第一章:计算机内存的基本认知
1.1 二进制数据是什么?
想象一下计算机的内存就像一条无限长的磁带,每个格子只能存储0或1(一个bit)。8个格子组成一个字节(byte),就像:
[0][1][1][0][1][0][0][1] = 1个字节(二进制数)
1.2 为什么需要类型?
同样的一串01101001:
· 作为整数:是105
· 作为ASCII字符:是字母"i"
· 作为颜色值:可能是某种灰色
关键点:内存里的0和1没有意义,意义来自于我们如何解释它。

同样的一串二进制数字01101001,就像一串摩尔斯电码,本身没有固定的意义,但我们可以用不同的规则去解读它,从而得到不同的信息。
1.2.1 作为整数:105
如果把01101001看作一个二进制数,那么它可以直接转换成十进制数。转换规则是每一位的数字乘以对应的2的幂次(从右往左,最右边是2⁰):
0×2⁷ + 1×2⁶ + 1×2⁵ + 0×2⁴ + 1×2³ + 0×2² + 0×2¹ + 1×2⁰
= 0 + 64 + 32 + 0 + 8 + 0 + 0 + 1
= 105从右往左看哪些位置是1:
text
位置 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7
二进制| 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
权值 | 2⁰| 2¹| 2²| 2³| 2⁴| 2⁵| 2⁶| 2⁷
| 1 | 2 | 4 | 8 |16 |32 |64 |128是1的位置有:位置0、3、5、6
所以:1 + 8 + 32 + 64 = 105
所以它就是十进制数105。

1.2.2 作为ASCII字符:字母 "i"
计算机中常用ASCII码 来表示字符,它规定一个数字对应一个字符。比如十进制105 对应小写字母 i 。既然01101001表示数字105,那么在ASCII规则下,它自然就代表字母"i"。

1.2.3 作为颜色值:某种灰色
在计算机中,颜色通常用红(R)、绿(G)、蓝(B)三个分量来表示,每个分量用一个8位二进制数(0~255)表示亮度。如果三个分量值相同,就会得到灰色(0是黑色,255是白色)。
如果把01101001当作一个颜色分量的亮度值,它对应的十进制是105,那么:
- 如果是灰度图像中的一个像素,这个值直接表示一种灰色(105/255 ≈ 41% 的亮度,偏暗的灰色)。
- 如果是RGB颜色 ,且红、绿、蓝都设为105,就得到RGB(105,105,105),也是一种灰色。

1.2.4 为什么可以这样?
计算机中所有数据(数字、文字、图片、声音)归根结底都是一连串的0和1。同样的0和1序列,在不同的上下文和解释规则下,就会变成不同的东西。就像同样的墨水痕迹:
- 在数学题里是数字,
- 在英文里是字母,
- 在画家里是深浅不同的灰色。

关键就在于我们用什么"密码本"去翻译它:
- 用二进制转十进制的规则,得到数字105;
- 用ASCII码表,得到字母"i";
- 用颜色编码规则,得到灰色。
这就是计算机灵活性的体现:数据本身没有意义,赋予它意义的规则决定了它是什么。
第二章:ArrayBuffer - 原始内存空间
2.1 最基础的比喻
ArrayBuffer = 一片空白的画布
javascript
// 申请一块16字节的空白内存
const buffer = new ArrayBuffer(16);这就像:
- 向操作系统说:"我要16个连续的内存格子"
- 操作系统给你一个"钥匙"(buffer对象)
- 但你看不到、摸不着这些格子,只能通过"钥匙"来操作
2.2 重要特性详解
特性1:固定大小
javascript
const buffer = new ArrayBuffer(16);
// buffer的大小永远固定为16字节
// 不能增加,不能减少为什么固定? 内存管理需要确定性。如果大小可变,会导致:
· 内存碎片化
· 重新分配时需要复制全部数据
· 性能不可预测
特性2:不能直接访问
javascript
const buffer = new ArrayBuffer(16);
// 以下操作都是错误的:
console.log(buffer[0]); // undefined
buffer[0] = 10; // 无效为什么不能直接访问? 因为ArrayBuffer不知道:
- 你要访问哪个位置?
- 你要读多少字节?
- 你要用什么数据类型读?

