1、运行CUDA示例
1.1 下载官方源码
c++
git clone https://github.com/NVIDIA/cuda-samples.git1.2 开发环境选择原则
1.2.1 Ubuntu系统
一般都选择vscode客户端,在vscode客户端中配置好cmake和c++扩展
1.2.2 Windows系统
如果是做客户端方向带GUI开发的,一般选择Visual Studio。我的主机配置是VS2022+QT5.15,QT作为VS的插件(当然也可用QT客户端,用VS的MSVC编译器编译)。用CMake的GUI或者直接用vscode来构建Visual Studio工程。
如果偏向服务端开发,封装一些算法库或者后台运行的程序,直接用vscode就可以完成,非常方便。
1.3 验证环境
下载好源码后,直接编译运行官方给的示例,确保环境是正常的再做更深入的工作。这里只做一个简单的验证,直接用vscode。
用vscode打开前面下载的cuda-samples-master工程,运行asyncAPI示例,依次执行下面指令:
c++
cd cd .\Samples\0_Introduction\asyncAPI\
mkdir build
cd build
cmake ..
cmake --build .报错如下:
c++
Unsupported gpu architecture 'compute_110'
C:\Program Files\Microsoft Visual Studio\2022\Community\MSBuild\Microsoft\VC\v170\BuildCustomizations\CUDA 12.8.targets(800,9): error MSB3721: 命令""C:\Program Files\NVIDIA GPU Computing Too
lkit\CUDA\v12.8\bin\nvcc.exe" --use-local-env -ccbin "C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.44.35207\bin\HostX64\x64" -x cu -rdc=true -I"C:\My_Project\
src\cuda-samples-master\Samples\0_Introduction\asyncAPI\..\..\..\Common" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\include" --keep-dir asyncAPI\x64\Debug -maxrregcou
nt=0 --machine 64 --compile -cudart static -Wno-deprecated-gpu-targets -lineinfo -std=c++17 --generate-code=arch=compute_75,code=[compute_75,sm_75] --generate-code=arch=compute_80,code=
