DeepSeek-OCR
原理
DeepSeek-OCR模型,整个模型大小在3B。
DeepSeek-OCR的提出,是为了探索,是否可以通过视觉模态进行文本信息的高效压缩,
也就是把文档内容,用图像Token表示,其Token数量会远小于原始文本Tokens数,
1w字,可能需要5000个Token,但用图像来表示,可能只需要512 个 Token。
DeepSeek,是在想用图像视觉压缩文本。
传统 OCR:图像 → 文字识别(OCR)→ 文本理解(NLP)
DeepSeek-OCR:图像 → 视觉编码(视觉 token)→ 直接语义理解(多模态大模型)
优势:避免了 OCR 识别错误的误差累积,尤其在模糊、低分辨率、复杂排版文档中,能更直接地捕捉语义结构。
通过视觉压缩大幅减少输入 token 数量,显著降低大模型推理成本
适用于高分辨率文档(如扫描件、PDF)的端到端处理,无需分块预处理
核心价值:DeepSeek-OCR 不是"更好的 OCR",而是"替代 OCR"的新一代文档理解范式。论文核心思想
上下文光学压缩 (Contexts Optical Compression)
当前LLM处理长文本时,其核心瓶颈在于Transformer架构中自注意力机制的计算复杂度会随着序列长度N呈 O(N²) 的平方级增长。这使得处理成千上万甚至更长的文本序列变得非常昂贵和缓慢。
作者反其道而行之,提出了一个新颖的思路:我们能否不直接处理一维的文本Token序列,而是先将文本渲染成一张二维的图像,然后让VLM来"读取"这张图像?
这个想法的直觉来源是,一张包含丰富文本信息的文档图像,可以用相对较少的视觉Token(Vision Tokens)来表示,而这些文本如果转换成数字文本Token(Text Tokens),数量会庞大得多。例如,一张A4纸的文档图像可能只需要几百个视觉Token就能捕捉其全貌,而其上的文字可能对应着数千个文本Token。这个从"大量文本Token"到"少量视觉Token"的转换过程,就是论文所谓的"光学压缩"。而从"少量视觉Token"还原出文字的过程,则可以看作是"解压缩",这本质上就是一个OCR(光学字符识别)任务。
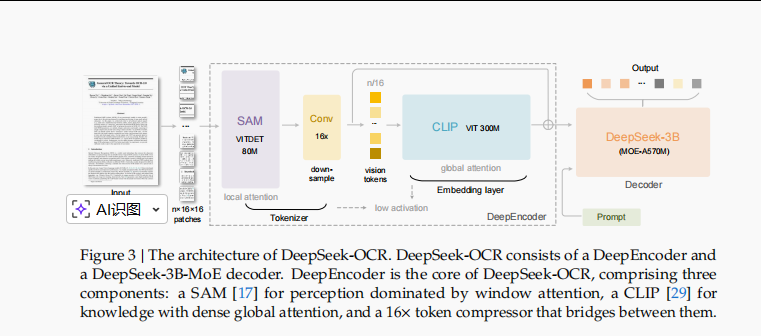
整个工作流程可以概括为:图像 -> DeepEncoder -> 视觉Token -> DeepSeek-3B-MoE 解码器 -> 输出文本
模型结构
DeepSeek-OCR模型也是三件套,图像编码器、映射层和文本解码器组成,其中图像编码器是特色,为DeepEncoder,参数为380M,文本解码器是一个deepseekv2-3b的模型,参数为3B,2个共享专家,64个激活专家,每次激活6个专家,激活参数为570M。
提出DeepEncoder,为了可以能够处理高分辨率图像、在高分辨率下激活值低、输出视觉Token少、支持多分辨率输入。结构如下,参数量为380M,主要由一个80M的SAM-base模型和一个300M的CLIP-large模型串联构成。
其中,SAM-base模型以窗口注意力感知局部特征,CLIP-large模型以密集全局注意力提取全局语义信息。
模型之间,采用一个两层卷积模块对视觉token进行16倍下采样,每个卷积层的kernel size为3,stride为2,padding为1,通道数从256增加到1024。
举例,输入图像大小为1024×1024,DeepEncoder首先划分为1024/16 × 1024/16 = 4096个patch token,在对4096个token进行压缩,数量变为4096/16 = 256。
训练过程
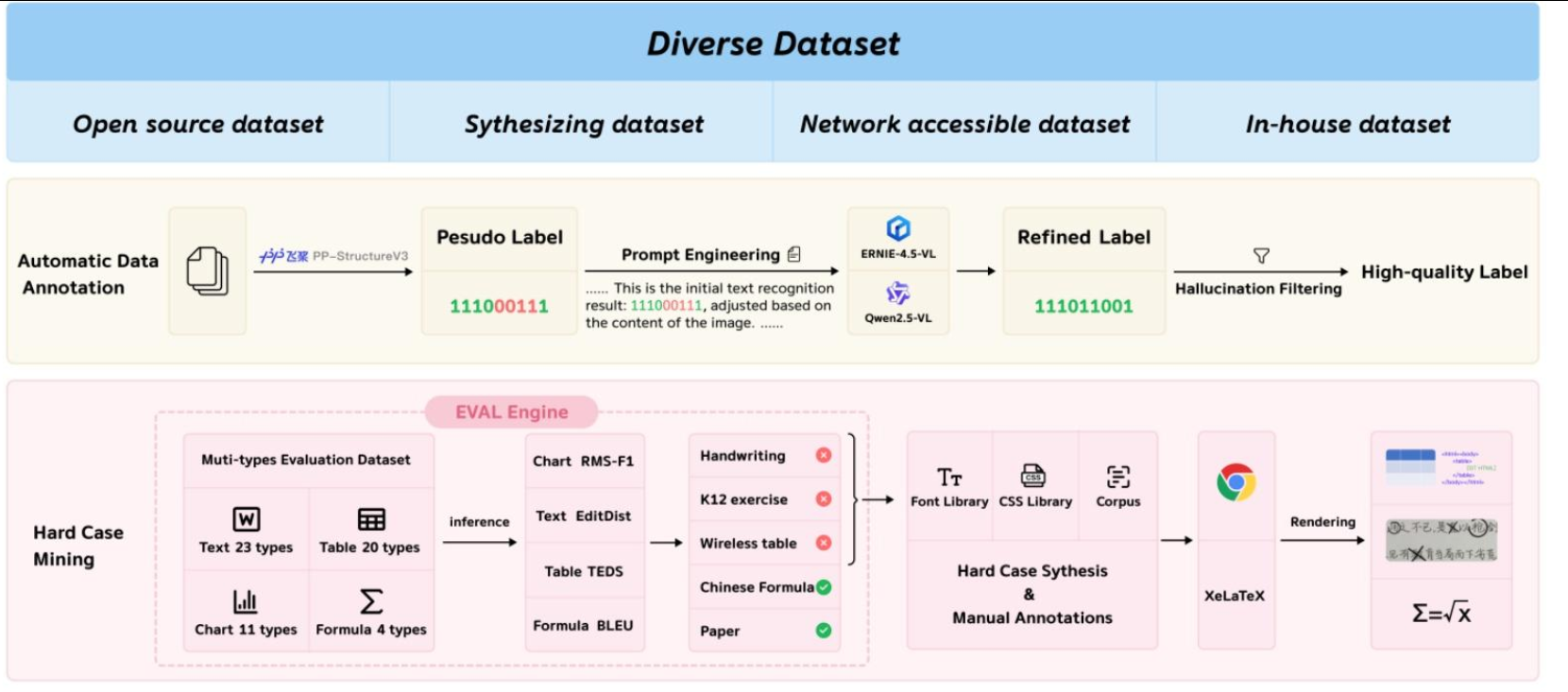
整体训练数据由4部分组成,
OCR1.0数据(43M张图片-文本对),由传统OCR任务组成,如图像OCR和文档OCR;
OCR2.0数据(16M张图片-文本对),包含复杂的图像解析任务,如图表、化学公式、平面几何等;
通用视觉数据(占比20%),用于注入通用图像理解能力;
纯文本数据(占比10%),用于确保模型的语言能力。
模型训练采用两阶段训练,先训练DeepEncoder部分,再全部参数联合训练。
训练DeepEncoder阶段,采用OCR1.0和OCR2.0数据,以及从LAION数据集中采样的100M通用数据,训练 2 个 epoch,BS为1280,优化器为AdamW,学习率调度器为cosine annealing ,初始学习率为 5e-5,最大长度为 4096。
全部参数训练阶段,采用20个A100-40G*8的节点进行PP训练,BS为 640,优化器为 AdamW,初始学习率为3e-5。