第三章:TypedArray
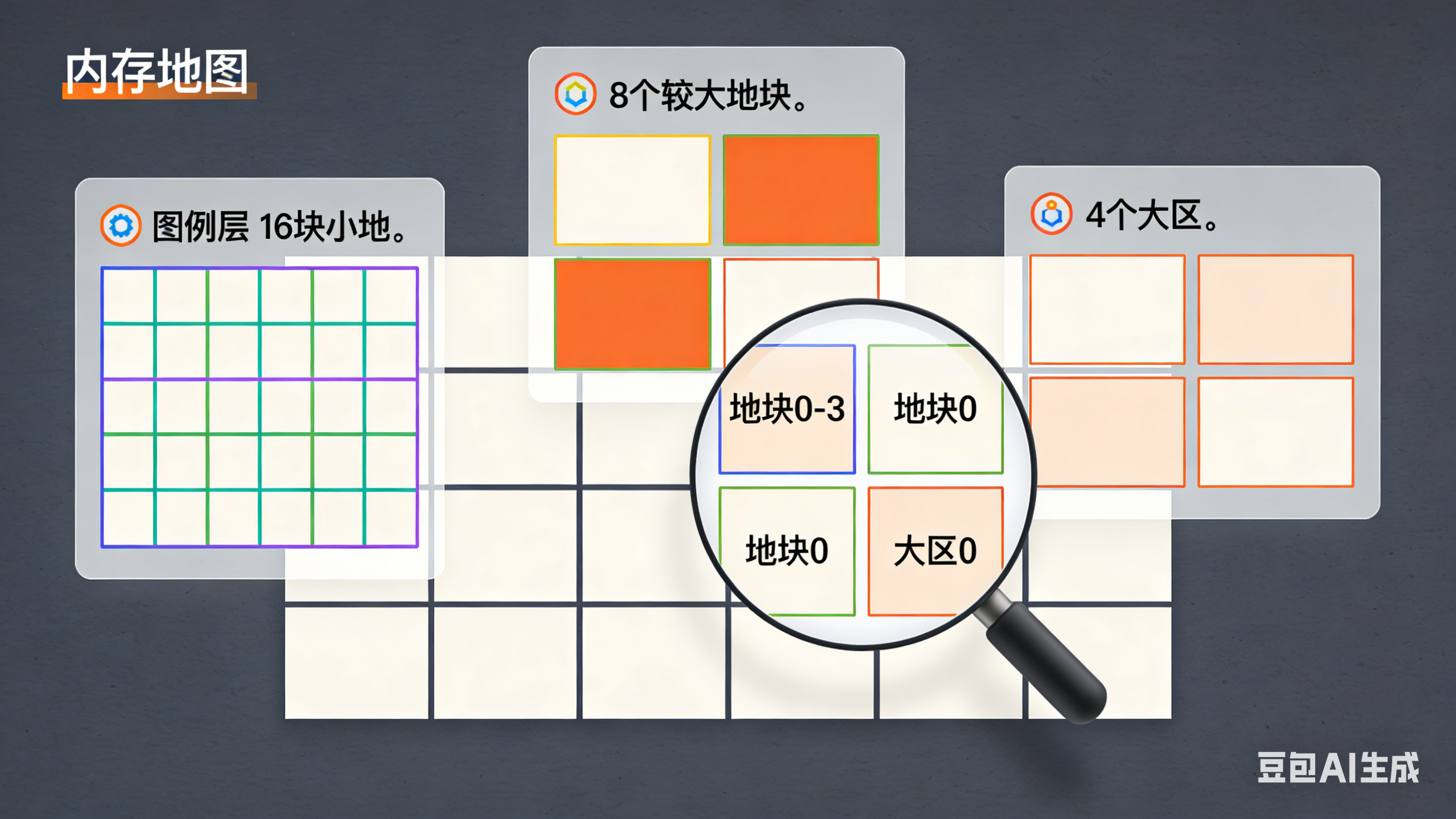
3.1 核心概念:视图(View)
TypedArray 不是数据容器,而是数据的解释器 或测量工具 。它本身不"拥有"数据,而是提供了一种规则,告诉我们如何看待 和访问 底层 ArrayBuffer 中的原始字节。
更准确的比喻:
·ArrayBuffer = 一段表面空白的标准木材(比如1米长)。
它只规定了长度(字节数),但上面没有任何刻度或标记。
· TypedArray = 一把按特定规格刻好刻度的标尺。
这把尺子可以贴在这段木材上,从而定义如何测量它。
javascriptconst buffer = new ArrayBuffer(16); // 一段16厘米长的空白木材 const int32尺 = new Int32Array(buffer); // 贴上"4厘米/格"的标尺 const int8尺 = new Uint8Array(buffer); // 贴上"1厘米/格"的标尺
关键点:
- 同一段木材,不同的尺子 :同一块内存 (
ArrayBuffer) 可以同时被多把不同的"尺子" (TypedArray) 测量。 - 尺子决定解释方式 :
Int32Array这把尺子告诉你,每4个字节算一个"单位"(元素);而Uint8Array尺子则说,每个字节就是一个独立的"单位"。 - 尺子是固定的 :一旦
new Int32Array(buffer),这把"4字节标尺"的刻度就固定了,你不能用它去读取单个字节的数据。
3.2 视图如何工作?
