文章目录
-
- [1. 介绍](#1. 介绍)
- [2. 使用详解](#2. 使用详解)
-
- [2.1 账号注册与 API 配置](#2.1 账号注册与 API 配置)
- [2.2 Task.init 方法](#2.2 Task.init 方法)
- [2.3 task.get_logger()](#2.3 task.get_logger())
-
- [2.3.1 基础使用模式](#2.3.1 基础使用模式)
- [2.3.2 核心方法详解](#2.3.2 核心方法详解)
- [2.3.3 高级可视化](#2.3.3 高级可视化)
-
- [2.3.3.1 report_plotly() 和 report_scatter2d()](#2.3.3.1 report_plotly() 和 report_scatter2d())
- [2.3.3.2 report_scatter2d() - 简单快速的散点图](#2.3.3.2 report_scatter2d() - 简单快速的散点图)
- [2.3.3.3 曲面图 (report_surface) 和 直方图 (report_histogram)**](#2.3.3.3 曲面图 (report_surface) 和 直方图 (report_histogram)**)
- [2.3.3.4 3D 模型与点云](#2.3.3.4 3D 模型与点云)
- [2.3.3.5 多媒体记录](#2.3.3.5 多媒体记录)
- [2.3.4 高级用法](#2.3.4 高级用法)
-
- [2.3.4.1 动态更新图表](#2.3.4.1 动态更新图表)
- [2.3.4.2 自定义布局](#2.3.4.2 自定义布局)
- [2.3.4.3 与 TensorBoard 集成](#2.3.4.3 与 TensorBoard 集成)
- [2.3.4.4 性能优化技巧](#2.3.4.4 性能优化技巧)
- [2.3.4.5 典型工作流](#2.3.4.5 典型工作流)
- [2.3.4.6 与 Web UI 的交互](#2.3.4.6 与 Web UI 的交互)
- [2.3.5 WebUI显示位置](#2.3.5 WebUI显示位置)
- [2.4 task.connect的使用](#2.4 task.connect的使用)
-
- [2.4.1 基础用法](#2.4.1 基础用法)
- [2.4.2 高级用法](#2.4.2 高级用法)
- [2.4.3 webUI的显示](#2.4.3 webUI的显示)
- [2.5 Task 对象获取](#2.5 Task 对象获取)
-
- [2.5.1 主要获取方法](#2.5.1 主要获取方法)
- [2.5.2 方法对比与选择指南](#2.5.2 方法对比与选择指南)
- [2.5.3 常见问题](#2.5.3 常见问题)
- [3 示例说明:](#3 示例说明:)
1. 介绍
ClearML是一个开源的MLOps平台,用于自动化和管理机器学习实验的全生命周期。它自动记录训练过程中的所有参数、代码、数据集和模型,提供实时可视化界面,支持团队协作、超参数优化和模型部署。推荐使用ClearML因为它:1)完全开源且可本地部署,保障数据隐私;2)集成简单(仅需两行代码);3)提供从研究到生产的无缝工作流;4)显著提升实验复现性和团队协作效率;5)免费版功能完整,无需昂贵订阅。ClearML让数据科学家专注于模型创新而非手动记录实验,大幅加速AI开发迭代周期。
想象一下:
你训练了 10 个模型,每个用了不同学习率,一周后,你完全记不清哪个模型效果最好,想复现最佳结果,但找不到当时用的参数想和同事分享结果,却只能发一堆截图和文本文件ClearML 就是解决这些问题的神器!✨
🚀 核心功能
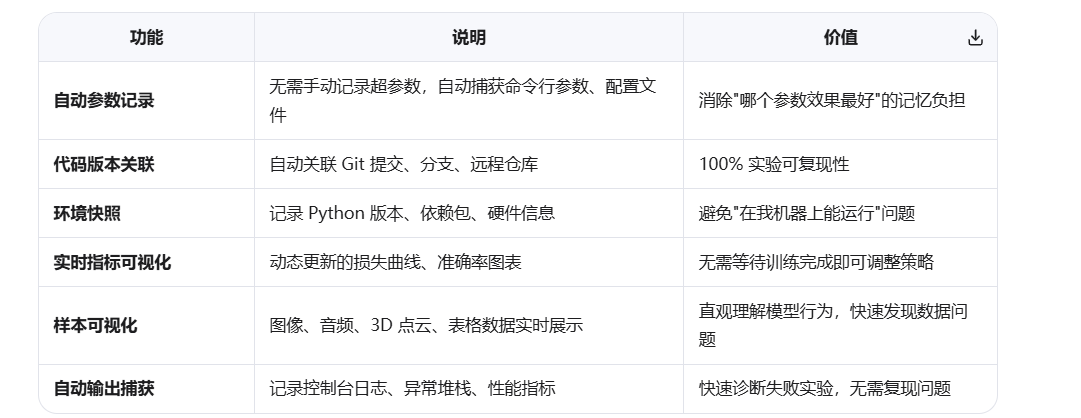
- 自动记录:所有训练参数、代码、环境
- 实时可视化:损失曲线、准确率、训练图片
- 实验对比:一键比较多个实验的指标
- 模型管理:保存、版本控制、部署模型
- 团队协作:共享实验结果,添加评论
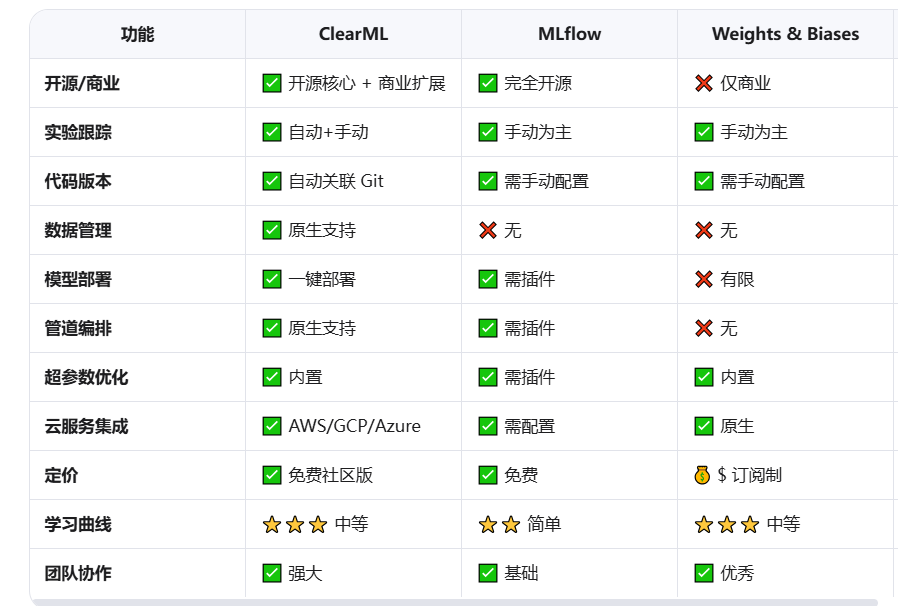
与其他竞品对比
💡 一句话总结
ClearML = 训练实验的"黑匣子" + 可视化仪表盘 + 团队协作平台
2. 使用详解
2.1 账号注册与 API 配置
(1)步骤 1: 注册账号
- 访问 ClearML 官网
- 点击 "Sign Up" → 选择 GitHub 或 Google 账号登录(推荐)
- 完成邮箱验证
登入后的页面如下图所示:
免费社区版已足够个人使用!
