前言❤️❤️
hello hello💕,这里是洋不写bug~😄,欢迎大家点赞👍👍,关注😍😍,收藏🌹🌹
在上篇博客中对表的操作,主要是针对整个表的,本篇博客中的CRUD就是针对表中具体的数据进行操作,这篇博客中的知识多并且杂,铁汁们可以分多次来看🐵
🎇个人主页:洋不写bug的博客
🎇所属专栏:数据库
🎇mysql8.0和navicate的安装:mysql安装教程
🎇铁汁们对于MySQL数据库的各种常用核心语法,都可以在上面的数据库专栏学习,专栏正在持续更新中🐵🐵,有问题可以写在评论区或者私信我哦~

1,什么是CRUD
CRUD就是四个英文单词的首字母和在一起:
- Create(创建)
- Retrieve(读取)
- Update(更新)
- Delete(删除)
这些操作合在一起,就是常说的增删改查操作
2,Create新增
Create新增,新增的就是数据行
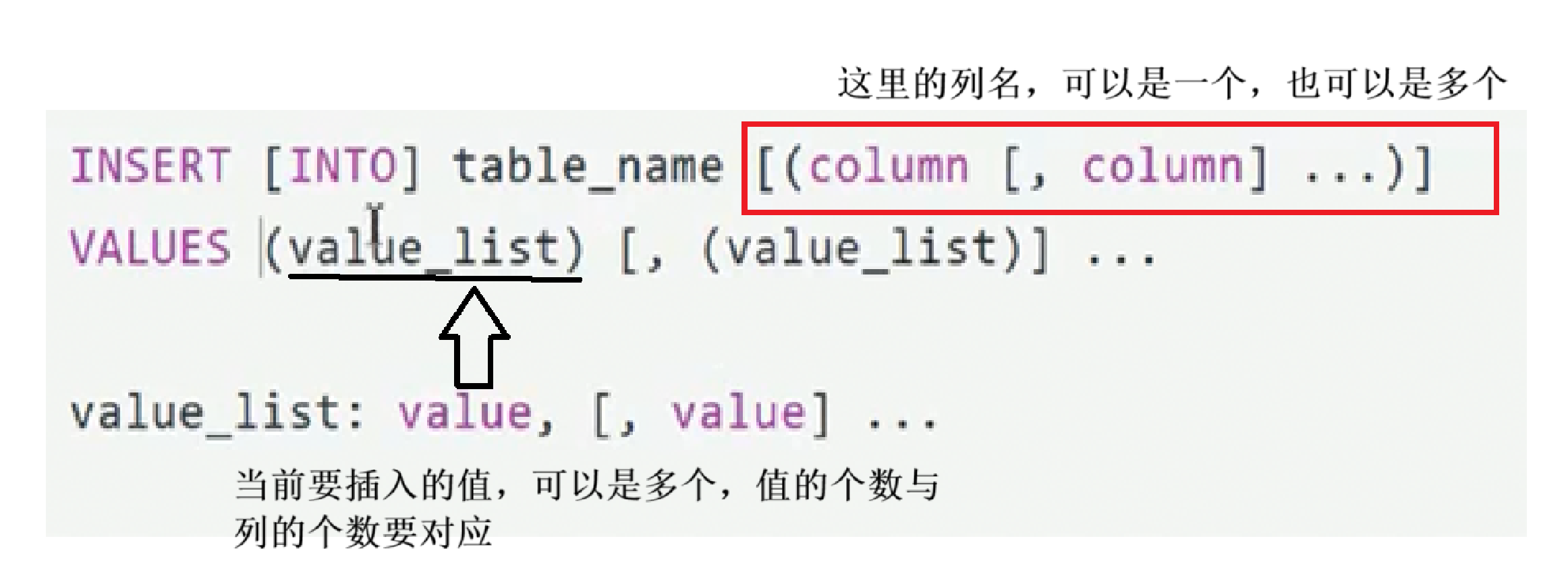
这里先大概看下语法,这里的column就是列,values就是在列中插入的数据值,这里刚看不太理解也无所谓,后面例子一上肯定就很容易理解了
sql
use first_database;
create table users (
id bigint,
name varchar(20) comment '用户名'
)在first_database数据库中创建一个表,有id列和name列,这时候这个表还没有具体的数据,如果要在表中插入数据,就要用到Create新增语句
下面这个sql语句就是插入了一行数据,对照前面的语法看下,应该很好理解
表名后面的括号就是列名,values后面的括号就是要在每列中插入的元素,前面的括号跟后面的括号里的内容应该是一一对应的
sql
insert into users(id,name) values (3,'helly');右键这个表,点击打开表,可以看到这行数据已经成功插入了
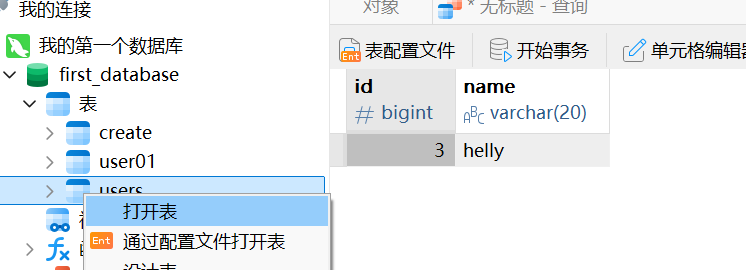
这里要注意,前面的括号跟后面的括号里的内容应该是一 一对应的
如果这样写,那肯定就会报错,因为这个相当于把'helly'加到了id这个列名里,但是id的数据类型是bigint,字符串数据类型肯定存不进去。
sql
insert into users(id,name) values ('helly',3);
users后面的括号也可以省略,这样就会自动按表的列名从前到后进行匹配,表的列名顺序是id,name;因此后面的插入id写在前,name写在后面
sql
insert into users values (3,'helly');那能不能values后面的括号先写name,再写id?
这个当然可以,无论怎么写,只要前面括号中的列名跟后面插入的数据匹配即可
示例如下:
sql
insert into users(name,id) values ('马克',2);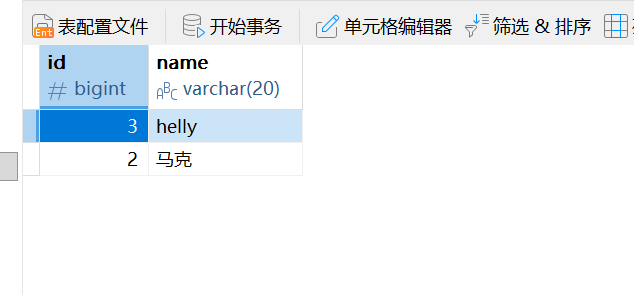
一个一个插入数据行太麻烦了,就可以把每个行的插入之间用逗号隔开,这样就能一次插入很多行
示例如下:
sql
insert into users(id,name) values(1,'米尔切克'),(4,'迪伦'),(5,'伯特');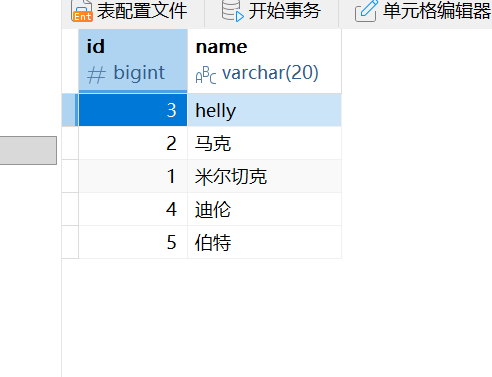
如果少插入一列的数据,只要前面的列名跟后面的插入的数据能对应上,就不会报错 ,只是这个数据就是NULL(后面学习约束时,就可以设定默认值,当没有插入这个数据时,就默认是什么值)
示例如下:
sql
insert into users(name) values ('海伦娜');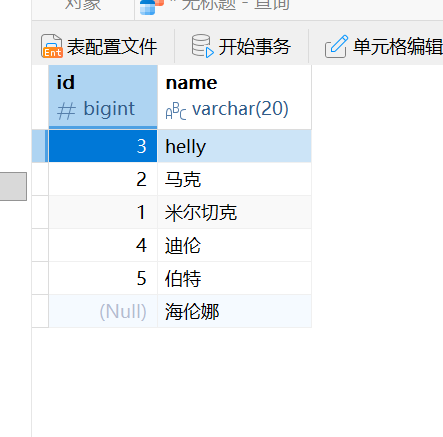
3,Retrieve检索
1,基础检索
Retrieve其实就是用于查询表中的数据,例如要查询表中所有的数据
用select这个关键字表示查询的意思,表示查询所有列,from后面跟表名,表示要查询哪个表示例如下:
sql
SELECT * from users;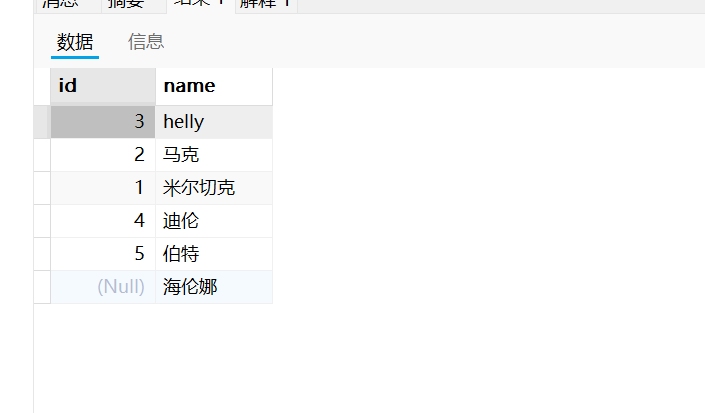
这里再创建一个学生成绩表,里面的内容是id,姓名,语数英成绩;再插入一些数据,进行操作演示
代码如下:
sql
use first_database;
create table students(
id bigint,
`name` VARCHAR(20),
chinese double,
math double,
english double
)
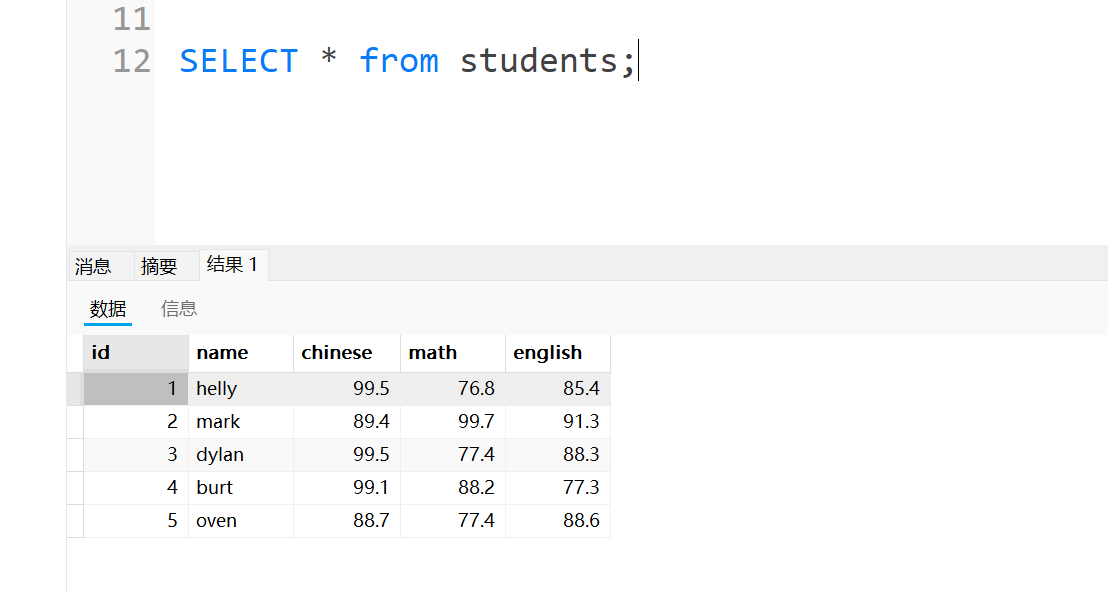
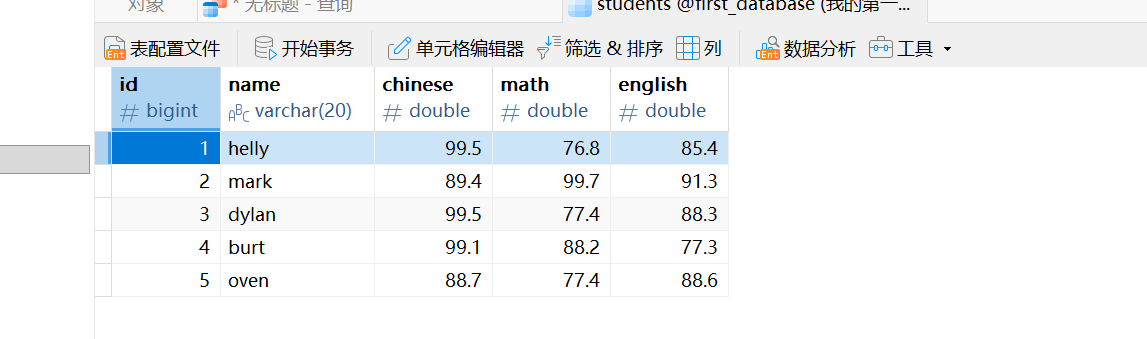
INSERT into students(id,name,chinese,math,english) values(1,'helly',99.5,76.8,85.4),(2,'mark',89.4,99.7,91.3),(3,'dylan',99.5,77.4,88.3),(4,'burt',99.1,88.2,77.3),(5,'oven',88.7,77.4,88.6);创建完成后,查看下表里的内容
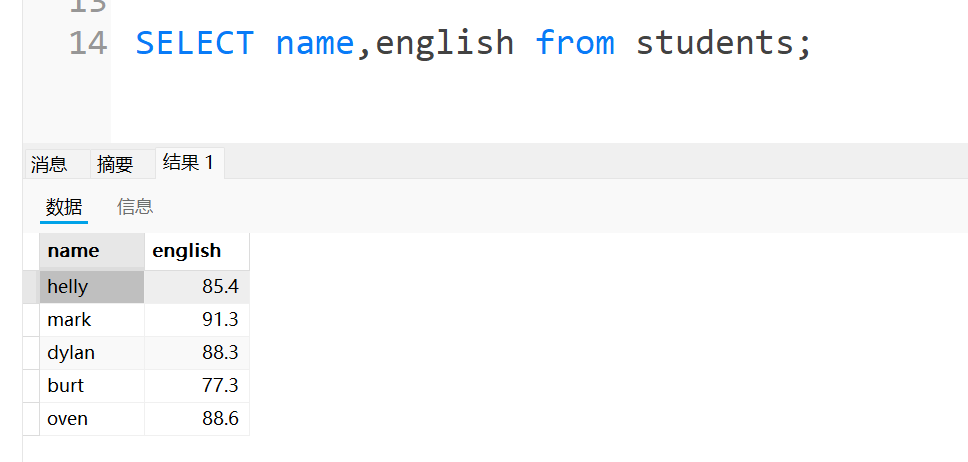
如果只想查每个人的英语成绩,就可以指定列名进行查询:
这时候就新生成了一个临时表,让我们查看
也可以把每个人的英语加上5分,重新生成一个临时表:
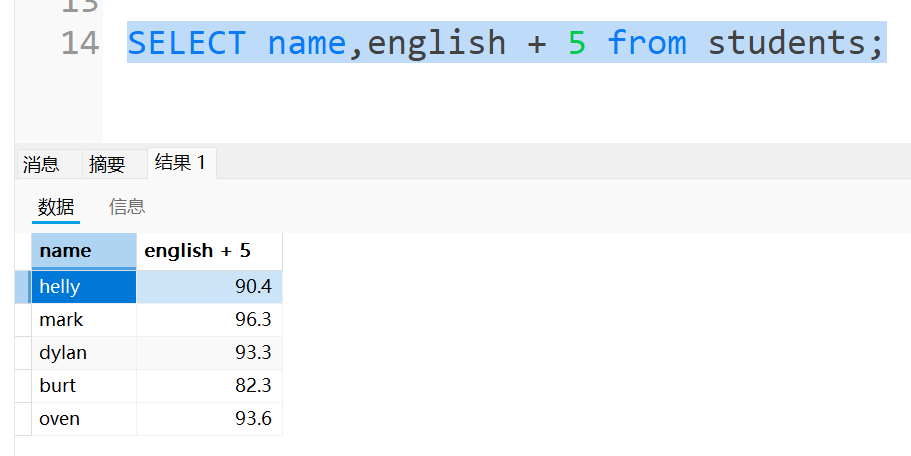
注意,这里只是生成了一个临时表供我们来查看,原表中的英语成绩是没有变的
也可以计算总分(如下图):

这里double会有精度损失,因此小数点后的位数就可能会不一样,使用decimal的话,就不会有这种问题了
可能有的铁汁会觉得,这样写列名不太好看,能不能把列名设为总分呢?
