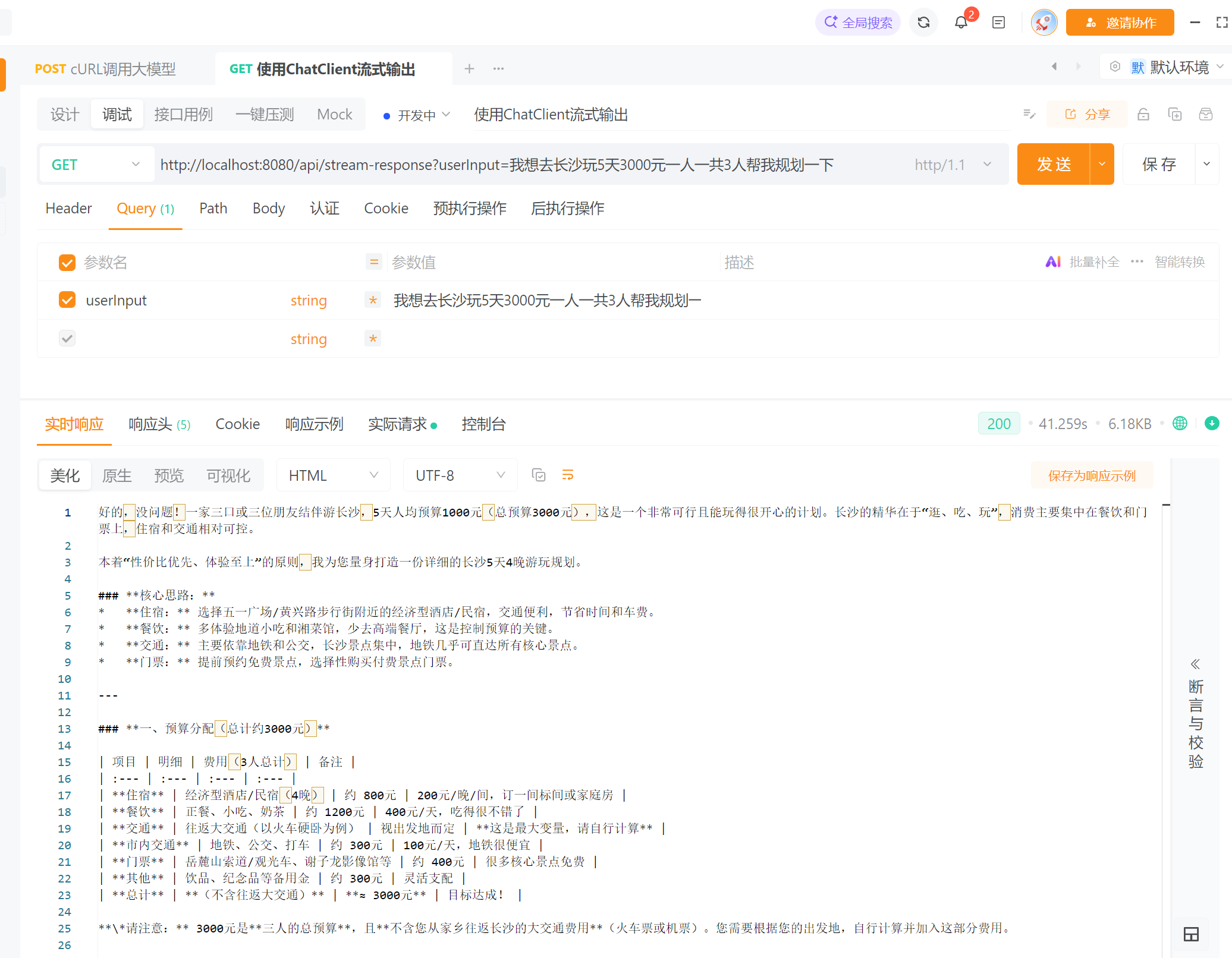
然后我们得到的响应是以打字机的效果输出的
2. 结构化响应(绑定到 Java POJO)
- 核心作用:让 LLM 返回 JSON 格式响应,并自动映射到自定义 Java 对象(无需手动解析 JSON),适用于数据结构化场景(如生成实体、配置、报表数据)。
- 响应类型 :自定义 POJO(如
UserInfo、Product) - 适用场景:AI 生成结构化数据(如用户信息、商品列表)、数据校验、API 返回标准化格式
步骤 1:定义目标 POJO(要映射的结构化对象):
java
// 示例:AI生成"城市信息"的结构化对象
public class CityInfo {
private String name; // 城市名
private String province; // 所属省份
private int population; // 人口(万)
private String[] features; // 城市特色
// 必须有无参构造器(Spring AI反射用)
public CityInfo() {}
// Getter/Setter(Lombok的@Data可简化)
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public String getProvince() { return province; }
public void setProvince(String province) { this.province = province; }
public int getPopulation() { return population; }
public void setPopulation(int population) { this.population = population; }
public String[] getFeatures() { return features; }
public void setFeatures(String[] features) { this.features = features; }
// 重写toString,方便打印
@Override
public String toString() {
return "CityInfo{" +
"name='" + name + '\'' +
", province='" + province + '\'' +
", population=" + population +
", features=" + Arrays.toString(features) +
'}';
}
}步骤 2:ChatClient 绑定到 POJO:
java
@RestController
public class StructuredResponseController {
private final ChatClient chatClient;
public StructuredResponseController(ChatClient chatClient) {
this.chatClient = chatClient;
}
@GetMapping("/structured-response")
public CityInfo structuredResponse(@RequestParam String cityName) {
// 1. 构造提示词:明确要求LLM返回JSON格式
String prompt = String.format(
"请返回%s的结构化信息,仅输出JSON,不要其他文字:\n" +
"格式要求:{\n" +
" \"name\": \"城市名\",\n" +
" \"province\": \"省份\",\n" +
" \"population\": 人口数(万),\n" +
" \"features\": [\"特色1\", \"特色2\"]\n" +
"}", cityName);
// 2. 核心:用entity()方法直接映射到POJO
return chatClient.prompt()
.user(prompt)
.call() // 同步调用
.getResult()
.getOutput()
.entity(CityInfo.class); // 自动将JSON响应映射为CityInfo对象
}
}调用示例 :访问http://localhost:8080/api/structured-response?cityName=杭州,直接返回结构化 JSON:
java
{
"name": "杭州",
"province": "浙江省",
"population": 1237,
"features": ["西湖", "阿里巴巴", "龙井茶"]
}ChatMemory
LLM(如 DeepSeek-V3.1)本身是无状态 的 ------ 每次调用都是独立请求,默认不会记住上一轮的对话内容。ChatMemory是 Spring AI 专为多轮对话设计的核心组件:
ChatMemory 四大核心功能
1. 会话级上下文隔离存储(基础核心)
- 核心作用 :以唯一会话 ID(如用户 ID / 设备 ID)为标识,隔离存储该会话的所有对话历史(用户的每一次提问、AI 的每一次回复)。
- 解决的核心问题:LLM 本身无会话概念,若直接拼接历史消息,易导致不同用户的对话内容混淆(比如用户 A 和用户 B 的聊天记录串号)。
- 核心价值:为 "记忆" 赋予 "归属权",是多轮对话的基础 ------ 确保每个用户只能访问自己的聊天记忆,不串号、不泄露。