(2)步骤 2: 获取 API 凭证
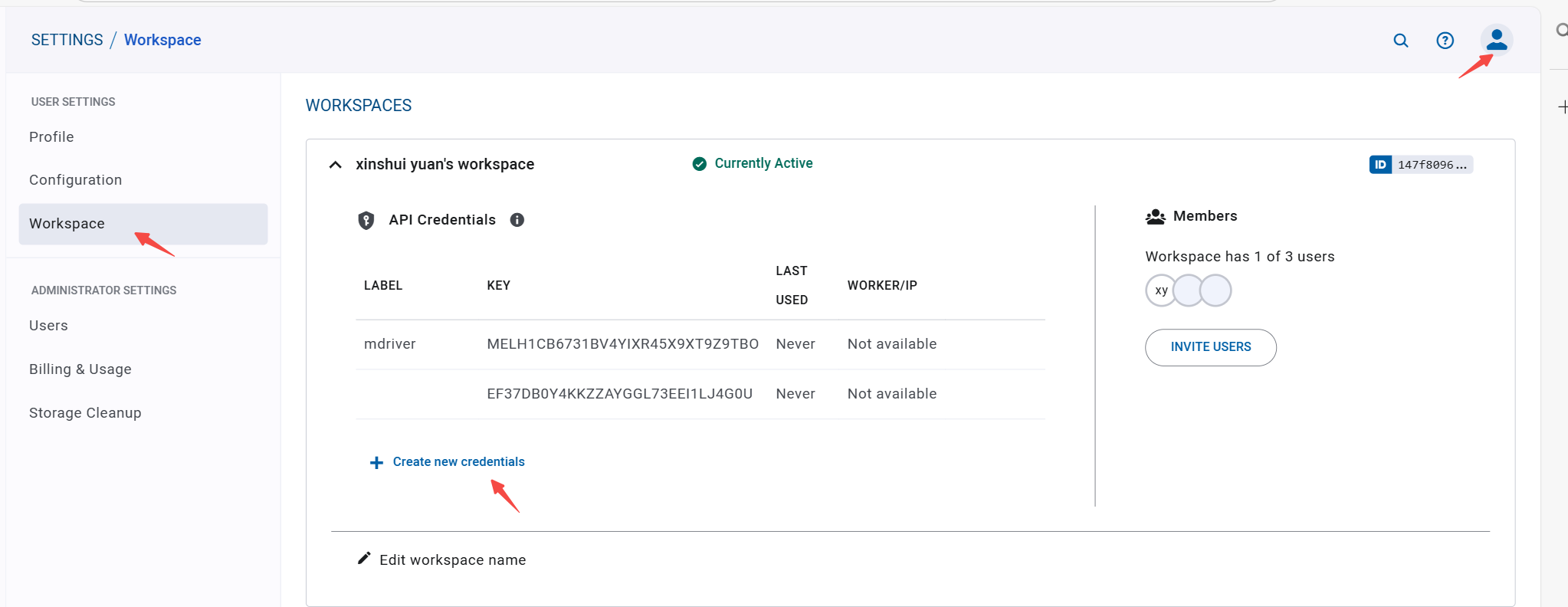
- 登录后,点击右上角
用户名 → Settings → Workspace - 选择 "Create new workspace":
- Name: my-first-workspace(自定义)
- Visibility: Private(私有)
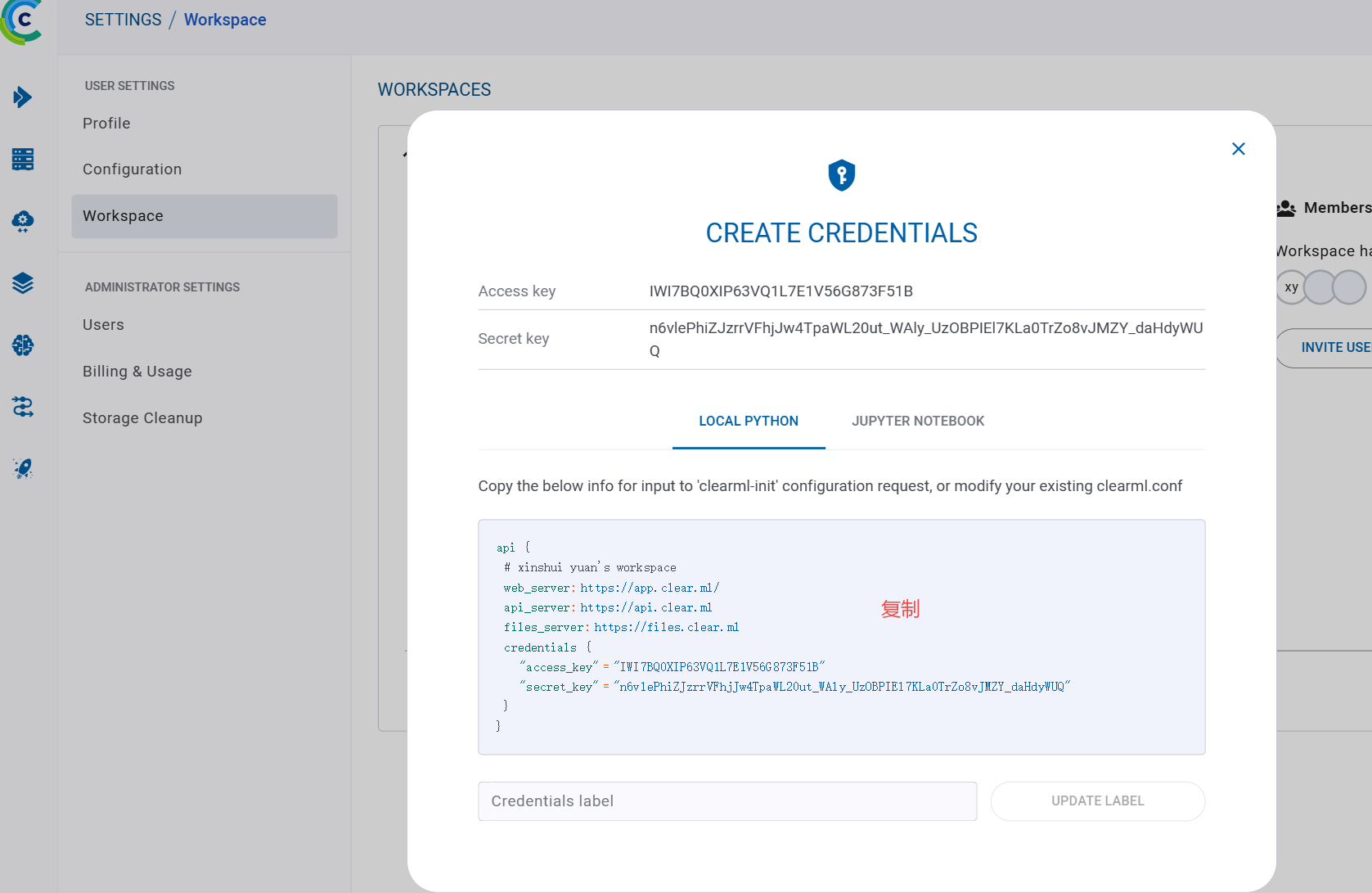
- 创建后,点击
"API Credentials" → "Create new credentials" - 复制生成的
api_server, web_server, files_server, api_key, api_secret
(3) 步骤 3: 配置本地环境
py
# 安装 ClearML
pip install clearml
# 初始化配置(按提示输入刚才复制的凭证)
clearml-init将刚才拿到的credentials,按照提示复制到终端,即可。
(4)验证安装
shell
from clearml import Task
print("ClearML 配置成功!")运行无错误即表示配置成功
2.2 Task.init 方法
Task.init() 是 ClearML 中初始化实验跟踪的核心方法,通过合理配置参数,可以精确控制实验记录行为。以下是所有参数的详细说明:
py
from clearml import Task
task = Task.init(
project_name="My Project",
task_name="Experiment ABC",
task_type=Task.TaskTypes.training, # training|testing|inference|data_processing
tags=["resnet", "v1"],
reuse_last_task_id=False, # 总是创建新任务
output_uri="s3://my-bucket/results" # 可选,指定输出存储
)(1) 基础参数
project_name (必需): 定义任务所属的项目名称, 支持嵌套项目:"CV/Image Classification"task_name (必需): 定义任务的显示名称task_type(可选): 标识任务类型,影响 Web UI 中的显示和默认行为,默认值: Task.TaskTypes.training, 可选值包括:
shell
from clearml import Task
Task.TaskTypes.training # 训练任务
Task.TaskTypes.testing # 测试/评估任务
Task.TaskTypes.inference # 推理任务
Task.TaskTypes.data_processing # 数据处理任务
Task.TaskTypes.application # 应用任务reuse_last_task_id: 是否重用上一次同名任务的 ID, False: 总是创建新任务(推荐用于正式实验;True: 覆盖上次实验数据(用于迭代开发)continue_last_task: 继续上次任务,保留历史指标, 默认值: Falseforce_single_instance: 确保同一时间只有一个相同名称的任务在运行,防止意外重复提交相同实验,默认值: Falseoutput_uri: 指定输出文件(模型、日志)的存储位置
py
None: 使用 ClearML 服务器配置的默认存储
False: 不上传任何输出(仅记录元数据)
"s3://bucket/path": 指定云存储路径
"./local_path": 本地路径(不推荐,可能丢失)auto_connect: 是否自动上传命令行参数和环境变量到clearml, True: 自动记录 sys.argv 和 os.environ,开启时有轻微性能开销(<1%)
py
# 仅记录重要参数
Task.init(auto_connect=False)
task.connect({"lr": 0.001, "batch_size": 32})auto_connect_frameworks: 控制自动连接哪些深度学习框架,默认值:
py
{
"tensorboard": True,
"pytorch": True,
"tensorflow": True,
"matplotlib": True,
"pillow": True,
"op": True
}示例
auto_connect_frameworks={
"pytorch": ["*.pt", "*.pth"], # 仅记录模型文件
"tensorboard": False, # 完全禁用
"matplotlib": True, # 启用但限制频率
"fastai": {"period": 60} # 每60秒记录一次
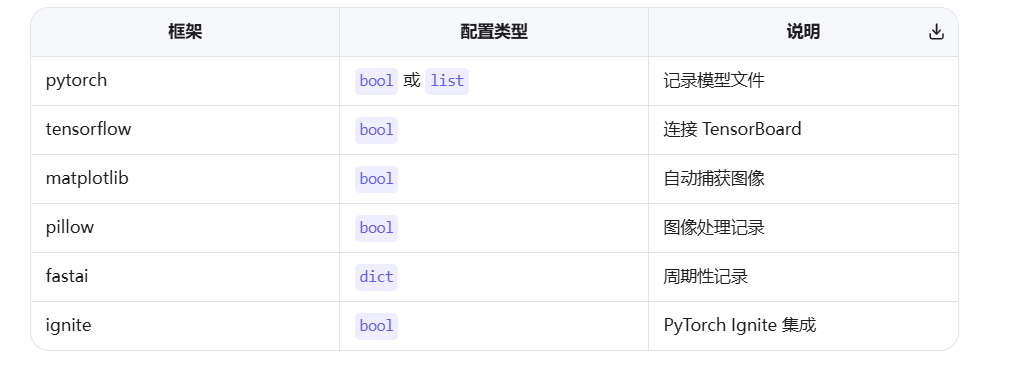
}支持框架:
auto_resource_monitoring: 是否自动监控系统资源, 默认值: True,每 10 秒采样一次,开销 < 2%
监控指标:- GPU 利用率/显存
- CPU 利用率/内存
- 网络/磁盘 I/O
py
# 资源受限环境
Task.init(auto_resource_monitoring=False)(2) 高级配置
docker: 指定训练使用的 Docker 镜像,确保环境可复现,支持远程执行,默认None,
py
# 简单字符串
Task.init(docker="pytorch/pytorch:1.12.1-cuda11.3-runtime")
# 详细配置
Task.init(docker={
"image": "my-registry/custom-image:latest",
"arguments": ["--shm-size=8g", "--ulimit memlock=-1"],
"setup_script": "apt-get update && apt-get install -y ffmpeg"
})- comment: 为任务添加描述性注释
py
Task.init(comment="Fix overfitting: added dropout=0.5 and weight decay")- connect_cloud_storage: 连接云存储桶到任务
py
Task.init(connect_cloud_storage={
"s3://data-bucket": "read", # 只读访问
"gs://models-bucket": "write" # 读写访问
