社交媒体舆情监控系统
基于 Python Django 框架开发的社交媒体舆情监控与分析系统,支持微博、知乎等多平台数据采集、情感分析、可视化展示,为用户提供全面的舆情监控解决方案。
目录
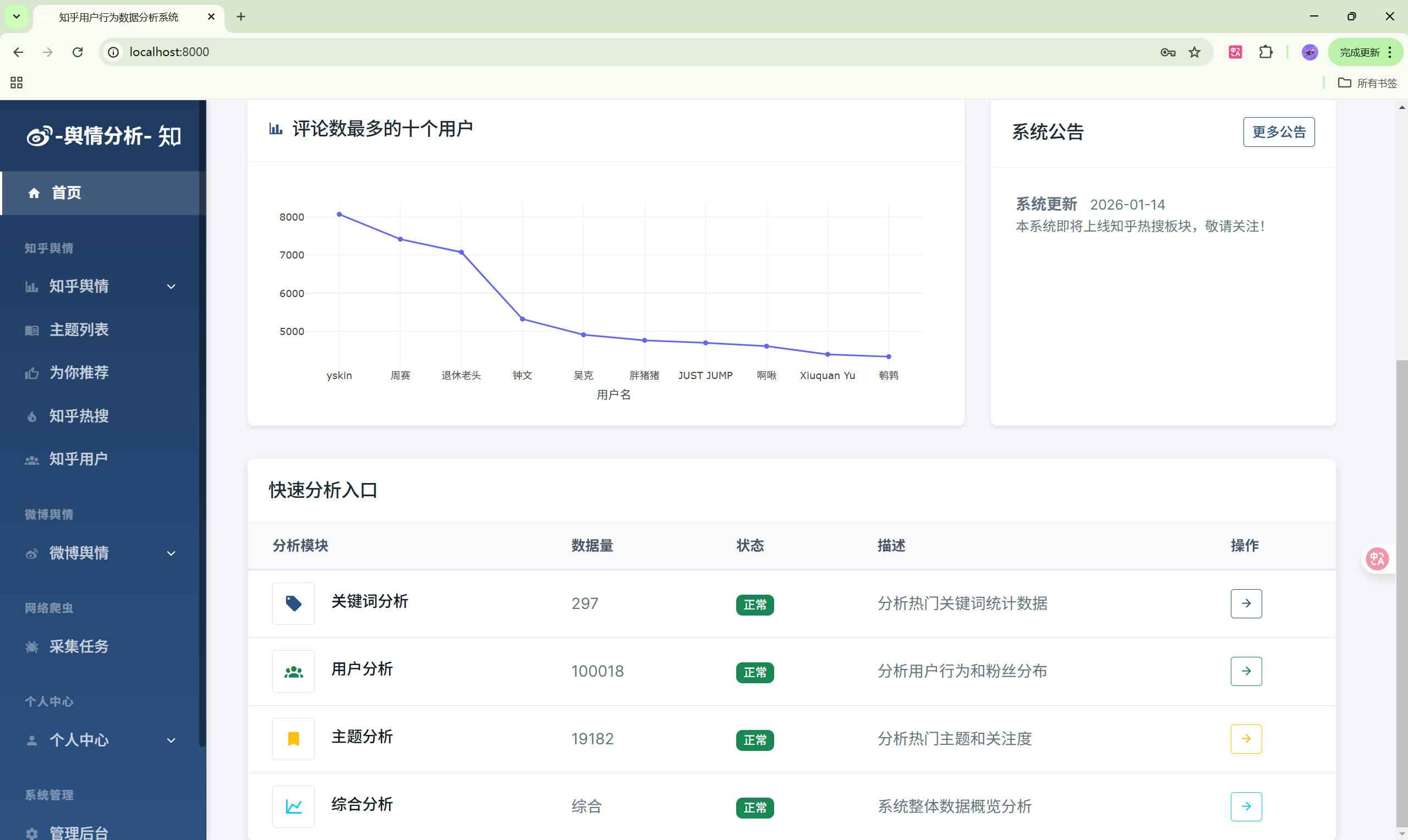
系统概述
本系统是一个功能完整的社交媒体舆情监控平台,主要功能包括:
- 多平台数据采集:支持微博、知乎等社交媒体数据爬取
- 实时热搜监控:获取各平台实时热搜榜单
- 情感分析:基于SnowNLP的中文情感分析
- 数据可视化:ECharts图表展示,词云图生成
- 用户管理:完整的用户认证与权限系统
- 知乎数据分析:用户行为分析、主题分析、关键词分析
系统架构图
┌─────────────────────────────────────────────────────────────┐
│ 前端展示层 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │Bootstrap│ │ ECharts │ │ jQuery │ │ WordCloud│ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
├─────────────────────────────────────────────────────────────┤
│ Django Web层 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Views │ │Templates│ │ URLs │ │ Forms │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
├─────────────────────────────────────────────────────────────┤
│ 业务逻辑层 │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ SpiderService│ │SentimentSvc │ │AnalysisSvc │ │
│ │ (数据爬取) │ │ (情感分析) │ │ (数据分析) │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ 数据存储层 │
│ ┌─────────────────────────────────────────────┐ │
│ │ MySQL │ │
│ │ Article | HotSearch | CrawlTask | ZhihuUser │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘技术栈
后端技术
| 技术 | 版本 | 说明 |
|---|---|---|
| Python | 3.8+ | 编程语言 |
| Django | 4.2+ | Web框架 |
| MySQL | 5.7+ | 数据库 |
| SnowNLP | 0.12.3 | 中文情感分析 |
| Jieba | 0.42.1 | 中文分词 |
| Requests | 2.28+ | HTTP请求库 |
| BeautifulSoup4 | 4.12+ | HTML解析 |
| WordCloud | 1.9+ | 词云生成 |
| Pandas | 1.5+ | 数据处理 |
前端技术
| 技术 | 版本 | 说明 |
|---|---|---|
| Bootstrap | 5.3 | UI框架 |
| ECharts | 5.4+ | 数据可视化 |
| jQuery | 3.6+ | JavaScript库 |
| Font Awesome | 6.0 | 图标库 |
系统配色
| 颜色 | 色值 | 用途 |
|---|---|---|
| 主色调 | #1e3a5f | 深蓝色,导航栏、标题 |
| 辅助色 | #2c5282 | 中蓝色,按钮、链接 |
| 背景色 | #f8f9fa | 浅灰色,页面背景 |
| 成功色 | #28a745 | 绿色,正面情感 |
| 警告色 | #ffc107 | 黄色,中性情感 |
| 危险色 | #dc3545 | 红色,负面情感 |
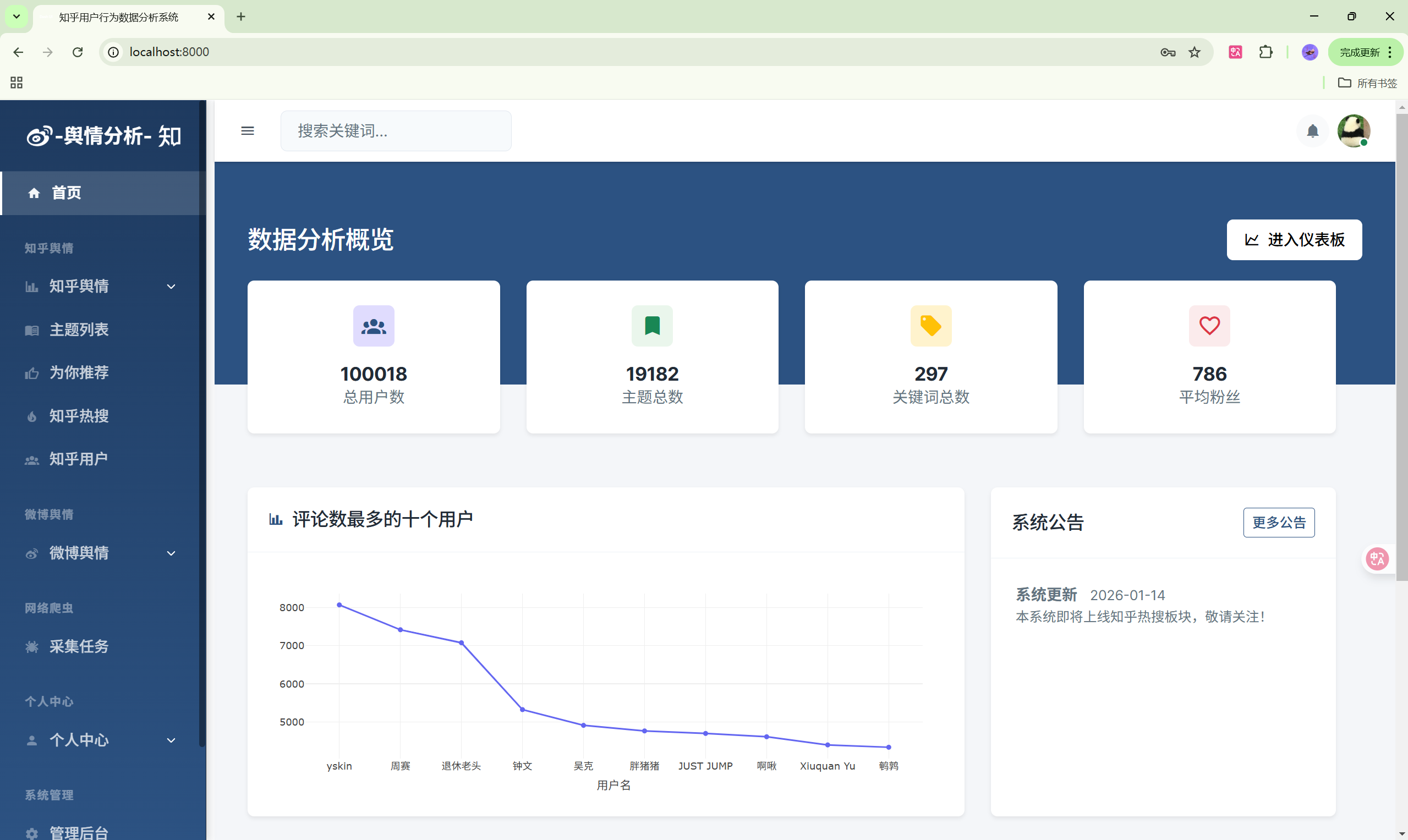
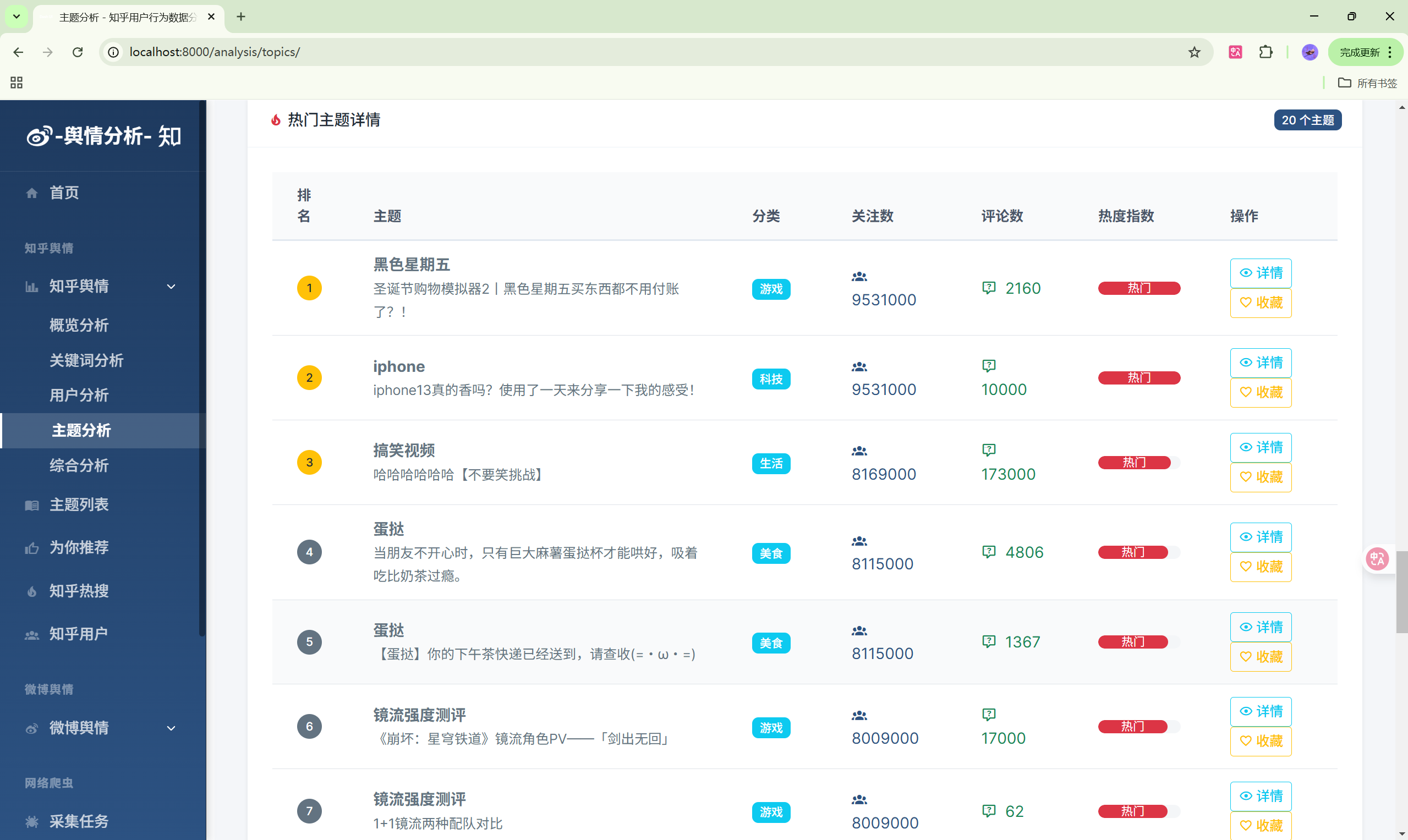
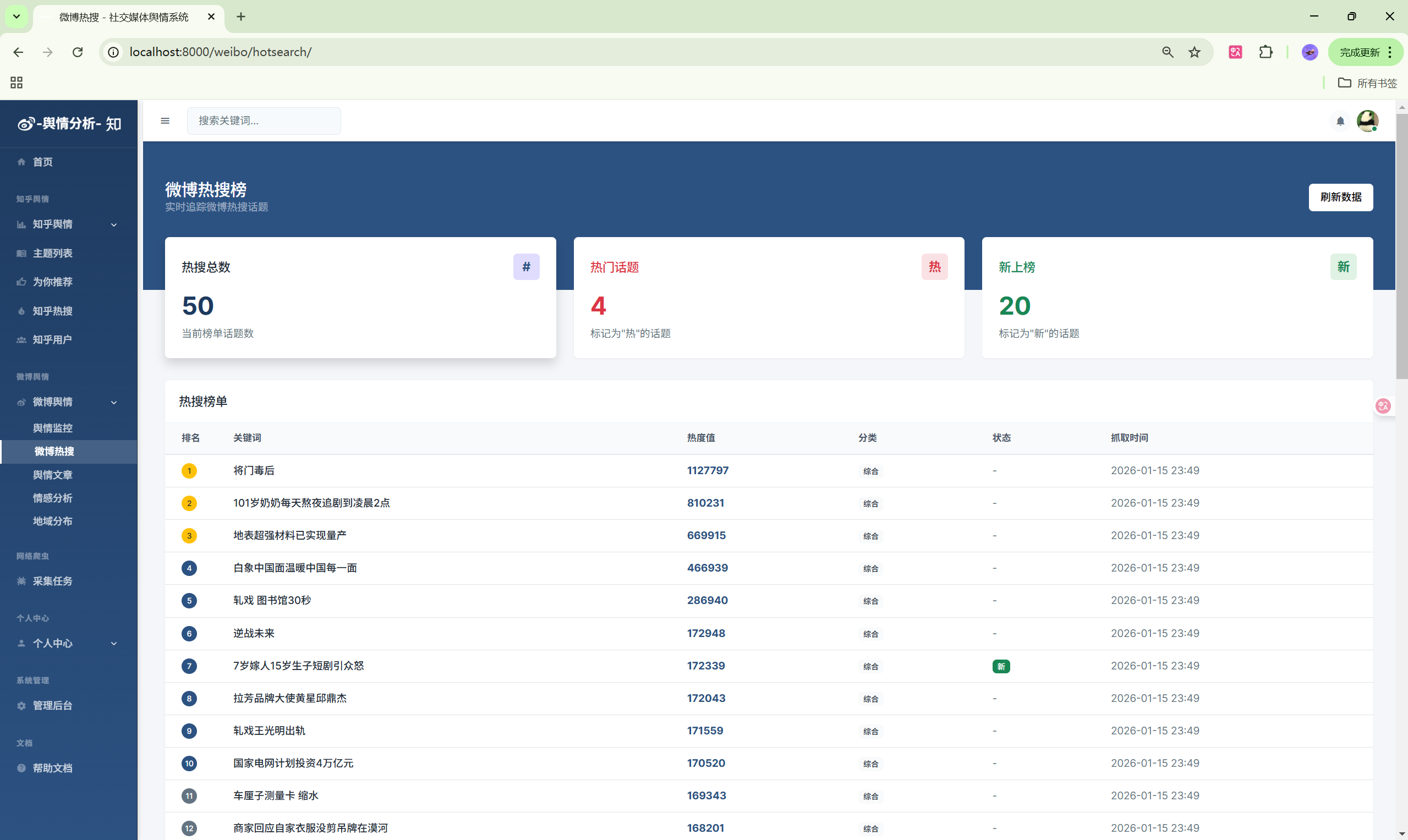
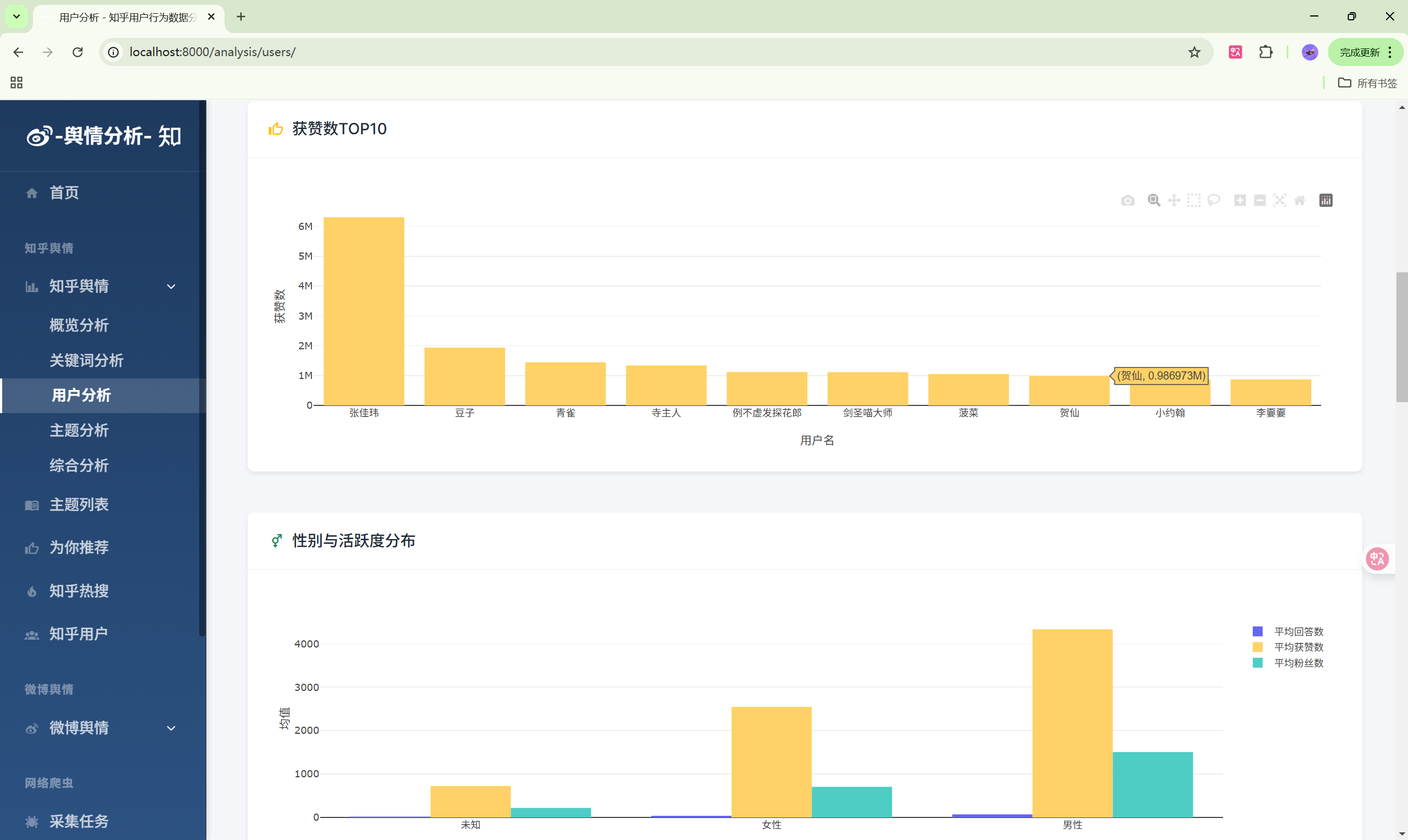
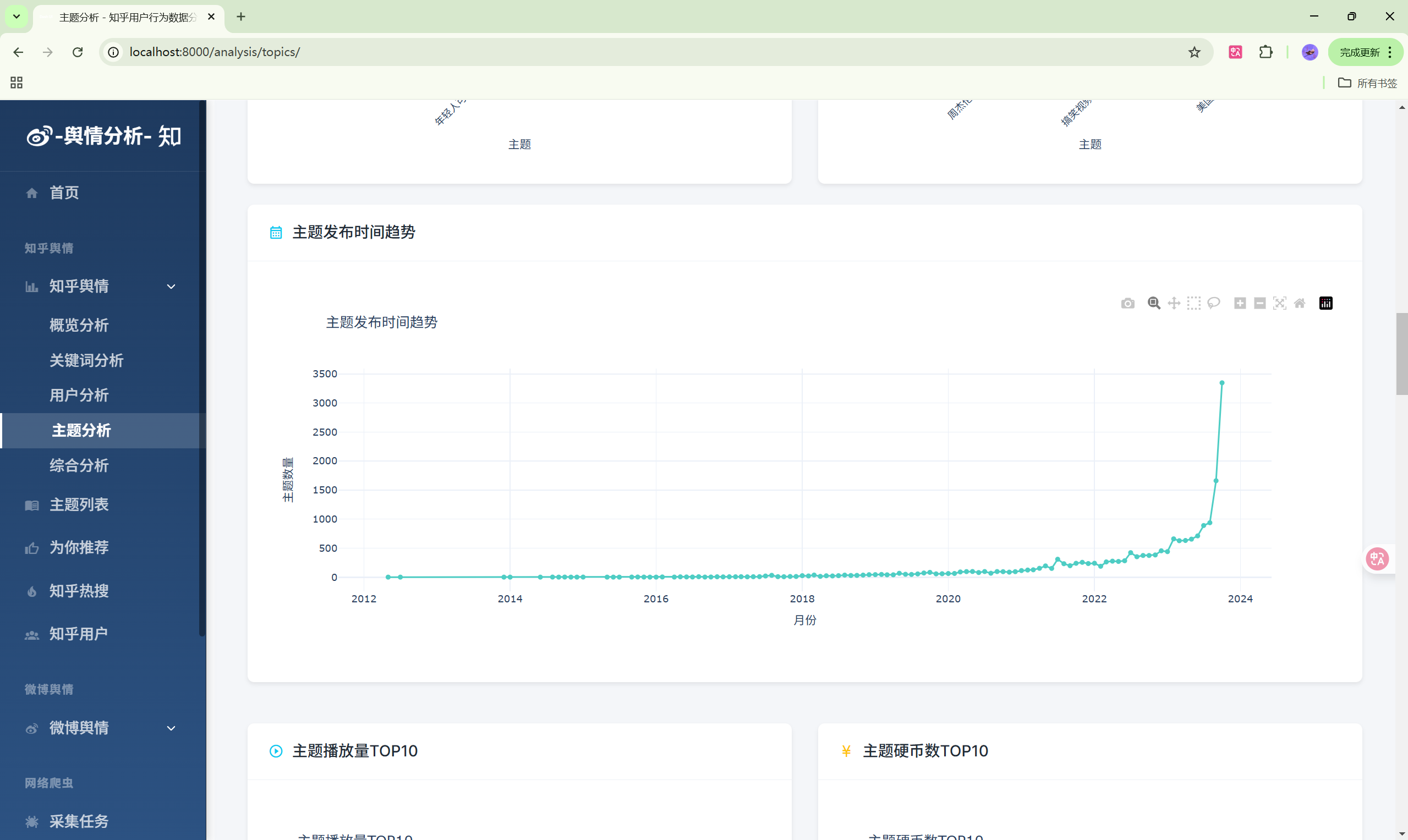
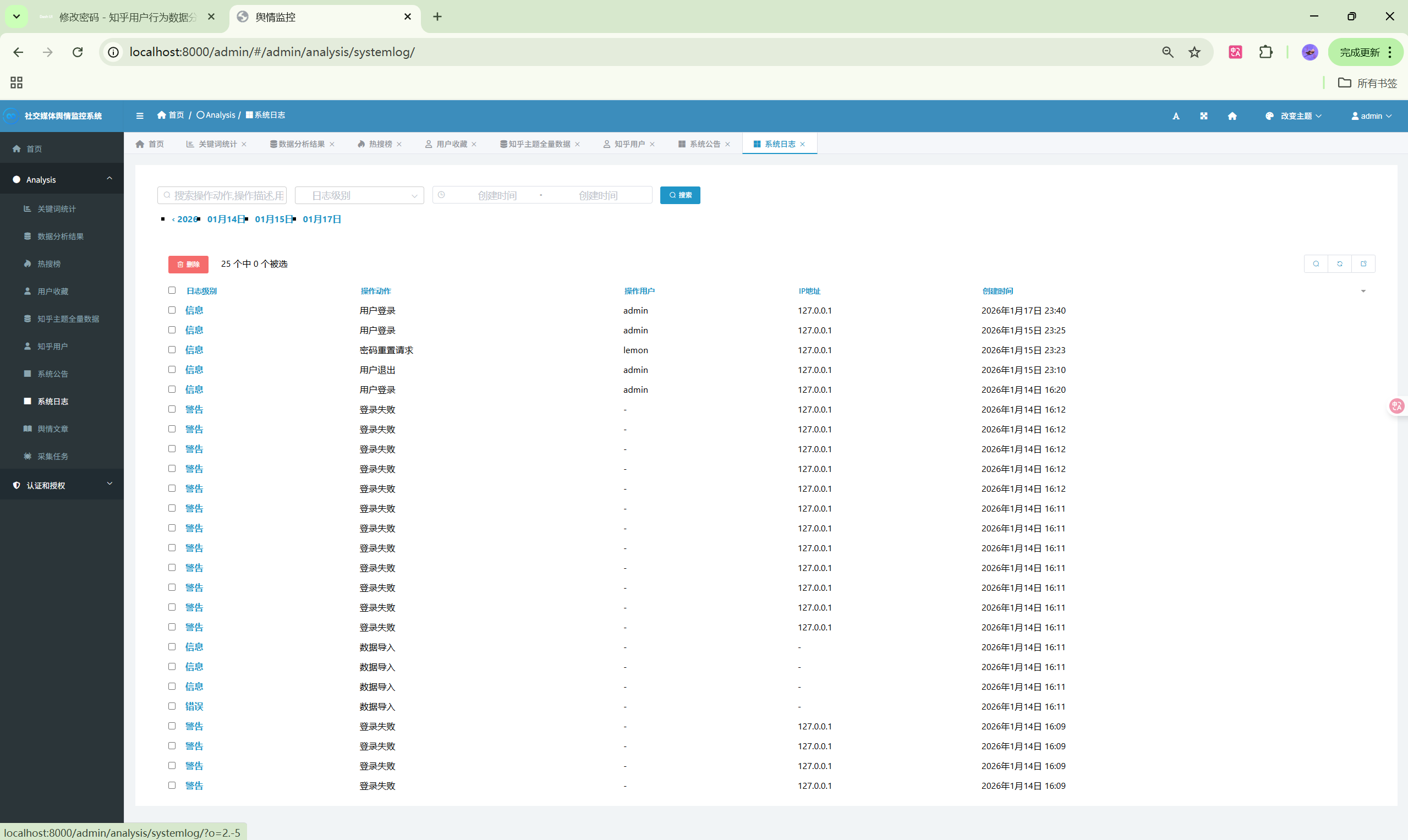
