1 概述

Next Token: 从生成的概率分布里面选择唯一Token。如何选择,则涉及Decoding技术。
2 Greedy Decoding

- 优点: 简单易实现、计算量少,速度快;
- 缺点: 缺乏多样性,无法回溯其他选择、容易陷入局部最优 (错过整体概率更高的句子)、容易陷入重复循环、不通顺。
3 Beam Search

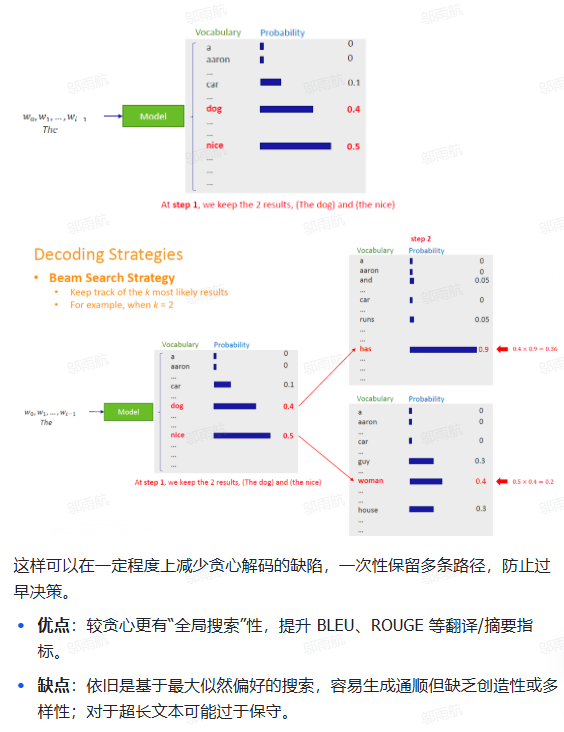
Beam Search的核心步骤:

好处: 能够求得整体序列的概率值,解决了重复循环 、不通顺 、陷入局部最优 这几个问题。
缺点: 无法及时 Decoding,耗时更长。
概述: 每一步的Token -> 整体序列的Token。

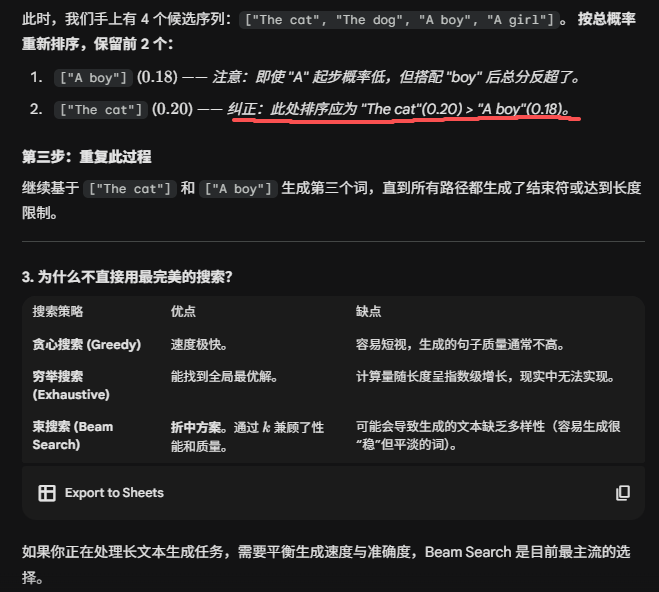
3 Top-K 采样
概述: Top-K采样是随机采样的一种优化策略。每个时间步,只保留概率最高的k个Token ,让模型只在这k个候选里进行随机抽取。与贪心解码(相当于k=1)相比,更能避免一味选最热门候选导致的重复或过度保守,也减少了从非常罕见词采样的风险。
例子:


缺点: 合适的 K 值很难定义,K 越大,效果不一定就越好。
4 Top-P 采样
概述:
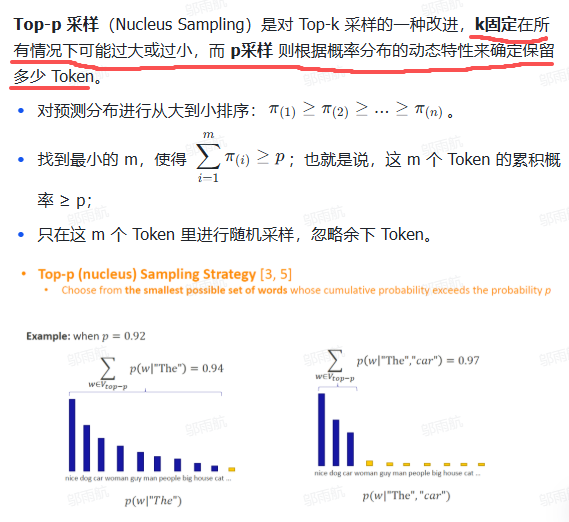
例子:


5 Temperature 采样
Temperature (温度) 是最常与 Top-k / Top-p 一起使用的另一个调控参数。它通过对 logits 值进行缩放,改变分布的 "尖锐度" 或 "平坦度" 。令模型输出的 logits 向量为 z ,则普通 softmax 概率是:

