1.程序执行
(1)加载环境
source ./ci/toolchain_env.sh
(2)执行一个case,用rtlsim来执行
./ci/blackbox.sh --clusters=1 --cores=4 --warps=4 --threads=4 --driver=rtlsim --app=vecadd
(3)看波形
gtkwave -o trace.vcd
(4)run.log转成csv文件, 按照PC指令顺序列出每条具体的指令
./ci/trace_csv.py -trtlsim run.log -otrace_rtlsim.csv
2.Vortex整体架构
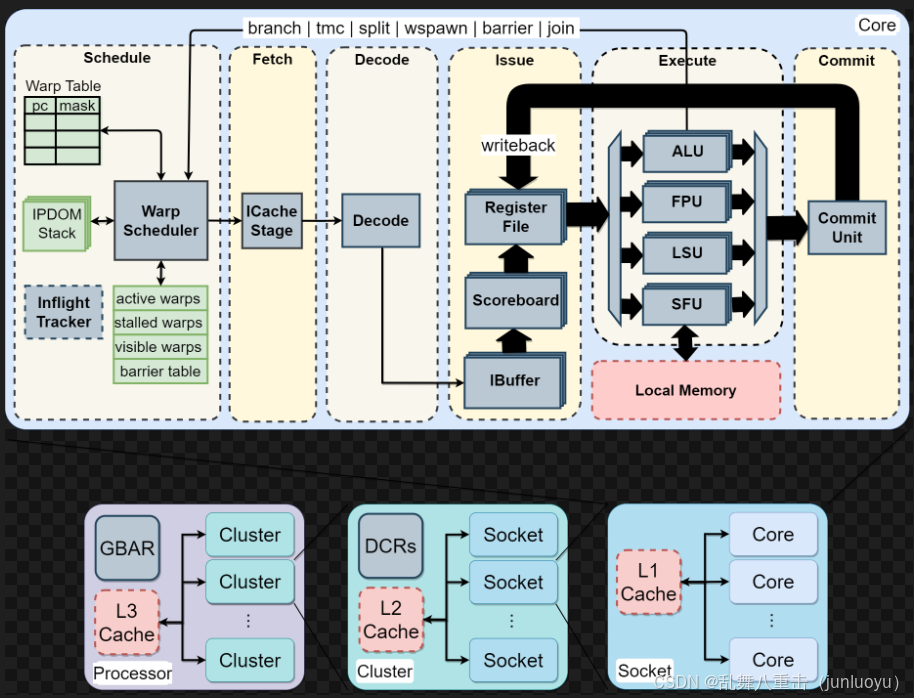
(1)先看Vortex整体架构,首先是core,如果开启L1 Cache的话,所有core会share L1 Cache,好像没有blackbox.sh里面找到L1 Cache的开关,先默认它是打开的;多个core组成一个socket,而socket与socket之间如果开启L2 Cache会share L2 Cache,在blackbox.sh明确有说明可以使用L2cache 来enable the shared l2 cache among the Vortex cores;多个Socket组成一个Cluster,而Cluster与Cluster可以share L3 Cache,在blackbox.sh明确有说明可以使用L3cache 来enable the shared l3 cache among the Vortex clusters。
也可以在blackbox.sh里面使用 --clusters=x,--cores=x来限制。
(2)再来从左到右看每一个模块的功能。
第一块是warp scheduler,可以理解为一个调度器,它会和其他模块交互,来唤醒对应的warp。这里需要强调的是IPDOM Stack,它是遇到SFU返送回来的split指令(假如有多个线程同时执行,在某一个if判断条件处有不同分支,就会发送split指令,这个时候需要把不同分支的线程信息的tmask以及split指令的下一条PC值写到这里面)发挥作用,可以理解就像软件遇到一个函数,需要把函数的指针写到一个栈里面,函数执行完成再读这个指针恢复上下文信息。 会把warp分为四种不同的warps,分别是active激活的,stall暂停的,visable可见的,barrier阻挡的(比如某个数据要更新,发了barrier指令,其他指令都需要暂停,等数据更新完才能正常工作)。
这里还有一个warp table,对于每一个PC都有自己的mask,一个warp里面通常有多个线程,这个掩码是用来指示线程是否激活(不确定)。
第二块是Fetch,就是把Warp sheduler抓到的指令写到一块指令cache里面(ICache)。
第三块是Decode,就是指令译码,按照riscv指令格式来译码。
第四块是Issue,Decode的输入首先到Ibuffer缓冲,再送到Scoreboard,感觉scoreboard是个很奇怪的东西,在NPU里面好像没有看到过,它其实可以理解为一个打分表,用来解决写后读、写后写 等问题。在Issue里面还会去控制regsiter file,众所周知,GPU为每一个线程都维护了自己的一块寄存器表来使用,在硬件上面其实就是一块4个Bank的SRAM来实现。
第五块是Execute,里面包含四个模块,分别是ALU,看名字就是一个矩阵计算的;FPU,看名字是一个浮点数计算用的;LSU,不知道;SFU,这里用来做了6条指令,就是图片中的branch,tmc,split,wspawn,barrierr,join,他们的实现都在SFU去完成。
这里还有一块和Local Memory的交互。
第六块是一个commit ,它会把数据通过write back回写到Issue的register file,这个就是数据的回写。
3.Cache结构
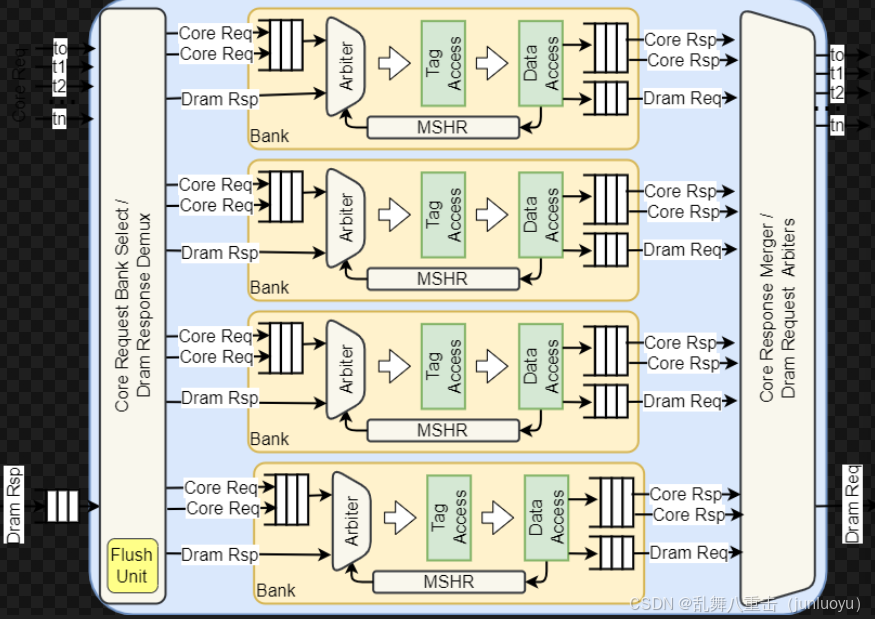