当然可以,在后面加个as + 列名就可以了
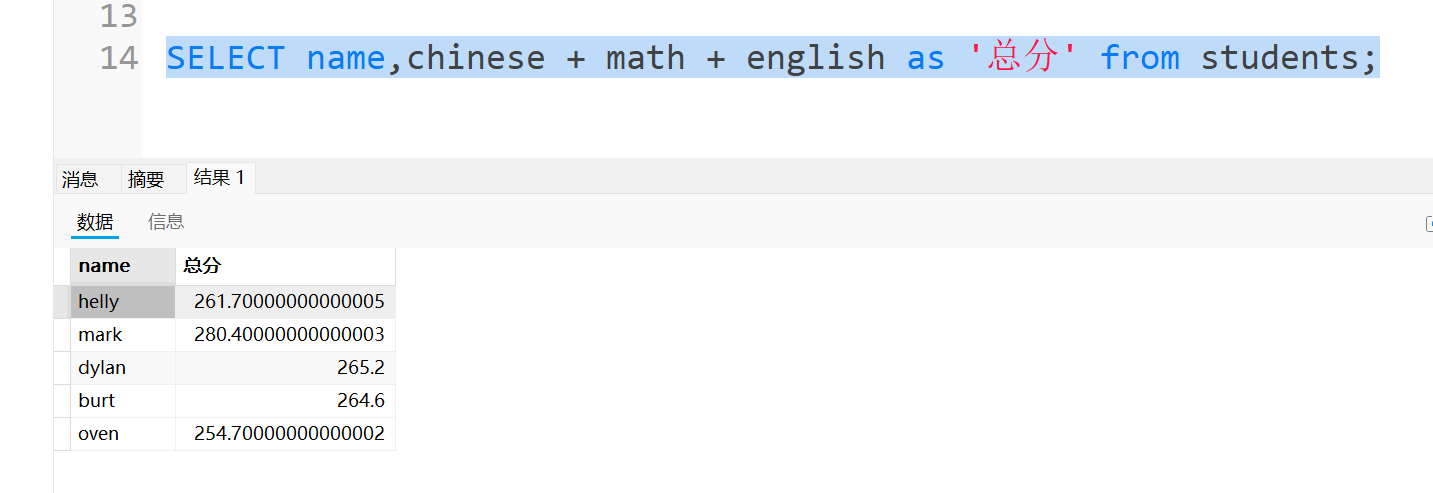
这里也可以直接省略as,把'总分'空一格写在后面,大家可以写下试一试
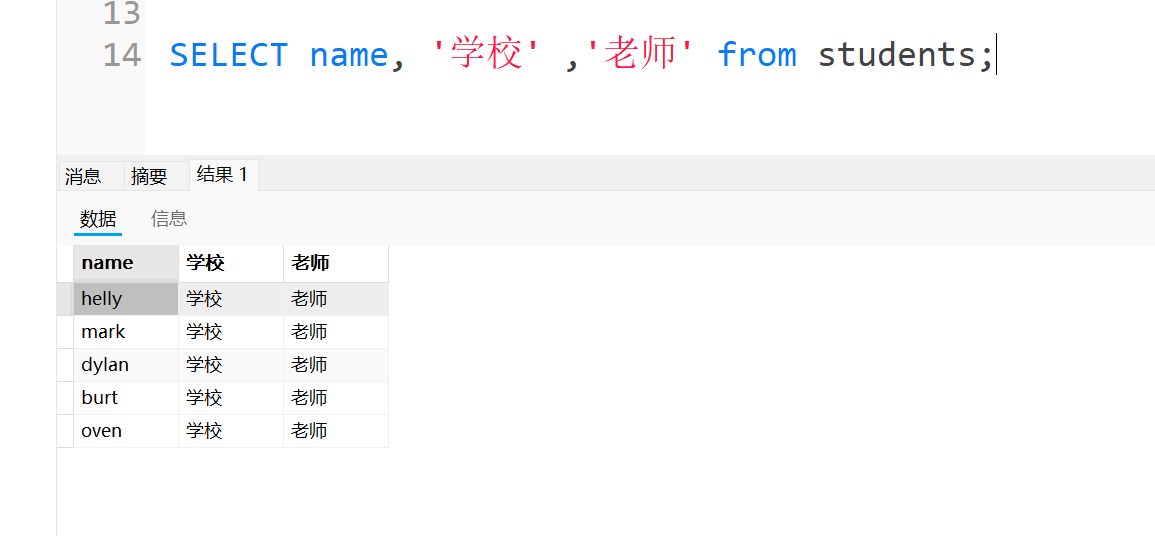
如果查询的列名不存在,这里就会重新生成列,里面填充列名
有时候会有这样的需求,那就是查询某个列,然后让这个列中相同的元素只显示一次,这时候就使用distinct
例如想要看语文成绩这列,这里helly和dylan的语文成绩都是99.5(如下图)
这里加上distinct看下效果,因此这列中不能有重复的元素,因此就会舍弃掉一个99.5,只显示一个:
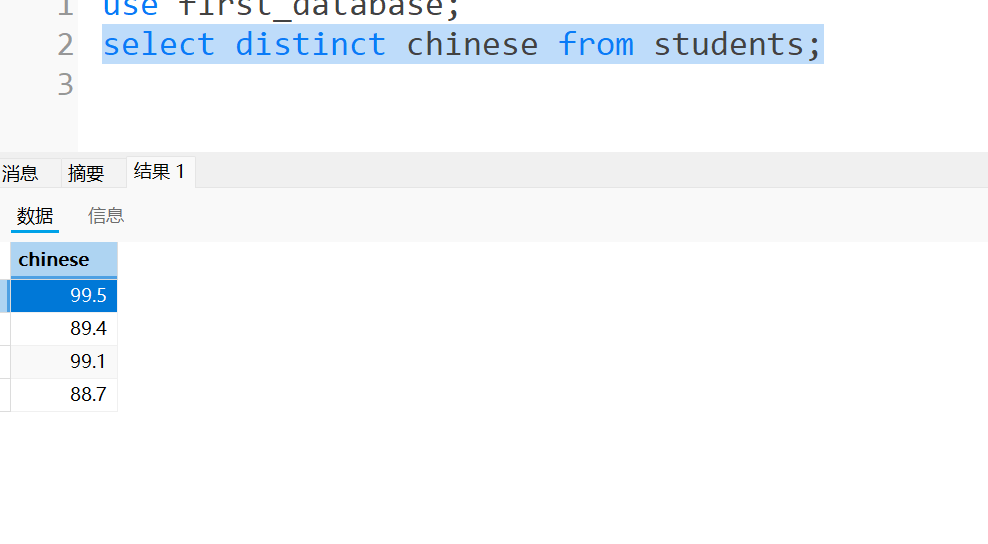
那我们如果这样写,会舍弃一个99.5吗?
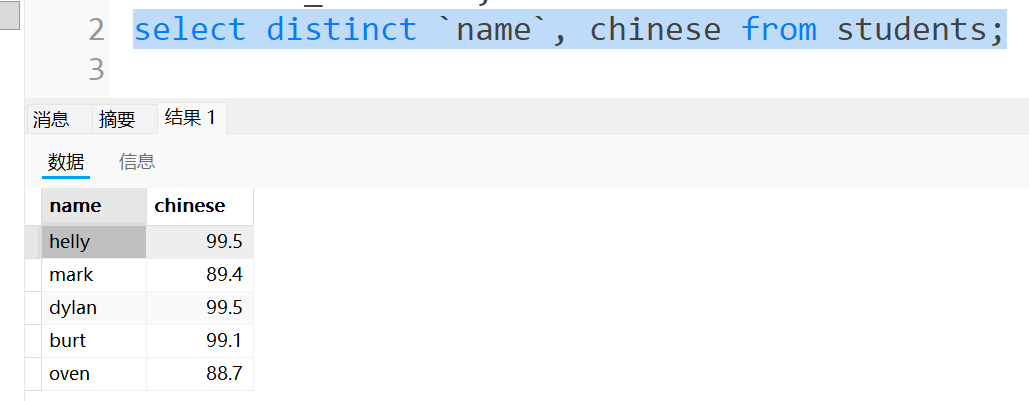
答案是不会,因为这时候一个是{helly,99.5},一个是{dylan,99.5},这是两个不同的元素,虽然chinese相同,但是名字不同
2,Where条件查询
刚刚提到的那些检索方法,如果表中有几十万,几百万条数据,这时候写个查询全表数据的代码,铁汁们想下会怎么样?