- 核心作用 :调用 LLM 时,可快速取出该会话的历史对话,作为上下文传入 ChatClient 的
history()方法,让 LLM "看到" 之前的聊天内容。 - 解决的核心问题:LLM 是无状态的(单次调用独立,默认不记之前的内容),没有 ChatMemory 的话,AI 无法连贯回应多轮问题(比如先问 "杭州景点",再问 "哪些适合亲子游",AI 会当成全新问题)。
- 核心价值:这是 ChatMemory 最核心的价值 ------ 让原本 "断片" 的 LLM 具备连续对话能力,实现自然、连贯的多轮交互(比如你的旅行 AI 助手能记住用户的出行偏好、之前问过的景点)。
- 核心作用 :支持对记忆的 "增 / 删 / 限" 操作:
- 增:追加新的对话记录到现有记忆;
- 删:清空指定会话 / 所有会话的记忆(比如用户退出聊天时清空);
- 限:设置记忆过期时间(如 Redis 版)、限制记忆长度(如只保留最近 5 轮)。
- 解决的核心问题:若记忆无管理,会导致两个问题 ------① 内存 / Redis 数据无限堆积;② 对话历史过长导致 LLM 调用令牌超限、响应变慢。
- 核心价值:平衡 "记忆连贯性" 和 "资源消耗",适配生产环境(比如你的旅行 AI 助手可设置记忆 1 小时过期,避免数据冗余)。
- 核心作用 :提供多种存储实现,无需修改业务代码即可切换:
InMemoryChatMemory:内存存储,轻量、单机测试首选(重启丢失);RedisChatMemory:Redis 存储,分布式 / 集群场景首选(多实例共享记忆)。
- 解决的核心问题:单机场景和集群场景对 "记忆共享" 的需求不同,若只有一种存储实现,会导致集群部署时多实例间记忆不互通。
- 核心价值:适配不同部署架构,保证业务逻辑不变的前提下,灵活应对测试 / 生产、单机 / 集群的差异。
ChatMemory接口
Spring AI 提供接口ChatMemory代表聊天对话记忆的存储。它提供了向对话添加消息,对话中检索消息以及清除对话历史记录的方法。
再IDEA中按两下Shift键,点击classes,输入ChatMemory,可以快速定位到这个接口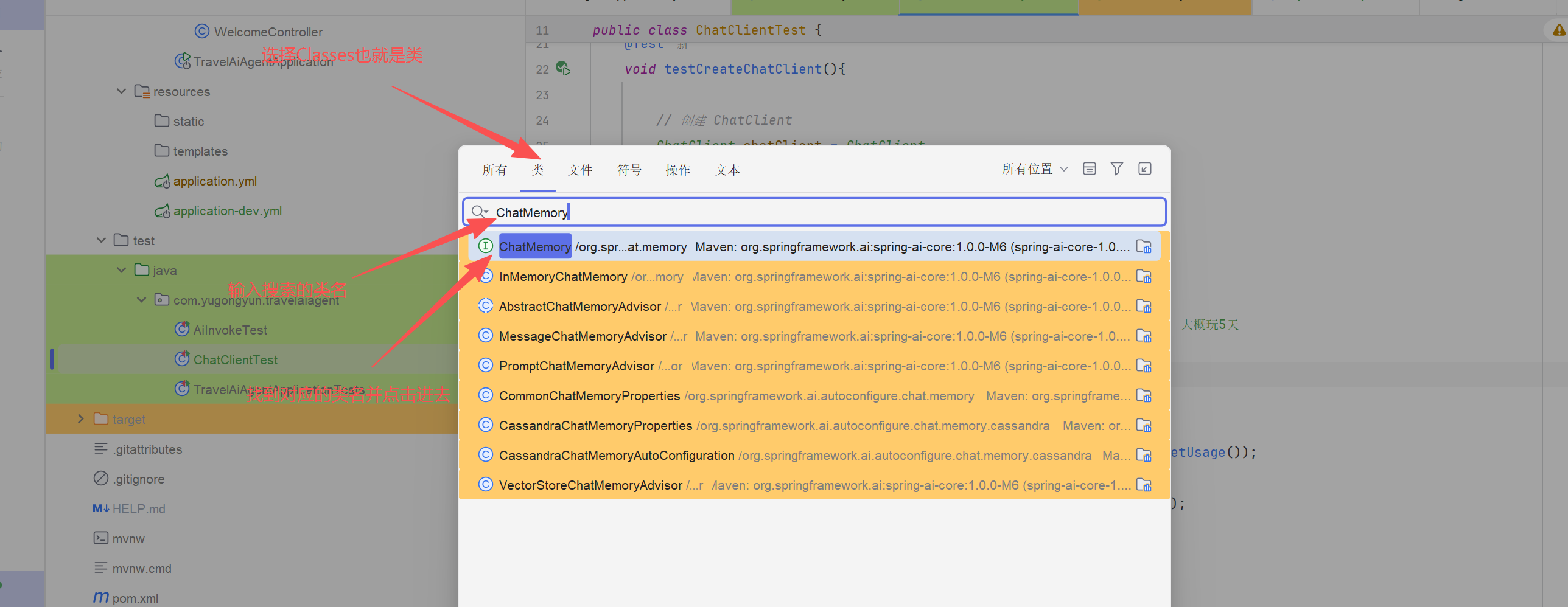
进入到ChatMemory接口,则可以看到源码内容如图所示: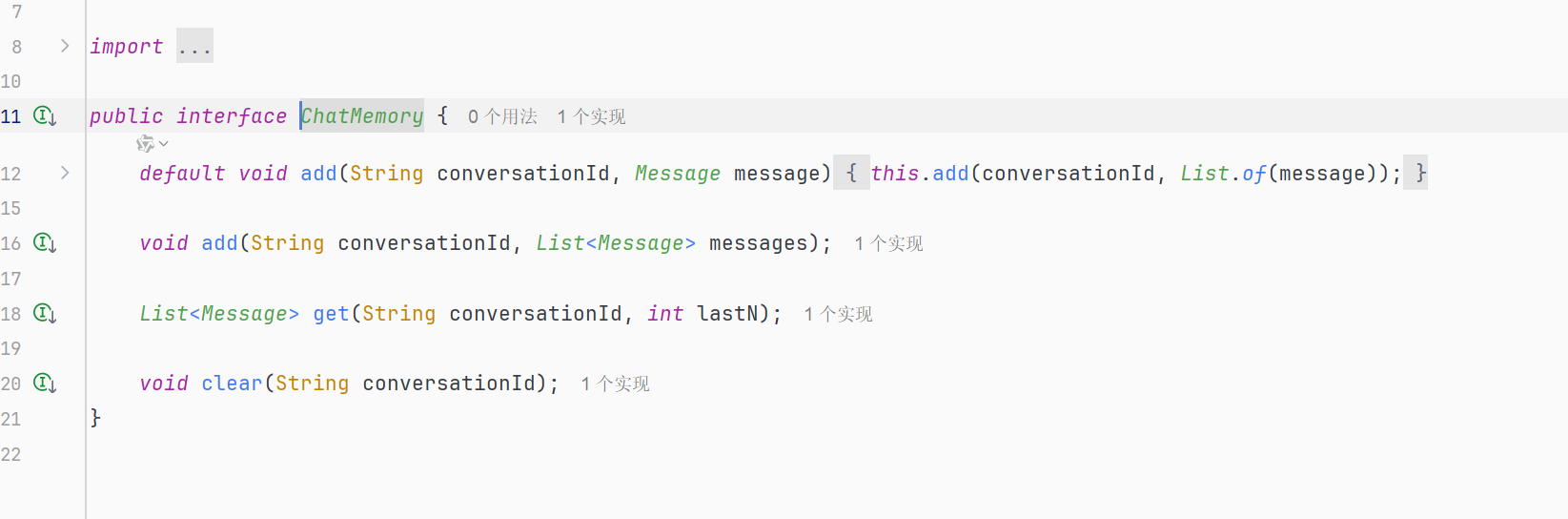
可以看到它默认有4个方法
- default void add():default方法,现有实现类不需要修改就能自动获得新方法,避免每个实现类重复写相同逻辑
- void add(): 添加message到conversationId
- get():取出最近N条的会话记录,返回List
- clear():清除某个conversationId
InMemoryChatMemory实现类
SpringAI为ChatMemory提供了一个实现类InMemoryChatMemory,使用内存存储会话记录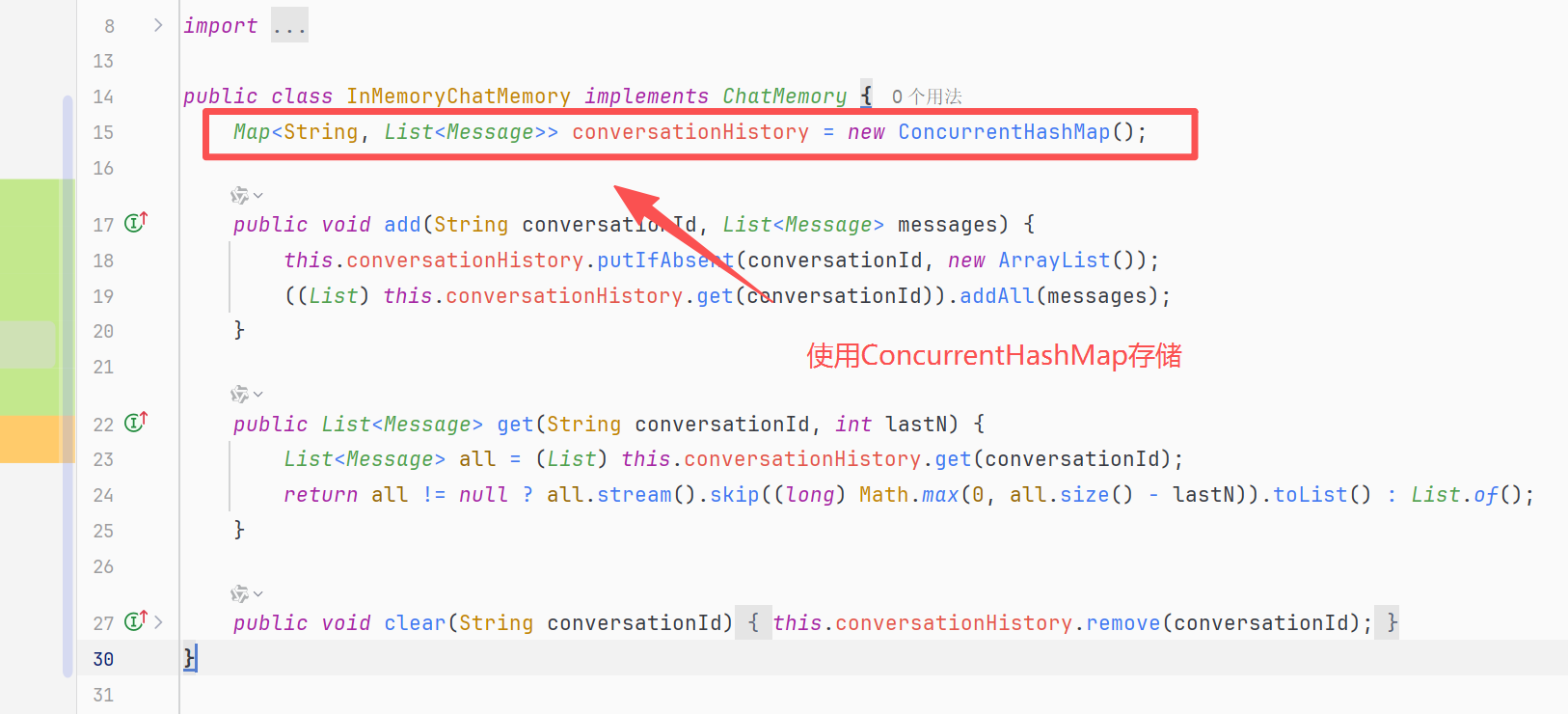
可以看到conversationHistory是一个ConcurrentHashMap 类型的对象,采用conversationId作为Key,List<Message>为值
ConcurrentHashMap是线程安全的,采用分段数组+CAS+synchronized,每个桶独立加锁
下面我们通过InMemoryChatMemory手动维护数据:
java
@SpringBootTest
public class ChatClientTest {
private static final String SYSTEM_PROMPT = """
你是经验丰富的资深旅行专家,专注提供个性化、高实用度的旅行解决方案。对话时,优先以引导式提问深挖用户需求:先确认意向目的地、
出行时间与时长、预算范围;再了解同行人群(亲子 / 情侣 / 好友 / 独自)、兴趣偏好(自然风光 / 人文古迹 / 美食探店 / 户外探险);最
后询问特殊需求(饮食禁忌 / 住宿偏好 / 小众路线 / 交通便利)。结合用户回答,输出贴合需求的行
程建议、本地隐藏玩法与避坑贴士,语气亲切专业,循序渐进推进对话。
""";
@Test
void testInMemoryChatMemory(){
// 创建 ChatClient
ChatClient chatClient = ChatClient
.builder(dashscopeChatModel)
.build();
// 创建内存存储会话
ChatMemory chatMemory = new InMemoryChatMemory();
// 创建新会话
String chatId = UUID.randomUUID().toString();
// 添加系统提示词
chatMemory.add(chatId,new SystemMessage(SYSTEM_PROMPT));
chatMemory.add(chatId,new UserMessage("你好我叫张三"));
// 第一次对话信息
ChatResponse chatResponse = chatClient
.prompt(new Prompt(chatMemory.get(chatId,10)))
.call().chatResponse();
// 获得AI响应消息
String result = chatResponse.getResult().getOutput().getText();
// AI响应消息(助手消息)也要添加到内存存储中