[compute_80,sm_80] --generate-code=arch=compute_86,code=[compute_86,sm_86] --generate-code=arch=compute_87,code=[compute_87,sm_87] --generate-code=arch=compute_89,code=[compute_89,sm_89] -
-generate-code=arch=compute_90,code=[compute_90,sm_90] --generate-code=arch=compute_100,code=[compute_100,sm_100] --generate-code=arch=compute_110,code=[compute_110,sm_110] --generate-code
=arch=compute_120,code=[compute_120,sm_120] --extended-lambda -Xcompiler="/EHsc -Zi -Ob0" -g -D_WINDOWS -D"CMAKE_INTDIR=\"Debug\"" -D_MBCS -D"CMAKE_INTDIR=\"Debug\"" -Xcompiler "/EHsc /W1
/nologo /Od /FS /Zi /RTC1 /MDd " -Xcompiler "/FdasyncAPI.dir\Debug\vc143.pdb" -o asyncAPI.dir\Debug\asyncAPI.obj "C:\My_Project\src\cuda-samples-master\Samples\0_Introduction\asyncAPI\asy
ncAPI.cu""已退出,返回代码为 1。 [C:\My_Project\src\cuda-samples-master\Samples\0_Introduction\asyncAPI\build\asyncAPI.vcxproj]解决方法:
修改cmakelists.txt,删除掉不支持的gpu架构,如下图所示:
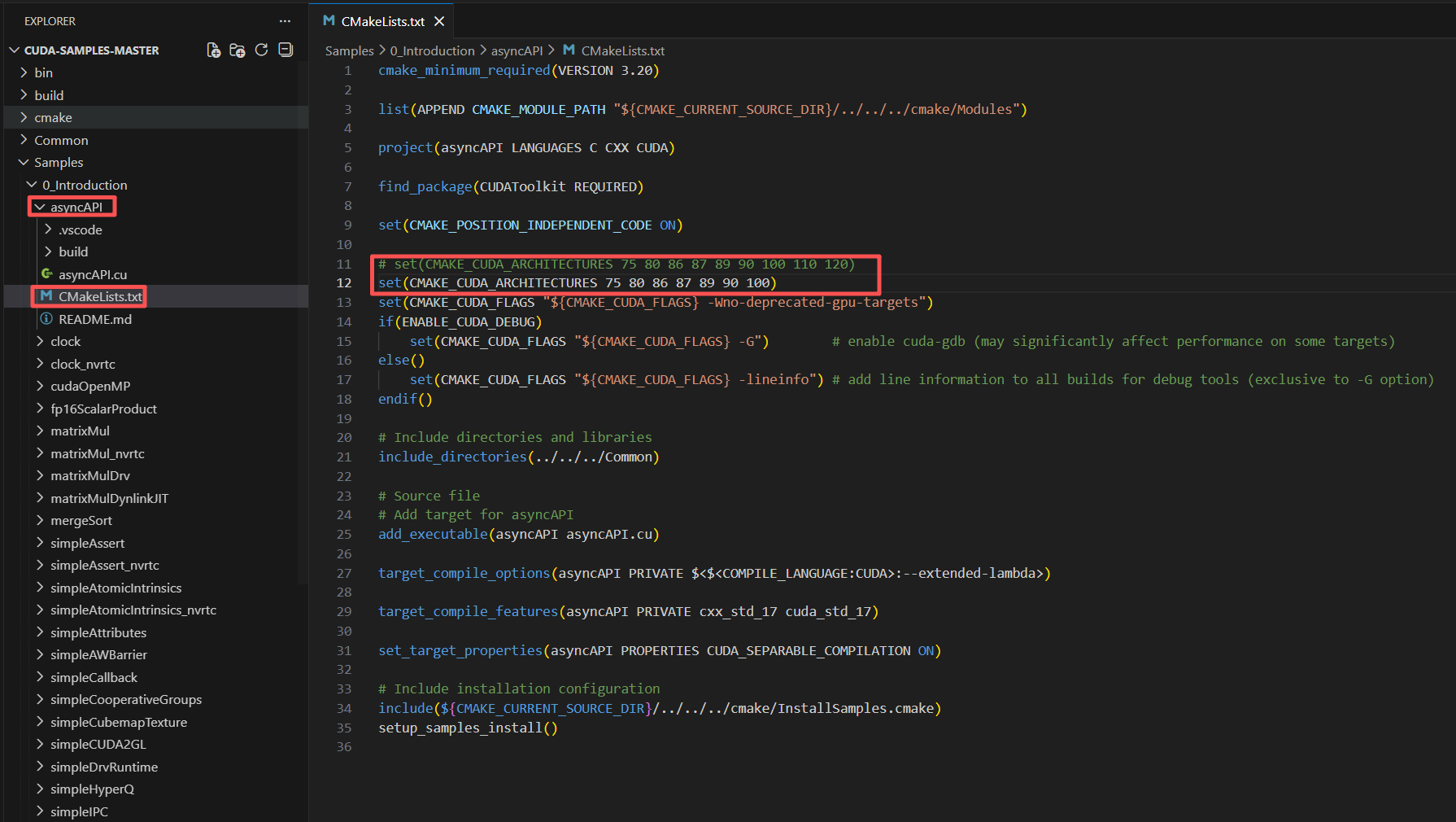
然后删除掉asyncAPI下的build文件夹,重新执行前面的构建编译流程,这次正常通过,然后进入build文件夹下Debug目录,执行生成
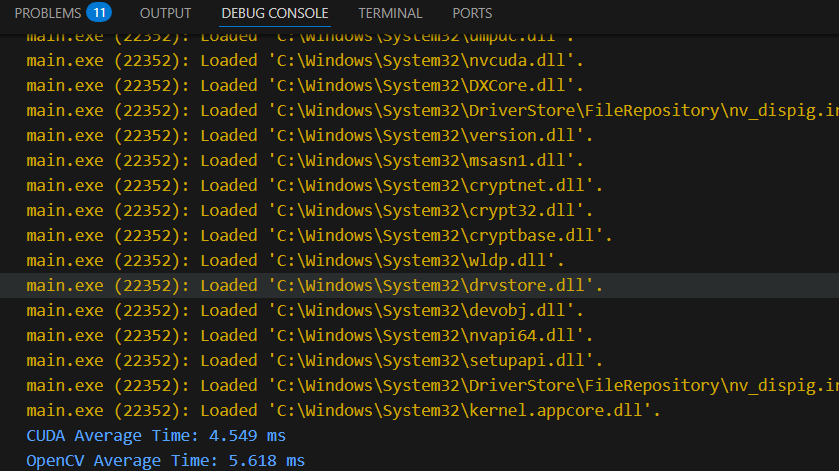
的可执行程序,如下图所示,能够正常运行,说明软硬件环境都是正常的。

2、用CMake构建带cuda的工程
https://github.com/CNugteren/CLBlast/blob/master/cmake/Modules/FindcuBLAS.cmake
在这里想结合OpenCV和CUDA实现简单的图像处理功能。
2.1 安装下载适合VS2022的OpenCV(vc17)
2.1.1 直接下载编译好的包(不采用)
这里下载Windows版4.8.0版本