小结
《DeepSeek-OCR: Contexts Optical Compression》是一篇极富创意和启发性的论文。它没有在现有技术路线上"卷"参数或优化算法,而是提出了一个颠覆性的"光学压缩"框架来应对LLM的长上下文挑战。通过扎实的模型设计(DeepEncoder)和充分的实验验证,它证明了这一方向的巨大潜力,不仅在文档智能领域取得了SOTA的效率和性能,更为未来VLM和LLM的发展开辟了全新的可能性。
PaddleOCR-VL
PaddleOCR‑VL 是 PaddleOCR 3.x 系列中的一款 视觉‑语言多模态文档解析模型,专门面向复杂文档场景设计。相比传统 OCR 仅能识别文字,PaddleOCR‑VL 通过融合视觉编码器与语言模型,实现了从"文字识别"到"图文理解"的跨模态能力。它不仅可以精准识别文字,还能理解文字在文档中的结构和语义,例如表格、公式、图表以及多栏排版内容。
该模型参数规模适中(约 0.9 亿),兼顾高精度和资源效率,因此既适合本地部署,也可在私有云或远程环境中使用。更重要的是,PaddleOCR‑VL 支持多语言文本识别(超过 100 种语言),在处理多语种混排文档时表现出色。凭借其跨模态能力,它不仅可以完成大批量文档解析,还能为知识抽取、智能问答等后续任务提供结构化输入,成为现代智能文档处理系统的核心技术。
简而言之,PaddleOCR‑VL 是一款专业的多模态文档理解模型,突破了传统 OCR 的局限,实现了文字识别、版式理解与语义分析的有机结合。其核心技术突破在于将动态分辨率视觉编码与轻量化语言解码深度融合。
技术要点
PaddleOCR-VL采用统一的Encoder-Decoder架构,整体流程如下:
- 输入图像经过动态分块处理,送入视觉编码器;
- 编码后的特征序列与提示词(prompt)拼接后输入语言解码器;
- 解码器自回归生成结构化输出,包括文本内容、元素类型、位置信息等;
- 后处理模块将其组织为JSON或HTML格式的结果。
这种端到端的设计避免了传统OCR中多个子模型串联带来的误差累积问题,显著提升了整体鲁棒性。
动态分辨率视觉编码器(NaViT风格)
PaddleOCR-VL的核心视觉组件借鉴了NaViT(Native Resolution Vision Transformer)的思想,具备以下关键特性:
• 原生分辨率输入:不强制缩放图像至固定尺寸,保留原始长宽比,减少形变失真。
• 动态Patch划分:根据图像大小自动调整patch size和数量,提升小图效率与大图细节捕捉能力。
• 局部注意力机制:引入滑动窗口注意力,降低计算复杂度,使高分辨率图像处理更高效。
该编码器能有效提取文档中的多层次视觉特征,尤其擅长区分紧密排列的文字区域与非文本元素(如边框线、底纹、图标)。
轻量级语言解码器(ERNIE-4.5-0.3B集成)
PaddleOCR-VL的语言解码部分基于ERNIE-4.5-0.3B进行定制优化,主要改进包括:
指令微调(Instruction Tuning):使用大量标注数据对齐"图像→描述"任务,增强语义生成能力。
结构化输出约束:通过特殊token设计(如, , )引导模型生成规范格式。
上下文感知解码:结合前序预测结果动态调整后续生成策略,提升整体一致性。
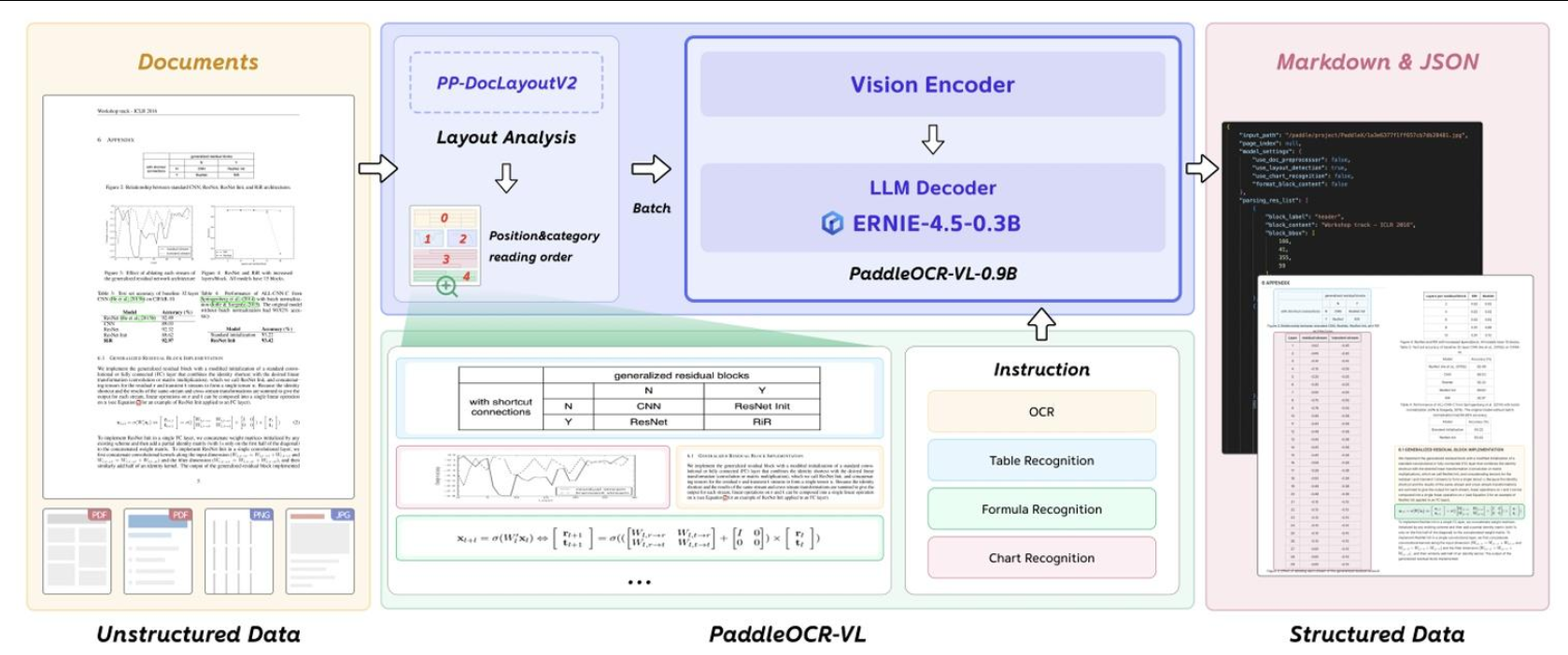
核心技术
PaddleOCR-VL的核心创新在于其独特的混合式架构,它将轻量而强大的视觉语言识别模型PaddleOCR-VL-0.9B与高精度版面分析模型PP-DocLayoutV2深度融合。
这种两阶段处理流程巧妙地解决了传统端到端VLM在处理复杂文档时面临的效率和稳定性问题,实现了性能与可扩展性的完美兼顾。
版面分析------PP-DocLayoutV2
在文档解析的第一阶段,PP-DocLayoutV2负责执行精细的版面分析,包括对文档中的语义区域进行定位,并预测其正确的阅读顺序。这一阶段的关键在于其解耦设计,避免了大型VLM在处理长序列时可能出现的延迟、高内存消耗和"幻觉"问题,尤其在多栏或图文混排布局中表现更稳定。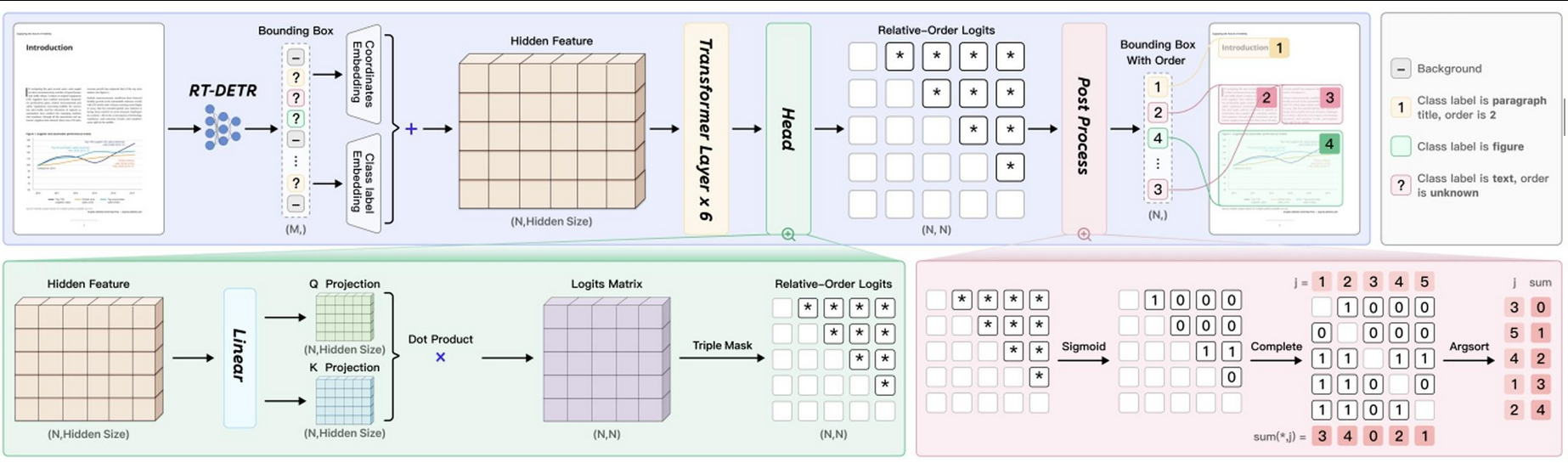
PP-DocLayoutV2主要由两部分组成:
基于RT-DETR的目标检测模型:该模型负责精确地检测并分类文档中的各种元素,如文本块、表格、公式、图表、图片、页眉页脚等,并输出它们的边界框位置。
轻量级指针网络(Pointer Network):在检测到所有元素后,一个包含六层Transformer的指针网络会根据元素的几何位置和语义信息,预测出符合人类阅读习惯的阅读顺序。该网络还融入了几何偏置机制(Geometric Bias Mechanism),以显式建模元素间的成对几何关系,并通过确定性累积解码算法(Win-Accumulation Decoding Algorithm)恢复拓扑一致的阅读顺序。