})- disabled: 全局禁用 ClearML,默认值: False
py
# 通过环境变量控制
disabled = os.environ.get("CLEARML_DISABLED", "false").lower() == "true"
Task.init(disabled=disabled)完整初始化示例:
py
from clearml import Task
task = Task.init(
project_name="Vision Models",
task_name="ResNet-34 Training",
task_type=Task.TaskTypes.training,
tags=["resnet", "imagenet", "experiment-v2"],
reuse_last_task_id=False,
continue_last_task=False,
output_uri="s3://company-ml-bucket/clearml",
artifacts_uri="s3://company-models-bucket/resnet",
auto_connect=True,
auto_connect_frameworks={
"pytorch": ["*.pt", "*.pth"],
"tensorboard": False,
"matplotlib": {"max_history": 10},
"pillow": True
},
auto_resource_monitoring=True,
docker="pytorch/pytorch:1.12.1-cuda11.3-runtime",
system_tags=["production"],
comment="Training ResNet-34 on ImageNet with dropout regularization",
parent=None,
connect_cloud_storage={
"s3://imagenet-dataset": "read"
},
task_base_task_id=None,
disabled=False,
deferred_init=False,
force_single_instance=False
)
# 添加额外配置
task.set_input_variables({"dataset_size": 1281167})
task.set_output_model_id("resnet34-imagenet-v1")2.3 task.get_logger()
task.get_logger() 是 ClearML 实验跟踪系统的核心日志接口,提供统一 API 记录训练过程中的各类数据(
标量、图像、表格、3D 模型等),并在 ClearML Web UI 中提供交互式可视化。
2.3.1 基础使用模式
(1) 获取 Logger 实例
py
from clearml import Task
task = Task.init(project_name="my_project", task_name="my_task")
logger = task.get_logger()(2) 基本记录模式
py
# 记录标量
logger.report_scalar(title="Loss", series="train", value=0.5, iteration=10)
# 记录图像
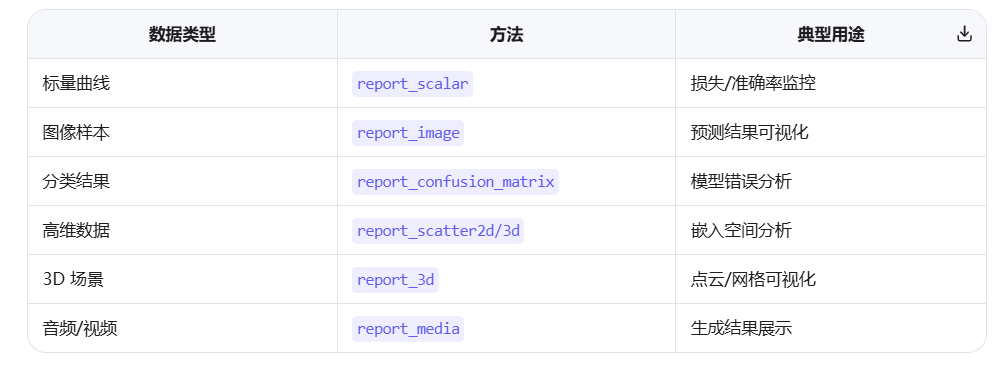
logger.report_image(title="Samples", series="validation", image=image_array, iteration=10)2.3.2 核心方法详解
(1) 标量记录 (report_scalar)
py
logger.report_scalar(
title, # 主标题(如 "Loss", "Accuracy")
series, # 子系列(如 "train", "val")
value, # 数值
iteration # 迭代步数
)示例:
py
for epoch in range(100):
train_loss = model.train()
val_acc = model.validate()
logger.report_scalar("Loss", "train", train_loss, epoch)
logger.report_scalar("Accuracy", "validation", val_acc, epoch)Web UI 效果 :
自动创建带对比曲线的图表,支持缩放/导出
标量数据(Scalars)→ SCALARS 标签页, 通过折线图绘制
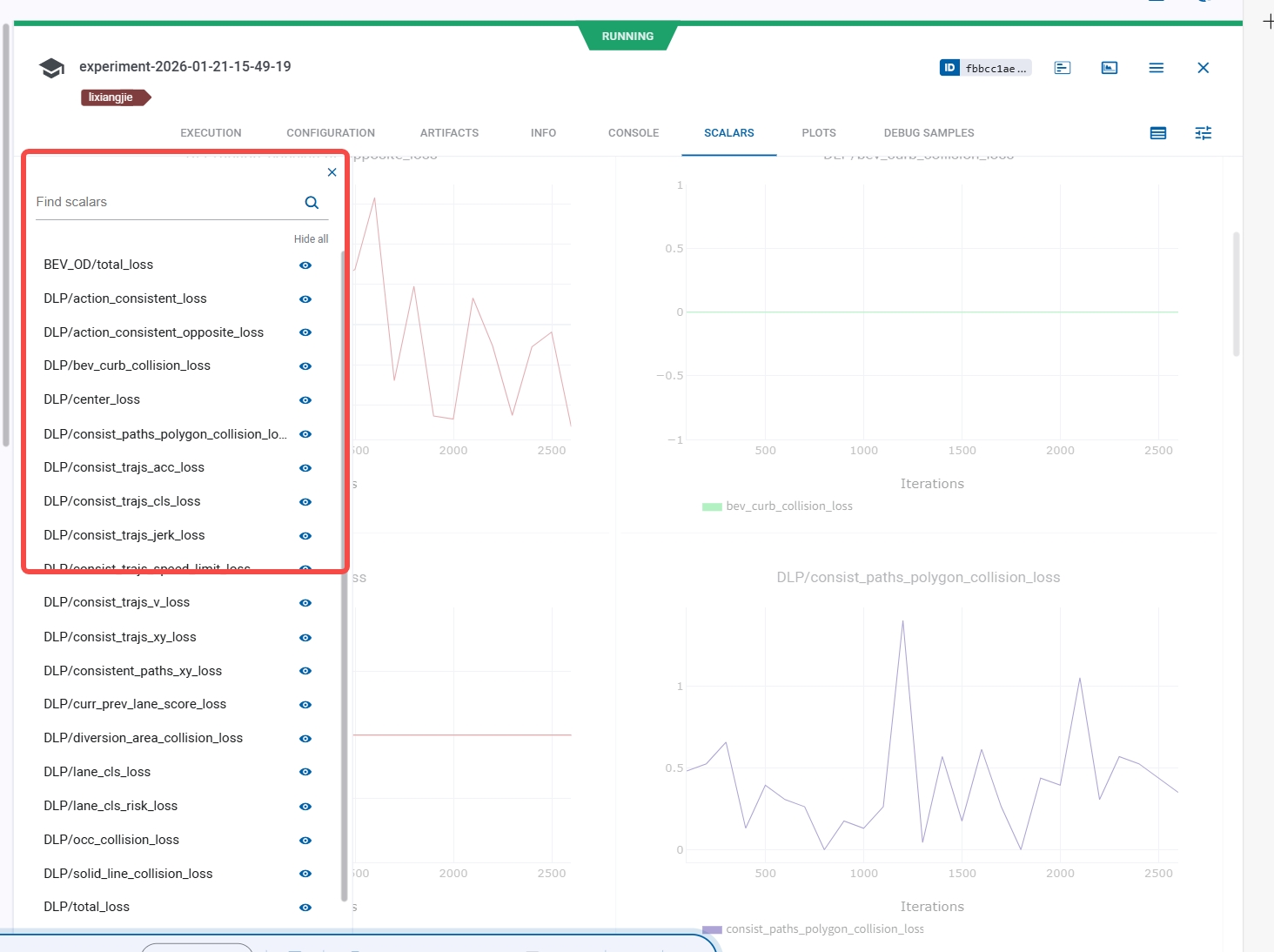
左侧还可以筛选要展示的标量
位置:任务详情页 → SCALARS 标签
显示内容:
- 训练/验证损失曲线
- 准确率/精确率/召回率等指标
- 学习率变化
- 梯度范数/权重更新统计
交互功能:
- ✅ 曲线对比:勾选多个系列,自动叠加显示
- ✅ 缩放:鼠标拖选区域放大
- ✅ 平滑:滑动条调整曲线平滑度
- ✅ 导出:CSV/JSON/PNG 格式导出
- ✅ 指标对比:多任务间指标直接比较
(2) 图像记录 (report_image)
py
logger.report_image(
title,
series,
iteration,
image=None, # numpy array/PIL image/path
matrix=None, # 3D 矩阵(如点云)
max_image_history=5, # 保留的历史图像数
delete_after_upload=False
)示例:
py
# 记录预测样本
for i, (img, pred) in enumerate(zip(images, predictions)):
fig = plot_prediction(img, pred)
logger.report_image("Predictions", f"sample_{i}", iteration=epoch, image=fig)
# 记录注意力图
attention_map = model.get_attention_map(input)
logger.report_image("Attention", "head_0", iteration=step, image=attention_map)(3) 表格/混淆矩阵记录
- 混淆矩阵 (report_confusion_matrix)
py
logger.report_confusion_matrix(
title,
series,
iteration,