关键机制:映射关系
javascript
// 创建16字节的内存
const buffer = new ArrayBuffer(16);
// 创建Int32Array视图(每个元素4字节)
const int32View = new Int32Array(buffer);
// 这时建立了映射:
// buffer: [0-3字节][4-7字节][8-11字节][12-15字节]
// int32View: [元素0] [元素1] [元素2] [元素3]
// ↓ ↓ ↓ ↓
// 读取4字节 读取4字节 读取4字节 读取4字节
// 注意: TypedArray 必须对齐访问。如果你尝试 new Int32Array(buffer, 1),浏览器会抛出 RangeError,
// 因为 Int32 要求偏移量必须是 4 的倍数。 而 DataView 支持非对齐访问,可以从任意偏移量读写,这是它的核心优势之一。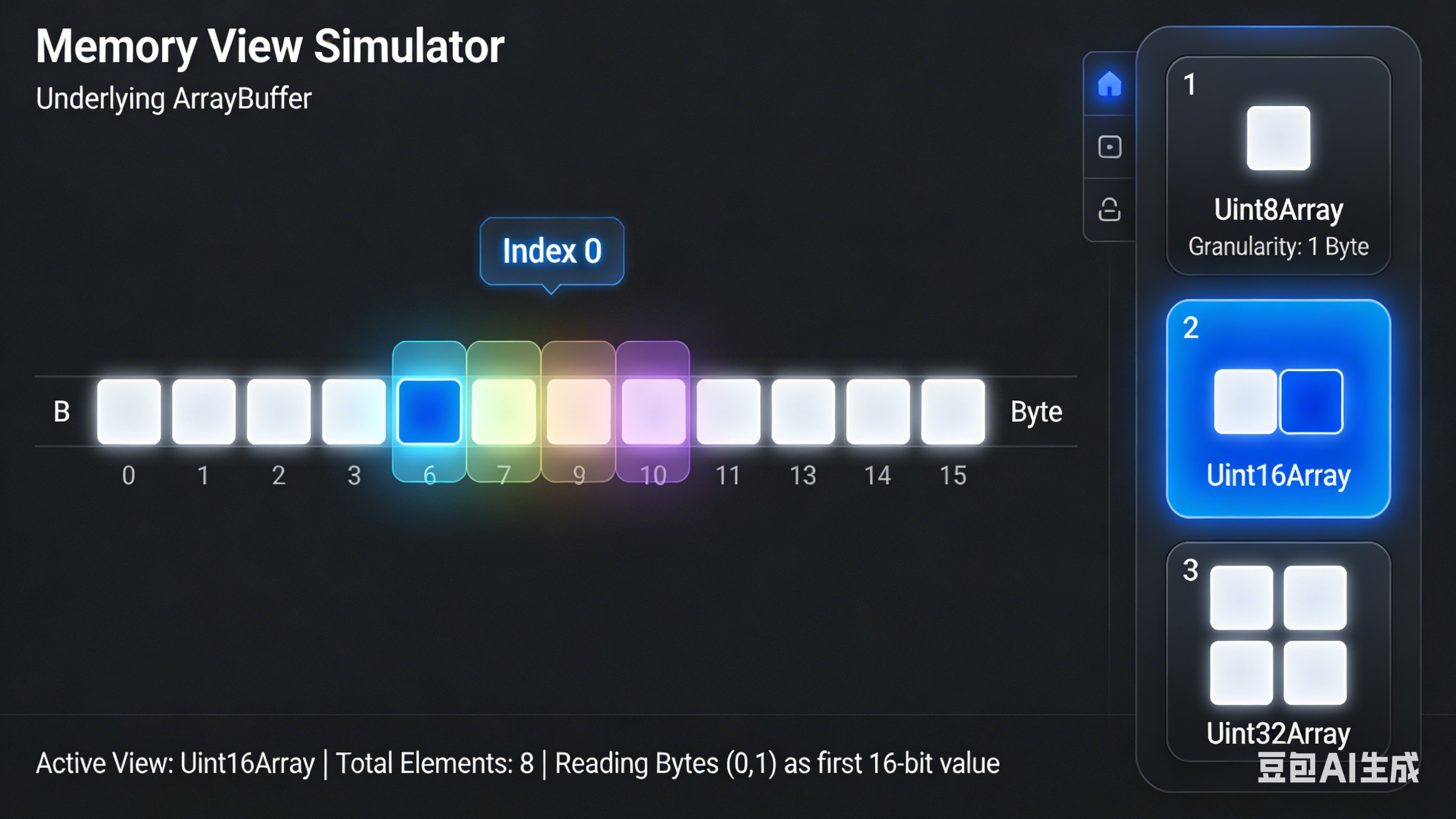
不同视图,不同解释
javascript
const buffer = new ArrayBuffer(4); // 4字节内存
const uint8View = new Uint8Array(buffer);
const uint16View = new Uint16Array(buffer);
// 同一块内存,不同解释方式
// uint8View看作4个单独字节:[A][B][C][D]
// uint16View看作2个双字节:[AB][CD]
3.3 字节序(Endianness)的深入解释
什么是字节序?