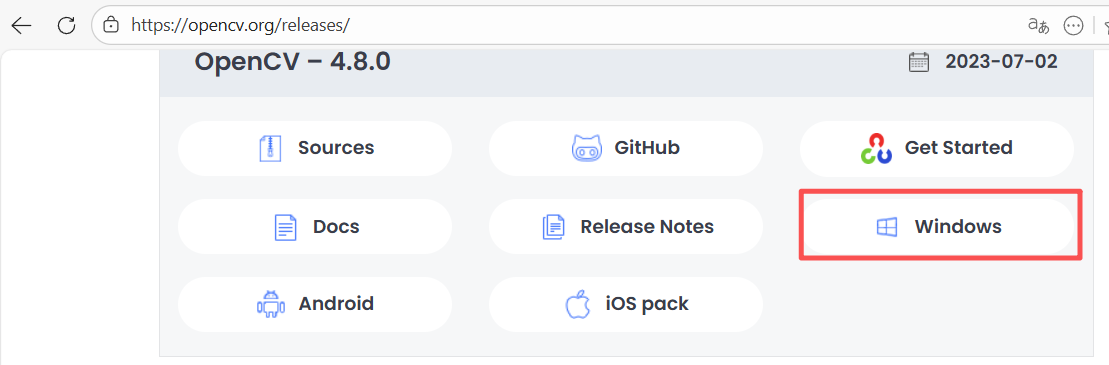
下载安装了windows版本4.8.0,发现build下x64里只有vc16并没有适配vs2022的v17,为了防止后续出现莫名其妙的问题,不采纳此方法,用源码编译。
2.1.2 源码编译opencv
这篇文章写的很详细:源码编译opencv
下载oencv和opencv_contrib
https://github.com/opencv/opencv/releases/tag/4.8.0
https://github.com/opencv/opencv_contrib/releases/tag/4.8.0下载好源码后,按照如下目录结构存放:
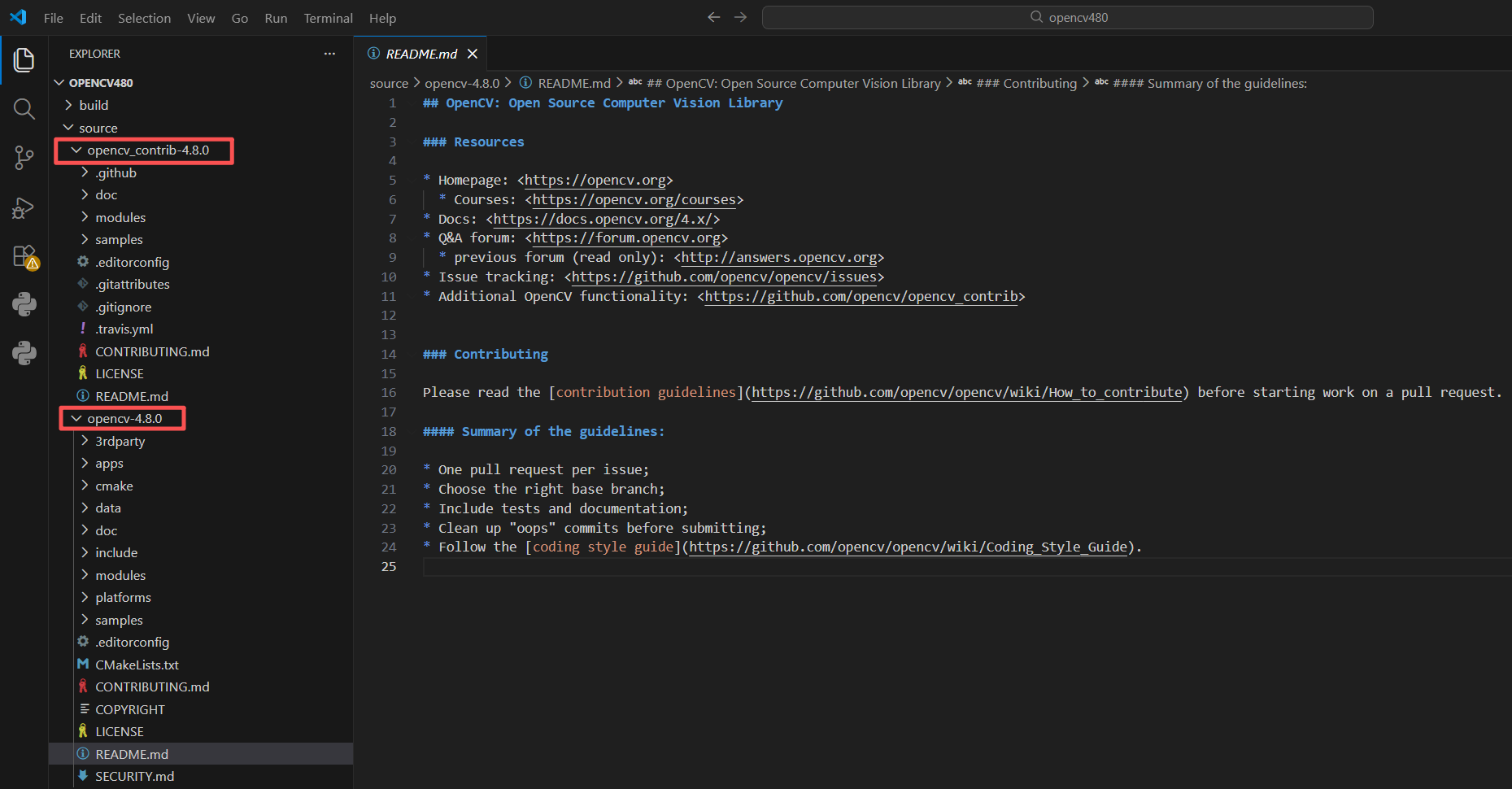
打开CMake的GUI客户端,按下图所示配置:
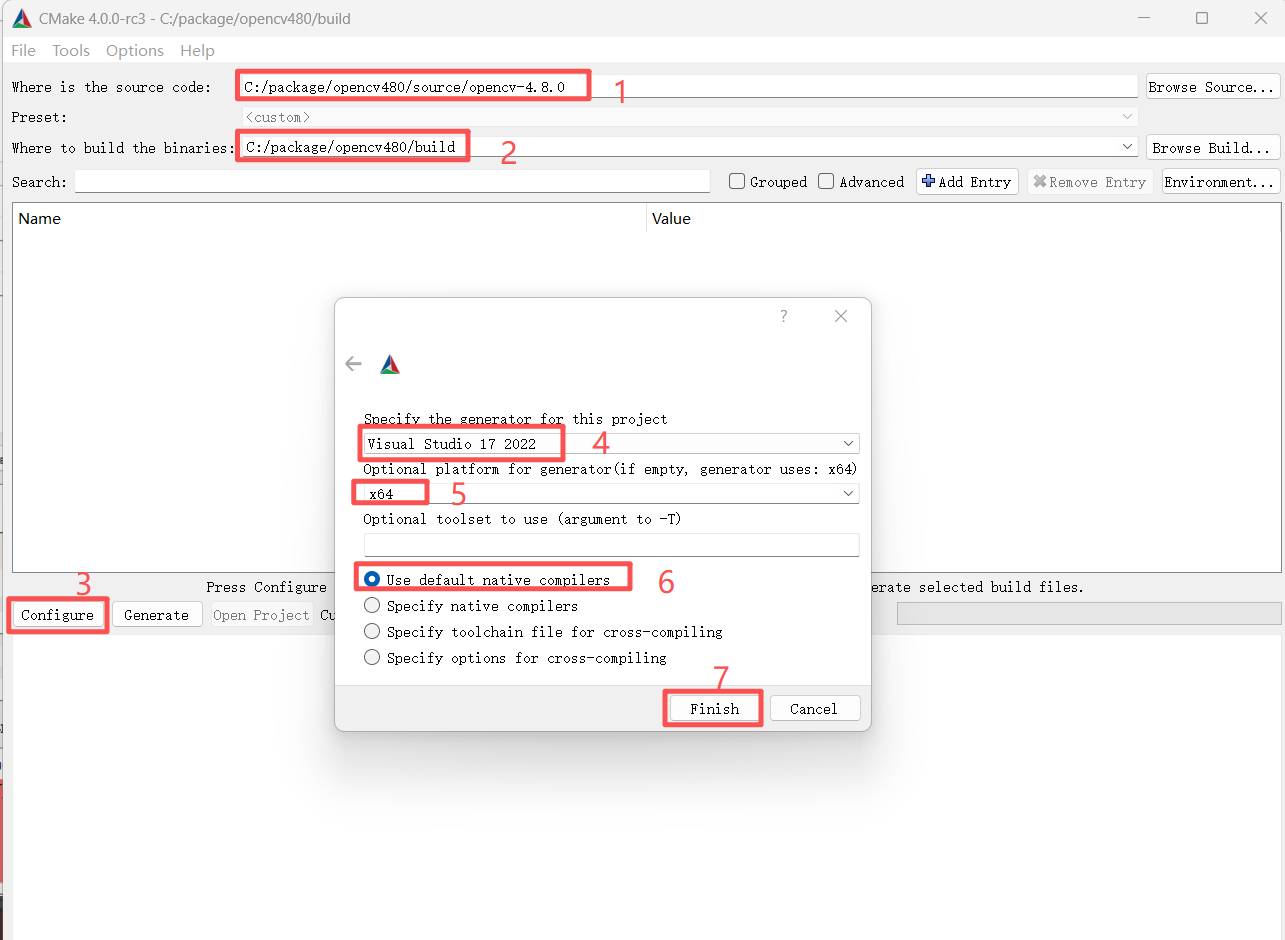
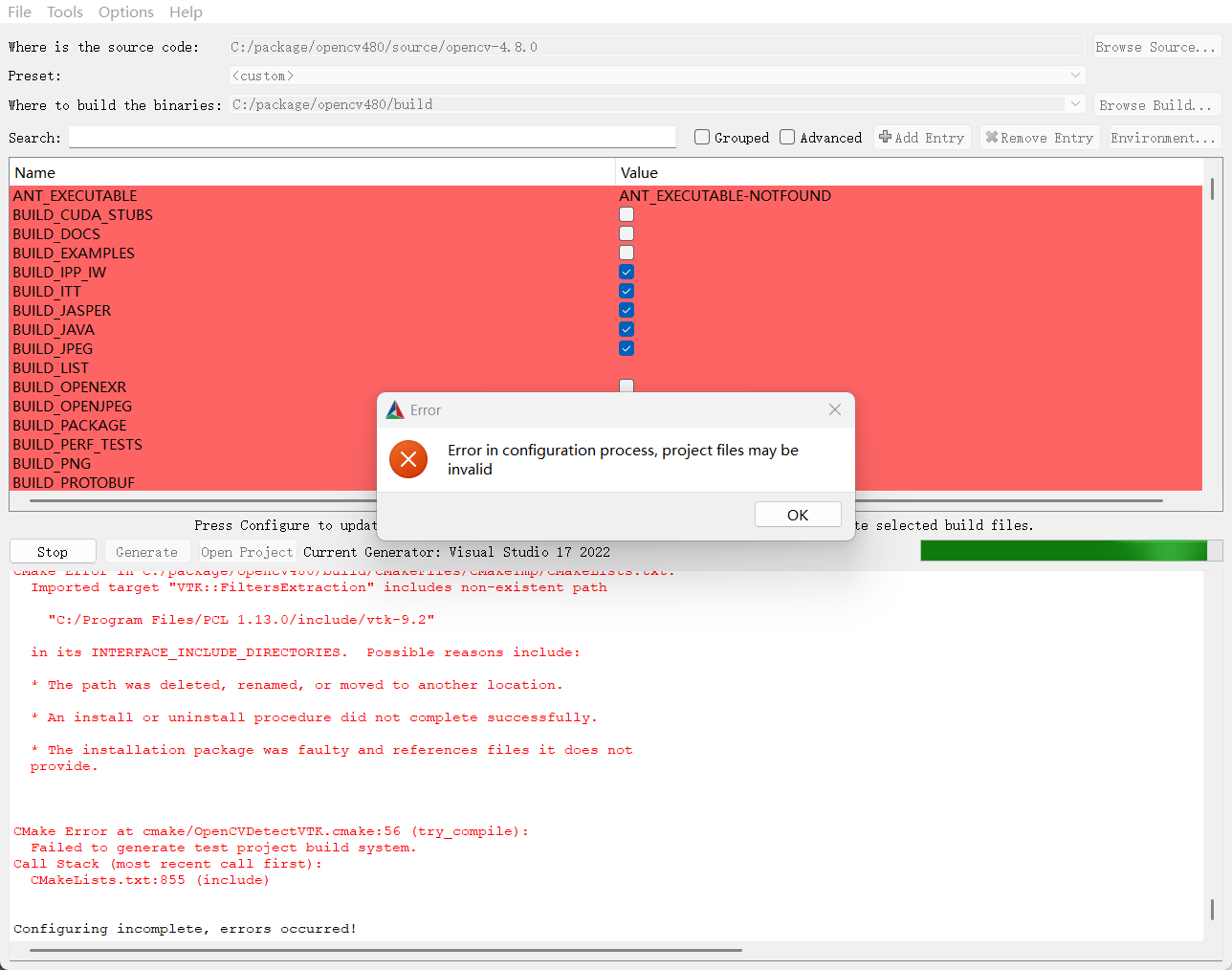
点击Finish报错如下:
配置contrib:
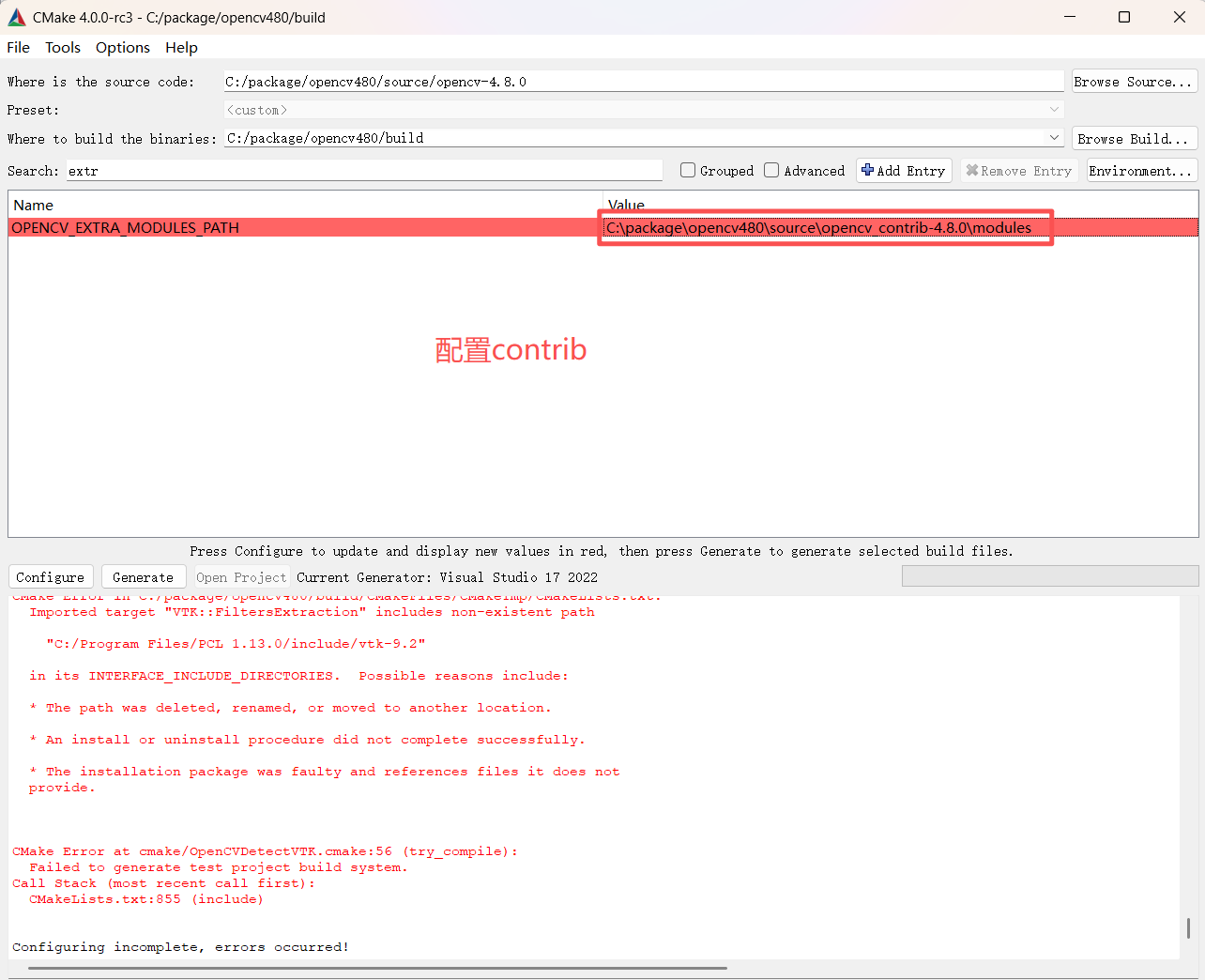
注意手动复制路径连接符一般是\,需要手动改成/,否则会报错,所以应该选择目录获取路径,或者手动修改上面配置如下图所示:

但是Configure仍是报错了,我这里报的VTK相关的错误,原因是我电脑里有VTK相关工具包,是我手动拷贝的,被opencv自动检测到了,实际编译并不需要VTK,关闭掉VTK相关编译项,重新CMake。
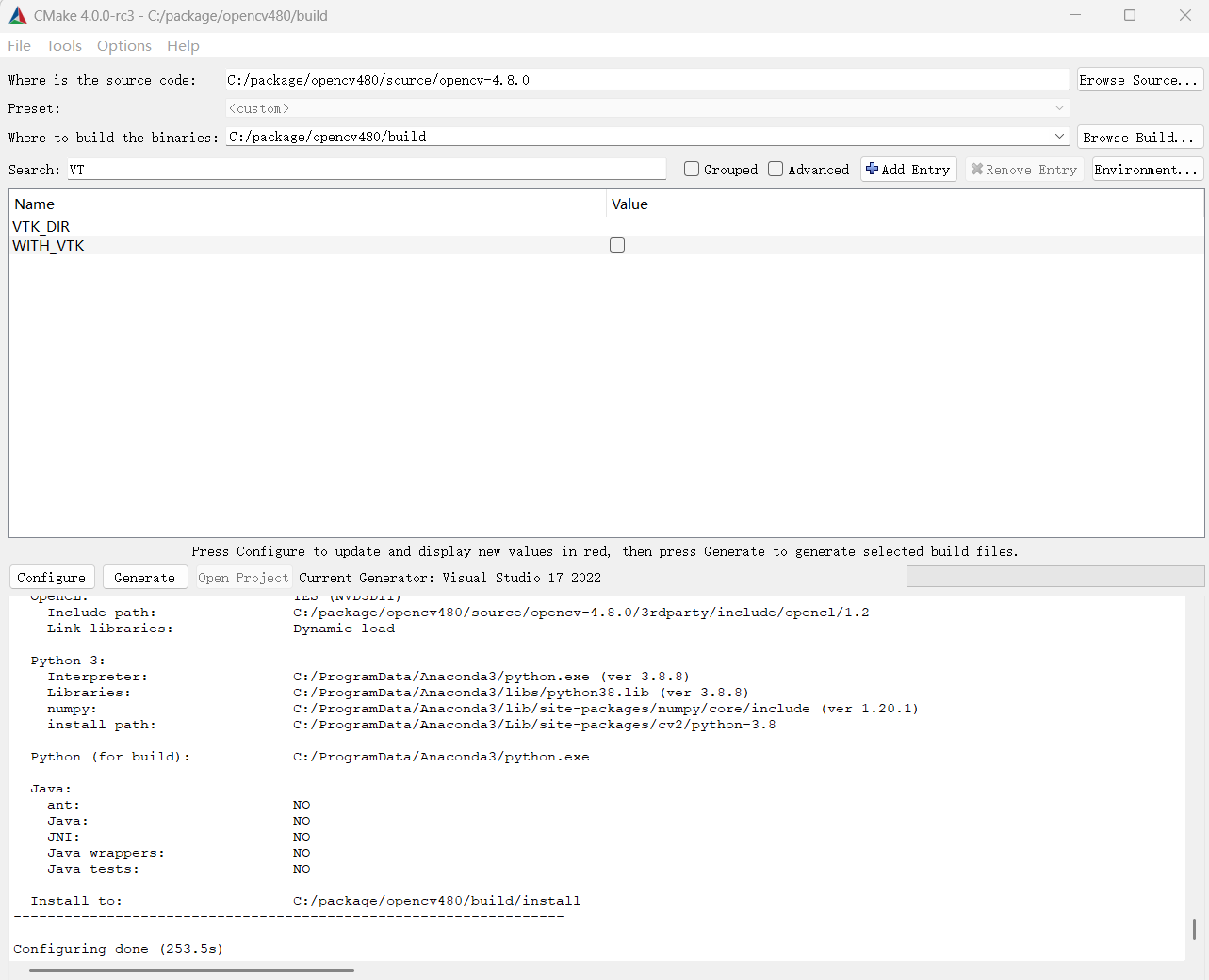
点击 Generate 生成代码到build目录下
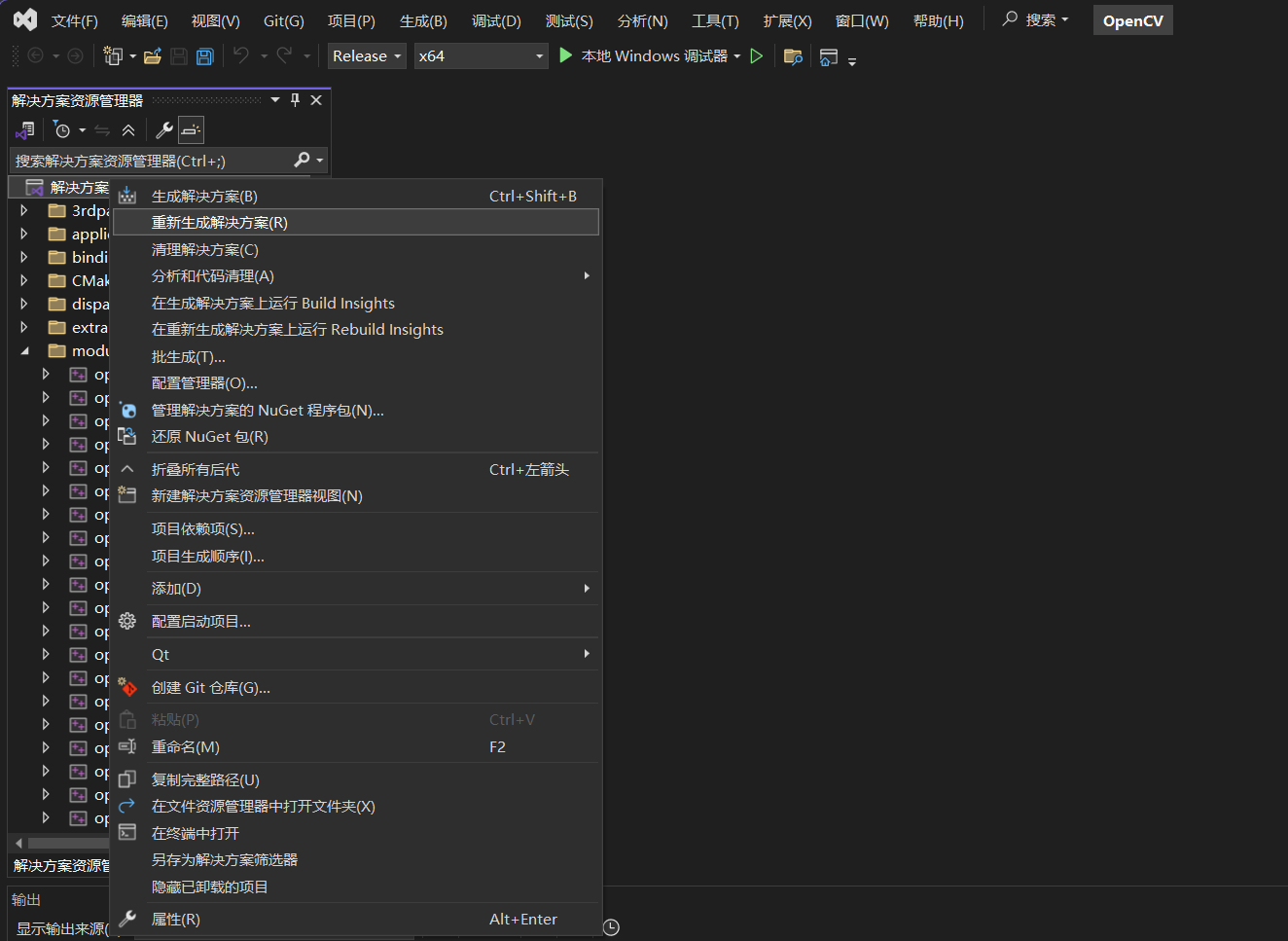
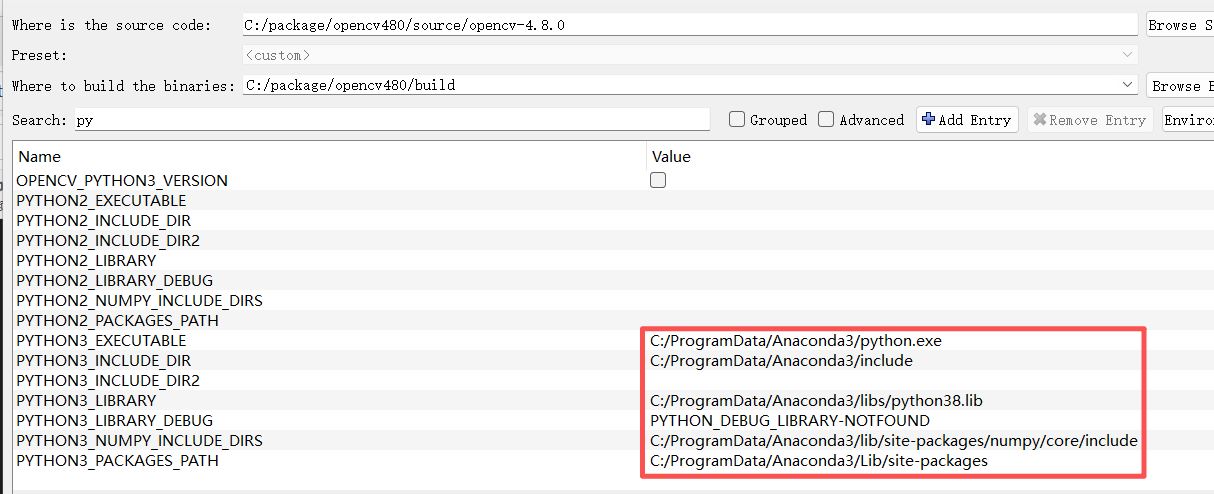
结果报了和python相关的错误,清除所有这些路径:
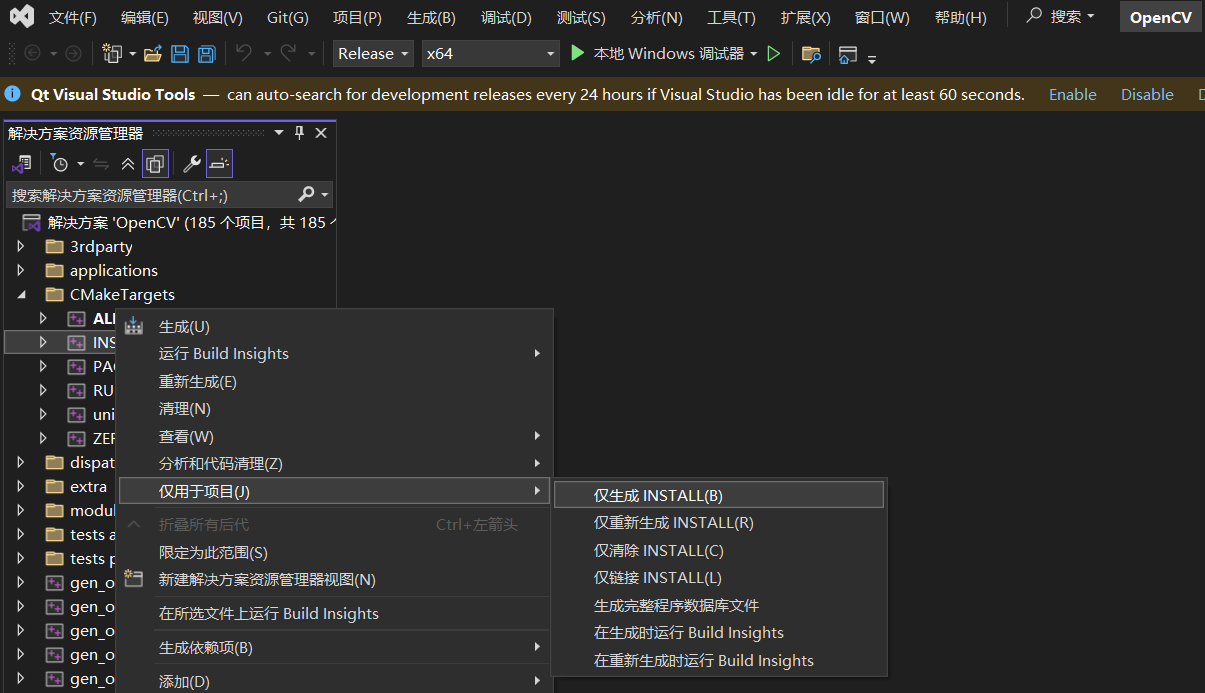
重新生成后,打卡生成的vs工程,先重新生成解决方案,然后安装:
执行完这一步后,就会生成install文件夹,如下图所示:
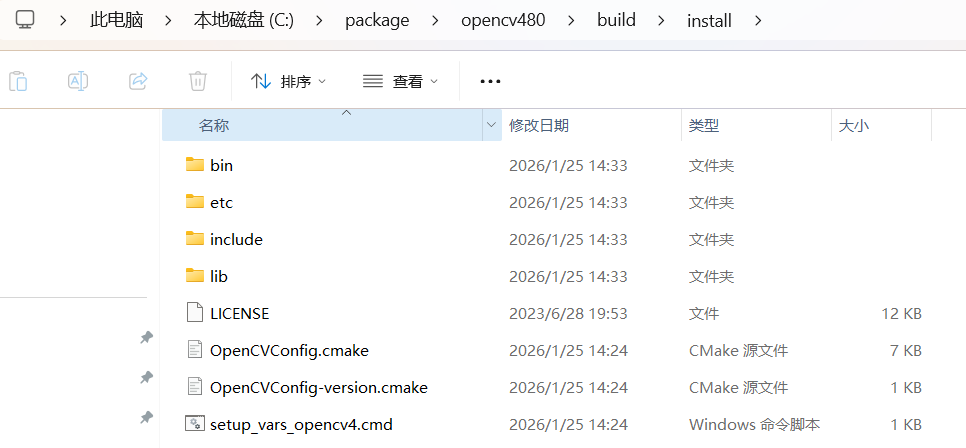
C:\package\opencv480\build\install\lib下包含OpenCVConfig.cmake和一系列必要的lib库。
2.2 构建CmakeLists.txt
这里主要用了opencv和cuda,这里我将cuda功能封装成lib库,然后用一个main.cpp去使用lib库中提供的接口,CMakeLists.txt文件如下所示:
c++
cmake_minimum_required(VERSION 3.18)
set(CMAKE_CXX_STANDARD 17)
PROJECT(opencv_cuda_demo LANGUAGES CXX CUDA)