matrix, # 2D numpy array
xaxis, # x轴标签列表
yaxis, # y轴标签列表
comment=None
)示例:
py
cm = sklearn.metrics.confusion_matrix(y_true, y_pred)
logger.report_confusion_matrix(
"Classification", "val",
iteration=epoch,
matrix=cm,
xaxis=[f"class_{i}" for i in range(10)],
yaxis=[f"class_{i}" for i in range(10)]
)- 通用表格 (report_table)
py
logger.report_table(
title,
series,
iteration,
table_plot, # pandas DataFrame 或 2D 列表
extra_layout=None # Plotly 布局参数
)示例:
py
import pandas as pd
metrics_df = pd.DataFrame({
"Metric": ["Precision", "Recall", "F1"],
"Value": [0.85, 0.76, 0.80]
})
logger.report_table("Metrics", "summary", iteration=epoch, table_plot=metrics_df)2.3.3 高级可视化
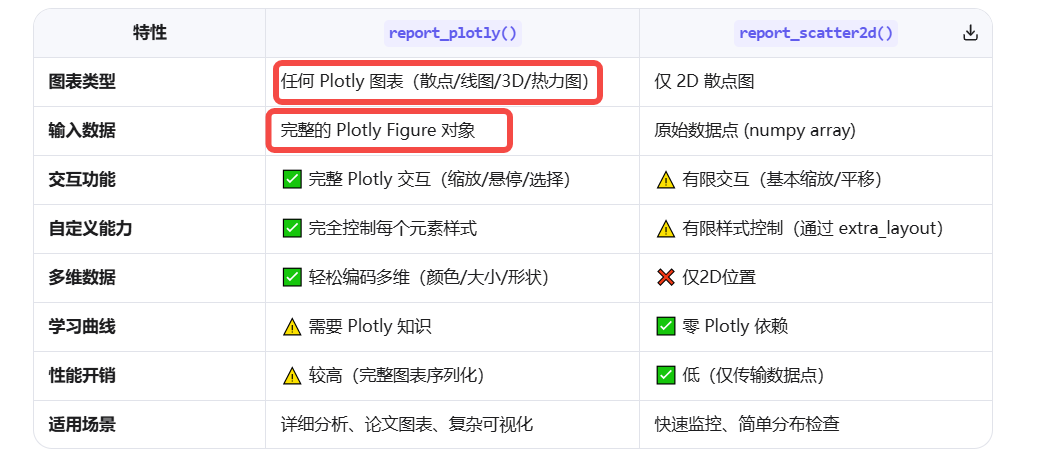
2.3.3.1 report_plotly() 和 report_scatter2d()
这两者都是 ClearML 用于记录 2D 散点图的方法,但设计理念和适用场景截然不同。以下是深入对比和使用指南。
report_plotly() - 全功能交互式图表
1). 核心功能
- 记录完整的 Plotly 图表对象
- 保留所有 Plotly 交互功能(缩放、悬停、选择、图例切换)
- 支持任何 Plotly 图表类型(散点、线图、热力图、3D、子图等)
- 适合复杂、定制化的可视化需求
2). 函数签名
py
logger.report_plotly(
title: str,
series: str,
figure: Union[plotly.graph_objs.Figure, plotly.graph_objs._figure.FigureWidget],
iteration: Optional[int] = None,
xaxis: str = 'x axis',
yaxis: str = 'y axis',
mode: str = 'lines',
comment: str = ''
)3). 完整使用示例
py
import plotly.graph_objects as go
import numpy as np
from clearml import Task
task = Task.init(project_name="Plotly Demo", task_name="Interactive Charts")
logger = task.get_logger()
# 生成示例数据
n_points = 100
x = np.random.randn(n_points)
y = np.random.randn(n_points)
z = np.random.rand(n_points) # 用于颜色/大小
labels = np.random.choice(['Class A', 'Class B', 'Class C'], n_points)
# 创建 Plotly 散点图
fig = go.Figure()
# 为每个类别添加轨迹(保留图例交互)
for label in np.unique(labels):
mask = labels == label
fig.add_trace(go.Scatter(
x=x[mask],
y=y[mask],
mode='markers',
marker=dict(
size=10 + 20 * z[mask], # 动态大小
color=z[mask], # 使用第三维作为颜色
colorscale='Viridis',
showscale=True,
colorbar=dict(title="Value")
),
name=label,
text=[f"Sample {i}<br>Value: {z[i]:.2f}" for i in range(n_points) if mask[i]],
hovertemplate="<b>%{text}</b><br>X: %{x:.2f}<br>Y: %{y:.2f}<br>Size: %{marker.size}"
))
# 设置布局(完全自定义)
fig.update_layout(
title="Interactive 2D Scatter with Plotly",
xaxis_title="Feature 1",
yaxis_title="Feature 2",
legend_title="Classes",
template="plotly_white",
hovermode='closest',
width=800,
height=600
)
# 添加注释
fig.add_annotation(
x=0, y=0,
text="Center Point",
showarrow=True,
arrowhead=2
)
# 记录到 ClearML
logger.report_plotly(
title="Advanced Visualization",
series="interactive_scatter",
figure=fig,
iteration=0
)4). 优势特点
• ✅ 完全保留 Plotly 交互:缩放、平移、悬停显示、图例切换
• ✅ 精细控制:每个元素样式、动画、注释均可定制
• ✅ 多维数据:轻松编码第三/四维度(颜色/大小/形状)
• ✅ 复杂布局:支持子图、双Y轴、3D视图等
• ✅ 专业外观:出版级图表质量
2.3.3.2 report_scatter2d() - 简单快速的散点图
1). 核心功能
- 专门用于记录 2D 散点图
- 接受原始数据点,由 ClearML 生成图表
- 适合简单、标准化的散点图需求
无需熟悉 Plotly,学习曲线平缓
2). 函数签名
py
logger.report_scatter2d(
title: str,
series: str,
scatter: np.ndarray, # shape: [n_points, 2]
iteration: int,