假设数字0x12345678(16进制)要存入内存:
大端序(Big Endian) - 人类阅读顺序:
地址: 00 01 02 03
数据: 12 34 56 78小端序(Little Endian) - Intel CPU使用:
地址: 00 01 02 03
数据: 78 56 34 12JavaScript中的字节序
javascript
const buffer = new ArrayBuffer(4);
const view = new DataView(buffer);
// 写入一个32位整数
view.setInt32(0, 0x12345678); // 注意:DataView 默认使用大端序(Big-Endian),忽略平台差异!
// 在不同CPU上读取,结果可能不同!
// x86 CPU(小端序):会按[78,56,34,12]存储
// 某些ARM CPU(大端序):会按[12,34,56,78]存储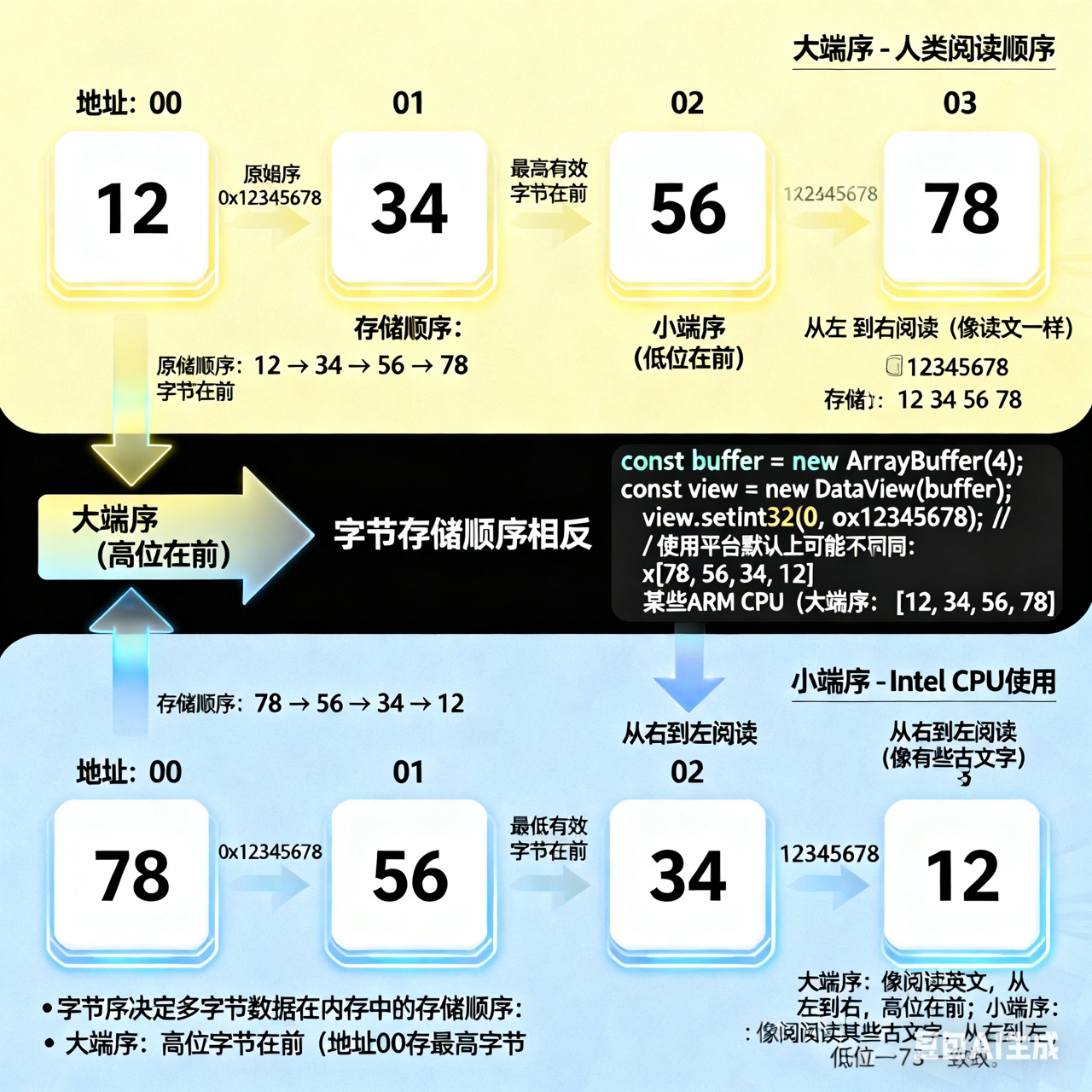
3.4 所有TypedArray类型详解
按位数分类
1字节(8位):
Int8Array - 有符号:-128 到 127
Uint8Array - 无符号:0 到 255
Uint8ClampedArray - 无符号但限制在0-255(用于颜色)
2字节(16位):
Int16Array - 有符号:-32768 到 32767