sql
SELECT * from users;这样检索表中的所有的数据的操作会大量服务器资源
可能你这个任务太大了,把服务器资源占满了,这时候服务器就只处理这一个指令,公司其他人对这个数据库进行操作,比如存数据,改数据,他们的操作就不会被执行
因此,在查询数据时,最好加上一点限制条件,只查询自己需要的那些数据,这个就是用到Where条件查询
语法如下,其实就是多写个WHERE,在WHERE后面加上个条件

WHERE后面的限制条件必不可少的就是运算符,那就看下sql语句中的运算符:

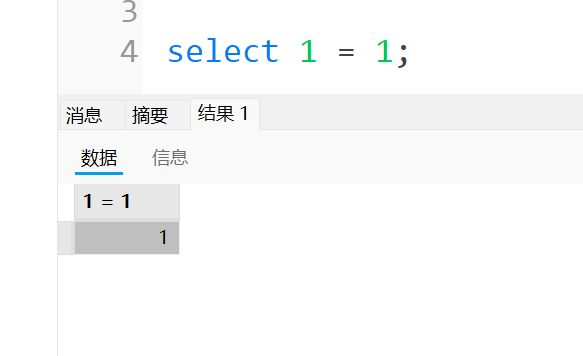
大于小于这些跟Java中一样,等于在这里是单等号,注意下区别
例如这里写个1=1,结果是1(true),这里跟C语言中一样,0代表的就是false,1代表的是true
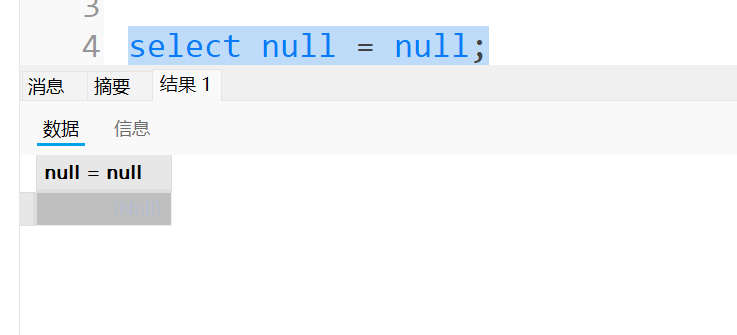
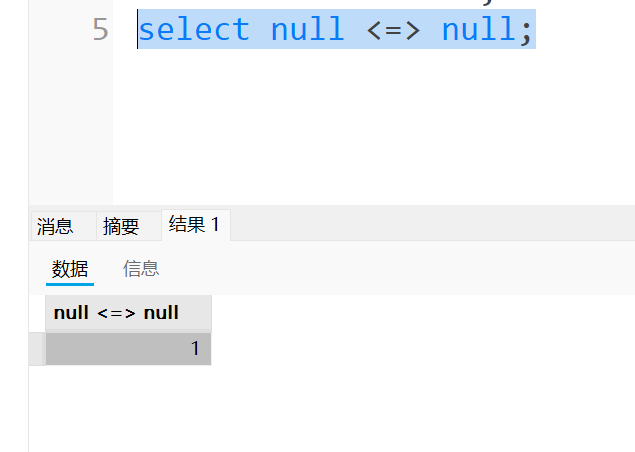
在判断null时,要用到特殊的等号<=>,用普通的等号判断出的结果还是null,没什么意义,示例如下:
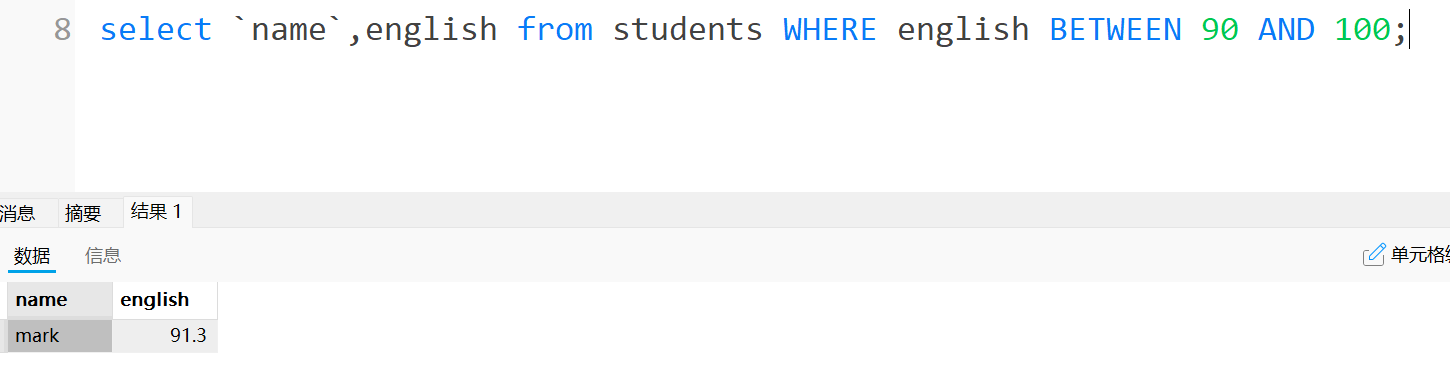
value BETWEEN就是用于查询一个列中在一个范围内的数据或者不在一个范围内的数据
例如查询到英语在90分以上的人:
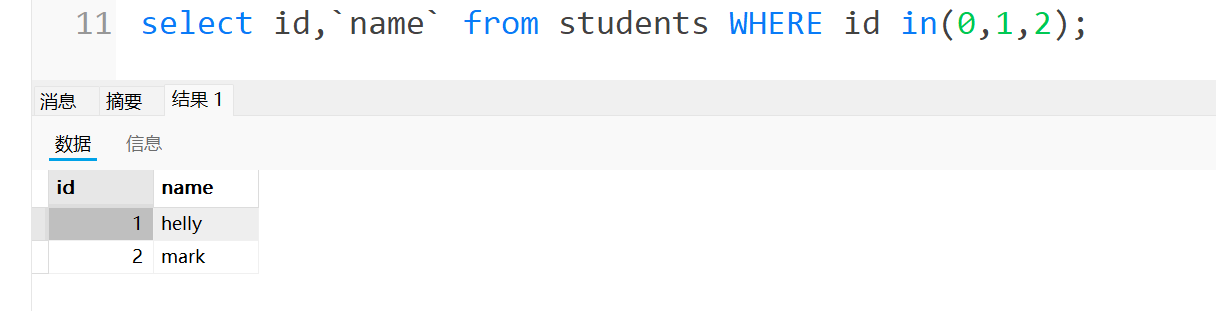
value in option就是查询value是否在option列表中
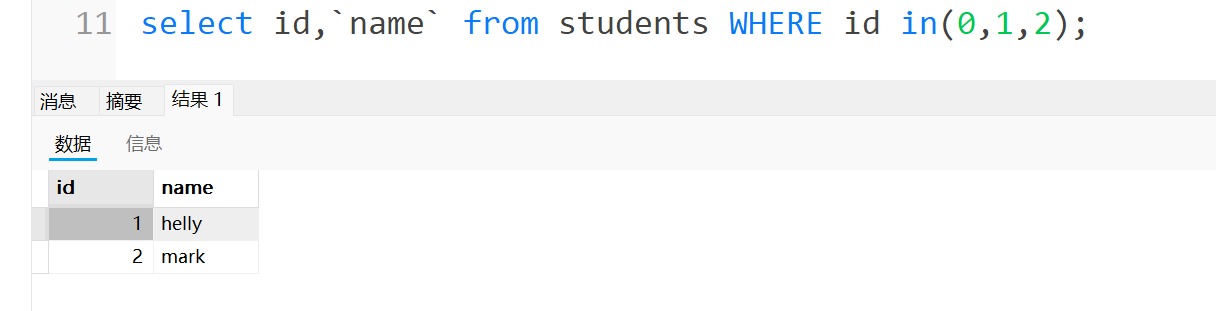
例如查id是0,1,2的学生的信息,只要id在in后面的括号里面,这里就可以匹配上,进行查询
接着就是like,在模糊匹配时使用
为了演示,在表中插入一个叫helena的学生:
sql
insert into students(id,name,chinese,english,math) VALUES(6,'helena',77,66,55);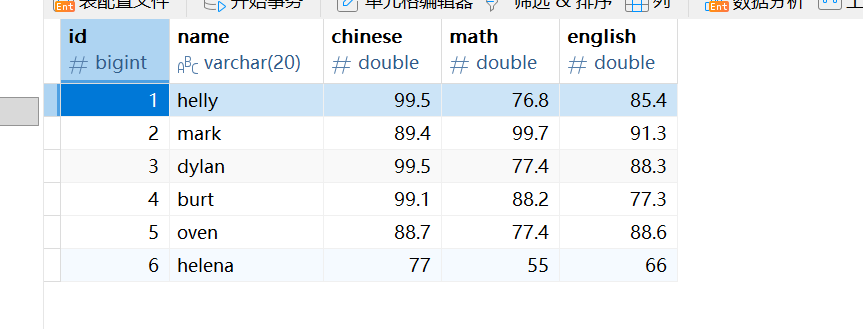
接着使用like进行模糊查询,来查询名字是h开头的人
需要在h后面加个百分号,意思就是h后面有几个字符什么的无所谓,只要名字是h开头就行
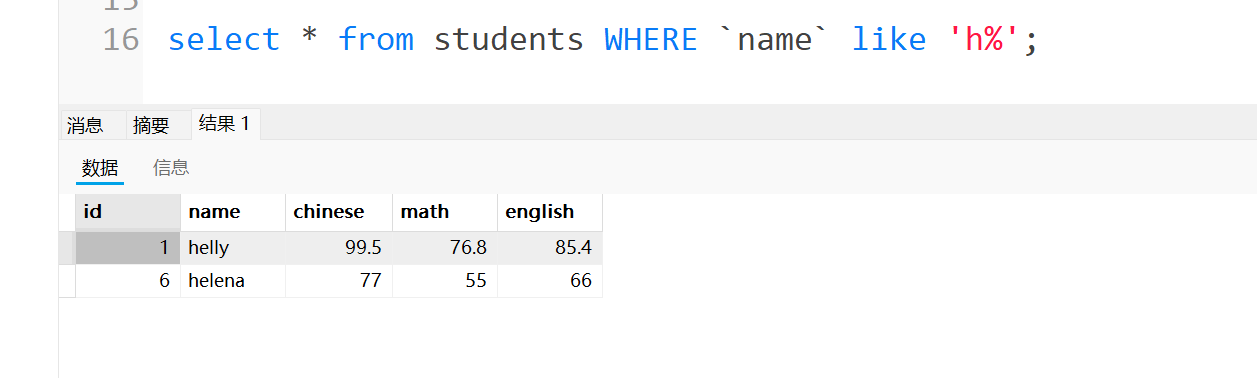
那如果想要比较精准的查找呢,比如说找以h开头并且h后面必须是5个字符,
在后面加下划线"_",一个下划线代表一个字母或者汉字,这里我们加5个下划线看下效果:
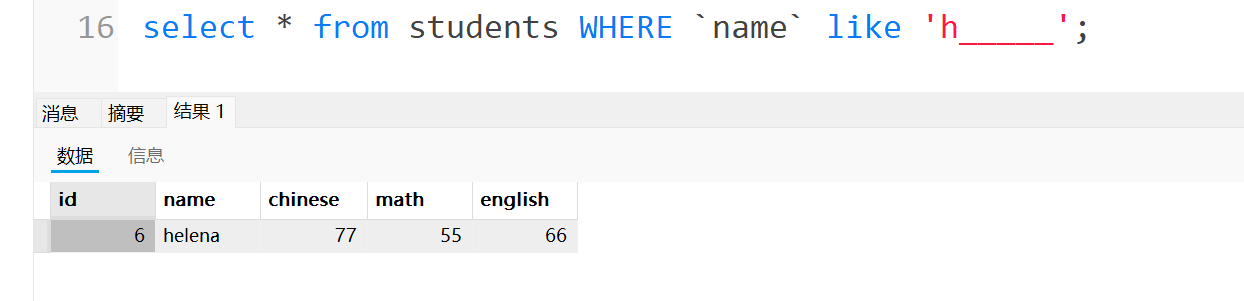
这里的like是查找的一个重点,我们可以用百分号进行模糊查询,但是查找还是越精确越好。
刚刚提到了了临时表,比如生成一个计算总分的临时表,也可以用临时表中的数据作为条件来进行查询,示例如下:
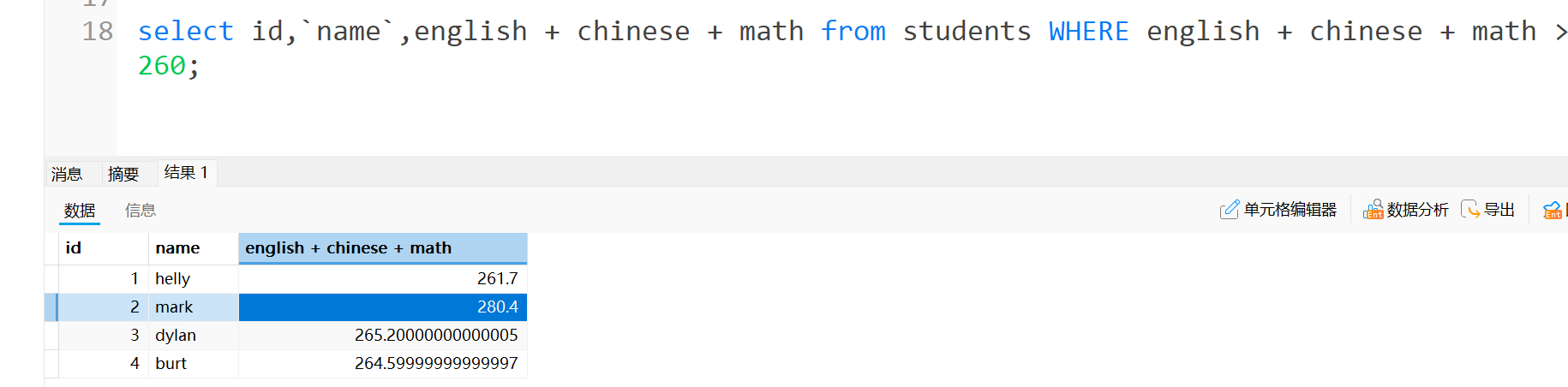
觉得列名不好看,也可以把列名改为total

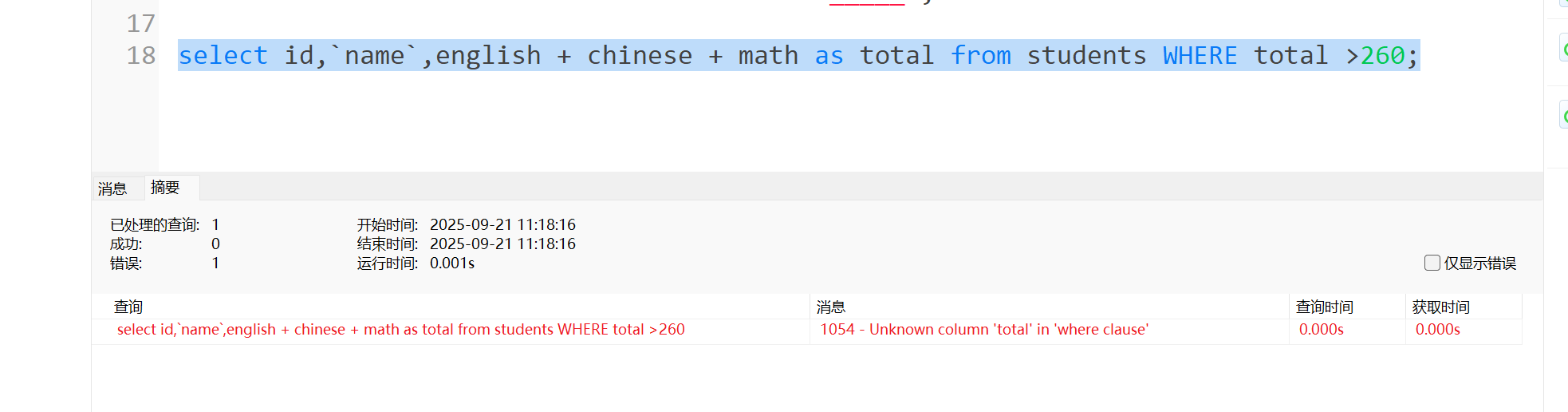
有的铁汁可能会说,你既然已经改了临时表的列名,那后面这样写,不是更方便?