通过这种分而治之的策略,PaddleOCR-VL在版面分析方面展现出高度的准确性和稳定性,为后续的精准内容识别奠定了坚实基础。
元素级识别------PaddleOCR-VL-0.9B
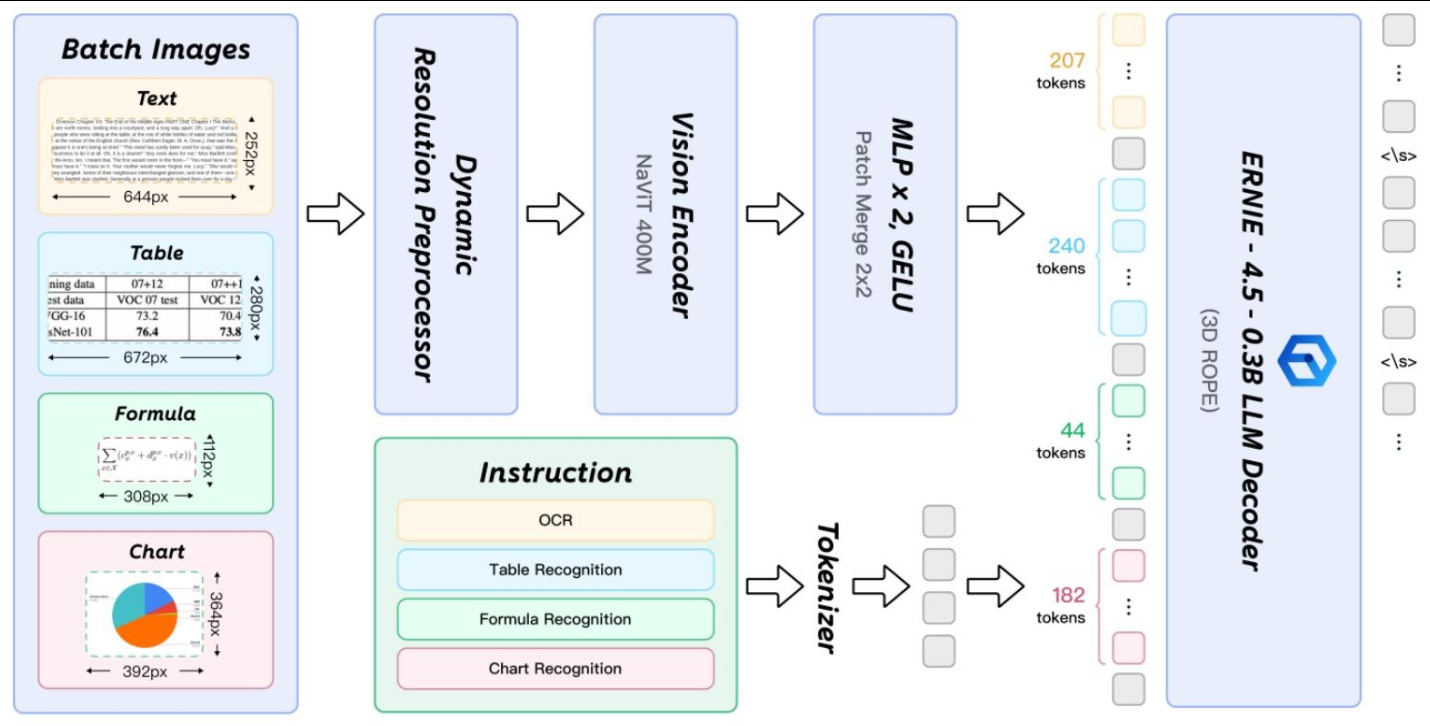
在第二阶段,PaddleOCR-VL-0.9B基于PP-DocLayoutV2生成的版面结构预测结果,进一步完成对多种内容类型的细粒度识别,涵盖文本、表格、数学公式以及图表等。该模型仅有0.9B的参数量,却展现出卓越的性能,其核心在于以下几点:
NaViT风格的动态高分辨率视觉编码器:传统的VLM在处理高分辨率图像时常面临计算量大、信息失真等问题。PaddleOCR-VL-0.9B采用了NaViT(Native Vision Transformer)风格的视觉编码器,支持原生动态分辨率输入。这意味着模型可以处理任意分辨率的图像而无需进行缩放或切片,有效避免了信息损失和失真,极大地增强了对密集文本和低质量图像的识别能力。
ERNIE-4.5-0.3B语言模型:作为语言模型的核心,PaddleOCR-VL-0.9B集成了轻量级的ERNIE-4.5-0.3B。该模型在保持较小参数量的同时,提供了强大的语言理解能力,确保了高效的推理速度。
双层MLP投影器:负责高效地将视觉编码器提取的特征映射到语言模型的嵌入空间,实现视觉与语言信息的无缝融合。
这种视觉与语言模型的紧密结合,使得PaddleOCR-VL-0.9B不仅能"看懂"文字,更能"理解"表格、公式、图表等非文本元素的内在结构和语义,实现了从视觉信息到结构化数据的智能转换。
OlmOCR-2
olm大家反馈不稳定,不如mineru
只提取文字,不是像markdown一样输出保留格式和图片的markdown
原理
olmOCR 2 是一套面向文档 OCR 的端到端解决方案,其核心方法围绕RLVR,通过 "合成数据规模化 - 单元测试定奖励 - RL 训练提性能" 的闭环,解决传统 OCR 系统在复杂场景(数学公式、表格、多列布局)中的痛点。
传统OCR系统的性能评估依赖编辑距离 ,计算模型输出与Ground Truth的字符级差异(插入、删除、替换次数)。

为解决上述问题,设计了下面6类可验证的二进制单元测试(结果仅"通过(PASS)"或"失败(FAIL)"),覆盖文档OCR的需求:
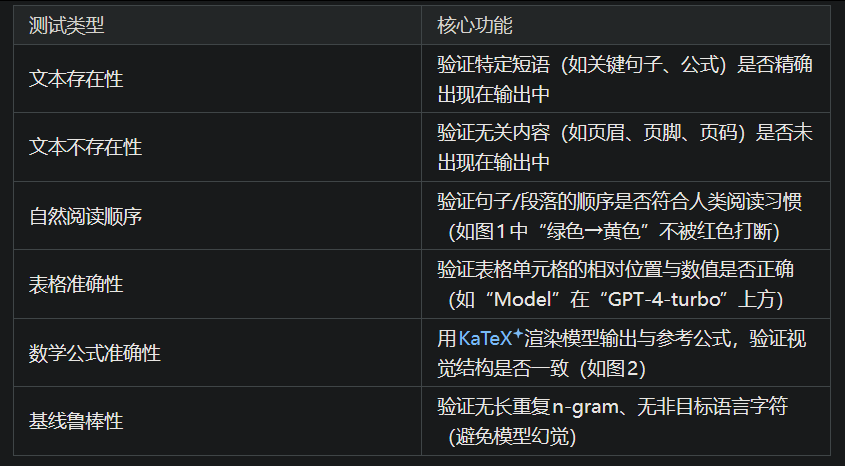
这些测试的优势在于:
公平处理浮动元素:对图注、表格等位置灵活的元素,只要核心逻辑正确(如表格单元格关系、阅读顺序),均判定为通过,避免编辑距离的"过度惩罚";
精准反映实际正确性:聚焦"用户是否能用"(如公式能否正确渲染、表格能否正确读取),而非"字符是否完全匹配"。
开发了全自动合成数据生成 pipeline,实现"文档→HTML→单元测试"的端到端规模化,核心流程分三步:
步骤1:挑选"难处理场景"PDF数据源
为确保合成数据的挑战性(覆盖真实OCR痛点,避免"模板化数据",确保数据多样性,与真实世界OCR需求对齐。),文章选择高难度文档样本: 数据来源arXiv数学论文(含复杂公式)、旧扫描件(低分辨率)、多列布局文档、含复杂表格的文档。
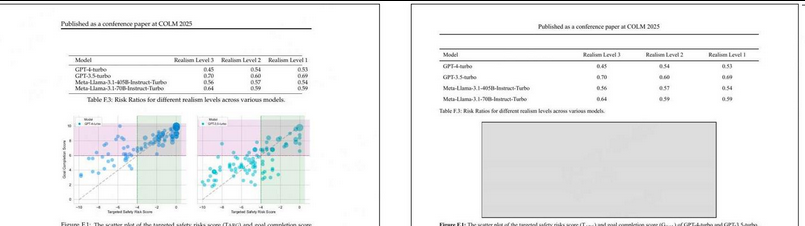
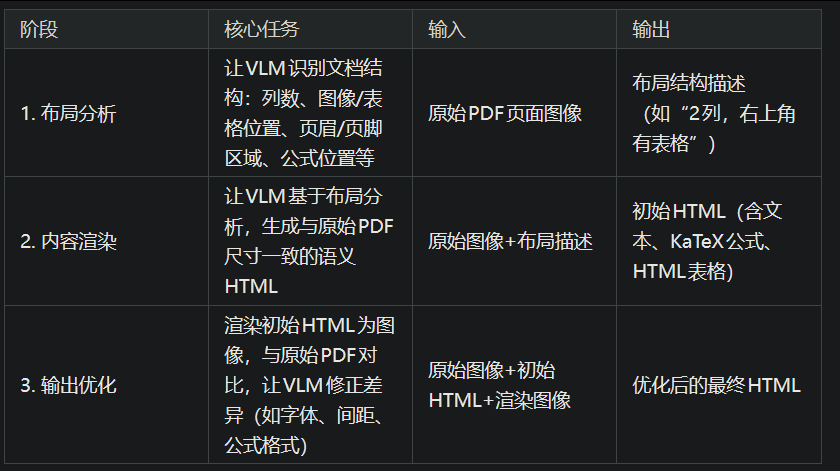
olmOCR 2 合成数据流水线的 HTML 页面生成。从真实文档中采样一个页面(左图),并提示通用<br>视觉语言模型(VLM)生成一个高度相似的 HTML 页面(右图)。渲染后的 HTML 页面图像与原始 HTML 配对,作<br>为专用于 OCR 的 VLM 的监督信号。
步骤2:PDF→HTML的三阶段转换(生成"带Ground Truth的结构化文档")
HTML是生成单元测试的关键:其语义标签(如
、 、、KaTeX公式)可直接用于自动提取测试用例。转换过程依赖通用VLM(Claude-sonnet-4-20250514) ,分三阶段迭代优化:
步骤3:基于HTML自动生成单元测试
利用HTML的结构化信息,程序化提取单元测试用例,无需人工干预:
文本不存在性测试:从 / 标签提取页眉/页脚,生成"这些内容不应出现"的测试;
数学公式测试:从KaTeX标签提取公式,生成"渲染后与参考一致"的测试;
表格测试:从 标签随机采样单元格,生成"单元格相对位置正确"的测试;
