3.3 LOGIC SIMULATION
这一节介绍两种常用的逻辑仿真的方法:
- compiled-code
- event-driven
虽然这一章没有介绍,但是常用来加速逻辑仿真的方法是:硬件仿真和加速hardware emulation and acceleration
3.3.1 Compiled-Code Simulation(编译代码仿真)
compiled-code simulation:就是模拟gates和他们之间互连的功能,形成一套机器指令,使代码和pattern配合在主机上执行。
仿真flow如下图a:
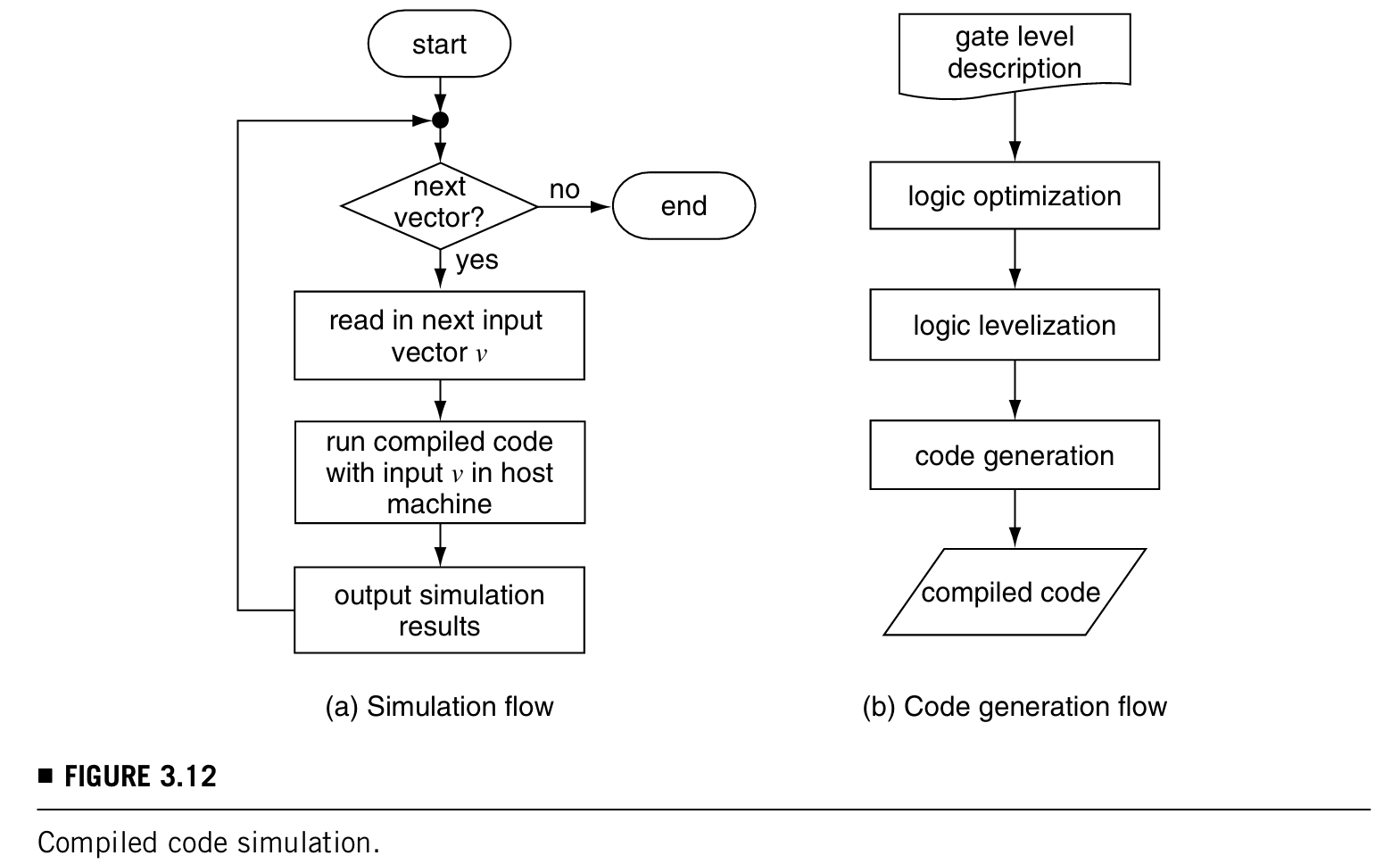
code生成的flow如上图b。详述如下面分节。
3.3.1.1 Logic Optimization