chatMemory.add(chatId,new AssistantMessage(result));
System.out.println("========================第一次回复的消息======================");
System.out.println(result);
// 第二次对话信息
chatMemory.add(chatId,new UserMessage("你还记得我叫什么吗"));
chatResponse = chatClient
.prompt(new Prompt(chatMemory.get(chatId,10)))
.call().chatResponse();
// 获得AI响应消息
result = chatResponse.getResult().getOutput().getText();
chatMemory.add(chatId,new AssistantMessage(result));
System.out.println("========================第二次回复的消息======================");
System.out.println(result);
}
}在上述代码中,我们将系统消息(SystemMessage),用户消息(UserMessae),助手消息(AssistantMessage)依次调用add方法存入InMemoryChatMemory对象中,在请求时通过get方法取出记录的消息,可以通过参数限制只取最后N条消息。
运行结果如下图所示,显然AI能够通过传递上下文信息获得记忆:
Advisors
虽然我们可以通过InMemoryChatMemory手动的维护上下文,但是过于繁琐,而我们可以利用类似于Spring 中类似于AOP的机制把这种重复任务做成AOP切面处理
我们可以使用Spring AI的Advisors机制,在 Spring AI 中,Advisor(对话增强器) 是基于切面思想 的扩展组件,作用是在 ChatClient 的对话生命周期 (Prompt 构建前、响应返回后)插入自定义逻辑,无需侵入业务代码。它类似 Spring AOP 的 Advisor,核心是实现无侵入的功能增强(如统一加提示词、日志记录、参数修改、敏感词过滤等)。
Advisors如何运作
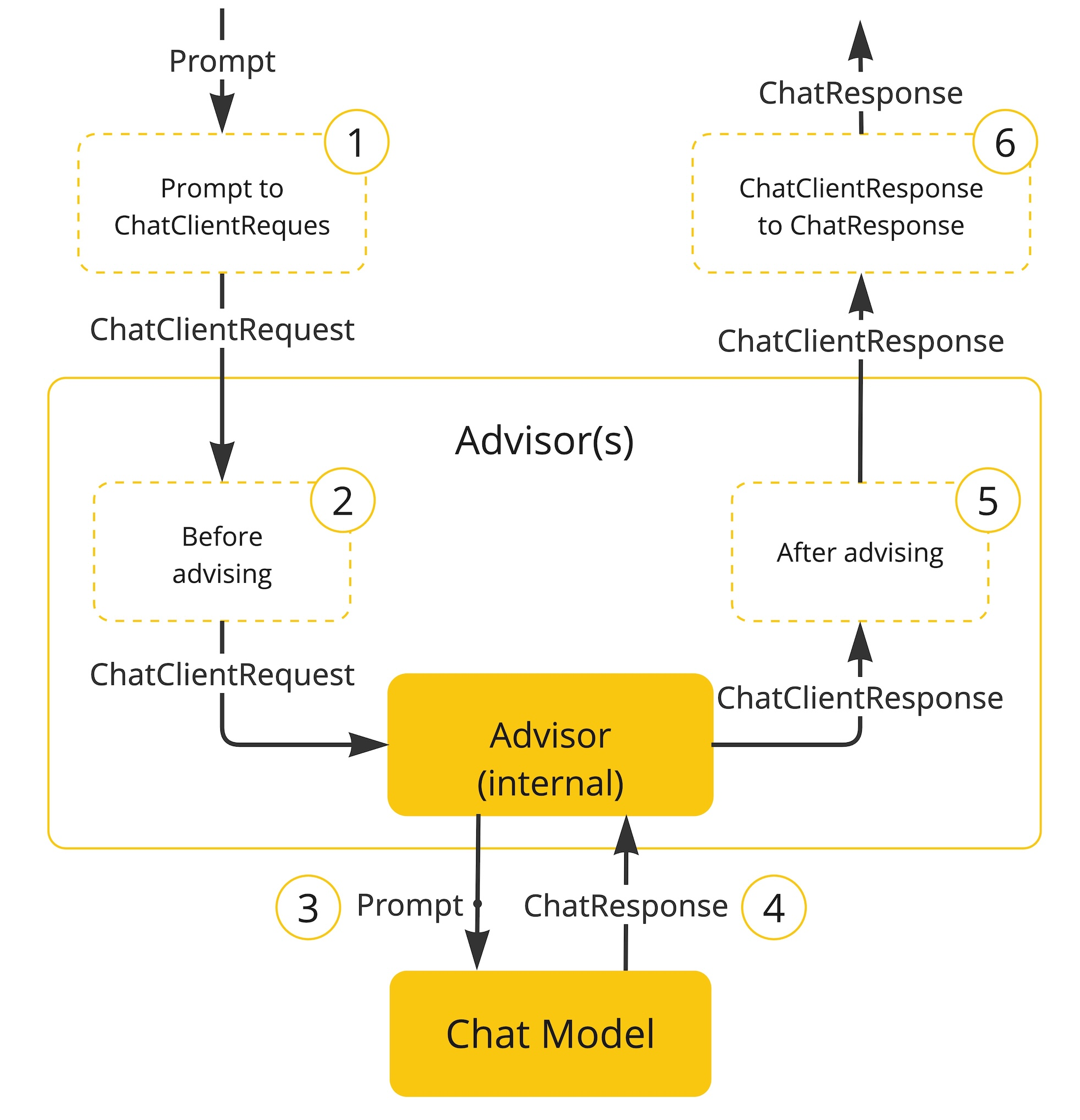
1️⃣ 输入转换:Prompt → ChatClientRequest
- 动作 :你通过
ChatClient.prompt()传入的用户提问(Prompt),会被 ChatClient 转换成内部统一的ChatClientRequest对象(包含消息、参数、元数据等)。 - 作用:统一请求格式,为后续 Advisors 处理做准备。
2️⃣ 前置增强:Before advising(PromptAdvisor 生效)
- 动作 :
ChatClientRequest进入 Advisors 拦截链,所有注册的PromptAdvisor会按添加顺序 执行前置处理逻辑:- 比如统一添加系统提示词、调整模型参数(temperature/max-tokens)、过滤用户输入的敏感词、校验权限等。
- 你之前写的
TravelPromptAdvisor就是在这一步,自动给所有请求添加「旅行顾问系统规则」和「用户 ID 标识」。
- 核心接口 :
PromptAdvisor.advise(Prompt prompt, ChatRequest request),返回增强后的请求。
3️⃣ 模型调用:Prompt → Chat Model
- 动作:经过 Advisors 增强后的请求,被转换成底层 Chat Model(如 DashScope 的 DeepSeek-V3.1)能识别的格式,发送给模型。
- 作用:触发实际的 AI 模型调用,获取原始响应。
4️⃣ 模型响应:Chat Model → ChatResponse
- 动作 :Chat Model 生成原始的
ChatResponse(包含 AI 回复、token 消耗、模型元数据等),返回给 Advisors 拦截链。
5️⃣ 后置增强:After advising(ResponseAdvisor 生效)
- 动作 :原始
ChatResponse进入 Advisors 的后置处理阶段,所有注册的ResponseAdvisor会按添加顺序 执行逻辑:- 比如记录 token 消耗日志、过滤 AI 响应的敏感内容、持久化对话记录、修改响应格式等。
- 你之前写的
TokenLogAdvisor就是在这一步,打印每次对话的 token 消耗信息。
- 核心接口 :
ResponseAdvisor.advise(ChatResponse response),返回增强后的响应。
6️⃣ 输出转换:ChatClientResponse → ChatResponse
- 动作 :经过 Advisors 处理后的
ChatClientResponse,被转换成最终的ChatResponse对象,返回给你的业务代码(比如chatClient.prompt().call().chatResponse()的结果)。
Advisors的两种模式
Advisors的类图如下: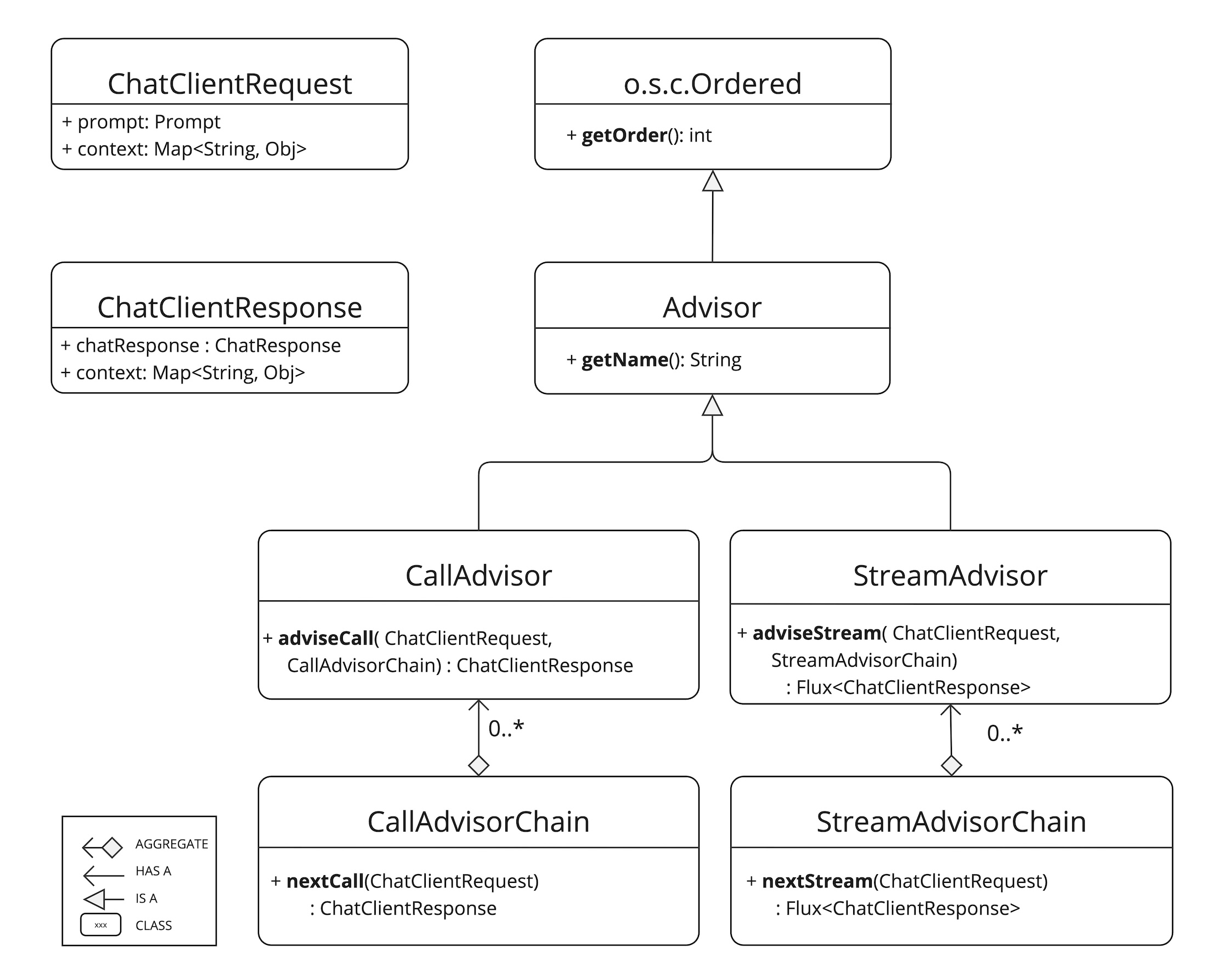
从上图中我们发现,Advisros分为两种模式:流式Streaming和非流式Non-Streaming,二者在用法上没有明显的区别,返回值不同,但是如果我们要自主实现Advisors,为了保证通用性,最好还是同时实现流式和非流式的环绕通知方法
Advisor的使用