阅读顺序测试:基于HTML中段落的先后顺序,生成"段落顺序符合HTML结构"的测试。
最终生成的合成数据集 olmOCR2-synthmix-1025 包含:2186个PDF页面 → 30381个单元测试用例,为RL训练提供充足数据。
训练流程:
SFT→RLVR→模型融合,端到端优化
olmOCR 2的训练分为监督微调(SFT) 和强化学习(RLVR) 两阶段,结合模型融合(Souping)进一步提升性能:
阶段1:sft
让模型掌握基础的文档解析能力(文本提取、公式识别、表格结构感知),为后续RL优化打基础。选择Qwen2.5-VL-7B-Instruct,使用改进后的监督数据集 olmOCR-mix-1025(267962页,来自10万+PDF),相比旧版(olmOCR-mix-0225)的改进:
用GPT-4.1替代GPT-4o处理数据,减少幻觉;
统一公式格式(块级公式用[,行内公式用();
表格用HTML格式存储(而非纯文本);
为图像添加基础alt文本;
阶段2:强化学习(RLVR)
核心是用合成数据的单元测试作为奖励信号,通过GRPO算法优化模型,解决SFT阶段未覆盖的复杂场景(如多列、公式、表格)。
训练数据:olmOCR2-synthmix-1025的合成文档(带单元测试);
采样策略:每个文档生成28个不同的模型输出(completions),确保覆盖足够多的候选结果;
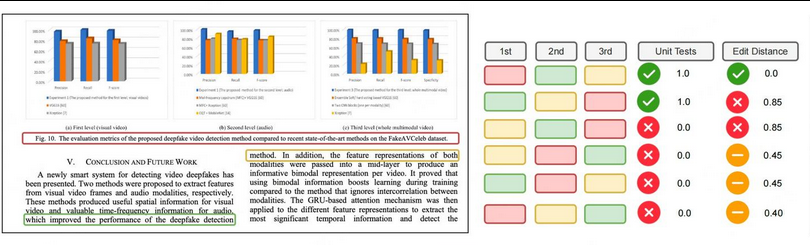
奖励函数设计
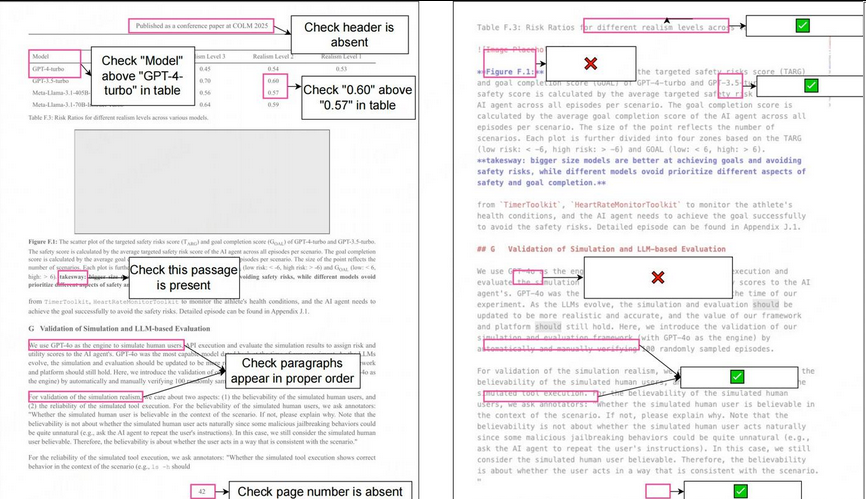
olmOCR 2 的 RLVR 训练的单元测试奖励。给定一个生成的 HTML 页面及其单元测试(左侧),可以<br>根据这些单元测试轻松地对生成的 Markdown 页面(右侧)进行评分。每个测试贡献一个二元奖励,这些奖励在页面级<br>别汇总为通过率。例如,6 个测试中有 4 个通过,则页面级别的奖励为 0.67。
奖励总分为三部分,取值均为0~1,确保模型同时优化"内容正确性"和"输出格式合规性":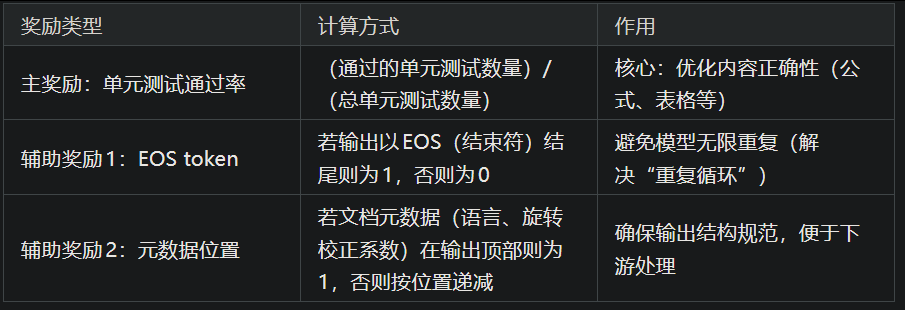
阶段3:模型融合(Souping)
为避免单一模型的随机性,文章采用模型权重平均(Souping) 策略:训练6个不同随机种子的RL模型(3个用token级重要性采样,3个用序列级重要性采样);对6个模型的权重进行平均,得到最终的olmOCR-2-7B-1025模型;
HunyuanOCR
1)轻量化架构:基于混元原生多模态架构与训练策略,打造仅1B参数的OCR专项模型,大幅降低部署成本。
2)全场景功能:单一模型覆盖文字检测和识别、复杂文档解析、卡证票据字段抽取、字幕提取等OCR经典任务,更支持端到端拍照翻译与文档问答。
3)极致易用:深度贯彻大模型"端到端"理念,单一指令、单次推理直达SOTA结果,较业界级联方案更高效便捷。
4)多语种支持:支持超过100种语言,在单语种和混合语言场景下均表现出色。
原理
纯粹的端到端架构
HunyuanOCR的架构设计得相当漂亮,可以用"简约而不简单"来形容。它由三个核心部分组成:原生分辨率视觉编码器(Hunyuan-ViT)、自适应MLP连接器和一个轻量级语言模型(Hunyuan-0.5B)。
原生分辨率视觉编码器:这个编码器很聪明,它能处理任意分辨率的输入图像,而且不改变原始长宽比。对于那些又长又窄的文档图片,这种设计能避免图像被强行拉伸或压缩,从而保留了关键的文字细节。
自适应MLP连接器:它像一个高效的"翻译官",负责将视觉编码器提取的视觉特征转换成语言模型能理解的格式。它能智能地压缩信息,丢掉冗余,同时保留文本密集区域的关键特征。
轻量级语言模型:基于Hunyuan-0.5B模型,它通过一种名为XD-RoPE的技术,原生建立了文本、高度、宽度和时间四个维度的对齐机制,让模型能更好地理解文本在图像中的空间位置。
这种纯粹的端到端(End-to-End)设计,最大的好处是摆脱了对布局分析等预处理模块的依赖。输入一张图片,直接输出最终结果,从根本上解决了传统流水线方法中常见的错误累积问题,也大大简化了部署流程。
精心构建的"数据食谱"
团队构建了一个覆盖超过130种语言、包含2亿图文对的庞大数据集。为了提升模型的泛化能力,他们不仅用了真实世界的图片,还开发了一套强大的数据合成与增强工具。
如上图所示,他们可以合成多语言文本(包括从右到左的书写顺序)、带有逼真褶皱和光影变化的文档图像,还能自动从已有的标注数据中生成新的问答和翻译数据,实现了数据的"一鱼多吃"。
四阶段预训练策略
为了让模型循序渐进地掌握各项技能,研究者设计了一个四阶段预训练流程:
第一阶段:视觉-语言对齐。冻结语言模型,只训练视觉编码器和连接器,让模型学会看图说话。
第二阶段:多模态预训练。放开所有参数进行端到端联调,增强对文档、表格等结构化内容的深层理解。
第三阶段:长上下文预训练。将模型的上下文窗口扩展到32K,专门"补习"长文档解析能力。
第四阶段:面向应用的SFT。使用高质量的人工标注真实数据进行微调,让模型更适应实际应用场景。
对于文字定位、文档解析这类有明确答案的任务,他们使用可验证奖励的强化学习(RLVR);对于翻译、问答这类开放性任务,则采用"LLM-as-a-judge"的方式,让一个更强的语言模型来当"裁判"打分。从训练动态图中可以看到,模型的平均奖励值在训练过程中稳步提升,证明模型确实"学进去了"。
MinerU 2.5
原理
MinerU 2.5 的模型由三个部分组成:
语言模型(Language Model): 采用了 0.5B 参数的 Qwen2-Instruct 模型,并将 1D-RoPE 位置编码改成 M-RoPE。
视觉编码器(Vision Encoder):采用了一个 675M 参数的 NaViT 编码器,这个由 Qwen2-VL 修改而来,并采用了 2D-RoPE 编码。
合并器(Patch Merger): 在 2×2 视觉 tokens 上使用像素反混叠(pixel-unshuffle),将视觉 tokens 进行预处理,再传入到语言模型中。
处理流程是分两阶段:
阶段1:布局分析。在输入图像被统一调整为 1036×1036 像素的缩略图,从而在控制计算成本的同时实现全局布局分析。
阶段2:内容识别。模型利用检测到的布局将原始高分辨率图像裁剪成局部区域,然后对这些区域进行精细解析。裁剪的区域以原始分辨率输入,像素上限为 2048 × 28 × 28,避免由于裁剪过小而导致的细节丢失,同时防止因裁剪过大而产生冗余计算。
总体来看,这个思路是很不错的,布局分析中用缩略图,这样有效避免原始图像分辨率过高,导致计算成本增加;内容识别中用原图进行裁切,这样可以避免因像素压缩导致的信息损失。
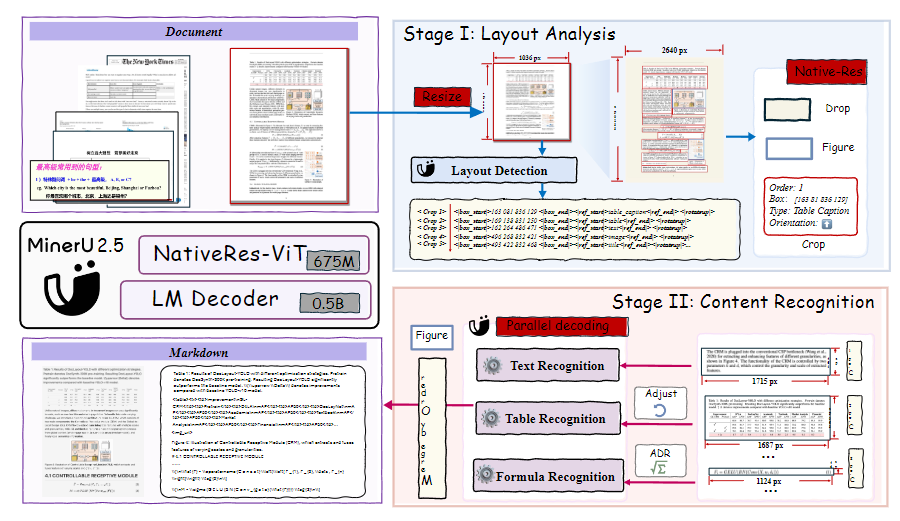
MinerU 2.5 成功就在于两阶段,因为其它的VLM模型大部分是端到端,在进行视觉编码的时候,自然会进行下采样,导致信息损失。
训练过程
MinerU 2.5 的训练分三个阶段。
模态对齐(Stage-0)
模态对齐是指将视觉信息和语言信息进行对齐,具体分以下两步:
语言-图像对齐。仅训练位于补丁合并器内的两层 MLP,而视觉编码器和语言模型均保持冻结状态。
视觉指令调优。所有模型参数均已解冻。重点在于知识积累和能力扩展,特别是加强视觉对齐和光学
字符识别(OCR)能力,目标是使 MinerU2.5 能够在各种视觉任务中遵循指令并生成合理的响应。
文档解析预训练(Stage-1)
文档解析预训练阶段的目标是使 MinerU2.5 获得两项基本能力:布局分析和内容识别。
布局分析,考虑到训练效率,整个文档图像被调整为固定分辨率,并配置了相应的相对坐标,同时使用提示"布局检测:"。
内容识别,使用文本块、公式块和表格块的单元素图像样本作为输入,分别使用提示"文本识别:"、"公式识别:"和"表格识别:"。
文档解析微调(Stage-2)
文档解析微调阶段的目标是在保持已获得的检测和解析能力的同时,进一步提高在复杂场景下的解析性能。
微调的核心是构建一个高质量的数据集,该数据集由两部分构成:
预训练数据集中抽取了高质量且多样化的示例
从一个大规模、多来源的 PDF 语料库中,利用数据工程识别出模型表现仍不理想的情况,并进行了有针对性的数据收集和人工标注,以获取代表挑战性案例的高质量样本
作者分析,MinerU 2.5 又快又好的重要原因是数据质量。为了构建高质量的数据集,他们又额外搭建了一套数据引擎。
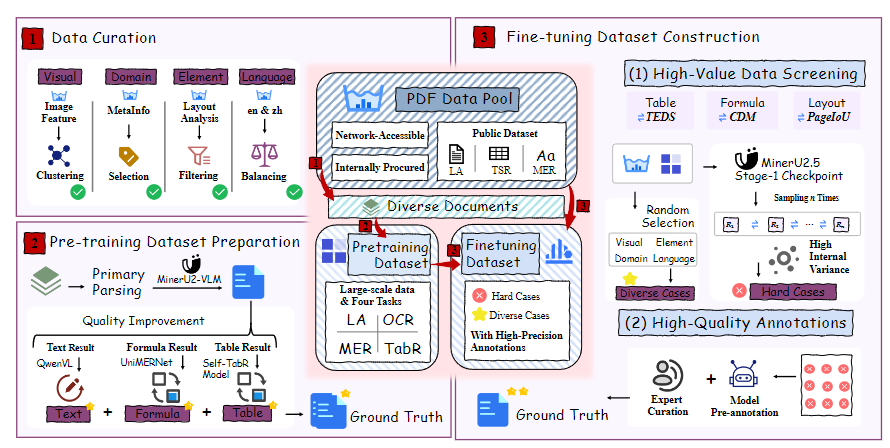
数据引擎分三个部分:
(1) 数据整理:从庞大的原始文档池中筛选,以根据布局、文档类型、元素平衡和语言构建多样且均衡的数据集。
(2) 预训练数据准备:整理后的数据生成自动标注,然后使用针对文本、表格和公式的专业强大模型进行优化,以确保高质量。
(3) 微调数据集构建:采用"通过推理一致性进行迭代挖掘(IMIC)"策略自动发现难例,然后经过严格的专家整理,以创建高质量的SFT数据集。其中,IMIC 是个比较创新的思路,IMIC 的核心原理利用了模型推理中固有的随机性。对于给定的样本,如果模型已经稳健地学习了其特征,那么启用随机采样的多次推理应产生高度一致的输出。相反,输出之间出现显著差异则表明该样本处于模型决策边界附近------这是模型预测不确定的"困难案例"。此类样本是手动标注的最有价值候选,因为它们直接针对模型的具体弱点。在此节中,作者还详细讨论了针对不同公式、表格、图像的处理。