set(OpenCV_DIR "C:/package/opencv480/build/install/lib")
FIND_PACKAGE(OpenCV REQUIRED)
set(CMAKE_MODULE_PATH "${CMAKE_SOURCE_DIR}/cmake;${CMAKE_MODULE_PATH}")
set (CUDA_ROOT "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.8")
find_package(CUDA)
set(CUDA_SOURCE_FILES src/cuda_lib/cuda_demo.cu)
cuda_add_library(cuda_lib ${CUDA_SOURCE_FILES} STATIC)
target_link_libraries(cuda_lib ${OpenCV_LIBS} ${CUBLAS_LIBRARIES})
FILE(GLOB SOURCES src/main.cpp)
ADD_EXECUTABLE(main ${SOURCES})
TARGET_LINK_LIBRARIES(main ${OpenCV_LIBS} cuda_lib)
target_compile_options(main PRIVATE "/MT")3、VSCode配置和相关代码
3.1 配置launch.json
c++
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "VS2022 调试 OpenCV-CUDA",
"type": "cppvsdbg", // 核心:VS2022编译必须用该调试器类型,替代原cppdbg
"request": "launch",
"program": "${workspaceFolder}/build/Debug/main.exe", // 你的可执行文件路径
"args": [], // 调试时传入的参数,对应你的--message
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIDebuggerPath": "C:/Program Files (x86)/Windows Kits/10/Debuggers/x86/cdb.exe",
"preLaunchTask": "build", // 调试前自动执行build任务,确保exe是最新的
"miDebuggerPath": "" // 清空gdb相关配置,避免冲突
}
]
}3.2 配置tasks.json
{
"version": "2.0.0",
"tasks": [
{
"label": "build",
"type": "shell",
// 核心修改:把 && 换成 ; ,PowerShell支持分号串联命令
"command": "cd build; cmake --build . -j22",
"group": {
"kind": "build",
"isDefault": true
},
"presentation": {