Uint16Array - 无符号:0 到 65535
4字节(32位):
Int32Array - 有符号:约-21亿到21亿
Uint32Array - 无符号:0到约42亿
Float32Array - 单精度浮点数
8字节(64位):
Float64Array - 双精度浮点数
BigInt64Array - 大整数(有符号)
BigUint64Array - 大整数(无符号)内存布局示例
javascript
// 假设我们要存储:整数100,浮点数3.14
const buffer = new ArrayBuffer(8); // 需要8字节
// 方案1:使用Uint32Array + Float32Array
const intView = new Uint32Array(buffer, 0, 1); // 前4字节
const floatView = new Float32Array(buffer, 4, 1); // 后4字节
intView[0] = 100; // 占用字节0-3
floatView[0] = 3.14; // 占用字节4-7
// 实际内存布局(小端序):
// [100,0,0,0, 195,245,72,64]
// ↑整数100 ↑浮点数3.14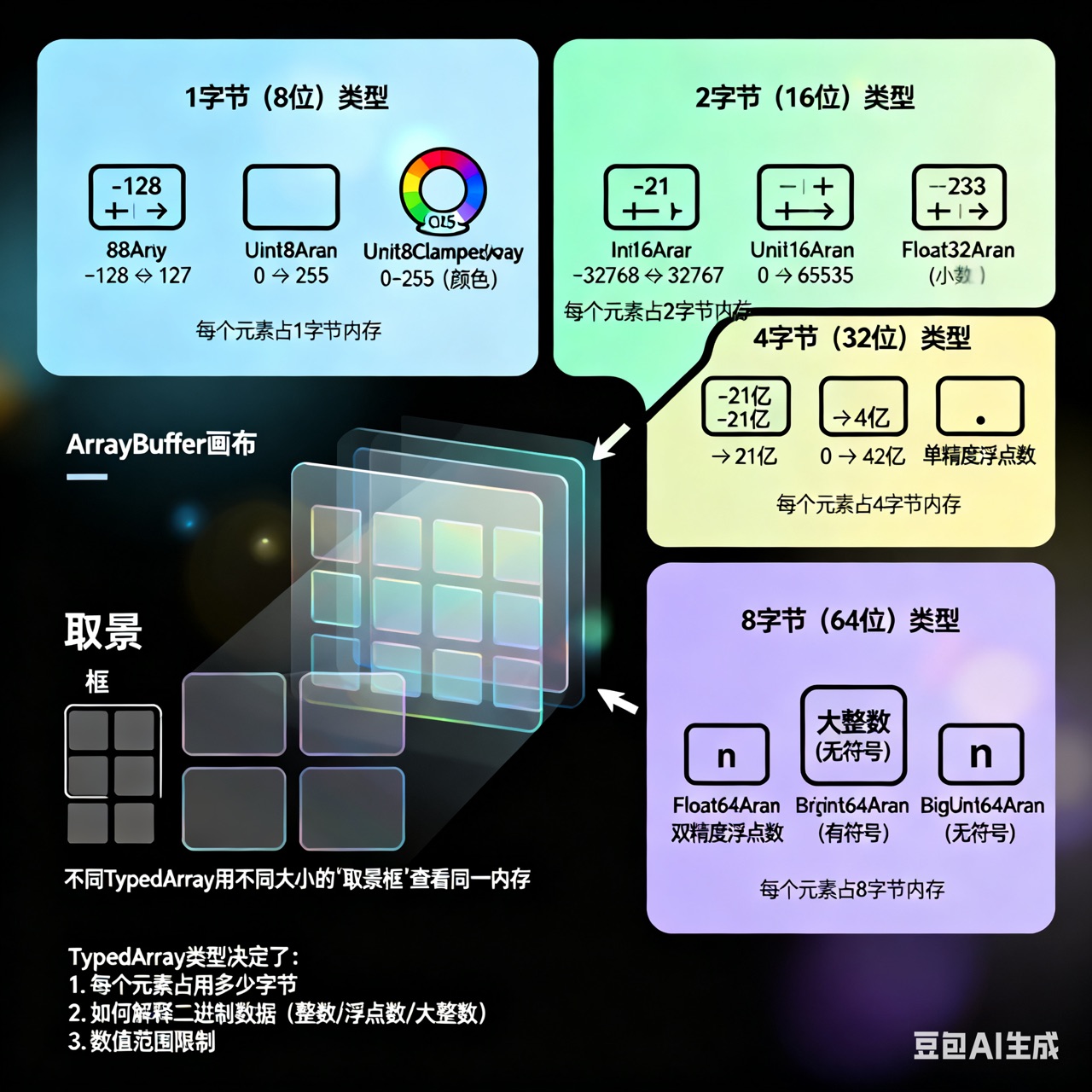
第四章:DataView
4.1 为什么需要DataView?