xaxis: str = 'x axis',
yaxis: str = 'y axis',
mode: str = 'lines',
comment: str = '',
extra_layout: Optional[dict] = None
)3). 完整使用示例
py
import numpy as np
from clearml import Task
task = Task.init(project_name="Scatter2d Demo", task_name="Simple Charts")
logger = task.get_logger()
# 生成示例数据
n_points = 50
x = np.random.randn(n_points)
y = np.random.randn(n_points)
# 创建2D散点数据 (shape: [n_points, 2])
scatter_data = np.column_stack((x, y))
# 记录到 ClearML
logger.report_scatter2d(
title="Basic Visualization",
series="simple_scatter",
scatter=scatter_data,
iteration=0,
xaxis="Feature 1",
yaxis="Feature 2",
mode="markers", # 'lines', 'markers', or 'lines+markers'
extra_layout={
'showlegend': True,
'legend': {'x': 1, 'y': 1},
'plot_bgcolor': 'white'
}
).4). 优势特点
✅ 极简API:只需提供数据点,无需构建图表对象
✅ 自动优化:ClearML 自动处理缩放/标记
✅ 轻量级:无 Plotly 依赖,内存占用小
✅ 快速记录:适合高频记录(如每batch)
✅ 标准化:保持团队内图表风格一致
report_plotly() 和 report_scatter2d()的区别
2.3.3.3 曲面图 (report_surface) 和 直方图 (report_histogram)**
py
logger.report_histogram(
title="Weight Distribution",
series="conv1",
iteration=epoch,
values=layer_weights, # 1D tensor
xaxis="weight value",
yaxis="count"
)
py
logger.report_surface(
title="Loss Landscape",
series="surface",
iteration=epoch,
matrix=loss_landscape, # 2D 矩阵
xaxis="param_1",
yaxis="param_2",
zaxis="loss"
)2.3.3.4 3D 模型与点云
py
logger.report_3d(
title="Point Cloud",
series="scene",
iteration=step,
points=point_cloud, # shape: [N, 3]
colors=point_colors, # shape: [N, 3] RGB
labels=point_labels, # 分类标签
camera_position=None # 相机位置
)- 支持格式:numpy arrays, Open3D 点云, MeshLab 网格
2.3.3.5 多媒体记录
- 音频 (report_media)
py
logger.report_media(
title="Audio Samples",
series="generated",
iteration=epoch,
local_path="output/audio.wav", # 本地文件路径
delete_after_upload=False
)- 视频
py
# 保存为 mp4 后上传
generate_video(frames, "output/video.mp4")
logger.report_media("Training Dynamics", "episode", iteration=epoch, local_path="output/video.mp4")2.3.4 高级用法
2.3.4.1 动态更新图表
py
# 创建可更新的图表
logger.report_scalar(title="Dynamic Loss", series="live", value=0, iteration=0)
for step in range(1000):
loss = train_step()
# 更新同一图表
logger.report_scalar("Dynamic Loss", "live", loss, step)- 效果:Web UI 中图表实时更新,无需刷新页面
2.3.4.2 自定义布局
py
# 设置图表布局
layout = {
"title": "Custom Loss Curve",
"xaxis": {"title": "Epochs"},
"yaxis": {"title": "Loss Value", "type": "log"},
"legend": {"x": 0, "y": 1}
}
logger.report_scalar(
"Loss", "train",
value=loss,
iteration=epoch,
layout=layout
)2.3.4.3 与 TensorBoard 集成
py
# 自动转发 TensorBoard 事件
task.set_tensorboard_auto_update(True) # 启用自动同步
# 或手动同步
from clearml import OutputModel
output = OutputModel(task=task)
output.update_weights(model.state_dict()) # 自动记录权重分布2.3.4.4 性能优化技巧
- 批量报告
py
# 避免高频调用(每步都报告)
if step % 100 == 0:
logger.report_scalar("Loss", "train", loss, step)- 异步上传
py
# 启用后台上传
logger.set_default_upload_destination(
uri="s3://my-bucket/clearml/",
async_mode=True
)- 限制历史
py
# 限制标量历史
logger.set_default_limits(