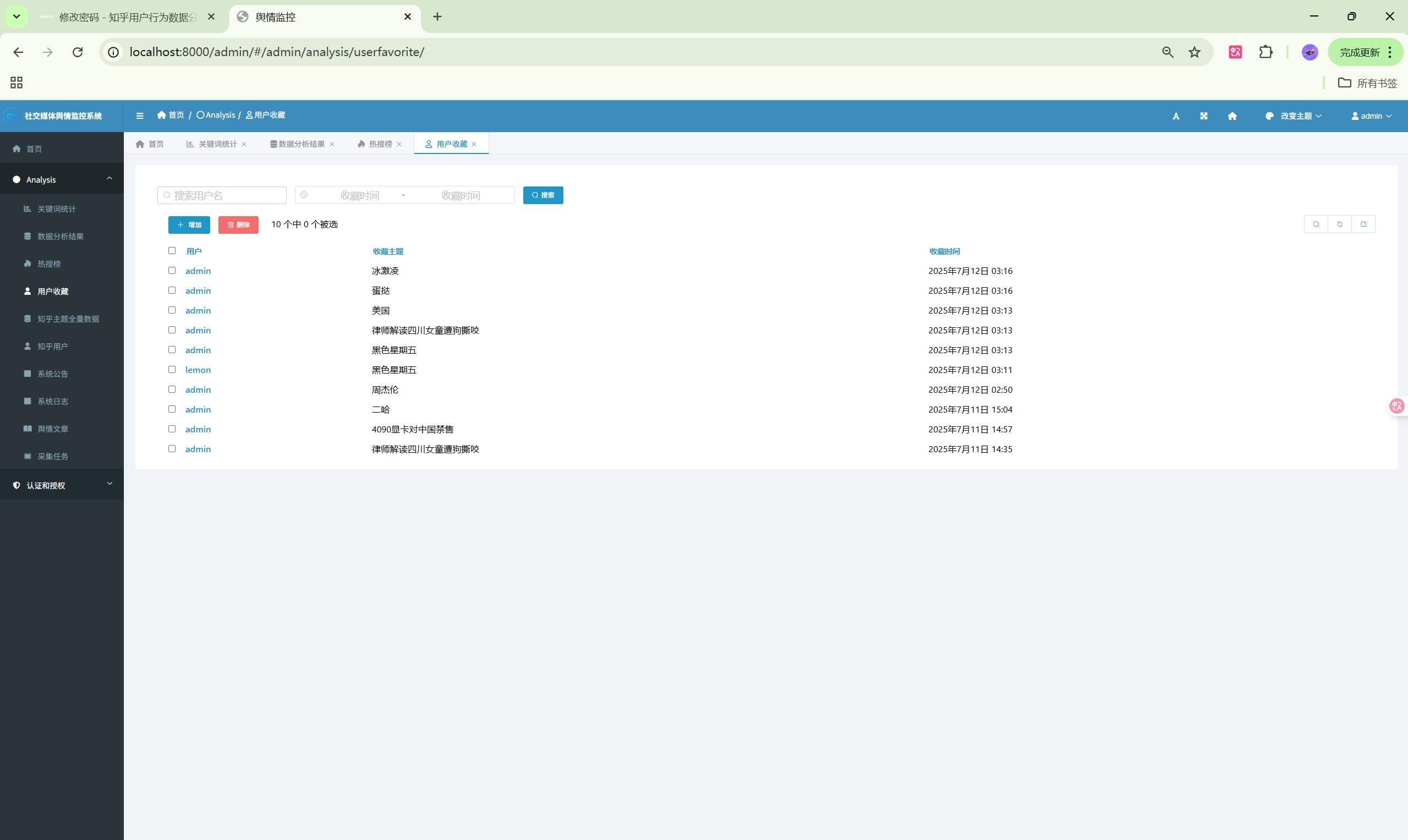
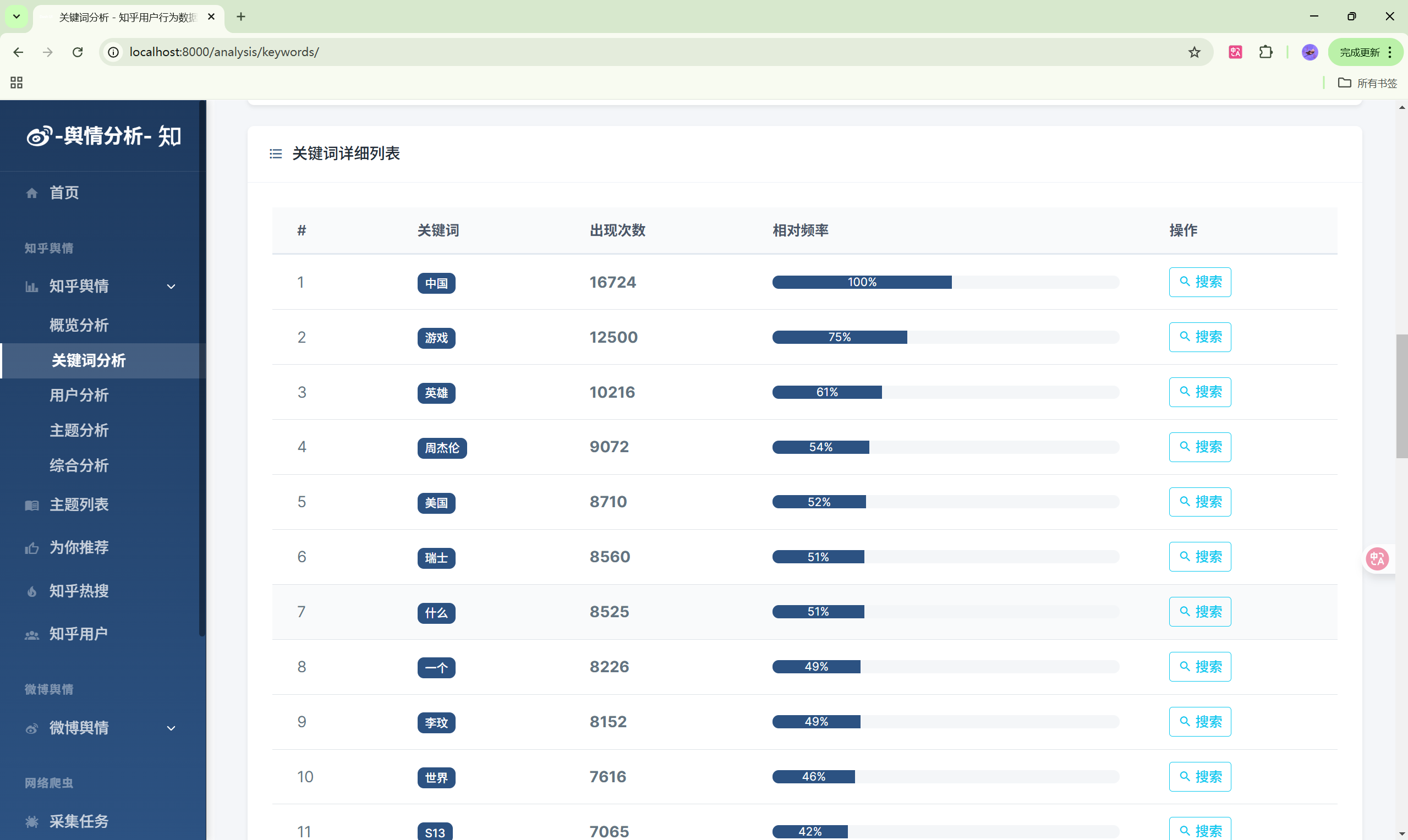
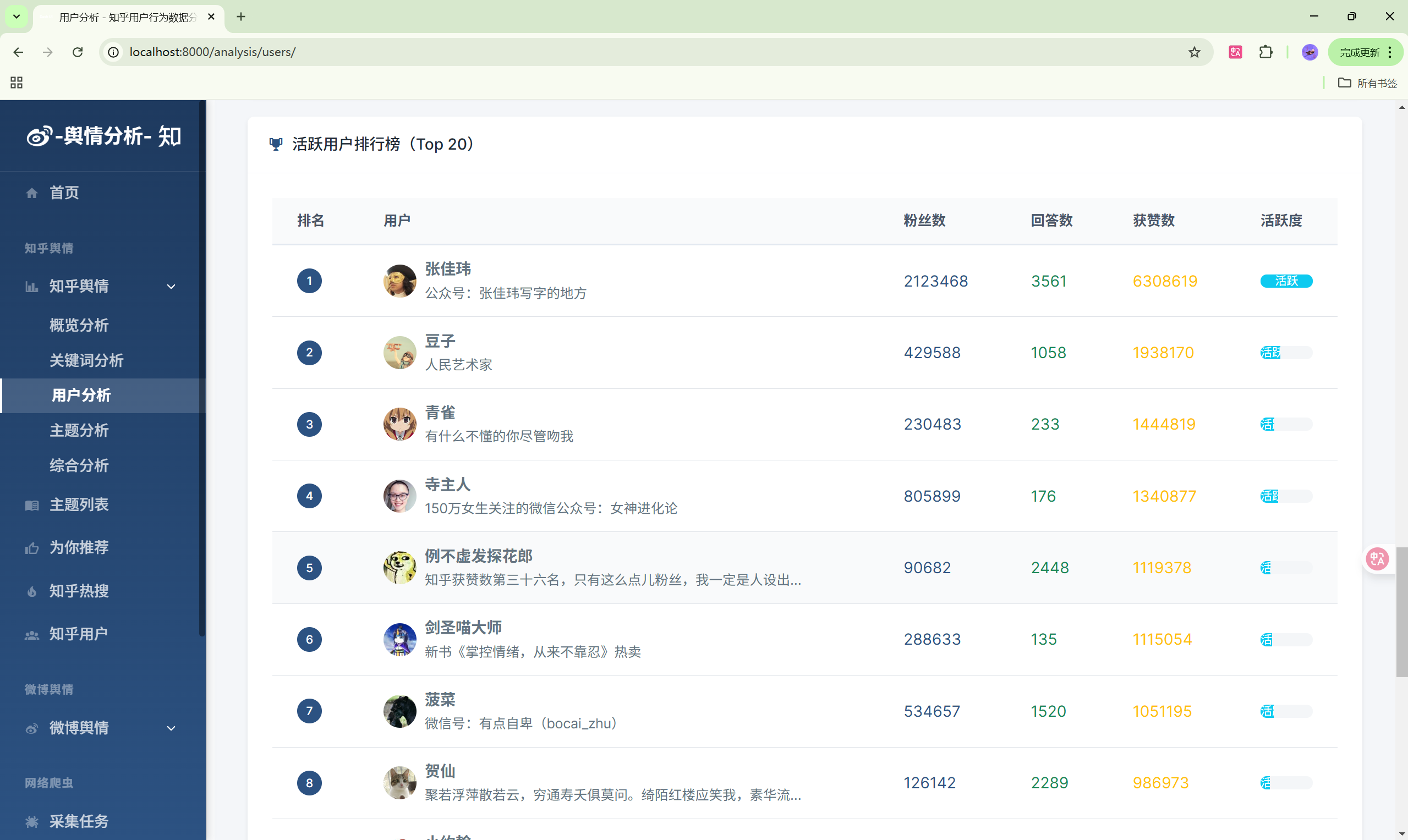
演示图片
330-基于Python的社交媒体舆情监控系统

环境要求
最低配置
- CPU: 双核处理器
- 内存: 4GB RAM
- 存储: 10GB可用空间
- 操作系统: Windows 10+ / Ubuntu 18.04+ / macOS 10.14+
推荐配置
- CPU: 四核处理器
- 内存: 8GB RAM
- 存储: 50GB SSD
- 数据库: MySQL 8.0+
安装部署
开发环境部署
1. 克隆项目
bash
git clone <项目地址>
cd code2. 创建虚拟环境
bash
# Windows
python -m venv venv
venv\Scripts\activate
# Linux/macOS
python3 -m venv venv
source venv/bin/activate3. 安装依赖
bash
pip install -r requirements.txt4. 配置数据库
编辑 social_media_analysis/settings.py:
python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'sentiment_db',
'USER': 'root',
'PASSWORD': 'your_password',
'HOST': '127.0.0.1',
'PORT': '3306',
'OPTIONS': {
'charset': 'utf8mb4',
}
}
}5. 初始化数据库
bash
# 创建数据库(MySQL命令行)
mysql -u root -p
CREATE DATABASE sentiment_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
exit
# 执行迁移
python manage.py makemigrations
python manage.py migrate
# 创建管理员账户
python manage.py createsuperuser6. 启动服务
bash
python manage.py runserver访问 http://127.0.0.1:8000 即可使用系统。
生产环境部署
使用 Gunicorn + Nginx
1. 安装 Gunicorn
bash
pip install gunicorn2. 配置 Gunicorn
创建 gunicorn.conf.py:
python
bind = '127.0.0.1:8000'
workers = 4
worker_class = 'sync'
timeout = 120
keepalive = 5
errorlog = '/var/log/gunicorn/error.log'
accesslog = '/var/log/gunicorn/access.log'
loglevel = 'info'3. 配置 Nginx
nginx
server {
listen 80;
server_name your_domain.com;
location /static/ {
alias /path/to/project/static/;
}
location /media/ {
alias /path/to/project/media/;
}
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}4. 启动服务
bash
# 收集静态文件
python manage.py collectstatic
# 启动 Gunicorn
gunicorn -c gunicorn.conf.py social_media_analysis.wsgi:applicationDocker部署
1. Dockerfile
dockerfile
FROM python:3.9-slim
WORKDIR /app
RUN apt-get update && apt-get install -y \
default-libmysqlclient-dev \
build-essential \
&& rm -rf /var/lib/apt/lists/*
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["gunicorn", "--bind", "0.0.0.0:8000", "social_media_analysis.wsgi:application"]2. docker-compose.yml
yaml
version: '3.8'
services:
web:
build: .
