PaddleOCR实现批量识别
本文实现pdf文件或者图片上的文本识别,并输出全部文本信息。在此基础上,可基于文本正则匹配等方法实现具体信息的提取。
输入:包含pdf、png的文件夹
输出:md、excel文件,包含每个文件的识别结果
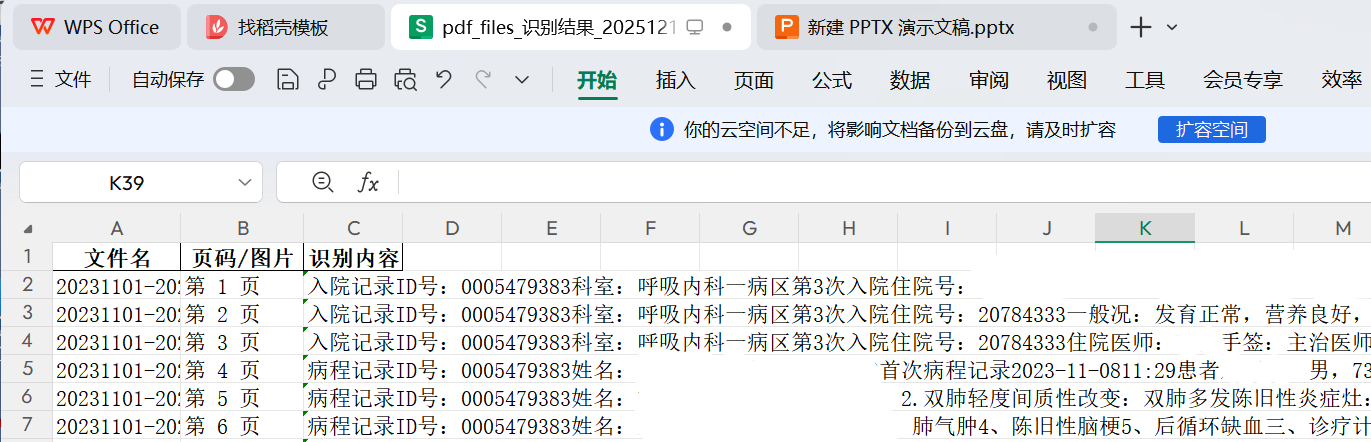
输出示例(pdf):
Step1: 环境配置
shell
### 环境搭建-linux-conda
conda create -n paddle_ocr python=3.9 -y
conda activate paddle_ocr
pip install numpy==1.26.4
python -m pip install paddlepaddle-gpu -i https://repo.huaweicloud.com/repository/pypi/simple/
pip install paddleocr==2.7.3
pip install pymupdf # 用于快速将PDF转图片
pip install pandas openpyxl tqdm
conda install cudnn=8.9.2.26 cudatoolkit=11.8 -c conda-forge -yStep2:OCR识别文本
shell
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CONDA_PREFIX/lib
# 加入环境中
mkdir -p $CONDA_PREFIX/etc/conda/activate.d
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CONDA_PREFIX/lib' > $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh
# 执行
python batch_TextOCR.py --input_dir pdf_files --input_type pdf --output_format xlsx --use_gpu
# usage: batch_TextOCR.py [-h] --input_dir INPUT_DIR [--input_type {pdf,image,all}] [--output_format {xlsx,md}] [--use_gpu]batch_TextOCR.py具体代码为:
python
import os
import argparse
import fitz # PyMuPDF
import cv2
import numpy as np
import pandas as pd
from paddleocr import PaddleOCR
from tqdm import tqdm
import logging
# 关闭 Paddle 的部分调试日志
logging.getLogger("ppocr").setLevel(logging.WARNING)
def parse_args():
"""
解析命令行参数
"""
parser = argparse.ArgumentParser(description="PaddleOCR 批量识别工具")
# 1. 输入目录
parser.add_argument('--input_dir', type=str, required=True, help='输入文件的文件夹路径')
# 2. 输入格式 (默认为 all)
parser.add_argument('--input_type', type=str, default='all', choices=['pdf', 'image', 'all'],
help='指定要处理的文件类型: pdf, image, 或 all (全部)')
# 3. 输出格式
parser.add_argument('--output_format', type=str, default='xlsx', choices=['xlsx', 'md'],
help='输出文件格式: xlsx (Excel) 或 md (Markdown)')
# 其他配置
parser.add_argument('--use_gpu', action='store_true', help='是否使用 GPU 加速 (默认不使用,加上此参数则使用)')
return parser.parse_args()
def init_ocr(use_gpu):
"""
初始化 OCR 引擎
"""
print(f"正在初始化 OCR 引擎 (GPU: {use_gpu})...")