logic optimization:逻辑优化的目的是提升仿真的效率。它能减少代码和执行时间。
过程如下图:
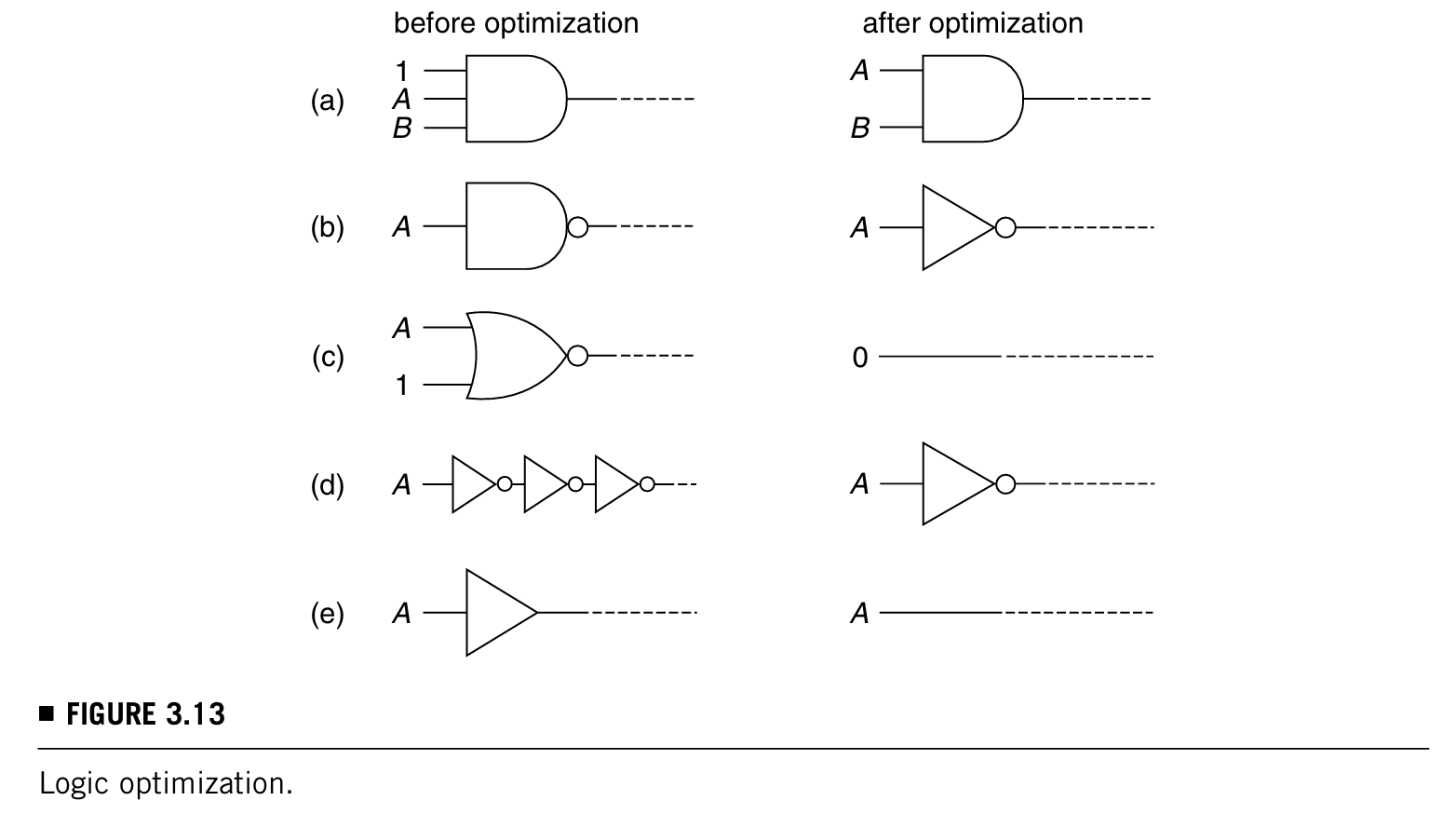
包括以下几步:
- a------移除noncontrolling values的输入
- b------将一输入的门转化成一个反相器或者一个buffer
- c------移除controlling value的输入,并且把输出替换为1或者0(就是这些输入对应的输入值)
- d------将三个串联的反相器替换为一个反相器(这个操作在时钟树中常用)
- e------将buffer替换为一单根线
- 移除掉drive unobservable或者floating outputs的门
3.3.1.2 Logic Levelization(逻辑分级)