这里的cache还是很复杂的,我感觉比视频编解码里面帧间预测的cache设计复杂很多,因为编解码里面的cache只是抓参考帧的数据,不会涉及到多个核之间的交互,而GPGPU的cache会涉及到L1 L2 L3 cache。不过按照我的理解,在GPGPU里面,很多cache的管理不是通过硬件去实现的,而是在软件通过指令去完成,这可能是因为GPGPU里面纯用硬件去实现硬件cache的成本过高了。
mshr其实是为了非阻塞cache准备的,也就是允许不满足一个地址请求的时候接着响应之后的请求。MSHR就是"Miss-status Handling Register",用来记录每一项未完成的事务,包括失效地址、关键字信息以及重命名寄存器信息 。在cache中,当发生cache miss时,MSHR用于存储之前要访问但未在cache中的请求。具体操作如下:当cache未命中时,首先搜索MSHR看是否有相同的Block也是处于缺失状态,如果找到了,就将当前请求合并到之前的请求中,一起解决历史和此次缺失;如果没有找到,且MSHR还有余位,则分配一个位置;如果没有余位,则发生资源冲突 。所以MSHR的作用是提高缓存系统的效率,允许在处理一个缓存未命中请求的同时,继续响应其他的存储访问请求 。当缓存未命中被满足后,MSHR会被释放,从而可以处理新的缓存未命中请求 。在现代缓存设计中,MSHR的存在使得缓存系统可以是非阻塞或者无锁的,提高了处理器的性能 。
接下来计划,是先看Execute里面的ALU单元,ALU用来处理算术单元和分支单元。
参考链接
环境搭建
https://blog.csdn.net/weixin_41029027/article/details/142668224?spm=1001.2014.3001.5502
scoreboard
https://zhuanlan.zhihu.com/p/1987631409838454164
https://zhuanlan.zhihu.com/p/1944809419641688801
cache
https://blog.csdn.net/weixin_41029027/article/details/140308133?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_41029027/article/details/140362696?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_41029027/article/details/140389611?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_41029027/article/details/141072411?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_55313207/article/details/155811480?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_55313207/article/details/155982887
https://zhuanlan.zhihu.com/p/1918984456628330681
https://zhuanlan.zhihu.com/p/20089628587
https://zhuanlan.zhihu.com/p/629237349
SFU
https://blog.csdn.net/weixin_55313207/article/details/156481015?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_55313207/article/details/156510243?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_55313207/article/details/156643114?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_55313207/article/details/156656438?spm=1001.2014.3001.5502