sql
select id,`name`,english + chinese + math as total from students WHERE total >260;我们发现这样写是会报错的,报错原因是系统不知道这个total是什么意思,我们明明已经修改过了,为什么系统和不知道呢,那我们就给大家分析一下:
在这句话中,有三个主要的关键字:
- select:在临时表中打印哪些数据
- from:选取查找在哪个表格中进行
- where:约束条件
铁汁们仔细想下,这里这三个关键字的执行顺序是什么?
是from - where - select首先from选取是数据库中的哪个表,where查询哪些数据符合条件,最后才是select根据查到的符合条件的数据和临时表的列名来生成临时表
where对于条件的判断在第二步,但是select中定义别名total在第三步,也就是where执行的时候还没有tatal这个别名呢,因此这时候肯定就会报错
有的查询要求也要用AND和OR
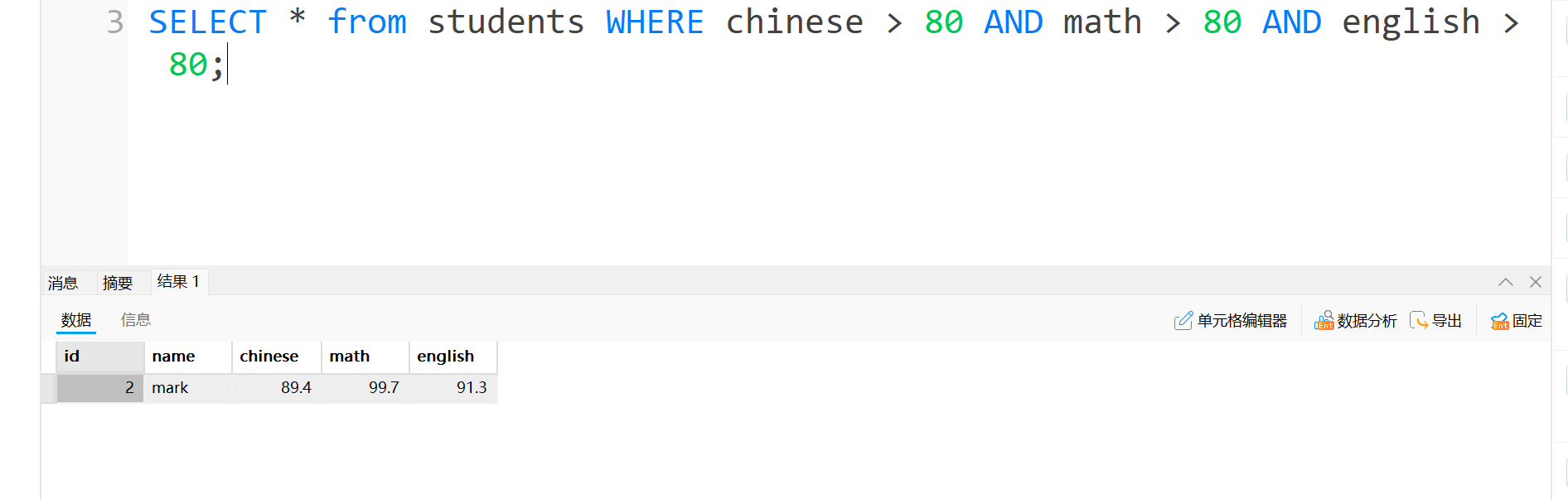
比如说查找语文,英语,数学这三门都大于80分的人(如下图):
还有就是想查询语文成绩在80到90之间的人,也可以使用AND来限定条件,但是一般不会用AND,因为between来查询会会更加方便
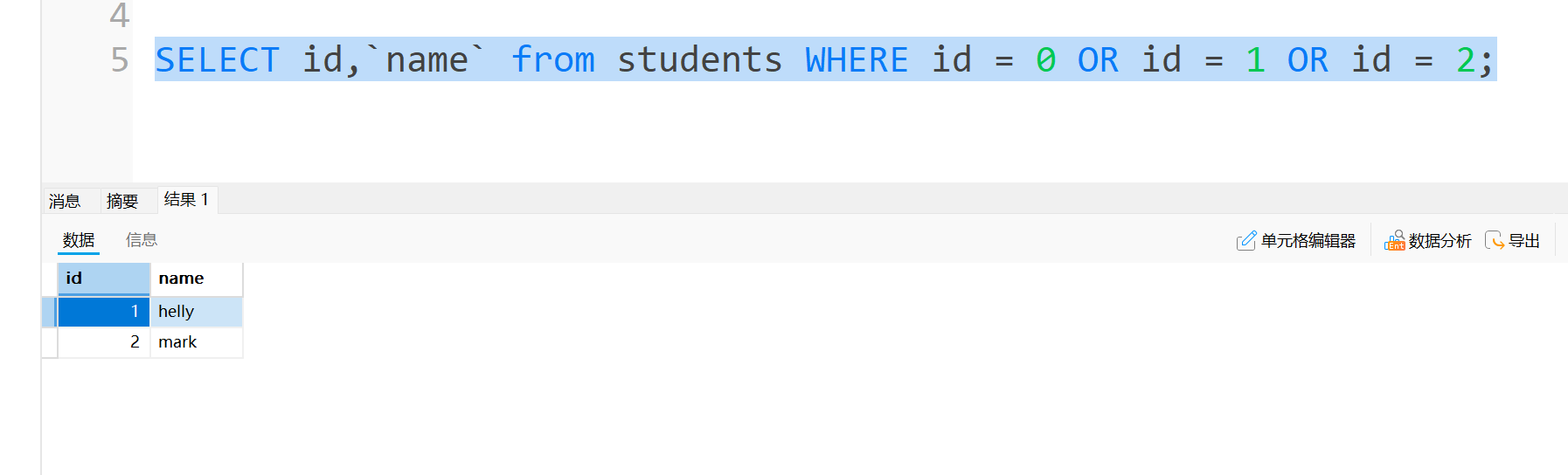
option in也可以用or来代替,但是用or来写,代码就比较多,不建议用:
接下来是有关NULL的查询,
在表中新插入一名学生,假设这位同学考试的时候出去打比赛了,数学缺考,成绩是NULL:
sql
INSERT students(id,name,chinese,math,english) values(7,"carrie",99,NULL,93);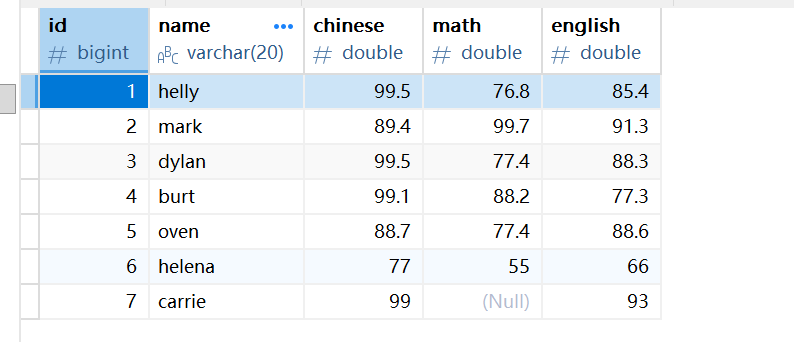
在sql语言中,NULL有个特性,那就是无论进行什么运算,结果都是NULL,示例如下:
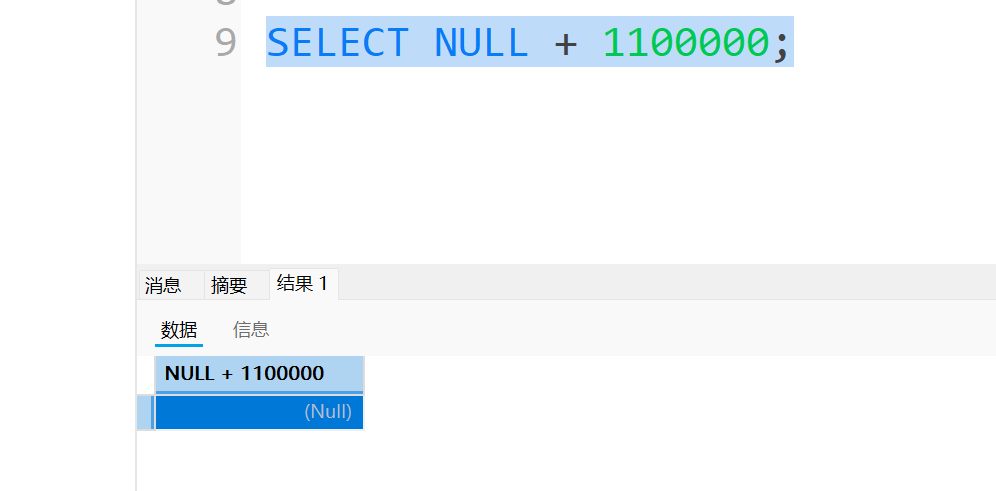
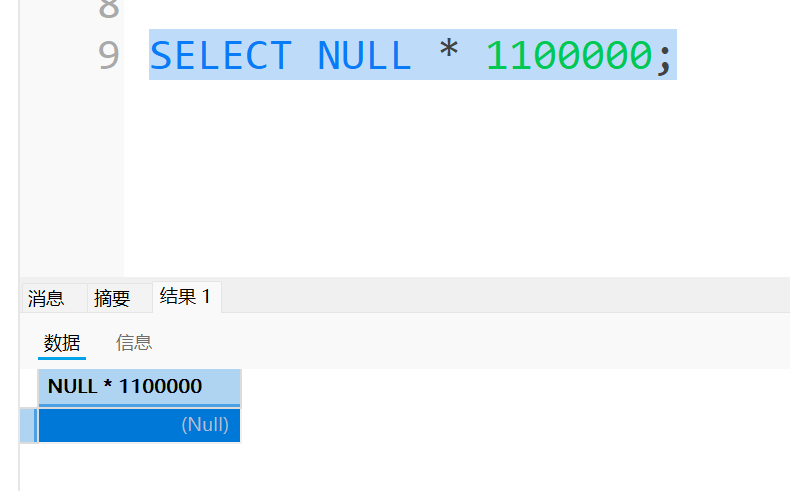
这时候计算总分时就存在了一个问题,正常应该是计算这个同学考的两科的成绩之和,但是现在计算出她的总分是NULL,这是不满足实际应用场景的
因此,在计算总分时,要用条件把那些成绩包含NULL的给筛出去,后面单独算他们的分数,
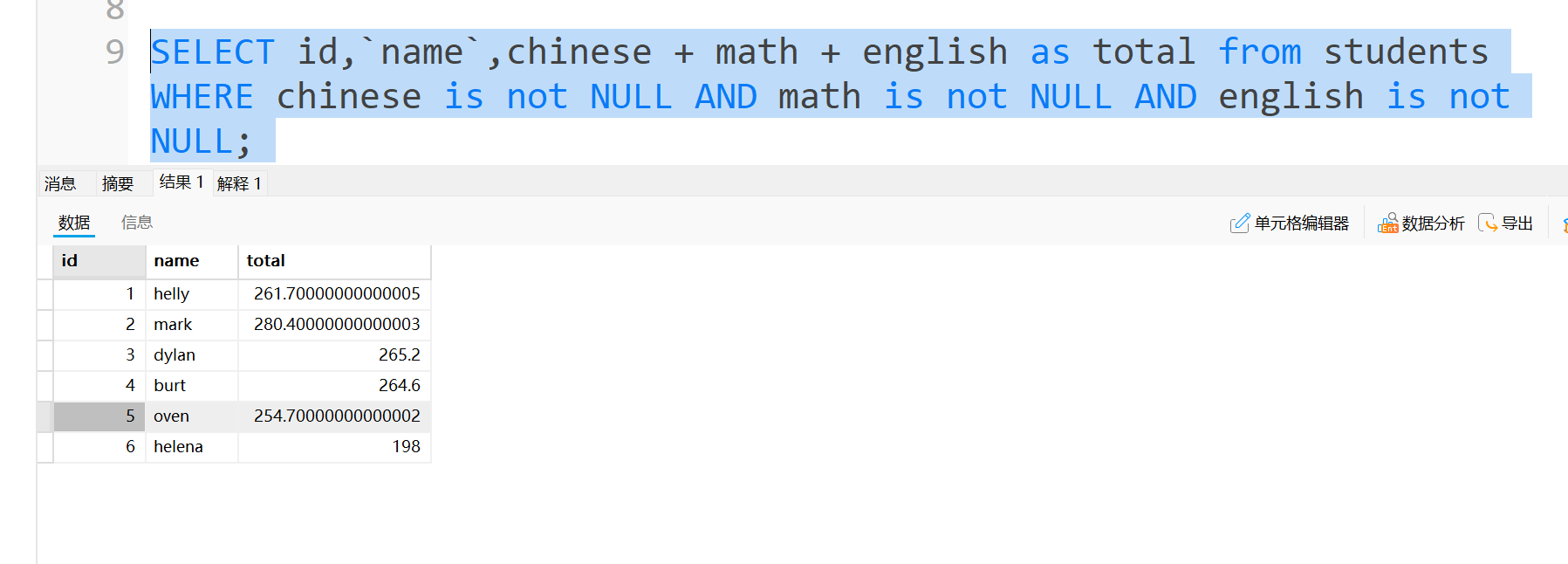
那有的铁汁就说了,那这里能不能用刚刚说的<>作为不等号来判断呢?