ports:
- "8000:8000"
depends_on:
- db
environment:
- DB_HOST=db
- DB_NAME=sentiment_db
- DB_USER=root
- DB_PASSWORD=your_password
volumes:
- static_volume:/app/static
- media_volume:/app/media
db:
image: mysql:8.0
environment:
MYSQL_ROOT_PASSWORD: your_password
MYSQL_DATABASE: sentiment_db
volumes:
- mysql_data:/var/lib/mysql
ports:
- "3307:3306"
volumes:
mysql_data:
static_volume:
media_volume:3. 启动容器
bash
docker-compose up -d配置说明
settings.py 主要配置
python
# 调试模式(生产环境设为False)
DEBUG = True
# 允许的主机
ALLOWED_HOSTS = ['localhost', '127.0.0.1', 'your_domain.com']
# 时区设置
TIME_ZONE = 'Asia/Shanghai'
USE_TZ = True
# 语言设置
LANGUAGE_CODE = 'zh-hans'
# 静态文件配置
STATIC_URL = '/static/'
STATICFILES_DIRS = [BASE_DIR / 'static']
# 媒体文件配置
MEDIA_URL = '/media/'
MEDIA_ROOT = BASE_DIR / 'media'
# Session配置
SESSION_COOKIE_AGE = 86400 # 24小时
SESSION_EXPIRE_AT_BROWSER_CLOSE = False功能模块
1. 用户认证模块
功能列表
- 用户登录:支持用户名密码登录
- 用户注册:新用户注册
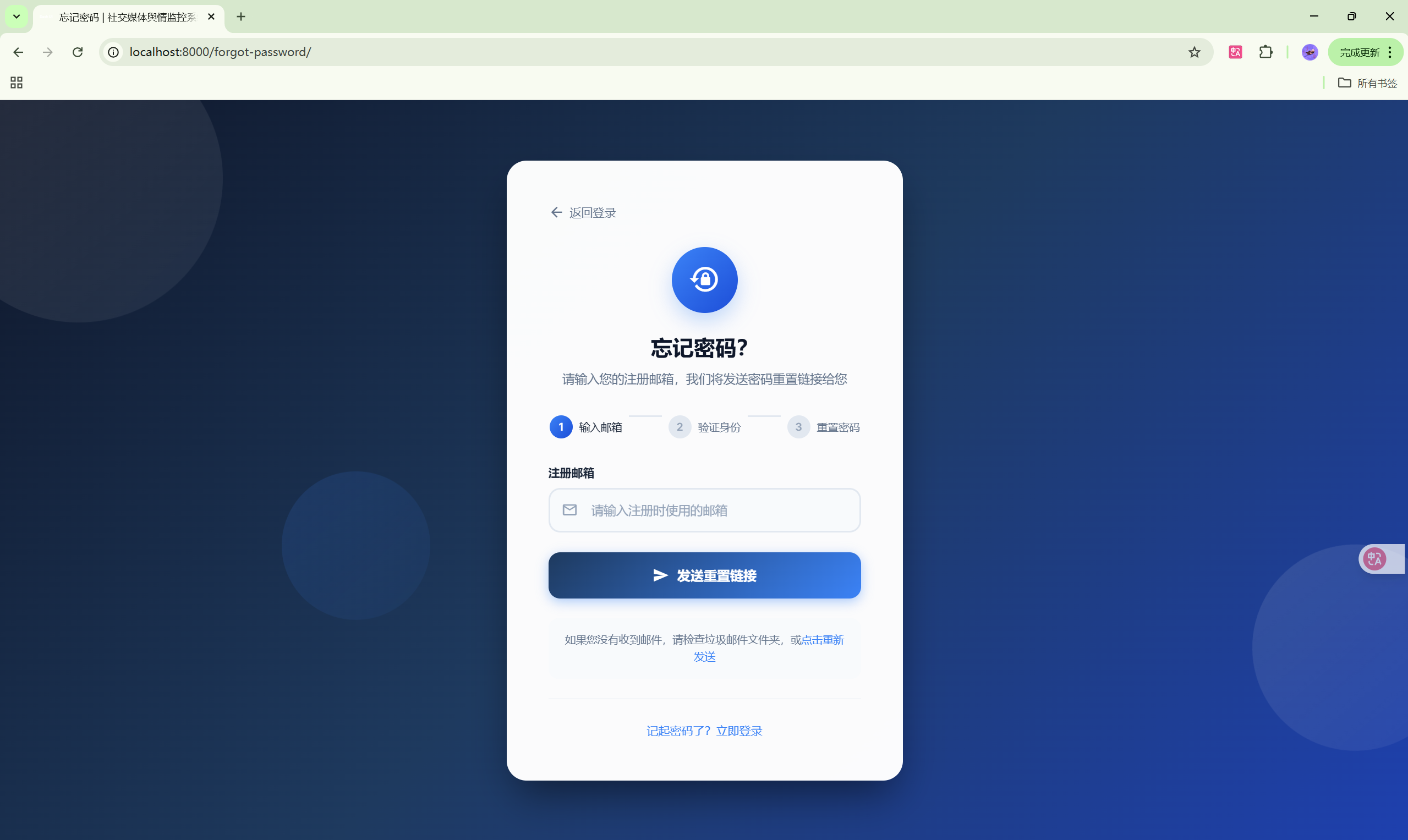
- 密码找回:忘记密码功能
- 密码修改:已登录用户修改密码
- 个人中心:查看和编辑个人资料
访问路径
| 功能 | URL | 说明 |
|---|---|---|
| 登录 | /login/ | 用户登录页面 |
| 注册 | /register/ | 用户注册页面 |
| 登出 | /logout/ | 退出登录 |
| 忘记密码 | /forgot-password/ | 密码找回 |
| 个人中心 | /profile/ | 个人资料页面 |
| 修改密码 | /change-password/ | 密码修改页面 |
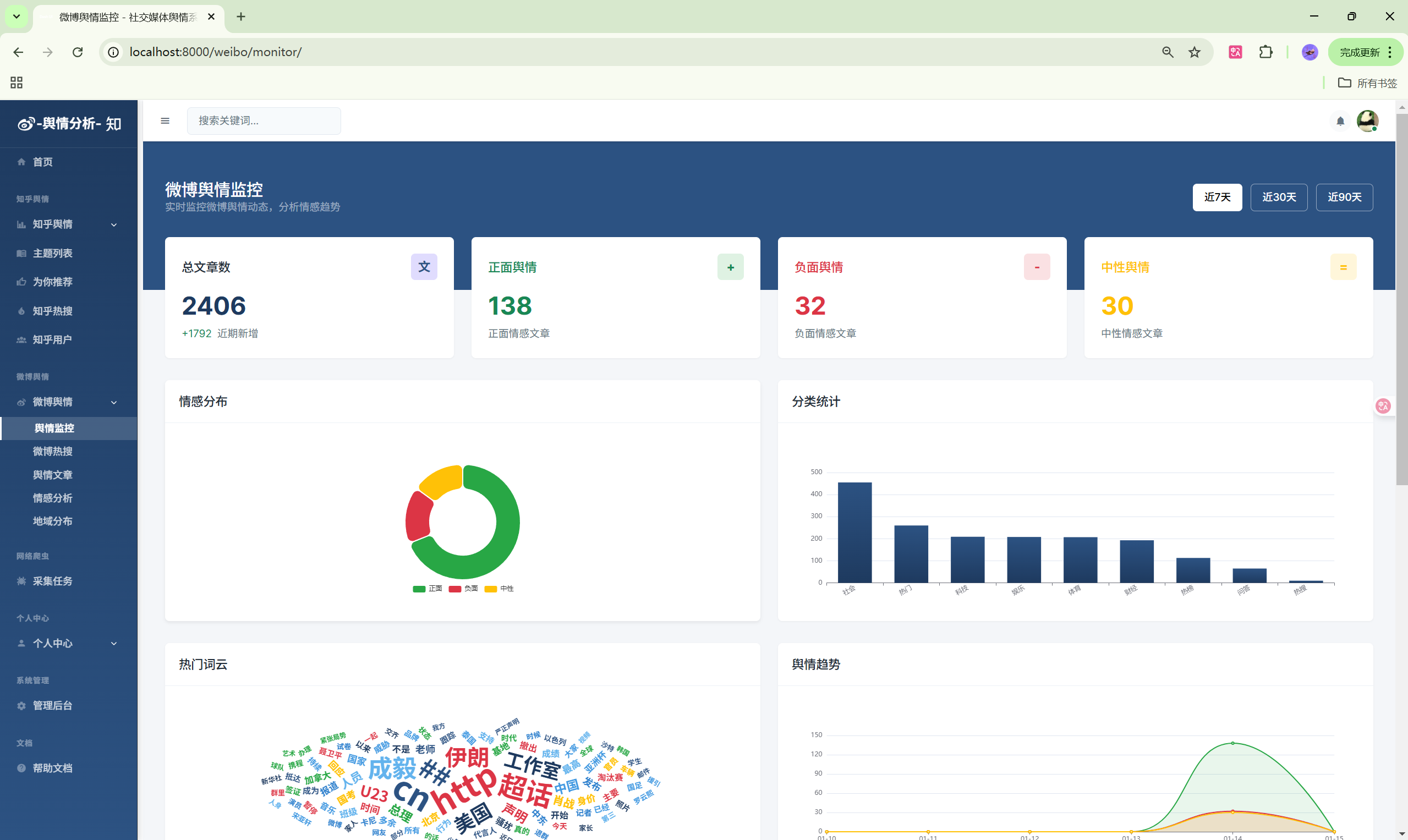
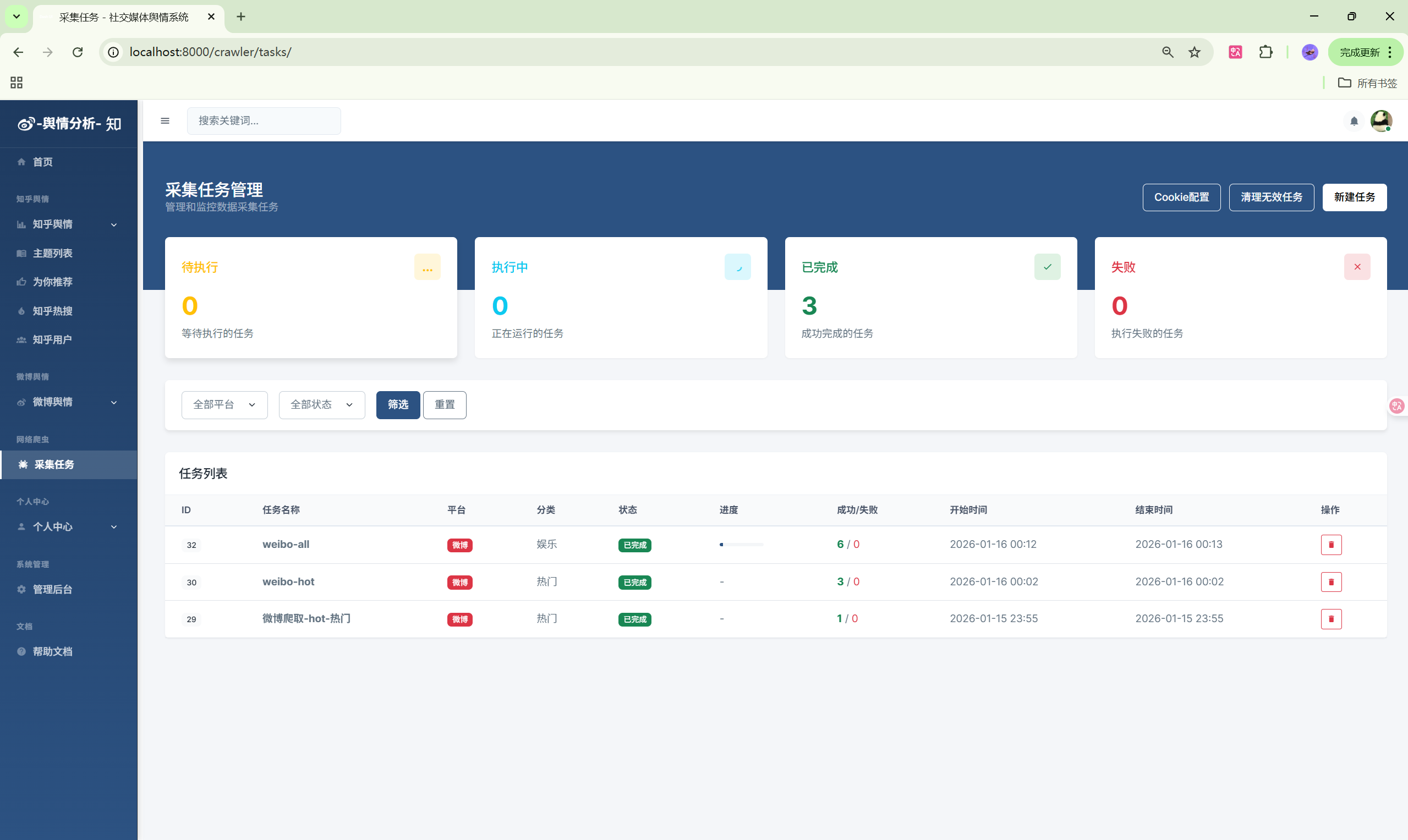
2. 微博舆情监控模块
功能列表
- 微博监控面板:实时数据概览
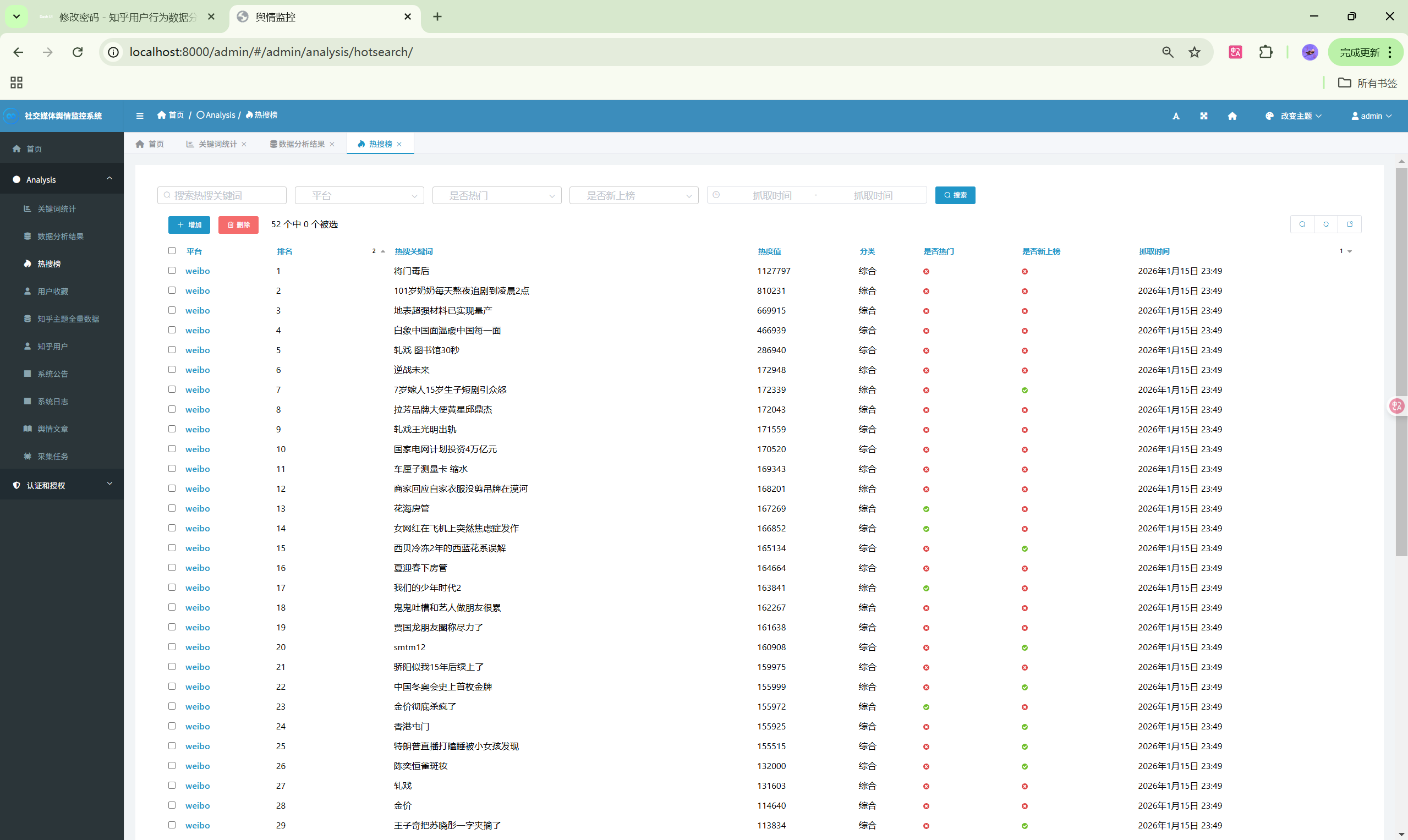
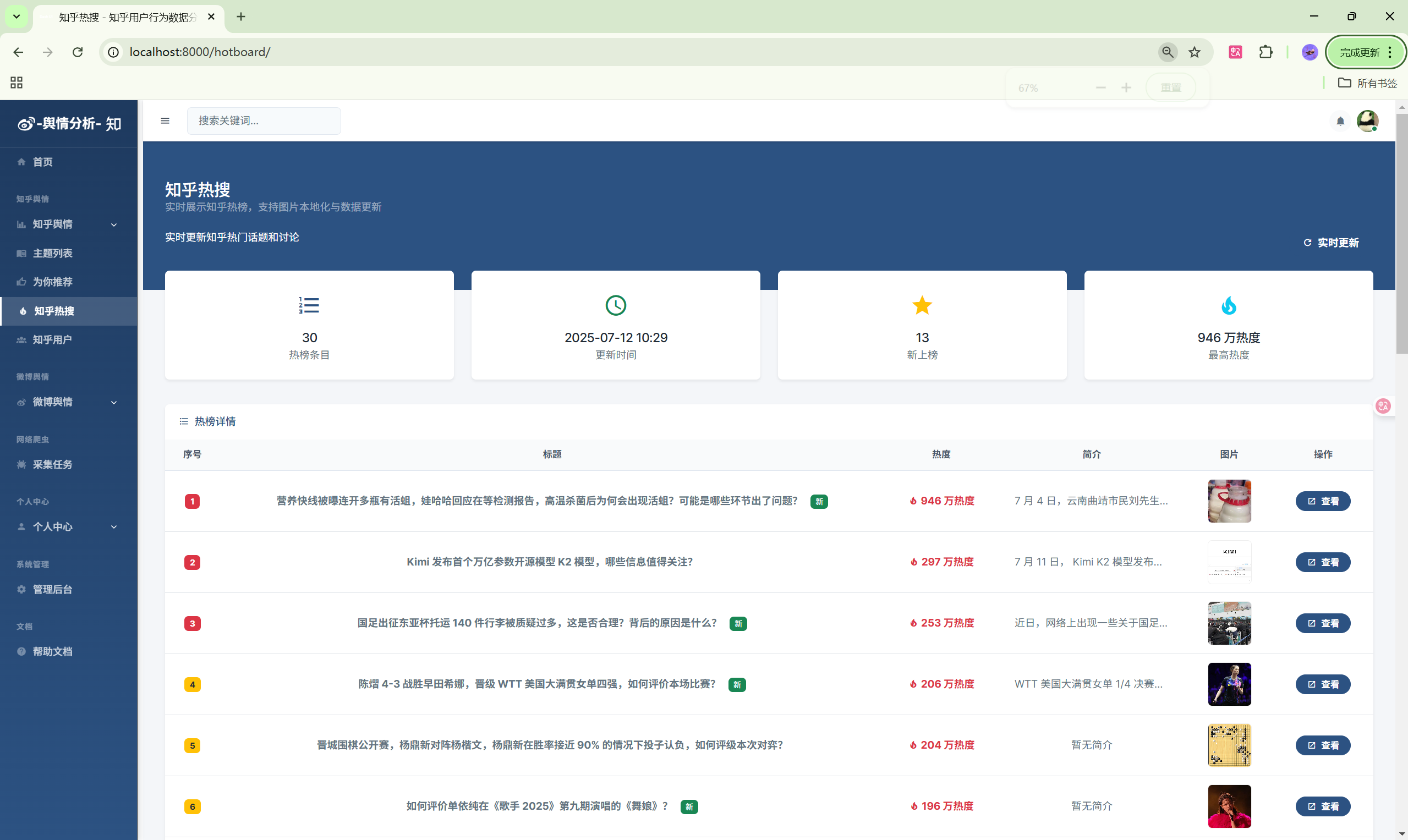
- 微博热搜:实时热搜榜单
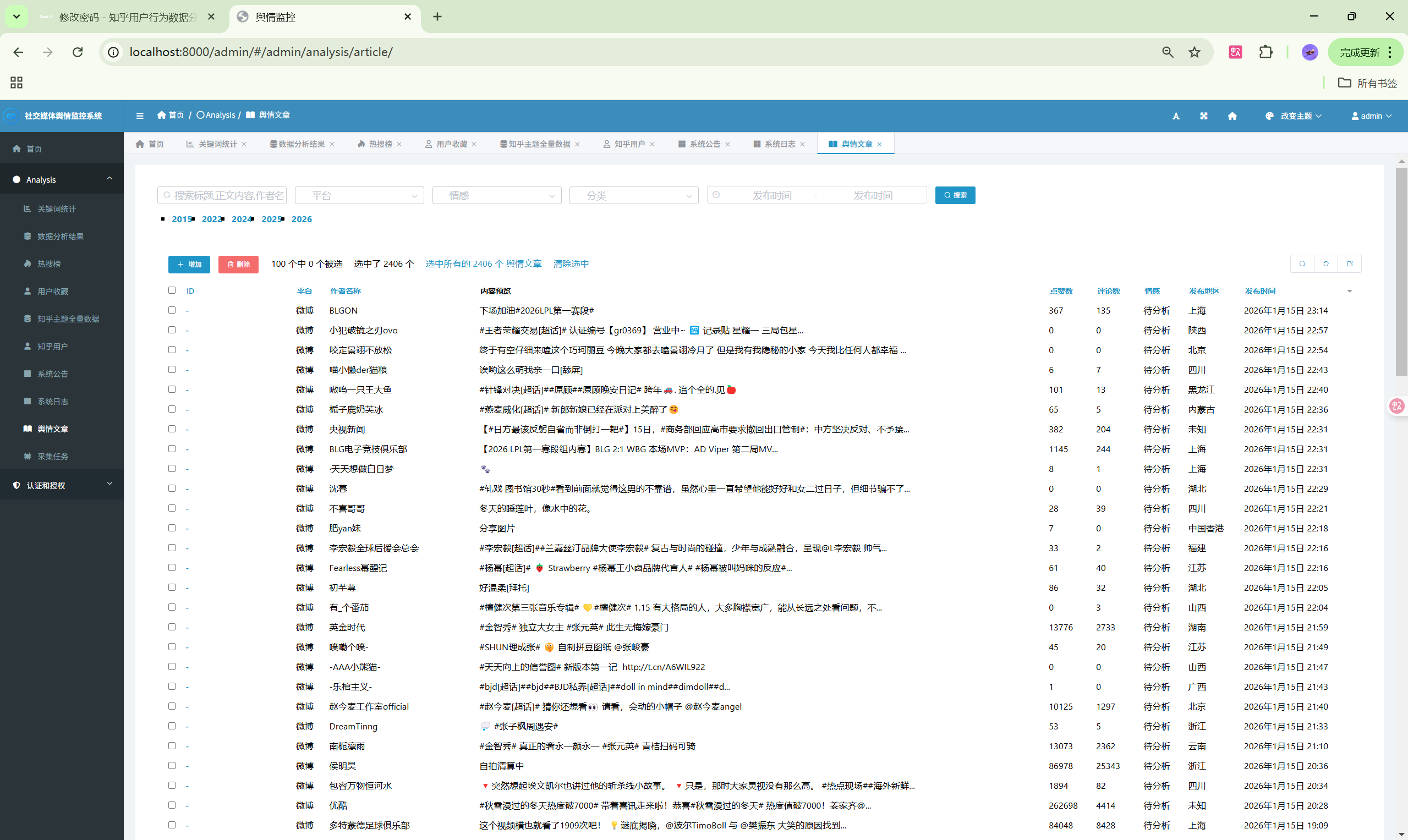
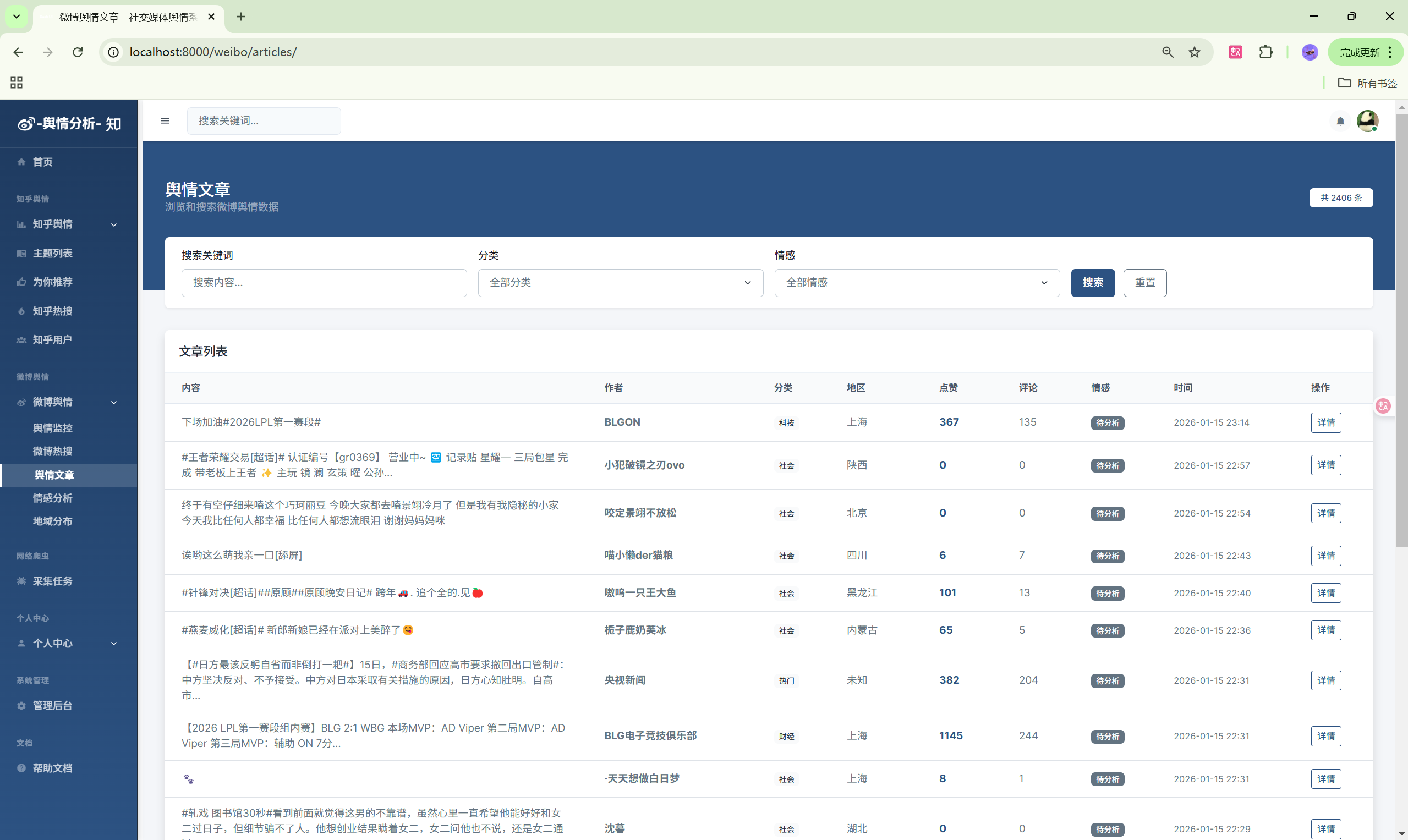
- 微博文章:文章列表与搜索
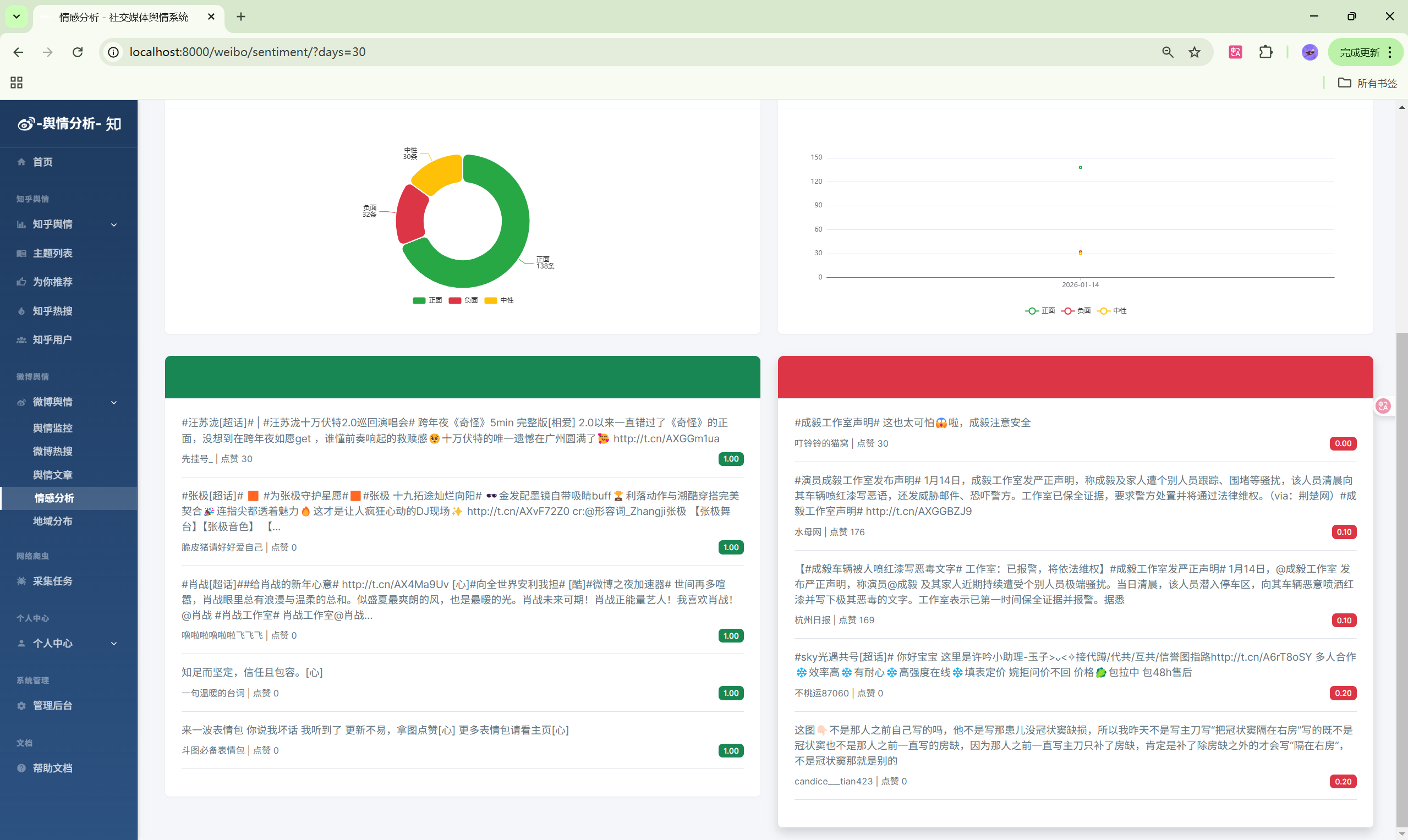