"echo": true,
"reveal": "always",
"focus": false,
"panel": "shared"
},
"problemMatcher": ["$msCompile"]
}
]
}3.3 相关代码
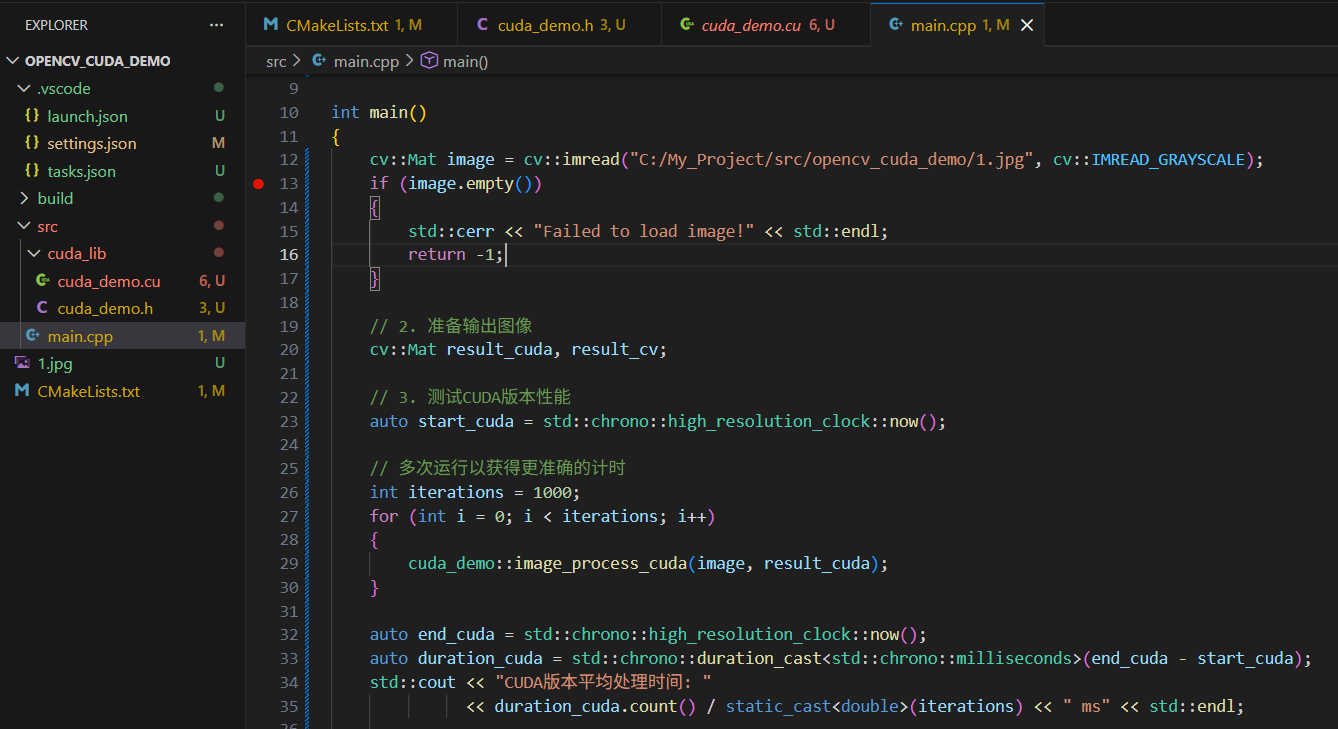
3.3.1 main.cpp
c++
#include <iostream>
#include <opencv2/opencv.hpp>
#include <cuda_runtime.h>
using namespace std::chrono;
#include "cuda_lib/cuda_demo.h"
int main()
{
cv::Mat image = cv::imread("C:/My_Project/src/opencv_cuda_demo/1.jpg", cv::IMREAD_GRAYSCALE);
if (image.empty())
{
std::cerr << "Failed to load image!" << std::endl;
return -1;
}
// 2. 准备输出图像
cv::Mat result_cuda, result_cv;
// 3. 测试CUDA版本性能
auto start_cuda = std::chrono::high_resolution_clock::now();
// 多次运行以获得更准确的计时
int iterations = 1000;
for (int i = 0; i < iterations; i++)
{
cuda_demo::image_process_cuda(image, result_cuda);
}
auto end_cuda = std::chrono::high_resolution_clock::now();
auto duration_cuda = std::chrono::duration_cast<std::chrono::milliseconds>(end_cuda - start_cuda);
std::cout << "CUDA版本平均处理时间: "
<< duration_cuda.count() / static_cast<double>(iterations) << " ms" << std::endl;
// 4. 测试OpenCV版本性能
auto start_cv = std::chrono::high_resolution_clock::now();
for (int i = 0; i < iterations; i++)
{
cuda_demo::image_process_cv(image, result_cv);
}
auto end_cv = std::chrono::high_resolution_clock::now();
auto duration_cv = std::chrono::duration_cast<std::chrono::milliseconds>(end_cv - start_cv);