scalar_history=1000, # 保留1000个点
image_history=10 # 每序列10张图
)2.3.4.5 典型工作流
py
def train_model():
task = Task.init(project_name="Autonomous Driving", task_name="BEV Segmentation")
logger = task.get_logger()
# 记录超参数
task.connect(vars(args), name="hyperparams")
# 训练循环
for epoch in range(args.epochs):
# 1. 记录标量
train_loss, val_iou = train_epoch()
logger.report_scalar("Loss", "train", train_loss, epoch)
logger.report_scalar("IoU", "validation", val_iou, epoch)
# 2. 每5个epoch记录样本
if epoch % 5 == 0:
sample_batch = get_validation_samples()
for i, (bev_gt, bev_pred) in enumerate(zip(sample_batch["gt"], sample_batch["pred"])):
# 3. 记录BEV分割结果
fig = plot_bev_comparison(bev_gt, bev_pred)
logger.report_image(f"BEV Samples", f"sample_{i}", epoch, image=fig)
# 4. 记录混淆矩阵
if i == 0: # 只记录第一个样本的详细统计
cm = compute_confusion_matrix(bev_gt, bev_pred)
logger.report_confusion_matrix(
"Segmentation", "class_metrics",
iteration=epoch,
matrix=cm,
xaxis=CLASSES,
yaxis=CLASSES
)
# 5. 每10个epoch记录3D场景
if epoch % 10 == 0:
point_cloud = get_point_cloud_sample()
logger.report_3d("Scene", "point_cloud", epoch, points=point_cloud)
# 6. 记录最终模型
task.upload_artifact("final_model", model_state_dict)2.3.4.6 与 Web UI 的交互
实时监控:
- 训练时打开 ClearML Web UI
- 查看动态更新的图表和样本
实验对比: - 选择多个任务
- 比较标量曲线、参数配置、结果图像
调试支持: - 点击图像查看原始分辨率
- 混淆矩阵中点击单元格查看对应样本
- 3D 点云支持交互式旋转/缩放
报告生成: - 一键导出 PDF/CSV 报告
- 复制图表到 Jupyter Notebook
task.get_logger() 是 ClearML 实验跟踪的核心引擎,通过统一 API 记录全类型训练数据
终极技巧:结合 task.connect()(参数管理)和 task.get_logger()(训练监控),可实现完全自动化的实验跟踪,无需手动记录任何中间结果。这是工业级 MLOps 的标准实践。
2.3.5 WebUI显示位置
Web UI 导航路径
py
Projects → [Project Name] → [Task Name] →
├── SCALARS (标量指标)
├── PLOTS (图表/表格/3D)
├── DEBUG SAMPLES (样本/媒体)
├── CONSOLE (日志)
├── CONFIGURATION (参数)
└── ARTIFACTS (模型/文件)2.4 task.connect的使用
task.connect() 是 ClearML(原 Trains)实验跟踪系统的核心函数,用于建立 Python 变量和 ClearML 服务器之间的双向连接,实现参数自动同步、实验复现和远程控制功能。
2.4.1 基础用法
(1) 基本语法
py
task.connect(object, name=None, section=None)(2) 参数说明
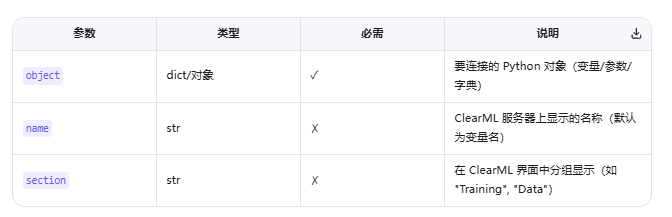
(3) 简单示例
py
from clearml import Task
task = Task.init(project_name="my_project", task_name="my_task")
# 连接字典
params = {"learning_rate": 0.001, "batch_size": 32}
task.connect(params, name="hyperparams")
# 连接普通变量
epoch = 100
task.connect(epoch, "training_epochs") # 注意:需要提供 name 参数2.4.2 高级用法
1). 连接 argparse 参数(最常用场景)
py
import argparse
from clearml import Task
parser = argparse.ArgumentParser()
parser.add_argument("--lr", type=float, default=0.001)
parser.add_argument("--batch_size", type=int, default=32)
args = parser.parse_args()
task = Task.init(project_name="my_project", task_name="my_task")
task.connect(vars(args), name="training_args") # 自动同步所有参数- ✅ 关键点:vars(args) 将 Namespace 转为字典
- ✅ 效果:
- ClearML 服务器自动记录所有命令行参数
- 在 ClearML Web UI 可直接修改参数并重新运行
- 支持参数对比和版本控制
2) 连接环境变量
py
import os
from clearml import Task
task = Task.init(project_name="my_project", task_name="my_task")
task.connect(dict(
HOSTNAME=os.environ.get("HOSTNAME", "unknown"),