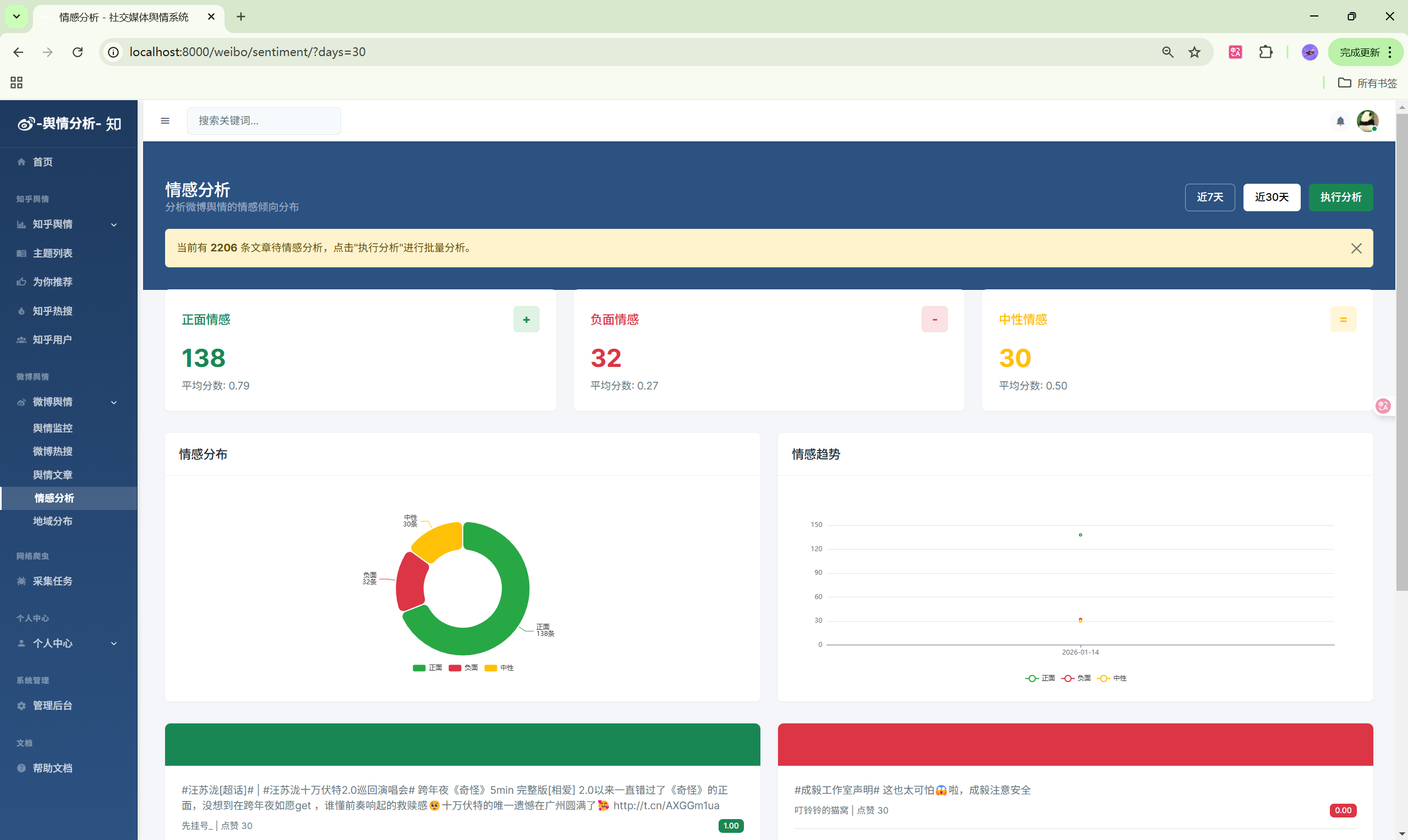
- 情感分析:文章情感分布
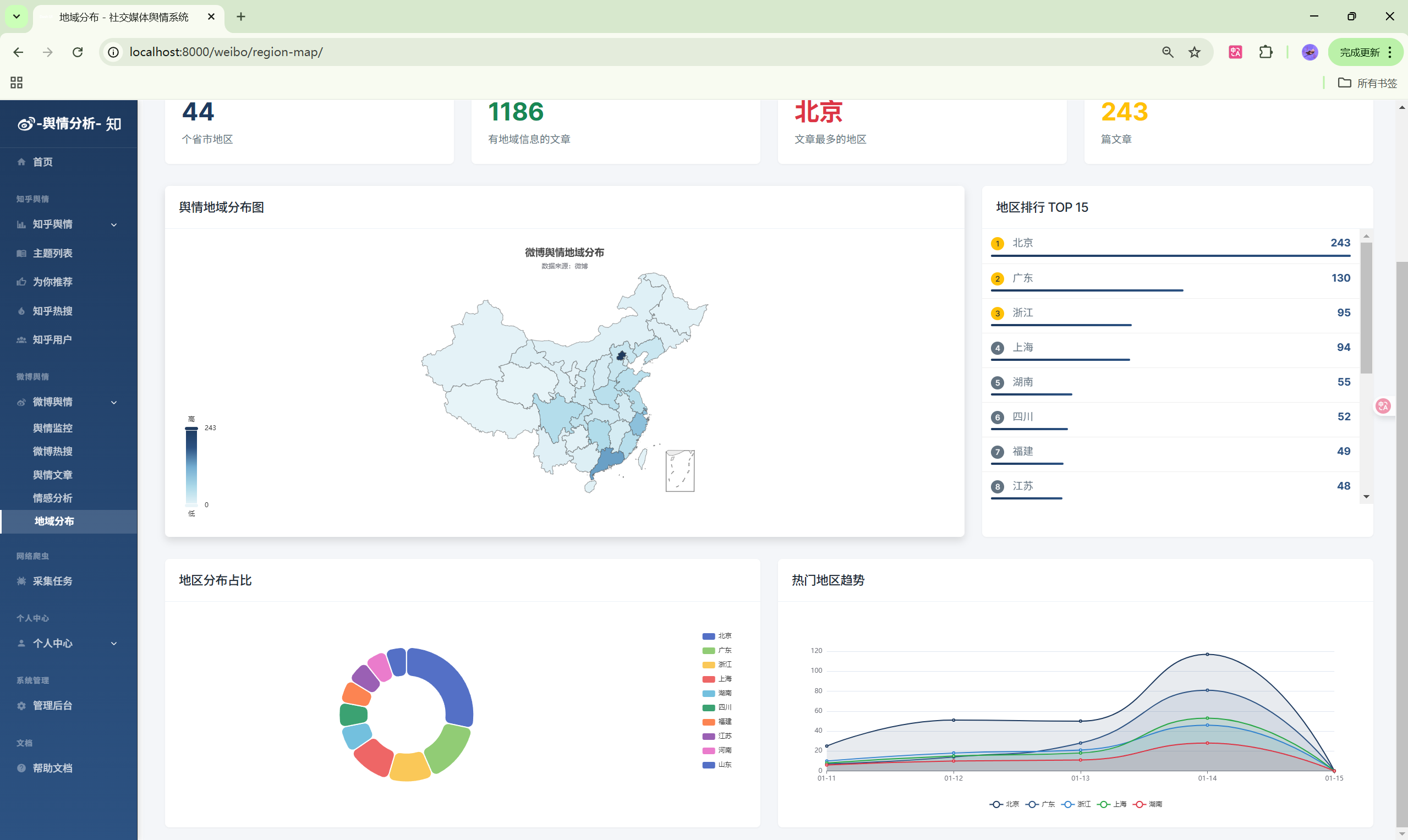
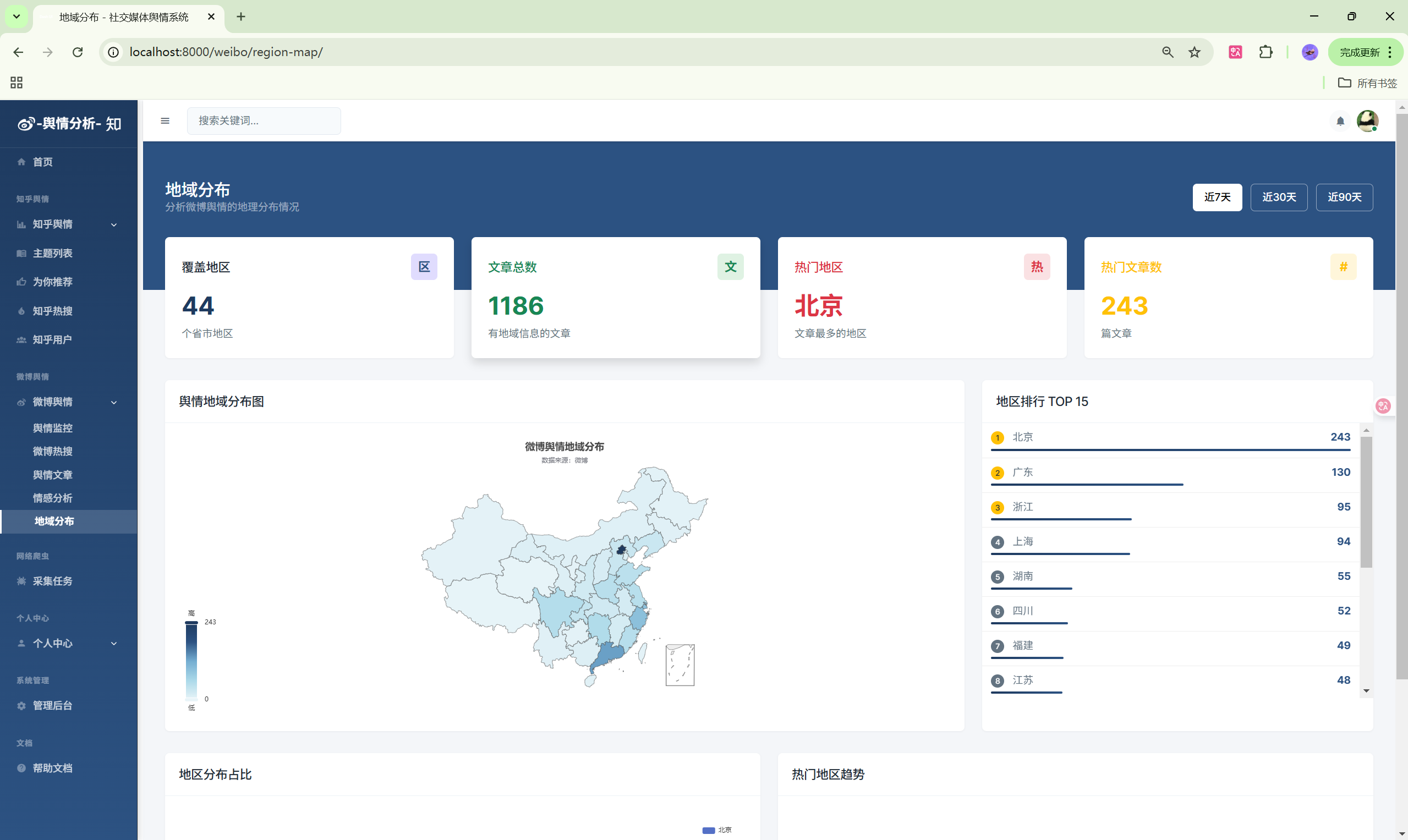
- 地区分布:发布地区地图展示
访问路径
| 功能 | URL | 说明 |
|---|---|---|
| 监控面板 | /weibo/monitor/ | 微博数据概览 |
| 热搜榜 | /weibo/hotsearch/ | 实时热搜 |
| 文章列表 | /weibo/articles/ | 微博文章 |
| 情感分析 | /weibo/sentiment/ | 情感分布 |
| 地区地图 | /weibo/region-map/ | 地区分布 |
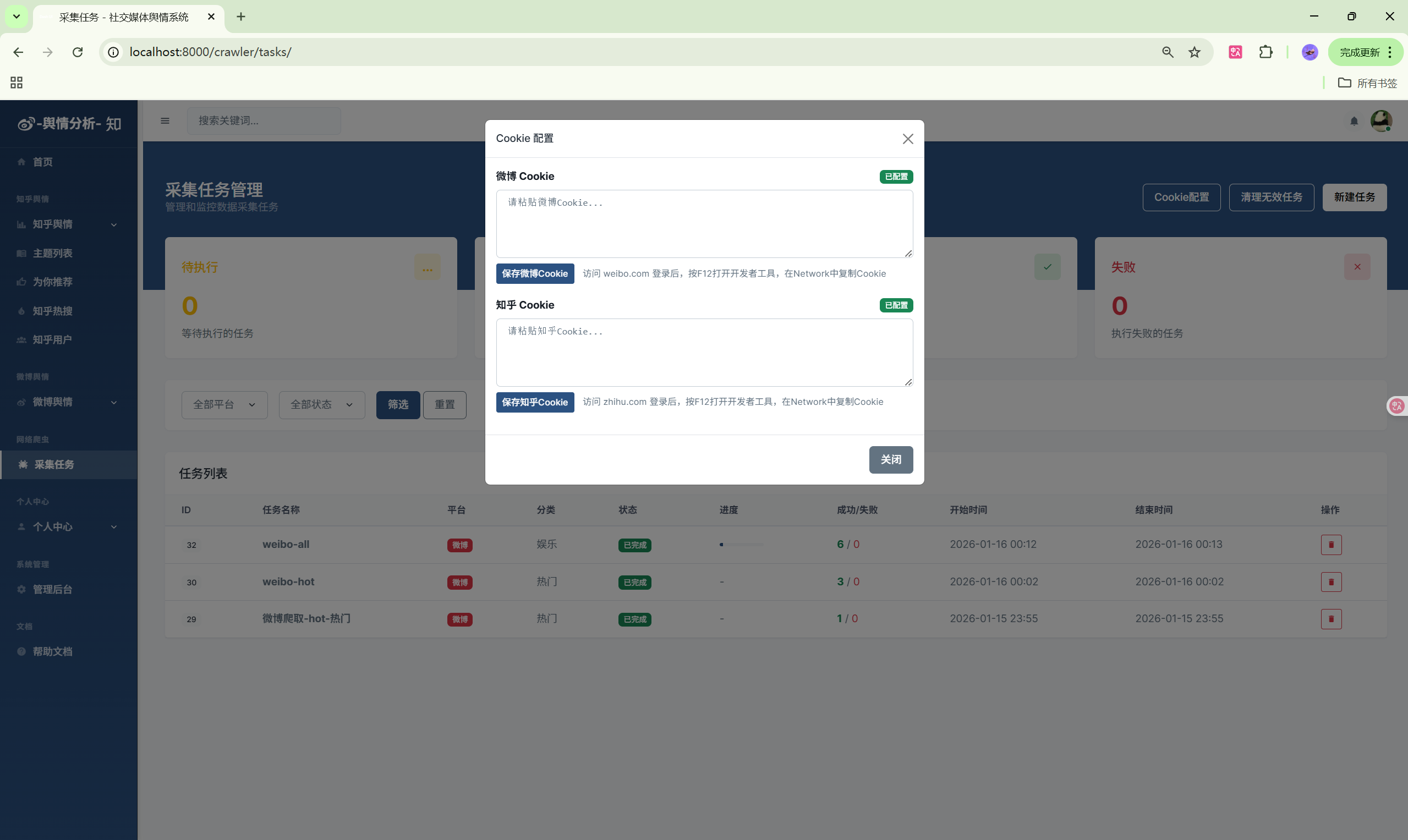
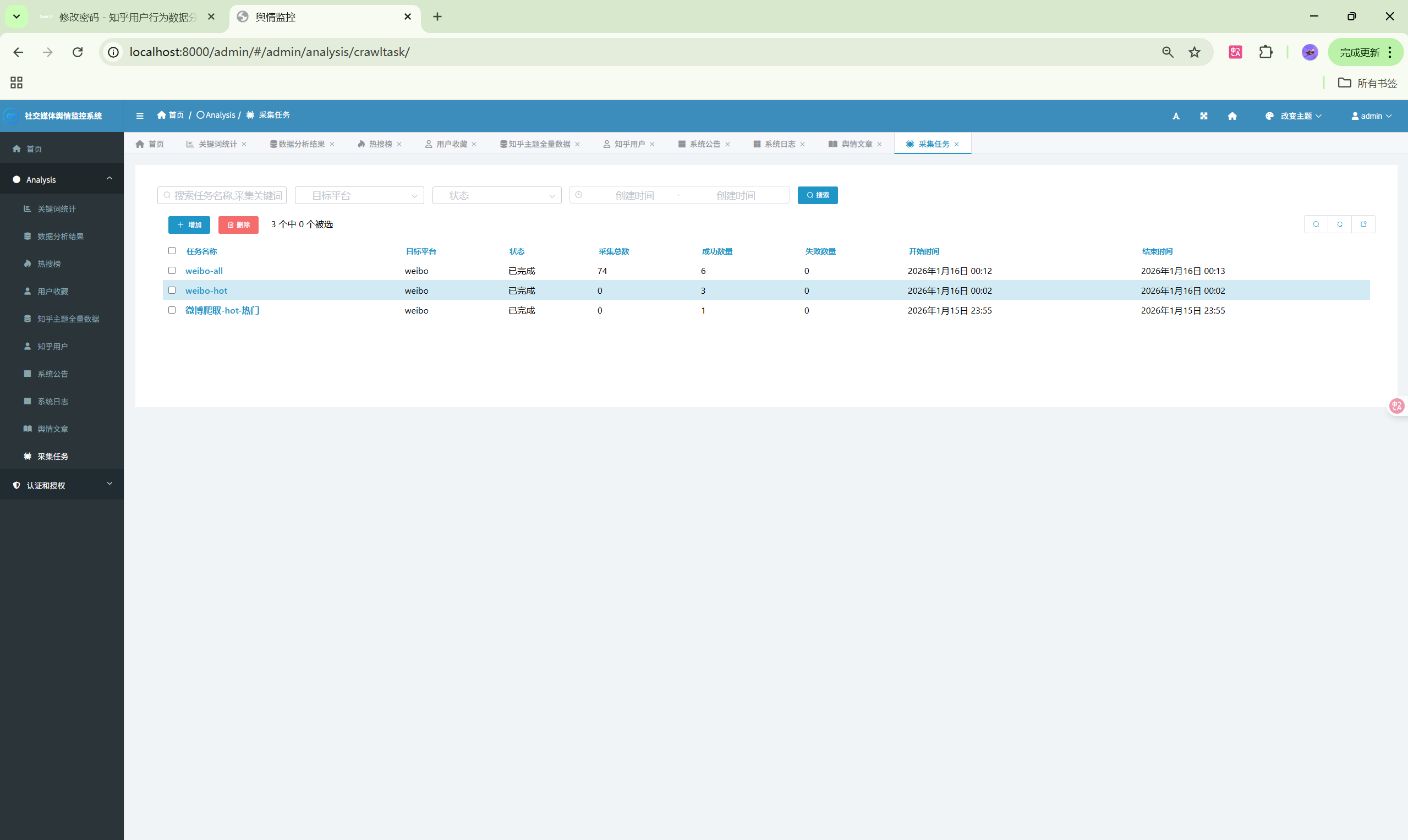
| 爬虫任务 | /crawler/tasks/ | 数据采集管理 |
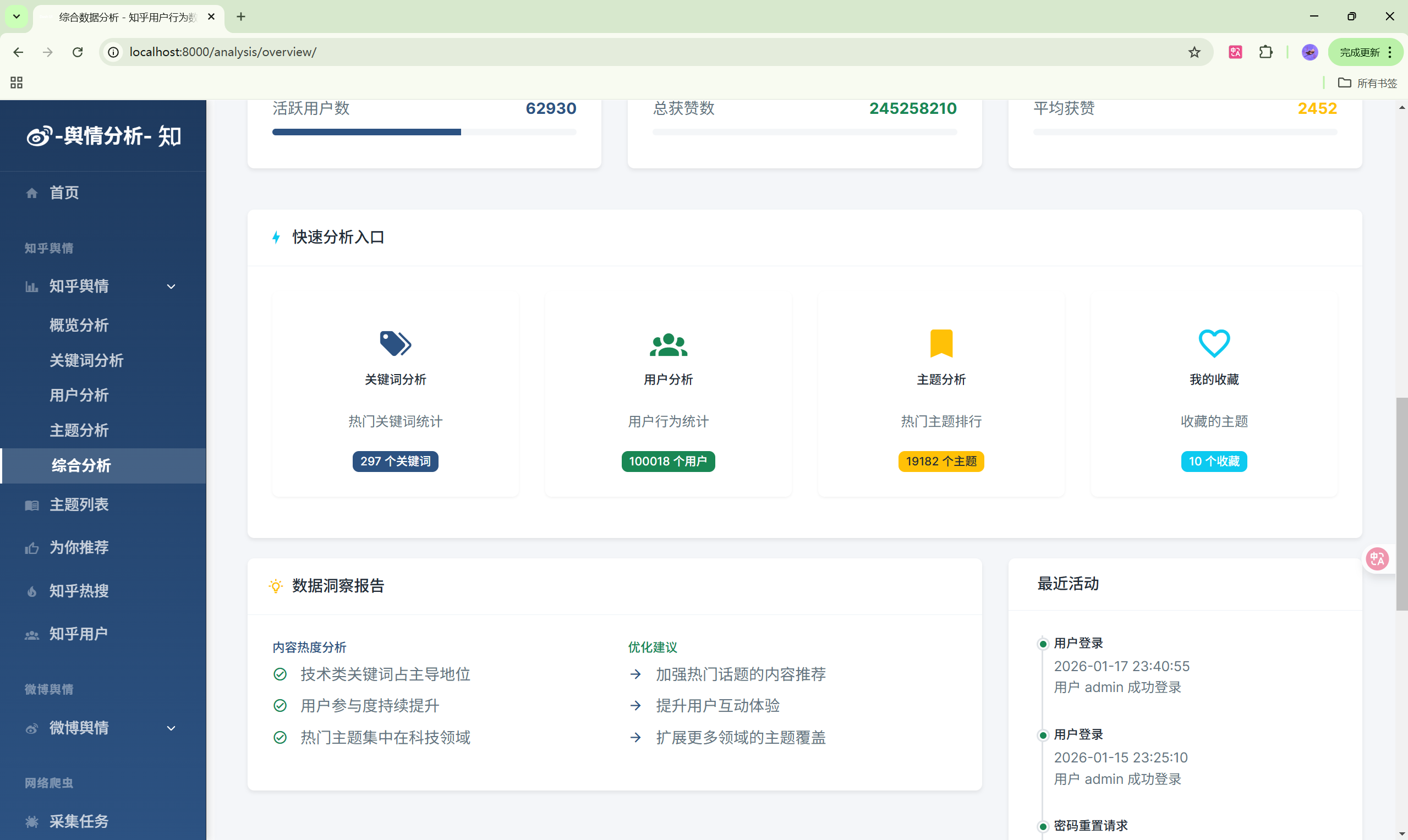
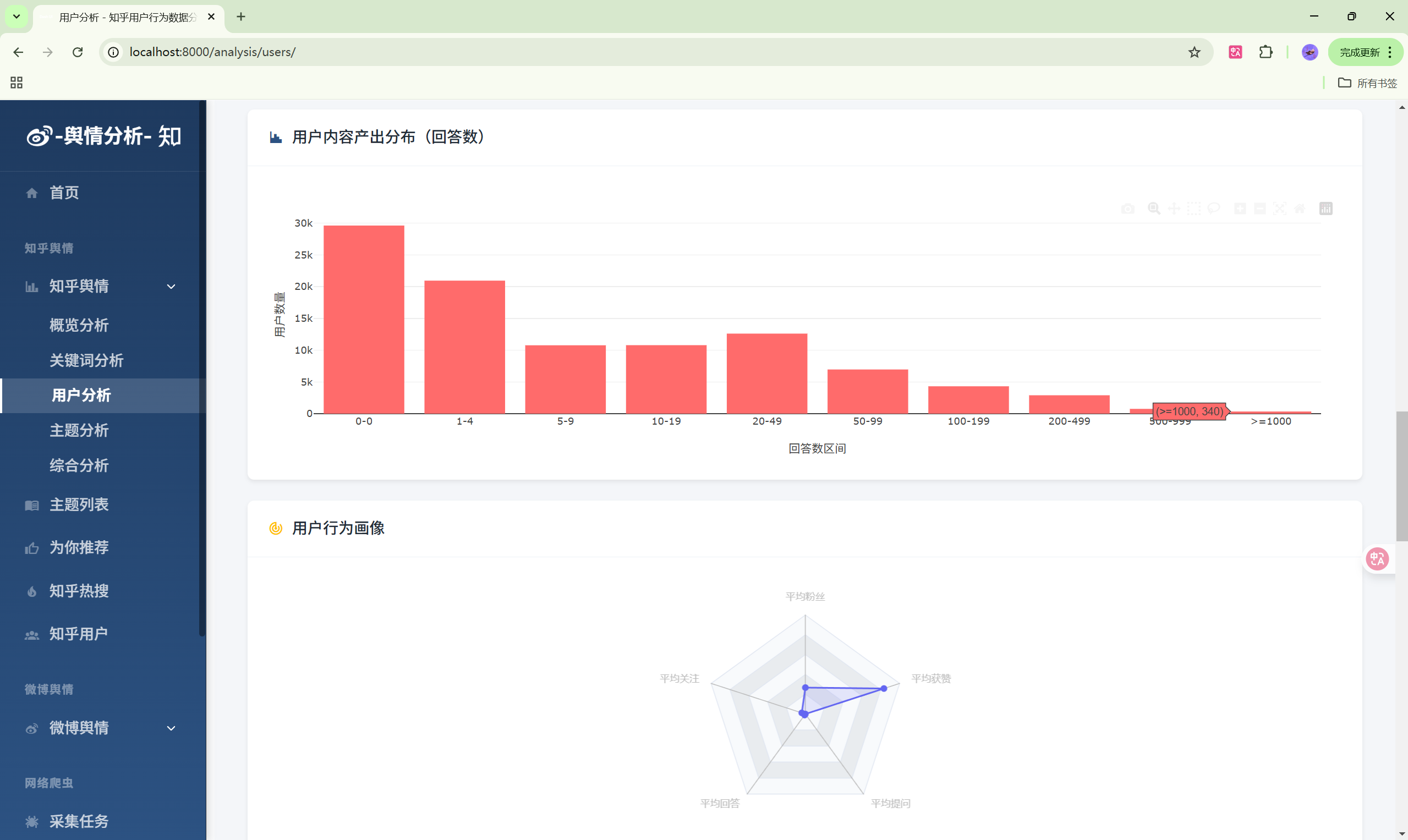
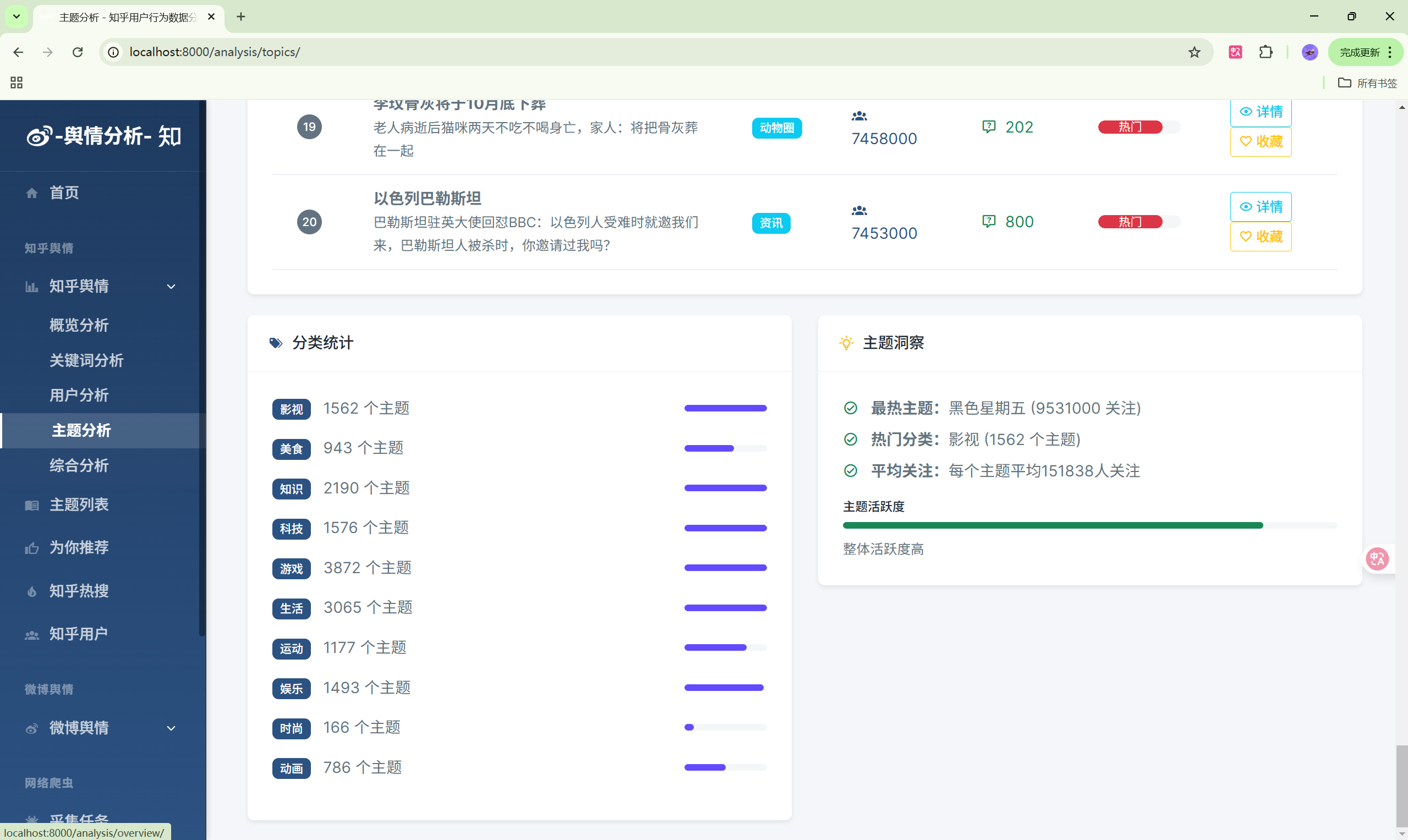
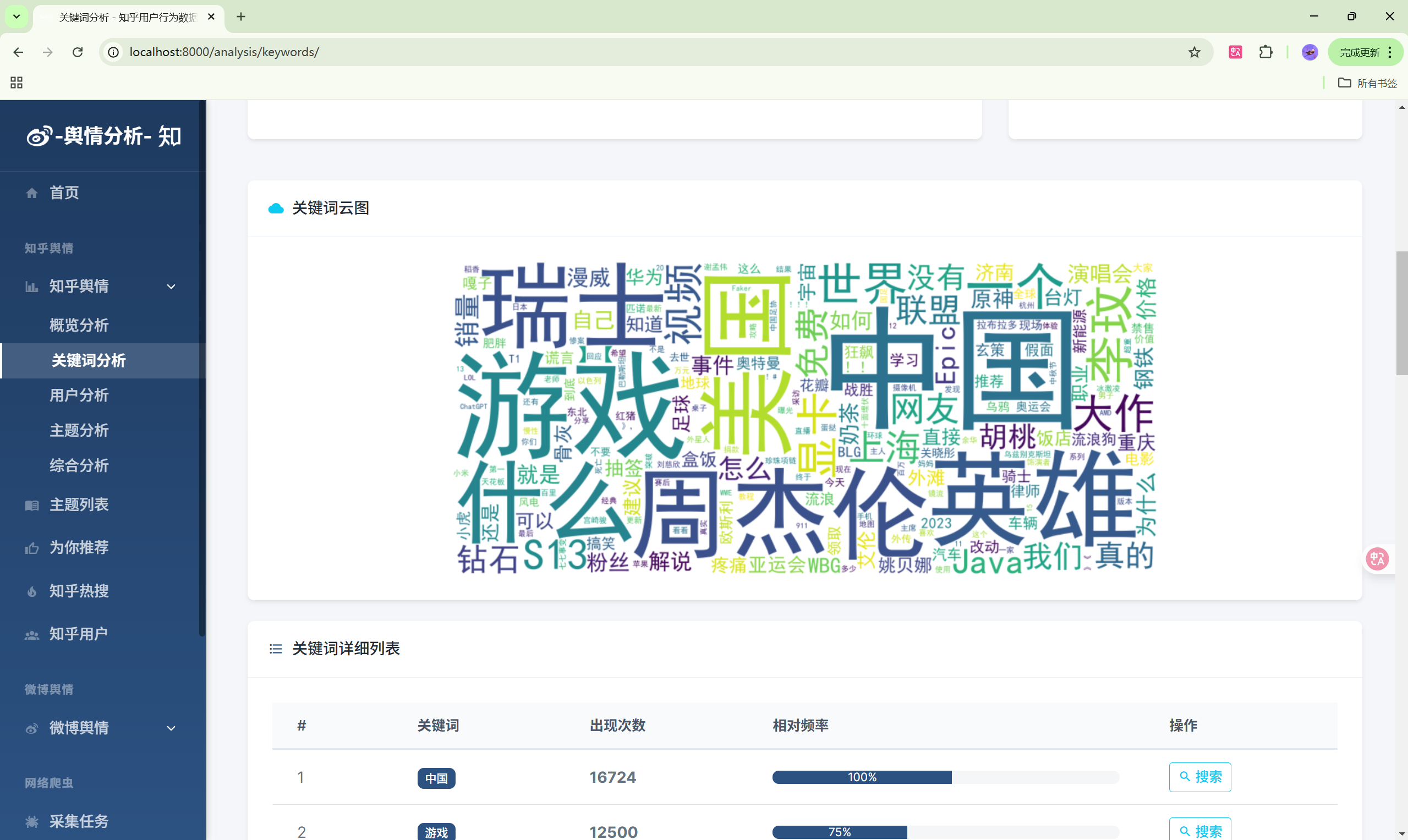
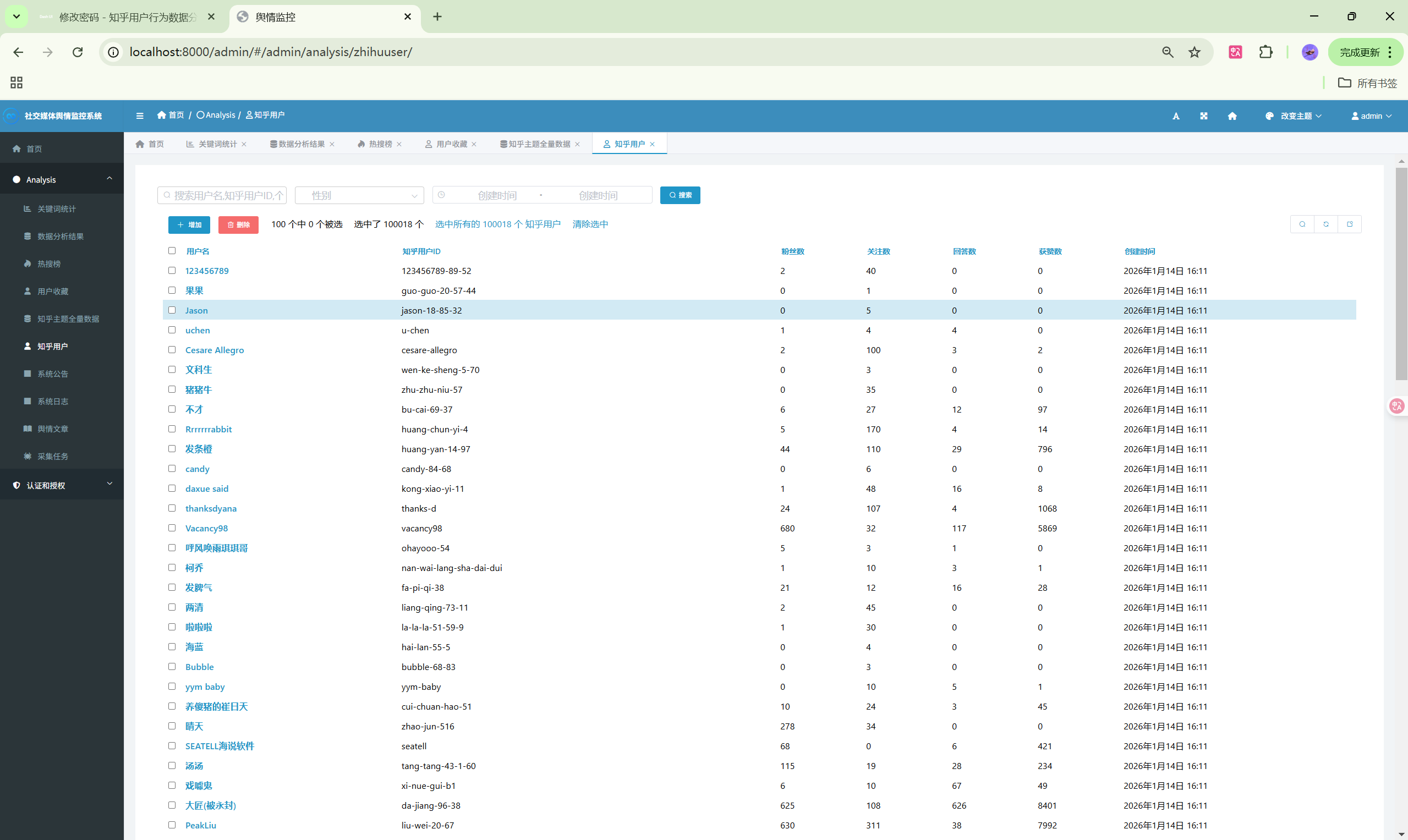
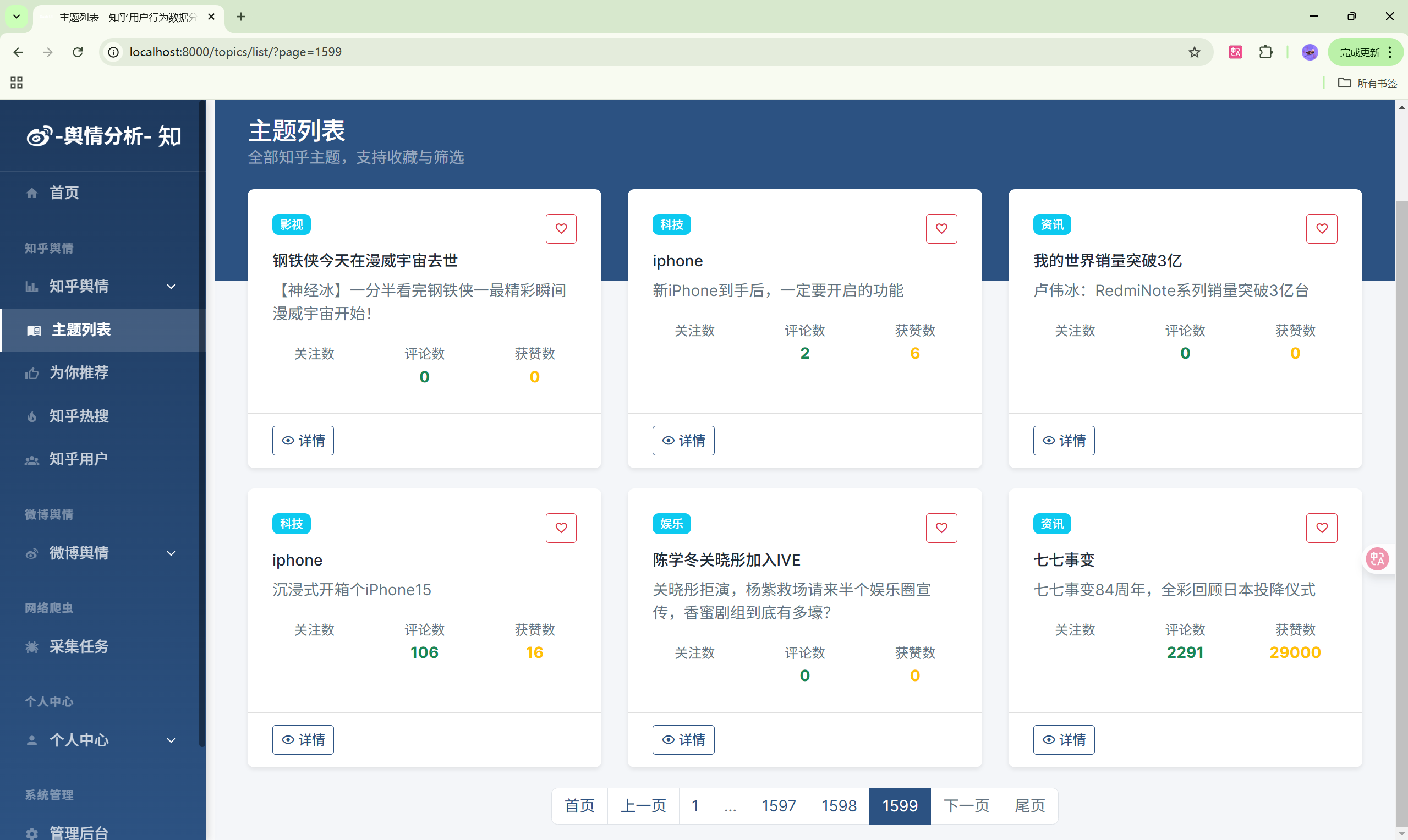
3. 知乎数据分析模块
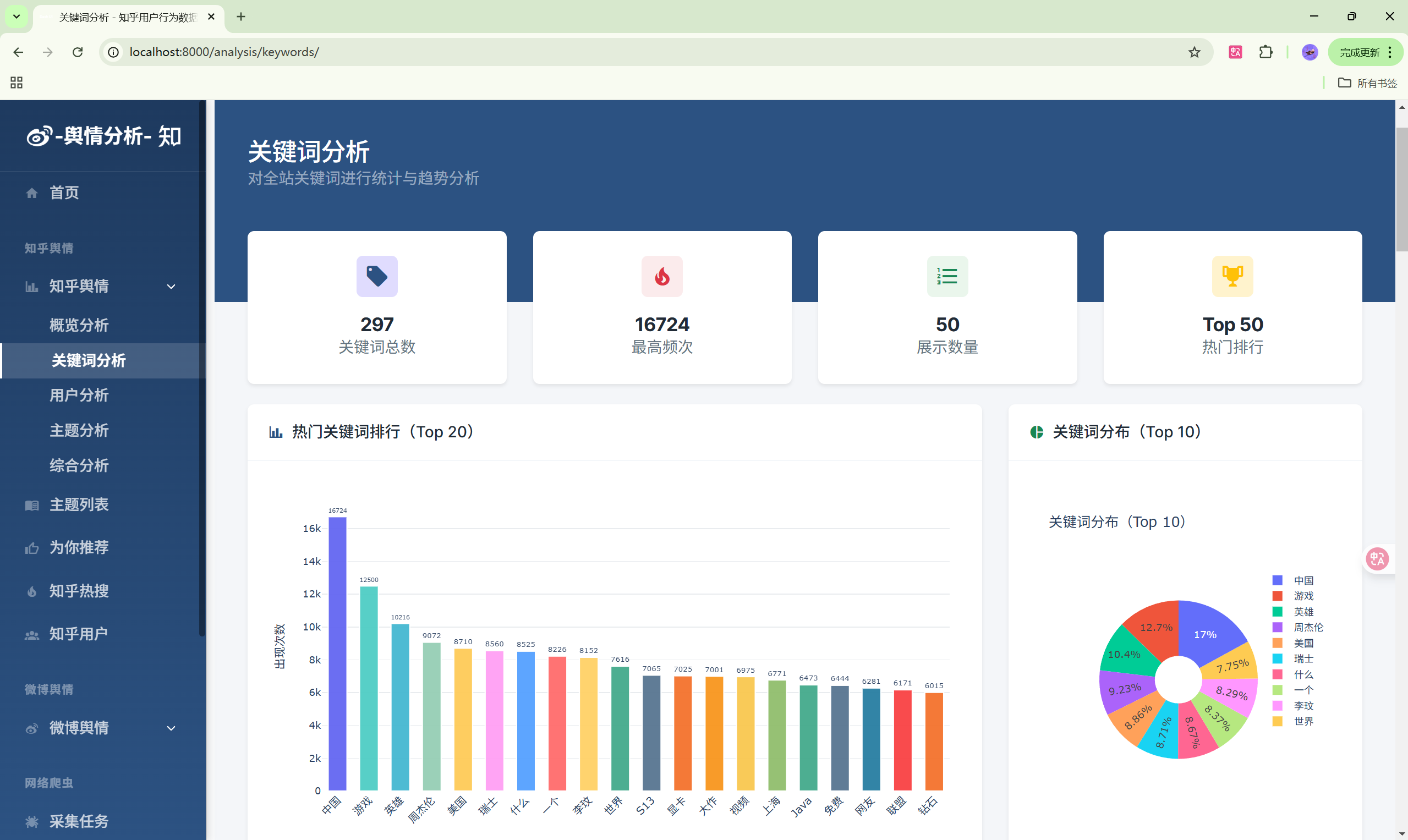
功能列表
- 关键词分析:热门关键词排行、词云图
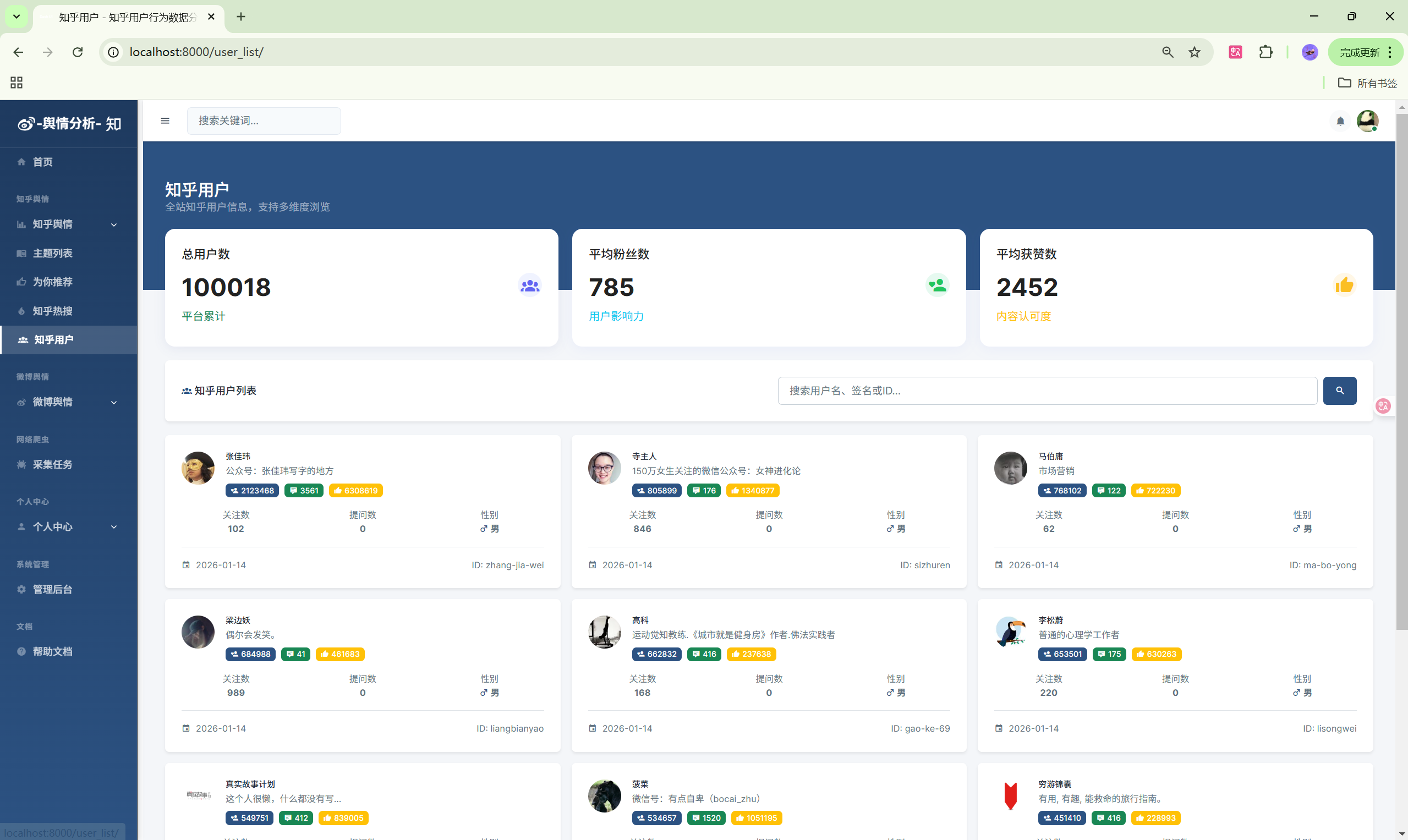
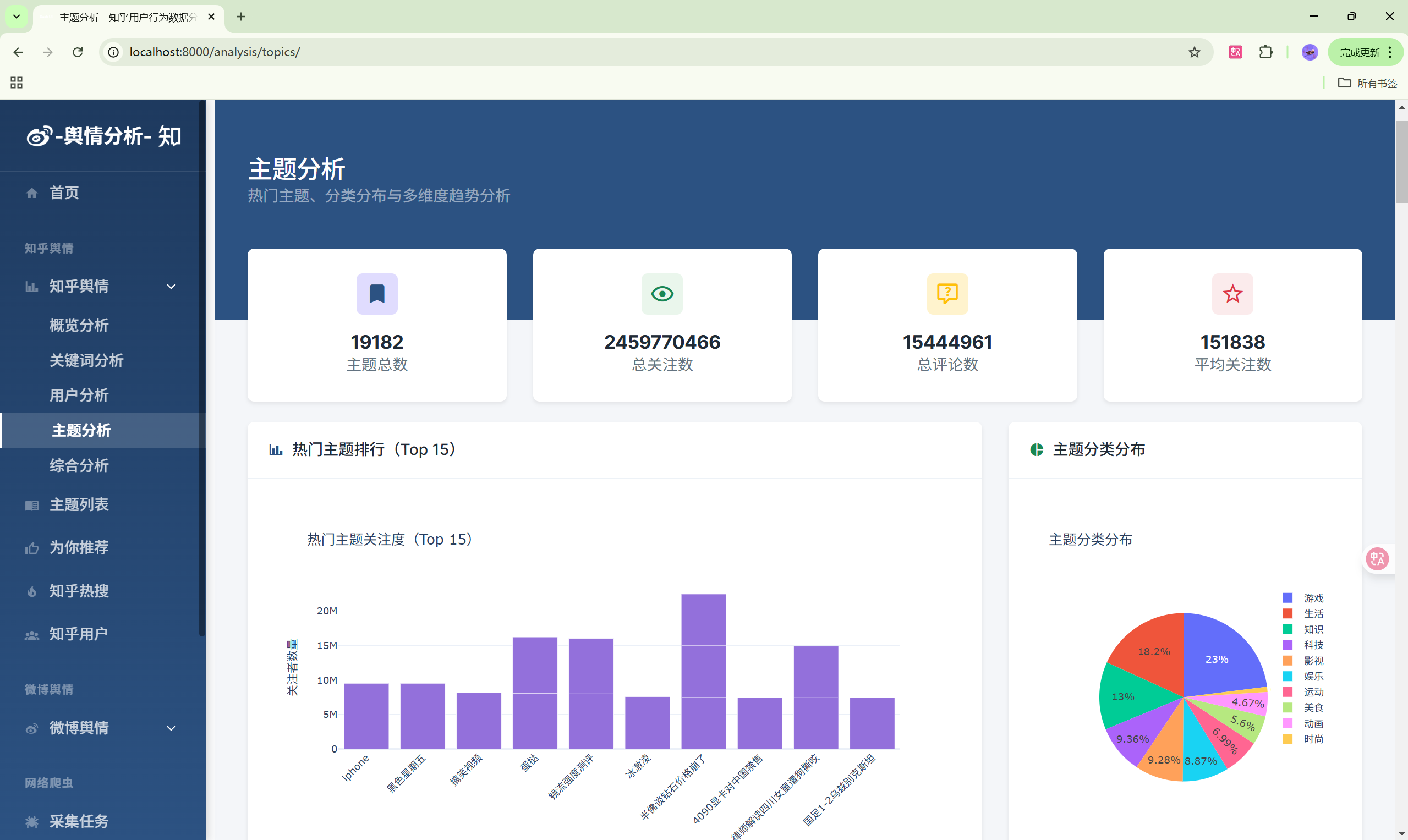
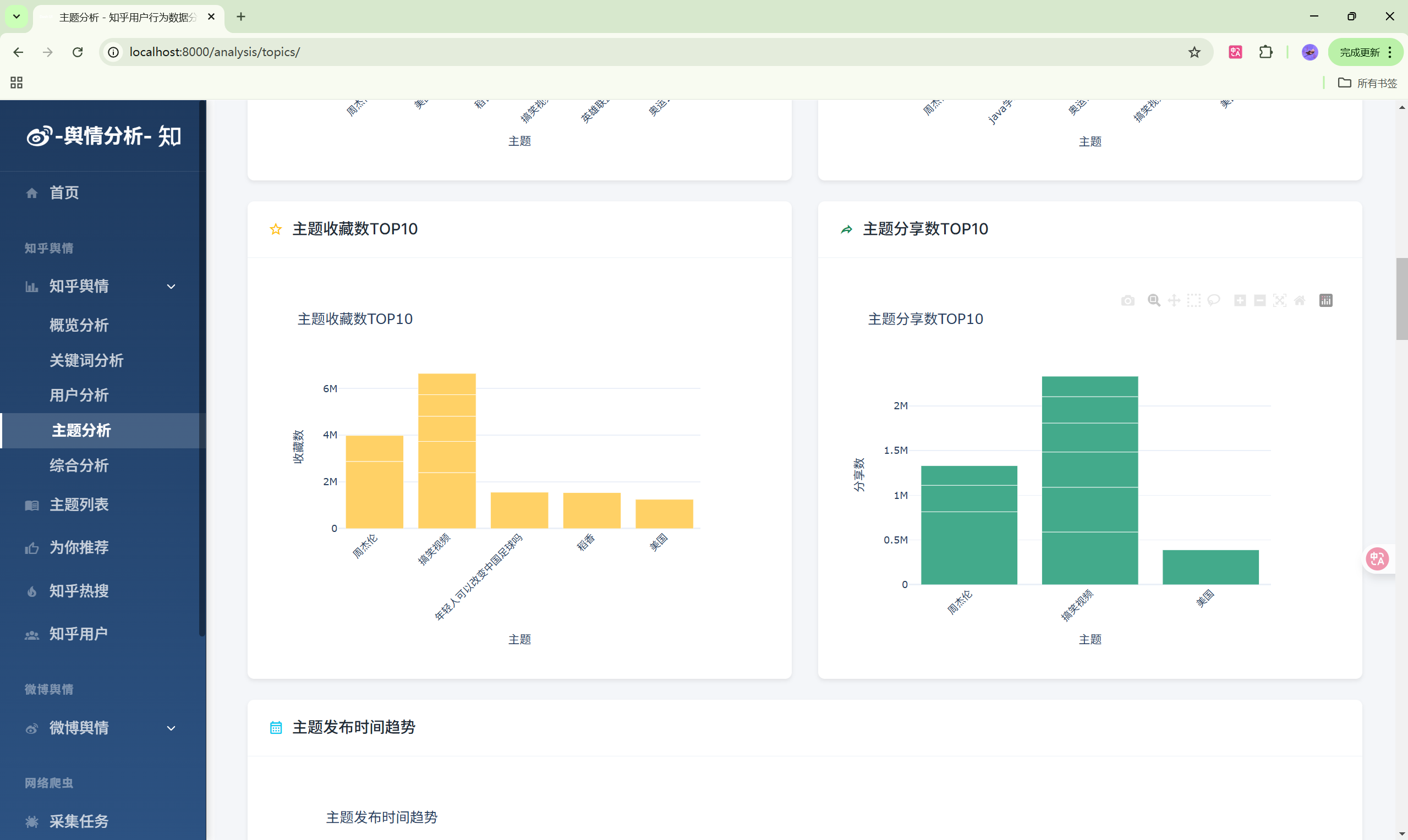
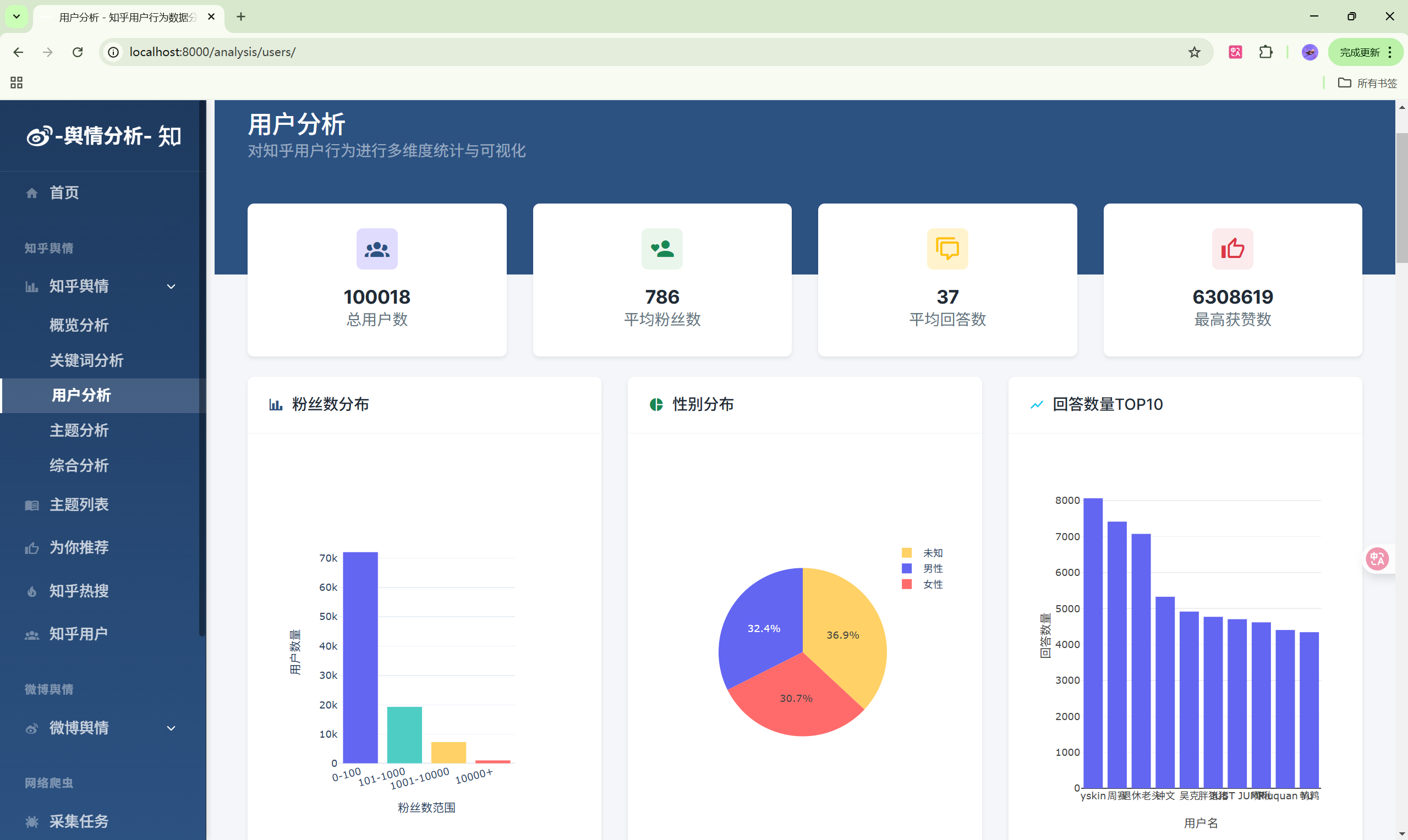
- 用户分析:知乎用户画像统计
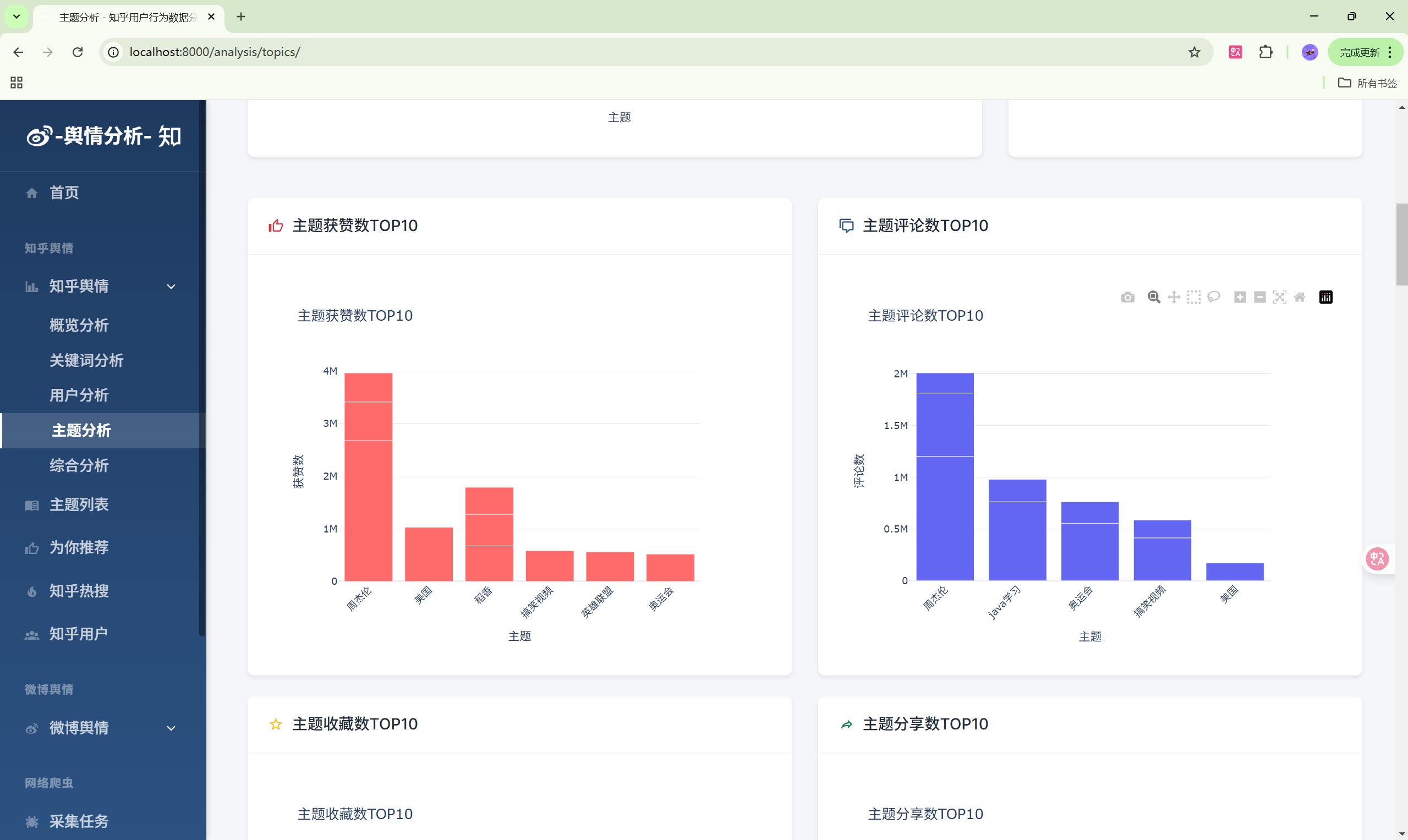
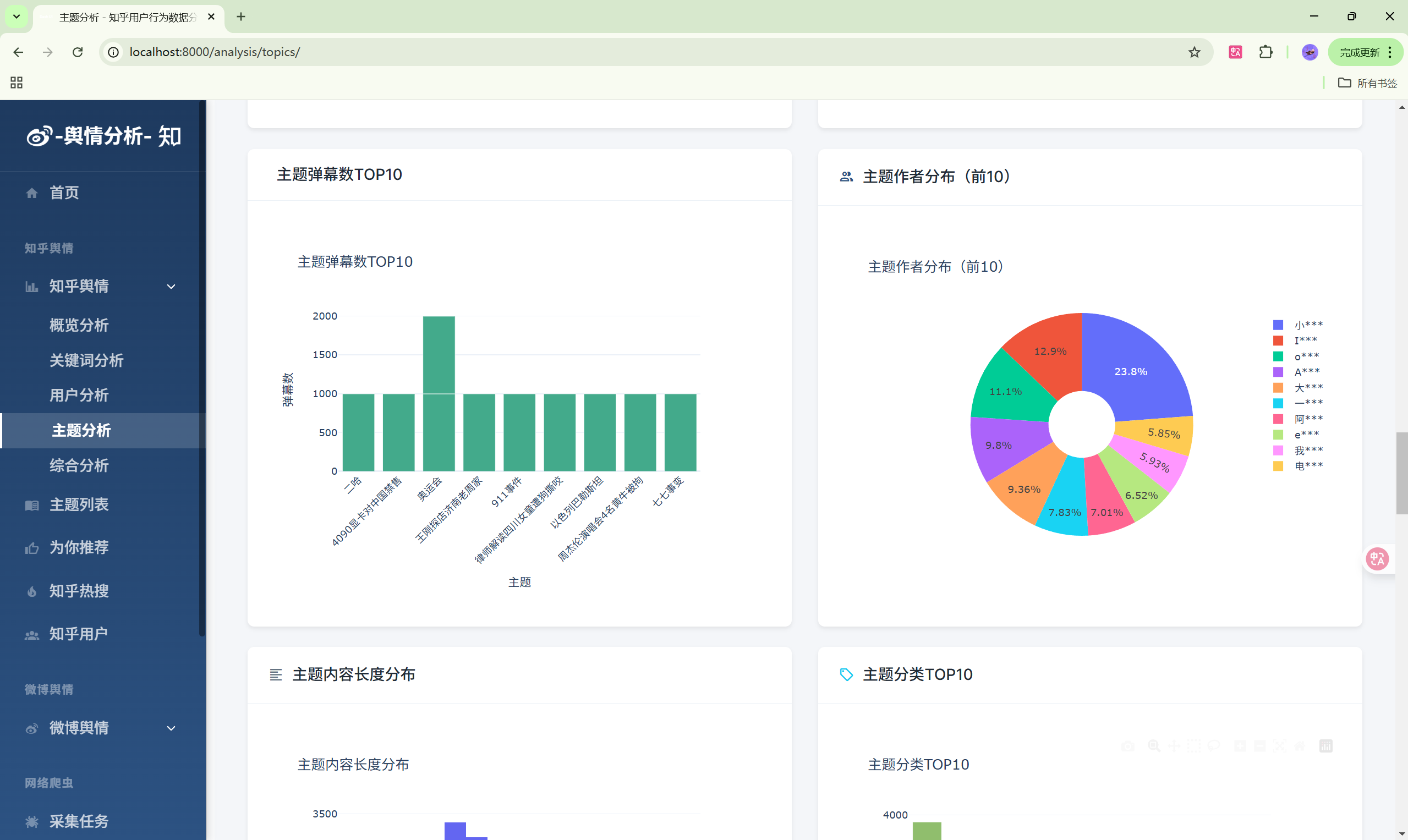
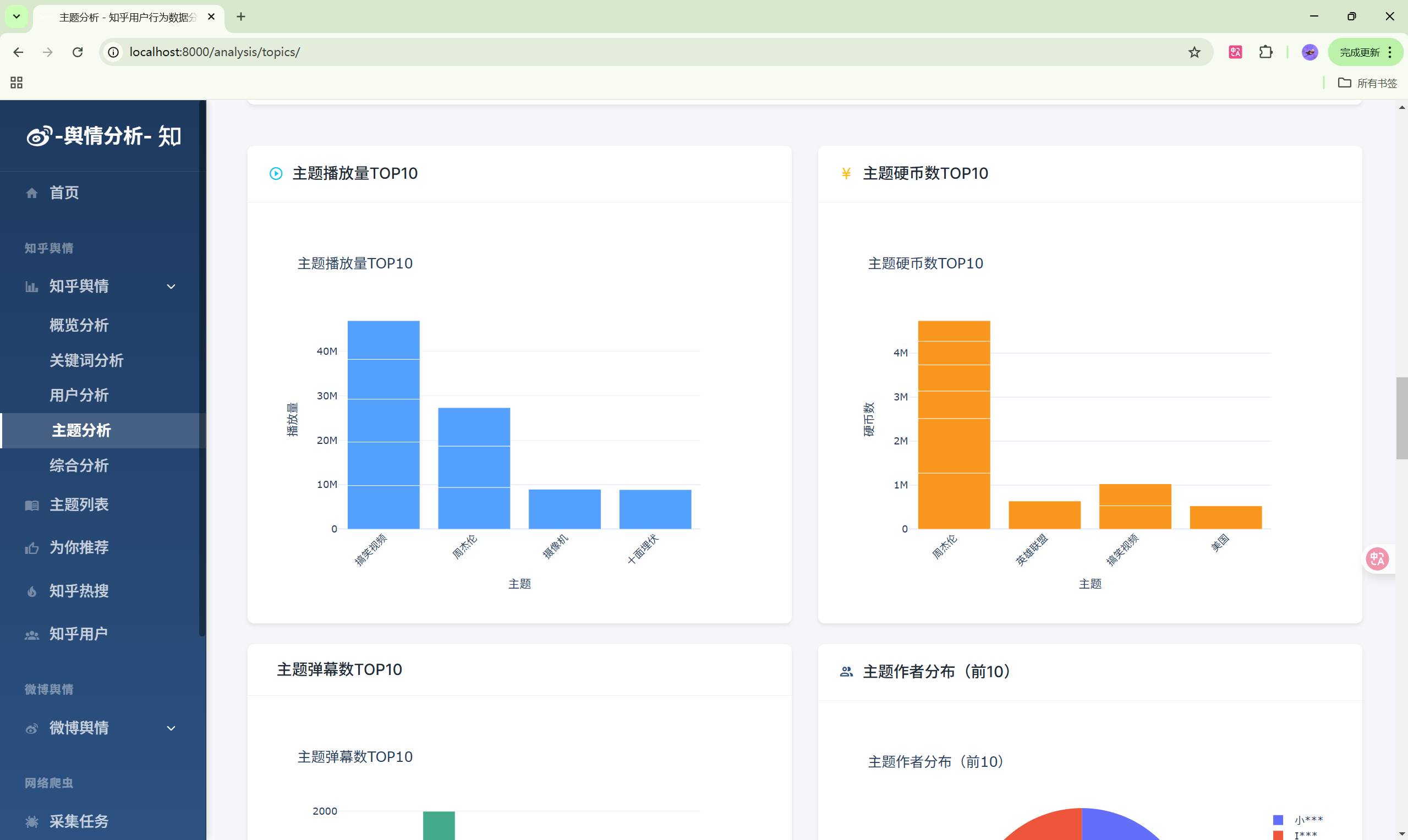
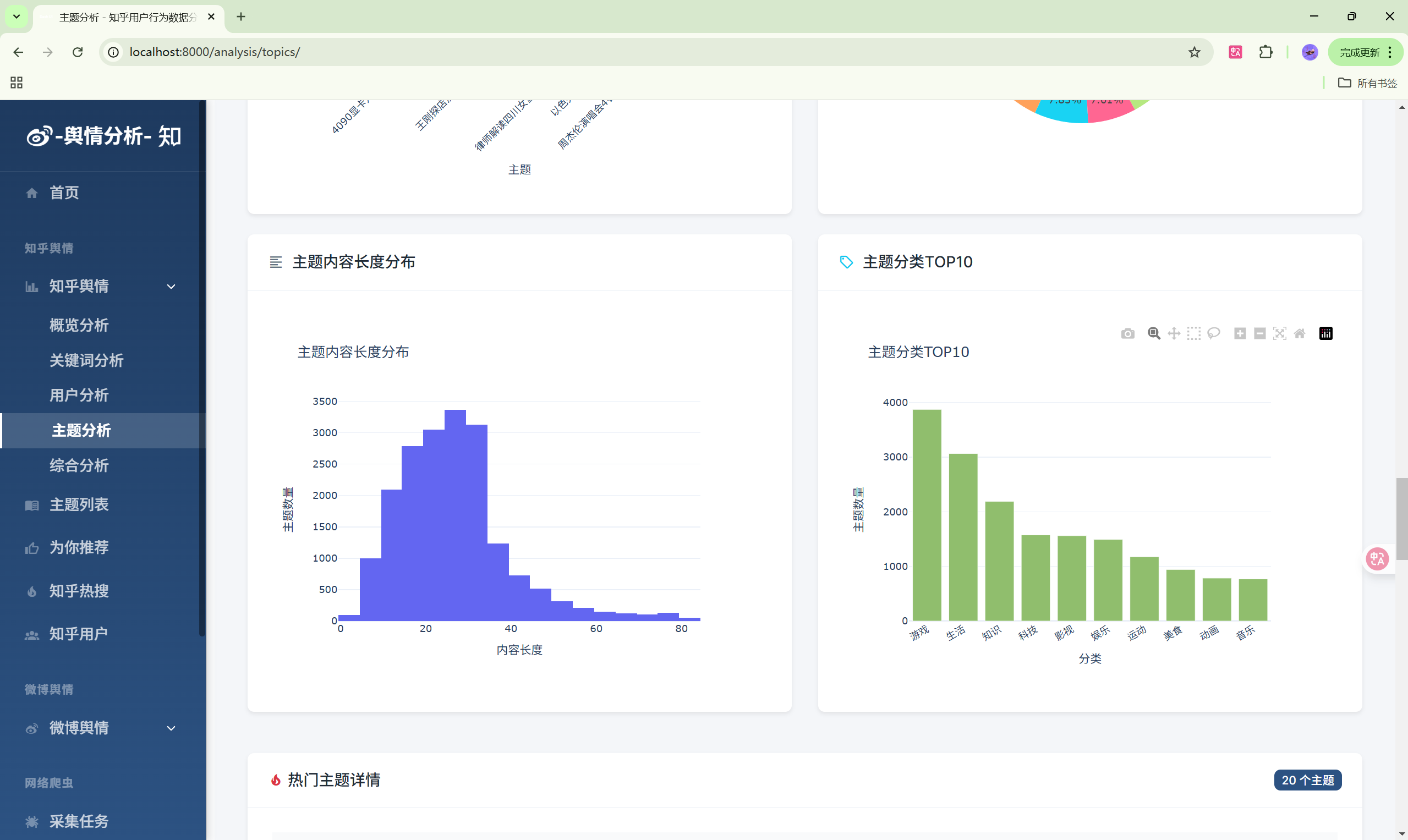
- 主题分析:主题热度排行
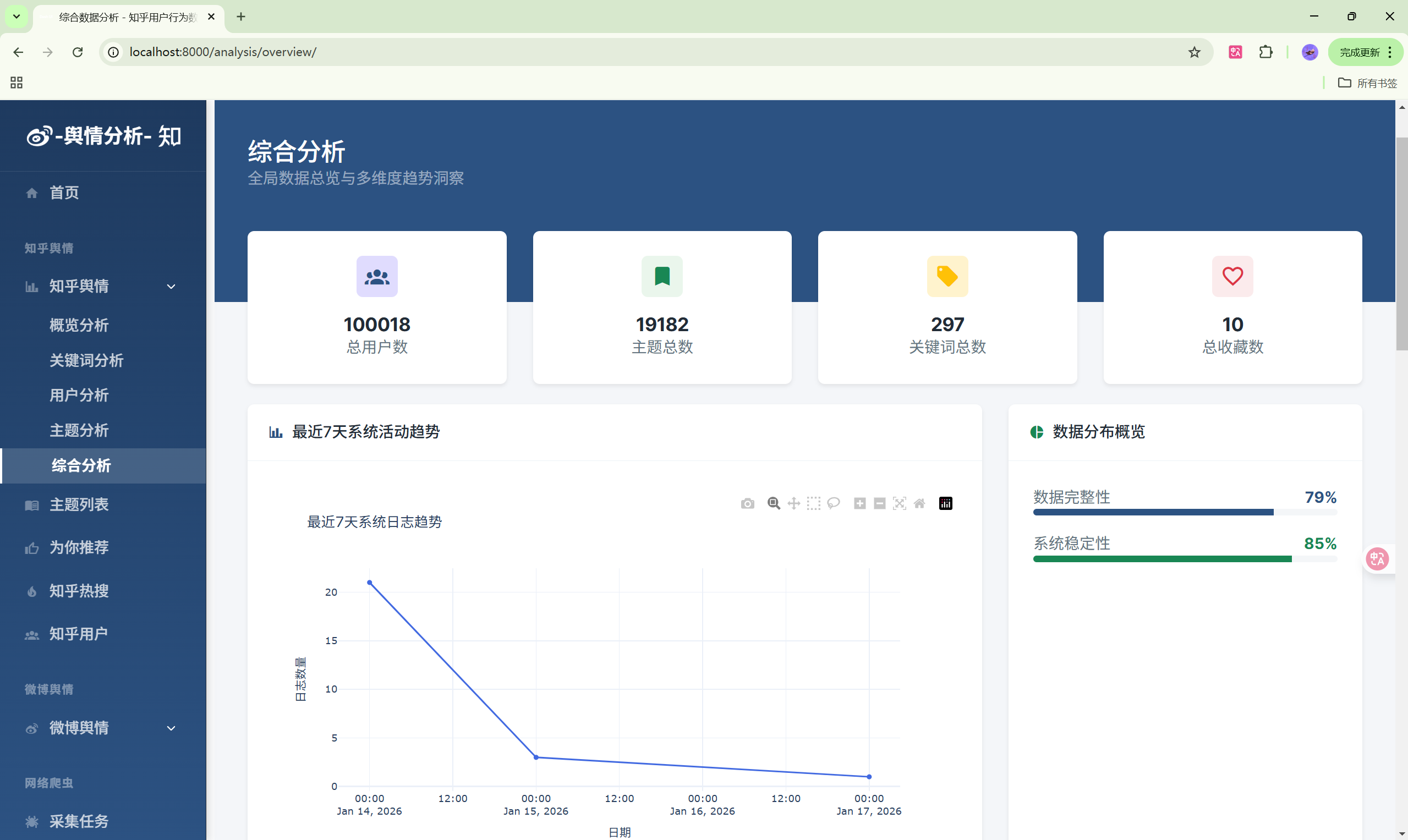
- 数据总览:多维度数据统计
访问路径
| 功能 | URL | 说明 |
|---|---|---|
| 关键词分析 | /analysis/keywords/ | 关键词统计 |
| 用户分析 | /analysis/users/ | 用户数据分析 |
| 主题分析 | /analysis/topics/ | 主题热度分析 |
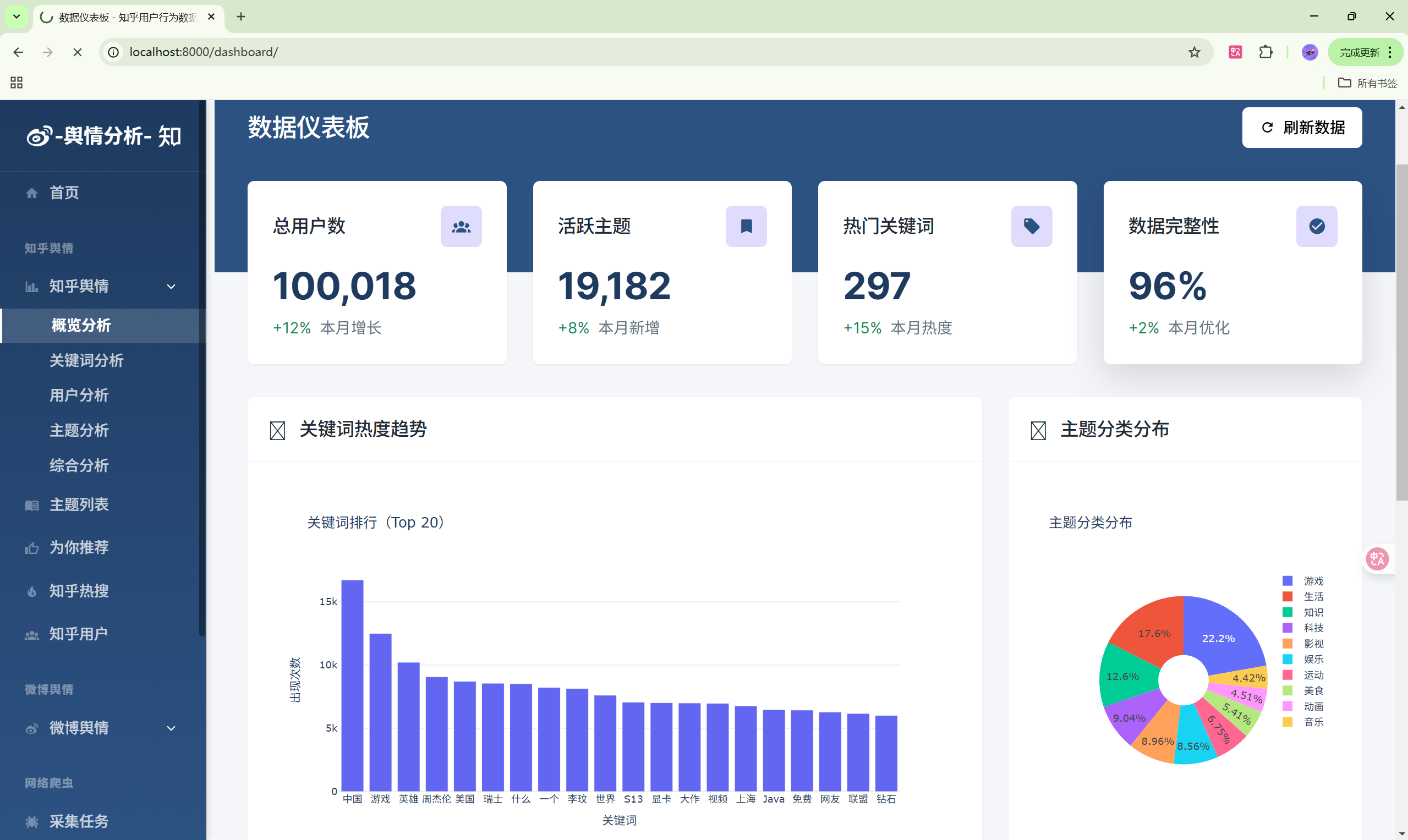
| 数据总览 | /analysis/overview/ | 综合数据统计 |
4. 数据可视化模块
图表类型
- 柱状图:数据对比展示
- 折线图:趋势变化分析
- 饼图:比例分布展示
- 词云图:关键词可视化
- 地图:地域分布展示