# 为了兼容性,显式设置 use_gpu
try:
ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=use_gpu, show_log=False)
except Exception:
# 如果旧版本不支持 show_log,尝试去掉该参数
ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=use_gpu)
return ocr
def pdf_to_imgs(pdf_path):
"""
将 PDF 转换为图像列表 (numpy 格式)
"""
doc = fitz.open(pdf_path)
images = []
for page in doc:
# 放大 2 倍以提高识别率
pix = page.get_pixmap(matrix=fitz.Matrix(2, 2))
img_array = np.frombuffer(pix.samples, dtype=np.uint8).reshape(pix.h, pix.w, pix.n)
if pix.n == 4:
img_array = cv2.cvtColor(img_array, cv2.COLOR_RGBA2RGB)
else:
img_array = cv2.cvtColor(img_array, cv2.COLOR_RGB2BGR)
images.append(img_array)
return images
def get_file_list(input_dir, input_type):
"""
根据参数筛选文件
"""
if not os.path.exists(input_dir):
raise FileNotFoundError(f"目录不存在: {input_dir}")
all_files = os.listdir(input_dir)
valid_files = []
img_exts = ('.jpg', '.jpeg', '.png', '.bmp', '.tiff')
pdf_exts = ('.pdf',)
for f in all_files:
ext = os.path.splitext(f)[1].lower()
if input_type == 'pdf' and ext in pdf_exts:
valid_files.append(f)
elif input_type == 'image' and ext in img_exts:
valid_files.append(f)
elif input_type == 'all':
if ext in img_exts or ext in pdf_exts:
valid_files.append(f)
return sorted(valid_files)
def save_to_excel(data, output_path):
"""保存为 Excel"""
df = pd.DataFrame(data)
df.to_excel(output_path, index=False)
print(f"Excel 文件已保存至: {output_path}")
def save_to_markdown(data, output_path):
"""保存为 Markdown"""
with open(output_path, 'w', encoding='utf-8') as f:
f.write(f"# OCR 识别结果报告\n\n")
f.write(f"> 生成时间: {pd.Timestamp.now()}\n\n")
current_file = None
for row in data:
filename = row['文件名']
page = row.get('页码/图片', '')
content = row['识别内容']
if filename != current_file:
if current_file: f.write("---\n\n")
f.write(f"# 📄 {filename}\n\n")
current_file = filename
if page:
f.write(f"### {page}\n\n")
f.write(f"```text\n{content}\n```\n\n")
print(f"Markdown 文件已保存至: {output_path}")
def main():
args = parse_args()
# 1. 获取文件列表
try:
files = get_file_list(args.input_dir, args.input_type)
except Exception as e:
print(f"错误: {e}")
return
if not files:
print("未找到符合条件的文件。")
return
print(f"共找到 {len(files)} 个文件,准备处理...")
# 2. 初始化 OCR
ocr = init_ocr(args.use_gpu)
results_data = []
# 3. 开始处理
for file_name in tqdm(files, desc="处理进度"):
file_path = os.path.join(args.input_dir, file_name)
ext = os.path.splitext(file_name)[1].lower()
try:
# 准备待处理的图片列表
process_queue = [] # [(页码标识, 图片对象)]
if ext == '.pdf':
imgs = pdf_to_imgs(file_path)
for idx, img in enumerate(imgs):
process_queue.append((f"第 {idx+1} 页", img))
else:
# 图像文件
img = cv2.imread(file_path)
if img is not None:
process_queue.append(("全图", img))
# 遍历队列进行 OCR
for label, img_obj in process_queue:
result = ocr.ocr(img_obj, cls=True)
content = ""
if result and result[0]:
text_lines = [line[1][0] for line in result[0]]
content = "\n".join(text_lines)
results_data.append({
"文件名": file_name,
"页码/图片": label,
"识别内容": content
})
except Exception as e:
print(f"\n处理文件 {file_name} 失败: {e}")
# 4. 导出结果
if not results_data:
print("没有识别到任何结果。")
return
# 生成输出文件名 (基于输入目录名 + 时间戳)
dir_name = os.path.basename(os.path.normpath(args.input_dir))
timestamp = pd.Timestamp.now().strftime("%Y%m%d_%H%M")
output_filename = f"{dir_name}_识别结果_{timestamp}.{args.output_format}"
output_path = os.path.join(args.input_dir, output_filename) # 默认保存在输入目录下
if args.output_format == 'xlsx':
save_to_excel(results_data, output_path)
else:
save_to_markdown(results_data, output_path)
if __name__ == "__main__":
main()