LightOnOCR-2
中文支持不好,更适合研究
https://mp.weixin.qq.com/s/5ZLHpf623cCTBOt1cY9AMw
原理
LightOnOCR 不仅仅是另一个名字里带有 OCR 的模型。它实际上是一个端到端的模型。它没有分割或文本检测阶段,而是联合学习所有步骤。这使得它完全可微分,意味着您可以针对任何特殊的数据集(收据、法律 PDF、学术论文)对其进行整体微调。这种简洁性正是其优势所在:更少的组件,更少的故障风险。
它本质上是一个紧凑的单参数模型,但它采用了重要的组件:
受Mistral的Pixtral启发,Vision Transformer (ViT)主干网络用于高分辨率图像理解。
基于Qwen3的语言模型,用于处理文本推理。
一个全新的多模态投影层,连接视觉和文本空间,从零开始训练。
两者结合起来,它就像一个小型通用型 VLM,但针对 PDF、扫描文档和屏幕截图进行了精细调整。
https://huggingface.co/spaces/lightonai/LightOnOCR-2-1B-Demo
实践
试用地址
DeepSeek-OCRhttps://deepseek-ocr.io/zh/
PaddleOCR-VLhttps://aistudio.baidu.com/paddleocr?login_type=weixin
HunYuanOCRhttps://hunyuan.tencent.com/chat/HunyuanDefault?modelId=HY-OCR-1.0&mid=308&from=vision-zh
MinerU 2.5https://mineru.net/OpenSourceTools/Extractor
DeepSeek-OCR完整部署步骤:
Linux下保留系统CUDA12.6,通过Conda创建CUDA11.8环境部署DeepSeek-OCR
核心逻辑:利用Conda环境隔离性,在新环境中安装CUDA11.8 toolkit,系统CUDA12.6完全不受影响,所有依赖均在隔离环境内安装。
步骤1:安装/验证Conda(Anaconda/Miniconda)
如果已安装Conda,跳过此步;未安装则执行:
下载Miniconda(Linux x86_64)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
执行安装(按提示操作,建议同意将conda加入PATH)
bash Miniconda3-latest-Linux-x86_64.sh
刷新环境变量
source ~/.bashrc
验证conda
conda --version
步骤2:创建Conda隔离环境(CUDA11.8 + Python3.12.9)
1. 创建环境(名称:deepseek-ocr,Python3.12.9)
conda create -n deepseek-ocr python=3.12.9 -y
2. 激活环境
conda activate deepseek-ocr
3. 安装Conda版CUDA11.8 toolkit(仅环境内生效,不影响系统CUDA12.6)
conda install -c conda-forge cudatoolkit=11.8 -y
4. 验证环境内CUDA版本(关键!输出需包含cudatoolkit=11.8)
conda list | grep cudatoolkit
步骤3:克隆DeepSeek-OCR仓库
克隆仓库
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
进入仓库根目录
cd DeepSeek-OCR
步骤4:安装PyTorch(CUDA11.8版本)
严格匹配仓库要求的torch2.6.0+cu118,指定PyTorch官方cu118源:
pip install torch2.6.0 torchvision0.21.0 torchaudio2.6.0 --index-url https://download.pytorch.org/whl/cu118
验证Torch关联的CUDA版本(必须输出11.8和True)
python -c "import torch; print('Torch CUDA版本:', torch.version.cuda); print('CUDA可用:', torch.cuda.is_available())"
若输出不是11.8,删除环境重新创建,或检查pip源是否被代理干扰。