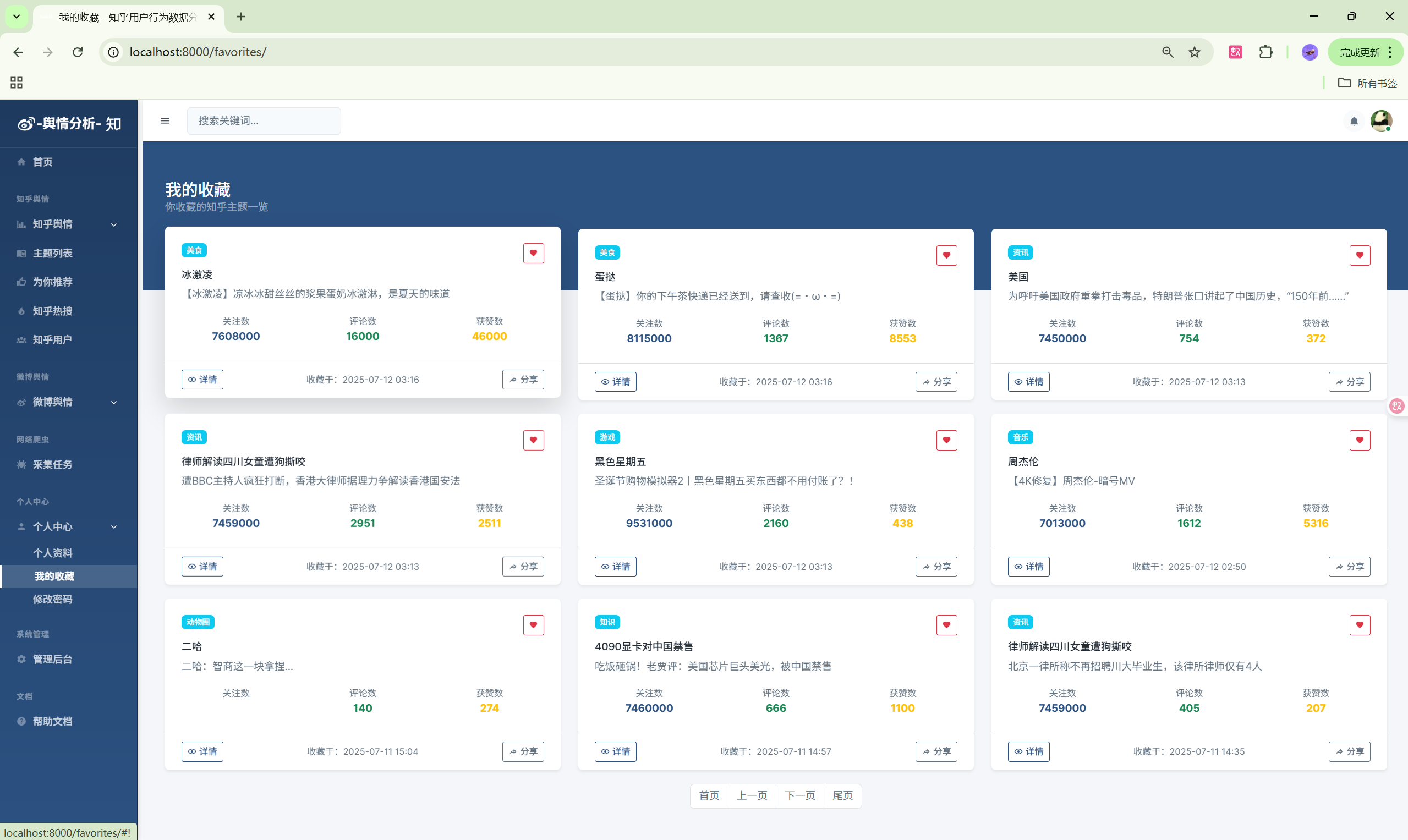
5. 收藏与推荐模块
功能列表
- 主题收藏:收藏感兴趣的主题
- 我的收藏:查看收藏列表
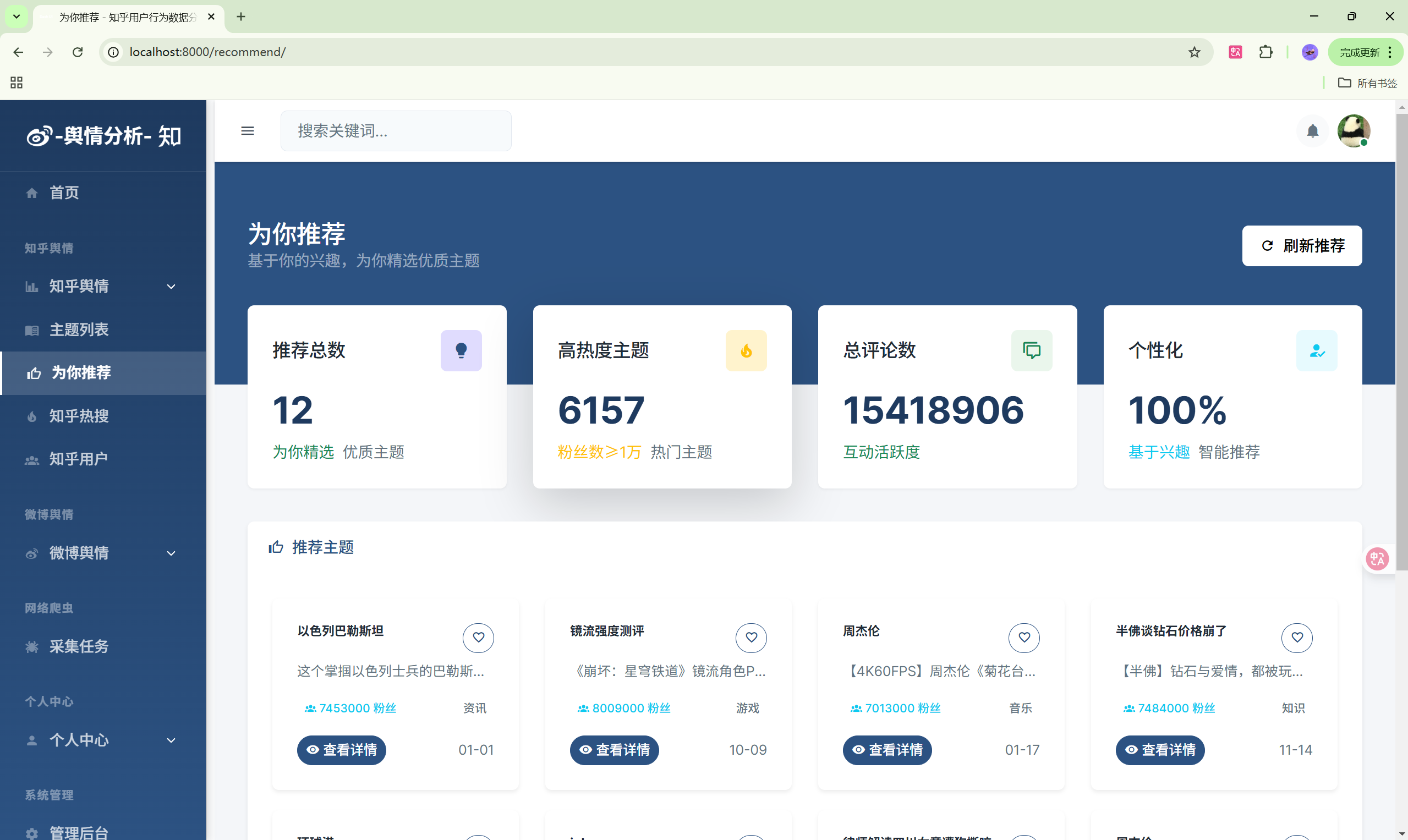
- 智能推荐:基于行为的个性化推荐
访问路径
| 功能 | URL | 说明 |
|---|---|---|
| 我的收藏 | /favorites/ | 收藏列表 |
| 添加收藏 | /favorite/{topic_id}/ | 收藏主题 |
| 取消收藏 | /unfavorite/{topic_id}/ | 取消收藏 |
| 推荐主题 | /recommend/ | 智能推荐 |
操作手册
1. 系统登录
- 访问系统首页 http://your_domain.com/
- 点击右上角"登录"按钮
- 输入用户名和密码
- 点击"登录"按钮完成登录
2. 用户注册
- 在登录页面点击"注册新账户"
- 填写用户名、邮箱、密码
- 确认密码后点击"注册"
- 注册成功后自动跳转登录
3. 查看微博热搜
- 登录系统后进入首页
- 点击导航栏"微博监控" > "热搜榜"
- 查看实时热搜排行榜
- 点击热搜词可跳转至微博查看详情
4. 文章搜索
- 进入"微博监控" > "文章列表"
- 在搜索框输入关键词
- 可选择筛选条件:平台、情感、时间范围
- 点击"搜索"查看结果
5. 情感分析查看
- 进入"微博监控" > "情感分析"
- 查看情感分布饼图
- 查看情感趋势折线图
- 可按时间范围筛选数据
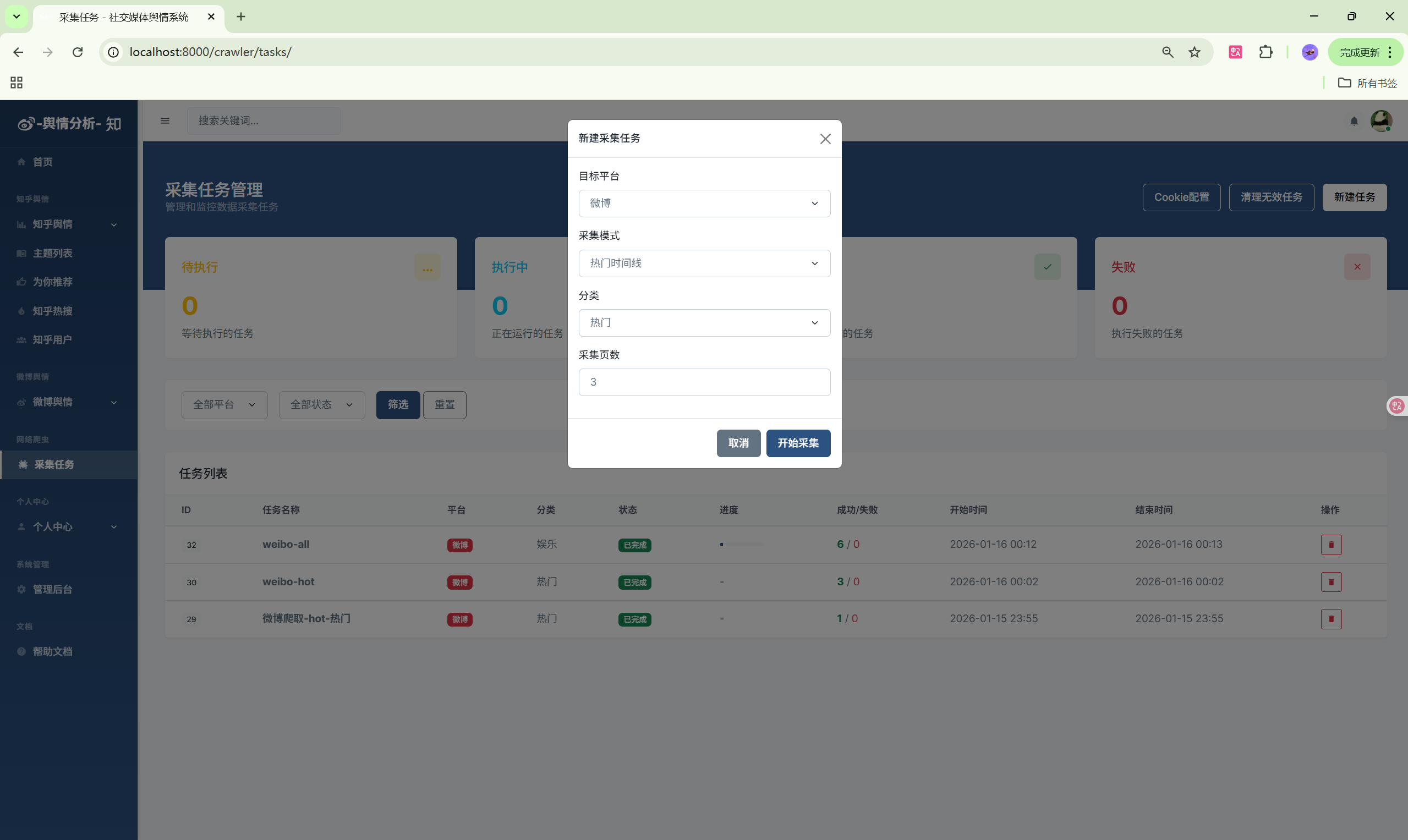
6. 启动数据采集
- 进入"爬虫任务"页面
- 点击"新建任务"按钮
- 选择目标平台(微博/知乎)
- 输入采集关键词或分类
- 点击"开始采集"启动任务
- 在任务列表查看采集进度
7. 知乎数据分析
- 进入"数据分析"菜单
- 选择分析类型:关键词/用户/主题
- 查看图表和统计数据
- 可导出分析报告
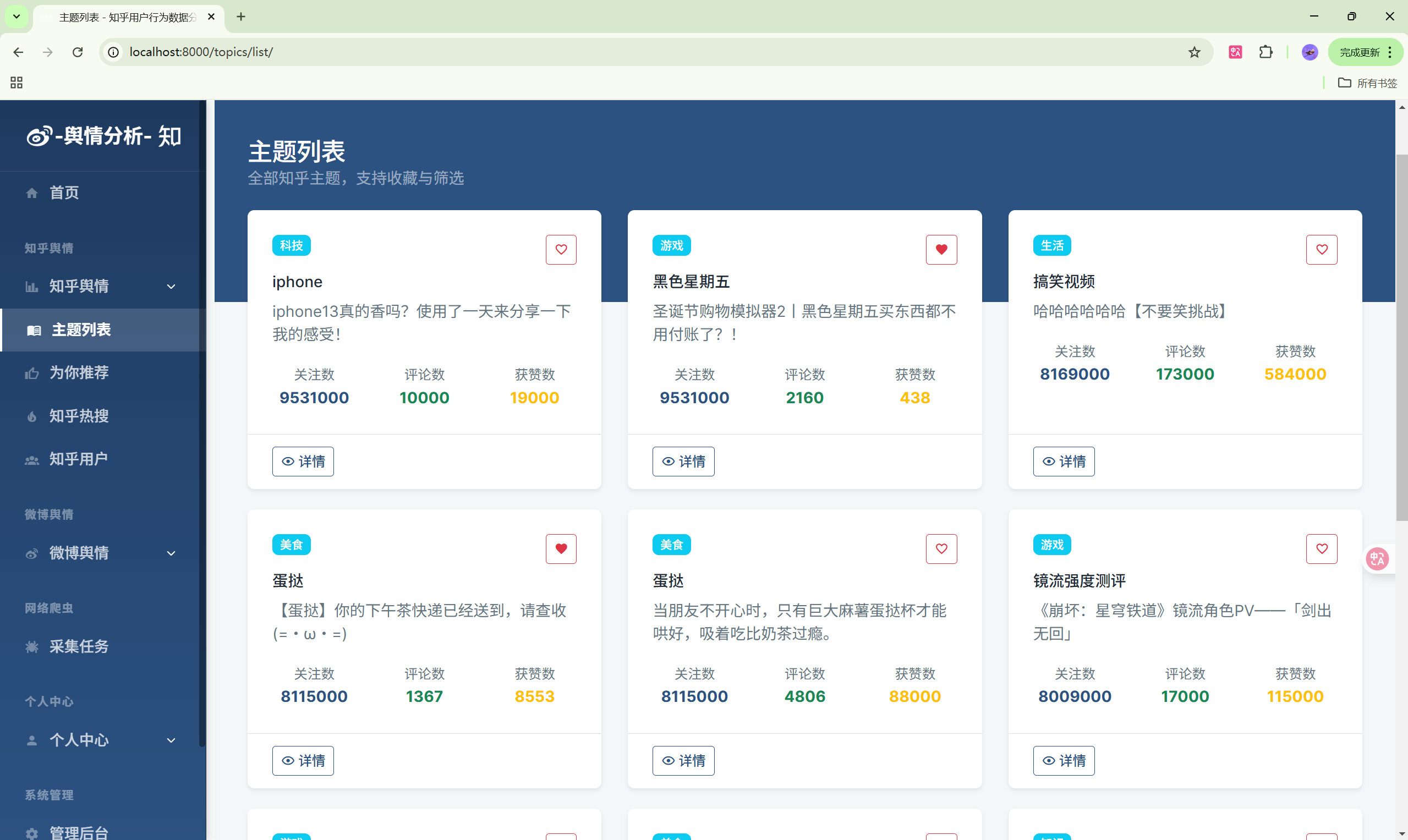
8. 收藏主题
- 浏览主题列表页面
- 点击主题卡片上的收藏图标
- 或进入主题详情页点击"收藏"按钮
- 在"我的收藏"页面管理收藏
API文档
仪表盘API
获取仪表盘概览
GET /api/dashboard/overview/响应示例:
json
{
"code": 200,
"data": {
"total_articles": 15680,
"today_articles": 234,
"positive_ratio": 45.2,
"negative_ratio": 18.5,
"neutral_ratio": 36.3
}
}获取趋势数据
GET /api/dashboard/trend/?days=7参数:
- days: 天数(默认7)
获取情感分布
GET /api/dashboard/sentiment/获取平台分布
GET /api/dashboard/platform/获取地区分布
GET /api/dashboard/region/文章API
获取文章列表
GET /api/articles/?page=1&page_size=20&keyword=xxx&platform=weibo&sentiment=positive参数:
- page: 页码
- page_size: 每页数量
- keyword: 搜索关键词
- platform: 平台筛选
- sentiment: 情感筛选
搜索文章