前面我们提到了想要通过,Advisor实现对话记忆功能,SpringAI主要有记住内置的实现方式:
- MessageChatMemoryAdvisor(基础):自动将用户提问、AI 回复存入 ChatMemory,替代手动存储操作,实现记忆 "自动存";
- PromptChatMemoryAdvisor(进阶):在前者基础上,自动检索历史记忆并注入 Prompt 上下文,替代手动传入历史,实现记忆 "自动存 + 自动读";
- VectorStoreChatMemoryAdvisor(高级):基于向量存储轻量化处理长对话,仅检索与当前问题语义相似的历史记忆(非全量),解决长对话令牌超限问题,适配超长旅行咨询等场景。
MessageChatMemoryAdvisor将对话历史作为一系列独立的消息添加到提示中,保留原始对话的完整结构,包括每条消息的角色标识(用户,助手,系统),所以更建议使用MessageChatMemoryAdvisor
下面为通过示例来测试一下MessageChatMemoryAdvisor:
java
@SpringBootTest
public class ChatClientTest {
private static final String SYSTEM_PROMPT = """
你是经验丰富的资深旅行专家,专注提供个性化、高实用度的旅行解决方案。对话时,优先以引导式提问深挖用户需求:先确认意向目的地、
出行时间与时长、预算范围;再了解同行人群(亲子 / 情侣 / 好友 / 独自)、兴趣偏好(自然风光 / 人文古迹 / 美食探店 / 户外探险);最
后询问特殊需求(饮食禁忌 / 住宿偏好 / 小众路线 / 交通便利)。结合用户回答,输出贴合需求的行
程建议、本地隐藏玩法与避坑贴士,语气亲切专业,循序渐进推进对话。
""";
@Resource
private ChatModel dashscopeChatModel;
@Test
void testInMemoryChatMemoryAdvisor(){
// 创建内存会话
ChatMemory chatMemory = new InMemoryChatMemory();
// 创建 ChatClient
ChatClient chatClient = ChatClient
.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory)
)
.build();
// 创建会话
String chatId = UUID.randomUUID().toString();
// 第一次对话
String result = chat(chatClient,chatId,"你好,我叫张三");
System.out.println("========================第一次回复的消息======================");
System.out.println(result);
// 第二次对话
result = chat(chatClient,chatId,"你还记得我是谁吗");
System.out.println("========================第二次回复的消息======================");
System.out.println(result);
}
private String chat(ChatClient chatClient,String chatId,String userInput){
ChatResponse chatResponse = chatClient.prompt()
.user(userInput)
.advisors(spec -> spec
.param(CHAT_MEMORY_CONVERSATION_ID_KEY,chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY,10)
).call().chatResponse();
return chatResponse.getResult().getOutput().getText();
}
}在上面的示例中我们创建ChatClient时传递了默认的Advisor,这样所有的请求都可以使用MessageChatMemoryAdvisor进行对话记忆
但是在消息发送之前我们需要配置CHAT_MEMORY_CONVERSATION_ID_KEY(对话ID),以及CHAT_MEMORY_RETRIEVE_SIZE_KEY(消息最大召回数量)。这样可以区别不同用户的消息并控制请求数量需要显示的导入
开发多轮对话AI应用
目前AI大模型对话,我们使用的是测试的方式实现,代码我们以理解,在包中新建一个TravelApp应用类
实现旅游应用(TravelApp)
新建com.yugongyun.travelaiagent.app包,用于放我们的AI应用类型,在包中新建TravelApp应用类
初始化ChatClient对象
我们使用Spring构造注入的方式来注入大模型,并使用该对象来初始化,ChatClient 初始化时指定默认的系统提示词和基于内存的对话记忆Advisor
java
@Slf4j
@Component
public class TravelApp {
private static final String SYSTEM_PROMPT = """
你是经验丰富的资深旅行专家,专注提供个性化、高实用度的旅行解决方案。对话时,优先以引导式提问深挖用户需求:先确认意向目的地、
出行时间与时长、预算范围;再了解同行人群(亲子 / 情侣 / 好友 / 独自)、兴趣偏好(自然风光 / 人文古迹 / 美食探店 / 户外探险);最