std::cout << "OpenCV版本平均处理时间: "
<< duration_cv.count() / static_cast<double>(iterations) << " ms" << std::endl;
// 5. 计算加速比
double speedup = static_cast<double>(duration_cv.count()) / duration_cuda.count();
std::cout << "加速比: " << speedup << "x" << std::endl;
// 6. 显示结果对比
cv::imshow("原始图像", image);
cv::imshow("CUDA处理结果", result_cuda);
cv::imshow("OpenCV处理结果", result_cv);
cv::waitKey(0);
return 0;
}3.3.2 cuda_demo.h
c++
#pragma once
#include <iostream>
#include <opencv2/opencv.hpp>
#include <cuda_runtime.h>
namespace cuda_demo
{
void image_process_cuda(const cv::Mat& src, cv::Mat& dst);
void image_process_cv(const cv::Mat& src, cv::Mat& dst);
__global__ void process(uchar* src, int src_row, int src_col, int src_channel, uchar* dst, int dst_row, int dst_col, int dst_channel);
}3.3.3 cuda_demo.cu
c++
#include "cuda_demo.h"
namespace cuda_demo
{
// 简单的双边滤波CUDA实现(为演示简化版本)
__global__ void process(uchar* src, int src_row, int src_col, int src_channel,
uchar* dst, int dst_row, int dst_col, int dst_channel)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
// 只处理图像内部像素(边界不处理)
if (row < src_row && col < src_col && row >= 0 && col >= 0)
{
int kernel_size = 9; // 滤波器大小
int half_kernel = kernel_size / 2;
float spatial_sigma = 3.0f; // 空间域标准差
float range_sigma = 30.0f; // 值域标准差