GET /api/search/articles/?q=关键词&platform=weibo热搜API
获取热搜榜
GET /api/hotsearch/{platform}/平台参数:weibo, zhihu, douyin
响应示例:
json
{
"code": 200,
"data": [
{
"rank": 1,
"keyword": "热搜词",
"hot_value": 5234567,
"url": "https://..."
}
]
}获取微博实时热搜
GET /api/weibo/realtime-hotsearch/分析API
作者排行
GET /api/analytics/author-ranking/?limit=10时段分析
GET /api/analytics/hourly/平台对比
GET /api/analytics/platform-compare/采集API
启动采集任务
POST /api/crawl/start/
Content-Type: application/json
{
"platform": "weibo",
"keyword": "搜索关键词",
"category": "分类"
}情感分析
POST /api/sentiment/analyze/
Content-Type: application/json
{
"article_ids": [1, 2, 3]
}数据库设计
核心数据表
Article(舆情文章表)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INT | 主键 |
| platform | VARCHAR(20) | 平台:weibo/zhihu/douyin |
| platform_id | VARCHAR(100) | 平台原始ID |
| title | VARCHAR(500) | 标题 |
| content | TEXT | 正文内容 |
| content_len | INT | 内容字数 |
| like_num | INT | 点赞数 |
| comments_len | INT | 评论数 |
| reposts_count | INT | 转发数 |
| view_count | INT | 浏览数 |
| region | VARCHAR(50) | 发布地区 |
| created_at | DATETIME | 发布时间 |
| crawl_time | DATETIME | 采集时间 |
| author_name | VARCHAR(100) | 作者名称 |
| sentiment | VARCHAR(20) | 情感:positive/negative/neutral |
| sentiment_score | DECIMAL(5,4) | 情感分数 |
| keywords | VARCHAR(500) | 关键词 |
HotSearch(热搜表)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INT | 主键 |
| platform | VARCHAR(20) | 平台 |
| rank_num | INT | 排名 |
| keyword | VARCHAR(200) | 热搜关键词 |
| hot_value | BIGINT | 热度值 |
| category | VARCHAR(50) | 分类 |
| url | VARCHAR(500) | 链接 |
| is_hot | BOOLEAN | 是否热门 |