后询问特殊需求(饮食禁忌 / 住宿偏好 / 小众路线 / 交通便利)。结合用户回答,输出贴合需求的行
程建议、本地隐藏玩法与避坑贴士,语气亲切专业,循序渐进推进对话。
""";
private final ChatClient chatClient;
public TravelApp(ChatModel dashscopeChatModel){
// 初始化基于内存的对话记忆
ChatMemory chatMemory = new InMemoryChatMemory();
this.chatClient = ChatClient
.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory)
)
.build();
}
/*
* 于AI大模型对话接口
* @param chatId 会话ID
* @param message 用户输入
* @return AI模型返回结果
* */
public String chat(String chatId,String message){
ChatResponse chatResponse = chatClient.prompt()
.user(message)
.advisors(spec -> spec
.param(CHAT_MEMORY_CONVERSATION_ID_KEY,chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY,10)
).call().chatResponse();
log.info("chatResponse: {}",chatResponse);
return chatResponse.getResult().getOutput().getText();
}
}测试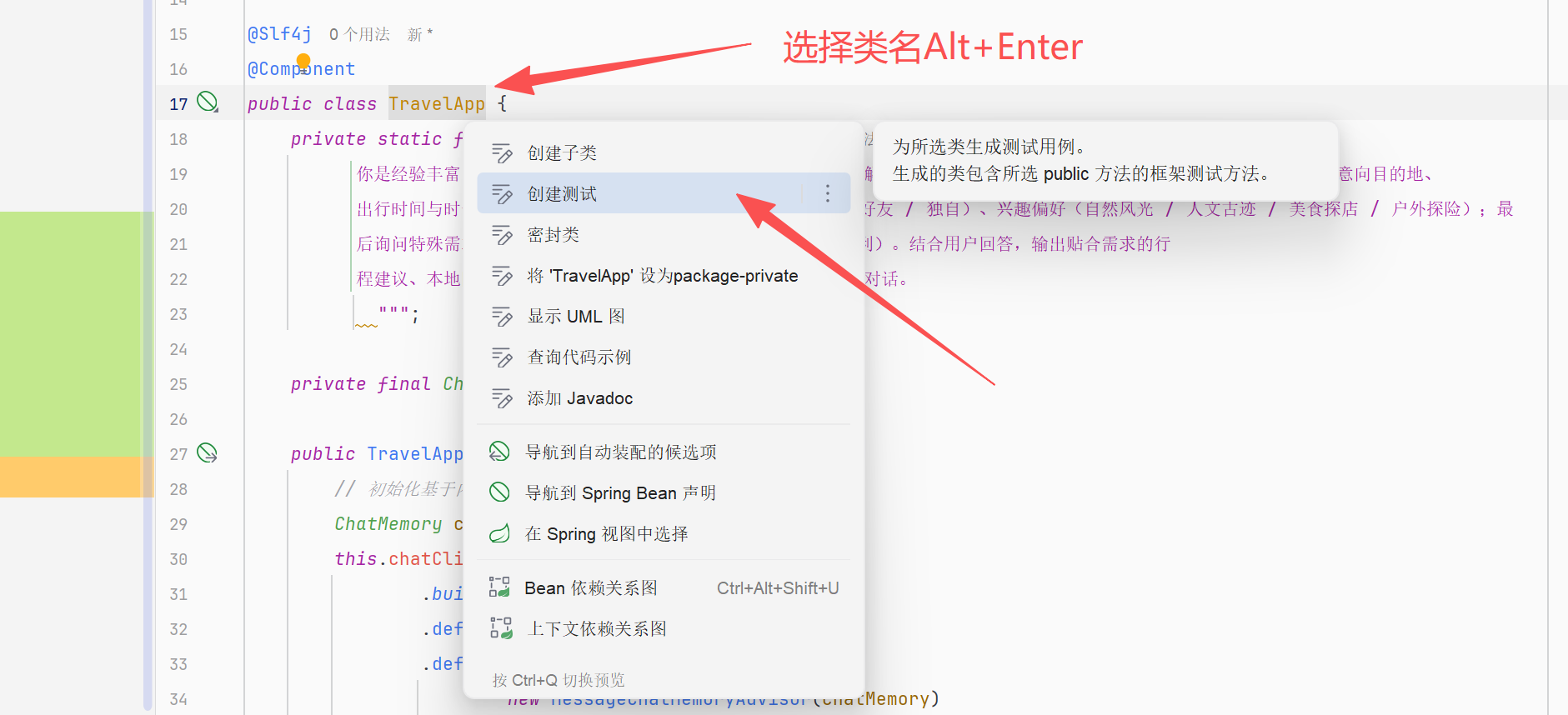
选择类名并安心Alt+Enter组合键创建测试,注入TravelApp类并调用caht方法执行测试
java
@SpringBootTest
class TravelAppTest {
@Autowired
TravelApp travelApp;
@Test
void chat() {
String result = travelApp.chat("1", "你好我叫张三");
System.out.println("========================第一次回复的消息======================");
System.out.println(result);
result = travelApp.chat("1", "你还记得我叫什么吗");
System.out.println("========================第二次回复的消息======================");
System.out.println(result);
}
}运行结果如下: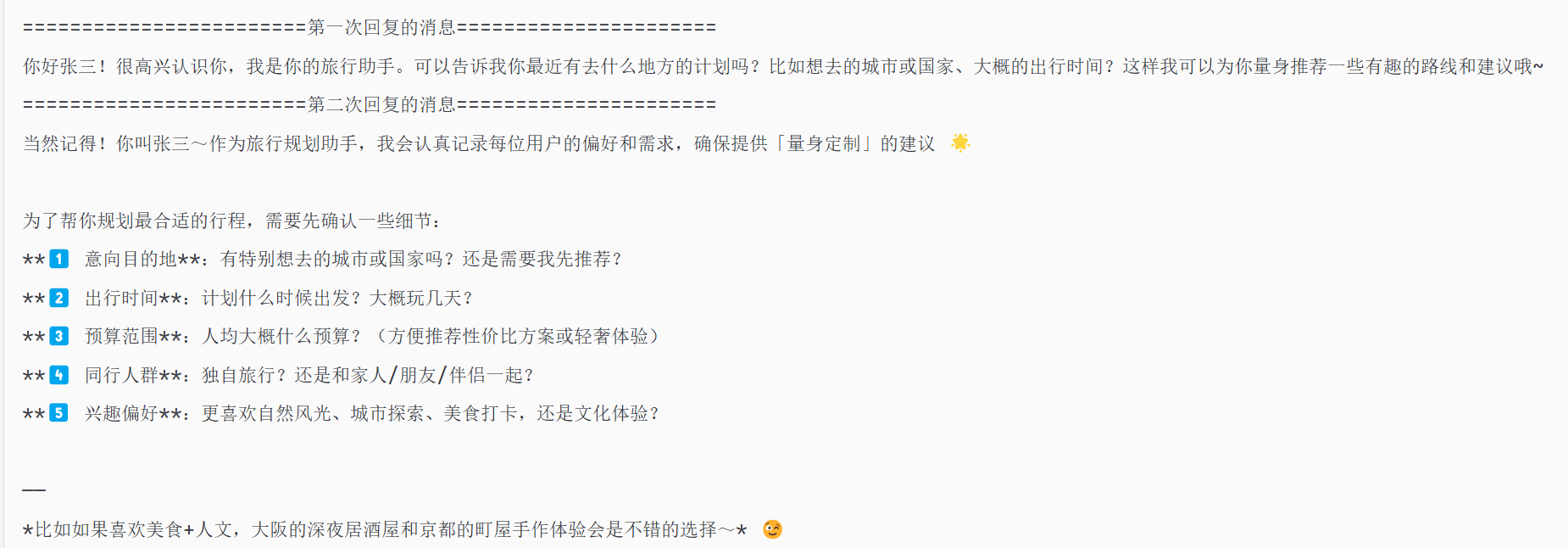
自定义Advisor实现Token统计
官方以提供了一些Advisor,但可能无法满足我们实际的业务需求。
例如token的统计,我们可以自定义Advisor功能,可以通过编写切面对请求和响应进行处理,而SpringAI的Advisor可以理解为AI的请求拦截器,可以对调用AI的请求进行增强,比如调用AI前鉴权,调用AI后记录日志
实现CallAroundAdvisor,StreamAroundAdvisor
选择一个合适的接口实现,实现以下接口之一或两者同时实现(建议同时实现):
- CallArundAdvisor:用于处理同步请求和响应(非流式)
- StreamAroundAdvisor:用于处理流式请求和响应
新建一个advisors包,然后定义我们自己的TokenCounterAdvisor
java
@Slf4j
public class TokenCounterAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
// 前置处理
private AdvisedRequest before(AdvisedRequest advisedRequest){
return advisedRequest;
}
// 后置处理
private void observeAfter(AdvisedResponse advisedResponse){
}
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
// 类似于AOP中的环绕增强,执行前置操作
advisedRequest = before(advisedRequest);
// 责任链模式,调用下一个顾问,或者请求AI大模型获得结果
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
// 执行后置操作
observeAfter(advisedResponse);
return advisedResponse;
}
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
advisedRequest = this.before(advisedRequest);
Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);
return (new MessageAggregator()).aggregateAdvisedResponse(advisedResponses, this::observeAfter);
