abstract
在:记录某大型风控系统调研中踩坑提到了采用了mysql的federated engine来实现贴源层相关数据的导入。 最近就发现了 mysql时不时因为oom kill被杀掉了,在16g的内存机器上使用15G左右:
shell
sudo dmesg -T | grep -i "killed process"
调查过程
查看日志
查看日志发现是在执行存储过程当中会失败,然后查看存储过程会生成类似的sql代码:
sql
INSERT INTO t_dp_i_import_collection_plan(xxx) --- 隐藏了
SELECT xxx --- 隐藏了
FROM import_collection_plan as t
where report_date = '2025-01-31'查看表大小:【估算】
sql
SELECT
TABLE_NAME AS `Table`,
ENGINE AS `Engine`,
ROUND((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024, 2) AS `Size_MB`,
ROUND(DATA_LENGTH / 1024 / 1024, 2) AS `Data_MB`,
ROUND(INDEX_LENGTH / 1024 / 1024, 2) AS `Index_MB`,
TABLE_ROWS AS `Est_Row_Count`
FROM
information_schema.TABLES
WHERE
TABLE_SCHEMA = 'xxx' -- 👈 替换为你的数据库名
ORDER BY TABLE_ROWS DESC然后发现:import_collection_plan 大概800w行,定义使用了federatedengine怀疑是这个导致的。
mysql的联邦表
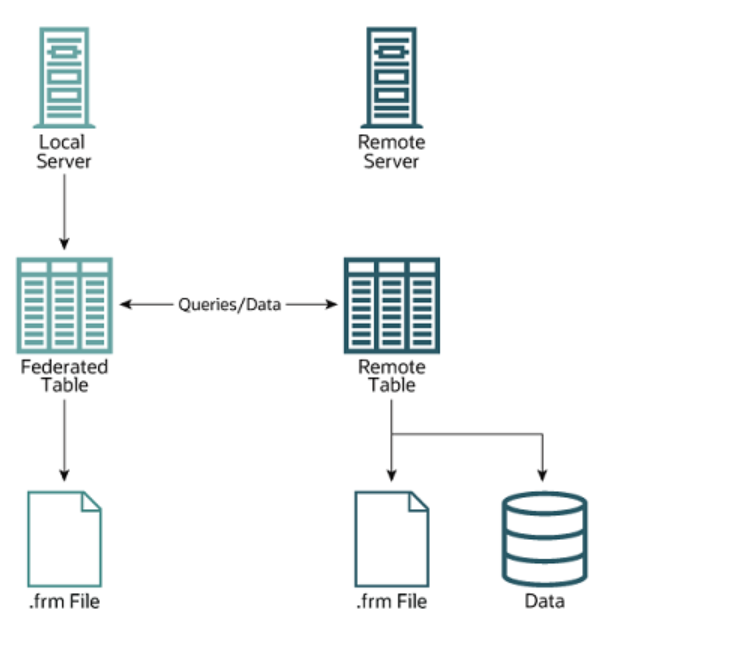
有一段关键的描述:
A FEDERATED table does not support indexes in the usual sense; because access to the table data is handled remotely, it is actually the remote table that makes use of indexes. This means that, for a query that cannot use any indexes and so requires a full table scan, the server fetches all rows from the remote table and filters them locally. This occurs regardless of any WHERE or LIMIT used with this SELECT statement; these clauses are applied locally to the returned rows.
Queries that fail to use indexes can thus cause poor performance and network overload. In addition, since returned rows must be stored in memory, such a query can also lead to the local server swapping, or even hanging.