步骤5:安装vllm 0.8.5+cu118
先下载对应CUDA11.8的vllm whl包,再安装:
下载vllm-0.8.5+cu118适配包(Python3.8+,manylinux1_x86_64)
安装下载的vllm包
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
若下载慢,可手动从vllm Release页下载对应whl到本地,再执行pip install 本地whl路径。
步骤6:安装其他依赖(requirements + flash-attn)
安装仓库依赖
pip install -r requirements.txt
安装flash-attn 2.7.3(需编译,先装系统编译工具)
sudo apt update && sudo apt install -y gcc g++ build-essential # Ubuntu/Debian
CentOS/RHEL:sudo yum install -y gcc gcc-c++ make
安装flash-attn(关键参数--no-build-isolation)
pip install flash-attn==2.7.3 --no-build-isolation
步骤7:配置运行参数(修改config.py)
进入vllm推理目录,修改核心路径和参数:
cd DeepSeek-OCR-master/DeepSeek-OCR-vllm
编辑config.py(用vim/nano/VSCode等)
vim config.py
修改以下关键参数(示例):
模型路径(自动从Hugging Face下载,也可指定本地路径)
MODEL_PATH = 'deepseek-ai/DeepSeek-OCR'
输入路径:改为你的测试文件(图片/jpg/png 或 PDF)
INPUT_PATH = '/path/to/your/test.jpg' # 或 /path/to/your/test.pdf
输出路径:自定义输出目录(自动创建)
OUTPUT_PATH = '/path/to/your/output_dir'
其他参数(按需调整,GPU内存不足时降低)
MAX_CONCURRENCY = 20 # 默认100,低配GPU改为20/10
MAX_CROPS = 4 # 默认6,低配GPU改为4/2
CROP_MODE = True # 保持默认
步骤8:运行测试(图片/PDF推理)
确保始终在deepseek-ocr Conda环境中执行:
激活环境(若已激活可跳过)
conda activate deepseek-ocr
1. 单图片推理(流式输出)
python run_dpsk_ocr_image.py
2. PDF推理(A100-40G约2500tokens/s)
python run_dpsk_ocr_pdf.py
3. 批量评估(基准测试)
python run_dpsk_ocr_eval_batch.py
关键问题解决(CUDA隔离+常见报错)
- 解决ptxas路径报错(TRITON_PTXAS_PATH)
由于系统CUDA是12.6,Conda环境内CUDA11.8的ptxas需手动指定:
修改run_dpsk_ocr_image.py/run_dpsk_ocr_pdf.py的开头CUDA判断逻辑
if torch.version.cuda == '11.8':
自动获取Conda环境内的ptxas路径,无需硬编码
os.environ"TRITON_PTXAS_PATH" = f"{os.environ'CONDA_PREFIX'}/bin/ptxas"
- GPU内存不足
降低config.py中MAX_CONCURRENCY(如10)、MAX_CROPS(如2);
修改脚本中llm = LLM(...)的gpu_memory_utilization为0.8(默认0.9)。
- Transformers版本冲突
仓库说明无需担心,但若报错可升级:
pip install transformers==4.51.1 -U
核心说明
CUDA隔离性:Conda环境内的cudatoolkit=11.8仅作用于该环境,系统nvcc --version仍显示12.6,完全不影响其他应用;
模型下载:首次运行会自动从Hugging Face下载deepseek-ai/DeepSeek-OCR模型,需保证网络通畅;
环境复用:后续使用只需执行conda activate deepseek-ocr即可,无需重复安装依赖。
PaddleOCR-VL部署:
https://www.freeforai.com/zh/document_parse.php