}
@Override
public String getName() {
return this.getClass().getName();
}
@Override
public int getOrder() {
return 100;
}
}编写token统计逻辑
Token是大模型处理文本的一个基本单位,可能是单词,标点符号,而大模型的输入输出都是按照token来进行计算,一般token 越多成本越高,并且输出越慢
因此在开发中,了解和控制token的消耗至关重要
那么如何计算token呢?不同大模型的token划分策略不同,根据OpenAI的文档:
- 英文文本:一个token相当于4个字符或0.75个英文单词
- 文字文本:一个汉字通常会被编码为1-2个token
- 空格和表情符号:可能要多个token来表示
在实际应用中更推荐使用工具来估计Prompt的token数量
- Open AI的 Tokenizer:https://platform.openai.com/tokenizer(需要科学上网)
- 非官方的计算器:https://tiktoken.aigc2d.com/
估算成本有个公式:总成本=(输入token数 * 输入单价)+(输出token数 * 输出单价)不同大模型计费成本不一样
而SpringAI会在大模型在响应结果中封装元数据,包含此次各种token用量的结果方便开发人员统计,我们可以在TokenCounterAdvisor的observeAfter方法中统计token的用量并打印:
java
// 省略其他代码
// 存储会话的token使用情况
private static final Map<String,Long> TOKEN_USAGE_MAP = new ConcurrentHashMap<>();
// 前置处理
private AdvisedRequest before(AdvisedRequest advisedRequest){
return advisedRequest;
}
// 后置处理
private void observeAfter(AdvisedResponse advisedResponse){
// 从Advisor的上下文中获取会话ID
String chatId = advisedResponse.adviseContext()
.get(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY).toString();
// 本次请求的token总数
Long tokenUsed = advisedResponse.response().getMetadata().getUsage().getTotalTokens().longValue();
Long totalTokens = countTokens(chatId, tokenUsed);
log.info("会话ID: {}, 本次请求的token总数: {}, 总的token数: {}",chatId,tokenUsed,totalTokens);
}
private static Long countTokens(String chatId,Long tokenUsed){
Long totalTokens = TOKEN_USAGE_MAP.get(chatId);
if(totalTokens == null){
totalTokens = tokenUsed;
}else {
totalTokens += tokenUsed;
}
TOKEN_USAGE_MAP.put(chatId,totalTokens);
return totalTokens;
}
// ...省略其他代码在上面代码中有几个关键点:
- 使用Map来存储每个会话对应的token数量,考虑线程安全问题使用了ConcurrentHashMap类型
- 响应对象advisorResponse.adviseContext()返回一个Map包含了我们通过spec.param(Key,Value)设置的参数,所以我们可以得到会话ID
- 而advisedResponse.response().getMetadata().getUsage().getTotalTokens()包含了token的使用情况,我们可以通过countTokens方法进行累计
注册Advisor使用
Advisor类我们已经写完,最后就是进行注册到ChatClient中使用,修改TravelApp完成注册TokenCounterAdvisor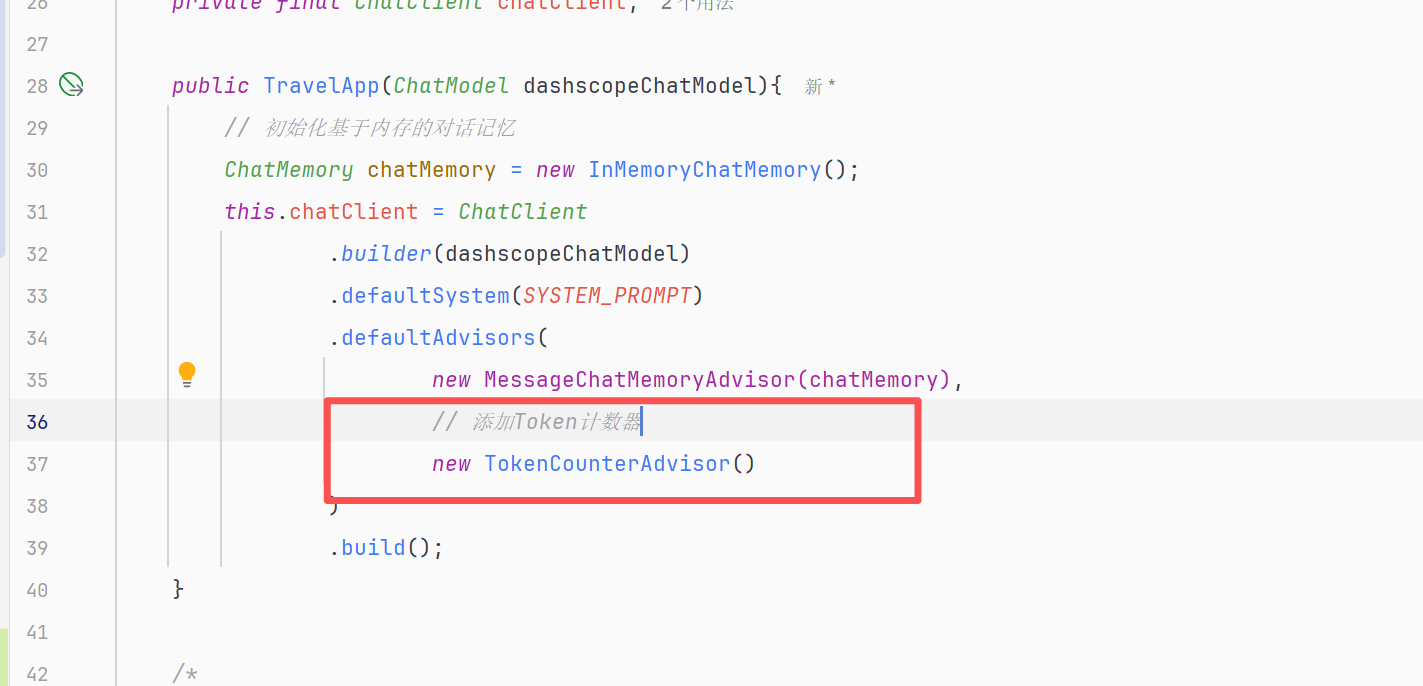
再次运行TravelAppTest测试,效果如下: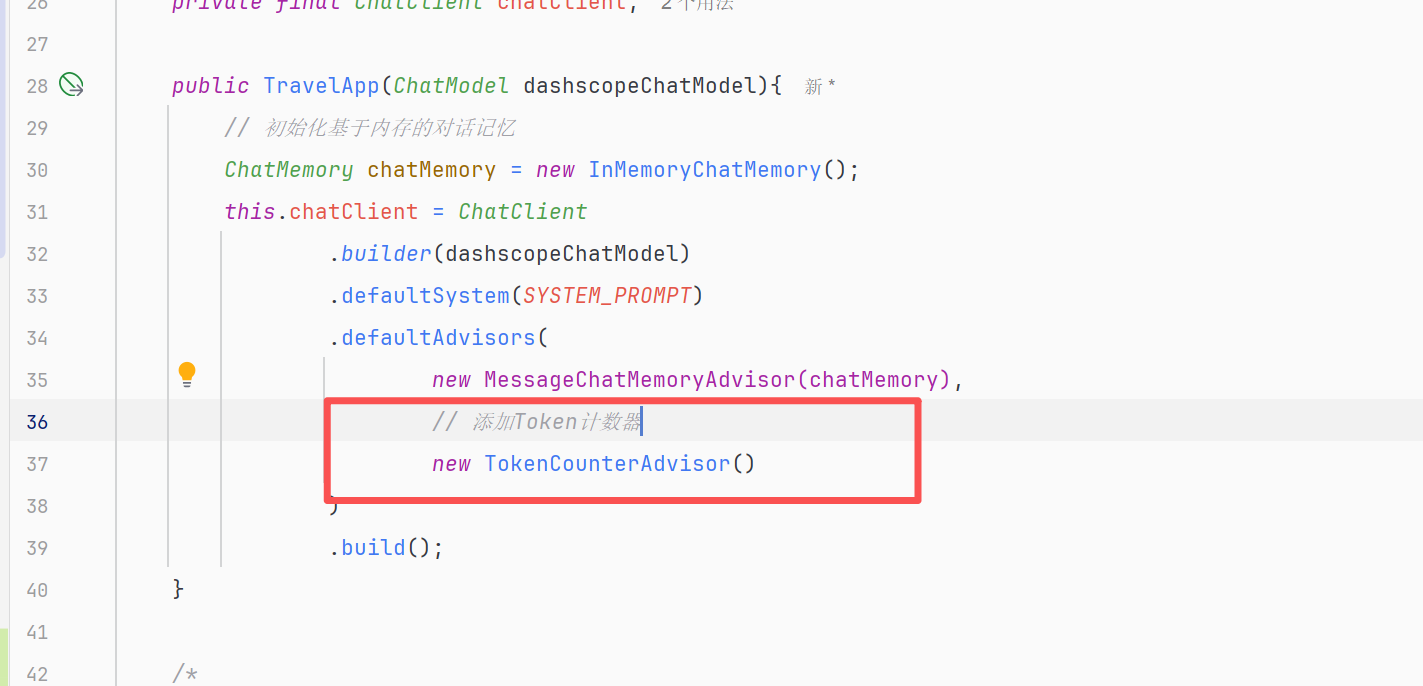
优化TravelApp应用
ChatMemory持久化
现在我们的TravelApp虽然可以使用但还有很多细节要处理,之前我们是基于内存存储,但是服务器一旦重启对话就会丢失,而数据库存储还需要建立数据库表比较麻烦,因此我们来实现一个基于文件读写的ChatMemory
Kryo简介
Kryo 是一个快速、高效、轻量级 的 Java 序列化 / 反序列化框架,由 Esoteric Software 开发,核心目标是替代 JDK 原生序列化,解决原生序列化速度慢、生成字节体积大、性能差的问题。
简单来说:JDK 序列化就像用普通快递寄包裹(慢、包装占空间),而 Kryo 就像用顺丰特快(快、包装精简),特别适合对性能和存储空间敏感的场景。
导入Kryo