可以看到他并不会进行索引或者条件的下推。 这个对于大表是非常危险的,而且会占用很大的内存进行本地的排序过滤。
我的测试
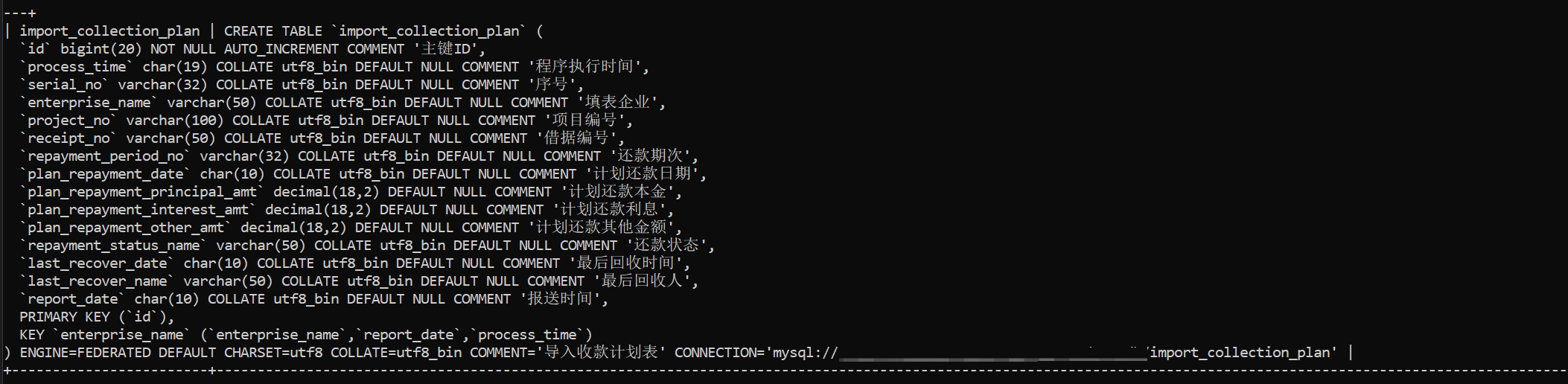
我自行在mac和win组成的局域网进行了测试,mac上存原始数据,数据500W,在win上创建的mysql服务器上创建联邦表:
CREATE TABLE `import_collection_plan` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`process_time` char(19) COLLATE utf8_bin DEFAULT NULL COMMENT '程序执行时间',
`serial_no` varchar(32) COLLATE utf8_bin DEFAULT NULL COMMENT '序号',
`enterprise_name` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '填表企业',
`project_no` varchar(100) COLLATE utf8_bin DEFAULT NULL COMMENT '项目编号',
`receipt_no` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '借据编号',
`repayment_period_no` varchar(32) COLLATE utf8_bin DEFAULT NULL COMMENT '还款期次',
`plan_repayment_date` char(10) COLLATE utf8_bin DEFAULT NULL COMMENT '计划还款日期',
`plan_repayment_principal_amt` decimal(18,2) DEFAULT NULL COMMENT '计划还款本金',
`plan_repayment_interest_amt` decimal(18,2) DEFAULT NULL COMMENT '计划还款利息',
`plan_repayment_other_amt` decimal(18,2) DEFAULT NULL COMMENT '计划还款其他金额',
`repayment_status_name` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '还款状态',
`last_recover_date` char(10) COLLATE utf8_bin DEFAULT NULL COMMENT '最后回收时间',
`last_recover_name` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '最后回收人',
`report_date` char(10) COLLATE utf8_bin DEFAULT NULL COMMENT '报送时间',
PRIMARY KEY (`id`),
KEY `enterprise_name` (`enterprise_name`,`report_date`,`process_time`)