不可以
只有<=>可以判断跟null是否相等,其他的= ,!=,<>都不能用于跟NULL的比较
因此,博主建议大家遇见跟NULL比较是否相等,就直接用is NULL,is not NULL这些,就不会出错
3,ORDER BY 排序
对表中数据的排序是我们拿到数据后很重要的一项操作(语法如下)

在排序时后面加上一个order by,写上要对哪一列进行排序,以及采用升序排序还是降序排序,这里的升序时ASC,降序是DESC
例如拿学生表,以英语成绩降序来排序:
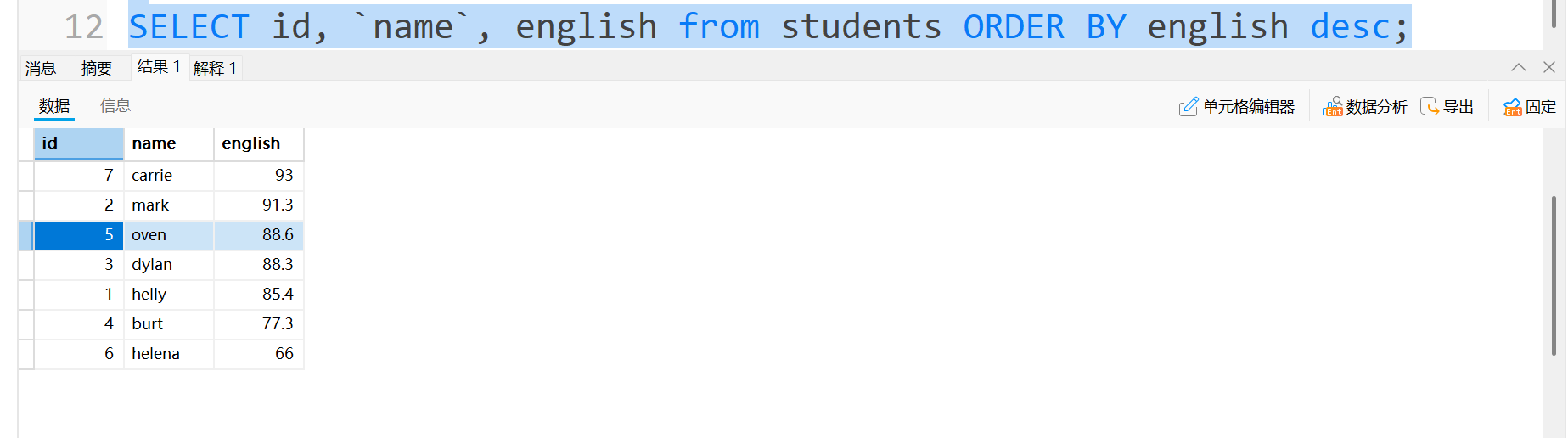
上篇博客中提到desc是用于查看表的结构的(下面是上篇博客的截图) ,那怎么到这里又成了降序的意思呢
这个可能就是SQL语言在设计上的一个小问题,但是这个关键字的两个使用场景相差比较大,就算初学,一看也知道它是什么意思,所以一般也不会造成歧义
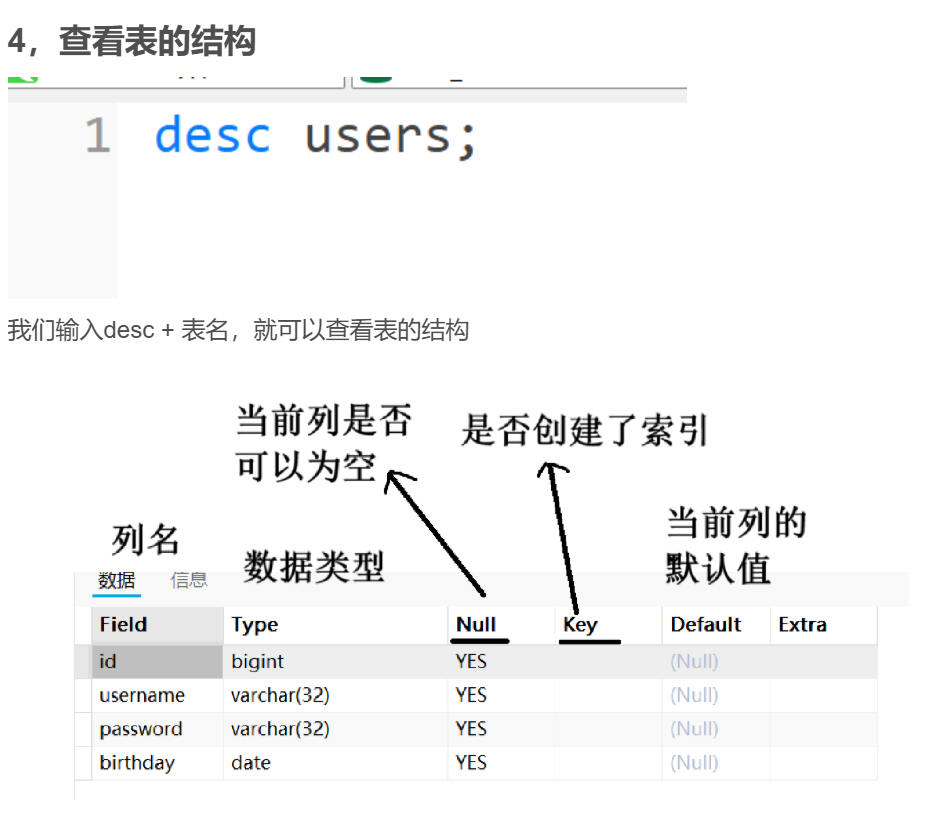
那如果排列时遇到NULL值是怎么排的呢?
我们看下,NULL其实就是看作最小的数据,我们用升序来排的话,它就在第一位,用降序来排,它就在最后(如下图)
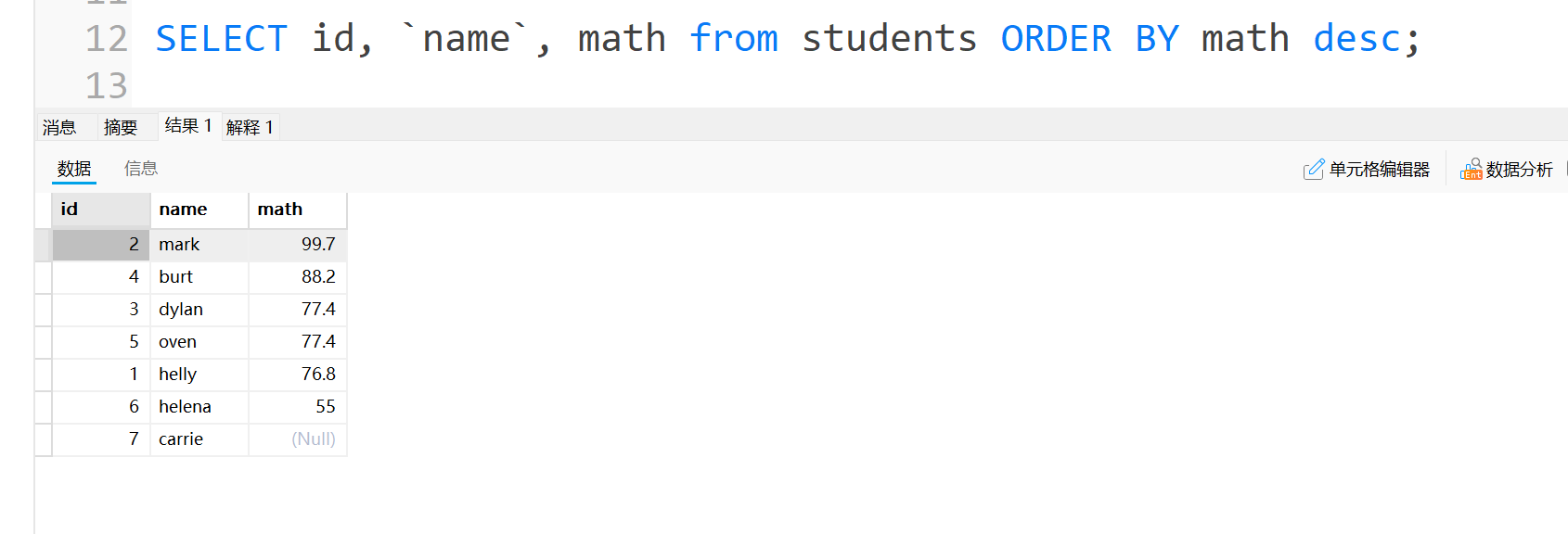
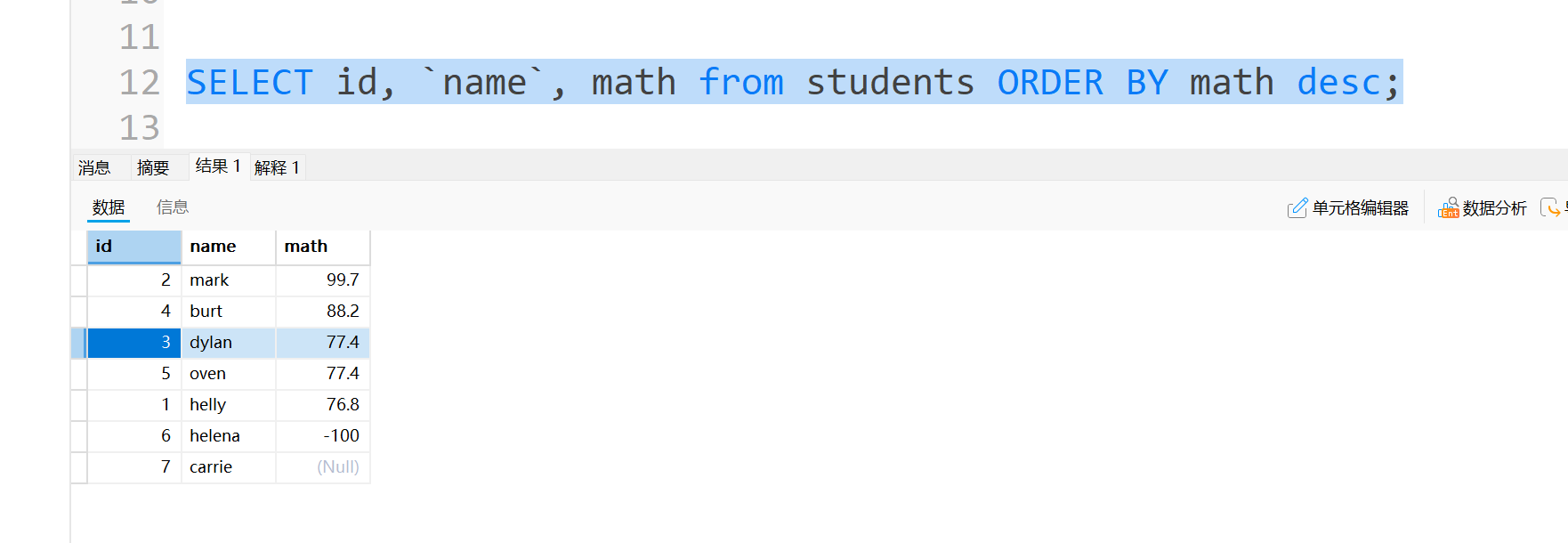
这里就算把成绩改成负的,NULL依然在最后,因此我们只需要记得,NULL代表的就是最小的数据。