要使用它我们必须引入它的依赖在pom.xml中添加:
XML
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.2</version>
</dependency>编写KryoChatMemory实现ChatMemory接口:
之前我们提到过SpringAI提供了ChatMemory接口,只需要实现这个接口我们就可以自定义的方式来存储聊天的对话记忆
创建memory包,自定义一个KryoChatMemory类,代码如下
java
public class KryoChatMemory implements ChatMemory {
// 会话保存路径
private String savePath;
public KryoChatMemory(String savePath) {
if(StrUtil.isBlank(savePath)){
throw new RuntimeException("savePath is null");
}
// 如果路径不存在,则创建
if(!FileUtil.exist(savePath)){
FileUtil.mkdir(savePath);
}
this.savePath = savePath;
}
private Kryo createKryo(){
Kryo kryo = new Kryo();
// 不需要注册
kryo.setRegistrationRequired( false);
// 该处设置对象实例化策略
kryo.setInstantiatorStrategy(new StdInstantiatorStrategy());
return kryo;
}
/*
* 序列化消息列表
* */
private void writeConversation(String conversationId,List<Message> messages, Kryo kryo){
// 获取会话文件
File file = getConversationFile(conversationId);
// 序列化消息列表
try(Output output = new Output(new FileOutputStream(file))){
// 序列化消息列表
kryo.writeObject(output, messages);
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
}
}
// 反序列化会话消息列表
private List<Message> readConversation(String conversationId, Kryo kryo){
File file = getConversationFile(conversationId);
List<Message> messages = new ArrayList<>();
if(FileUtil.exist( file)){
try(Input input = new Input(new FileInputStream( file))){
messages = kryo.readObject(input, ArrayList.class);
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
}
}
return messages;
}
private File getConversationFile(String conversationId) {
// 以会话ID为文件名,保存会话
return new File(savePath, conversationId + ".bin");
}
@Override
public void add(String conversationId, List<Message> messages) {
Kryo kryo = createKryo();
List<Message> messagesList = readConversation(conversationId, kryo);
messagesList.addAll(messages);
writeConversation(conversationId, messagesList, kryo);
}
@Override
public List<Message> get(String conversationId, int lastN) {
Kryo kryo = createKryo();
// 获取会话消息列表
List< Message> messages = readConversation(conversationId, kryo);
// 获取最后N条消息
return messages.subList(Math.max(0,messages.size() - lastN), messages.size());
}
@Override
public void clear(String conversationId) {
FileUtil.del(getConversationFile(conversationId));
}
}需要注意的是Kroy是非线程安全的,建议创建局部变量进行操作
使用KryoChatMemory
目前我们使用的是InMemoryChatMemory将会话数据存储在内存中,现在替换为我们自定义的KryoChatMemory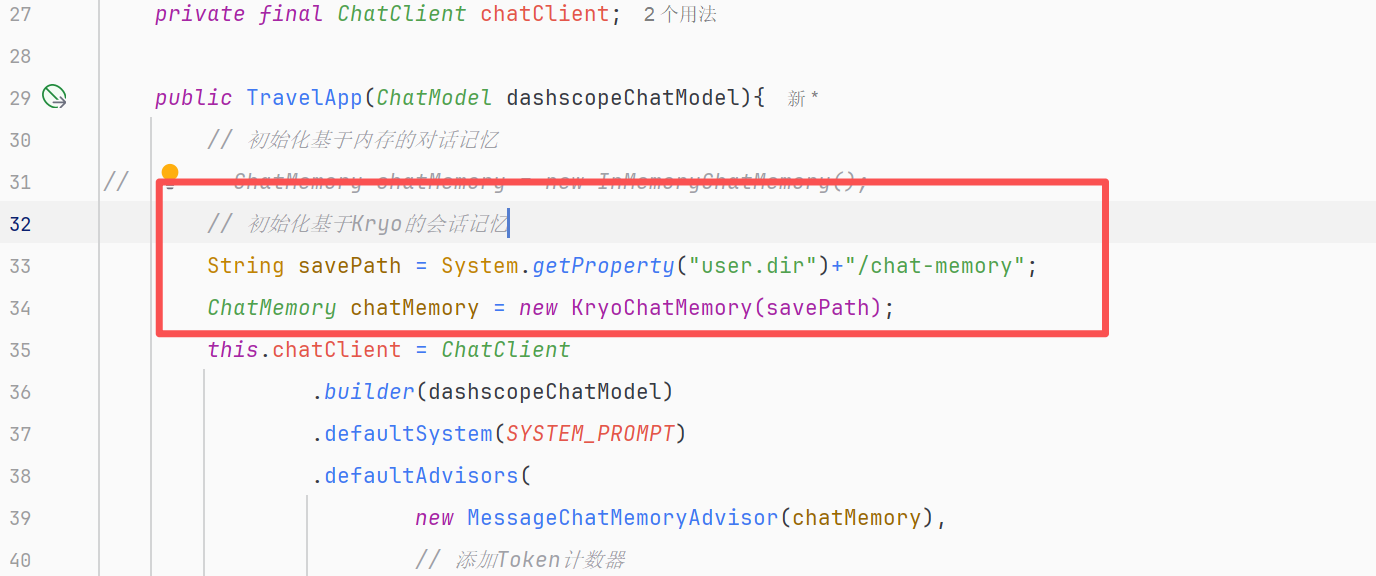
修改TravelApp的构造函数,测试运行,序列化会话数据文件成功,效果如下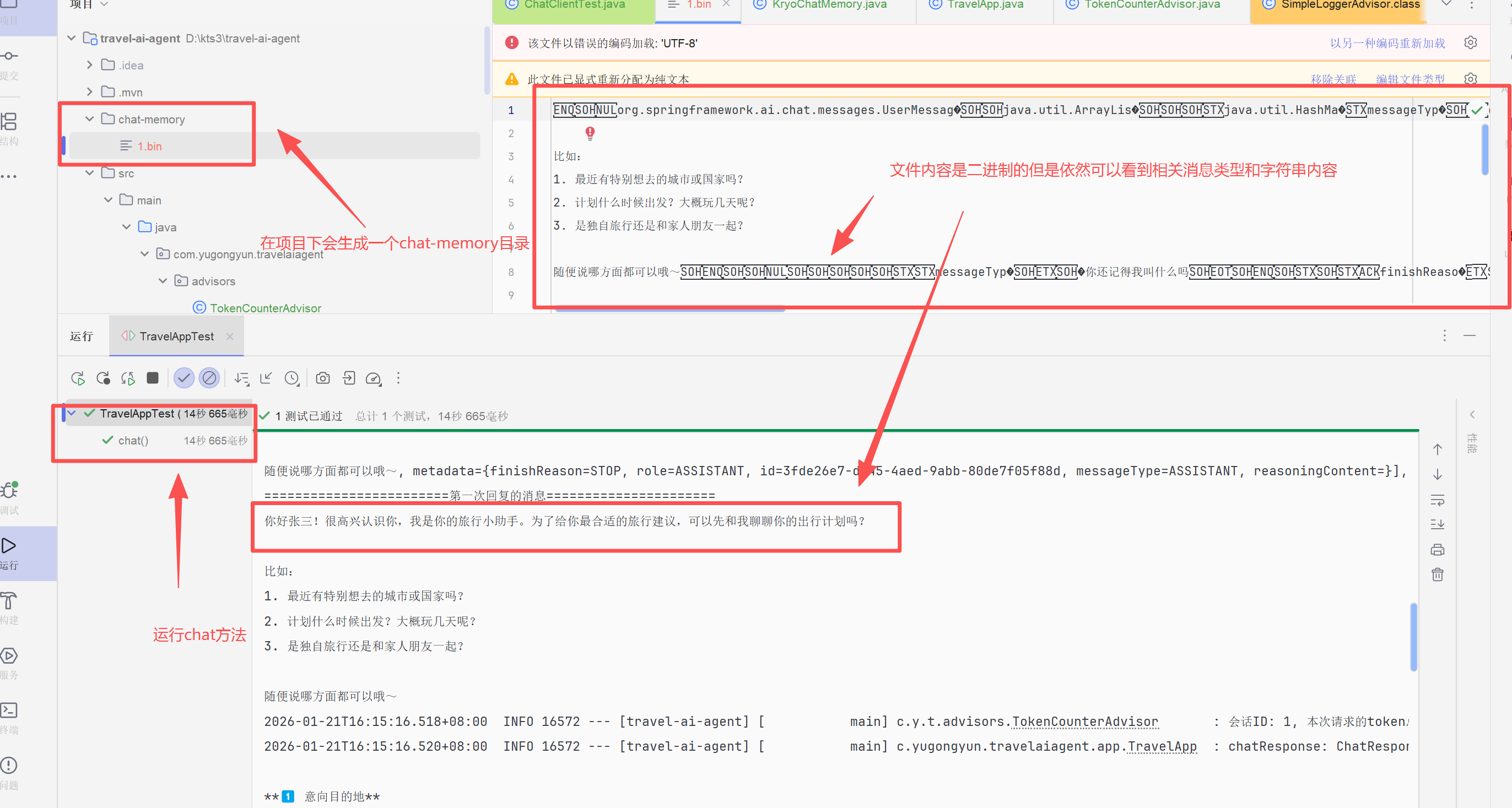