为了避免不必要的计算,需要对逻辑门进行分级,即对他们的工作顺序进行排列,防止后一级已经准备好了但是前级驱动还没准备好。
逻辑分级算法如下图所示:
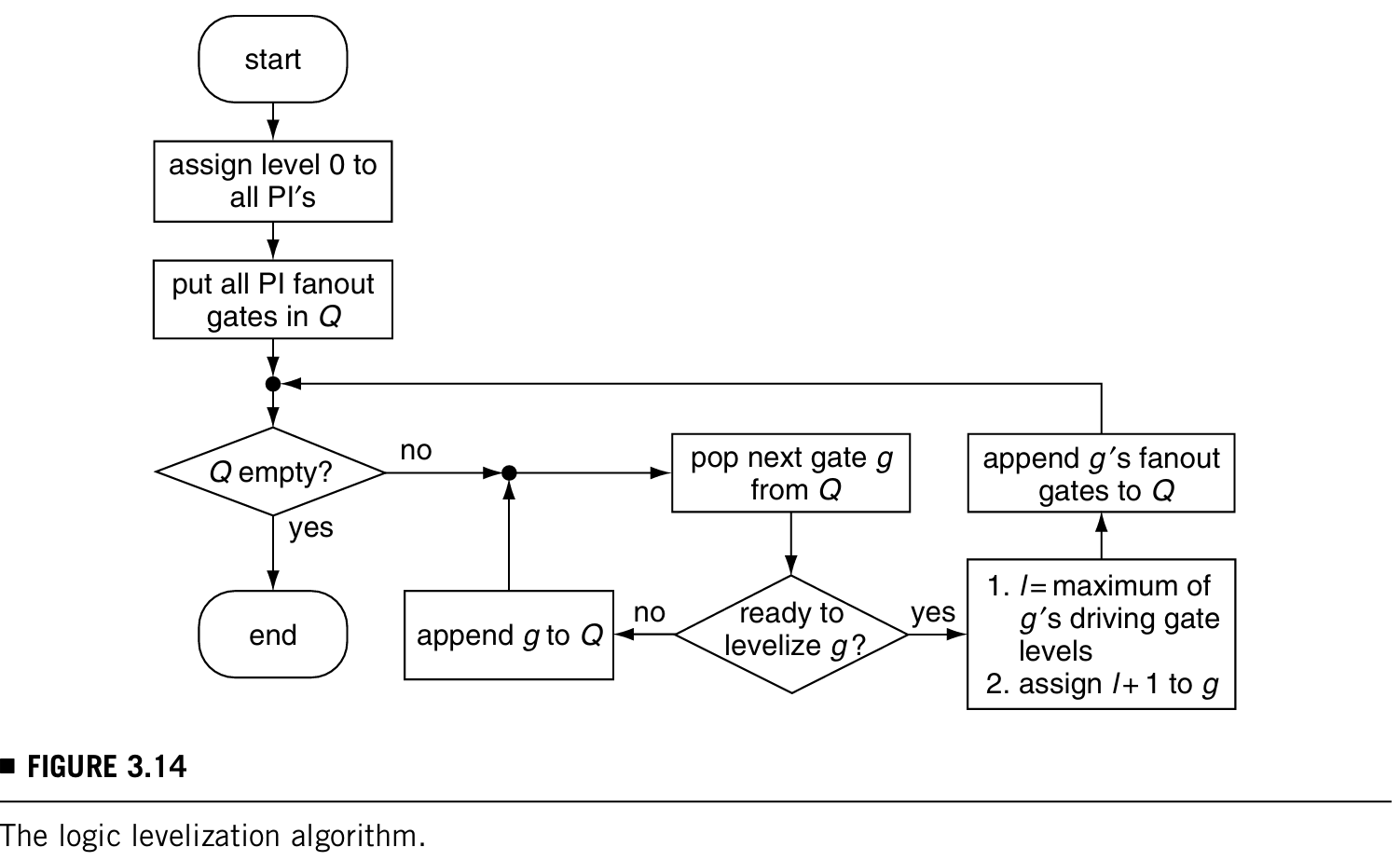
根据这样的算法,对电路N进行分级的步骤如下表:
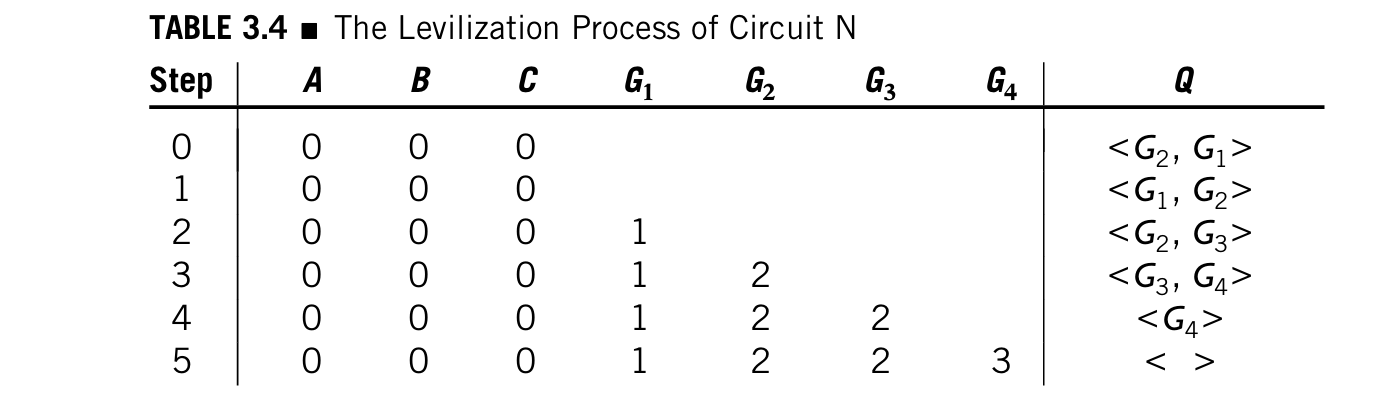
*如果门的level一样,那么他们的顺序就无所谓
所以电路N的分级可以是下面两种中任意一种:
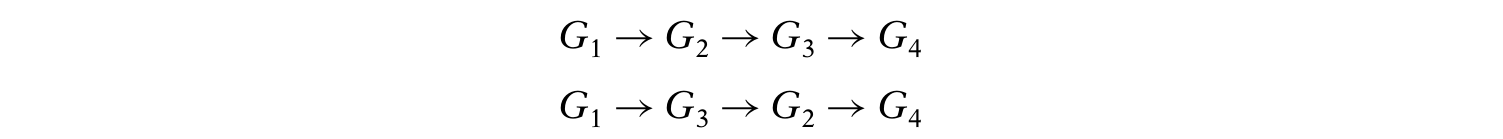
3.3.1.3 Code Generation
对于性能、可移植性、可维护性的需求不同,可以选择不同的代码生成技术。以下介绍3种代码生成方法:
- High-level programming language source code :例如c语言
- 优点:容易debug、可移植性高(可以移植到有c语言编译器的任何机器上)
- 缺点:仿真时间长
- Native machine code :直接生成机器代码,不需要编译
- 优点:可能可以实现高效仿真
- Interpreted code :
- 优点:能提供最佳的可移植性和可维护性
- 缺点:牺牲性能
Compiled-code simulation这种仿真方法在二值系统中是最有效的,它的主要缺陷是:
- incapability of timing modeling------不能仿真时序:探测不了时序问题。
- low simulation efficiency------效率低:对于每个输入的向量,都得把整个电路网络都评估一遍,但是其实每个向量只有1-10%的输入信号会发生变化。