如果写了order by,但是不写排序规则,那默认就是按升序排序。
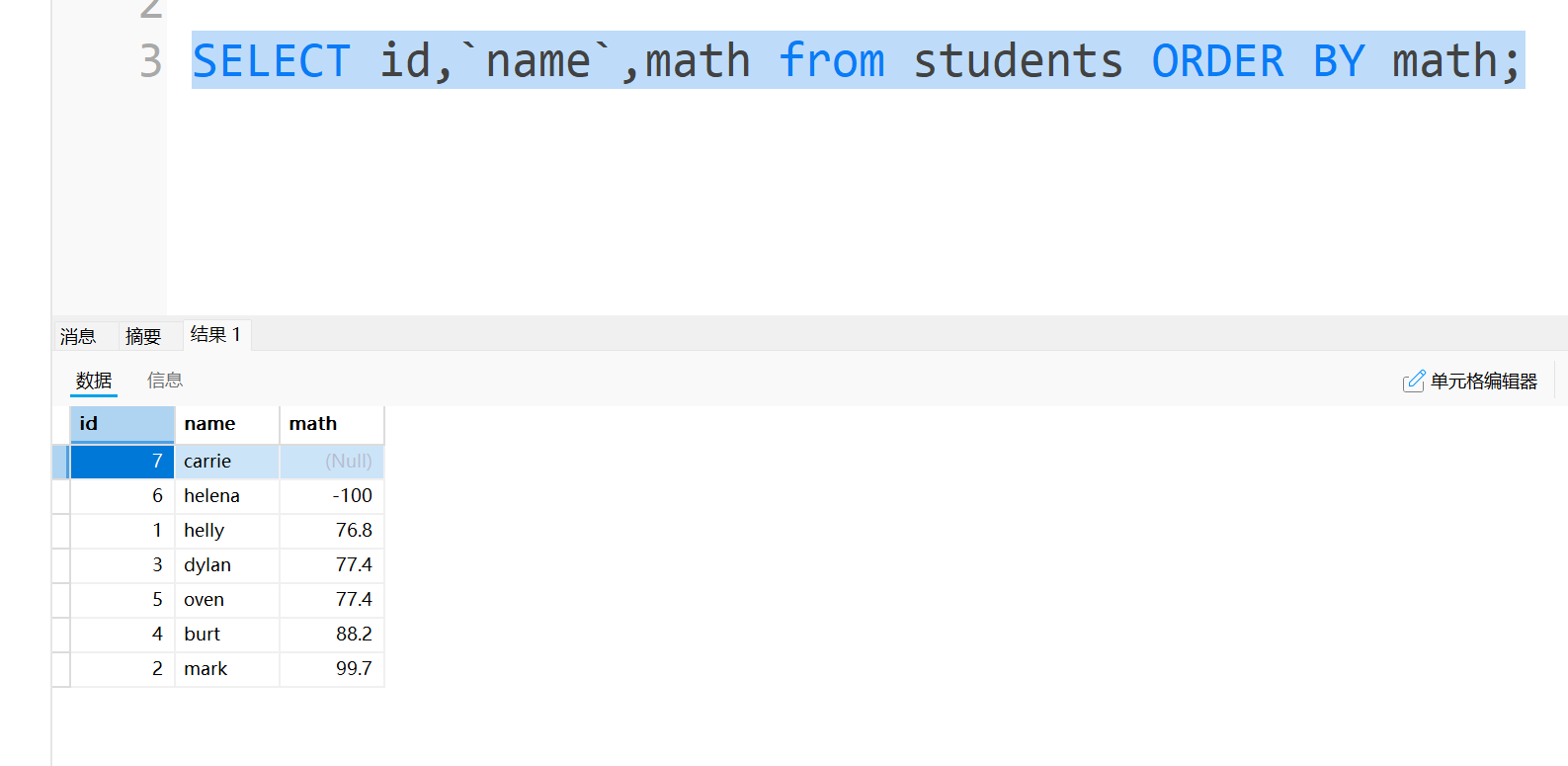
前面提到,在进行条件查询时,是不能用别名放在Where后面进行条件查询的,因为进行条件查询时还没有执行定义别名的select关键字
但是看排序的时候是可以这样的,这是为什么呢???
铁汁们可以细品一下,排序的话不需要过滤出什么数据,因此是在select后执行的,排序是先按照条件进行查询,再对查询的进行排序
这里的执行顺序是:from - where - select - order by
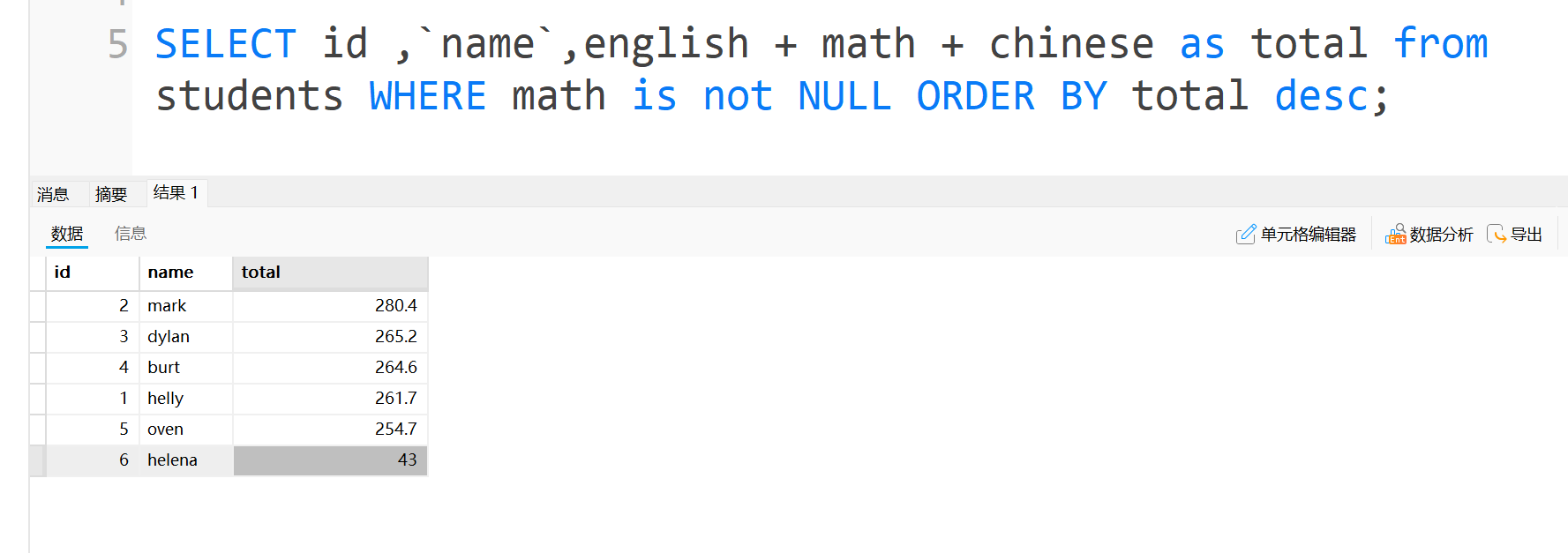
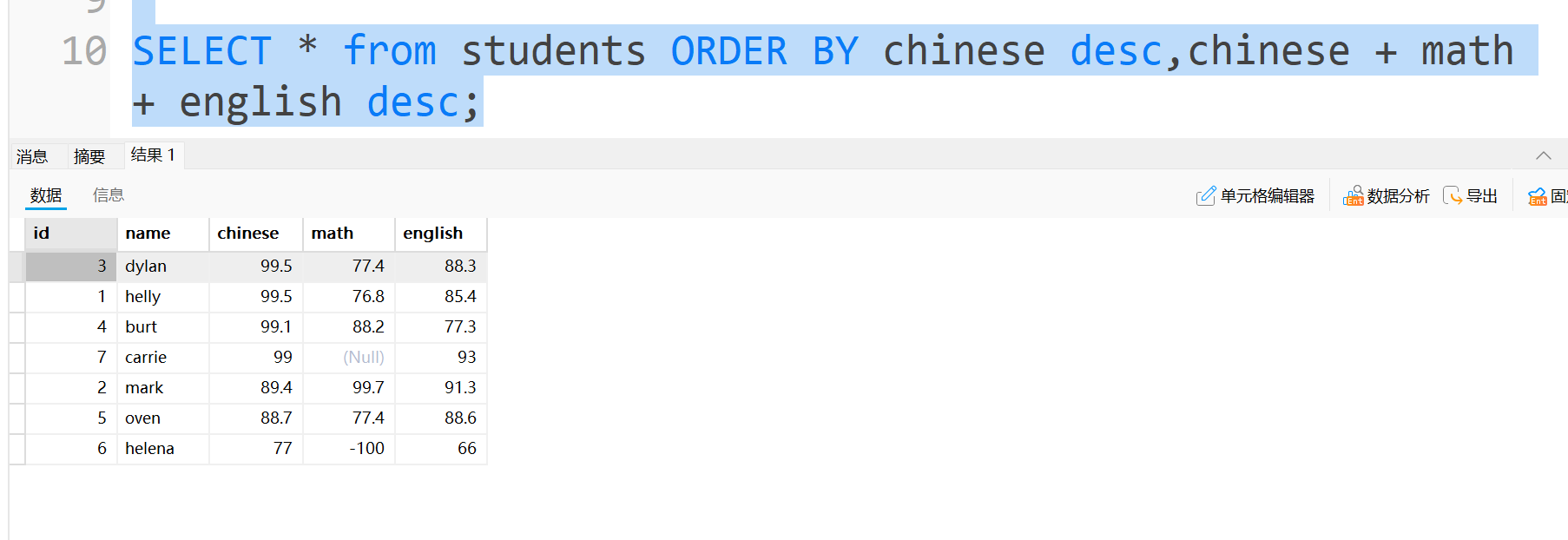
我们如果是一个老师,在考试完后,想看语文从高到底的排序,如果两个人的语文成绩相等的话,那怎么分先后呢?
可以按照谁的总分好谁就靠前
这里写代码时,chinese写在前面,总分写在后面,排序时只有chinese相同时才会比较后面的总分,chinese不同后面的比较是不会执行的示例如下:dylan和helly的语文成绩相同,但是dylan的总分高,因此dylan的排名就比较靠前
4,分页查询
这里在浏览器上搜索一个问界M7,我们会发现搜索出的数据并不是一下子全部展现出来了
而是下面分成了一页一页,每页中放有一定量的数据,这个就是分页查询。
那分页查询有什么好处呢?