我们还需要验证能否通过会话ID重新载入会话记忆,并更新会话文件新建一个测试方法,用上一步的chatId
java
@Test
void testKryoChat(){
String chatId = "1";
String result = travelApp.chat(chatId,"你好,还记得我是谁吗");
System.out.println(result);
}运行效果,如下图所示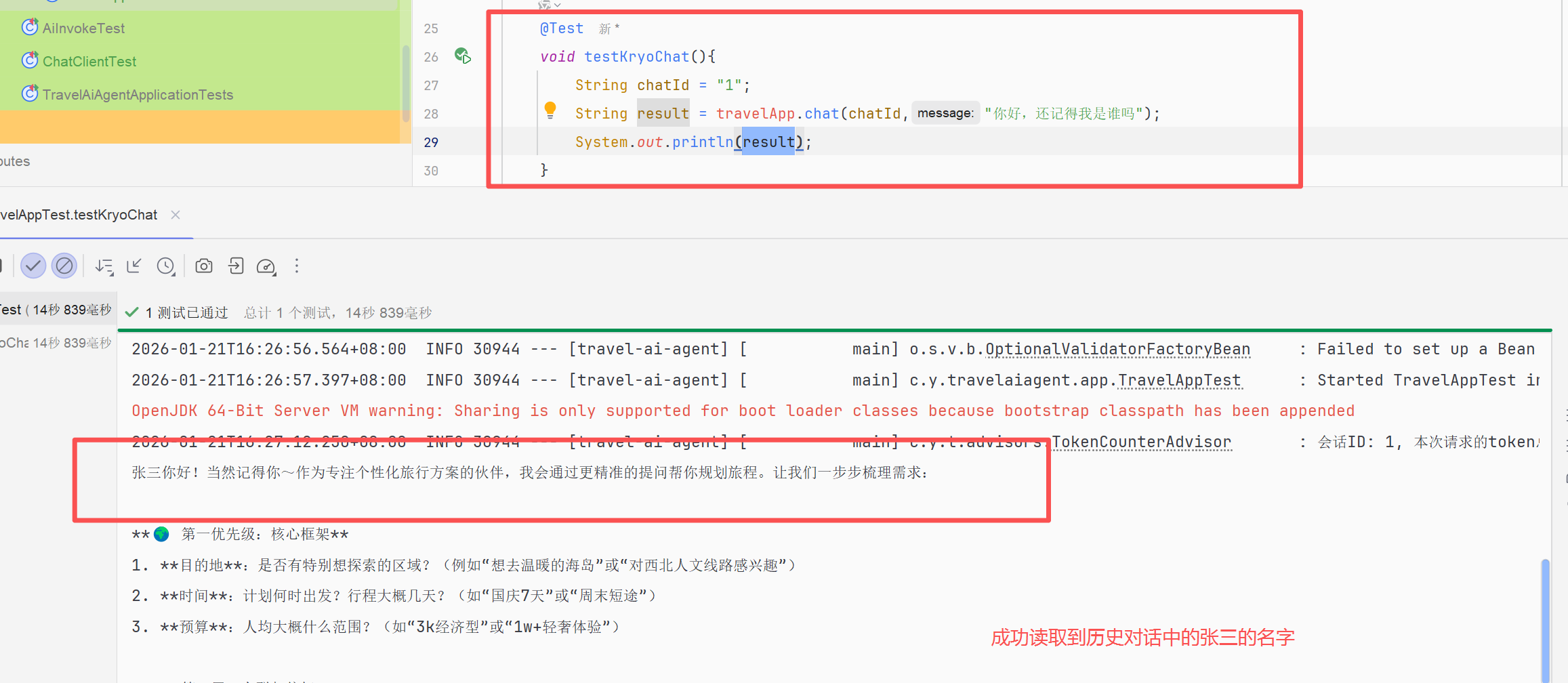
这样即使程序重启,还可以从文件中加载此会话记忆,继续更新记忆文件
PromptTemplate模板
PromptTemplate是 Spring AI 中用于构建结构化提示词的核心工具,它允许你:
- 定义包含占位符的提示词模板字符串
- 动态填充占位符参数,生成最终的提示词
- 结合会话记忆(ChatMemory),自动注入历史对话内容
下面我们继续在TravelAppTest编写一个测试方法testTemplate,测试一下效果:
java
@Test
void testTemplate(){
String template = "你好,{name},今天是{day},天气{weather}。";
// 创建模板对象
PromptTemplate promptTemplate = new PromptTemplate(template);
// 准备变量映射
Map<String,Object> variables = new HashMap<>();
variables.put("name","张三");
variables.put("day","星期三");
variables.put("weather","晴天");
String prompt = promptTemplate.render(variables);
System.out.println(prompt);
}运行结果如下: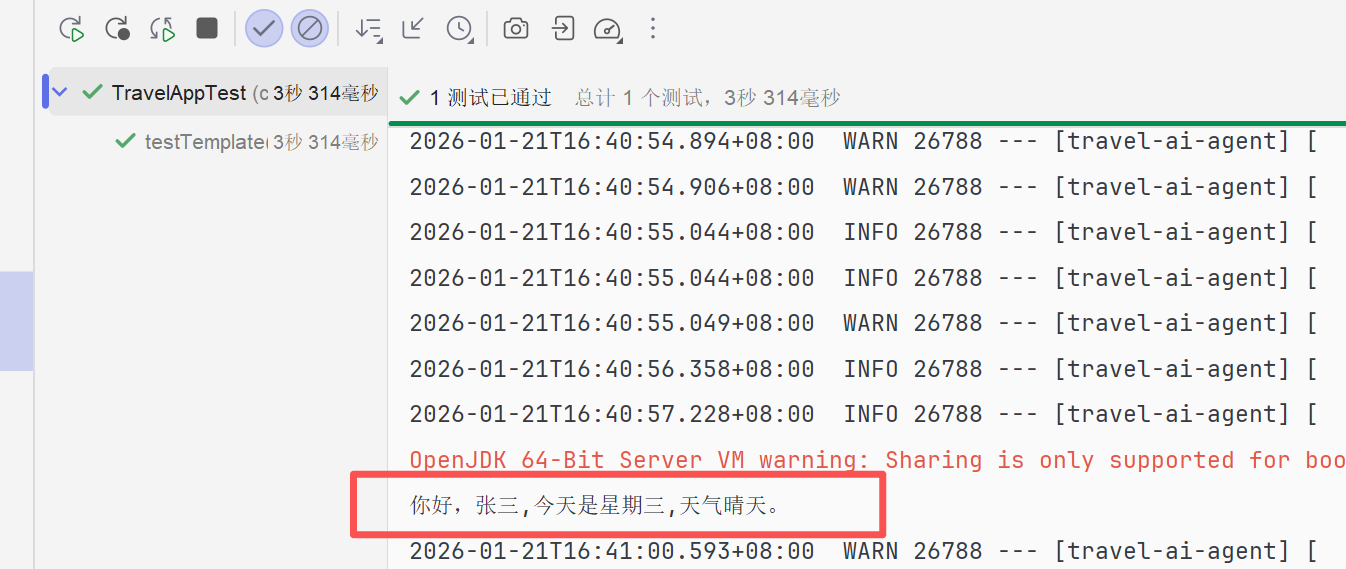
PromptTemplate 核心使用场景
- 动态参数填充 :固定提示词框架,仅替换
{占位符}(如{city}、{days}),避免重复编写相似提示词,比如 "为 {city} 规划 {days} 天旅行攻略"。 - 标准化提示词格式:统一 AI 角色、回答规则(如 "回答控制在 {maxLen} 字内"),确保 AI 输出符合预期。
- 结合会话记忆 :将
{history}占位符与 ChatMemory 结合,注入历史对话,实现上下文连贯的多轮对话。 - 拆分管理提示词:把系统提示、用户问题、历史对话拆分为不同模板片段,组合成完整 Prompt,便于维护。
从文件加载模板
PromptTemplate支持从外部文件加载模板内容,很适合管理复杂的提示词,SpringAI通过Spring 的Resource 对象来从指定路径加载模板文件
TravelApp中的复杂提示词,我们就可以通过外部配置文件实现管理
1.我们先在resources目录新建一个prompt文件夹,专门存放各种提示词,然后新建一个travel-app-system.pt文本文件
可以复制之前的提示词然后添加一段占位符,则可以通过变量进行修改如
2.注入模板内容
修改TravelApp的构造函数,注入模板内容
java
public TravelApp(ChatModel dashscopeChatModel,
@Value("classpath:/prompts/travel-app-system.pt") Resource systemPromptResource
,@Value("${travel.app.name:愚公云}") String name
){
// 初始化基于内存的对话记忆
// ChatMemory chatMemory = new InMemoryChatMemory();
// 初始化基于Kryo的会话记忆
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemPromptResource);
Map<String, Object> vars = Map.of("name",name);
Prompt systemPrompt = systemPromptTemplate.create(vars);
String systemPromptStr = systemPrompt.getContents();
String savePath = System.getProperty("user.dir")+"/chat-memory";
ChatMemory chatMemory = new KryoChatMemory(savePath);
this.chatClient = ChatClient
.builder(dashscopeChatModel)
.defaultSystem(systemPromptStr)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
// 添加Token计数器
new TokenCounterAdvisor()
)
.build();
}我们运行测试方法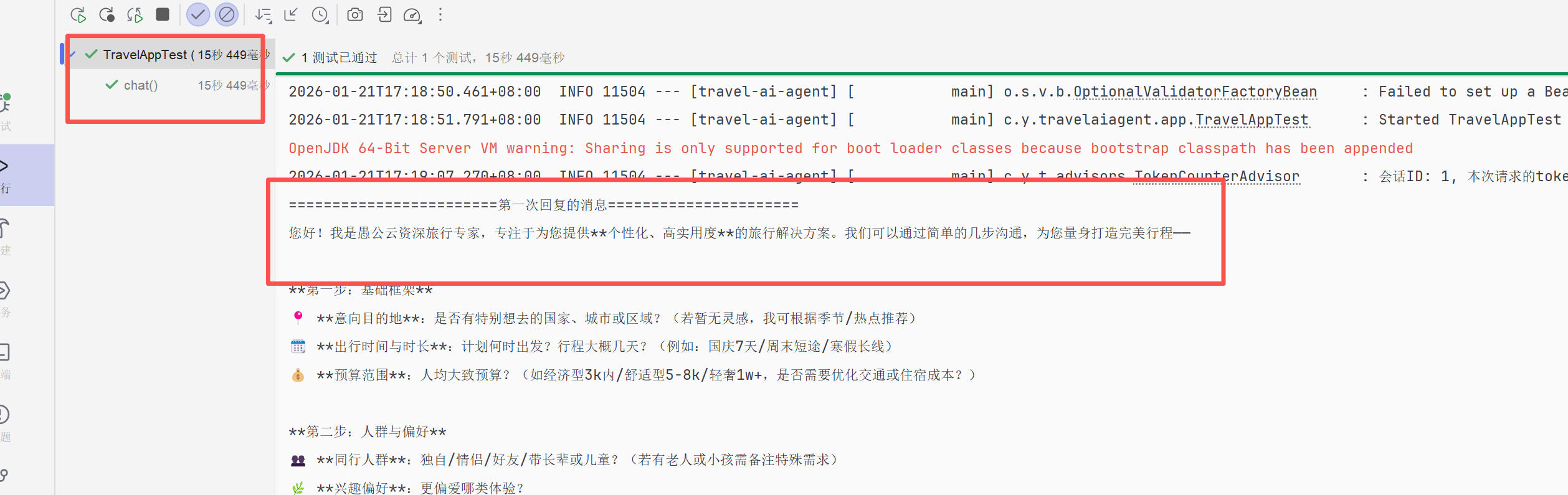
我们可以从运行效果来看他已经将我配置的提示词对占位符进行了替换,后期可以通application.yml中配置travel.app.name这个值。
到现在,TravelApp已经初步具备了AI应用的基本功能,后续还会持续升级,包括RAG,工具调用,MCP等等