TypedArray的局限性:
- 创建时必须确定数据类型
- 所有元素必须是同一类型
- 不能混合访问
DataView的优势:
· 可以随意切换"镜头"
· 可以查看内存的任何位置
· 可以控制字节序
4.2 DataView的工作原理
不是"读任何一位",而是"以不同的数据类型读任何位置的一段字节"。
核心区别:数据类型的"解释权"
TypedArray(固定解释权)
javascript
const buffer = new ArrayBuffer(8);
const int32View = new Int32Array(buffer); // 创建时就固定:只能读32位整数
// 只能这样读:
// int32View[0] → 读取字节0-3,解释为1个32位整数
// int32View[1] → 读取字节4-7,解释为1个32位整数DataView(动态解释权)
javascript
const buffer = new ArrayBuffer(8);
const view = new DataView(buffer); // 没有固定类型!
// 现在可以:
// view.getInt32(0) → 读取字节0-3,解释为1个32位整数
// view.getInt16(2) → 读取字节2-3,解释为1个16位整数
// view.getUint8(5) → 读取字节5,解释为1个8位无符号整数
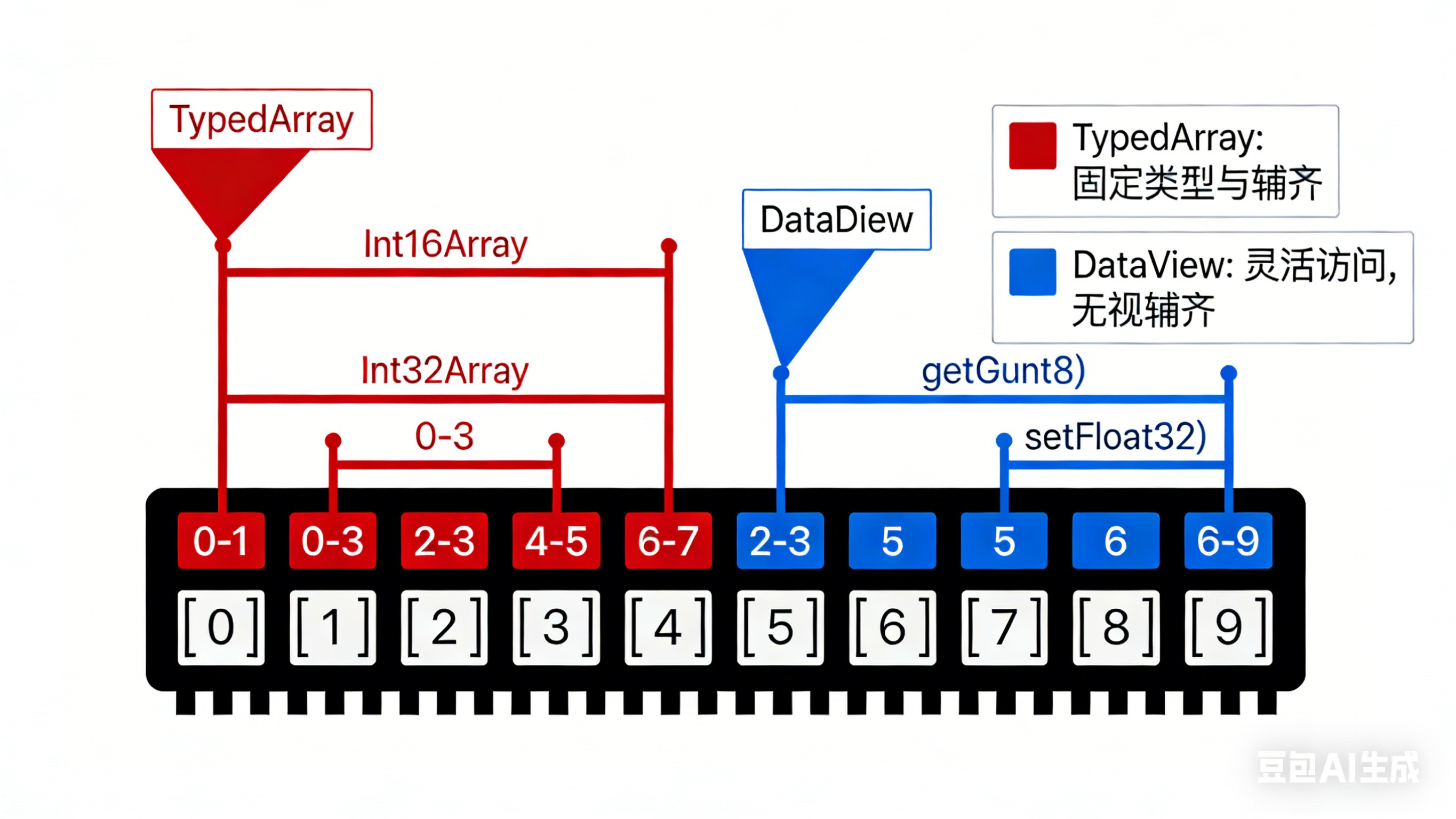
// view.getFloat32(4) → 读取字节4-7,解释为1个32位浮点数最简对比图
TypedArray: 一套固定尺寸的盒子
内存:[0][1][2][3][4][5][6][7]
Int32Array盒子:[0-3] [4-7] ← 只能装4字节数据
Int16Array盒子:[0-1][2-3][4-5][6-7] ← 只能装2字节数据DataView: 一把可调卡尺
同一内存:[0][1][2][3][4][5][6][7]
同一把卡尺可以:
- 量[2-3](设为16位模式)
- 量[5](设为8位模式)
- 量[0-3](设为32位模式)
- 量[4-7](设为浮点数模式)关键点
- 单位是字节,不是位:最小读1个字节(8位),不能读单个位
- 灵活的位置:可以从任意字节偏移量开始读,不要求对齐
- 灵活的类型:同一个DataView实例,可以一会儿读整数,一会儿读浮点数
- 字节序控制:可以明确指定是大端还是小端
实际例子
假设你收到一个网络数据包,格式是:
- 前2字节:ID(16位整数)
- 第3字节:状态(8位整数)
- 后4字节:数值(32位浮点数)
用TypedArray做不到 (需要创建多个视图),但用DataView一个就够了:
javascript
const view = new DataView(networkPacket);