| is_new | BOOLEAN | 是否新上榜 |
| fetch_time | DATETIME | 抓取时间 |
CrawlTask(采集任务表)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INT | 主键 |
| task_name | VARCHAR(100) | 任务名称 |
| platform | VARCHAR(20) | 目标平台 |
| keywords | VARCHAR(500) | 采集关键词 |
| status | VARCHAR(20) | 状态:pending/running/completed/failed |
| total_count | INT | 采集总数 |
| success_count | INT | 成功数量 |
| fail_count | INT | 失败数量 |
| start_time | DATETIME | 开始时间 |
| end_time | DATETIME | 结束时间 |
| error_msg | TEXT | 错误信息 |
ZhihuUser(知乎用户表)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INT | 主键 |
| user_id | VARCHAR(100) | 知乎用户ID |
| name | VARCHAR(200) | 用户名 |
| headline | TEXT | 个人签名 |
| gender | INT | 性别 |
| follower_count | INT | 粉丝数 |
| following_count | INT | 关注数 |
| answer_count | INT | 回答数 |
| voteup_count | INT | 获赞数 |
ZhihuTopic(知乎主题表)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INT | 主键 |
| title | VARCHAR(256) | 标题 |
| description | TEXT | 描述 |
| category | VARCHAR(64) | 分类 |
| play_count | INT | 播放数 |
| comment_count | INT | 评论数 |
| like_count | INT | 点赞数 |
| favorite_count | INT | 收藏数 |
| share_count | INT | 分享数 |
| author_name | VARCHAR(128) | 作者名称 |
ER关系图
┌─────────────┐ ┌─────────────┐
│ Article │ │ HotSearch │
├─────────────┤ ├─────────────┤
│ id │ │ id │
│ platform │ │ platform │
│ content │ │ keyword │
│ sentiment │ │ hot_value │
│ author_name │ │ fetch_time │
└─────────────┘ └─────────────┘
┌─────────────┐ ┌─────────────┐
│ CrawlTask │ │ ZhihuUser │
├─────────────┤ ├─────────────┤
│ id │ │ id │
│ task_name │ │ user_id │
│ platform │ │ name │