https://blog.csdn.net/fufan_LLM/article/details/153832353
https://aistudio.baidu.com/paddleocr?login_type=weixin
HunyuanOCR部署:
https://blog.csdn.net/paopao_wu/article/details/155500929
MinerU 2.5部署:
https://blog.csdn.net/gitblog_00795/article/details/152012164
参考:
https://www.modelscope.cn/models/opendatalab/MinerU2.5-2509-1.2B
https://zhuanlan.zhihu.com/p/1964739506629490036
https://www.cnblogs.com/daibitx/p/19231470
https://apifox.com/apiskills/hwo-to-use-deepseek-ocr/
https://zhuanlan.zhihu.com/p/81876510521
https://www.bilibili.com/video/BV1zCXhYbE2p/?vd_source=b3b702c752363b3c1ac01a51268137f5
https://zhuanlan.zhihu.com/p/1966570562085160648
https://blog.csdn.net/Everly_/article/details/153966236
https://developer.volcengine.com/articles/7563877547419631654
https://blog.csdn.net/fufan_LLM/article/details/153832353
https://zhuanlan.zhihu.com/p/1974059457282586385
https://blog.csdn.net/weixin_42124497/article/details/157006803
https://zhuanlan.zhihu.com/p/408148217
https://zhuanlan.zhihu.com/p/28327088393
https://blog.csdn.net/gitblog_01191/article/details/151210236
https://blog.csdn.net/paopao_wu/article/details/155500929
https://mp.weixin.qq.com/s/5ZLHpf623cCTBOt1cY9AMw
https://blog.csdn.net/paopao_wu/article/details/155500929
https://hunyuan.tencent.com/chat/HunyuanDefault?from=modelSquare\&modelId=HY-OCR-1.0
https://zhuanlan.zhihu.com/p/1964708061026428289
https://huggingface.ac.cn/papers/2511.19575
https://zhuanlan.zhihu.com/p/1977498008712131326
https://zhuanlan.zhihu.com/p/1978412033520186450
https://hunyuan.tencent.com/chat/HunyuanDefault?from=modelSquare\&modelId=HY-OCR-1.0
https://blog.csdn.net/paopao_wu/article/details/155500929
https://zhuanlan.zhihu.com/p/1977065984788541488
https://blog.51cto.com/wukongmazi/14442089
https://juejin.cn/post/7568817148326084643
https://blog.csdn.net/qq1198768105/article/details/152509899
https://blog.csdn.net/qq1198768105/article/details/152509899
https://blog.csdn.net/gitblog_00795/article/details/152012164