const id = view.getUint16(0); // 读字节0-1
const status = view.getUint8(2); // 读字节2
const value = view.getFloat32(3); // 读字节3-6所以不是"读任何一位",而是"用任何数据类型读任何一段字节 "。
4.3 DataView的字节序控制
javascript
const buffer = new ArrayBuffer(4);
const view = new DataView(buffer);
// 写入同一个数字,用不同字节序
view.setInt32(0, 0x12345678, true); // 小端序
// 内存:[0x78, 0x56, 0x34, 0x12]
view.setInt32(0, 0x12345678, false); // 大端序
// 内存:[0x12, 0x34, 0x56, 0x78]
// 读取时也必须指定相同的字节序
console.log(view.getInt32(0, true)); // 0x12345678(小端序读)
console.log(view.getInt32(0, false)); // 0x78563412(大端序读,错误!)第五章:三者的关系与选择
5.1 内存模型完整视图
┌─────────────────────────────────────────┐
│ JavaScript Heap(堆内存) │
├─────────────────────────────────────────┤
│ ArrayBuffer对象(引用) │
│ ┌─────────────────────────────────────┐│
│ │ buffer#1 → 内存地址: 0x1000 ││
│ │ buffer#2 → 内存地址: 0x2000 ││
│ └─────────────────────────────────────┘│
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ Native Memory(原生内存) │
├─────────────────────────────────────────┤
│ 地址: 0x1000 地址: 0x2000 │
│ ┌──────────┐ ┌──────────┐ │
│ │ 数据.....│ │ 数据.....│ │
│ └──────────┘ └──────────┘ │
│ ▲ ▲ │
│ │ │ │
│ TypedArray DataView │
│ 视图#1 视图#2 │
└─────────────────────────────────────────┘5.2 选择指南:什么时候用什么?