CUDA_VISIBLE_DEVICES=os.environ.get("CUDA_VISIBLE_DEVICES", ""),
), name="environment")3). 连接 URL 链接(增强可追溯性)
py
# 阿里云训练任务链接
DLC_JOB_ID = os.environ.get("DLC_JOB_ID")
if DLC_JOB_ID:
ppu_link = f"https://pai.console.aliyun.com/#/dlc/jobs/{DLC_JOB_ID}/overview"
task.connect(dict(ppu_link=ppu_link), name="ppu_link")效果:在 ClearML Web UI 中显示可点击的链接
4). 嵌套字典连接
py
# 复杂配置
config = {
"data": {
"train_ratio": 0.8,
"augmentation": True
},
"model": {
"num_layers": 12,
"hidden_dim": 768
}
}
task.connect(config, name="full_config")2.4.3 webUI的显示
connect 的clearml上的参数,显示在WebUI页面的
CONFIGURATION这个tab也是,左侧是定义的参数类别,右侧可以显示各个参数的值
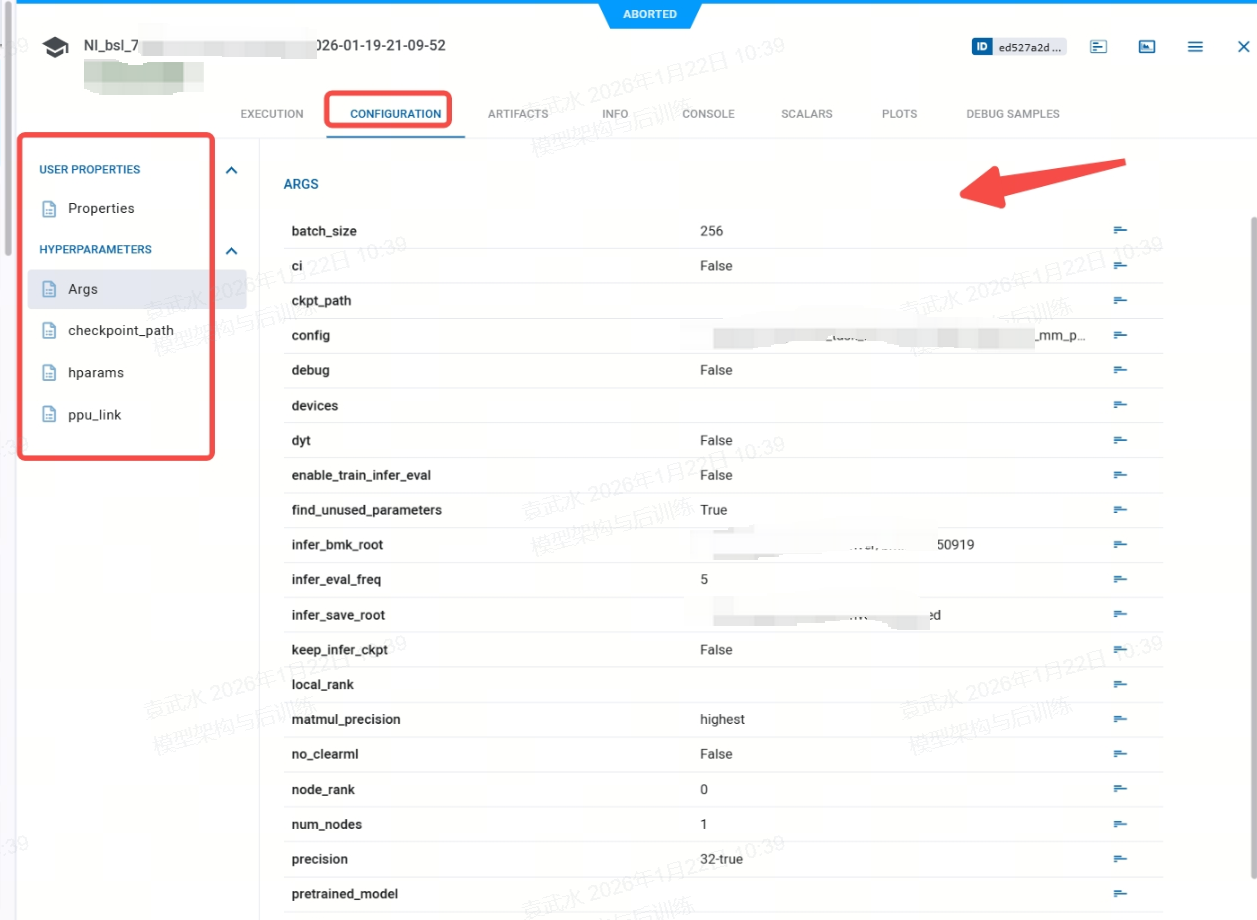
2.5 Task 对象获取
在 ClearML 中,有多种方式获取 Task 实例,适用于不同使用场景。以下是所有官方支持的方法及其典型应用场景:
2.5.1 主要获取方法
(1)Task.init() - 创建新任务(最常用)
py
from clearml import Task
task = Task.init(
project_name="My Project",
task_name="Experiment ABC",
task_type=Task.TaskTypes.training, # training|testing|inference|data_processing
tags=["resnet", "v1"],
reuse_last_task_id=False, # 总是创建新任务
output_uri="s3://my-bucket/results" # 可选,指定输出存储
)- 用途:训练开始时初始化新实验
- 返回:新创建的 Task 实例
- 关键参数:
reuse_last_task_id: False=总是新任务,True=复用上次任务IDcontinue_last_task: 继续上次任务(保留历史指标)
(2). Task.current_task() - 获取当前任务
py
task = Task.current_task()
if task:
logger = task.get_logger()
logger.report_scalar("Loss", "train", 0.5, iteration=10)
else:
print("No active ClearML task")用途:在任何地方获取当前活动的任务
- 返回:当前上下文中的 Task 实例,无活动任务时返回 None
- 典型场景:
- 训练循环中的指标记录
- 自定义回调函数
无法访问原始 task 变量的代码位置
(3). Task.get_task() - 通过标识获取现有任务
py
# 通过任务ID获取
task = Task.get_task(task_id="a1b2c3d4e5")
# 通过任务名和项目名获取(获取最新匹配任务)
task = Task.get_task(
project_name="CV Projects",
task_name="ResNet Training"
)
# 通过标签过滤
task = Task.get_task(
project_name="NLP",
task_name="BERT",
tags=["production"]
)- 用途:访问历史任务或远程任务
- 参数:
- task_id: 任务唯一ID(最可靠)
- task_name + project_name: 任务名称和项目
- tags: 标签过滤
- status: 任务状态("created"|"queued"|"in_progress"|"stopped"|"published")
- 返回:匹配的第一个任务,无匹配时抛出异常
(4)Task.get_tasks() - 获取多个任务
py
tasks = Task.get_tasks(
project_name="Object Detection",
task_name="YOLO",
status=["stopped", "published"],
page_size=20,
order_by="-created" # 按创建时间倒序
)
# 打印任务信息
for t in tasks:
print(f"Task: {t.name}, ID: {t.id}, Status: {t.status}")- 用途:批量操作、实验对比、自动化分析
- 返回:Task 对象列表
- 高级过滤:
- created_after: 日期字符串 "2023-01-01"
- system_tags: 系统标签(如"pipeline", "archived")
- only_fields: 仅返回特定字段,提升性能
(5) 从任务 URL 获取
py
task_url = "https://app.clear.ml/projects/a1b2c3/tasks/d4e5f6"
task_id = task_url.split("/")[-1]
task = Task.get_task(task_id=task_id)- 用途:从 Web UI 链接快速获取任务
- 技巧:ClearML Web UI 中的任何任务页面 URL 都包含 task_id
2.5.2 方法对比与选择指南
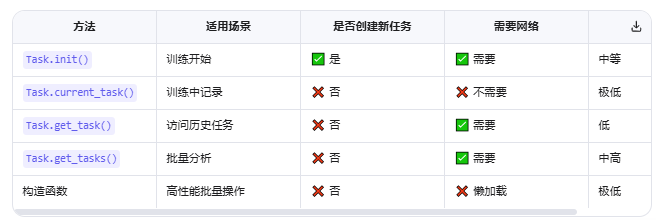
2.5.3 常见问题
- 错误 1: 忘记检查 None
py
# 错误
task = Task.current_task()
task.get_logger().report_scalar(...) # 可能抛出 AttributeError
# 正确
task = Task.current_task()
if task:
task.get_logger().report_scalar(...)- 错误 2: 重复初始化
py
# 错误:多次调用 init
task1 = Task.init(...)