float sum = 0.0f;
float weight_sum = 0.0f;
float center_pixel = src[row * src_col + col] / 255.0f;
// 遍历滤波器窗口
for (int i = -half_kernel; i <= half_kernel; i++)
{
for (int j = -half_kernel; j <= half_kernel; j++)
{
int new_row = row + i;
int new_col = col + j;
// 检查边界
if (new_row >= 0 && new_row < src_row && new_col >= 0 && new_col < src_col)
{
float current_pixel = src[new_row * src_col + new_col] / 255.0f;
// 空间距离权重(高斯)
float spatial_dist = expf(-(i*i + j*j) / (2.0f * spatial_sigma * spatial_sigma));
// 像素值差异权重(高斯)
float pixel_diff = center_pixel - current_pixel;
float range_weight = expf(-(pixel_diff * pixel_diff) / (2.0f * range_sigma * range_sigma));
// 组合权重
float weight = spatial_dist * range_weight;
sum += weight * current_pixel;
weight_sum += weight;
}
}
}
// 归一化并写回结果
if (weight_sum > 0.0f)
{
dst[row * src_col + col] = static_cast<uchar>(sum / weight_sum * 255.0f);
}
else
{
dst[row * src_col + col] = src[row * src_col + col];
}
}
}
void image_process_cuda(const cv::Mat& src, cv::Mat& dst)
{
// 检查输入图像是否是单通道灰度图
CV_Assert(src.channels() == 1 && src.type() == CV_8UC1);
// 确保dst大小和类型与src一致
if (dst.empty() || dst.rows != src.rows || dst.cols != src.cols || dst.type() != src.type())
{
dst.create(src.rows, src.cols, src.type());
}
// 分配GPU内存
uchar* srcData;
size_t src_size = src.rows * src.cols * sizeof(uchar);