) ENGINE=FEDERATED DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='导入收款计划表' CONNECTION='mysql://root:root@192.168.110.164:3106/xxx/import_collection_plan';后测试sql:
create table d select * from import_collection_plan
where report_date = '2023-02-21';在mac端,该表在report_date上有索引。 mac上执行上面语句约:0.6秒完成。
win上执行10分钟,且mysql内存从150M涨到1.6G,网络跑满:

查询验证
打开源端的genral log:
sql
set global general_log = ON
-- 输出到文件(默认)
SET GLOBAL log_output = 'FILE';
-- 或输出到 mysql.general_log 表(方便 SQL 查询)
SET GLOBAL log_output = 'TABLE';在本地执行查询:
INSERT INTO d select * from import_collection_plan
where report_date = '2023-02-18';在源端查看general log: 可以看到where条件并没有被下推:
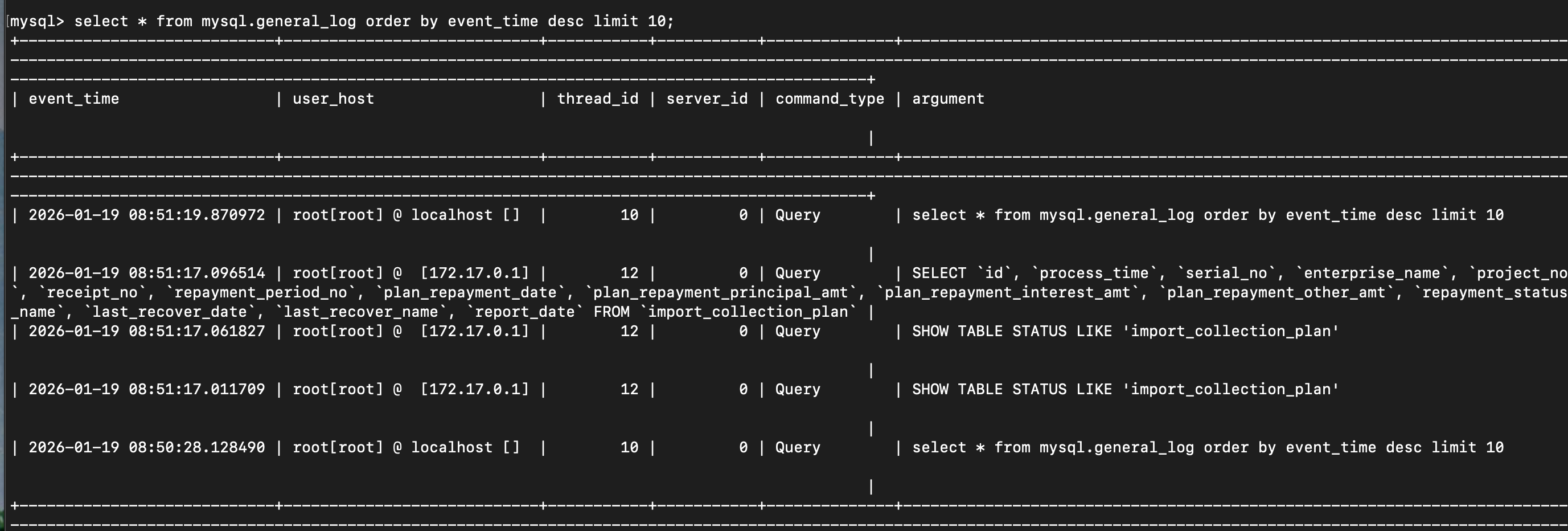

怎么解决
方案1 源端服务器创建视图
sql
-- 在 192.168.110.164 上执行
CREATE TABLE import_collection_plan_20230221 AS
SELECT * FROM import_collection_plan
WHERE report_date = '2023-02-21';如果该时间有变(我们场景,需要考虑周期性cron创建)
方案2 应用层同步
应用层查询数据后同步而不依赖federated engine.
方案3 CDC捕获关注表 同步到本地后查询
更多的测试和调查
我又尝试多问了下AI,这个到底要怎么解决,AI给我的答复是:
 可以看到这个
可以看到这个where clause pushdown 是 limited, 这个就比较奇怪了,所以我做了更多的测试和查看mysql源码:
Case 1: 源表有索引, 本地表没索引, 无法使用下推。会生成全表sql:select col1, col2 from tableA。
Case 2: 源表无索引, 本地表有索引, 本地使用下推 会生成sql:select col1, col2 from tableA where indexCol = 'x' ,但是源表 因为没索引会全表扫描。
Case 3: 源表有索引, 本地表有索引, 可以使用等值下推和< > 这种也行。
所以说最终的解决办法是源表和本地表都要加上索引才行。
注: federated engine无法在线加索引,需要重新创建并添加。
总结
本文对mysql federated engine 做了很多测试和研究,结论如下:
1,对生成发给源端的sql取决于:本地表定义。
2,对发给源端的sql在源端执行时,取决于源端自身的优化器和执行器。
3,建议2个表有同样的索引来激活where下推和索引下推。如果源表没有索引,源表会全表扫描。 如果本地表没有索引,发送给源表的就是一个不带where语句的查询,然后在本地进行过滤,会导致全表数据的网络发送和本地内存的大量使用。