首先就是可能让界面看起来更加美观了,如果我们搜一个东西,搜到了几千条结果,全部堆在一个页面上,那肯定是不太美观的。
另外,那就是能够有效降低服务器崩溃的风险。如果我们搜索一个东西,一下子查到了成千上万条的有关数据,全显示在页面上,那服务器需要处理这么多数据,是很容易崩溃的。
分页查询就有了一个显著的好处:一次只查询很少的数据,如果觉得这些信息不够,再点击下一页,看更多的信息,这样就可以控制一次查询的数据数量,速度又快,又减少了服务器的压力。因此这种分页查询在实际开发中被广泛的使用
下面是在数据库这个界面下控制每次查询的数据个数的语法,start表示从哪行往后开始,num表示要查询几行的数据。
这是表中所有的数据

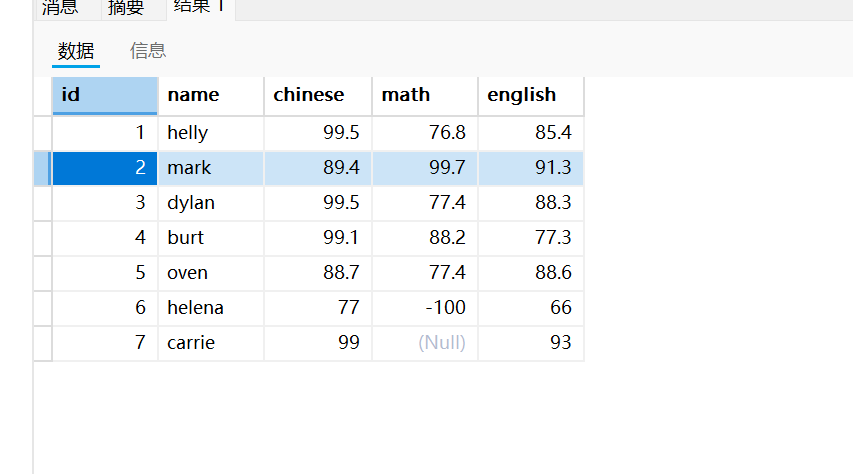
使用LIMITE关键字,就是对查询的限制
LIMITE后面有两个参数,这里写1,2的意思就是,查询第一行往后的两行数据
注意:这里是不包括第一行的
sql
SELECT * from students LIMIT 1,2;那么查询结果就是第二行和第三行。
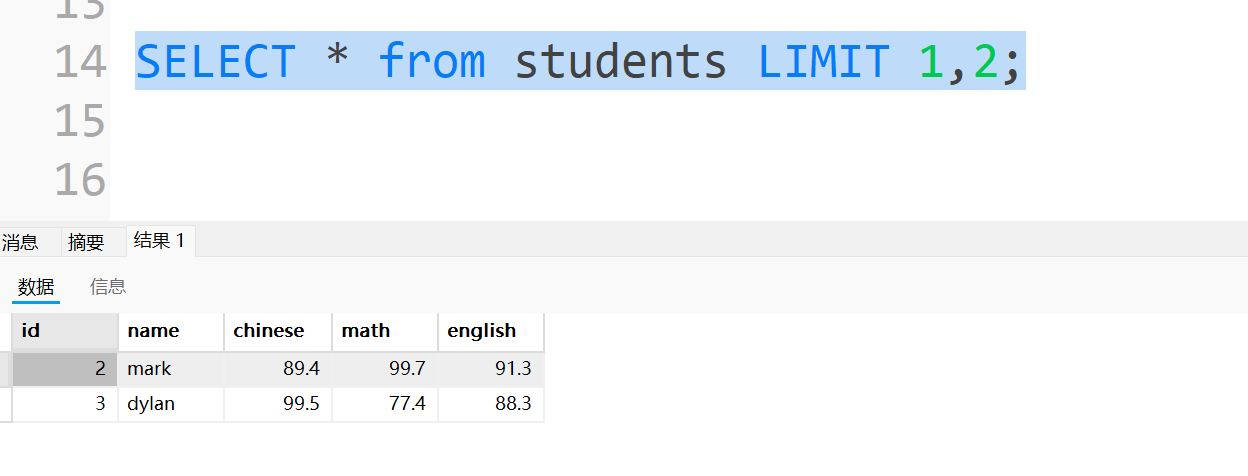
还有另一种查询方法,start写在后面,前面是要查询的行数,中间用一个OFFSET连接,我们一般不用这个写,但是其他人这么写我们要知道是什么意思:
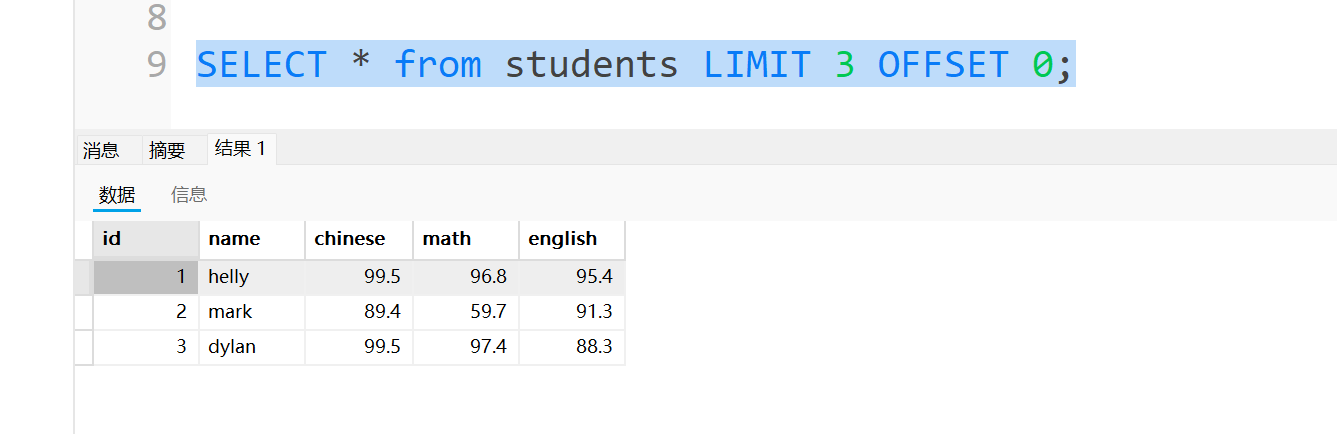
这里要是查询的不小心超过范围会不会像数组那样报错呢?
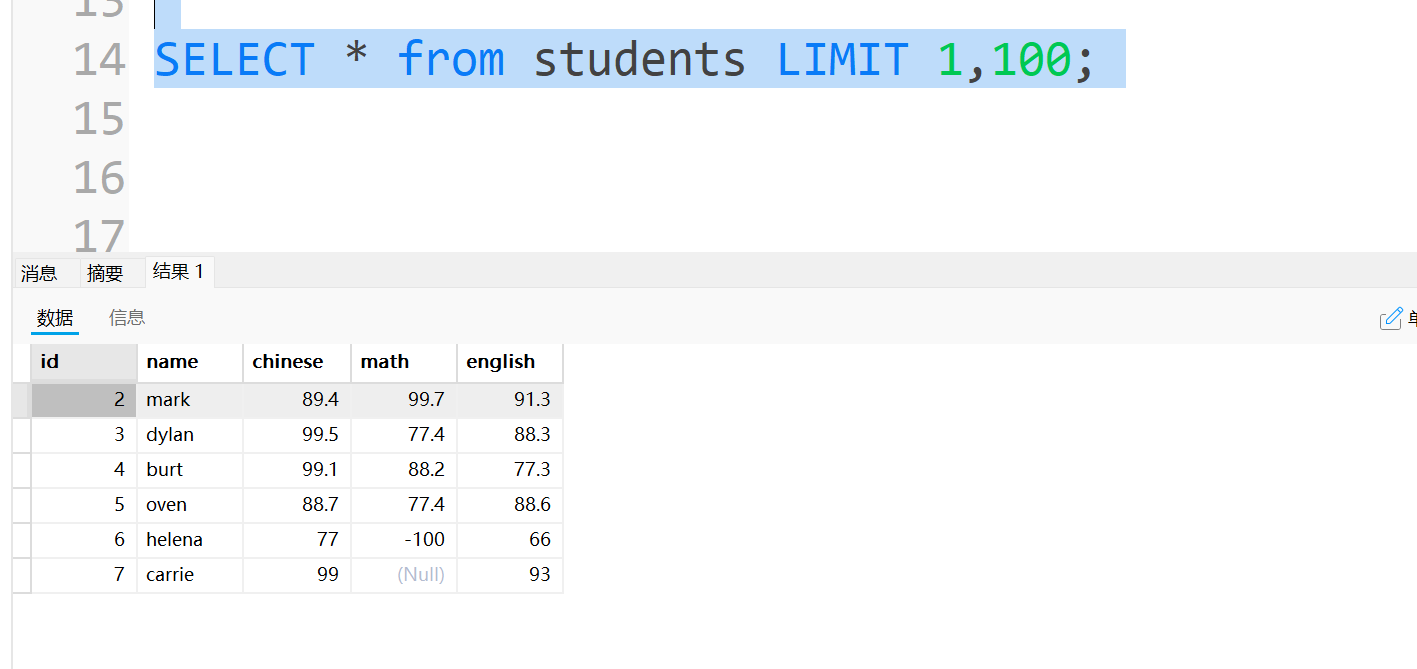
可以试一下,查询第一行往后的100个数据,发现并不会报错,只是能查到多少就查多少
注意,查询是完全按照行的,给id这些列名什么没有一点关系
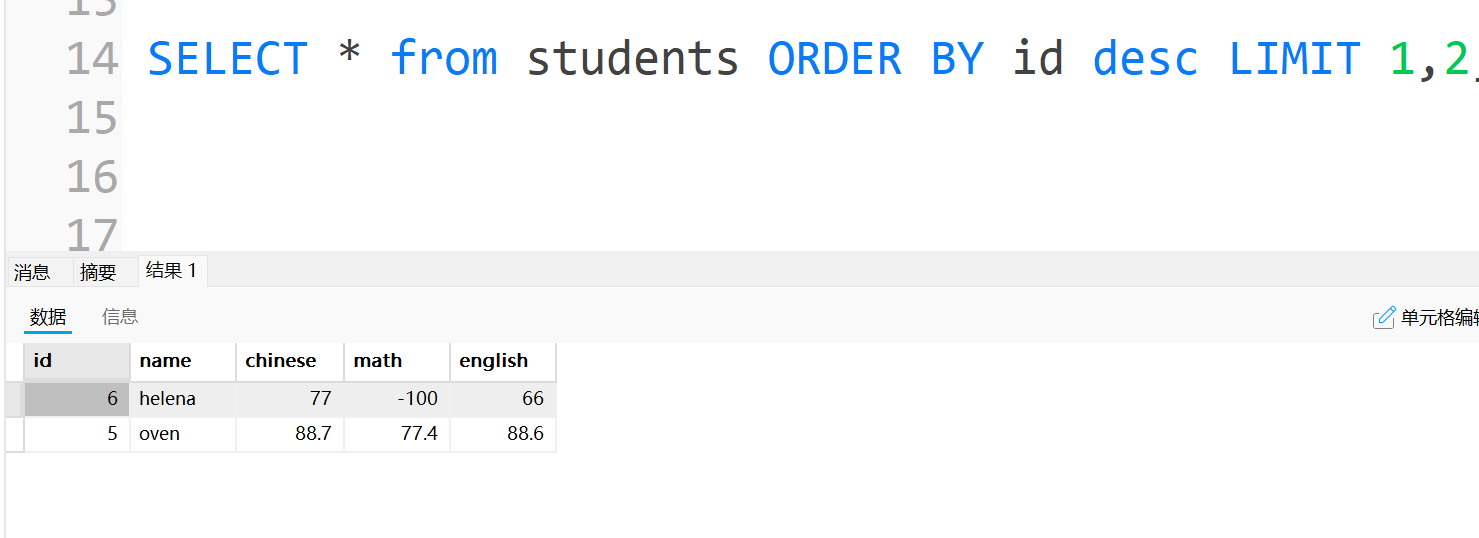
当然,也可以先排序,再进行查询,比如这里先将id从大到小进行排序:
现在在数据库中还没办法去达到网页的那种选页效果,但是铁汁们可以想下计算页数的公式:
总页数 = 数据库中数据的总条数 / 每页要显示的记录数 (有余数就加1)例如查到了100条数据,每页显示19条,最后还多出来了5条数据,那这5条数据就会新开一页,这一页只放5条数据
那怎么根据页号来计算start(从第几行往后的数据)的值呢?