task2 = Task.init(...) # 会创建第二个任务!
# 正确:单例模式
if not Task.current_task():
task = Task.init(...)
else:
task = Task.current_task()💡 黄金法则:在一个训练脚本(任务重)中,
只应有一次 Task.init() 调用,其他位置使用 Task.current_task() 获取实例。这样既能保证实验记录完整,又能避免意外创建多个任务。
3 示例说明:
(1) 在模型训练的入口,比如train.py 文件中,定义如下代码
py
import os
import torch.distributed as dist
import argparse
parser = argparse.ArgumentParser()
parse.add_argument('--no-clearml', action='store_true', help='禁用ClearML实验跟踪')
parse.add_argument('--exp-desc', type=str, default='', help='实验描述')
parse.add_argument('--project_group', type=str, default='test_exp', help='ClearML项目组名称')
parse.add_argument('--exp_name', type=str, default='train', help='实验名称')
# 在训练脚本中初始化ClearML(仅rank 0)
args = parser.parse_args()
def _is_master_node():
# 1. 检查环境变量 (优先级最高)
rank_env = os.environ.get("RANK") or os.environ.get("NODE_RANK") or os.environ.get("SLURM_PROCID")
if rank_env is not None:
try:
return int(rank_env) == 0
except ValueError: # 仅捕获类型转换错误
return str(rank_env) == "0"
# 2. 检查PyTorch分布式环境
if dist.is_available() and dist.is_initialized():
return dist.get_rank() == 0
# 3. 非分布式环境默认为主节点
return True
def train(args):
args.no_clearml = getattr(args, "no_clearml", False)
output_uri = None
if _is_master_node() and not args.no_clearml:
try:
experiment_group = getattr(args, "project_group")
ws_name = os.popen("whoami").read().split("\n")[0]
experiment_desc = getattr(args, "exp_description", "")
time_str = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
experiment_name = getattr(args, "exp_name", "experiment")
experiment_run_name = f"{experiment_name}-{time_str}"
task = Task.init(
project_name=experiment_group,
task_name=experiment_run_name,
tags=[ws_name],
output_uri=output_uri,
auto_connect_frameworks={
"pytorch": ["*.pt"],
"tensorboard": False,
"matplotlib": False,
"pandas": False,
},
reuse_last_task_id=False, # 禁用任务ID复用,避免冲突
)
task.set_comment(experiment_desc)
task.connect(vars(args), name="training_args")以上代码,实现在分布式训练环境中智能初始化 ClearML 实验跟踪系统的功能,专为多 GPU/多节点训练场景设计。其核心思想是仅在主节点初始化 ClearML,同时提供灵活的命令行控制。
pytorch: ["*.pt"]:仅自动记录 PyTorch 模型文件- 其他框架tensorboard、matplotlib等设为 False:
避免与 ClearML 本身功能冲突,减少性能开销 reuse_last_task_id=False:确保每次运行创建新实验,避免意外复用tags=[ws_name]:标记实验作者,便于团队筛选
记录训练的参数,便于复现
py
# 将参数自动连接到 ClearML
task.set_comment(experiment_desc)
task.connect(vars(args), name="training_args")- 所有命令行参数自动同步到 ClearML 服务器
- 实现:实验可复现性 + 参数对比分析 + 超参数优化支持
(2) 在模型出现loss的位置,通过clearml记录各个loss 变化,比如在model.py中
py
from clearml import Task
# ========== 7. 训练循环 ==========
task = Task.current_task()
logger = task.get_logger()
total_steps = 0
print("🚀 开始训练...")
for epoch in range(args["epochs"]):
# --- 训练阶段 ---
model.train()
train_loss = 0
correct = 0
total = 0
for step_id, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
# 累计指标
train_loss += loss.item()
if _is_master_node():
# 记录 batch 损失
logger.report_scalar(
title="Batch Loss",
series="train",
value=loss.item(),
iteration= step_id,
)
# 每 log_interval 个 batch 记录一次图片
if batch_idx % args["log_interval"] == 0:
print(f"Epoch [{epoch+1}/{args['epochs']}], Step [{batch_idx}/{len(trainloader)}], Loss: {loss.item():.4f}")
# 随机选择 16 张图片可视化
idx = torch.randperm(inputs.size(0))[:16]
sample_images = inputs[idx]
sample_labels = targets[idx]
sample_preds = predicted[idx]
# 生成并记录图像
fig = plot_images(sample_images, sample_labels, sample_preds)
if _is_master_node():
logger.report_matplotlib_figure(
title="Training Samples",
series=f"epoch_{epoch}_step_{batch_idx}",
figure=fig,
iteration=step_id
)
total_steps += 1
# --- 验证阶段 ---
model.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in testloader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
# 计算平均指标
train_acc = 100. * correct / total
test_acc = 100. * correct / total
avg_train_loss = train_loss / len(trainloader)
avg_test_loss = test_loss / len(testloader)
# 记录 epoch 指标
if _is_master_node():
logger.report_scalar("Loss", "train", avg_train_loss, epoch)
logger.report_scalar("Loss", "test", avg_test_loss, epoch)
logger.report_scalar("Accuracy", "train", train_acc, epoch)
logger.report_scalar("Accuracy", "test", test_acc, epoch)
# 记录学习率
current_lr = optimizer.param_groups[0]['lr']
if _is_master_node():
logger.report_scalar("Learning Rate", "SGD", current_lr, epoch)
# ========== 8. 记录最终结果 ==========
final_results = {
"final_train_acc": train_acc,
"final_test_acc": test_acc,
"final_train_loss": avg_train_loss,
"final_test_loss": avg_test_loss
}
logger.report_table(
title="Final Results",
series="metrics",
table_plot=pd.DataFrame([final_results]),
iteration=args["epochs"]
)
print("✅ 训练完成!实验已保存到 ClearML")
task.close() # 显式关闭任务- 在主进程时,通过
logger.report_scalar, 记录每个step 各个loss的变化 - 也可以记录训练过程中,可视化的图片信息,通过
logger.report_matplotlib_figure - 其中通过
Task.current_task(), 可以在任何地方(项目的任何文件)获取当前活动的task