│ status │ │ follower │
│ total_count │ │ voteup │
└─────────────┘ └─────────────┘
┌─────────────┐ ┌─────────────┐
│ ZhihuTopic │◄──────│UserFavorite │
├─────────────┤ ├─────────────┤
│ id │ │ id │
│ title │ │ user_id(FK) │
│ category │ │ topic_id(FK)│
│ like_count │ │ created_at │
└─────────────┘ └─────────────┘
│
│ FK
▼
┌─────────────┐
│ User │
├─────────────┤
│ id │
│ username │
│ email │
└─────────────┘常见问题
Q1: 如何修改数据库连接?
编辑 social_media_analysis/settings.py 中的 DATABASES 配置:
python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '数据库名',
'USER': '用户名',
'PASSWORD': '密码',
'HOST': '主机地址',
'PORT': '3306',
}
}Q2: 如何添加新的数据分析功能?
- 在
views.py中编写视图函数 - 在
urls.py中添加URL路由 - 在
templates/中创建HTML模板 - 使用ECharts进行数据可视化
Q3: 爬虫无法获取数据?
可能原因:
- 网络连接问题
- 目标网站反爬限制
- Cookie或登录状态失效
解决方法:
- 检查网络连接
- 更新请求头和Cookie
- 添加请求延迟避免被封
Q4: 情感分析不准确?
SnowNLP的情感分析基于训练数据,对于特定领域可能不够准确。可以:
- 收集领域数据重新训练模型
- 结合关键词规则进行修正
- 使用更专业的NLP模型
Q5: 如何备份数据?
bash
# 导出数据
python manage.py dumpdata > backup.json
# 导入数据
python manage.py loaddata backup.json
# MySQL备份
mysqldump -u root -p sentiment_db > backup.sqlQ6: 如何部署HTTPS?
使用Nginx配置SSL证书:
nginx
server {
listen 443 ssl;
server_name your_domain.com;
ssl_certificate /path/to/cert.pem;
ssl_certificate_key /path/to/key.pem;
# 其他配置...
}Q7: 系统运行缓慢?
优化建议:
- 为数据库表添加索引
- 使用Redis缓存热点数据
- 优化SQL查询语句
- 考虑分表或读写分离
更新日志
v2.0.0
- 新增微博舆情监控功能
- 新增情感分析模块
- 新增热搜榜实时监控
- 新增地区分布地图
- 优化UI设计,采用深蓝色主题
- 重构爬虫服务模块
v1.0.0
- 初始版本发布
- 知乎用户行为分析
- 关键词分析与词云
- 用户收藏与推荐
技术支持
如有问题或建议,请通过以下方式联系:
- 查看帮助文档:/help/
- 系统公告:/announcements/
声明:本系统仅供学习研究使用,请遵守相关法律法规和平台使用条款。