这里就有个公式:
start = (当前页号 - 1) * 每页显示的记录数
例如想每页记录三行数据,第一页的页号是1,套入公式start就是0,如下:
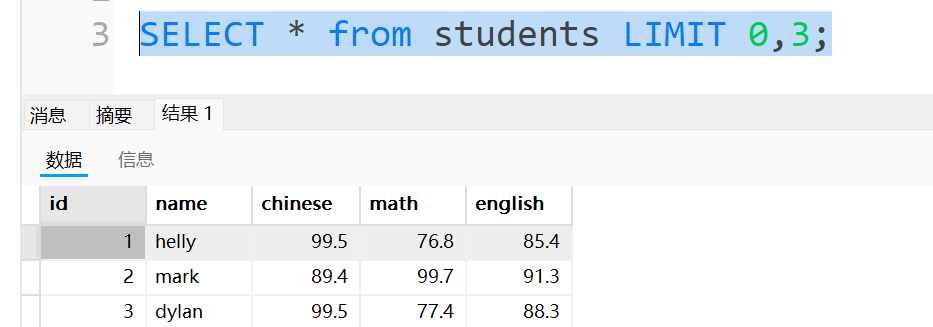
第二页页号是2,套入公式后start就是3
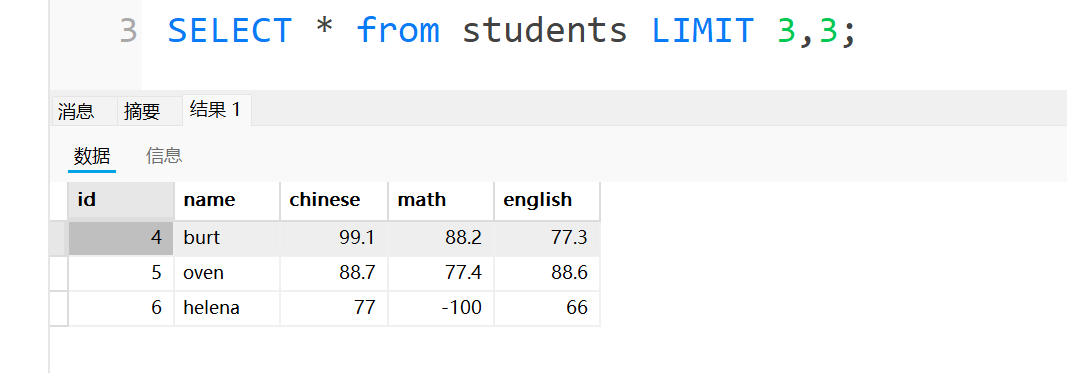
最后再补充一个东西,这样写的话就是查询数据的前5行,前面默认省掉了一个0这个一会要在update修改操作中搭配在一起使用,因为update与limit结合只支持我们这样写封的单参数,不支持双参数
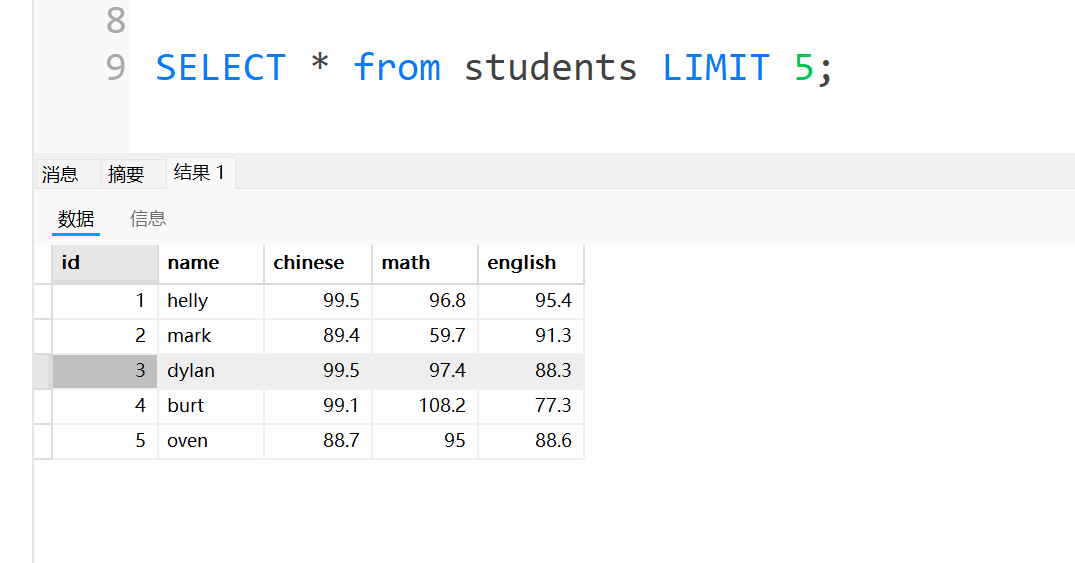
4,Update修改
Update修改就是针对表中的一些数据进行修改。
语法:
Update 表名 set 列名 = 值 Where + 条件
前面为了看NULL和负数在排序时的大小顺序,把helena的数学成绩设为了-100,现在我们就可以把它改成正数
选择要修改的表,再选择要修改那一列里面的数据,最后选择修改这列的哪个数据
这里就把helena的数学成绩改为了90,示例如下:
sql
UPDATE students set math = 90 WHERE `name` = 'helena';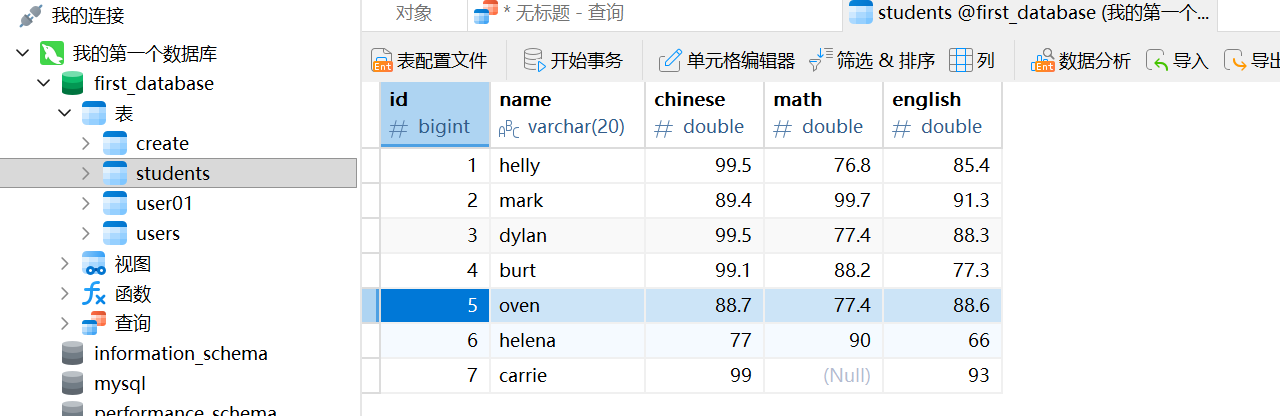
如果有两个人重名了,只想修改一个人的成绩,那应该怎么办呢?
答案就是把Where后面的条件换成别的,比如学号,不会重复的这种信息。
铁汁们可能会觉得这个修改操作很简单
但是修改操作存在一个巨大的风险,当修改数据忘记写WHERE的时候,就像下面这样,可以猜一下运行会发生什么:
sql
UPDATE students set math = 90; 没错,会把这列所有的数据都改为90😂😅
当我们一个表很大时,我们不小心进行了一个这样的操作,就会比较麻烦
比如设计电动汽车充电系统,一个人充了100电费,如果程序员不小心把所有人的电费余额都加了100,那就有点炸缸了
在sql语言中是不支持"+= -="这样写的,这里试下使用+=修改把helly的英语成绩加10分,发现是会报错的
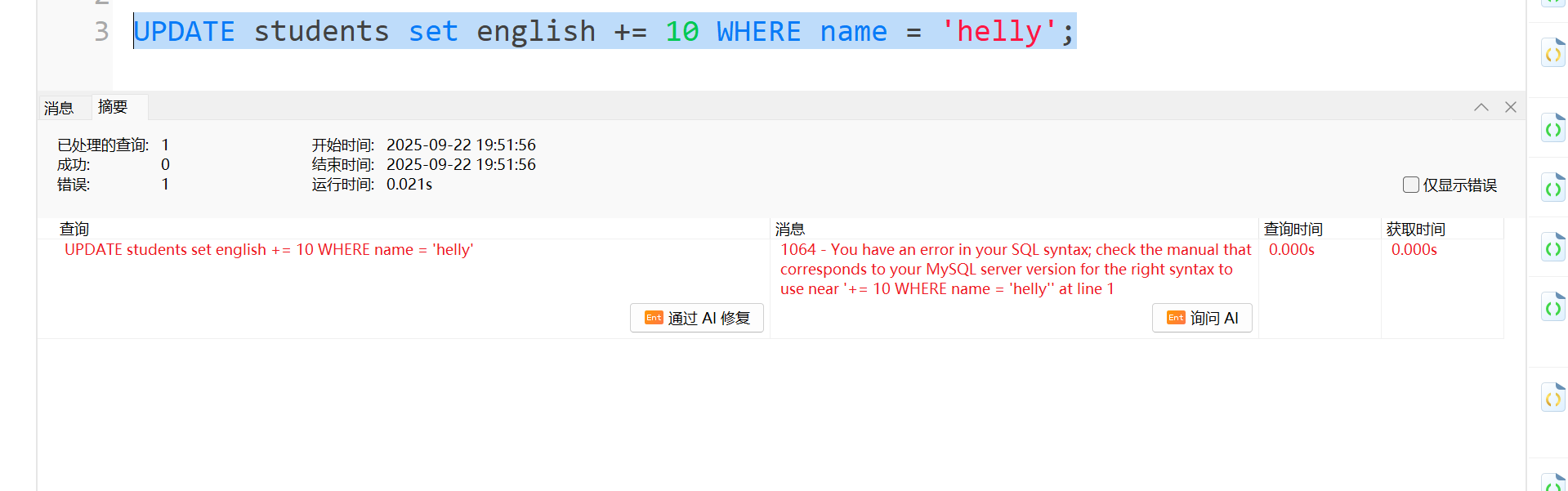
要使用这种不能省略的写法:
sql
UPDATE students set english = english + 10 WHERE name = 'helly';接下来就把检索和修改结合起来练习一下:
要求将排名倒数后三位的学生总成绩加上20分,倒数后三位的学生不包括考试缺考的(也就是有一门成绩为NULL的)
先来分析下,这个需求需要结合Where条件查询,ORDER BY排序,以及Update修改,单参数limit限制前面提到,update只支持单参数的limit,就是体现在这里。
大家可以写试一下,代码如下:
sql
UPDATE students set math = math - 20 where chinese + math + english is not
NULL order by chinese + math + english asc limit 3;也可以扩展讨论一下,这些关键字执行的顺序是什么
WHERE(筛选) → ORDER BY(排序) → LIMIT(限制数量) → SET(执行更改)
先筛选出总分不为空的数据,再进行排序,取前3个,最后进行数学成绩更改操作。
5,Delete删除
跟修改一样,删除也是一个比较危险的操作
看下面的语法,后面也要加一堆条件去限制,手抖一下,可能就把整个表给删了。

还是拿前面的成绩表为例,删除helena的数据,原表如下:
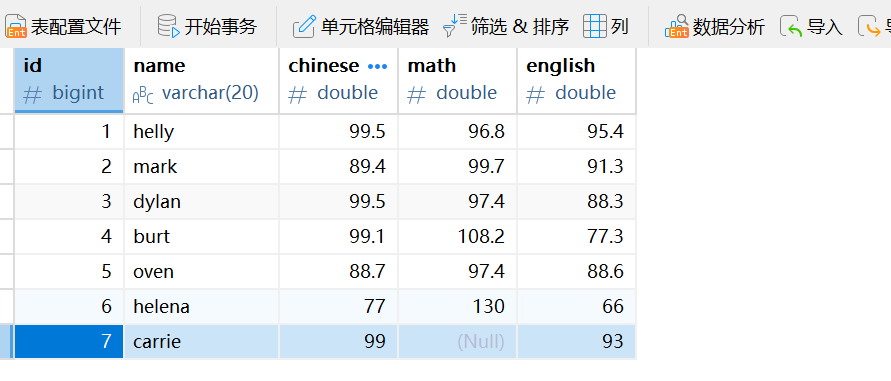
运行下面的删除语句,刷新一下表格,就发现已经删除成功了。
sql
delete from students WHERE name = 'helena';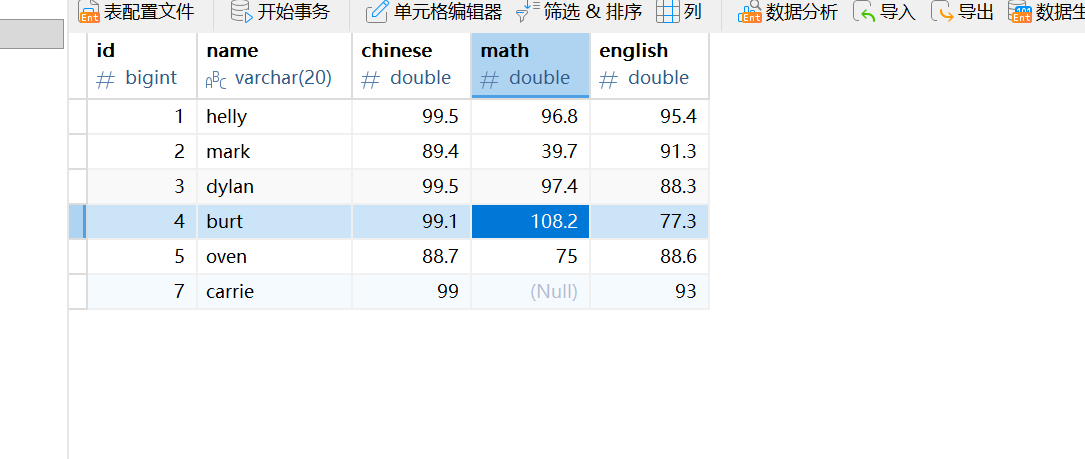
如果忘了加WHERE的话,就会把整个表都删了😅
那如何避免不小心把整个表删了呢?答案就是不进行删除操作
牺牲数据库中的一点点空间,再创建一个列deleteState,里面的值不是0就是1,0代表这行的数据还需要,1代表这行的数据已经删除,不需要了(实际上并没有删)
在删除时只改这一列,那即使删错了也没事,反正数据还在,删错了把1改为0就行了,后续在操作数据时,可以加个where,只操作这列为1的数据