cudaMalloc((void**)&srcData, src_size);
uchar* dstData;
size_t dst_size = dst.rows * dst.cols * sizeof(uchar);
cudaMalloc((void**)&dstData, dst_size);
// CPU -> GPU
cudaMemcpy(srcData, src.data, src_size, cudaMemcpyHostToDevice);
// 初始化输出为0
cudaMemset(dstData, 0, dst_size);
// 设置CUDA核函数执行配置
dim3 blockSize(16, 16);
dim3 gridSize((src.cols + blockSize.x - 1) / blockSize.x,
(src.rows + blockSize.y - 1) / blockSize.y);
// 启动核函数
process<<<gridSize, blockSize>>>(srcData, src.rows, src.cols, src.channels(),
dstData, dst.rows, dst.cols, dst.channels());
// 等待核函数执行完成
cudaDeviceSynchronize();
// GPU -> CPU
cudaMemcpy(dst.data, dstData, dst_size, cudaMemcpyDeviceToHost);
// 释放GPU内存
cudaFree(srcData);
cudaFree(dstData);
// 检查CUDA错误
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess)
{
std::cerr << "CUDA error: " << cudaGetErrorString(err) << std::endl;
}
}
void image_process_cv(const cv::Mat& src, cv::Mat& dst)
{
// 检查输入图像是否是单通道灰度图
CV_Assert(src.channels() == 1 && src.type() == CV_8UC1);
// 双边滤波参数(与CUDA版本对应)
int kernel_size = 9; // 滤波器大小
double sigma_color = 30.0; // 值域标准差
double sigma_space = 3.0; // 空间域标准差
// 使用OpenCV的双边滤波
cv::bilateralFilter(src, dst, kernel_size, sigma_color, sigma_space, cv::BORDER_DEFAULT);
}
}3.4 目录结构
3.5 结果
对比是用的双边滤波算法,加速幅度并不明显,包含数据搬运消耗的时间。运行相关指令:
cmake ..
cmake --build .