场景1:处理图像像素 → Uint8ClampedArray
javascript
// Canvas的ImageData使用这种类型
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const imageData = ctx.getImageData(0, 0, 100, 100);
// imageData.data就是Uint8ClampedArray
// 每个像素:[R, G, B, A] 每个值0-255场景2:WebGL顶点数据 → Float32Array
javascript
// 顶点位置需要浮点数精度
const vertices = new Float32Array([
-0.5, -0.5, 0.0, // x, y, z
0.5, -0.5, 0.0,
0.0, 0.5, 0.0
]);场景3:解析网络协议 → DataView
javascript
// 协议包头可能包含不同类型的数据
function parsePacket(buffer) {
const view = new DataView(buffer);
// 协议版本:1字节
const version = view.getUint8(0);
// 数据长度:2字节(大端序,网络字节序)
const length = view.getUint16(1, false);
// 时间戳:4字节(小端序)
const timestamp = view.getUint32(3, true);
// 使用最合适的工具
return { version, length, timestamp };
}场景4:与C/C++代码交互 → 选择合适的TypedArray
javascript
// WebAssembly内存访问
const wasmMemory = new WebAssembly.Memory({ initial: 1 });
const buffer = wasmMemory.buffer; // ArrayBuffer
// 根据C结构体选择对应视图
// struct Data { int id; float value; };
const idView = new Int32Array(buffer, offset, 1);
const valueView = new Float32Array(buffer, offset + 4, 1);5.3 性能考虑
内存访问模式
javascript
// 好的模式:连续访问(CPU缓存友好)
for (let i = 0; i < array.length; i++) {
sum += array[i]; // 连续内存访问
}
// 坏的模式:随机访问(缓存不命中)
for (let i = 0; i < 1000; i++) {
sum += array[randomIndex()]; // 跳跃式访问
}数据类型对齐
javascript
// 非对齐访问(某些CPU上慢)
const buffer = new ArrayBuffer(10);
const view = new DataView(buffer);
const value = view.getInt32(1); // 从奇数地址读32位数据
// 对齐访问(快)
const value = view.getInt32(0); // 从4的倍数地址读
const value = view.getInt32(4); // 从4的倍数地址读第六章:常见误区与陷阱
6.1 误区1:TypedArray是Array的子类
javascript
const arr = new Uint8Array(10);
console.log(arr instanceof Array); // false!
console.log(arr instanceof Object); // true
// TypedArray有自己的原型链
// Array → Object
// TypedArray → Object6.2 误区2:修改视图会创建新ArrayBuffer
javascript
const buffer1 = new ArrayBuffer(16);
const view1 = new Uint8Array(buffer1);
const view2 = new Uint8Array(buffer1);
view1[0] = 100;
console.log(view2[0]); // 100!共享同一内存
// 想要独立副本必须显式复制
const buffer2 = new ArrayBuffer(16);
new Uint8Array(buffer2).set(view1); // 复制数据6.3 误区3:所有的TypedArray都有相同的API
javascript
const intArray = new Int32Array(10);
const floatArray = new Float32Array(10);
// 大部分方法相同
intArray.map(x => x * 2); // ✅
floatArray.map(x => x * 2); // ✅
// 但有些类型特定方法
const bigIntArray = new BigInt64Array(10);
bigIntArray[0] = 100n; // 必须用BigInt字面量总结:核心要点回顾
- ArrayBuffer是原始内存,不能直接操作
- TypedArray是"类型化视图",创建时固定数据类型
- DataView是"灵活视图",访问时指定数据类型
- 字节序决定了多字节数据的存储顺序
- 内存共享:多个视图可以操作同一ArrayBuffer
- 性能关键:连续访问、对齐访问、选择合适类型
记住这个简单的流程图:
你需要操作二进制数据吗?
↓
是否需要极高性能且数据类型统一? → TypedArray(注意:需内存对齐)
是否需要解析复杂的二进制协议(如前 2 字节是整数,后 4 字节是浮点数)? → DataView
是否需要跨平台强制统一字节序(如处理网络大端数据)? → DataView
↓ 否
需要灵活访问不同数据类型? → 用DataView
↓
两者都需要底层内存? → 创建ArrayBuffer如果你觉得文章难懂,看这张表就够了:
| 维度 | ArrayBuffer | TypedArray | DataView |
|---|---|---|---|
| 角色 | 原始内存 | 固定视图 | 灵活视图 |
| 能否直接操作 | ❌ 不能 | ✅ 能(像操作数组一样) | ✅ 能(通过 get/set 方法) |
| 数据类型 | 无 | 单一(全是同一种类型) | 混合(可以在同一段内存读不同类型) |
| 对齐要求 | 无 | 严格(必须是字节长度的倍数) | 无(随意偏移位置) |
| 字节序控制 | 无 | 自动(跟随你的电脑系统) | 手动(你可以指定大端或小端) |
理解这些概念后,你就能根据具体需求选择合适的工具,高效地处理JavaScript中的二进制数据了。